一種基於好友圈子的動態微博轉發行為預測系統及方法與流程
2023-10-05 14:29:34 4
本發明涉及社交網絡信息分析領域,主要涉及根據社交網絡用戶行為分析,構建一種動態微博轉發行為預測模型。
背景技術:
隨著WEB2.0理念的普及與相關技術的日益成熟,社交網站如Twitter、Facebook、新浪微博等對人們的生活產生了巨大影響。人們在社交網站中更新狀態或發送廣播,以此來展現自己的生活狀態、發表感想或與朋友們分享信息。社交網站為用戶相互交流、發表意見和觀點提供了非常便利的平臺。對社交網站的用戶行為進行建模和預測對於安全、商業等多個領域具有十分重要的社會意義和應用價值,近年來逐漸得到研究者的重視。
新浪微博是一款為大眾提供娛樂休閒生活服務的信息分享和交流平臺,於2009年8月14日開始內測。截至2014年6月底,我國微博用戶規模為2.75億,用戶之間組成複雜的關注網絡,平均每天發送微博近1億條,信息沿著用戶間的關注關係傳播,形成傳播擴散網絡。用戶轉發是微博中最有效的信息傳播機制,當前轉發預測的研究主要集中在興趣特徵、用戶影響力以及用戶屬性等對轉發行為預測結果的影響。所使用的方法包括基於文本的分析、基於用戶影響力的分析和基於網絡結構的分析等。其中,基於文本的分析主要利用概率主題模型分析文本,根據文本主題與用戶興趣的相似度預測用戶的轉發行為。例如:Xuning Tang等人在《接下來誰將參與?預測黑色網絡社區的參與》(Who will be Participating Next?Predicting the Participation of Dark Web Community)中構建了一個用戶興趣和話題檢測模型(UTD)。在給定已有部分用戶對某個帖子進行回復的條件下,UTD模型通過獲取話題內容和發展趨勢預測哪些用戶會對新的帖子產生興趣;基於用戶影響力分析主要研究用戶在社交網絡中對於其他用戶的影響力,並與影響用戶轉發、評論的行為因素相結合,從而達到預測用戶轉發概率的目的。例如:Weng J等人在《基於主題找到影響力用戶》(TwitterRank:Finding Topic-sensitive Influential Twitterers)中通過用戶影響力評價,幫助用戶迅速找出自己感興趣的信息,從而解決了「微博網絡中朋友過多所導致的信息過載問題」;基於網絡結構的分析主要利用小世界理論、用戶出入度等理論,構建因子圖模型預測用戶的轉發行為。例如:Jing Zhang等人在《誰影響了你?通過社會影響力預測轉發行為》(Who Influenced You?Predicting Re-tweet via social Influence Locality)中研究了基於用戶好友圈子,結合因子圖模型和社會影響力分析的轉發預測方法。
用戶的信息轉發行為是多因素共同作用的結果,但上述現有技術未考慮到用戶行為的複雜性,僅僅集中於一方面預測用戶轉發行為,預測結果並不準確,而且無法評估影響用戶行為的各個特徵的重要性。另外,當前的研究主要集中在網絡靜態特徵對信息傳播的影響,但卻忽視了網絡動態特性的重要作用,造成動態網絡靜態化問題。例如,用戶活躍度具有動態特性,用戶的活躍度隨時間不斷變化,其信息擴散速度和範圍也將隨之改變。因此,在網絡靜態特徵的基礎上,應充分考慮動態因素對信息傳播的影響。由於社交網絡中充斥著海量的信息,挖掘用戶興趣是提高信息轉發預測效果的主要途徑之一,利用LDA主題模型在大文本處理和特徵降維方面的巨大優勢,可以幫助用戶迅速找出自己感興趣的信息。本文重點針對網絡動態特性、用戶行為表徵以及用戶特徵重要性評定等問題,引入並優化LDA主題模型,對用戶行為進行建模分析,並採用時間離散化及時間切片方法,增強LDA模型對動態用戶特徵的處理能力,動態監測用戶活躍度,提高轉發預測的準確度。
技術實現要素:
本發明針對現有技術存在的問題:針對信息傳播中網絡動態特性、用戶行為表徵以及用戶特徵重要性評定等問題,提出了一種有效估計消息是否能獲得轉發及其轉發規模、及早發現可能引發大規模爆發的微博的基於好友圈子的動態微博轉發行為預測系統及方法。本發明的技術方案如下:
一種基於好友圈子的動態微博轉發行為預測系統,包括用戶行為數據源獲取模塊,用於獲取社交網絡中的用戶關係和用戶行為數據,將發文用戶的粉絲作為備選用戶,其還包括屬性提取模塊、模型構建模塊及預測分析模塊,其中,所述屬性提取模塊分別從用戶間興趣差異、備選用戶的活躍度以及發文用戶的影響力三方面提取相關屬性向量作為預測模型的輸入;微博轉發行為預測模型構建模塊,用於對備選用戶構建微博轉發行為預測模型,轉發行為主要受備選用戶與其好友的興趣差異τ、備選用戶在文章發布時段的活躍度s和其好友的網絡影響力r參數決定,並對以上模型參數進行擬合;預測分析模塊用於將擬合後獲得的參數和任一時刻t的用戶發文情況進行備選用戶是否會轉發該條微博的預測。
進一步的,所述屬性提取模塊針對用戶間興趣差異,提取用戶興趣向量包括:利用用戶的關注行為屬性,獲取每個用戶的關注列表,定義用戶v的興趣向量為其中,ev,u表示用戶v關注列表中的用戶,u=1,2......|Ev|,|Ev|表示用戶v關注列表中的用戶總數。
進一步的,所述屬性提取模塊針對備選用戶的活躍度,提取用戶狀態向量包括:利用用戶的交互行為屬性和時間屬性,獲取每個用戶在一段時間內的用戶發布微博活躍度及轉發微博活躍度,定義用戶v的活躍度狀態向量為其中,表示用戶v在時間片t上的發布微博活躍度,表示用戶v在時間片t上的轉發微博活躍度,和分別代表用戶v在時間片t上的發布微博數、轉發微博數以及用戶v平均每天發布微博數。
進一步的,所述屬性提取模塊針對發文用戶的影響力,提取用戶特徵向量包括:利用網絡拓撲結構屬性,獲取每個用戶節點的出度、入度和局部聚集係數,定義用戶v的影響力特徵向量為其中,dv,1表示用戶v的粉絲數,dv,2表示用戶v的好友數,表示用戶v的局部聚集係數,Ngv是節點v的鄰居節點集合,edgij是它的相鄰結點之間的連接。
進一步的,所述微博轉發行為預測模型從用戶間興趣差異、備選用戶活躍度以及發文用戶影響力三方面,對於用戶間興趣差異方面,從用戶行為和用戶關係信息中提取用戶的興趣向量,利用LDA模型訓練所有用戶,獲取用戶的興趣主題分布;對於備選用戶活躍度方面,從用戶行為和時間信息中提取各個時間片上的用戶的狀態向量,針對用戶狀態向量中的元素是連續值,使用高斯分布改進LDA,再利用改進的LDA模型訓練所有用戶,獲取用戶在各個時間片上的活躍狀態分布;對於發文用戶影響力方面,從網絡結構信息中提取用戶的特徵向量,同上述用戶狀態向量一樣,使用高斯分布改進LDA,再利用改進的LDA模型訓練所有用戶,獲取用戶的網絡角色分布;最後根據用戶間興趣是否一致、備選用戶在各個時間片上所處的活躍狀態、發文用戶的網絡角色以及用戶的歷史轉發數據訓練整個預測模型,得到用戶轉發行為的多項分布。
進一步的,所述微博轉發行為預測模型獲取用戶的興趣主題分布還包括:在用戶關係網絡的基礎上再利用用戶之間的交互行為,對用戶的興趣向量I(v)進行加權得到加權用戶興趣向量為其中,wv,n表示用戶v發生第n次交互行為的交互對象,n=1,2......Nv,Nv為用戶v交互總次數,再利用LDA模型訓練所有用戶,便可得到用戶的興趣主題分布。
進一步的,所述獲取用戶在各個時間片上的活躍狀態分布還包括:針對用戶發布活躍度xv,t,1和轉發活躍度xv,t,2是連續變量,使用高斯分布改進LDA模型,使得發布活躍度和轉發活躍度的取值分別服從不同的高斯分布:其中,xv,t,m表示用戶v在時間片t上的第m個屬性值,μs,m和σs,m分別是用戶活躍狀態為s時第m個屬性的均值和標準差。
進一步的,通過時間切片方法,將每天從夜間0點開始切割成4個時段,即t=1,2,3,4,將用戶的活躍狀態分為三個等級,即非常活躍、一般活躍和不活躍,利用改進的LDA模型訓練所有用戶,便可得到用戶在各個時間片上的活躍狀態分布。
進一步的,基於網絡拓撲結構將用戶節點分為三種角色類型,即意見領袖、信息傳播者和普通用戶,同樣,使用高斯分布改進LDA模型後,利用此模型訓練所有用戶,便可得到用戶的網絡角色分布。
一種基於所述系統的好友圈子的動態微博轉發行為預測方法,其包括以下步驟:
獲取社交網絡中的用戶關係和用戶行為數據,將發文用戶的粉絲作為備選用戶;分別從用戶間興趣差異、備選用戶的活躍度以及發文用戶的影響力三方面獲取三個用戶向量作為預測模型的輸入;
構建微博轉發行為預測模型,並對模型參數進行擬合;
將擬合後獲得的參數和任一時刻t的用戶發文情況輸入到預測模型進行備選用戶是否會轉發該條微博的預測。
本發明的優點及有益效果如下:
本發明提出了一種基於好友圈子的動態微博轉發行為預測方法。首先,針對單個用戶興趣、活躍度和影響力的多樣性,利用LDA主題模型可解決「一詞多義,多詞一義」的基礎思想和方法,對用戶行為進行建模分析,得到關於用戶行為的主題分布;其次,考慮到用戶狀態向量和用戶特徵向量中的元素是連續值,使用高斯分布改進LDA,以發現用戶的活躍度和影響力;最後,針對用戶的活躍度隨時間的變化,利用時間離散化及時間切片方法,提出一種改進的LDA動態微博轉發行為預測模型,動態監測用戶的活躍度,提高預測模型的準確度。
本發明針對信息傳播中網絡動態特性、用戶行為表徵以及用戶特徵重要性評定等問題,提出了一種基於好友圈子的動態微博轉發行為預測方法,能夠對用戶轉發行為做出準確的預測。根據預測結果,能夠有效估計消息是否能獲得轉發及其轉發規模,及早發現可能引發大規模爆發的微博,對微博突發性檢測和微博影響力評估具有重要意義。
附圖說明
圖1是本發明提供優選實施例基於好友圈子的動態微博轉發行為預測方法總體流程圖;
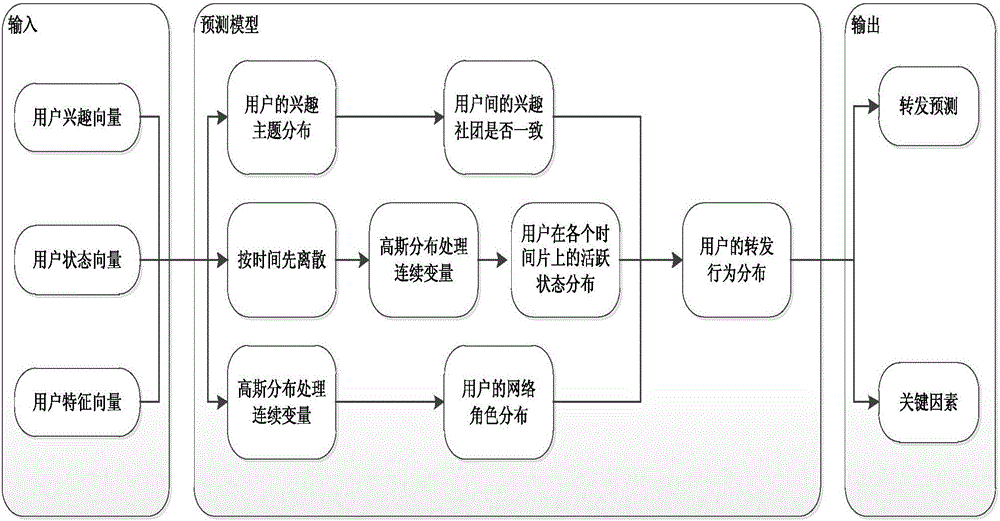
圖2是本發明的預測模型框圖;
圖3是本發明的預測模型流程圖。
具體實施方式
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、詳細地描述。所描述的實施例僅僅是本發明的一部分實施例。
本發明解決上述技術問題的技術方案是,
由於社交網絡中的信息傳播主要受興趣差異、用戶歷史行為和網絡結構推動,因此本發明分別從用戶興趣、活躍度和影響力三個方面出發,利用LDA主題模型的基礎思想和方法,對用戶行為進行建模分析,得到關於用戶行為的主題分布;其次,針對用戶屬性中存在連續變量的問題,使用高斯分布改進LDA,以發現用戶的活躍度和影響力;最後,針對用戶的活躍度隨時間的變化,利用時間離散化及時間切片方法,提出一種改進的LDA動態微博轉發行為預測模型,使其能夠動態監測用戶的活躍度,準確的預測用戶的轉發行為並發現影響用戶轉發的關鍵因素。
具體表述為:給定一個社交關係網絡G=(V,E,Y)。其中,V表示網絡中的所有用戶,|V|=N表示用戶的數量;E表示所有用戶之間的關係,是一個N×N維的矩陣;Y表示用戶的一系列過往行為,|Y|=I表示用戶行為數據總數。設計一個概率生成模型,利用社交網絡中的用戶關係和用戶行為信息,並加入時效性因素的影響,對每個用戶進行分析,通過4個概率生成過程得到每個用戶的興趣分布、活躍等級分布、網絡角色分布以及用戶轉發行為的分布,依據這4個分布對一段時間內用戶對其關注好友微博的轉發行為進行預測。
如圖1所示為本發明的總體流程圖,主要包括:獲取數據模塊,提取屬性模塊,構建模型模塊,預測分析模塊共四大模塊。
以下具體說明本發明的詳細實施過程。
S1:獲取數據源。獲取的數據具體包括用戶關注關係網絡和網絡中所有用戶的用戶行為信息,用戶行為包括用戶過往發布和轉發的微博,以及發布和轉發微博的時間。具體可採用如下方法(也可採用現有技術的常規方法獲取):
S11:獲取原始數據。獲取一個用戶關注關係網絡和該網絡下的所有用戶的過往行為數據。通過社交網絡公共API或直接下載現有數據源都可以得到原始數據,也可結合網絡爬蟲等方法補充數據。
S12:簡單的數據清洗。通過簡單的數據清洗可以使大部分數據利於分析。例如,刪除重複數據、清理無效節點等。
S13:對數據進行時間分片,確定用戶在各個時間片上的屬性。這裡的用戶屬性具體指用戶的發布活躍度和轉發活躍度。由於用戶的轉發行為與其作息時間密切相關,根據用戶的生活作息特點,將一天以預定時間(如6個小時)為一個時間段進行時間分片。在某個時間段t裡,根據用戶屬性確定此時段內用戶的活躍狀態,以預測用戶是否會轉發其好友的微博。
S2:提取相關屬性。考慮社交網絡中的轉發行為主要從興趣差異、用戶歷史行為以及網絡結構三方面,本發明分別從用戶興趣、活躍度和影響力三個方面出發來提取相關屬性,如關注行為屬性、交互行為屬性、時間屬性和網絡結構屬性。其屬性可根據數據方面的特徵對其進行適當修改。
提取完以上三方面的各個屬性後,獲取相應的用戶向量。其具體方式如下。
S21:提取用戶興趣向量。考慮到用戶對自己感興趣的用戶關注,利用用戶的關注行為屬性,獲取每個用戶的關注列表,定義用戶v的興趣向量為:
其中,ev,u(u=1,2......|Ev|)表示用戶v關注列表中的用戶,|Ev|表示用戶v關注列表中的用戶總數。例如:用戶a關注列表中的用戶有:b,c,d,e......,則用戶a的興趣向量為I(a)=[b,c,d,e......]。
S22:提取用戶狀態向量。根據用戶的生活作息特點,將一天以預定時間(如6個小時)為一個時間段進行時間分片,利用用戶的交互行為屬性和時間屬性,獲取每個用戶在各個時間片內的發布微博活躍度及轉發微博活躍度,定義用戶v的狀態向量為:
其中,表示用戶v在時間片t上的發布微博活躍度,表示用戶v在時間片t上的轉發微博活躍度。和分別代表用戶v在時間片t上的發布微博數、轉發微博數以及用戶v平均每天發布微博數。例如:用戶a在第1時間片上發布了3條微博,其中轉發微博為2條,而用戶a平均一天發布5條微博,則用戶a的行為向量為
S23:提取用戶特徵向量。由於用戶節點在網絡中的位置對信息傳播有重大影響,利用網絡拓撲結構屬性,獲取每個用戶節點的出度、入度和局部聚集係數,定義用戶v的特徵向量為:
其中,dv,1表示用戶v的粉絲數,dv,2表示用戶v的好友數,表示用戶v的局部聚集係數。Ngv是節點v的鄰居節點集合,edgij是它的相鄰結點之間的連接。例如:用戶a擁有30個粉絲,20個好友,鄰居節點共有40個,其鄰居節點之間存在200個連接邊,則用戶a的特徵向量為
S3:建立預測模型,如圖2所示為本發明的預測模型框圖。備選用戶是否會轉發其好友的微博,主要受備選用戶與其好友的興趣差異τ、備選用戶在文章發布時段的活躍度s和其好友的網絡影響力r決定。
預測模型進行備選用戶是否會轉發其好友的某條微博的預測具體包括:對於興趣差異方面,從用戶行為和用戶關係信息中提取用戶的興趣向量I(v),利用LDA模型訓練所有用戶,獲取用戶的興趣社區分布其中,表示用戶v的興趣社區分布,N為用戶總數;對於用戶活躍度方面,從用戶行為和時間信息中提取各個時間片上的用戶的狀態向量L(v,t),針對用戶狀態向量中的元素是連續值,先使用高斯分布改進LDA,再利用改進的LDA模型訓練所有用戶,獲取用戶在各個時間片上的活躍狀態分布其中,表示用戶v在t時間片上的活躍狀態概率分布;對於用戶的網絡影響力方面,從網絡結構信息中提取用戶的特徵向量F(v),同上述用戶狀態向量一樣,使用高斯分布改進LDA,再利用改進的LDA模型訓練所有用戶,獲取用戶的網絡角色分其中,表示用戶v的網絡角色概率分布;最後,根據用戶的興趣社區分布用戶在各個時間片上的活躍狀態分布用戶的網絡角色分布以及用戶的歷史轉發數據Y訓練整個預測模型,得到用戶的轉發行為分布其中,表示當用戶間興趣差異為τ,備選用戶處於活躍狀態s且發文用戶扮演網絡角色r時備選用戶轉發該條微博的概率,表示不轉發的概率。模型的求解和如何預測備選用戶在各個時間片上的轉發行為將在接下來的部分詳細敘述。
如圖3所示為本發明的預測模型流程圖。
S31:獲取用戶的興趣社區分布。
由於好友關係僅表示用戶間具有交互的可能性,不能真實反映兩者信息交互的強度,趨於靜態。為了發現活躍的興趣社區,我們在用戶關係網絡的基礎上再利用用戶之間的交互行為,對用戶的興趣向量I(v)進行交互加權,這裡的交互行為具體指轉發行為,得到加權用戶興趣向量為:
其中,wv,n(n=1,2......Nv)表示用戶v發生第n次交互行為的交互對象,Nv為用戶v交互總次數。例如:用戶a與用戶b發生2次交互,與用戶c發生4次交互......,則用戶a的加權興趣向量為I'(a)=[b,b,c,c,c,c......]。
給定C作為興趣社區數,採用LDA模型訓練所有用戶,具體生成過程如下:
對每一個用戶v:
1、抽樣一個邊分布ξ~Dir(λ),λ是Dirichlet分布的參數;
2、抽樣一個用戶興趣社區分布α是Dirichlet分布的參數;
3、對用戶的每一條邊ev,i:
1)抽樣一個興趣社區
2)抽樣一條邊
其中,表示用戶v的興趣社區分布,表示興趣社區c的邊分布。
在此概率生成模型中,對用戶行為建模實際上是要計算用戶的興趣社區分布以及興趣社區的邊分布對於Φ和ξ的求解,採用Gibbs抽樣,Gibbs抽樣每次迭代估算Φ和ξ的公式如下:
其中,表示用戶v在興趣社區c的概率,C為興趣社區總數,nv,c表示用戶v與處於興趣社區c的關注用戶交互的次數,|Nv|為用戶v與其好友的交互總次數;表示興趣社區c中出現用戶e的概率,|E|為網絡中邊的總數,nc,e表示興趣社區c中用戶e的交互次數,nc為興趣社區c中的交互總次數。
S32:獲取用戶在各個時間片上的活躍狀態分布。
用戶的轉發行為與其作息時間密切相關,每個用戶都有自己相對固定的上網時間,在該時段內,用戶較活躍,發帖轉帖概率較大,而其他時間很少參與話題的傳播。因此,通過時間切片方法,將每天從夜間0點開始切割成4個時段(t=1,2,3,4),對向量數據按時間先離散。其次,針對用戶發布活躍度xv,t,1和轉發活躍度xv,t,2是連續變量,使用高斯分布改進LDA模型,使得發布活躍度和轉發活躍度的取值分別服從不同的高斯分布:
其中,xv,t,m表示用戶v在時間片t上的第m個屬性值,μs,m和σs,m分別是用戶活躍狀態為s時第m個屬性的均值和標準差。
本發明將用戶的活躍狀態設為三個等級S=3,即非常活躍、一般活躍和不活躍。利用改進的LDA模型訓練所有用戶,具體生成過程如下:
對每一個用戶v:
1、抽樣一個用戶在時間片t上的活躍狀態分布β是Dirichlet分布的參數;
2、抽樣一個活躍等級
3、對用戶v的每一個屬性:
1)抽樣一個屬性值
其中,表示用戶v在時間片t上的活躍狀態分布。
在此概率生成模型中,對用戶狀態屬性建模實際上是要計算用戶在各個時間片上的活躍狀態分布以及用戶各個屬性取值服從的高斯分布N(μ,σ)。對於Θ(t)和μ,σ的求解,採用EM算法,EM迭代估算Θ(t)和μ,σ的過程分為兩步:
E-step:更新
M-step:更新μs,m和σs,m。
其中,表示用戶v在時間片t上活躍狀態為s的概率,S為狀態等級數,M為用戶狀態屬性個數,xv,t,m表示用戶v在時間片t上的第m個屬性值,μs,m和σs,m分別是用戶活躍狀態為s時第m個屬性的均值和標準差。
S33:獲取用戶的網絡角色分布。
節點在網絡中的位置及其所產生的影響對信息傳播效果具有重要影響。本發明基於網絡拓撲結構將用戶節點分為三種角色類型R=3,即意見領袖、信息傳播者和普通用戶。意見領袖擁有較高的入度而信息傳播者擁有較高的出度。
同樣,由於角色屬性中存在連續變量,使用高斯分布改進LDA模型後,利用改進的LDA模型訓練所有用戶,具體生成過程如下:
對每一個用戶v:
1、抽樣一個用戶網絡角色分布ε是Dirichlet分布的參數;
2、抽樣一個網絡角色
3、對用戶v的每一個角色屬性:
1)抽樣一個角色屬性值
其中,表示用戶v的網絡角色分布。
在此概率生成模型中,對用戶角色屬性建模實際上是要計算用戶的網絡角色分布以及用戶各個角色屬性取值服從的高斯分布N(μ',σ')。對於η和μ',σ'的求解,採用EM算法,EM迭代估算η和μ',σ'的過程分為兩步:
E-step:更新
M-step:更新μ'r,h和σ'r,h。
其中,表示用戶v扮演網絡角色r的概率,R為網絡角色個數,H為用戶狀態屬性個數,dv,h表示用戶v的第h個屬性值,μ'r,h和σ'r,h分別是用戶扮演網絡角色r時第h個屬性的均值和標準差。
S34:獲取用戶的轉發行為分布。
根據用戶的興趣社區分布用戶在各個時間片上的活躍狀態分布用戶的網絡角色分布以及用戶的歷史轉發數據Y訓練整個預測模型,得到用戶的轉發行為分布具體生成過程如下:
對每一個用戶轉發行為yi:
1、抽樣一個用戶轉發行為分布ρ~Dir(γ),γ是Dirichlet分布的參數;
2、為備選用戶v抽樣一個興趣社區
3、為發文用戶u抽樣一個興趣社區
4、為備選用戶v抽樣一個活躍狀態
5、為發文用戶u抽樣一個網絡角色
6、抽樣一個用戶轉發行為
其中,表示用戶的轉發行為分布,表示當用戶間興趣差異為τ,備選用戶處於活躍狀態s且發文用戶扮演網絡角色r時備選用戶轉發該條微博的概率,表示不轉發的概率。τ為指示函數,定義如下:
其中,zu,zv分別表示用戶u、v所在的興趣社區。τ=1表示興趣一致,τ=0表示興趣不一致。
在此概率生成模型中,對用戶轉發行為建模實際上是要計算用戶的轉發行為分布對於的求解,採用Gibbs抽樣,Gibbs抽樣每次迭代估算的公式如下:
其中,ni,τ,s,r表示興趣差異為τ、備選用戶活躍狀態為s、發文用戶扮演網絡角色r時,用戶行為yi=1(轉發)或yi=0(不轉發)的次數;I為用戶行為總數,包括不轉發行為;M為用戶狀態屬性個數,H為用戶角色屬性個數。
S4:通過擬合出來的Φ、Θ(t)、η、和用戶好友的任意一條微博,根據擬合的預測模型,計算其轉發概率即可得到預測結果。通過預測到的結果即可分析出用戶會轉發哪些好友的微博,以及影響用戶轉發微博的關鍵因素。
本發明利用社交網絡中的用戶關係和用戶行為數據,將發文用戶的粉絲作為備選用戶,預測備選用戶是否會在一段時間內轉發其好友的微博。首先,針對單個用戶興趣、活躍度和影響力的多樣性,利用LDA主題模型可解決「一詞多義,多詞一義」的基礎思想和方法,對用戶行為進行建模分析,得到關於用戶行為的主題分布;其次,考慮到用戶狀態向量和用戶特徵向量中的元素是連續值,使用高斯分布改進LDA,以發現用戶的活躍度和用戶影響力;最後,針對用戶的活躍度隨時間的變化,利用時間離散化及時間切片方法,提出一種改進的LDA動態微博轉發行為預測模型,動態監測用戶的活躍度,使其能夠準確預測用戶的轉發行為,並分析影響用戶轉發的關鍵因素。
以上這些實施例應理解為僅用於說明本發明而不用於限制本發明的保護範圍。在閱讀了本發明的記載的內容之後,技術人員可以對本發明作各種改動或修改,這些等效變化和修飾同樣落入本發明權利要求所限定的範圍。