基於增益補償助聽器語音質量W‑PESQ客觀評價方法與流程
2023-12-12 06:37:12 3
本發明屬於助聽器語音質量評估技術領域,尤其涉及一種基於增益補償助聽器語音質量w-pesq客觀評價方法。
背景技術:
隨著科學技術的不斷進步,助聽器呈現智能化、數位化等趨勢。助聽器所具備的高端性能越來越豐富,價格差距也越來越大。而如何評價助聽器的質量,是助聽器廠家、消費者以及驗配醫師都很關注的問題。目前對助聽器進行客觀評估還主要局限在物理聲學參數上,國際國內都有相關的標準規範。語音質量作為助聽器的重要性能,其評估還主要還局限在主觀評價上。而主觀評測方法因其耗費大量人力、物力及時間,不適合作為計量檢測手段。必須採用科學客觀的方法對助聽器語音質量進行評價,才能避免市場定價混亂,企業不健康競爭,從而避免損害消費者利益。對於語音質量評價的客觀評價方法有許多,而檢驗客觀評價的金標準就是主觀評價,即用耳朵去聽。因而,考慮耳朵聽覺特性,用客觀方法對主觀評價過程進行一定程度模擬,可望改善評價性能。目前廣泛應用的是w-pesq(寬帶pesq)算法,其評價結果與主觀評價的相關度也最高。國際電信聯盟提出的w-pesq算法最初適用的是對電話語音的質量進行評估,並取得了較好的評價效果,進而在其他領域推廣。然而目前尚未發現有相關技術應用在助聽器語音質量領域,並且w-pesq算法的提出是基於正常人耳的聽力水平,沒有考慮聽力障礙人群的聽力衰減。
技術實現要素:
針對上述問題,本發明的目的在於利用現有的w-pesq算法提出一種新的適用於助聽器的客觀評估方法,將w-pesq算法與聽力患者的典型聽力圖相結合,進行增加補償,進而將其運用於助聽器語音質量的客觀評估方法。
技術方案如下所述:
一種基於增益補償的助聽器語音質量的w-pesq客觀評價方法,包括以下步驟:
步驟一:播放大於一定時間長度的純淨語音,錄製助聽器的輸出語音信號;利用端點檢測法將錄製的助聽器輸出語音信號與原始純淨語音信號進行端點檢測對齊處理。
步驟二:將端點檢測對齊處理後的助聽器輸出語音信號與原始純淨語音信號進行穩定助聽器信號截取處理。
步驟三:對未經過助聽器的純淨語音信號進行增益補償;設計增益補償濾波器,將原始純淨語音信號按照當前助聽器的頻域增益曲線,進行增益調整,以將增益補償濾波器的頻域響應曲線和助聽器的增益曲線進行擬合。
步驟四:採用w-pesq算法進行助聽器語音質量的客觀評價。
所述端點檢測法採用基於雙門限的端點檢測方法,用於檢測語音信號的起始點,去除語音錄製和採集系統本身的時延,將信號對齊。
所述穩定助聽器信號截取處理為:在錄製語音信號大於60s的前提下,捨棄助聽器輸出語音信號端點對齊後的15s語音信號,截取15s-60s之間的45s語音信號作為有效助聽器信號,同樣,在端點對齊後的原始純淨語音信號做相同的信號截取處理。
所述增益補償是根據聽障患者的聽力圖,調整助聽器的參數設置,完成驗配之後,測量助聽器在各個不同頻率點的增益情況,通過設計濾波器的頻域響應曲線和助聽器的增益曲線相擬合,從而將未經過助聽器的純淨語音進行增益補償。
本發明的有益效果在於:
本發明提出的一種基於增益補償的助聽器語音質量w-pesq客觀評價方法,該方法在原有的w-pesq語音質量客觀評價方法的基礎上,增加了端點檢測處理、語音截取和增益補償濾波器;利用端點檢測算法,將錄製的助聽器輸出語音與原始純淨語音信號對齊,去除音頻錄製系統及作業系統本身所引入的較大信號延遲;通過語音截取去除助聽器15s之內的不穩定信號,截取45s的有效語音信號。另外考慮到聽力障礙人群的聽力衰減,將原始語音信號按照當前助聽器的頻域增益曲線,設計增益補償濾波器,進行增益調整,以將原始信號的幅度調整到與助聽器輸出相匹配的範圍,最後採用w-pesq算法進行助聽器語音質量的客觀評價。經過主觀驗證,該方法的主客觀相關係數達到0.8,具有很好主客觀吻合度,易於評價助聽器的語言質量優劣,相比於w-pesq算法的性能略勝一籌,具有極大的實用價值。
附圖說明
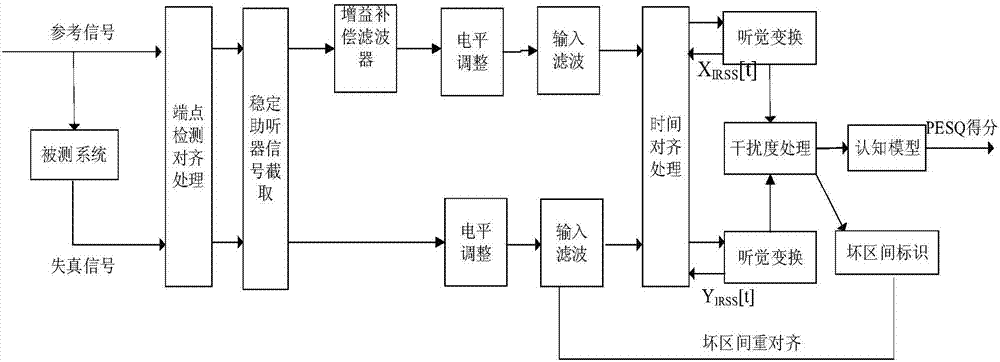
附圖1為基於增益補償的助聽器語音質量的w-pesq客觀評價方法的算法流程圖。
附圖2為原始語音信號和助聽器輸出語音信號對比圖。
附圖3為經過端點檢測之後的原始語音信號和助聽器輸出語音信號對比圖。
附圖4為經過信號截取之後的原始語音信號和助聽器輸出語音信號對比圖。
附圖5為助聽器1的增益補償效果圖。
附圖6為助聽器2的增益補償效果圖。
附圖7為助聽器3的增益補償效果圖。
具體實施方式
下面結合附圖和實施例對本發明進行詳細說明。
附圖1為基於增益補償的助聽器語音質量的w-pesq客觀評價方法的算法流程圖。如圖1所示,首先需要播放60s以上的原始純淨語音,並作為該算法的參考語音信號,將助聽器錄製的輸出語音信號作為該算法的失真語音信號,然後利用端點檢測模塊,將錄製的助聽器輸出語音信號與原始純淨語音信號進行端點檢測對齊處理,該環節採用端點檢測方法,用來檢測語音信號的起始點,將原始純淨語音信號和助聽器輸出語音信號對齊。接下來將端點檢測對齊處理後的助聽器輸出語音信號與原始純淨語音信號進行信號截取處理,依據ieee60118-15標準,捨棄端點對齊後的15s信號,從第16s開始,一直到60s結束,保留共45s的有效助聽器信號,以避免15s之內的不穩定信號;由於助聽器各個頻率的信號放大作用,使得助聽器輸出語音信號的幅度遠大於純淨語音信號所對應的幅度,導致無法直接對二者進行比較研究,因此,在進行電平調整之前,需要設計增益補償濾波器,設計濾波器的頻域響應曲線和助聽器的增益曲線相擬合,將原始純淨語音信號按照當前助聽器的頻域增益曲線,進行增益調整和補償,將原始純淨語音信號各個頻率點的幅度調整到和助聽器輸出信號相當的水平,以使其幅度與助聽器的輸出相匹配,從而使得二者具有可比性;最後按照w-pesq算法進行助聽器語音質量的客觀評價,即將助聽器輸出語音信號和經過補償後的原始純淨語音信號調整到標準聽覺電平,利用輸入濾波器將助聽器的輸出語音限制在50hz~7000hz的頻率範圍,然後將兩個信號進行時間對齊,將對齊好的信號進行聽覺轉換,轉換之後的輸入和輸出信號差值為幹擾度,通過認知模型處理,最後得到w-pesq分值,在幹擾度的處理中識別出壞區間,然後對壞區間進行重新對齊。
進一步地,在端點檢測對齊處理環節,本發明採用基於雙門限的端點檢測方法,但端點檢測的方法不限於此方法。所述基於雙門限的端點檢測方法的步驟如下所述:首先在播放語音的起始端之前的固定時間間隔位置添加固定時長的高強度白噪聲,以提高端點檢測的準確性。採用短時能量和短時過零率相結合的方法,利用短時能量和短時過零率兩個門限來確定語音信號的起點和終點,目的是從採集到的語音信號中分離出真正的語音信號作為系統處理的對象。在開始端點檢測之前,首先為短時能量和過零率分別確定兩個門限。一個是比較低的門限,其數值比較小,對信號的變化比較敏感,很容易會被超過。另一個是比較高的門限,數值比較大,信號必須達到一定的強度,該門限才可能被超過。低門限被超過未必就是語音的開始,有可能是時間很短的噪聲引起的。高門限被超過可以基本確信是由於語音信號引起的。整個語音信號的端點檢測可以分成四段:靜音、過渡段、語音段、結束。在靜音段,如果能量或過零率超越了低門限,就應該開始標記起始點,進入過渡段。在過渡段中,由於參數的數值比較小,不能確信是否處於真正的語音段,因此只要兩個參數的數值回落到低門限以下,就將當前狀態恢復到靜音狀態。而如果在過渡段中兩個參數中的任一個超過了高門限,就可以確信進入語音段了。由於一些突發性的噪聲也可以引起短時能量或過零率的數值很高,但是往往不能維持足夠長的時間,如門窗的開關、物理的碰撞等引起的噪聲,這些都可以通過設定最短時間門限來判別。當前狀態處於語音段時,如果兩個參數的數值降低到低門限一下,而且總的計時長度小於最短時間門限,則認為這是一段噪音,繼續掃描以後的語音數據。否則,標記好結束端點,並返回。
進一步地,在設計增益補償濾波器環節,設計濾波器的頻域響應曲線和助聽器的增益曲線相擬合,具體步驟如下所述:首先將患者聽力曲線下載到待測助聽器中,並將助聽器交由專業驗配機構進行驗配和功能調試,使其聲音效果對於患者達到最佳,然後依據標準iec60118-8標準測量1/3倍頻程下的插入增益,採用頻率採樣法設計fir濾波器,使得濾波器的輸出和所測量得到的待測助聽器的插入增益儘量擬合。採用該濾波器將經過端點對齊處理與穩定信號截取之後純淨語音信號進行濾波,將純淨語音信號各個頻率點的幅度調整到和助聽器輸出信號相當的水平,以使得二者具有可比性。
為了加強w-pesq算法在語音質量客觀評價中運用的有效性,通常利用算法的客觀評價結果與人的主觀評價結果的相關度進行充分證明。其中相關度表示為:
式中,ai為語音信號在第i種聽力損失曲線下的主觀mos評分,bi為客觀評分,和分別為二者的算術平均值。
對於主觀評估採用基於mos評分法。該方法的描述如下所述:請14位具有聽力障礙耳的主觀試聽者對語音信號質量進行主觀評估。表1給出了mos法的評分標準,對用戶接聽和感知的語音質量狀況進行調研和量化,主要有五個等級用來衡量語音質量;評測人分別對標準語音以及經過語音測試系統處理的失真語音進行主觀評分,統計出所有評測者的平均分得到所測語音質量的mos分。為了保證測試評分的準確性,對實驗中的環境、語音材料以及測評人的數量等都要明確的嚴格規定,mos得分由高到低,主要意味著語音質量的由好到差。
表1mos評分五級標準
實施例一
下面以某家助聽器產品為例進行詳細說明。選擇好、壞、中三款不同等級的助聽器作為測試樣品,分別標記為助聽器1、助聽器2、助聽器3,首先利用casia中文普通話語音庫中純淨語音,合成60s以上的純淨語音,然後在特定測試平臺上,分別採集經過測試的三款助聽器後的輸出語音信號。採用雙門限的端點檢測方法,檢測錄製的助聽器輸出語音的起始端點,將之與原始純淨語音對齊。以助聽器1的信號處理過程為例,錄製得到的助聽器輸出語音信號與原始語音信號的對比如圖2所示,由於原始純淨語音經過助聽器後信號是有延遲的,並且語音錄製過程中的操作也會引入一定的延遲,為了保證端點檢測的準確性,在原始語音信號的初始部分人工添加了時長固定且與正式語音之間的時長固定的較大幅度的白噪聲。然後對助聽器輸出語音信號採用雙門限端點檢測法將錄製的助聽器輸出語音與原始純淨語音信號對齊。在初始部分添加的大幅度白噪聲的能量和過零率都非常高,在檢測出語音信號起始端點之後,將助聽器輸出語音信號前面一段截取,從而將原始純淨語音信號和助聽器輸出語音信號對齊,效果如圖3所示,然後分別從對齊後的原始純淨語音和助聽器輸出語音的15s開始位置,截取長度為45s的語音信號,得到的原始語音信號和助聽器輸出語音信號的對比圖如圖4所示,顯而易見,二者的語音信號是對齊的,並且保證了助聽器的輸出是在助聽器穩定狀態下錄製的。接下來設計增益補償濾波器對原始純淨語音信號進行增益補償,將信號幅度調整到可以和助聽器輸出語音信號幅度相匹配的大小。以iec60118-15中提到的典型聽力圖n2為例,分別將聽力圖下載到好,中,壞三款不同等級的待測助聽器中,依據iec60118-8標準測量其插入增益,圖5-7分別是助聽器1-3根據下載的聽力圖n2插入增益後的增益補償效果圖,將調整後的45s純淨語音和未調整的45s助聽器輸出語音分別輸入到w-pesq算法中,進行客觀評估分值的計算。再採用正常聽力人群,針對本發明提出的方法進行驗證,主客觀評價分數如表2所示。
表2三款不同等級助聽器的主客觀評價分數
經統計學分析驗證,基於本發明的方法與主觀評價具有良好的相關度,根據本發明中的方法,能夠將好、中、壞三款助聽器正確地區分開來,並且與主觀評價結果相一致。
此實施例僅為本發明較佳的具體實施方式,但本發明的保護範圍並不局限於此,任何熟悉本技術領域的技術人員在本發明揭露的技術範圍內,可輕易想到的變化或替換,都應涵蓋在本發明的保護範圍之內。因此,本發明的保護範圍應該以權利要求的保護範圍為準。