一種基於卷積神經網絡的漢字識別方法與流程
2023-10-19 10:51:57 2
本發明涉及圖像處理技術領域,尤其涉及一種基於卷積神經網絡的漢字識別方法。
背景技術:
利用計算機自動識別字符的技術,是模式識別應用的一個重要領域。人們在生產和生活中,要處理大量的文字、報表和文本。為了減輕人們的勞動,提高處理效率,50年代開始探討一般文字識別方法,並研製出光學字符識別器。60年代出現了採用磁性墨水和特殊字體的實用機器。60年代後期,出現了多種字體和手寫體文字識別機,其識別精度和機器性能都基本上能滿足要求。如用於信函分揀的手寫體數字識別機和印刷體英文數字識別機。70年代主要研究文字識別的基本理論和研製高性能的文字識別機,並著重於漢字識別的研究。
文字識別可應用於許多領域,如閱讀、翻譯、文獻資料的檢索、信件和包裹的分揀、稿件的編輯和校對、大量統計報表和卡片的匯總與分析、銀行支票的處理、商品發票的統計匯總、商品編碼的識別、商品倉庫的管理,以及水、電、煤氣、房租、人身保險等費用的徵收業務中的大量信用卡片的自動處理和辦公室打字員工作的局部自動化等。以及文檔檢索,各類證件識別,方便用戶快速錄入信息,提高各行各業的工作效率。
技術實現要素:
本發明要解決的技術問題在於針對現有技術中的缺陷,提供一種基於卷積神經網絡的漢字識別方法。
本發明解決其技術問題所採用的技術方案是:一種基於卷積神經網絡的漢字識別方法,包括以下步驟:
1)採集訓練用的文本圖像;
2)圖像預處理:首先對圖像進行非均勻光照調整,然後將圖像轉換為灰度圖像
3)對預處理的圖像進行特徵提取:
採用Gabor濾波器提取圖像八個方向的Gabor特徵,八個方向分別是0°,22.5°,45°,67.5°,90°,112.5°,135°,157.5°;
其中Gabor濾波器的公式如下所示:
其中,σ=π,M為方向數目,ι表示波長,表示方向;
4)通過訓練獲得最終識別模型:將經過預處理的圖像和經過Gabor特徵提取的圖像一起作為輸入,輸入卷積神經網絡,所述卷積神經網絡結構包括兩層卷積層,一層多卷積層的神經網絡,並在神經網絡的輸入層和隱藏層,均使用Dropout技術;
選取測試識別正確率最高的卷積神經網絡模型,作為最終識別模型;
5)文字識別:對待識別的文本圖像進行如步驟2)的圖像預處理,採用訓練所得的卷積神經網絡模型進行識別,輸出類別,匹配標籤中漢字類別,輸出漢字識別結果。
按上述方案,所述步驟2)中利用公式對圖像進行非均勻光照調整;公式中,I'是進行調整後該點的像素值,C是圖像中心位置的像素值,BG是進行中值濾波後的圖像中該點的像素值,I是原始圖像在該點的像素值。
按上述方案,所述步驟4)中,在神經網絡的輸入層和隱藏層,均使用Dropout技術。
本發明產生的有益效果是:
(1)本發明中,在圖像預處理過程中,調整圖像背景,減少因為光照不均勻,造成的識別錯誤的情況。
(2)本發明中,將提取方向特徵圖作為先驗知識,和原始圖像一起作為輸入層的數據輸入,以增強神經網絡的識別性能,提高了漢字的識別率;且最終模型較小,計算速度快。
附圖說明
下面將結合附圖及實施例對本發明作進一步說明,附圖中:
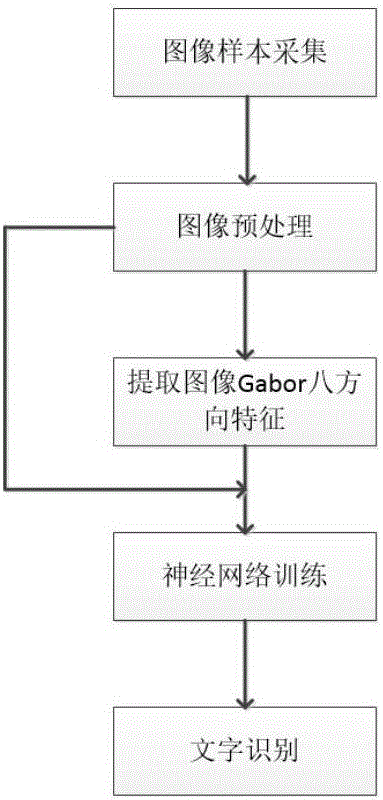
圖1是本發明實施例的方法流程圖;
圖2是本發明實施例的神經網絡的具體結構圖;
圖3是本發明實施例的方法流程圖。
具體實施方式
為了使本發明的目的、技術方案及優點更加清楚明白,以下結合實施例,對本發明進行進一步詳細說明。應當理解,此處所描述的具體實施例僅用以解釋本發明,並不用於限定本發明。
如圖1所示,一種基於卷積神經網絡的漢字識別的方法,包括以下步驟:
1)採集訓練用的的文本圖像;
2)圖像預處理:利用公式對圖像進行非均勻光照調整、將圖像轉換為灰度圖像;公式中,I'是進行調整後該點的像素值,C是圖像中心位置的像素值,BG是進行中值濾波後的圖像中該點的像素值,I是原始圖像在該點的像素值。
3)對預處理的圖像進行特徵提取:
採用Gabor濾波器提取圖像八個方向的Gabor特徵,充分顯示了Gabor濾波器的多分辨性。八個方向分別是0°,22.5°,45°,67.5°,90°,112.5°,135°,157.5°;波長為
其中Gabor濾波器的公式如下所示:
其中,σ=π,M為方向數目,ι表示波長,表示方向;
4)將經過預處理的圖像和經過Gabor特徵提取的圖像一起作為輸入,輸入卷積神經網絡,所述卷積神經網絡結構包括兩層卷積層,一層多卷積層的神經網絡,並在輸入層和隱藏層,均使用Dropout技術。如圖2,本實施例中神經網絡的具體結構如下:
48*48-20C5-MP2-50C5-MP2-96C3-128C3-MP2-3500
48為輸入圖像尺寸;例:20C5中20表示該層特徵圖數量,C表示為該層為卷積層,5表示該層卷積核大小;MP2中,MP表示該層為池化層,2表示該層卷積核大小;3500表示該層為3500類的分類層。
參數調整方法:
根據輸入圖像的數量及電腦配置,調整每批次處理圖片的數量,調整迭代次數。
訓練結束判斷:
當誤差值loss收斂且測試識別正確率出現小範圍波動時,即可停止訓練,選取測試識別正確率最高的模型,作為最終識別模型。
5)文字識別:對待識別的文本圖像進行如步驟2)的圖像預處理,採用訓練所得的卷積神經網絡模型進行識別,輸出類別,匹配標籤中漢字類別,輸出漢字識別結果。
為了驗證本發明,進行了實驗案例的檢測。本文將Gabor特徵提取與原始圖像結合,同時進行卷積神經網絡訓練。將原始圖像直接放入卷積神經網絡進行訓練作為對比實驗1。將梯度特徵和原始圖像結合,同時進行卷積神經網絡訓練,作為對比試驗2。
表1不同特徵提取與神經網絡的識別結果
由表1可知,Gabor特徵有效的反應了漢字的特徵信息,彌補了部分CNN自學習中所丟失的特徵,提升了識別率。
Dropout技術是在模型訓練時隨機讓網絡某些隱含層節點輸出值為零,這種如同在圖像中加入噪聲的方式能防止模型在訓練過程中出現過擬合,提高神經網絡的泛化能力。對於每次輸進來的樣本,由於其Dropout的隨機性,每個樣本對應的網絡結構都不相同,這些不同的網絡結構同時又共享隱含節點的權值,使得不同的樣本對應不同的模型。本文對輸入層和所有的隱藏層都採用了Dropout技術。如圖3所示,深色的神經元表示被隨機選為Dropout的節點單位。
為了研究在不同網絡層上進行Dropout的效果,本發明設置如下實驗:
以0.4作為Dropout率,分別在輸入層,隱藏層,以及輸入層和隱藏層進行Dropout,實驗結果如表2所示
表2為在不同層使用dropout的結果
當同時對輸入層和所有的隱藏層使用Dropout技術時,效果比僅僅在輸入層或僅僅在隱藏層使用Dropout要好,相比於沒有使用Dropout的網絡,準確率大約高出3%。為了最大限度地優化網絡的泛化性能,本發明對輸入層和所有的隱藏層使用Dropout技術。
綜上所述,本發明將Gabor特徵提取與原始圖像放入輸入層和隱藏層均使用Dropout技術的神經網絡中訓練,得到了98.2%的識別率。
應當理解的是,對本領域普通技術人員來說,可以根據上述說明加以改進或變換,而所有這些改進和變換都應屬於本發明所附權利要求的保護範圍。