基於低差異度數列交叉檢驗的數據分類優化方法及系統與流程
2024-02-10 10:19:15 3
本發明屬於數據挖掘和機器學習分類領域,尤其涉及一種基於低差異度數列交叉檢驗的數據分類優化方法及系統。
背景技術:
目前,監督機器學習(supervisedmachinelearning)技術在人工智慧輔助醫療數據分類的已經開始得到應用。其思想為用一個監督機器學習分類算法統計模型(下簡稱分類學習模型),通過統計大量已經被人類分類的醫療歷史數據,來學習人類的分類能力,從而達到輔助人類來準確對醫療數據進行分類的目的。通常情況下,其實施流程為:
(1)首先收集一個數據集,內含大量就診人員的臨床診斷歷史數據,其中包括這些就診人員的各種醫學和生化檢驗的特徵信息(比如血壓,心率等特徵)和就診人員的分類標籤(比如把就診人員分成健康人員或病患,輕度患病或重度患病,就診人員的細胞存活或死亡等類別);(2)然後採用一種監督機器學習方法,設立一個分類學習模型(比如,採用邏輯回歸算法,建立一個線性回歸模型),對這個數據集做交叉驗證(crossvalidation,亦稱循環估計)。交叉驗證包括訓練和測試兩個部分。通常情況下,該數據集的樣本被隨機分入到k個子集裡,利用k-1個子集來訓練模型,映射訓練集中就診人員的特徵和和醫生的診斷分類之間的關係。餘下一個子集作來對之前訓練好的模型進行測試,衡量之前在訓練集中得到的特徵和診斷分類之間的映射關係是否也存在於測試集的數據裡,由此得到一個預測分類準確率。(3)如果準確率達到或超過預先設定的合格分類水平,則該統計模型通過交叉檢驗,可以直接被部署應用;如果準確度不高,則需要研究人員修改統計模型或使用另外一種監督機器學習方法,重做交叉測試,直到通過為止。
理想的交叉檢驗方法必須遵守子集代表性(representativesubsets)條件。也就是說每個子集必須從全部樣本歷史數據(下簡稱全部樣本數據)中均勻取樣。均勻取樣的目的是希望減少每個子集與全部數據之間的偏差,使得特徵和診斷分類之間的映射關係在每個子集裡都能很好得存在。這k個子集數據應為全部樣本數據的有代表性的縮小版,盡最大可能地保留全部樣本數據的特徵和診斷分類之間的映射信息。其中,最常用的交叉檢驗方法是隨機10-折交叉檢驗(randomk-foldcrossvalidation,k=10)。
該方法先對全部樣本數據中得每個樣本的序號進行編號。然後利用一個計算機生產的偽隨機數列(pseudorandomnumbersequence)。該數列所有數字為不重複的整數,最小為1,最大為全部樣本數據的樣本量。這些數字在該數列裡排列的次序為隨機的。每個數字對應全部樣本數據一個樣本的序號。先將該偽隨機數列分成10個等份,然後把每個等份裡的偽隨機數所對應的全部樣本數據樣本抽出放入到一個子集中,依次把全部樣本數據樣本分配到10個子集裡。
每次實驗輪流用取一份子集做測試集,餘下的9份作為訓練集。每次先在訓練集上訓練模型,得到相應的假設統計模型,然後用測試集測試假設統計模型,計算該模型的預測分類準確率。隨機k折交叉檢驗需要循環進行k次實驗,即每一子集都會作為一次測試集,因此會得到k個預測分類準確率。最後取這k個預測分類準確率的平均值(以下稱為k折平均預測分類準確率)為該模型的評價指標,用於跟預先設定的合格分類水平進行比較。
這種交叉檢驗方法依賴一個計算機生成的偽隨機數列,而偽隨機數列的產生則依賴於隨機種子。使用一個偽隨機數列劃分子集會對於隨機種子非常敏感。如果使用不同的隨機種子,每次做交叉檢驗,都會劃分都可能把全部樣本數據樣本劃分到不同的子集裡。如果同一個模型重複做若干次交叉檢驗,每次交叉驗證的時候會得到不同的k折平均預測分類準確率。因此,為了抵消隨機數列帶來的子集不確定性,研究人員往往需要用不同的隨機種子重複幾十次該交叉檢驗過程,然後對這幾十個k折平均預測分類準確率求平均值,作為該模型的預測分類準確率。但是重複幾十次不光計算成本較大,而且也不能很好地解決子集缺乏代表性問題。也就是說,即使重複幾十次交叉檢驗,每個子集的預測分類準確率依然差別很大(即子集之間的預測分類準確率標準方差較大,最好和最低預測分類準確率的間距較大)。
綜上所述,針對醫療信息系統的資料庫內的樣本數據做交叉檢驗的過程中,往往採用現有的隨機k折交叉檢驗方法來對當前訓練完成的分類學習模型進行交叉檢驗,以評估其預測分類準確率,比如:
對1000個來自醫療信息系統的資料庫內的心臟樣本數據進行分類,其中,每個心臟數據樣本的分類標籤為健康和不健康,每個心臟樣本的生化檢驗的特徵信息(包括每個心臟所屬患者的年齡、性別、胸部疼痛類別、靜止血壓、血清膽固醇含量、空腹血糖和最大心率);將1000個心臟樣本數據隨機分到10個子集中,利用這10個子集來對一個分類學習模型進行交叉檢驗。由於每個子集內的心臟數據樣本依賴一個計算機生成的偽隨機數列,使用一個偽隨機數列劃分的這10個子集缺乏代表性,該模型極有可能在訓練的時候不能很好地反映特徵和分類標籤的映射關係,因此測試效果不好或無意義,導致研究人員對該分類學習模型作出錯誤的評估,進而降低了醫療數據分類的效率。
技術實現要素:
為了解決上述技術問題,本發明的第一目的是提供一種基於低差異度數列交叉檢驗的數據分類優化方法。該方法能夠提高模型交叉檢驗的效率。
本發明的一種基於低差異度數列交叉檢驗的數據分類優化方法,包括:
步驟1:從醫療信息系統的資料庫中提取就診人員歷史醫療數據,所述就診人員歷史醫療數據包括分類標籤和生化檢驗的特徵信息;利用提取的就診人員歷史醫療數據構建出樣本數據矩陣;
步驟2:對樣本數據矩陣進行降維處理得到的一維數列作為抽樣框架,再結合一個均勻分布的低差異度數列,將提取的醫療數據樣本數據矩陣均勻分成k個子集;其中k為大於1的正整數;
步驟3:根據一個監督機器學習分類算法,構建一個分類學習模型,用k個子集中的數據進行交叉檢驗;其中用k-1個子集訓練該分類學習模型,得到該分類學習模型的各項係數;然後用餘下的一個子集做測試,得到該分類學習模型的預測分類準確率;依次循環k次,最後對得到的k個預測分類準確率求平均值,得到該分類學習模型的平均預測分類準確率;
步驟4:判斷該分類學習模型的平均預測分類準確率是否大於或等於預設預測分類準確率閾值,若是,則該分類學習模型符合要求;否則,提示研究人員修改該分類學習模型或使用另外一個監督機器學習分類算法構建新的模型,返回步驟3。
該方法還包括:將待分類的醫療數據輸入至符合要求的分類學習模型中進行分類並輸出分類結果。
進一步的,所述步驟1中的樣本數據矩陣的第一列由相應就診人員樣本的分類標籤構成,其他列由相應就診人員樣本的生化檢驗的特徵信息構成。
其中,就診人員樣本的分類標籤包括就診人員的細胞存活和死亡,或就診人員健康和就診人員不健康,疾病驗證輕微或嚴重等。
就診人員樣本的生化檢驗的特徵信息包括血壓、心率、血糖含量和血細胞含量。除了上述生化檢驗的特徵信息之外,還包括其他現有特徵信息,此處將不再舉例說明。
進一步的,所述步驟2的具體過程,包括:
步驟2.1:構建由至少一種降維方法組成的降維方法集合,利用降維方法分別對樣本數據矩陣進行降維處理,得到相應一維數列;再分別對相應一維數列進行離差標準化,得到相應離差標準化一維數列;離差標準化一維數列中每個數據的取值均介於0-1之間,且小數點後保留預設位數(比如保留3位或4位等);
步驟2.2:利用圓周率π的正整數倍的小數部分構建一系列低差異數,並且使得該低差異數的小數點後保留數字位數與步驟2.1預設小數點後保留數字位數相等;
比較每個低差異數和離差標準化一維數列中數據的大小,將與所述低差異度數相等的數據逐個分配到預設的k個臨時容器裡;一直循環本步驟,直到把離差標準化一維數列的數值分配到k個臨時容器裡,每個臨時容器為一個子集。
由於k個臨時容器裡每個離差標準化一維數列上的數字對應樣本數據矩陣中的一個樣本(即矩陣的一行),可以從樣本數據矩陣相對應的樣本分配到相對應的k個子集中。每個子集中的樣本數相等,且子集樣本數的總和等於全集數據矩陣中所代表的樣本數。
進一步的,本發明採用降維方法來保留樣本數據矩陣的最重要信息,降維後的離差標準化一維數列作為抽樣框架(samplingframe)。
不同的降維方法保留樣本數據矩陣信息的程度會略有不同。
降維方法可以使用:主成分分析方法、核主成分分析方法、因子分析方法、截斷奇異值分解方法和多維度尺度分析方法,或者其他現有的降維方法。
本發明可以使用單個降維方法,也可以用降維方法集合來包括兩個、三個或其他數量的降維方法,依次對樣本數據矩陣進行降維。
進一步的,本發明需要用一個低差異數在離差標準化一維數列中匹配相等的數值。小數點後保留預設位數會影響匹配的精度,位數越多,精度越高,但計算時間越長。保留預設位數可以設為3位,4位,5位或6位。
進一步的,所述步驟3具體包括:
步驟3.1:根據一個監督機器學習分類算法,建立一個分類學習模型;
其中,監督機器學習分類算法可以包括任何一種現成的監督機器學習分類算法,比如邏輯回歸,神經網絡、決策樹或樸素貝葉斯;分類學習模型是一個算法的實施實例,比如一個線性回歸模型是邏輯回歸算法的實施實例;
步驟3.2:使用上述k個子集的數據對該分類學習模型進行循環交叉驗證,得到相應k個預測分類準確率並存儲至一個臨時結果集合內;
步驟3.3:對臨時結果集合中的k個預測分類準確率求平均值,將該平均值存入平均預測準確率集合中。
本發明採用保留樣本數據矩陣的最重要信息的一維數列作為抽樣框架(samplingframe)和低差異度數列均勻分布的性質,本發明能實現每個子集之間差異度較小且都能代表樣本數據矩陣的信息,提高分類學習模型的訓練效率,從而降低每個子集之間的預測分類準確率的差異,也進一步提高最終的k折平均預測分類準確率。
本發明的第二目的是提供一種基於低差異度數列交叉檢驗的數據分類優化系統。
本發明的一種基於低差異度數列交叉檢驗的數據分類優化系統,包括:
樣本數據導入模塊,其用於從醫療信息系統的資料庫中提取就診人員歷史醫療數據,所述就診人員歷史醫療數據包括分類標籤和生化檢驗的特徵信息;利用提取的就診人員歷史醫療數據構建出樣本數據矩陣;
子集數據分配模塊,其用於對樣本數據矩陣進行降維處理得到的一維數列作為抽樣框架,再結合一個均勻分布的低差異度數列,將提取的醫療數據樣本數據矩陣均勻分成k個子集;其中k為大於1的正整數;
交叉檢驗模塊,其用於根據一個監督機器學習分類算法,構建一個分類學習模型,用k個子集中的數據進行交叉檢驗;其中用k-1個子集訓練該分類學習模型,得到該分類學習模型的各項係數;然後用餘下的一個子集做測試,得到該分類學習模型的預測分類準確率;依次循環k次,最後對得到的k個預測分類準確率求平均值,得到該分類學習模型的平均預測分類準確率;
分類學習模型優化模塊,其用於判斷該分類學習模型的平均預測分類準確率是否大於或等於預設預測分類準確率閾值,若是,則該分類學習模型符合要求;否則,提示研究人員修改該分類學習模型或使用另外一個監督機器學習分類算法構建新的模型。
該系統還包括:數據分類模塊,其用於將待分類的醫療數據輸入至符合要求的分類學習模型中進行分類並輸出分類結果。
進一步的,在所述樣本數據導入模塊中,樣本數據矩陣的每一行代表一個就診人員樣本,樣本數據矩陣的列由相應就診人員樣本的分類標籤和生化檢驗的特徵信息構成。
其中,就診人員樣本的分類標籤包括就診人員存活和就診人員死亡,或就診人員健康和就診人員不健康,疾病嚴重程度輕和高。就診人員樣本的生化檢驗的特徵信息包括血壓、心率、血糖含量和血細胞含量。
除了上述生化檢驗的特徵信息之外,還包括其他現有特徵信息,此處將不再舉例說明。
進一步的,所述子集數據分配模塊,包括:
降維模塊,其用於構建由至少一種降維方法組成的降維方法集合,利用降維方法分別對樣本數據矩陣進行降維處理,得到相應一維數列;再分別對相應一維數列進行離差標準化,得到相應離差標準化一維數列;離差標準化一維數列中每個數據的取值均介於0-1之間,且小數點後保留預設位數(比如保留3位或4位等);
樣本數據分配模塊,其用於利用圓周率π的正整數倍的小數部分構建一系列低差異數,並且使得該低差異數的小數點後保留數字位數與預設小數點後保留數字位數相等;
比較每個低差異數和離差標準化一維數列中數據的大小,將與所述低差異度數相等的數據逐個分配到預設的k個臨時容器裡;一直循環本步驟,直到把離差標準化一維數列的數值分配到k個臨時容器裡,每個臨時容器為一個子集。
由於k個臨時容器裡每個離差標準化一維數列上的數字對應樣本數據矩陣中的一個樣本(即矩陣的一行),可以從樣本數據矩陣相對應的樣本分配到相對應的k個子集中。每個子集中的樣本數相等,且子集樣本數的總和等於全集數據矩陣中所代表的樣本數。
進一步的,本發明採用降維方法來保留樣本數據矩陣的最重要信息,降維後的離差標準化一維數列作為抽樣框架(samplingframe)。
不同的降維方法保留樣本數據矩陣信息的程度會略有不同。
降維方法可以使用:主成分分析方法、核主成分分析方法、因子分析方法、截斷奇異值分解方法和多維度尺度分析方法,或者其他現有的降維方法。
本發明可以使用單個降維方法,也可以用降維方法集合來包括兩個、三個或其他數量的降維方法,依次對樣本數據矩陣進行降維。
進一步的,本發明需要用一個低差異數在離差標準化一維數列中匹配相等的數值。小數點後保留預設位數會影響匹配的精度,位數越多,精度越高,但計算時間越長。保留預設位數可以設為3位,4位,5位或6位。
進一步的,所述交叉檢驗模塊,包括:
分類學習模型構建模塊,其用於根據一個監督機器學習分類算法,建立一個分類學習模型;其中,監督機器學習分類算法可以包括任何一種現成的監督機器學習分類算法,比如邏輯回歸,神經網絡、決策樹或樸素貝葉斯;分類學習模型是一個算法的實施實例,比如一個線性回歸模型是邏輯回歸算法的實施實例;
預測分類準確率存儲模塊,其用於使用上述k個子集的數據對該分類學習模型進行循環交叉驗證,得到相應k個預測分類準確率並存儲至一個臨時結果集合內;
平均預測分類準確率計算模塊,其用於對臨時結果集合中的k個預測分類準確率求平均值,將該平均值存入平均預測準確率集合中。
本發明還提供另一種基於低差異度數列交叉檢驗的醫療數據分類學習模型優化的系統。
本發明的另一種基於低差異度數列交叉檢驗的醫療數據分類學習模型優化的系統,包括:
數據採集裝置,其被配置為:從醫療信息系統的資料庫中提取就診人員歷史數據;所述就診人員歷史數據包括分類標籤和生化檢驗的特徵信息;及
數據分類優化伺服器,其被配置為:
接收就診人員歷史醫療數據,構建樣本數據矩陣,對樣本數據矩陣進行降維處理得到的一維數列作為抽樣框架,再結合一個均勻分布的低差異度數列,將提取的醫療數據樣本數據矩陣均勻分成k個子集;
根據一個監督機器學習分類算法,構建一個分類學習模型,用k個子集中的數據進行交叉檢驗。其中用k-1個子集訓練該模型,得到該模型的各項係數。然後用餘下的一個子集做測試,得到預測分類準確率。依次循環k次,最後對這k個預測分類準確率求平均值;
判斷該分類學習模型的k折平均預測分類準確率是否大於或等於預設預測分類準確率閾值,若是,則該分類學習模型符合要求;否則,提示研究人員修改該分類學習模型或使用另外一個監督機器學習分類算法構建新的模型。
進一步的,所述數據分類優化伺服器,還被配置為:
將待分類的醫療數據輸入至符合要求的分類學習模型中進行分類並輸出分類結果。
進一步的,所述數據分類優化伺服器,還被配置為:
利用降維方法分別對樣本數據矩陣進行降維處理,得到相應一維數列;再分別對相應一維數列進行離差標準化,得到相應離差標準化一維數列;離差標準化一維數列中每個數據的取值均介於0-1之間,且小數點後保留預設位數;
利用圓周率π的正整數倍的小數部分構建一系列低差異數,並且使得該低差異數的小數點後保留數字位數與步驟2.1預設小數點後保留數字位數相等。比較小數點後保留預設位數的離差標準化一維數列和一個低差異度數列中數據的大小,將與所述低差異度數列中相等的數據逐個分配到預設的k個臨時容器裡。一直循環直到把一維數列的數值分配到k個臨時容器裡,每個臨時容器為一個子集。
由於k個臨時容器裡每個一維數列上的數字對應樣本數據矩陣中的一個樣本(即矩陣的一行),可以從樣本數據矩陣相對應的樣本分配到相對應的k個子集中。每個子集中的樣本數相等,且子集樣本數的總和等於全集數據矩陣中所代表的樣本數。
建立一個監督機器學習分類學習模型。使用上述k個子集的數據對該分類學習模型進行循環交叉驗證,得到相應預測分類準確率並存儲至一個臨時結果集合內。對臨時結果集合中的k個預測分類準確率求平均值,將該平均值存入預測準確率集合中。
最後判斷醫療數據的分類學習模型的預測分類準確率是否大於或等於預設預測分類準確率閾值,若是,則醫療數據的分類學習模型符合要求,則可以部署該模型,將新的待分類的醫療數據至該模型進行分類並輸出分類結果;否則,繼續對分類學習模型進行修改或使用另外一種監督機器學習分類算法構建新的模型。
與現有技術相比,本發明的有益效果是:
本發明利用超越數π(圓周率)的小數點後數字有無限不循環的特徵來產生一個均勻分布的低差異度數列,來取代目前隨機k-折交叉檢驗技術中使用的一個隨機數列,然後利用降維方法來保留樣本數據矩陣的最重要信息到一個一維數列,該一維數列離差標準化後作為抽樣框架。利用這兩個數列可以將全部樣本數據均勻地分成若干個子集,實現子集之間的低差異度,進而能夠得到當前訓練完成的分類學習模型可靠的預測分類準確率,而且在無需改進具體機器學習算法的情況下,大大提高了分類學習模型的訓練效率,減少了交叉檢驗計算時間,最終減少了醫療數據分類過程的時間,提高了醫療數據分類的效率。
附圖說明
構成本申請的一部分的說明書附圖用來提供對本申請的進一步理解,本申請的示意性實施例及其說明用於解釋本申請,並不構成對本申請的不當限定。
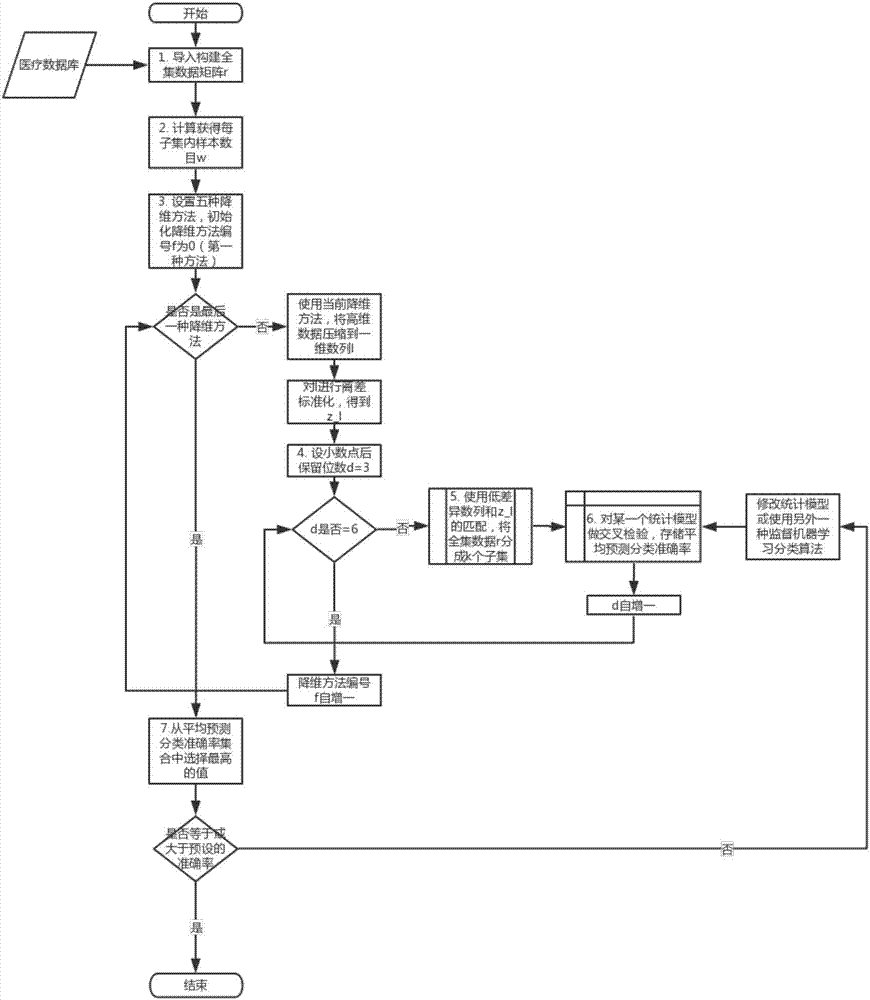
圖1是本發明的一種基於低差異度數列交叉檢驗的醫療數據分類學習模型優化方法的流程圖。
圖2是本發明的一種基於低差異度數列交叉檢驗的醫療數據分類學習模型優化方法的具體實施流程圖。
圖3是將樣本數據矩陣均勻分成k個子集。
圖4是子集對分類學習模型進行交叉驗證的流程圖。
圖5是本發明的一種基於低差異度數列交叉檢驗的數據分類優化系統結構示意圖。
圖6是本發明的另一種基於低差異度數列交叉檢驗的數據分類優化系統結構示意圖。
具體實施方式
應該指出,以下詳細說明都是例示性的,旨在對本申請提供進一步的說明。除非另有指明,本文使用的所有技術和科學術語具有與本申請所屬技術領域的普通技術人員通常理解的相同含義。
需要注意的是,這裡所使用的術語僅是為了描述具體實施方式,而非意圖限制根據本申請的示例性實施方式。如在這裡所使用的,除非上下文另外明確指出,否則單數形式也意圖包括複數形式,此外,還應當理解的是,當在本說明書中使用術語「包含」和/或「包括」時,其指明存在特徵、步驟、操作、器件、組件和/或它們的組合。
圖1是本發明的一種基於低差異度數列交叉檢驗的數據分類優化方法的流程圖。
如圖1所示的基於低差異度數列交叉檢驗的數據分類優化方法,包括:
步驟1:從醫療信息系統的資料庫中提取就診人員歷史醫療數據,所述就診人員歷史醫療數據包括分類標籤和生化檢驗的特徵信息;利用提取的就診人員歷史醫療數據構建出樣本數據矩陣。
具體地,就診人員樣本的分類標籤包括就診人員存活和就診人員死亡,或就診人員健康和就診人員不健康,或疾病驗證輕微或嚴重等。
就診人員樣本的生化檢驗的特徵信息包括血壓、心率、血糖含量和血細胞含量。除了上述生化檢驗的特徵信息之外,還包括其他現有特徵信息,此處將不再舉例說明。
下面以樣本為美國克利夫蘭市醫院的心臟病就診數據為例:
從醫療資料庫獲得297個就診人員的歷史數據,得到297個就診人員樣本,就診人員的分類標籤為心血管造影疾病嚴重狀況,從0到4,「0」表示正常,「4」表示心血管的直徑嚴重變小或嚴重堵塞,「1-3」表示心血管的直徑嚴重變小不同程度或嚴重堵塞不同程度。
就診人員樣本的生化檢驗的特徵信息包括:年齡,性別,胸部疼痛類別,靜止血壓,血清膽固醇含量,空腹血糖,心電圖結果,最大心率,運動引起的心絞痛,相對於其餘的運動誘發心電圖st段壓低值,心電圖st段的斜率,大血管被透視著色數及地貧因素。
全部樣本數據矩陣r是一個297行*14列的矩陣。
在該步驟中,通過計算樣本數據矩陣r的行數,即可得到樣本數據矩陣r中的樣本總量s。本例s=297,而且本實施例設定子集數k=10,那麼繼續可計算出10個子集裡每個子集的樣本數w,w=s/k且w取整數,即w=30。
步驟2:對樣本數據矩陣進行降維處理得到的一維數列,再結合一個均勻分布的低差異度數列,將提取的就診人員歷史醫療數據均勻分成k個子集。
具體地,如圖2和3所示,所述步驟2的具體過程,包括:
步驟2.1:構建由至少一種降維方法組成的降維方法集合,利用降維方法分別對樣本數據矩陣進行降維處理,得到相應一維數列;再分別對相應一維數列進行離差標準化,得到相應離差標準化一維數列;離差標準化一維數列中每個數據的取值均介於0-1之間,且小數點後保留預設位數(比如保留3位或4位等);
步驟2.2:利用圓周率π的正整數倍的小數部分構建一系列低差異數,並且使得該低差異數的小數點後保留數字位數與步驟2.1預設小數點後保留數字位數相等。比較每個低差異數和離差標準化一維數列中數據的大小,將與所述低差異度數相等的數據逐個分配到預設的k個臨時容器裡。一直循環本步驟,直到把離差標準化一維數列的數值分配到k個臨時容器裡,每個臨時容器為一個子集。由於k個臨時容器裡每個離差標準化一維數列上的數字對應樣本數據矩陣中的一個樣本(即矩陣的一行),可以從樣本數據矩陣相對應的樣本分配到相對應的k個子集中。每個子集中的樣本數相等,且子集樣本數的總和等於全集數據矩陣中所代表的樣本數。
在具體實施中,設置降維方法集合,可以只使用一個降維方法,也可以包括兩個、三個或其他數量。需要說明的是,降維方法可以是任何現有的降維方法,比如主成分分析方法、核主成分分析方法、因子分析方法、截斷奇異值分解方法和多維度尺度分析方法。
在該步驟中,如圖2和3所示,具體的步驟2.1過程包括:
a)初始化降維方法編號f為0(即第一種方法);
b)判斷降維方法編號f是否是4(即最後一種方法)。如果為否,則:
b.1.)使用當前降維方法將全部樣本數據矩陣降到一維數列ζ(即從14列降到只有一列)。
b.2.)對ζ進行離差標準化,得到z_ζ(即值介於0-1之間)。接下來執行步驟2.2,降維方法編號f自增1,之後返回b)。
c)如果降維方法編號f等於4(即最後一種方法),接下來執行步驟4:
具體的步驟2.2過程包括
步驟2.2.1:設置小數點保留數字的位數
具體地,
a)初始化小數點保留數字的位數d為3。
b)判斷d是否為6,如果為否,則進入步驟2.2.2。
c)如果d等於6,則降維方法編號f自增一(即指向下一個降維方法),循環執行該步驟,直到降維方法編號f等於4(即最後一種方法)。
需要說明的是,設置小數點保留數字的位數是為了設置不同的匹配精度,保留位數越高越精確但計算時間越多。
步驟2.2.2:分配樣本數據至k個子集(k=10)
具體地,如圖2和3所示,
a)從之前的幾個步驟輸入全集數據矩陣r,每個子集的樣本數w,子集數k,離差標準化後的一維數列z_ζ和小數點後保留的位數d。在本例中,樣本數據矩陣r是一個297行x14列的矩陣。w為30。k為10個子集。
b)將z_ζ中的每個數字只保留小數點後d位,d已經在步驟2.2.1中設置好。
c)初始化g等於1。
d)初始化單個子集內已有的樣本量s為0。
e)設置空集合k,內含k個空子集,初始化當前子集編號k_id為0(即指向第一個空子集)。
f)為當前子集選擇樣本:
f.1)判斷k_id是否等於k-1(即k中的最後一個子集),如果為否,則:
f.1.1)判斷當前子集內已有的樣本量s已經等於w,如果為否,則:
●產生一個低差異數lds,使之等於g與圓周率(即3.141592653589793238462)的積的小數部分,保留小數點後d位。
●在z_ζ內找到與lds一致的數字a。
●獲取a在z_l內的正向序號a_i。在r中獲得a_i所對應的那行數據,存入當前子集中。
●a的值改為999,使得a永不會再被選中。
·s自增一。
·g自增一。
·循環執行f.1.1步驟,直到s=w
f.1.2.)如果當前子集內已有的樣本量s已經等於w,則子集編號k_id自增一
f.1.3.)s歸零。
f.1.4.)循環執行f.1.步驟,直到當前子集是k中的最後一個子集。
f.2)如果當前子集是k中的最後一個子集,則將r中餘下未被選的數據放入最後一個子集。
g)返回k,內含k個子集數據(在本例中,為10個子集)。執行步驟3。
步驟3,用k個子集數據對該分類學習模型進行交叉驗證(其中包含訓練和測試),得到若干個相應的預測分類準確率指標,並存儲至預測分類準確率集合內。
具體地,如圖4所示:
a)從步驟2輸入k(在本例中,為10個子集)。
b)初始化當前測試集編號test_id=0(即指向k中的第一個子集數據)。
b.1.)判斷test_id是否等於k-1(即當前測試集已經是k個子集中的最後一個),如果為否,則:
b.1.1.)將當前測試集之外的k中其他子集合併,作為訓練集。
b.1.2.)利用訓練子集訓練一個監督機器學習算法的統計模型,比如邏輯回歸(logisticregression),樸素貝葉斯(bayes),支持向量機(supportvectormachine)和決策樹(decisiontree)等等。本例使用邏輯回歸算法,建立一個多分量的邏輯回歸模型。用訓練子集的數據得出該回歸模型的13個特徵變量的回歸係數。
b.1.3.)使用測試子集檢驗b.1.2中訓練好的統計模型。即把測試子集的13個特徵列代入b.1.2中得到多分量的邏輯回歸模型,通過分別乘以b.1.2中得到的回歸係數,預測出測試子集裡每個樣本的分類標籤(在本例中為心血管造影疾病嚴重狀況的五個等級)。通過對比預測出測試子集裡每個樣本的預測分類標籤和實際分類標籤,計算出在這個測試子集中,該統計模型的預測準確率。
b.1.4.記錄在這個測試子集中,該統計模型的預測準確率到一個臨時預測準確率集合中。
b.1.5.)測試集編號test_id自增一,指向k中的下一個子集數據。循環執行b步驟,直到判斷測試集已經是k個子集中的最後一個。
c)測試集已經是k個子集中的最後一個,則計算k次循環後該外部機器學習算法模型泛化指標的平均值,即求臨時預測準確率集合中的10個數值的平均值(稱作k折平均預測分類準確率),存儲入一個平均預測準確率集合中。
d)接下來返回步驟2。
步驟4:步驟2和步驟3的循環完成後,平均預測準確率集合中共包含20個k折平均預測分類準確率(即4x5,小數點後保留位數d的四種設置乘以五種降維方法f)。在這個20個指標裡找到最高者,判斷其是否大於或等於預設預測分類準確率閾值,若是,則該分類學習模型符合要求;否則,提示研究人員修改該分類學習模型或使用另外一個監督機器學習分類算法構建新的模型,返回步驟3。
該方法還包括:將待分類的醫療數據輸入至符合要求的分類學習模型中進行分類並輸出分類結果。
在本例中,由於10個子集之間差異度較小,都能代表全集矩陣的信息,該邏輯回歸模型得到了很好的訓練,所以最佳的平均預測分類準確率為60.51%,10個子集之間的預測分類準確率很接近(最高和最低預測分類準確率間的差距為20%,標準方差為0.058)。該邏輯回歸模型也用傳統的隨機10-折交叉檢驗來訓練和測試,並且重複30次(即用30個不同的隨機種子產生30個不同的偽隨機數列),平均預測分類準確率為57.91%(最高和最低預測分類準確率間的差距為50%,標準方差為0.083)。
為了證明本方法的有益結果,使用另外8個醫學數據集做對比(見表一)。進一步地,我們使用另外一種分類算法--決策樹(一種非參數、非線性分類算法)對這些數據集分別用本發明和傳統隨機10折交叉檢驗法做分析。對比結果顯示在表二和表三。
表一9個醫學數據集描述性統計
註明:標籤不均勻度指的是樣本分類標籤的分布是否均勻(0為最均勻)
表二邏輯回歸交叉檢驗結果對比
表三決策樹交叉檢驗結果對比
實驗結果表明,在使用同一種機器學習算法且參數設置完全相同的情況下,使用本方法訓練和測試模型後,邏輯回歸分類算法的準確率(classificationaccuracy)平均提高了1%,最高和最低預測準確率區間變小了100%,標準方差(variance)降低18%;決策樹算類方法的準確率平均提高了31%,最高和最低預測準確率區間變小了149%,方差降低40%。實驗證明,由於本發明能明顯降低訓練集和測試集之間的差異度,研究人員在不改進監督機器學習分類算法的情況下,使用本發明來訓練統計模型,預測分類準確率有明顯的提升且和穩定性能指標更好(即最高和最低預測準確率區間和標準方差都變得更小)。
本發明的該方法利用超越數π(圓周率)的小數點後數字有無限不循環的特徵來產生一個均勻分布的低差異度數列,來取代目前隨機k-折交叉檢驗技術中使用的一個隨機數列,然後利用降維方法來保留樣本數據矩陣的最重要信息到一個一維數列作為抽樣框架(samplingframe),利用這兩個數列可以將全部樣本數據均勻地分成若干個子集,實現子集之間的低差異度,進而能夠得到當前訓練完成的分類學習模型可靠的預測分類準確率,而且在無需改進具體機器學習算法的情況下,大大提高了預設分類學習模型的訓練效率,減少了交叉檢驗計算時間,最終減少了醫療數據分類過程的時間,提高了醫療數據分類的效率。
圖5是本發明的一種基於低差異度數列交叉檢驗的數據分類優化系統結構示意圖。
如圖5所示,本發明的一種基於低差異度數列交叉檢驗的數據分類優化系統,包括:
(a)樣本數據導入模塊,其用於(1)從醫療信息系統的關係型資料庫中提取多個就診人員的歷史數據,生成一個全集數據矩陣,每一行是一個就診者樣本,第一列為就診者的醫生診斷分類標籤(比如健康或不健康,輕度患病或嚴重患病,存活或死亡等等),其餘的每一列是就診者的一個特徵(比如血壓,心率等);需要說明的是,這樣能夠快速準確地查看就診人員樣本的分類標籤,但是就診人員樣本的分類標籤也可以設置在其他列,並不影響本發明的整體交叉檢驗方法的效果。(2)計算全集數據矩陣的總樣本數,以及平均分配到k個子集裡的每個子集的樣本數。
下面以樣本為美國克利夫蘭市醫院的心臟病就診數據為例說明:
從醫療資料庫獲得297個就診人員的歷史數據,得到297個就診人員樣本,就診人員的分類標籤為心血管造影疾病嚴重狀況,從0到4,「0」表示正常,「4」表示心血管的直徑嚴重變小或嚴重堵塞,「1-3」表示心血管的直徑嚴重變小不同程度或嚴重堵塞不同程度。
就診人員樣本的生化檢驗的特徵信息包括:年齡,性別,胸部疼痛類別,靜止血壓,血清膽固醇含量,空腹血糖,心電圖結果,最大心率,運動引起的心絞痛,相對於其餘的運動誘發心電圖st段壓低值,心電圖st段的斜率,大血管被透視著色數及地貧因素。
通過計算樣本數據矩陣r的行數,即可得到樣本數據矩陣r中的樣本總量s。本例s=297,而且本實施例設定子集數k=10,那麼繼續可計算出10個子集裡每個子集的樣本數w,w=s/k且w取整數,即w=30。
(b)子集數據分配模塊,其用於對樣本數據矩陣進行降維處理得到的一維數列作為抽樣框架,再結合一個均勻分布的低差異度數列,將提取的醫療數據樣本數據矩陣均勻分成k個子集;其中k為大於1的正整數。
所述子集數據分配模塊,包括:
降維模塊,其用於構建由至少一種降維方法組成的降維方法集合,利用降維方法分別對樣本數據矩陣進行降維處理,得到相應一維數列;再分別對相應一維數列進行離差標準化,得到相應離差標準化一維數列;離差標準化一維數列中每個數據的取值均介於0-1之間,且小數點後保留預設位數(比如保留3位或4位等);
樣本數據分配模塊,其用於利用圓周率π的正整數倍的小數部分構建一系列低差異數,並且使得該低差異數的小數點後保留數字位數與預設小數點後保留數字位數相等;
比較每個低差異數和離差標準化一維數列中數據的大小,將與所述低差異度數相等的數據逐個分配到預設的k個臨時容器裡;一直循環本步驟,直到把離差標準化一維數列的數值分配到k個臨時容器裡,每個臨時容器為一個子集。
由於k個臨時容器裡每個離差標準化一維數列上的數字對應樣本數據矩陣中的一個樣本(即矩陣的一行),可以從樣本數據矩陣相對應的樣本分配到相對應的k個子集中。每個子集中的樣本數相等,且子集樣本數的總和等於全集數據矩陣中所代表的樣本數。
進一步的,本發明採用降維方法來保留樣本數據矩陣的最重要信息,降維後的離差標準化一維數列作為抽樣框架(samplingframe)。
不同的降維方法保留樣本數據矩陣信息的程度會略有不同。
降維方法可以使用:主成分分析方法、核主成分分析方法、因子分析方法、截斷奇異值分解方法和多維度尺度分析方法,或者其他現有的降維方法。
本發明可以使用單個降維方法,也可以用降維方法集合來包括兩個、三個或其他數量的降維方法,依次對樣本數據矩陣進行降維。
進一步的,本發明需要用一個低差異數在離差標準化一維數列中匹配相等的數值。小數點後保留預設位數會影響匹配的精度,位數越多,精度越高,但計算時間越長。保留預設位數可以設為3位,4位,5位或6位。
(c)交叉檢驗模塊,其用於(1)根據一種監督機器學習分類算法,建立一個統計模型(比如使用邏輯回歸算法,建立一個線性回歸模型);(2)用樣本數據分配模塊中得到的k個子集數據,對該統計模型進行循環交叉檢驗;(3)保存所獲得的預測分類準確率到臨時集合中;(4)對臨時集合中的k個預測分類準確率求平均值,將該平均值存入預測準確率集合中。
需要說明的是,在所述交叉檢驗模塊中建立一個監督機器學習分類學習模型。監督機器學習分類算法可以包括任何一種現成的監督機器學習分類算法,比如邏輯回歸,神經網絡、決策樹或樸素貝葉斯。分類學習模型是一個算法的實施實例。比如一個線性回歸模型是邏輯回歸算法的實施實例。
(d)分類學習模型優化模塊,其用於判斷該分類學習模型的平均預測分類準確率是否大於或等於預設預測分類準確率閾值,若是,則該分類學習模型符合要求;否則,提示研究人員修改該分類學習模型或使用另外一個監督機器學習分類算法構建新的模型。
該系統還包括:數據分類模塊,其用於將待分類的醫療數據輸入至符合要求的分類學習模型中進行分類並輸出分類結果。
本發明的該系統利用超越數π(圓周率)的小數點後數字有無限不循環的特徵來產生一個均勻分布的低差異度數列,來取代目前隨機k-折交叉檢驗技術中使用的一個隨機數列,然後利用降維方法來保留樣本數據矩陣的最重要信息到一個一維數列作為抽樣框架(samplingframe),利用這兩個數列可以將全部樣本數據均勻地分成若干個子集,實現子集之間的低差異度,進而能夠得到當前訓練完成的分類學習模型可靠的預測分類準確率,而且在無需改進具體機器學習算法的情況下,大大提高了預設分類學習模型的訓練效率,減少了交叉檢驗計算時間,最終減少了醫療數據分類過程的時間,提高了醫療數據分類的效率。
圖6是本發明的另一種基於低差異度數列交叉檢驗的數據分類優化系統結構示意圖。
如圖6所示,本發明的另一種基於低差異度數列交叉檢驗的數據分類優化系統,包括:數據採集裝置和數據分類優化伺服器。
(1)數據採集裝置,其被配置為:從醫療信息系統的資料庫中提取就診人員歷史數據;所述就診人員歷史數據包括分類標籤和生化檢驗的特徵信息。
具體地,就診人員樣本的分類標籤包括就診人員存活和就診人員死亡,或就診人員健康和就診人員不健康。
就診人員樣本的生化檢驗的特徵信息包括血壓、心率、血糖含量和血細胞含量。除了上述生化檢驗的特徵信息之外,還包括其他現有特徵信息,此處將不再舉例說明。
下面以樣本為美國克利夫蘭市醫院的心臟病就診數據為例:
從醫療資料庫獲得297個就診人員的歷史數據,得到297個就診人員樣本,就診人員的分類標籤為心血管造影疾病嚴重狀況,從0到4,「0」表示正常,「4」表示心血管的直徑嚴重變小或嚴重堵塞,「1-3」表示心血管的直徑嚴重變小不同程度或嚴重堵塞不同程度。
就診人員樣本的生化檢驗的特徵信息包括:年齡,性別,胸部疼痛類別,靜止血壓,血清膽固醇含量,空腹血糖,心電圖結果,最大心率,運動引起的心絞痛,相對於其餘的運動誘發心電圖st段壓低值,心電圖st段的斜率,大血管被透視著色數及地貧因素。
(2)數據分類優化伺服器,其被配置為:
接收就診人員歷史醫療數據,構建樣本數據矩陣,對樣本數據矩陣進行降維處理得到的一維數列作為抽樣框架,再結合一個均勻分布的低差異度數列,將提取的醫療數據樣本數據矩陣均勻分成k個子集;
根據一個監督機器學習分類算法,構建一個分類學習模型,用k個子集中的數據進行交叉檢驗。其中用k-1個子集訓練該模型,得到該模型的各項係數。然後用餘下的一個子集做測試,得到預測分類準確率。依次循環k次,最後對這k個預測分類準確率求平均值;
判斷該分類學習模型的k折平均預測分類準確率是否大於或等於預設預測分類準確率閾值,若是,則該分類學習模型符合要求;否則,提示研究人員修改該分類學習模型或使用另外一個監督機器學習分類算法構建新的模型。
進一步的,所述數據分類優化伺服器,還被配置為:
將待分類的醫療數據輸入至符合要求的分類學習模型中進行分類並輸出分類結果。
進一步的,所述數據分類優化伺服器,還被配置為:
利用降維方法分別對樣本數據矩陣進行降維處理,得到相應一維數列;再分別對相應一維數列進行離差標準化,得到相應離差標準化一維數列;離差標準化一維數列中每個數據的取值均介於0-1之間,且小數點後保留預設位數;
利用圓周率π的正整數倍的小數部分構建一系列低差異數,並且使得該低差異數的小數點後保留數字位數與步驟2.1預設小數點後保留數字位數相等。比較小數點後保留預設位數的離差標準化一維數列和一個低差異度數列中數據的大小,將與所述低差異度數列中相等的數據逐個分配到預設的k個臨時容器裡。一直循環直到把一維數列的數值分配到k個臨時容器裡,每個臨時容器為一個子集。
由於k個臨時容器裡每個一維數列上的數字對應樣本數據矩陣中的一個樣本(即矩陣的一行),可以從樣本數據矩陣相對應的樣本分配到相對應的k個子集中。每個子集中的樣本數相等,且子集樣本數的總和等於全集數據矩陣中所代表的樣本數。
建立一個監督機器學習分類學習模型。使用上述k個子集的數據對該分類學習模型進行循環交叉驗證,得到相應預測分類準確率並存儲至一個臨時結果集合內。對臨時結果集合中的k個預測分類準確率求平均值,將該平均值存入預測準確率集合中。
最後判斷醫療數據的分類學習模型的預測分類準確率是否大於或等於預設預測分類準確率閾值,若是,則醫療數據的分類學習模型符合要求,則可以部署該模型,將新的待分類的醫療數據至該模型進行分類並輸出分類結果;否則,繼續對分類學習模型進行修改或使用另外一種監督機器學習分類算法構建新的模型。
本發明的該系統利用超越數π(圓周率)的小數點後數字有無限不循環的特徵來產生一個均勻分布的低差異度數列,來取代目前隨機k-折交叉檢驗技術中使用的一個隨機數列,然後利用降維方法來保留樣本數據矩陣的最重要信息到一個一維數列作為抽樣框架(samplingframe),利用這兩個數列可以將全部樣本數據均勻地分成若干個子集,實現子集之間的低差異度,進而能夠得到當前訓練完成的分類學習模型可靠的預測分類準確率,而且在無需改進具體機器學習算法的情況下,大大提高了預設分類學習模型的訓練效率,減少了交叉檢驗計算時間,最終減少了醫療數據分類過程的時間,提高了醫療數據分類的效率。
上述雖然結合附圖對本發明的具體實施方式進行了描述,但並非對本發明保護範圍的限制,所屬領域技術人員應該明白,在本發明的技術方案的基礎上,本領域技術人員不需要付出創造性勞動即可做出的各種修改或變形仍在本發明的保護範圍以內。