識別網絡爬蟲的方法及系統與流程
2023-09-10 16:35:30 5
本發明涉及網絡安全技術領域,特別涉及一種識別網絡爬蟲的方法及系統。
背景技術:
網際網路的廣泛普及,使得在線web應用平臺已成為網際網路信息交互的中心,各種商業交易均可以在web應用平臺上完成,隨之而來的是在線web應用平臺面臨的越來越多的安全威脅。其中,黑客們使用各種各樣掃描工具掃描web程序,進行一些非法的網絡行為,並依此來獲取相關利益。不管是對web應用平臺進行漏洞掃描,還是針對商品頁面進行刷單搶單等薅羊毛行為,首先進行的都是頁面的爬蟲活動,進而從返回的頁面裡提取相關信息。複雜的網絡請求中,存在各式各樣頁面信息爬取,不正規的、惡意的程序過量爬取會造成伺服器負載過大。
目前,識別網絡爬蟲主要有以下三種方法:(1)統計方法,通過對訪問記錄進行統計,根據事件類型、訪問頻率等進行分析;(2)用戶代理(useragent,簡稱為ua)分析方法,分析ua是否帶有明顯的爬蟲程序的信息;(3)陷阱方法,通過設置一種瀏覽器渲染不可見的隱藏連結,等待爬蟲觸發。
上述方法中均存在一些不足,具體如下:
(1)統計方法跟產品自身相關性較大,需根據產品特徵來定義。判斷的準則具有不確定性,無法根據一個定性的條件來判斷。在某些頁面存在線上活動時,就會導致局部頁面請求的頻率出現異常,從而出現爬蟲特徵。而有些公司、學校統一網絡出口的地址其頁面訪問信息的統計結果也符合爬蟲特徵。
(2)ua分析方法,ua信息容易被偽造,造成遺漏。ua信息是由超文本傳輸協議(hypertexttransferprotocol,簡稱為http)請求發起方主動攜帶的標記當前請求環境的一個信息欄位,這個信息可由發起方進行修改。如常用的各種瀏覽器均會在ua帶上自己瀏覽器信息的特殊字符,包括谷歌、百度等搜尋引擎爬蟲的ua均帶有特殊標記的字符,而一些惡意爬蟲程序利用這個特徵偽造ua信息欄位,使之和正規的搜尋引擎爬蟲的ua或者正常瀏覽器的ua欄位信息一樣,這樣就導致無法對這一類惡意爬蟲程序進行有效的識別。
(3)陷阱方法,對於一些指定頁面爬取的爬蟲請求無法識別,會存在一定的誤報。
技術實現要素:
為了解決現有技術中爬蟲程序偽造信息欄位造成爬蟲識別結果判斷不準確,以及現有爬蟲識別方法存在一定的延時判斷,無法及時對請求進行識別判斷的問題,本發明實施例提供了一種識別網絡爬蟲的方法及系統。所述技術方案如下:
根據本發明實施例的一個方面,提供了一種識別網絡爬蟲的方法,包括:
接收客戶端發起的頁面請求;
判斷所述頁面請求是否是爬蟲識別程序的請求;
如果所述頁面請求是爬蟲識別程序的請求,根據所述爬蟲識別程序的請求數據判斷所述客戶端是否為正常客戶端,並修改資料庫中的爬蟲判斷記錄;
如果所述頁面請求不是爬蟲識別程序的請求,在響應內容類型為超文本標記語言(hypertextmarkuplanguage,簡稱為html)或javascript(簡稱為js,是一種腳本語言)的頁面添加爬蟲識別程序代碼,並發送給所述客戶端。
進一步的,根據所述爬蟲識別程序的請求數據判斷所述客戶端是否為正常客戶端,並修改資料庫中的爬蟲判斷記錄,包括:
判斷所述頁面請求是否是獲取焦點請求;
如果是獲取焦點請求,則將所述客戶端的爬蟲判斷記錄中的緩衝時間修改為當前時間;
如果不是獲取焦點請求,則判斷所述頁面請求是否是失去焦點請求、關閉頁面請求和用戶行為請求中的任一個;
如果是失去焦點請求、關閉頁面請求和用戶行為請求中的任一個,則確定所述客戶端為正常客戶端,並修改所述客戶端的爬蟲判斷記錄中的對應欄位;
如果不是失去焦點請求、關閉頁面請求和用戶行為請求中的任一個,則判斷所述頁面請求是否是需要再下發爬蟲識別程序代碼的請求;
如果是需要再下發爬蟲識別程序代碼的請求,則修改所述客戶端的爬蟲判斷記錄中的對應欄位;
如果不是需要再下發爬蟲識別程序代碼的請求,則不做任何處理。
進一步的,所述爬蟲判斷記錄包括以下欄位:客戶端標識、緩衝時間、更新時間、下發狀態和爬蟲標識位;其中,所述緩衝時間表示所述爬蟲識別程序的請求的接收時間範圍的計算起點;所述更新時間表示修改所述爬蟲標識位的時間;所述下發狀態表示所述爬蟲識別程序代碼是否下發給客戶端,0表示默認值,1表示已下發,2表示再下發;爬蟲標識位包括:0表示默認值,1表示正常客戶端,2表示爬蟲可疑客戶端。
進一步的,確定所述客戶端為正常客戶端,並修改所述客戶端的爬蟲判斷記錄中的對應欄位,包括:將緩衝時間修改為0,更新時間修改為當前時間,下發狀態修改為0,爬蟲標識位修改為1;
如果是需要再下發爬蟲識別程序代碼的請求,則修改所述客戶端的爬蟲判斷記錄中的對應欄位,包括:將緩衝時間修改為0,更新時間修改為0,下發狀態修改為2。
進一步的,在響應內容類型為html或javascript的頁面添加爬蟲識別程序代碼,並發送給所述客戶端,包括:
判斷所述頁面請求是否是html頁面且支持javascript;
如果不是html頁面和/或不支持javascript,則確定不需要下發所述爬蟲識別程序代碼,直接響應所述頁面請求;
如果是html頁面且支持javascript,則確定需要下發所述爬蟲識別程序代碼。
進一步的,在確定需要下發所述爬蟲識別程序代碼之後,所述方法還包括:
根據客戶端標識判斷所述資料庫中是否存儲有所述客戶端的爬蟲判斷記錄;
如果否,則確定所述客戶端未做過爬蟲識別處理,在響應中添加所述爬蟲識別程序代碼,發給所述客戶端,並在所述資料庫中添加所述客戶端的爬蟲判斷記錄;
如果是,則確定所述客戶端做過爬蟲識別處理,根據所述客戶端的爬蟲判斷記錄中的下發狀態判斷是否需要再下發所述爬蟲識別程序代碼;
如果下發狀態為2,則確定需要再下發所述爬蟲識別程序代碼,在響應中添加所述爬蟲識別程序代碼,發給所述客戶端,並將所述客戶端的爬蟲判斷記錄中的緩衝時間修改為當前時間,下發狀態修改為1;
如果下發狀態不為2,則確定不需要再下發所述爬蟲識別程序代碼,直接響應所述頁面請求。
進一步的,所述方法還包括:
判斷所述爬蟲判斷記錄中的緩衝時間與當前時間的差值是否超出預設時間範圍;
如果超出所述預設時間範圍且未收到所述爬蟲識別程序的請求,則確定所述客戶端為爬蟲可疑客戶端,並將緩衝時間修改為0,更新時間修改為當前時間,下發狀態修改為0,爬蟲標識位修改為2;
如果未超出所述預設時間範圍,則根據爬蟲標識位與更新時間確定所述客戶端的當前情況以及所要執行的操作。
進一步的,根據爬蟲標識位與更新時間確定所述客戶端的當前情況以及所要執行的操作,包括:
如果爬蟲標識位為0,則確定處於判斷過程,不做任何處理;
如果爬蟲標識位為1,則說明之前已判斷該客戶端為正常客戶端,此時需判斷更新時間與當前時間的差值是否超出預設的識別間隔時間;如果是,則刪除所述客戶端的爬蟲判斷記錄,等待下次接收頁面請求進行重新識別;如果否,則不做任何處理;
如果爬蟲標識位為2,則說明之前已判斷該客戶端為爬蟲可疑客戶端,此時需判斷更新時間與當前時間的差值是否超出預設的爬蟲處理時間;如果是,則確定需再下發所述爬蟲識別程序代碼,將下發狀態修改為2,緩衝時間修改為當前時間,更新時間修改為空,爬蟲標識位修改為0;如果否,則不做任何處理。
根據本發明實施例的另一個方面,提供了一種識別網絡爬蟲的系統,包括:
接收單元,用於接收客戶端發起的頁面請求;
第一判斷單元,用於判斷所述頁面請求是否是爬蟲識別程序的請求;
第一處理單元,用於在所述頁面請求是爬蟲識別程序的請求的情況下,根據所述爬蟲識別程序的請求數據判斷所述客戶端是否為正常客戶端,並修改資料庫中的爬蟲判斷記錄;
第二處理單元,用於在所述頁面請求不是爬蟲識別程序的請求的情況下,在響應內容類型為html或javascript的頁面添加爬蟲識別程序代碼,並發送給所述客戶端。
進一步的,所述第一處理單元包括:
第一判斷模塊,用於判斷所述頁面請求是否是獲取焦點請求;
第一處理模塊,用於在所述頁面請求是獲取焦點請求的情況下,將所述客戶端的爬蟲判斷記錄中的緩衝時間修改為當前時間;
第二判斷模塊,用於在所述頁面請求不是獲取焦點請求的情況下,判斷所述頁面請求是否是失去焦點請求、關閉頁面請求和用戶行為請求中的任一個;
第二處理模塊,用於在所述頁面請求是失去焦點請求、關閉頁面請求和用戶行為請求中的任一個的情況下,確定所述客戶端為正常客戶端,並修改所述客戶端的爬蟲判斷記錄中的對應欄位;
第三判斷模塊,用於在所述頁面請求不是失去焦點請求、關閉頁面請求和用戶行為請求中的任一個的情況下,判斷所述頁面請求是否是需要再下發爬蟲識別程序代碼的請求;
第三處理模塊,用於在所述頁面請求是需要再下發爬蟲識別程序代碼的請求的情況下,修改所述客戶端的爬蟲判斷記錄中的對應欄位;以及在所述頁面請求不是需要再下發爬蟲識別程序代碼的請求的情況下,不做任何處理。
進一步的,所述爬蟲判斷記錄包括以下欄位:客戶端標識、緩衝時間、更新時間、下發狀態和爬蟲標識位;其中,所述緩衝時間表示所述爬蟲識別程序的請求的接收時間範圍的計算起點;所述更新時間表示修改所述爬蟲標識位的時間;所述下發狀態表示所述爬蟲識別程序代碼是否下發給客戶端,0表示默認值,1表示已下發,2表示再下發;爬蟲標識位包括:0表示默認值,1表示正常客戶端,2表示爬蟲可疑客戶端。
進一步的,所述第二處理模塊具體用於將緩衝時間修改為0,更新時間修改為當前時間,下發狀態修改為0,爬蟲標識位修改為1;
所述第三處理模塊具體用於將緩衝時間修改為0,更新時間修改為0,下發狀態修改為2。
進一步的,所述第二處理單元包括:
第四判斷模塊,用於判斷所述頁面請求是否是html頁面且支持javascript;
第四處理模塊,用於在所述頁面請求不是html頁面和/或不支持javascript的情況下,確定不需要下發所述爬蟲識別程序代碼,直接響應所述頁面請求;
確定模塊,用於在所述頁面請求是html頁面且支持javascript的情況下,確定需要下發所述爬蟲識別程序代碼。
進一步的,所述第二處理單元還包括:
第五判斷模塊,用於在所述確定模塊確定需要下發所述爬蟲識別程序代碼之後,根據客戶端標識判斷所述資料庫中是否存儲有所述客戶端的爬蟲判斷記錄;
第五處理模塊,用於在判斷結果為否的情況下,確定所述客戶端未做過爬蟲識別處理,在響應中添加所述爬蟲識別程序代碼,發給所述客戶端,並在所述資料庫中添加所述客戶端的爬蟲判斷記錄;
第六判斷模塊,用於在判斷結果為是的情況下,確定所述客戶端做過爬蟲識別處理,根據所述客戶端的爬蟲判斷記錄中的下發狀態判斷是否需要再下發所述爬蟲識別程序代碼;
第六處理模塊,用於在下發狀態為2的情況下,確定需要再下發所述爬蟲識別程序代碼,在響應中添加所述爬蟲識別程序代碼,發給所述客戶端,並將所述客戶端的爬蟲判斷記錄中的緩衝時間修改為當前時間,下發狀態修改為1;
第七處理模塊,用於在下發狀態不為2的情況下,確定不需要再下發所述爬蟲識別程序代碼,直接響應所述頁面請求。
進一步的,所述系統還包括:
第二判斷單元,用於判斷所述爬蟲判斷記錄中的緩衝時間與當前時間的差值是否超出預設時間範圍;
第三處理單元,用於在超出預設時間範圍且未收到所述爬蟲識別程序的請求的情況下,確定所述客戶端為爬蟲可疑客戶端,並將緩衝時間修改為0,更新時間修改為當前時間,下發狀態修改為0,爬蟲標識位修改為2;
第四處理單元,用於在未超出所述預設時間範圍的情況下,根據爬蟲標識位與更新時間確定所述客戶端的當前情況以及所要執行的操作。
進一步的,所述第四處理單元具體用於:
如果爬蟲標識位為0,則確定處於判斷過程,不做任何處理;
如果爬蟲標識位為1,則說明之前已判斷該客戶端為正常客戶端,此時需判斷更新時間與當前時間的差值是否超出預設的識別間隔時間;如果是,則刪除所述客戶端的爬蟲判斷記錄,等待下次接收頁面請求進行重新識別;如果否,則不做任何處理;
如果爬蟲標識位為2,則說明之前已判斷該客戶端為爬蟲可疑客戶端,此時需判斷更新時間與當前時間的差值是否超出預設的爬蟲處理時間;如果是,則確定需再下發所述爬蟲識別程序代碼,將下發狀態修改為2,緩衝時間修改為當前時間,更新時間修改為空,爬蟲標識位修改為0;如果否,則不做任何處理。
本發明實施例提供的技術方案帶來的有益效果是:將爬蟲識別程序代碼下發給客戶端,通過判斷接收的頁面請求是否是爬蟲識別程序的請求,然後進行相應的處理,根據請求數據和客戶端的爬蟲判斷記錄識別客戶端是否有爬蟲活動,能夠根據頁面請求及時進行爬蟲識別判斷。同時,對源伺服器中的代碼結構和業務邏輯無需做任何改變,識別過程與產品特徵無關,也與易於偽造的用戶代理信息欄位無關,提高了識別結果的準確性。
附圖說明
為了更清楚地說明本發明實施例中的技術方案,下面將對實施例描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對於本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
圖1是本發明實施例提供的識別網絡爬蟲的方法的流程圖;
圖2是本發明實施例提供的識別網絡爬蟲的方法中步驟s103的具體流程圖;
圖3是本發明實施例提供的識別網絡爬蟲的方法中步驟s104的具體的流程圖;
圖4是本發明具體實施例提供的識別網絡爬蟲方法的流程圖;
圖5是本發明具體實施例提供的時間處理流程圖;
圖6是本發明實施例提供的識別網絡爬蟲的系統的結構框圖。
具體實施方式
為使本發明的目的、技術方案和優點更加清楚,下面將結合附圖對本發明實施方式作進一步地詳細描述。
本發明實施例提供了一種識別網絡爬蟲的方法,可以由伺服器執行。圖1是本發明實施例提供的識別網絡爬蟲的方法的流程圖,如圖1所示,該方法包括如下的步驟s101至步驟s104。
步驟s101,接收客戶端發起的頁面請求。
步驟s102,判斷頁面請求是否是爬蟲識別程序的請求。具體的,如果爬蟲識別程序代碼下發到客戶端,爬蟲識別程序可以利用一些請求進行爬蟲識別,例如,該請求可以是敲擊鍵盤、點擊滑鼠等用戶行為請求,或者是關閉頁面請求等。
步驟s103,如果頁面請求是爬蟲識別程序的請求,根據爬蟲識別程序的請求數據判斷客戶端是否為正常客戶端,並修改資料庫中的爬蟲判斷記錄。其中,爬蟲判斷記錄是存儲在資料庫中的,用於輔助進行爬蟲識別的信息。
步驟s104,如果頁面請求不是爬蟲識別程序的請求,在響應內容類型為html或javascript的頁面添加爬蟲識別程序代碼,並發送給客戶端。即通過響應向客戶端下發爬蟲識別程序代碼。
上述識別網絡爬蟲的方法中,將爬蟲識別程序代碼下發給客戶端,通過判斷接收的頁面請求是否是爬蟲識別程序的請求,然後進行相應的處理,根據請求數據和爬蟲判斷記錄識別客戶端是否有爬蟲活動,後續根據客戶端情況實時修改該客戶端的爬蟲判斷記錄。該方法能夠根據頁面請求及時進行爬蟲識別判斷,同時,對源伺服器中的代碼結構和業務邏輯無需做任何改變,識別過程與產品特徵無關,也與易於偽造的用戶代理信息欄位無關,提高了識別結果的準確性。
上述爬蟲判斷記錄包括以下欄位:客戶端標識(即客戶端id)、緩衝時間、更新時間、下發狀態和爬蟲標識位。其中,客戶端標識可以包括mac(mediaaccesscontrol,媒體訪問控制)地址、客戶端信息(如js、html、html5特性等的支持情況)、瀏覽器類型等。緩衝時間表示爬蟲識別程序的請求的接收時間範圍的計算起點,在具體應用中,可以計算緩衝時間與當前時間的差值,若該差值超過預設的接收時間範圍,即預設的接收時間範圍內未收到爬蟲識別程序的請求,可以確定客戶端為爬蟲可疑客戶端。更新時間表示修改爬蟲標識位的時間。下發狀態表示爬蟲識別程序代碼是否下發給客戶端,0表示默認值,1表示已下發,2表示再下發。爬蟲標識位的值可以為0、1或2,0表示默認值,1表示正常客戶端,2表示爬蟲可疑客戶端。
初始的爬蟲判斷記錄中,緩衝時間為當前時間戳,更新時間為空,下發狀態為1,爬蟲標識位為0。
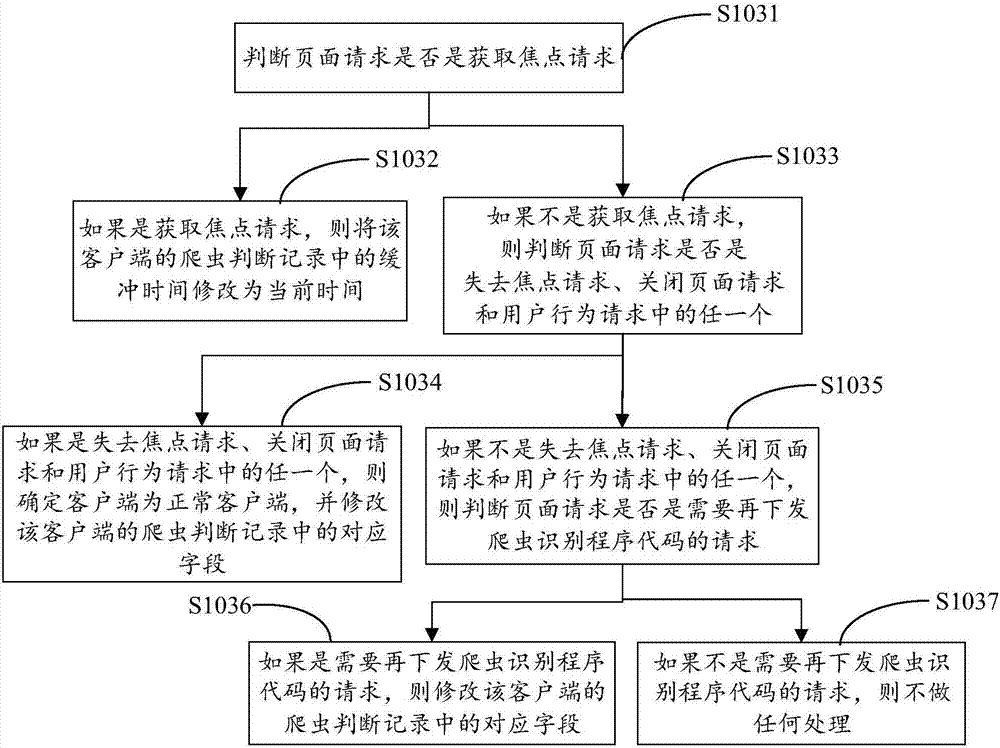
如圖2所示,步驟s103中根據爬蟲識別程序的請求數據判斷客戶端是否為正常客戶端並修改資料庫中的爬蟲判斷記錄,可以包括以下步驟:
步驟s1031,判斷頁面請求是否是獲取焦點請求。其中,獲取焦點請求是指滑鼠點擊屏幕上某一位置,滑鼠所點位置為焦點,則該位置或位置所屬頁面獲取了焦點,點擊行為所產生的請求即為獲取焦點請求。
步驟s1032,如果是獲取焦點請求,則將該客戶端的爬蟲判斷記錄中的緩衝時間修改為當前時間。此時,並不能判斷出客戶端是否有爬蟲活動,對緩衝時間欄位進行修改,以便後續計算接收時間範圍內是否接收到爬蟲識別程序的請求,從而可以識別客戶端是否有爬蟲活動。
步驟s1033,如果不是獲取焦點請求,則判斷頁面請求是否是失去焦點請求、關閉頁面請求和用戶行為請求中的任一個。
舉例而言,用戶打開了某個頁面,然後點擊滑鼠右鍵彈出新窗口,那麼該頁面就失去焦點,該點擊右鍵的行為所產生的請求即為失去焦點請求。用戶行為請求包括用戶敲擊鍵盤、點擊滑鼠、滾輪、滑動等用戶具體操作行為所產生的請求。在實際應用中,點擊右鍵彈出窗口的位置是隨機的,不同的客戶端在不同的時間彈出窗口的位置不相同,這樣的隨機性可以確保不會造成重放攻擊。對於這種輕度影響用戶正常使用、瀏覽網頁的因素,用戶行為上往往有比較簡單的下意識操作去進行修正,例如,移動滑鼠後點擊、滑鼠右鍵點擊空白處等,由此可以儘量避免爬蟲誤報。
步驟s1034,如果是失去焦點請求、關閉頁面請求和用戶行為請求中的任一個,則確定客戶端為正常客戶端,並修改該客戶端的爬蟲判斷記錄中的對應欄位。具體修改欄位如下:將緩衝時間修改為0,更新時間修改為當前時間,下發狀態修改為0,爬蟲標識位修改為1。
本步驟中,確定為正常客戶端時,對更新時間欄位進行修改,以便後續根據該更新時間計算是否到了識別間隔時間,如果到了識別間隔時間,則需要重新對該客戶端進行識別,以免發生漏報。具體的,如果頁面請求是用戶行為請求,對於隱藏滑鼠的方案,伺服器需收到至少3個滑鼠位置,才能判斷為正常客戶端,從而減少漏報誤報的發生。
步驟s1035,如果不是失去焦點請求、關閉頁面請求和用戶行為請求中的任一個,則判斷頁面請求是否是需要再下發爬蟲識別程序代碼的請求。
步驟s1036,如果是需要再下發爬蟲識別程序代碼的請求,則修改該客戶端的爬蟲判斷記錄中的對應欄位。具體修改欄位如下:將緩衝時間修改為0,更新時間修改為0,下發狀態修改為2。將緩衝時間和更新時間歸零,便於下一輪識別過程中對其進行賦值。
步驟s1037,如果不是需要再下發爬蟲識別程序代碼的請求,則不做任何處理。
通過圖2所示的流程,能夠根據爬蟲識別程序的請求數據判斷出客戶端是否有爬蟲活動,如果暫時未能判斷出結果,則等待下一輪再接收到頁面請求進行識別。
如圖3所示,步驟s104包括以下步驟:
步驟s1041,判斷頁面請求是否是html頁面且支持javascript,以判斷是否需要下發爬蟲識別程序代碼;
步驟s1042,如果不是html頁面和/或不支持javascript,則確定不需要下發爬蟲識別程序代碼,直接響應頁面請求;
步驟s1043,如果是html頁面且支持javascript,則確定需要下發爬蟲識別程序代碼,並進入步驟s1044;
步驟s1044,根據客戶端標識判斷資料庫中是否存儲有該客戶端的爬蟲判斷記錄;
步驟s1045,如果否,則確定客戶端未做過爬蟲識別處理,在響應中添加爬蟲識別程序代碼,發給客戶端,並在資料庫中添加該客戶端的爬蟲判斷記錄;
步驟s1046,如果是,則確定客戶端做過爬蟲識別處理,根據該客戶端的爬蟲判斷記錄中的下發狀態判斷是否需要再下發爬蟲識別程序代碼;
步驟s1047,如果下發狀態為2,則確定需要再下發爬蟲識別程序代碼,在響應中添加爬蟲識別程序代碼,發給客戶端,並將該客戶端的爬蟲判斷記錄中的緩衝時間修改為當前時間,下發狀態修改為1;
步驟s1048,如果下發狀態不為2,則確定不需要再下發爬蟲識別程序代碼,直接響應頁面請求。
圖3所示的流程中,在頁面請求不是爬蟲識別程序的請求的情況下,根據頁面請求的特點以及資料庫中是否存在該客戶端的爬蟲判斷記錄,決定是否需要下發代碼給客戶端,以便及時識別爬蟲,避免對該客戶端的漏報。
在上述識別網絡爬蟲的過程中,還可以包括時間處理流程,例如,在多長時間內未收到爬蟲識別程序的請求,則判定客戶端為爬蟲可疑客戶端;爬蟲可疑客戶端的爬蟲處理時間;對正常客戶端進行重新識別的間隔時間。時間處理流程可以是與識別過程並行進行,根據資料庫中的爬蟲判斷記錄計算時間差值,與預設值進行對比,並進行相應處理。時間處理流程可以在接收到客戶端發起的時間處理請求後啟動,也可以由伺服器自身決定何時啟動,例如,間隔一段時間對所有客戶端或部分客戶端啟動時間處理流程。
具體的,上述識別網絡爬蟲的方法還可以包括以下時間處理步驟:判斷爬蟲判斷記錄中的緩衝時間與當前時間的差值是否超出預設時間範圍;如果超出預設時間範圍,且未收到爬蟲識別程序的請求,則確定客戶端為爬蟲可疑客戶端,並將緩衝時間修改為0,更新時間修改為當前時間,下發狀態修改為0,爬蟲標識位修改為2;如果未超出預設時間範圍,則根據爬蟲標識位與更新時間確定客戶端的當前情況以及所要執行的操作。
上述時間處理步驟中,確定為爬蟲可疑客戶端時,對更新時間欄位進行修改,以便後續根據該更新時間計算是否到了爬蟲處理時間,如果到了爬蟲處理時間,則需要重新對該客戶端進行識別,以免發生誤報。上述預設時間範圍可以根據實際需求自行設定,例如,可以配置為1分鐘,從緩衝時間起算,超過1分鐘未收到爬蟲識別程序的請求,則確定客戶端為爬蟲可疑客戶端。
其中,根據爬蟲標識位與更新時間確定客戶端的當前情況以及所要執行的操作,包括:
(1)如果爬蟲標識位為0,則確定處於判斷過程,暫時不做任何處理。
(2)如果爬蟲標識位為1,則說明之前已判斷該客戶端為正常客戶端,此時需判斷更新時間與當前時間的差值是否超出預設的識別間隔時間;如果是,則刪除該客戶端的爬蟲判斷記錄,等待下次接收頁面請求進行重新識別;如果否,則不做任何處理。
(3)如果爬蟲標識位為2,則說明之前已判斷該客戶端為爬蟲可疑客戶端,此時需判斷更新時間與當前時間的差值是否超出預設的爬蟲處理時間;如果是,則確定需再下發爬蟲識別程序代碼,將下發狀態修改為2,緩衝時間修改為當前時間,更新時間修改為空,爬蟲標識位修改為0;如果否,則不做任何處理。本步驟中,過了爬蟲處理時間,對緩衝時間欄位進行修改,以便後續計算接收時間範圍內是否接受到爬蟲識別程序的請求,從而可以及時識別客戶端是否有爬蟲活動。
對於正常客戶端,在經過一段時間後需要重新進行爬蟲識別,這段時間即為識別間隔時間,可以根據實際需求自行設定,例如24小時。對於爬蟲可疑客戶端,在對其進行一段時間的處理(例如,攔截)後,需要重新下發代碼,這段時間即為爬蟲處理時間,可以根據實際需求自行設定,例如10分鐘。
通過上述時間處理流程,對確定為正常客戶端或者爬蟲可疑客戶端的客戶端,在間隔一定時間後,重新進行爬蟲識別,從而能夠及時發現爬蟲活動,避免漏報情況發生。
下面結合圖4和圖5的具體實施例對上述識別網絡爬蟲的方法進行詳細說明。以下具體實施例僅作示例,在實際應用中,在能夠實現方案的基礎上可以對其步驟的執行順序或實現方式稍作改變。
圖4是本發明具體實施例提供的識別網絡爬蟲方法的流程圖,包括以下步驟:
步驟s4001,接收頁面請求。
步驟s4002,判斷頁面請求是否是爬蟲識別程序的請求。如果不是,則進入步驟s4003;如果是,則進入步驟s4010。
步驟s4003,判斷頁面請求是否是html頁面且支持js(javascript,java腳本),本步驟是為了判斷是否需要下發代碼。如果不是html頁面和/或者不支持js,說明不能解析js的請求,則進入步驟s4004;如果是html頁面且支持js,則進入步驟s4005。
步驟s4004,直接響應。
步驟s4005,判斷資料庫中是否存在此客戶端的爬蟲判斷記錄,本步驟是為了判斷此客戶端是否有做過爬蟲識別的處理。如果存在,則進入步驟s4007;如果不存在,則進入步驟s4006。
步驟s4006,在響應中加入爬蟲識別程序代碼,並在資料庫中插入一條記錄。
初始化記錄的各欄位值如下:
客戶端id:當前的客戶端id;
緩衝時間:當前時間戳;
更新時間:空;
下發狀態:1,表示已下發;
爬蟲標識位:0,表示默認值。
步驟s4007,判斷下發狀態欄位是否為2,本步驟是為了判斷是否需要再下發代碼。如果是,則需要再下發代碼,進入步驟s4008;如果不是,則無需再下發代碼,進入步驟s4009。
步驟s4008,在響應中加入爬蟲識別程序代碼,發給客戶端,並修改資料庫中記錄的欄位。
客戶端id:當前的客戶端id;
緩衝時間:當前時間戳;
更新時間:空;
下發狀態:1,表示已下發;
爬蟲標識位:0,表示默認值。
步驟s4009,直接響應。
步驟s4010,判斷頁面請求是否是獲取焦點請求,本步驟是為了判斷接收到的頁面請求的類型。如果是,則進入步驟s4011;如果不是,則進入步驟s4012。
步驟s4011,將緩衝時間修改為當前時間。
客戶端id:當前的客戶端id;
緩衝時間:當前時間戳;
更新時間:空;
下發狀態:1,表示已下發;
爬蟲標識位:0,表示默認值。
步驟s4012,判斷頁面請求是否是失去焦點請求,本步驟是為了判斷接收到的頁面請求的類型。如果是,則進入步驟s4013;如果不是,則進入步驟s4014。
步驟s4013,判斷為正常的客戶端,修改資料庫中記錄的欄位。
客戶端id:當前的客戶端id;
緩衝時間:0;
更新時間:當前時間;
下發狀態:0,表示默認值;
爬蟲標識位:1,表示正常客戶端。
步驟s4014,判斷頁面請求是否是關閉頁面請求,本步驟是為了判斷接收到的請求的類型。如果是,則進入步驟s4015;如果不是,則進入步驟s4016。
步驟s4015,判斷為正常的客戶端,修改資料庫中記錄的欄位。
客戶端id:當前的客戶端id;
緩衝時間:0;
更新時間:當前時間;
下發狀態:0,表示默認值;
爬蟲標識位:1,表示正常客戶端。
步驟s4016,判斷頁面請求是否是用戶行為請求,本步驟是為了判斷接收到的請求的類型。如果是,則進入步驟s4017;如果不是,則進入步驟s4018。
步驟s4017,判斷為正常客戶端,修改資料庫中記錄的欄位。
客戶端id:當前的客戶端id;
緩衝時間:0;
更新時間:當前時間;
下發狀態:0,表示默認值;
爬蟲標識位:1,表示正常客戶端。
步驟s4018,判斷頁面請求是否是需要再下發的請求。如果是,則進入步驟s4019;如果不是,則進入步驟s4020。
步驟s4019,修改下發狀態為2。
客戶端id:當前的客戶端id;
緩衝時間:0;
更新時間:0;
下發狀態:2,表示再下發;
爬蟲標識位:0,表示默認值。
步驟s4020,不做任何處理。
圖5是本發明具體實施例提供的時間處理流程圖,包括以下步驟:
步驟s5001,接收客戶端發起的時間判斷請求。
步驟s5002,判斷緩衝時間欄位的時間戳與當前時間的差值是否超過預設時間範圍1分鐘。如果超過,進入步驟s5003;如果不超過,進入步驟s5004
步驟s5003,判斷此客戶端為爬蟲可疑客戶端,爬蟲標識位改為2,更新時間更改為當前時間,緩衝時間和下發狀態都改為0。
步驟s5004,判斷爬蟲標識位是否為非零值。本步驟是為了判斷此客戶端目前的情況,其中0表示還處於判斷階段,1是正常客戶端,2是爬蟲客戶端。如果為0,進入步驟s5005;如果為非零值,進入步驟s5006。
步驟s5005,還處於判斷階段,等待客戶端的頁面請求,暫時不做任何處理。
步驟s5006,判斷爬蟲標識位是否為1。本步驟仍是為了判斷此客戶端目前的情況。如果為1,進入步驟s5010;如果為2,進入步驟s5007。
步驟s5007,說明是已經判斷為爬蟲可疑客戶端的客戶端,判斷當前時間與更新時間的時間差是否大於爬蟲處理時間10分鐘。本步驟是為了判斷是否到了爬蟲處理時間,對於爬蟲可疑客戶端,可以做相應的處理,比如攔截,爬蟲處理時間到達後重新判斷是否有爬蟲活動。如果是,進入步驟s5008,如果否,進入步驟s5009。
步驟s5008,說明攔截時間到,需重新下發代碼,修改下發狀態為2,其他欄位改為初始值。
步驟s5009,說明還在攔截時間內,可不做處理。
步驟s5010,說明是已經判斷為正常的客戶端,判斷當前時間與更新時間的時間差是否大於識別間隔時間24小時,本步驟是為了判斷是否到了重新識別的時間,例如24小時後重新識別。如果是,進入步驟s5011;如果否,進入步驟s5012。
步驟s5011,刪除此條記錄,等待下次請求過來重新識別。
步驟s5012,還沒到重新識別的時間,可不做處理。
本發明實施例還提供了一種識別網絡爬蟲的系統,用於實現上述識別網絡爬蟲的方法,其實施可以參考上述方法實施例。如圖6所示,該系統包括:接收單元61、第一判斷單元62、第一處理單元63和第二處理單元64。下面對其結構進行詳細說明。
接收單元61,用於接收客戶端發起的頁面請求。
第一判斷單元62,連接至接收單元61,用於判斷頁面請求是否是爬蟲識別程序的請求。
第一處理單元63,連接至第一判斷單元62,用於在頁面請求是爬蟲識別程序的請求的情況下,根據爬蟲識別程序的請求數據判斷客戶端是否為正常客戶端,並修改資料庫中的爬蟲判斷記錄。爬蟲判斷記錄包括的欄位參考方法實施例中所述,此處不再贅述。
第二處理單元64,連接至第一判斷單元62,用於在頁面請求不是爬蟲識別程序的請求的情況下,在響應內容類型為html或javascript的頁面添加爬蟲識別程序代碼,並發送給客戶端。
上述識別網絡爬蟲的系統將爬蟲識別程序代碼下發給客戶端,通過判斷接收的頁面請求是否是爬蟲識別程序的請求,然後進行相應的處理,根據請求數據和爬蟲判斷記錄識別客戶端是否有爬蟲活動,後續根據客戶端情況實時修改該客戶端的爬蟲判斷記錄。該方法能夠根據頁面請求及時進行爬蟲識別判斷,同時,對源伺服器中的代碼結構和業務邏輯無需做任何改變,識別過程與產品特徵無關,也與易於偽造的用戶代理信息欄位無關,提高了識別結果的準確性。
優選的,第一處理單元63包括:第一判斷模塊、第一處理模塊、第二判斷模塊、第二處理模塊、第三判斷模塊和第三處理模塊。上述模塊用於判斷請求數據以及進行相應處理。
具體的,第一判斷模塊,用於判斷頁面請求是否是獲取焦點請求;第一處理模塊,連接至第一判斷模塊,用於在頁面請求是獲取焦點請求的情況下,將該客戶端的爬蟲判斷記錄中的緩衝時間修改為當前時間;第二判斷模塊,連接至第一判斷模塊,用於在頁面請求不是獲取焦點請求的情況下,判斷頁面請求是否是失去焦點請求、關閉頁面請求和用戶行為請求中的任一個;第二處理模塊,連接至第二判斷模塊,用於在頁面請求是失去焦點請求、關閉頁面請求和用戶行為請求中的任一個的情況下,確定客戶端為正常客戶端,並修改該客戶端的爬蟲判斷記錄中的對應欄位;第三判斷模塊,連接至第二判斷模塊,用於在頁面請求不是失去焦點請求、關閉頁面請求和用戶行為請求中的任一個的情況下,判斷頁面請求是否是需要再下發爬蟲識別程序代碼的請求;第三處理模塊,連接至第三判斷模塊,用於在頁面請求是需要再下發爬蟲識別程序代碼的請求的情況下,修改該客戶端的爬蟲判斷記錄中的對應欄位;以及在頁面請求不是需要再下發爬蟲識別程序代碼的請求的情況下,不做任何處理。
其中,第二處理模塊具體用於將緩衝時間修改為0,更新時間修改為當前時間,下發狀態修改為0,爬蟲標識位修改為1。第三處理模塊具體用於將緩衝時間修改為0,更新時間修改為0,下發狀態修改為2。
優選的,第二處理單元64包括:第四判斷模塊、第四處理模塊、確定模塊、第五判斷模塊、第五處理模塊、第六判斷模塊、第六處理模塊和第七處理模塊。
具體的,第四判斷模塊,用於判斷頁面請求是否是html頁面且支持javascript;第四處理模塊,連接至第四判斷模塊,用於在頁面請求不是html頁面和/或不支持javascript的情況下,確定不需要下發爬蟲識別程序代碼,直接響應頁面請求;確定模塊,連接至第四判斷模塊,用於在頁面請求是html頁面且支持javascript的情況下,確定需要下發爬蟲識別程序代碼;第五判斷模塊,連接至確定模塊,用於在確定模塊確定需要下發爬蟲識別程序代碼之後,根據客戶端標識判斷資料庫中是否存儲有該客戶端的爬蟲判斷記錄;第五處理模塊,連接至第五判斷模塊,用於在判斷結果為否的情況下,確定客戶端未做過爬蟲識別處理,在響應中添加爬蟲識別程序代碼,發給客戶端,並在資料庫中添加該客戶端的爬蟲判斷記錄;第六判斷模塊,連接至第五判斷模塊,用於在判斷結果為是的情況下,確定客戶端做過爬蟲識別處理,根據該客戶端的爬蟲判斷記錄中的下發狀態判斷是否需要再下發爬蟲識別程序代碼;第六處理模塊,連接至第六判斷模塊,用於在下發狀態為2的情況下,確定需要再下發爬蟲識別程序代碼,在響應中添加爬蟲識別程序代碼,發給客戶端,並將該客戶端的爬蟲判斷記錄中的緩衝時間修改為當前時間,下發狀態修改為1;第七處理模塊,連接至第六判斷模塊,用於在下發狀態不為2的情況下,確定不需要再下發爬蟲識別程序代碼,直接響應頁面請求。
上述系統還可以包括:第二判斷單元、第三處理單元和第四處理單元。
具體的,第二判斷單元,用於判斷爬蟲判斷記錄中的緩衝時間與當前時間的差值是否超出預設時間範圍;第三處理單元,連接至第二判斷單元,用於在超出預設時間範圍且未收到爬蟲識別程序的請求的情況下,確定客戶端為爬蟲可疑客戶端,並將緩衝時間修改為0,更新時間修改為當前時間,下發狀態修改為0,爬蟲標識位修改為2;第四處理單元,連接至第二判斷單元,用於在未超出預設時間範圍的情況下,根據爬蟲標識位與更新時間確定客戶端的當前情況以及所要執行的操作。
其中,第四處理單元具體用於:如果爬蟲標識位為0,則確定處於判斷過程,不做任何處理;如果爬蟲標識位為1,則說明之前已判斷該客戶端為正常客戶端,此時需判斷更新時間與當前時間的差值是否超出預設的識別間隔時間;如果是,則刪除該客戶端的爬蟲判斷記錄,等待下次接收頁面請求進行重新識別;如果否,則不做任何處理;如果爬蟲標識位為2,則說明之前已判斷該客戶端為爬蟲可疑客戶端,此時需判斷更新時間與當前時間的差值是否超出預設的爬蟲處理時間;如果是,則確定需再下發爬蟲識別程序代碼,將下發狀態修改為2,緩衝時間修改為當前時間,更新時間修改為空,爬蟲標識位修改為0;如果否,則不做任何處理。
以上所描述的系統實施例僅僅是示意性的,其中所述作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位於一個地方,或者也可以分布到多個網絡單元上。可以根據實際的需要選擇其中的部分或者全部模塊來實現本實施例方案的目的。本領域普通技術人員在不付出創造性的勞動的情況下,即可以理解並實施。
通過以上的實施方式的描述,本領域的技術人員可以清楚地了解到各實施方式可藉助軟體加必需的通用硬體平臺的方式來實現,當然也可以通過硬體。基於這樣的理解,上述技術方案本質上或者說對現有技術做出貢獻的部分可以以軟體產品的形式體現出來,該計算機軟體產品可以存儲在計算機可讀存儲介質中,如rom/ram、磁碟、光碟等,包括若干指令用以使得一臺計算機設備(可以是個人計算機,伺服器,或者網絡設備等)執行各個實施例或者實施例的某些部分所述的方法。
以上所述僅為本發明的較佳實施例,並不用以限制本發明,凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護範圍之內。