基於規則輔助的高爐冶煉過程數據驅動建模方法與流程
2023-06-12 02:13:21 5
本發明屬於數據挖掘與機器學習技術領域,涉及數據挖掘與數據處理方法,具體地說,涉及一種基於規則輔助的高爐冶煉過程數據驅動建模方法。
背景技術:
數據驅動建模方法是當前的一個研究熱點,學者們提出了大量數據驅動模型。數據驅動模型的應用範圍非常廣泛,涉及回歸分析、聚類分析、分類問題、密度估計等諸多領域。其中,非線性模型憑藉其強大的非線性逼近能力通常表現出較高的預測精度。然而,當前的非線性數據驅動模型仍存在以下兩個亟待解決的主要問題:(1)無法有效整合專家知識、模糊規則等異質信息,導致無法進一步提升模型的精度;(2)缺乏可解釋性,導致非線性數據驅動模型在許多對模型透明度較高的應用領域內使用受限。
近年來學者們針對非線性數據驅動模型存在的上述問題,開展了一系列試探性研究並取得初步研究成果。jan與jacek提出了一種從神經網絡中提取規則的方法,該方法抽取的規則通過模擬網絡背後的邏輯關係改進神經網絡模型的推廣能力。將先驗知識融入非線性數據驅動模型則是另外一條有效途徑。maclin等人通過向svms優化問題加入不等式約束的方式合併先驗知識到svms模型。更進一步,為了將非線性知識融入到非線性數據驅動模型中,mangasarian等人藉助理論分析將非線性先驗知識轉化為線性不等式約束。然而,上述方法都是針對具體算法設計的,無法實現規則知識與一般數據驅動模型的融合,導致這些數據驅動模型的精度低,可解釋性差。
技術實現要素:
本發明的目的在於針對ls-svms等現有數據驅動模型無法有效整合專家知識、模糊規則等多源異質數據導致精度無法進一步提高、數據驅動模型可解釋性差等上述不足,提供了一種基於規則輔助的高爐冶煉過程數據驅動建模方法,該方法通過實現專家知識、模糊規則等信息與數據驅動模型的高效集成,進而提高數據驅動模型的精度和可解釋性。
根據本發明一實施例,提供了一種基於規則輔助的高爐冶煉過程數據驅動建模方法,含有以下步驟:
(一)採集2000m3高爐冶煉過程實際數據,高爐實際採集數據具有時序特徵,故在數據處理過程中保持數據先後順序不變;採用如下數據處理方法i=1,…,n;j=1,…,d對採樣數據進行預處理,其中表示原始採集數據,表示第j個特徵的平均值,表示第j個採集變量的標準差,將採集數據轉換為無量綱數據,消除數據的數量級差異,將上述預處理後的數據轉換為規則數據,其具體步驟為:(1)收集並整理專家知識,利用決策樹算法生成if…then…規則:
(2)定義第k個樣本點xk的第ip個特徵關於基本規則區間的隸屬度為:
其中,
(3)定義合取算子∧及析取算子計算and-型規則及or-型規則對樣本xk的規則支持度為:
(4)利用規則支持度產生規則數據,規則數據表示為:
rk=(r1(xk),…,rm(xk))∈[01]m(6);
(二)採用多核學習算法融合多源規則數據,其具體步驟為:
(1)選擇高斯rbf函數作為核函數,利用步驟(一)產生的p組規則數據i=1,…,p,分別產生核矩陣k1,…,kp;
(2)利用面向ls-svms的多核學習算法對p組規則數據進行融合:
s.t.||μ||≤1,
μi≥0,i=1,…,p+1,
其中fi(α)=αtkiα,i=1,…,p+1,
求解上述融合的優化問題,得到ls-svms模型正則化參數ν=μp+1及最優核矩陣係數μi(i=1,…,p),進而獲得進行數據融合的規則核矩陣
(三)建立數據驅動預測模型,其具體步驟為:
利用ls-svms建立數據驅動模型為:
其中,w為分類超平面的法向量,b為分類超平面的截距項,ei為誤差項,v≥0為模型正則化參數,表示特徵映射,通過指定核函數的方式隱式確定;
通過求解上述數據驅動模型的kkt系統
得到數據驅動預測模型為:
(四)建立規則預測模型,其具體步驟為:將步驟(二)中的得到ls-svms模型正則化參數ν以及規則矩陣kr代入ls-svms模型的kkt系統
求解公式(11)表示的kkt系統得到規則預測模型:
(五)採用sigmoid函數擬合將步驟(四)中規則預測模型的輸出轉換為後驗概率,其具體步驟為:通過擬牛頓算法求解優化問題:
其中n+/n_分別為正/負類樣本點個數;
得到sigmoid函數的最優擬合參數a和b,進而將規則預測模型的輸出決策值轉化為後驗概率進行輸出,後驗概率表示為:
(六)通過後驗概率集成數據驅動預測模型和規則預測模型,建立規則輔助的數據驅動模型,其具體步驟為:通過步驟(五)分別擬合出數據驅動預測模型和規則預測模型的sigmoid函數的最優擬合參數,將數據驅動預測模型和規則預測模型的決策值轉換為後驗概率pd和pr,並對數據驅動預測模型和規則預測模型進行集成,獲得規則輔助的數據驅動模型為:
優選的,所述高爐冶煉過程實際數據包括控制參數和狀態參數,所述控制參數包括噴煤量、風量、風溫以及富氧量,所述狀態參數包括高爐鐵水矽含量、凸臺溫差、冶煉強度、透氣性指數、料速、頂風壓力以及爐渣鹼度;以高爐鐵水矽含量作為高爐爐溫的表徵,並選取其為規則輔助的數據驅動模型的輸出變量,通過對高爐鐵水矽含量進行一階差分處理和符號函數的複合運算得到二元趨勢變量yi=sign([si]i-[si]i-1),其中,y∈[1,-1],1對應爐溫升高的趨勢,-1對應爐溫下降的趨勢,[si]i表示第i爐的高爐鐵水矽含量實際採集數據;選擇高爐冶煉過程實際數據除高爐鐵水矽含量外的其他參數為規則輔助的數據驅動模型輸入變量x=(x1,…,xd),並對輸入變量進行預處理。
優選的,步驟採用sigmoid函數擬合將步驟(三)中數據驅動預測模型的輸出轉換為後驗概率,其具體步驟為:通過擬牛頓算法求解優化問題:
其中n+/n_分別為正/負類樣本點個數;
得到sigmoid函數的最優擬合參數a和b,進而將數據驅動預測模型的輸出決策值轉化為後驗概率進行輸出,後驗概率表示為:
本發明提出的基於規則輔助的高爐冶煉過程數據驅動建模方法,選取高爐鐵水矽含量([si],又稱為高爐化學溫度)作為模型輸出變量,通過對採樣[si]數據的一階差分和符號函數複合運算得到二值型輸出變量,進而可建立高爐爐溫趨勢預報模型。通過收集、整理專家知識得到if…then…規則,根據if…then…規則將採集的原始採集數據轉化為規則數據,能有效抑制工業噪聲、異常數據的影響,利用多核學習算法整合多個專家知識得到基於規則的規則預測模型,並建立數據驅動預測模型,通過sigmoid函數將規則預測模型和數據驅動預測模型的輸出決策值轉換為後驗概率,並對數據驅動預測模型和規則預測模型進行集成,獲得規則輔助的數據驅動模型。通過根據本發明實施例的基於規則輔助的高爐冶煉過程數據驅動建模方法建立的數據驅動模型,由於將專家知識、模糊規則等異質信息與數據驅動模型進行集成,與現有技術相比,本發明建模方法建立的數據驅動模型的預測精度和可解釋性得到顯著提高,從而提高高爐冶煉過程採集數據的利用率。
附圖說明
附圖1為本發明具體實施例規則輔助的數據驅動建模的流程框圖。
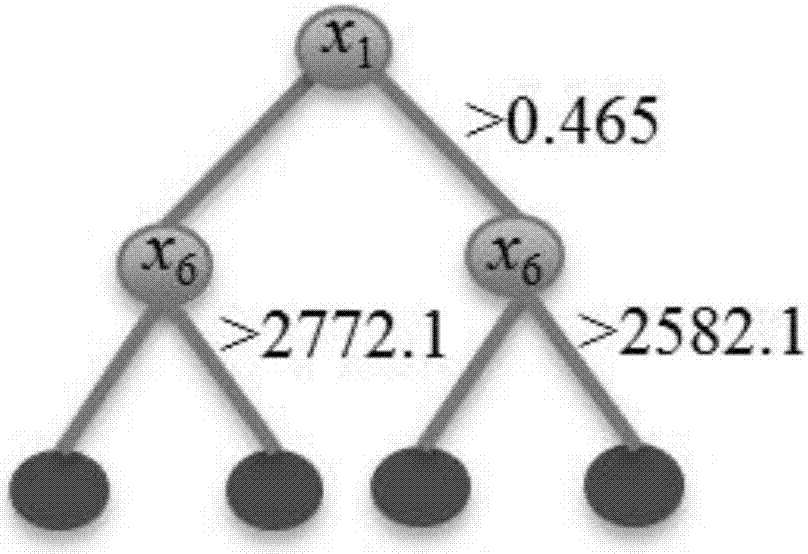
附圖2a-d分別為本發明實施例cart算法產生的t1,t2,t3,t4四種決策規則圖。
附圖3為本發明實施例三種模型在國內某高爐冶煉過程數據上的預測效果圖。
具體實施方式
以下結合附圖對本發明實施例作進一步說明。
以國內某2000m3高爐冶煉過程實際採集數據為例。參見圖1,一種基於規則輔助的高爐冶煉過程數據驅動建模方法,含有以下步驟:
(一)採集2000m3高爐冶煉過程實際數據,高爐實際採集數據具有時序特徵,故在數據處理過程中保持數據先後順序不變;所述高爐冶煉過程實際數據包括控制參數和狀態參數,所述控制參數包括噴煤量、風量、風溫以及富氧量,所述狀態參數包括高爐鐵水矽含量、凸臺溫差、冶煉強度、透氣性指數、料速、頂風壓力以及爐渣鹼度;以高爐鐵水矽含量作為高爐爐溫的表徵,並選取其為規則輔助的數據驅動模型的輸出變量,通過對高爐鐵水矽含量進行一階差分處理和符號函數的複合運算得到二元趨勢變量yi=sign([si]i-[si]i-1),其中,y∈[1,-1],1對應爐溫升高的趨勢,-1對應爐溫下降的趨勢,[si]i表示第i爐的高爐鐵水矽含量實際採集數據;選擇高爐冶煉過程實際數據除高爐鐵水矽含量外的其他參數為規則輔助的數據驅動模型輸入變量x=(x1,…,xd),並對輸入變量進行預處理;採用如下數據處理方法i=1,…,n;j=1,…,d對採樣數據進行預處理,其中表示原始採集數據,表示第j個特徵的平均值,表示第j個採集變量的標準差,將採集數據轉換為無量綱數據,消除數據的數量級差異,降低各輸入變量在數量級上的差異對趨勢預報器的性能所產生的影響。將上述預處理後的數據轉換為規則數據,其具體步驟為:
(1)選擇待處理數據集合,從中選取200個樣本點構造集合dr,用於產生決策樹規則;其餘樣本點構造集合dv,用於驗證模型。使用bootstrap方式對dr抽樣,然後應用決策樹算法在抽樣上產生決策樹。本實施例中,決策樹算法採用cart算法。上述步驟執行多次,直到產生4個不同的決策樹t1,t2,t3,t4,參見圖2a-d。
(2)將驗證集合dr分成學習集和測試集,從dv中隨機選取p%的樣本構造測試集,其餘樣本構造學習集,其中p∈{10,15,…,85,90},設學習集為{(x1,y1),…,(xk,yk),…,(xl,yl)},定義第k個樣本點xk的第ip個特徵關於基本規則區間的隸屬度為:
其中,
(3)定義合取算子∧及析取算子計算and-型規則及or-型規則對樣本xk的規則支持度為:
(4)利用規則支持度產生規則數據,規則數據表示為:
rk=(r1(xk),…,rm(xk))∈[01]m(6);
由此產生對應於決策樹規則t1,t2,t3,t4的規則數據r1,r2,r3,r4。
(二)採用多核學習算法融合多源規則數據,其具體步驟為:
(1)選擇高斯rbf函數作為核函數,核寬參數σ取默認值,即輸入數據的維數,利用規則數據r1,r2,r3,r4產生核矩陣k1,k2,k3,k4;
(2)利用面向ls-svms的多核學習算法對4組規則數據進行融合:
s.t.||μ||≤1,
μi≥0,i=1,…,p+1,
其中fi(α)=αtkiα,i=1,…,p+1,
求解上述融合的優化問題,得到ls-svms模型正則化參數ν=μp+1及最優核矩陣係數μi(i=1,…,p),進而獲得進行數據融合的規則核矩陣
(三)建立數據驅動預測模型,其具體步驟為:
利用ls-svms建立數據驅動模型為:
其中,w為分類超平面的法向量,b為分類超平面的截距項,ei為誤差項,v≥0為模型正則化參數,此處取值為1,表示特徵映射,通過指定核函數的方式隱式確定;
通過求解上述數據驅動模型的kkt系統
得到數據驅動預測模型為:
(四)建立規則預測模型,其具體步驟為:將步驟(二)中的得到ls-svms模型正則化參數ν以及規則矩陣kr代入ls-svms模型的kkt系統
求解公式(11)表示的kkt系統得到規則預測器:
(五)採用sigmoid函數擬合將步驟(四)中規則預測模型的輸出轉換為後驗概率,其具體步驟為:通過擬牛頓算法求解優化問題:
其中n+/n_分別為正/負類樣本點個數;
得到sigmoid函數的最優擬合參數a和b,進而將規則預測模型的輸出決策值轉化為後驗概率進行輸出,後驗概率表示為:
同樣地,採用sigmoid函數擬合將步驟(三)中數據驅動預測模型的輸出轉換為後驗概率,其具體步驟為:通過擬牛頓算法求解優化問題:
其中n+/n_分別為正/負類樣本點個數;
得到sigmoid函數的最優擬合參數a和b,進而將數據驅動預測模型的輸出決策值轉化為後驗概率進行輸出,後驗概率表示為:
(六)通過後驗概率集成數據驅動預測模型和規則預測模型,建立規則輔助的數據驅動模型,其具體步驟為:通過步驟(五)分別擬合出數據驅動預測模型和規則預測模型的sigmoid函數的最優擬合參數,將數據驅動預測模型和規則預測模型的決策值轉換為後驗概率pd和pr,並對數據驅動預測模型和規則預測模型進行集成,獲得規則輔助的數據驅動模型為:
分別應用本發明具體實施例上述基於規則輔助的高爐冶煉過程數據驅動建模方法(簡稱:ensemble)、數據驅動建模方法(簡稱:data)以及規則數據建模方法(簡稱:rule),校驗上述三種方法建模的有效性。數值實驗結果參見圖3,由圖3可以看出,本發明實施例所提基於規則輔助的高爐冶煉過程數據驅動建模方法(圖3中的ensemble)在國內某高爐冶煉過程採集數據bf(a)上的測試精度優於其它兩種建模方法(圖3中的data和rule)。
上述實施例用來解釋本發明,而不是對本發明進行限制,在本發明的精神和權利要求的保護範圍內,對本發明做出的任何修改和改變,都落入本發明的保護範圍。