理賠單據的字符識別方法及伺服器與流程
2023-09-12 00:33:00 2
本發明涉及計算機技術領域,尤其涉及一種理賠單據的字符識別方法及伺服器。
背景技術:
隨著大眾保險意識的增強、購買保險的客戶群大幅增多,保險公司需處理的客戶理賠申請越來越多,保險公司作業人員需錄入的理賠單據影像也越來越多,以致於錄單作業人員的人力緊張,同時,經常會出現錄單錯誤。為了有效減少錄單錯誤、提高錄單效率,目前,有些保險公司在錄單作業過程中引入ocr(opticalcharacterrecognition,光學字符識別)技術,以自動識別出理賠單據影像的字符以填充到對應的輸入欄位中。
然而,現有的利用ocr技術進行理賠單據影像字符的識別方案僅利用自身的識別引擎對整個理賠單據影像中的字符進行統一識別,並未考慮理賠單據框架格式對識別精度的影響,也並未考慮單據中的框線對字符識別的幹涉,使得現有的識別方案的識別精度不高,需要耗費大量的人力、物力進行校驗。
技術實現要素:
本發明的主要目的在於提供一種理賠單據的字符識別方法及伺服器,旨在提高理賠單據的識別精度。
為實現上述目的,本發明提供的一種理賠單據的字符識別方法,所述方法包括以下步驟:
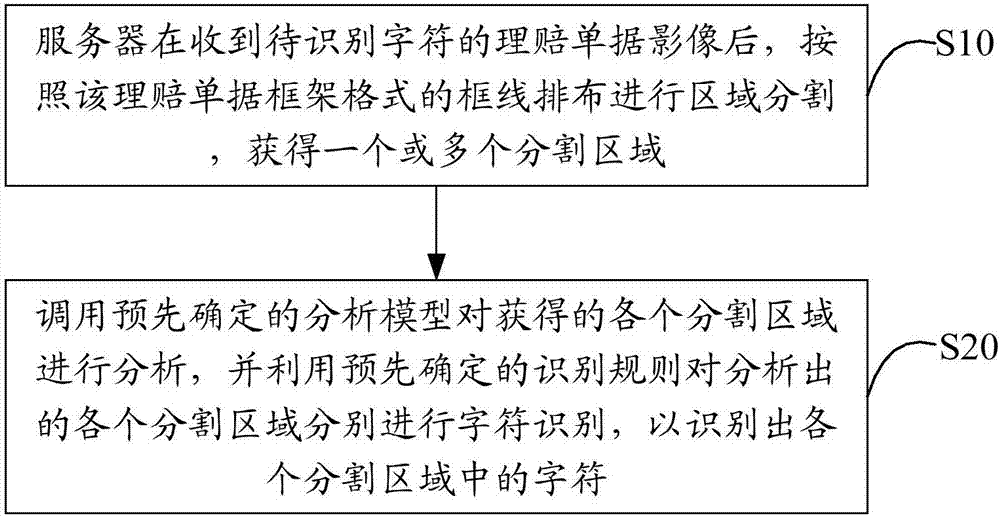
伺服器在收到待識別字符的理賠單據影像後,按照該理賠單據框架格式的框線排布進行區域分割,獲得一個或多個分割區域;
調用預先確定的分析模型對獲得的各個分割區域進行分析,並利用預先確定的識別規則對分析出的各個分割區域分別進行字符識別,以識別出各個分割區域中的字符。
優選地,所述調用預先確定的分析模型對獲得的各個分割區域進行分析的步驟包括:
調用預先確定的分析模型對獲得的各個分割區域進行分析,以分析出可利用光學字符識別引擎識別的第一分割區域和不可利用光學字符識別引擎識別的第二分割區域;
所述利用預先確定的識別規則對分析出的各個分割區域分別進行字符識別的步驟還包括:
利用預先確定的光學字符識別引擎對各個所述第一分割區域進行字符識別,以識別出各個所述第一分割區域中的字符,並調用預先確定的識別模型對各個所述第二分割區域進行字符識別,以識別出各個所述第二分割區域中的字符。
優選地,所述預先確定的分析模型為卷積神經網絡模型,所述預先確定的分析模型的訓練過程如下:
a、針對預先確定的理賠單據框架格式,獲取預設數量的基於該理賠單據框架格式的理賠單據影像樣本;
b、對每一個理賠單據影像樣本按照該理賠單據框架格式的框線排布進行區域分割,並確定出各個理賠單據影像樣本中利用光學字符識別引擎識別錯誤的第三分割區域和利用光學字符識別引擎識別正確的第四分割區域;
c、將所有第三分割區域歸入第一訓練集,將所有第四分割區域歸入第二訓練集;
d、分別從所述第一訓練集和所述第二訓練集中提取出第一預設比例的分割區域作為待訓練的分割區域,並將所述第一訓練集和所述第二訓練集中剩餘的分割區域作為待驗證的分割區域;
e、利用提取的各個待訓練的分割區域進行模型訓練,以生成所述預先確定的分析模型,並利用各個待驗證的分割區域對生成的所述預先確定的分析模型進行驗證;
f、若驗證通過率大於或等於預設閾值,則訓練完成,或者,若驗證通過率小於預設閾值,則增加理賠單據影像樣本的數量,並重複執行上述步驟a、b、c、d、e,直至驗證通過率大於或等於預設閾值。
優選地,所述預先確定的識別模型為長短期記憶lstm模型,所述預先確定的識別模型的訓練過程如下:
獲取預設數量的分割區域樣本,對各個分割區域樣本以該分割區域樣本所含字符來進行標註;
將預設數量的分割區域樣本按照預設比例分為第一數據集和第二數據集,並將所述第一數據集作為訓練集,將所述第二數據集作為測試集;
將所述第一數據集送入lstm網絡進行模型訓練,每隔預設時間,使用訓練得到的模型對所述第二數據集中的分割區域樣本進行字符識別,並將識別的字符與該分割區域樣本的標註進行比對,以計算識別的字符和標註的誤差;
若訓練得到的模型識別字符的誤差出現發散,則調整預設的訓練參數並重新訓練,直至使得訓練得到的模型識別字符的誤差能夠收斂;
若訓練得到的模型識別字符的誤差收斂,則結束模型訓練,將生成的模型作為訓練好的所述預先確定的識別模型。
優選地,所述分割區域是由該理賠單據框架格式的框線所圍成的最小單位的區域,且所述分割區域為不包含框線的區域。
此外,為實現上述目的,本發明還提供一種理賠單據的字符識別伺服器,所述字符識別伺服器包括:
分割模塊,用於在收到待識別字符的理賠單據影像後,按照該理賠單據框架格式的框線排布進行區域分割,獲得一個或多個分割區域;
識別模塊,用於調用預先確定的分析模型對獲得的各個分割區域進行分析,並利用預先確定的識別規則對分析出的各個分割區域分別進行字符識別,以識別出各個分割區域中的字符。
優選地,所述識別模塊還用於:
調用預先確定的分析模型對獲得的各個分割區域進行分析,以分析出可利用光學字符識別引擎識別的第一分割區域和不可利用光學字符識別引擎識別的第二分割區域;
利用預先確定的光學字符識別引擎對各個所述第一分割區域進行字符識別,以識別出各個所述第一分割區域中的字符,並調用預先確定的識別模型對各個所述第二分割區域進行字符識別,以識別出各個所述第二分割區域中的字符。
優選地,所述預先確定的分析模型為卷積神經網絡模型,所述預先確定的分析模型的訓練過程如下:
a、針對預先確定的理賠單據框架格式,獲取預設數量的基於該理賠單據框架格式的理賠單據影像樣本;
b、對每一個理賠單據影像樣本按照該理賠單據框架格式的框線排布進行區域分割,並確定出各個理賠單據影像樣本中利用光學字符識別引擎識別錯誤的第三分割區域和利用光學字符識別引擎識別正確的第四分割區域;
c、將所有第三分割區域歸入第一訓練集,將所有第四分割區域歸入第二訓練集;
d、分別從所述第一訓練集和所述第二訓練集中提取出第一預設比例的分割區域作為待訓練的分割區域,並將所述第一訓練集和所述第二訓練集中剩餘的分割區域作為待驗證的分割區域;
e、利用提取的各個待訓練的分割區域進行模型訓練,以生成所述預先確定的分析模型,並利用各個待驗證的分割區域對生成的所述預先確定的分析模型進行驗證;
f、若驗證通過率大於或等於預設閾值,則訓練完成,或者,若驗證通過率小於預設閾值,則增加理賠單據影像樣本的數量,並重複執行上述步驟a、b、c、d、e,直至驗證通過率大於或等於預設閾值。
優選地,所述預先確定的識別模型為長短期記憶lstm模型,所述預先確定的識別模型的訓練過程如下:
獲取預設數量的分割區域樣本,對各個分割區域樣本以該分割區域樣本所含字符來進行標註;
將預設數量的分割區域樣本按照預設比例分為第一數據集和第二數據集,並將所述第一數據集作為訓練集,將所述第二數據集作為測試集;
將所述第一數據集送入lstm網絡進行模型訓練,每隔預設時間,使用訓練得到的模型對所述第二數據集中的分割區域樣本進行字符識別,並將識別的字符與該分割區域樣本的標註進行比對,以計算識別的字符和標註的誤差;
若訓練得到的模型識別字符的誤差出現發散,則調整預設的訓練參數並重新訓練,直至使得訓練得到的模型識別字符的誤差能夠收斂;
若訓練得到的模型識別字符的誤差收斂,則結束模型訓練,將生成的模型作為訓練好的所述預先確定的識別模型。
優選地,所述分割區域是由該理賠單據框架格式的框線所圍成的最小單位的區域,且所述分割區域為不包含框線的區域。
本發明提出的理賠單據的字符識別方法及伺服器,在對理賠單據影像進行字符識別前,按照該理賠單據框架格式的框線排布對其進行區域分割,利用預先確定的識別規則對該理賠單據的各個分割區域分別進行字符識別,以分別識別出各個分割區域中的字符。由於考慮到理賠單據框架格式對識別精度的影響,在進行字符識別前先按照理賠單據框架格式的框線排布進行區域分割,再針對各個分割區域來進行字符識別,避免了在對整個理賠單據影像中的字符進行統一識別時單據中的框線對字符識別的影響及幹涉,能有效提高對理賠單據中字符的識別精度。
附圖說明
圖1為本發明理賠單據的字符識別方法第一實施例的流程示意圖;
圖2為本發明理賠單據的字符識別方法第二實施例的流程示意圖;
圖3為本發明理賠單據的字符識別伺服器第一實施例的功能模塊示意圖。
本發明目的的實現、功能特點及優點將結合實施例,參照附圖做進一步說明。
具體實施方式
為了使本發明所要解決的技術問題、技術方案及有益效果更加清楚、明白,以下結合附圖和實施例,對本發明進行進一步詳細說明。應當理解,此處所描述的具體實施例僅僅用以解釋本發明,並不用於限定本發明。
本發明提供一種理賠單據的字符識別方法。
參照圖1,圖1為本發明理賠單據的字符識別方法第一實施例的流程示意圖。
在第一實施例中,該理賠單據的字符識別方法包括:
步驟s10,伺服器在收到待識別字符的理賠單據影像後,按照該理賠單據框架格式的框線排布進行區域分割,獲得一個或多個分割區域;
本實施例中,伺服器可以接收用戶發出的包含待識別字符的理賠單據影像的字符識別請求,例如,接收用戶通過手機、平板電腦、自助終端設備等終端發送的字符識別請求,如接收用戶在手機、平板電腦、自助終端設備等終端中預先安裝的客戶端上發送來的字符識別請求,或接收用戶在手機、平板電腦、自助終端設備等終端中的瀏覽器系統上發送來的字符識別請求。
伺服器在收到待識別字符識別的理賠單據影像後,按照該理賠單據框架格式的框線排布進行區域分割,理賠單據影像中按照其框架格式排布有橫向或豎向的框線,以組成各項輸入欄供用戶填寫相關信息。本實施例中,按照該理賠單據框架格式的框線排布進行區域分割,獲得一個或多個分割區域。例如,在一種實施方式中,由於一般不同類型的保險均對應有不同的單據格式模板,因此,可預先根據用戶上傳的單據類型(可能不同的保險有不同的單據格式),獲取到對應的單據模板,然後根據模板的格式來分割。如可根據收到的待識別字符的理賠單據影像的單據類型,找到該理賠單據影像對應的單據模板,然後根據其對應的單據模板進行區域分割。該分割區域是由該理賠單據框架格式的框線所圍成的最小單位的區域,且該分割區域為不包含框線的區域,以避免後續在對每一分割區域進行字符識別時框線對識別精度的幹涉及影響,該分割區域類似於excel表格的每個方格,excel表格的每個方格即是最小區域內不包含框線的區域。
步驟s20,調用預先確定的分析模型對獲得的各個分割區域進行分析,並利用預先確定的識別規則對分析出的各個分割區域分別進行字符識別,以識別出各個分割區域中的字符。
在按照該理賠單據框架格式的框線排布對理賠單據影像進行區域分割得到一個或多個分割區域後,可調用預先確定的分析模型對獲得的各個分割區域進行分析,並利用預先確定的識別規則對各個分割區域分別進行字符識別,以識別出各個分割區域中的字符,也即理賠單據影像中的字符。例如,可利用預先確定的分析模型分析各個分割區域所適用的識別模型或識別方式,再根據分析出的結果針對各個分割區域利用適合各個分割區域自身的識別模型或識別方式來進行字符識別,以提高字符識別的準確率。如針對不同的分割區域,可分析出字符識別的方式為利用光學字符識別引擎進行識別,也可以用其他識別引擎或訓練的識別模型來進行識別,在此不做限定。識別出各個分割區域中的字符,還可將各個分割區域中的字符自動填充、錄入至與該理賠單據影像對應的電子理賠單據的各相應輸入欄位中。
本實施例在對理賠單據影像進行字符識別前,按照該理賠單據框架格式的框線排布對其進行區域分割,利用預先確定的識別規則對該理賠單據的各個分割區域分別進行字符識別,以分別識別出各個分割區域中的字符。由於考慮到理賠單據框架格式對識別精度的影響,在進行字符識別前先按照理賠單據框架格式的框線排布進行區域分割,再針對各個分割區域來進行字符識別,避免了在對整個理賠單據影像中的字符進行統一識別時單據中的框線對字符識別的影響及幹涉,能有效提高對理賠單據中字符的識別精度。
如圖2所示,本發明第二實施例提出一種理賠單據的字符識別方法,在上述實施例的基礎上,所述步驟s20包括:
步驟s201,調用預先確定的分析模型對獲得的各個分割區域進行分析,以分析出可利用光學字符識別引擎識別的第一分割區域和不可利用光學字符識別引擎識別的第二分割區域;
步驟s202,利用預先確定的光學字符識別引擎對各個所述第一分割區域進行字符識別,以識別出各個所述第一分割區域中的字符,並調用預先確定的識別模型對各個所述第二分割區域進行字符識別,以識別出各個所述第二分割區域中的字符。
本實施例中,在按照該理賠單據框架格式的框線排布進行區域分割得到一個或多個分割區域後,在對獲得的分割區域進行識別之前,還調用預先確定的分析模型對獲得的各個分割區域進行分析,以分析出無需深度識別的第一分割區域和需要深度識別的第二分割區域。例如,以當前自身的識別引擎為ocr字符識別引擎為例進行說明,可將ocr字符識別引擎能正確識別或識別率高的區域作為無需深度識別的區域,即利用當前自身的ocr字符識別引擎即可對該區域的字符進行正確的識別,無需藉助其他識別方式。將ocr字符識別引擎無法識別或識別率低的區域作為需要深度識別的區域,即利用當前自身的ocr字符識別引擎無法對該區域的字符進行正確的識別,需藉助其他識別方式如經訓練過的識別模型來進行字符識別。
在分析出該理賠單據影像中可利用ocr字符識別引擎進行正確識別的第一分割區域和不可利用ocr字符識別引擎識別的第二分割區域之後,即可針對分析出的第一分割區域和第二分割區域採取不同的識別方式進行字符識別。利用預先確定的ocr字符識別引擎對各個所述第一分割區域進行字符識別,以正確識別出各個所述第一分割區域中的字符。調用預先確定的識別模型對各個所述第二分割區域進行字符識別,以正確識別出各個所述第二分割區域中的字符,該預先確定的識別模型可以是針對大量分割區域樣本進行訓練好的識別模型,也可以是比自身的ocr字符識別引擎識別方式更複雜、識別效果更好的識別引擎,在此不做限定。
進一步地,在其他實施例中,所述預先確定的分析模型為卷積神經網絡(convolutionalneuralnetwork,簡稱cnn)模型,所述預先確定的分析模型的訓練過程如下:
a、針對預先確定的理賠單據框架格式,獲取預設數量(例如,50萬個)的基於該理賠單據框架格式的理賠單據影像樣本;
b、對每一個理賠單據影像樣本按照該理賠單據框架格式的框線排布進行區域分割,並確定出各個理賠單據影像樣本中ocr字符識別引擎識別錯誤的第三分割區域和ocr字符識別引擎識別正確的第四分割區域;
c、將所有第三分割區域歸入第一訓練集,將所有第四分割區域歸入第二訓練集;
d、分別從第一訓練集和第二訓練集中提取出第一預設比例(例如,80%)的分割區域作為待訓練的分割區域,並將第一訓練集和第二訓練集中剩餘的分割區域作為待驗證的分割區域;
e、利用提取的各個待訓練的分割區域進行模型訓練,以生成所述預先確定的分析模型,並利用各個待驗證的分割區域對生成的所述預先確定的分析模型進行驗證;
f、若驗證通過率大於等於預設閾值(例如,98%),則訓練完成,或者,若驗證通過率小於預設閾值,則增加理賠單據影像樣本的數量,並重複執行所述步驟a、b、c、d、e,直至驗證通過率大於或等於預設閾值。
本實施例中利用經大量理賠單據影像樣本訓練過的卷積神經網絡模型來進行分割區域分析,能夠準確分析出理賠單據的各個分割區域中可利用ocr字符識別引擎來正確識別字符的第一分割區域和無法利用ocr字符識別引擎來正確識別字符的第二分割區域,以便後續針對第一分割區域和第二分割區域分別採用不同的識別方式來進行準確的字符識別操作,從而提高對理賠單據中字符的識別精度。
進一步地,在其他實施例中,所述預先確定的識別模型為長短期記憶(longshort-termmemory,簡稱lstm)模型,所述預先確定的識別模型的訓練過程如下:
獲取預設數量(例如,10萬)的區域樣本,該區域樣本可以是歷史數據中對若干理賠單據按照其框架格式的框線排布進行區域分割後的分割區域樣本。在一種實施方式中,可統一將分割區域樣本中的字體設置為黑色,背景設置為白色,以便於進行字符識別。並將各個分割區域樣本進行標註,如可將各個分割區域樣本的名稱命名為該分割區域樣本所包含的字符以進行標註。
將預設數量的分割區域樣本按照預設比例(例如,8:2)分為第一數據集和第二數據集,將第一數據集作為訓練集,將第二數據集作為測試集,其中,第一數據集的樣本數量比例大於或者等於第二數據集的樣本數量比例。
將第一數據集送入lstm網絡進行模型訓練,每隔預設時間(例如每30分鐘或每進行1000次迭代),對模型使用第二數據集進行測試,以評估當前訓練的模型效果。例如,在測試時,可使用訓練得到的模型對第二數據集中的分割區域樣本進行字符識別,並將利用訓練得到的模型對分割區域樣本的字符識別結果與該分割區域樣本的標註進行比對,以計算出訓練得到的模型的字符識別結果與該分割區域樣本的標註的誤差。具體地,在計算誤差時,可採用編輯距離作為計算標準,其中,編輯距離(editdistance),又稱levenshtein距離,是指兩個字串之間,由一個轉成另一個所需的最少編輯操作次數。許可的編輯操作包括將一個字符替換成另一個字符,插入一個字符,刪除一個字符,一般來說,編輯距離越小,兩個串的相似度越大。因此,在以編輯距離作為計算標準來計算訓練得到的模型的字符識別結果與該分割區域樣本的標註的誤差時,計算得到的誤差越小,說明訓練得到的模型的字符識別結果與該分割區域樣本的標註的相似度越大;相反,計算得到的誤差越大,說明訓練得到的模型的字符識別結果與該分割區域樣本的標註的相似度越小。
由於該分割區域樣本的標註為該分割區域樣本的名稱也即該分割區域樣本所包含的字符,因此,計算出的訓練得到的模型的字符識別結果與該分割區域樣本的標註的誤差即為訓練得到的模型的字符識別結果與該分割區域樣本所包含的字符之間的誤差,能反映出訓練得到的模型識別出的字符與正確的字符之間的誤差。記錄每一次對訓練的模型使用第二數據集進行測試的誤差,並分析誤差的變化趨勢,若分析測試時的訓練模型對分割區域樣本的字符識別的誤差出現發散,則調整訓練參數如activation函數、lstm層數、輸入輸出的變量維度等,並重新訓練,使測試時的訓練模型對分割區域樣本的字符識別的誤差能夠收斂。當分析測試時的訓練模型對分割區域樣本的字符識別的誤差收斂後,則結束模型訓練,將生成的訓練模型作為訓練好的所述預先確定的識別模型。
本實施例中,針對ocr字符識別引擎無法識別的區域,採用訓練好的lstm模型進行識別,由於lstm模型為經大量分割區域樣本訓練過的,且對分割區域樣本的字符識別的誤差收斂的模型,配合lstm模型自身的長期記憶功能使該lstm模型在識別分割區域中的字符時,能利用模型記住的長期信息如上下文信息等,更加準確地識別出分割區域中的字符,從而進一步提高對理賠單據中字符的識別精度。
本發明進一步提供一種理賠單據的字符識別伺服器。
參照圖3,圖3為本發明理賠單據的字符識別伺服器第一實施例的功能模塊示意圖。
在第一實施例中,該理賠單據的字符識別伺服器包括:
分割模塊01,用於在收到待識別字符的理賠單據影像後,按照該理賠單據框架格式的框線排布進行區域分割,獲得一個或多個分割區域;
本實施例中,伺服器可以接收用戶發出的包含待識別字符的理賠單據影像的字符識別請求,例如,接收用戶通過手機、平板電腦、自助終端設備等終端發送的字符識別請求,如接收用戶在手機、平板電腦、自助終端設備等終端中預先安裝的客戶端上發送來的字符識別請求,或接收用戶在手機、平板電腦、自助終端設備等終端中的瀏覽器系統上發送來的字符識別請求。
伺服器在收到待識別字符識別的理賠單據影像後,按照該理賠單據框架格式的框線排布進行區域分割,理賠單據影像中按照其框架格式排布有橫向或豎向的框線,以組成各項輸入欄供用戶填寫相關信息。本實施例中,按照該理賠單據框架格式的框線排布進行區域分割,獲得一個或多個分割區域。例如,在一種實施方式中,由於一般不同類型的保險均對應有不同的單據格式模板,因此,可預先根據用戶上傳的單據類型(可能不同的保險有不同的單據格式),獲取到對應的單據模板,然後根據模板的格式來分割。如可根據收到的待識別字符的理賠單據影像的單據類型,找到該理賠單據影像對應的單據模板,然後根據其對應的單據模板進行區域分割。該分割區域是由該理賠單據框架格式的框線所圍成的最小單位的區域,且該分割區域為不包含框線的區域,以避免後續在對每一分割區域進行字符識別時框線對識別精度的幹涉及影響,該分割區域類似於excel表格的每個方格,excel表格的每個方格即是最小區域內不包含框線的區域。
識別模塊02,用於調用預先確定的分析模型對獲得的各個分割區域進行分析,並利用預先確定的識別規則對分析出的各個分割區域分別進行字符識別,以識別出各個分割區域中的字符。
在按照該理賠單據框架格式的框線排布對理賠單據影像進行區域分割得到一個或多個分割區域後,可調用預先確定的分析模型對獲得的各個分割區域進行分析,並利用預先確定的識別規則對各個分割區域分別進行字符識別,以識別出各個分割區域中的字符,也即理賠單據影像中的字符。例如,可利用預先確定的分析模型分析各個分割區域所適用的識別模型或識別方式,再根據分析出的結果針對各個分割區域利用適合各個分割區域自身的識別模型或識別方式來進行字符識別,以提高字符識別的準確率。如針對不同的分割區域,可分析出字符識別的方式為利用光學字符識別引擎進行識別,也可以用其他識別引擎或訓練的識別模型來進行識別,在此不做限定。識別出各個分割區域中的字符,還可將各個分割區域中的字符自動填充、錄入至與該理賠單據影像對應的電子理賠單據的各相應輸入欄位中。
本實施例在對理賠單據影像進行字符識別前,按照該理賠單據框架格式的框線排布對其進行區域分割,利用預先確定的識別規則對該理賠單據的各個分割區域分別進行字符識別,以分別識別出各個分割區域中的字符。由於考慮到理賠單據框架格式對識別精度的影響,在進行字符識別前先按照理賠單據框架格式的框線排布進行區域分割,再針對各個分割區域來進行字符識別,避免了在對整個理賠單據影像中的字符進行統一識別時單據中的框線對字符識別的影響及幹涉,能有效提高對理賠單據中字符的識別精度。
進一步地,在上述實施例的基礎上,上述識別模塊02還用於:
調用預先確定的分析模型對獲得的各個分割區域進行分析,以分析出可利用光學字符識別引擎識別的第一分割區域和不可利用光學字符識別引擎識別的第二分割區域;
利用預先確定的光學字符識別引擎對各個所述第一分割區域進行字符識別,以識別出各個所述第一分割區域中的字符,並調用預先確定的識別模型對各個所述第二分割區域進行字符識別,以識別出各個所述第二分割區域中的字符。
本實施例中,在按照該理賠單據框架格式的框線排布進行區域分割得到一個或多個分割區域後,在對獲得的分割區域進行識別之前,還調用預先確定的分析模型對獲得的各個分割區域進行分析,以分析出無需深度識別的第一分割區域和需要深度識別的第二分割區域。例如,以當前自身的識別引擎為ocr字符識別引擎為例進行說明,可將ocr字符識別引擎能正確識別或識別率高的區域作為無需深度識別的區域,即利用當前自身的ocr字符識別引擎即可對該區域的字符進行正確的識別,無需藉助其他識別方式。將ocr字符識別引擎無法識別或識別率低的區域作為需要深度識別的區域,即利用當前自身的ocr字符識別引擎無法對該區域的字符進行正確的識別,需藉助其他識別方式如經訓練過的識別模型來進行字符識別。
在分析出該理賠單據影像中可利用ocr字符識別引擎進行正確識別的第一分割區域和不可利用ocr字符識別引擎識別的第二分割區域之後,即可針對分析出的第一分割區域和第二分割區域採取不同的識別方式進行字符識別。利用預先確定的ocr字符識別引擎對各個所述第一分割區域進行字符識別,以正確識別出各個所述第一分割區域中的字符。調用預先確定的識別模型對各個所述第二分割區域進行字符識別,以正確識別出各個所述第二分割區域中的字符,該預先確定的識別模型可以是針對大量分割區域樣本進行訓練好的識別模型,也可以是比自身的ocr字符識別引擎識別方式更複雜、識別效果更好的識別引擎,在此不做限定。
進一步地,在其他實施例中,所述預先確定的分析模型為卷積神經網絡(convolutionalneuralnetwork,簡稱cnn)模型,所述預先確定的分析模型的訓練過程如下:
a、針對預先確定的理賠單據框架格式,獲取預設數量(例如,50萬個)的基於該理賠單據框架格式的理賠單據影像樣本;
b、對每一個理賠單據影像樣本按照該理賠單據框架格式的框線排布進行區域分割,並確定出各個理賠單據影像樣本中ocr字符識別引擎識別錯誤的第三分割區域和ocr字符識別引擎識別正確的第四分割區域;
c、將所有第三分割區域歸入第一訓練集,將所有第四分割區域歸入第二訓練集;
d、分別從第一訓練集和第二訓練集中提取出第一預設比例(例如,80%)的分割區域作為待訓練的分割區域,並將第一訓練集和第二訓練集中剩餘的分割區域作為待驗證的分割區域;
e、利用提取的各個待訓練的分割區域進行模型訓練,以生成所述預先確定的分析模型,並利用各個待驗證的分割區域對生成的所述預先確定的分析模型進行驗證;
f、若驗證通過率大於等於預設閾值(例如,98%),則訓練完成,或者,若驗證通過率小於預設閾值,則增加理賠單據影像樣本的數量,並重複執行所述步驟a、b、c、d、e,直至驗證通過率大於或等於預設閾值。
本實施例中利用經大量理賠單據影像樣本訓練過的卷積神經網絡模型來進行分割區域分析,能夠準確分析出理賠單據的各個分割區域中可利用ocr字符識別引擎來正確識別字符的第一分割區域和無法利用ocr字符識別引擎來正確識別字符的第二分割區域,以便後續針對第一分割區域和第二分割區域分別採用不同的識別方式來進行準確的字符識別操作,從而提高對理賠單據中字符的識別精度。
進一步地,在其他實施例中,所述預先確定的識別模型為長短期記憶(longshort-termmemory,簡稱lstm)模型,所述預先確定的識別模型的訓練過程如下:
獲取預設數量(例如,10萬)的區域樣本,該區域樣本可以是歷史數據中對若干理賠單據按照其框架格式的框線排布進行區域分割後的分割區域樣本。在一種實施方式中,可統一將分割區域樣本中的字體設置為黑色,背景設置為白色,以便於進行字符識別。並將各個分割區域樣本進行標註,如可將各個分割區域樣本的名稱命名為該分割區域樣本所包含的字符以進行標註。
將預設數量的分割區域樣本按照預設比例(例如,8:2)分為第一數據集和第二數據集,將第一數據集作為訓練集,將第二數據集作為測試集,其中,第一數據集的樣本數量比例大於或者等於第二數據集的樣本數量比例。
將第一數據集送入lstm網絡進行模型訓練,每隔預設時間(例如每30分鐘或每進行1000次迭代),對模型使用第二數據集進行測試,以評估當前訓練的模型效果。例如,在測試時,可使用訓練得到的模型對第二數據集中的分割區域樣本進行字符識別,並將利用訓練得到的模型對分割區域樣本的字符識別結果與該分割區域樣本的標註進行比對,以計算出訓練得到的模型的字符識別結果與該分割區域樣本的標註的誤差。具體地,在計算誤差時,可採用編輯距離作為計算標準,其中,編輯距離(editdistance),又稱levenshtein距離,是指兩個字串之間,由一個轉成另一個所需的最少編輯操作次數。許可的編輯操作包括將一個字符替換成另一個字符,插入一個字符,刪除一個字符,一般來說,編輯距離越小,兩個串的相似度越大。因此,在以編輯距離作為計算標準來計算訓練得到的模型的字符識別結果與該分割區域樣本的標註的誤差時,計算得到的誤差越小,說明訓練得到的模型的字符識別結果與該分割區域樣本的標註的相似度越大;相反,計算得到的誤差越大,說明訓練得到的模型的字符識別結果與該分割區域樣本的標註的相似度越小。
由於該分割區域樣本的標註為該分割區域樣本的名稱也即該分割區域樣本所包含的字符,因此,計算出的訓練得到的模型的字符識別結果與該分割區域樣本的標註的誤差即為訓練得到的模型的字符識別結果與該分割區域樣本所包含的字符之間的誤差,能反映出訓練得到的模型識別出的字符與正確的字符之間的誤差。記錄每一次對訓練的模型使用第二數據集進行測試的誤差,並分析誤差的變化趨勢,若分析測試時的訓練模型對分割區域樣本的字符識別的誤差出現發散,則調整訓練參數如activation函數、lstm層數、輸入輸出的變量維度等,並重新訓練,使測試時的訓練模型對分割區域樣本的字符識別的誤差能夠收斂。當分析測試時的訓練模型對分割區域樣本的字符識別的誤差收斂後,則結束模型訓練,將生成的訓練模型作為訓練好的所述預先確定的識別模型。
本實施例中,針對ocr字符識別引擎無法識別的區域,採用訓練好的lstm模型進行識別,由於lstm模型為經大量分割區域樣本訓練過的,且對分割區域樣本的字符識別的誤差收斂的模型,配合lstm模型自身的長期記憶功能使該lstm模型在識別分割區域中的字符時,能利用模型記住的長期信息如上下文信息等,更加準確地識別出分割區域中的字符,從而進一步提高對理賠單據中字符的識別精度。
需要說明的是,在本文中,術語「包括」、「包含」或者其任何其他變體意在涵蓋非排他性的包含,從而使得包括一系列要素的過程、方法、物品或者裝置不僅包括那些要素,而且還包括沒有明確列出的其他要素,或者是還包括為這種過程、方法、物品或者裝置所固有的要素。在沒有更多限制的情況下,由語句「包括一個……」限定的要素,並不排除在包括該要素的過程、方法、物品或者裝置中還存在另外的相同要素。
通過以上的實施方式的描述,本領域的技術人員可以清楚地了解到上述實施例方法可藉助軟體加必需的通用硬體平臺的方式來實現,當然也可以通過硬體來實現,但很多情況下前者是更佳的實施方式。基於這樣的理解,本發明的技術方案本質上或者說對現有技術做出貢獻的部分可以以軟體產品的形式體現出來,該計算機軟體產品存儲在一個存儲介質(如rom/ram、磁碟、光碟)中,包括若干指令用以使得一臺終端設備(可以是手機,計算機,伺服器,空調器,或者網絡設備等)執行本發明各個實施例所述的方法。
以上參照附圖說明了本發明的優選實施例,並非因此局限本發明的權利範圍。上述本發明實施例序號僅僅為了描述,不代表實施例的優劣。另外,雖然在流程圖中示出了邏輯順序,但是在某些情況下,可以以不同於此處的順序執行所示出或描述的步驟。
本領域技術人員不脫離本發明的範圍和實質,可以有多種變型方案實現本發明,比如作為一個實施例的特徵可用於另一實施例而得到又一實施例。凡在運用本發明的技術構思之內所作的任何修改、等同替換和改進,均應在本發明的權利範圍之內。