基於DIA技術探究和分析不同民族人乳中差異蛋白的方法與流程
2024-04-16 04:12:05 4
基於dia技術探究和分析不同民族人乳中差異蛋白的方法
技術領域
1.本發明屬於乳品技術領域,具體涉及一種基於數據非依賴採集的蛋白組學技術(dia)對採集的不同民族的人乳進行蛋白組成和含量差異性比較分析的方法。
背景技術:
2.母乳是嬰兒最天然、最理想的食物,為新生兒提供生長發育所必需的營養,並增強抵抗力。在這種情況下,作為母乳替代物,嬰幼兒配方粉的科學設計和研發具有重要的意義。
3.為使嬰幼兒能夠獲得更接近母乳的營養成分,國內外相關研究機構長期深入探索母乳組分,試圖找到最符合母乳的營養均衡型嬰幼兒配方乳粉。我國在母乳研究營養成分上取得了一定的研究成果,相關機構紛紛建立了中國母乳營養成分資料庫,但仍存在樣本地域碎片化、樣本分析常規化的不足。我國人口眾多、地域遼闊、膳食多樣,如何利用現代技術詳盡地分析中國母乳功能組分,將常規母乳營養素研究擴展到更加細微的母乳成分研究顯得至關重要。我國東北朝鮮族、西北地區等母乳研究較少,對母乳的蛋白質組學研究也較少。而相關研究表明,母乳成分受種族、飲食等多種因素影響。因此,探究不同民族人乳之間的營養成分的差異性,並開發針對性的嬰配粉具有重要意義。
4.乳主要包括乳蛋白、乳糖和乳脂等多種營養成分,其中乳蛋白質是最重要的組成成分。乳蛋白質可以為新兒和哺乳動物提供氮、酶、激素及免疫物質等,對其健康成長有重要的作用。乳中含有種類多樣、含量豐富的蛋白質,由於遺傳變異和翻譯後修飾對乳蛋白的影響,使乳蛋白的組成變得複雜、龐大。其中酪蛋白(cn)、乳清蛋白(wp)和乳脂球膜蛋白(mfgm)是乳蛋白的重要組成部分。蛋白質組學是研究蛋白組的一個新的領域,主要研究蛋白質的特性,包括蛋白質表達水平、胺基酸序列、翻譯後加工和蛋白質相互作用,在蛋白質水平上了解細胞的各項功能、各種生理生化過程以及疾病的病理過程等。
5.採用蛋白質組學等技術對中國東北延邊地區的朝鮮族和漢族人乳進行詳細的分析和比較,探索民族差異對母乳中營養成分的影響,建立特色人群母乳資料庫,為開發更加接近特定人群母乳營養成分及功效的嬰幼兒配方奶粉提供依據,未來將有更多的嬰幼兒受惠於針對性母乳資料庫。
技術實現要素:
6.本發明所要解決的技術問題是針對蛋白種類繁多的我國不同民族的母乳,提供一種通過對樣品進行高速分離得不同的乳清蛋白層、酪蛋白層和乳脂肪球膜蛋白層,並採用dia技術對蛋白進行高通量分析的方法。為了達到上述技術效果,本發明包括以下技術方案:
7.一種基於dia技術探究和分析不同民族人乳中差異蛋白的方法,有以下步驟:
8.步驟1:樣品採集
9.採集不同民族新鮮母乳,每例30毫升放入50毫升的無菌離心管中,並貼上標籤,獲
得的樣品立即放置在-80℃的冰箱中儲存,同一民族隨機6~10個樣品混合成一個混合樣品,每個民族收集至少三個平行的混合樣本進行生物學重複;
10.步驟2:乳清蛋白提取和分離
11.將蛋白酶抑制劑加入母乳樣品,取12ml母乳樣品裝入15ml離心管;4℃,3000rpm,離心30min分層,最上層為脂肪層,貼掛側管壁,輕柔倒出下層脫脂奶液至新管,留脂肪層於原離心管中;磷酸緩衝液(pbs)衝洗脂肪層5次,4℃存放待用;脫脂奶液取1ml用10%乙酸調節溶液ph值至4.6,用於酪蛋白析出,4℃,10000rpm,離心15min,使乳清蛋白與酪蛋白分離;
12.乳清蛋白沉澱:在乳清蛋白與酪蛋白分離後,取上清液,加入4倍體積預冷丙酮,-20℃過夜,沉澱用預冷丙酮清洗3次,得到乳清蛋白沉澱,吹乾備用;
13.酪蛋白沉澱:在乳清蛋白與酪蛋白分離後,除去上清液,沉澱即為酪蛋白,預冷丙酮清洗3次,吹乾備用;
14.脂肪蛋白提取:在母乳樣品進行離心分離後得到的脂肪層中加入3倍體積甲醇,渦旋震蕩,至脂肪層破碎懸浮於甲醇,4℃,9000g,離心10s;除去上清液,加入體系2倍體積的氯仿,渦旋震蕩,至沉澱懸浮於氯仿;向體系中加入體系3倍體積去離子水,混勻,4℃,9000g,離心1min,溶液分三層,下層為氯仿,中間層為蛋白層,將上清液移除,向剩餘體系中加入3倍體積甲醇,混勻,4℃,9000g,離心2min;除上清,將沉澱用甲醇洗滌2次,吹乾,沉澱即為脂肪蛋白;
15.步驟3:過濾輔助樣品製備(fasp)酶解
16.基於過濾輔助樣品製備(fasp)方法,對100μg蛋白質樣品進行蛋白質酶水解,所述的蛋白質樣品是步驟2中分離出的乳清蛋白、酪蛋白、脂肪蛋白的一種,向蛋白質樣品中添加8m尿素,使總體積達到200μl,加入二硫蘇糖醇(dtt)至體系中dtt最終濃度為10mm,並使混合物在56℃下靜置30分鐘,添加碘乙酸(iaa)至碘乙酸的終濃度為50mm,並在室溫下無光反應40min,將樣品轉移到10k超濾管中,然後在室溫下以12000g離心,棄掉濾液,並重複該步驟三次,添加200μl濃度為50mm的碳酸氫銨溶液,然後在室溫下以12000g離心,丟棄濾液,並重複該步驟3次,將胰蛋白酶以樣品:酶=50:1的質量比添加到試管中,並在37℃下酶解16小時,通過在12000g、4℃下離心獲得多肽樣品,然後冷凍乾燥;
17.步驟4:建庫樣本準備
18.酶解後的多肽樣品在色譜儀中進行high ph反相色譜分級,柱子在初始條件下平衡5min,柱流速維持0.4ml/min;隨後柱流速增至0.7ml/min,使用1.5ml ep管,每1分鐘接收1管;
19.步驟5:dda建庫數據採集
20.另取酶解後的多肽樣品經由軌道阱質譜儀進行分析;共上樣18μl,以60/120min梯度分離:3%溶液b至100%溶液b;柱流量控制在600nl/min;所述溶液b為98%acn,2%ddh2o,ph10;
21.軌道阱質譜儀在數據依賴採集模式下運行,質譜參數設置如下:(1)msn1:掃描範圍(m/z):375-1500;解析度:120,000;agctarget:4e5;最大注入時間:50ms;(2)msn2:解析度:15,000;agctarget=5e4;最大注入時間:22ms;碰撞能量:30%;將獲得的質譜數據用proteome discoverer 2.1.0182進行蛋白質分析,最終獲得dda參考譜圖庫;數據處理參數為:搜庫引擎採用sequestht;蛋白質資料庫用uniprottaxid:9606;設置胰蛋白酶酶解;最
大允許漏切位點設為2;肽段水平的假陽性率(fdr)設置為1%;肽和片段質量誤差分別設置為
±
10ppm和
±
0.02da;
22.步驟6:dia進行生物樣本定量數據採集
23.另取步驟3中的多肽樣品經由軌道阱質譜儀進行分析;共上樣18μl,以60/120min梯度分離:3%溶液b至100%溶液b;柱流量控制在600nl/min;
24.軌道阱質譜儀在數據依賴採集模式下運行,質譜參數設置如下:(1)msn1:掃描範圍(m/z):350-1500;解析度:60,000;agctarget:4e5;最大注入時間:50ms;(2)msn2:解析度:30,000;agctarget=3e5;最大注入時間:54ms;碰撞能量:33%;
25.用skyline軟體進行dia分析,通過導入步驟5所得的dda參考譜圖庫,對dia原始數據進行多肽信號提取與定量分析,設置參數為:多肽長度選6-25;子離子m/z要求為大於母離子且last ion-3;子離子最大數目設為5;子離子最小數目設為2;子離子抽提窗口採用5min;dotp需要大於等於0.6;
26.步驟7:差異表達蛋白質篩選
27.將符合fc》1.5或《0.67,且pvalue《0.05的蛋白設定為差異表達蛋白,並進行go和kegg功能富集分析和蛋白互作分析。
28.有益效果:
29.1、本發明首次從不同民族的人乳差異性出發,系統化研究其蛋白組成和含量的差異性。
30.2、本發明採用高速分離的方法得到乳清蛋白、乳脂肪球膜蛋白以及酪蛋白三層。
31.3、本發明採用dia技術對朝鮮族和漢族母乳中的乳蛋白進行系統化、高通量的研究,並進行比較分析,鑑定出的總蛋白種類多,能全面的獲得不同民族之間人乳蛋白的差異,為開發針對我國特定人群的創新性嬰幼兒配方食品提供技術支持和新的研發思路。
附圖說明
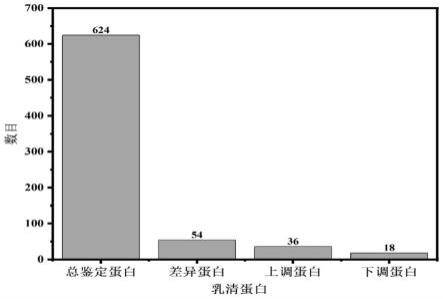
32.圖1是乳清蛋白總鑑定蛋白及差異蛋白。
33.圖2是乳清蛋白中差異蛋白的go富集分析。
34.圖3是乳清蛋白中差異蛋白的kegg富集分析。
35.圖4是酪蛋白總鑑定蛋白及差異蛋白。
36.圖5是酪蛋白中差異蛋白的go富集分析。
37.圖6是酪蛋白中差異蛋白的kegg富集分析。
38.圖7是乳脂肪球膜蛋白總鑑定蛋白及差異蛋白。
39.圖8是乳脂肪球膜蛋白中差異蛋白的go富集分析。
40.圖9是乳脂肪球膜蛋白中差異蛋白的kegg富集分析。
具體實施方式
41.下面將通過具體的實施例對本發明做進一步的詳細描述。
42.實施例1:樣品採集及蛋白質分離
43.步驟1:樣品採集
44.根據初步調查問卷,從吉林省延邊自治州選擇18名朝鮮族哺乳期母親,在採集樣
本前仔細清潔乳暈和乳頭數次,然後用無菌水衝洗相關部位。輕輕地擠出母乳,丟棄第一滴,然後將大約30毫升的母乳放入50毫升的無菌離心管中,並貼上標籤。獲得的樣品立即放置在-80℃的冰箱中,然後通過冷鏈運輸運送到實驗室。每6個樣品混合成一個混合樣,得到3個平行樣本;用於後續做三個平行樣的生物學重複測定;
45.用同樣的步驟得到漢族母乳的3個平行樣本。
46.將蛋白酶抑制劑加入母乳樣品,取12ml母乳樣品裝入15ml離心管;4℃,3000rpm,離心30min分層,最上層為脂肪層,貼掛側管壁,輕柔倒出下層脫脂奶液至新管,留脂肪層於原離心管中;磷酸緩衝液(pbs)衝洗脂肪層5次,4℃存放待用;脫脂奶液取1ml用10%乙酸調節溶液ph值至4.6,用於酪蛋白析出,4℃,10000rpm,離心15min,使乳清蛋白與酪蛋白分離;
47.乳清蛋白沉澱:在乳清蛋白與酪蛋白分離後,取上清液,加入4倍體積預冷丙酮,-20℃過夜,沉澱用預冷丙酮清洗3次,得到乳清蛋白沉澱,吹乾備用;
48.酪蛋白沉澱:在乳清蛋白與酪蛋白分離後,除去上清液,沉澱即為酪蛋白,預冷丙酮清洗3次,吹乾備用;
49.脂肪蛋白提取:在母乳樣品進行離心分離後得到的脂肪層中加入3倍體積甲醇,渦旋震蕩,至脂肪層破碎懸浮於甲醇,4℃,9000g,離心10s;除去上清液,加入體系2倍體積的氯仿,渦旋震蕩,至沉澱懸浮於氯仿;向體系中加入體系3倍體積去離子水,混勻,4℃,9000g,離心1min,溶液分三層,下層為氯仿,中間層為蛋白層,將上清液移除,向剩餘體系中加入3倍體積甲醇,混勻,4℃,9000g,離心2min;除上清,將沉澱用甲醇洗滌2次,吹乾,沉澱即為脂肪蛋白;
50.實施例2乳清蛋白的差異性分析
51.基於過濾輔助樣品製備(fasp)方法,對實施例1得到的乳清蛋白質樣品(100μg)進行蛋白質酶水解,向樣品中添加8m尿素,使其體積達到200μl。引入二硫蘇糖醇(dtt)至最終濃度為10mm,並使混合物在56℃下靜置30分鐘。將碘乙酸(iaa)添加到50mm的最終水平,並在室溫下無光反應40min。將樣品轉移到10k超濾管中,然後在室溫下以12000g離心,棄掉濾液,並重複該步驟三次。添加碳酸氫銨溶液(200μl,50mm),然後在室溫下以12000g離心,丟棄濾液,並重複該步驟3次。將胰蛋白酶以樣品:酶=50:1(質量比)添加到試管中,並在37℃下進行酶解16小時。通過在12000g、4℃下離心獲得肽樣品,然後冷凍乾燥。
52.酶解後的多肽樣品在agilent 1100色譜儀中進行high ph反相色譜分級。柱子在初始條件下平衡5min,柱流速維持0.4ml/min;隨後柱流速增至0.7ml/min,流動相位變化情況為5-5.10min/3%b,5.10-10min/5%b,10-35min/18%b,35-45min/34%b,45-58min/95%b,58-60min/3%b。使用1.5ml ep管,每1分鐘接收1管。
53.另取酶解後的多肽樣品經由orbitrap fusion lumos軌道阱質譜儀進行分析;共上樣18μl,以60min梯度分離:3%溶液b至100%溶液b;柱流量控制在600nl/min;軌道阱質譜儀在數據依賴採集模式下運行,質譜參數設置如下:(1)msn1:掃描範圍(m/z):375-1500;解析度:120,000;agctarget:4e5;最大注入時間:50ms;(2)msn2:解析度:15,000;agctarget=5e4;最大注入時間:22ms;碰撞能量:30%;分級後的建庫dda數據用proteome discoverer 2.1.0182進行蛋白質分析,最終獲得dda參考譜圖庫;相關數據處理參數如下:搜庫引擎採用sequestht;蛋白質資料庫用uniprottaxid:9606);設置胰蛋白酶酶解;最大允許漏切位點設為2;肽段水平的假陽性率(fdr)設置為1%;肽和片段質量誤差分別為
±
10ppm和
±
0.02da。
54.另取酶解後的多肽樣品經由orbitrap fusion lumos軌道阱質譜儀進行分析;共上樣18μl,以60min梯度分離:3%溶液b至100%溶液b;柱流量控制在600nl/min;軌道阱質譜儀在數據依賴採集模式下運行,質譜參數設置如下:(1)msn1:掃描範圍(m/z):350-1500;解析度:60,000;agctarget:4e5;最大注入時間:50ms;(2)msn2:解析度:30,000;agctarget=3e5;最大注入時間:54ms;碰撞能量:33%;用skyline軟體進行dia分析,通過導入上面所得參考譜圖庫,對dia原始數據進行多肽信號提取與定量分析。詳細參數如下:多肽長度選6-25;子離子m/z要求為大於母離子且last ion-3;子離子最大數目設為5;子離子最小數目設為2;子離子抽提窗口採用5min;dotp需要大於等於0.6。
55.上述測定,對每個民族樣本做三個平行樣的生物重複,結果取平均值。
56.對兩個民族的測定結果進行比較,將符合fc》1.5或《0.67,且pvalue《0.05的蛋白設定為差異表達蛋白,並進行功能注釋和蛋白互作分析。
57.差異蛋白列表:
58.圖1以柱狀圖的形式顯示了總鑑定蛋白,差異蛋白的數目。相較於漢族組,朝鮮族母乳樣品中共鑑定到54個差異表達蛋白,其中36個蛋白表達上調,18個蛋白表達下調。上調蛋白中,細胞間粘附分子-1具有最大的fc值5.50,p值為0.0076。它被認為在多種細胞上表達,同時也是許多關鍵生理過程所需的最重要的保守人類受體之一。wap四個二硫核心結構域蛋白2,則是有著第二高的fc值4.72,以及0.04的p值,這表明在兩組之間存在顯著差異。作為wap家族成員之一,它在腫瘤的進展、惡性和轉移中起著重要作用,同時研究表明,它能促進卵巢癌的轉移,並可能成為卵巢癌的潛在治療靶點。下調蛋白中,磷酸丙糖異構酶是差異最大的蛋白質,有著最小的fc值0.03,p值為0.0027。它是糖酵解和糖異生過程中催化磷酸二羥丙酮(dhap)和甘油醛-3-磷酸(g3p)相互轉化的關鍵糖酵解酶。除了催化作用外,它還對所有活細胞的碳水化合物代謝和能量生產起著至關重要的作用。
59.差異蛋白的go富集分析:
60.通過go富集分析分析朝鮮族和漢族母乳之間的差異表達蛋白,結果表明722個go項中共有357個顯著富集(p《0.05)。最顯著富集的前30個go項,包括19個bp,9個cc和2個mf。作為參與蛋白數量最多的項(16),細胞的富集因子為0.007。其p值為最小值2.85e-08,表明它是最顯著富集的go項。通過go富集分析研究了韓國和漢族母乳之間的dep,結果表明,722個go項中共有357個顯著富集(p《0.05)。圖2以氣泡圖的形式顯示了前30個顯著富集的go項,包括19bp、9cc和2mf。作為參與蛋白質數量最多的項(16),細胞內的富集因子為0.007,最小p值為2.85e-08。
61.在54個dep中,rac1參與go富集分析的項數最多,共101項,其次是40s核糖體蛋白s27a(96)和β澱粉樣a4蛋白(95)。
62.差異蛋白的kegg富集分析:
63.採用kegg富集分析研究了朝鮮族和漢族乳清蛋白之間的差異表達蛋白。圖3結果表明,129個kegg途徑中共有58個顯著富集(p《0.05)。涉及6種蛋白質的病毒性心肌炎是最顯著富集的途徑,擁有最小p值4.14e-10,其富集因子為0.1。
64.差異蛋白的蛋白互作網絡分析:
65.通過mcc法挖掘排名前10位的核心蛋白,按分數排序如下:40s核糖體蛋白s27a
(150),60s核糖體蛋白l10a(150),60s酸性核糖體蛋白p2(146),40s核糖體蛋白s4(145),40s核糖體蛋白s18(120),60s核糖體蛋白l35(120),蛋白酶體亞單位α1型(26),肽基脯氨酸順反異構酶(12)、l-乳酸脫氫酶(12)和磷酸丙糖異構酶(11)。
66.實施例3:酪蛋白的差異性分析
67.基於過濾輔助樣品製備(fasp)方法,對實施例1得到的酪蛋白樣品(100μg)進行蛋白質酶水解,向樣品中添加8m尿素,使其體積達到200μl。引入二硫蘇糖醇(dtt)至最終濃度為10mm,並使混合物在56℃下靜置30分鐘。將碘乙酸(iaa)添加到50mm的最終水平,並在室溫下無光反應40min。將樣品轉移到10k超濾管中,然後在室溫下以12000g離心,棄掉濾液,並重複該步驟三次。添加碳酸氫銨溶液(200μl,50mm),然後在室溫下以12000g離心,丟棄濾液,並重複該步驟3次。將胰蛋白酶以樣品:酶=50:1(質量比)添加到試管中,並在37℃下進行酶解16小時。通過在12000g、4℃下離心獲得肽,然後冷凍乾燥。
68.酶解後的多肽樣品在agilent 1100色譜儀中進行high ph反相色譜分級。柱子在初始條件下平衡5min,柱流速維持0.4ml/min;隨後柱流速增至0.7ml/min,流動相位變化情況為5-5.10min/3%b,5.10-10min/5%b,10-35min/18%b,35-45min/34%b,45-58min/95%b,58-60min/3%b。使用1.5ml ep管,每1分鐘接收1管。
69.另取酶解後的多肽樣品經由orbitrap fusion lumos軌道阱質譜儀進行分析;共上樣18μl,以60min梯度分離:0min/3%b,0-2min/8%b,2-46min/28%b,46-55min/50%b,55-56min/100%b,56-60min/100%b。柱流量控制在600nl/min;軌道阱質譜儀在數據依賴採集模式下運行,質譜參數設置如下:(1)msn1:掃描範圍(m/z):375-1500;解析度:120,000;agctarget:4e5;最大注入時間:50ms;(2)msn2:解析度:15,000;agctarget=5e4;最大注入時間:22ms;碰撞能量:30%;分級後的建庫dda數據用proteome discoverer 2.1.0182進行蛋白質分析,最終獲得dda參考譜圖庫;相關數據處理參數如下:搜庫引擎採用sequestht;蛋白質資料庫用uniprottaxid:9606);設置胰蛋白酶酶解;最大允許漏切位點設為2;肽段水平的假陽性率(fdr)設置為1%;肽和片段質量誤差分別為
±
10ppm和
±
0.02da。
70.另取酶解後的多肽樣品經由orbitrap fusion lumos軌道阱質譜儀進行分析;共上樣18μl,以120min梯度分離:0min/3%b,0-2min/7%b,2-92min/22%b,92-107min/40%b,107-110min/100%b,110-120min/100%b。柱流量控制在600nl/min;軌道阱質譜儀在數據依賴採集模式下運行,質譜參數設置如下:(1)msn1:掃描範圍(m/z):350-1500;解析度:60,000;agctarget:4e5;最大注入時間:50ms;(2)msn2:解析度:30,000;agctarget=3e5;最大注入時間:54ms;碰撞能量:33%;用skyline軟體進行dia分析,通過導入上面所得參考譜圖庫,對dia原始數據進行多肽信號提取與定量分析。詳細參數如下:多肽長度選6-25;子離子m/z要求為大於母離子且last ion-3;子離子最大數目設為5;子離子最小數目設為2;子離子抽提窗口採用5min;dotp需要大於等於0.6。
71.上述測定,對每個民族樣本做三個平行樣的生物重複,結果取平均值。
72.對兩個民族的測定結果進行比較,將符合fc》1.5或《0.67,且pvalue《0.05的蛋白設定為差異表達蛋白,並進行功能注釋。
73.差異蛋白列表:
74.圖4以柱狀圖的形式顯示了總鑑定蛋白,差異蛋白的數目。通過比較朝鮮族和漢族
的酪蛋白中所鑑定蛋白質,觀察到39種顯著差異表達的蛋白質,其中有10種蛋白質上調,29種下調。在上調的蛋白質中,補體成分c9的fc最高,為5.74,p值為0.0013,這是兩組之間差異最大的蛋白質。c9是母乳中補體的九種成分之一,在初乳中作為補體系統的防禦因子發揮作用。而在下調的蛋白中,血清轉鐵蛋白的fc值最低,為0.19,p值為0.0045。作為一種鐵結合糖蛋白,它除了能調節體液中的鐵含量外,還與多種疾病有關,如無鐵蛋白血症和心血管疾病。同時血清轉鐵蛋白及其受體的特性可以被用來向腦和癌細胞輸送藥物。
75.差異蛋白的go富集分析:
76.通過go富集分析分析朝鮮族和漢族母乳之間的差異表達蛋白,結果表示545個go項中共有125個顯著富集(q《0.05)。圖5以氣泡圖的形式顯示了前30個顯著富集的go項,其中bp的對刺激反應(7),cc的細胞與外細胞器(8),mf的作用於l-胺基酸肽的肽酶活性(3)和肽酶活性(3)分別是涉及蛋白數目最多的項。血液微粒是最富集的go項,其富集因子為0.235,具有最小q值2.58e-06。經驗細胞凋亡過程的負調控(2)則具有最高的富集因子0.33。該項涉及的蛋白質為纖維蛋白原α鏈和纖維蛋白原γ鏈。纖維蛋白原是一種豐富的血漿糖蛋白,由α、β和γ鏈組成。纖維蛋白原是止血的關鍵分子之一。凝血酶介導的纖維蛋白肽從纖維蛋白原中釋放,將這種可溶性蛋白轉化為纖維蛋白纖維網絡,形成血栓的構建塊。纖維蛋白原除了參與凝血,還參與炎症、細胞遷移和腫瘤發生。
77.差異蛋白的kegg富集分析:
78.對於kegg富集分析,圖6結果表明113個kegg途徑中共有35個被顯著富集(q《0.05)。金黃色葡萄球菌的富集因子為0.103,並且擁有最小q值為1.03e-10,是最富集的途徑。而涉及蛋白質數量最多的途徑是金黃色葡萄球菌感染和補體和凝血級聯,這二者均涉及7種蛋白質。非洲錐蟲病則是有最大富集因子0.135。
79.差異蛋白的蛋白互作網絡分析:
80.差異表達蛋白的蛋白互作網絡分析顯示存在23個節點和47條邊,表明有23個差異表達蛋白參與了47種相互作用。在這23種蛋白中,19個蛋白表達下調,4個蛋白表達上調。纖維蛋白原α鏈與9種差異蛋白存在相互作用,是相互作用最多的蛋白質。
81.通過mcc法挖掘排名前10位的核心蛋白,按分數排序如下:纖維蛋白原α鏈(1442),補體成分c9(1442),纖溶酶原(1441),血清轉鐵蛋白(1441),纖維蛋白原γ鏈(1440),cdna flj35730 fis(1440),補體c3(724),α-2-巨球蛋白(721),cd59糖蛋白(5),聚合免疫球蛋白受體(4)。
82.實施例4:脂肪蛋白的差異性分析
83.基於過濾輔助樣品製備(fasp)方法,對實施例1得到的脂肪蛋白樣品(100μg)進行蛋白質酶水解,向樣品中添加8m尿素,使其體積達到200μl。引入二硫蘇糖醇(dtt)至最終濃度為10mm,並使混合物在56℃下靜置30分鐘。將碘乙酸(iaa)添加到50mm的最終水平,並在室溫下無光反應40min。將樣品轉移到10k超濾管中,然後在室溫下以12000g離心,棄掉濾液,並重複該步驟三次。添加碳酸氫銨溶液(200μl,50mm),然後在室溫下以12000g離心,丟棄濾液,並重複該步驟3次。將胰蛋白酶以樣品:酶=50:1(質量比)添加到試管中,並在37℃下進行酶解16小時。通過在12000g、4℃下離心獲得肽,然後冷凍乾燥。
84.酶解後的多肽樣品在agilent 1100色譜儀中進行high ph反相色譜分級。柱子在初始條件下平衡5min,柱流速維持0.4ml/min;隨後柱流速增至0.7ml/min,流動相位變化情
況為5-5.10min/3%b,5.10-10min/5%b,10-35min/18%b,35-45min/34%b,45-58min/95%b,58-60min/3%b。使用1.5ml ep管,每1分鐘接收1管。
85.另取酶解後的多肽樣品經由orbitrap fusion lumos軌道阱質譜儀進行分析;共上樣18μl,以60min梯度分離,流速為0.60ml/min。梯度洗脫方法為:0min/3%b,0-2min/8%b,2-46min/28%b,46-55min/50%b,55-56min/100%b,56-60min/100%b。樣品採用1.5ml ep管採集,間隔1min。軌道阱質譜儀在數據依賴採集模式下運行,質譜參數設置如下:(1)msn1:掃描範圍(m/z):375-1500;解析度:120,000;agctarget:4e5;最大注入時間:50ms;(2)msn2:解析度:15,000;agctarget=5e4;最大注入時間:22ms;碰撞能量:30%;分級後的建庫dda數據用proteome discoverer 2.1.0182進行蛋白質分析,最終獲得dda參考譜圖庫;相關數據處理參數如下:搜庫引擎採用sequestht;蛋白質資料庫用uniprottaxid:9606);設置胰蛋白酶酶解;最大允許漏切位點設為2;肽段水平的假陽性率(fdr)設置為1%;肽和片段質量誤差分別為
±
10ppm和
±
0.02da。
86.另取酶解後的多肽樣品經由orbitrap fusion lumos軌道阱質譜儀進行分析;共上樣18μl,以60min梯度分離:0min/3%b,0-2min/8%b,2-46min/28%b,46-55min/40%b,55-56min/100%b,56-60min/100%b。;柱流量控制在600nl/min;軌道阱質譜儀在數據依賴採集模式下運行,質譜參數設置如下:(1)msn1:掃描範圍(m/z):350-1500;解析度:60,000;agctarget:4e5;最大注入時間:50ms;(2)msn2:解析度:30,000;agctarget=3e5;最大注入時間:54ms;碰撞能量:33%;用skyline軟體進行dia分析,通過導入上面所得參考譜圖庫,對dia原始數據進行多肽信號提取與定量分析。詳細參數如下:多肽長度選6-25;子離子m/z要求為大於母離子且last ion-3;子離子最大數目設為5;子離子最小數目設為2;子離子抽提窗口採用5min;dotp需要大於等於0.6。
87.上述測定,對每個民族樣本做三個平行樣的生物重複,結果取平均值。
88.對兩個民族的測定結果進行比較,將符合fc》1.5或《0.67,且pvalue《0.05的蛋白設定為差異表達蛋白,並進行功能注釋。
89.差異蛋白列表:
90.圖7以柱狀圖的形式顯示了總鑑定蛋白,差異蛋白的數目。通過比較朝鮮族和漢族的酪蛋白中所鑑定蛋白質,觀察到238種顯著差異表達的蛋白質,其中有142種蛋白質上調,96種下調。在上調的蛋白質中,聚合酶蛋白同源樣結構域,家族a,成員1,亞型cra_a(phlda1)的fc最高,log2fc值為26.18,p值為0.000776,這是兩組之間差異最大的蛋白質。phlda1是一種具有多種功能的蛋白,在調節細胞凋亡、增殖、分化和細胞遷移的許多生物學過程中發揮重要作用,因此在不同類型的癌症中表達改變。而在下調的蛋白中,酪氨酸蛋白激酶受體的fc值最低,log2fc值為-7.35,p值為0.01998。酪氨酸蛋白激酶受體可以協調多種細胞功能,如細胞增殖和分化,因此在多種細胞的起始和進化中發揮重要作用
91.差異蛋白的go富集分析:
92.通過go富集分析分析朝鮮族和漢族母乳之間的差異表達蛋白,結果表示共有374個顯著富集(q《0.05)。圖8顯示了前三十項並對其進行研究,其中bp的細胞代謝過程(30),cc的膜有界細胞器(37),mf的催化活性(25)分別是涉及蛋白數目最多的項。細胞外間隙是最富集的go項,其富集因子為0.045,具有最小q值2.27e-15。過氧化物還蛋白活性則具有最高的富集因子0.8。該項涉及的4個差異蛋白均為過氧化物酶,屬於硫醇特異性過氧化物酶,
分別催化過氧化氫和有機氫過氧化物還原為水和醇。通過解毒過氧化物和作為過氧化氫介導的信號事件的傳感器,在細胞保護氧化應激中發揮作用。
93.差異蛋白的kegg富集分析:
94.對於kegg富集分析,共有118個被顯著富集(q《0.05)。圖9顯示了前二十項並對其進行研究,數據顯示,吞噬小體擁有最小q值為2.20e-12,是富集最顯著的途徑。而涉及蛋白質數量最多的途徑是代謝途徑,涉及33個差異蛋白。哮喘則是有最大富集因子0.194。過敏性哮喘是最常見的哮喘表型,通常始於兒童時期,通常同時伴有特應性皮炎和變應性鼻炎等併發症狀
95.差異蛋白的蛋白互作網絡分析:
96.差異表達蛋白的蛋白互作網絡分析顯示存在202個節點和979條邊,表明有202個差異表達蛋白參與了979種相互作用。對ppi網絡與對應的前20個樞紐基因的蛋白質的互作網絡進行研究,數據表明存在20個節點和143條邊。
97.通過degree法挖掘排名前20位的核心蛋白,按分數排序如下:肌動蛋白,細胞質1,熱休克蛋白hsp 90-alpha,熱休克同源物71kda蛋白,白蛋白,延伸因子1-alpha 1,40s核糖體蛋白sa,60s核糖體蛋白l9,t複合體蛋白1亞基,40s核糖體蛋白s4,40s核糖體蛋白s6,鈣聯接蛋白,60s核糖體蛋白l18,60s核糖體蛋白l27a,40s核糖體蛋白s19,增殖相關蛋白2g4,60s核糖體蛋白l15,真核翻譯起始因子3亞基m,真核生物起始因子4a-i,真核生物起始因子4a-i以及40s核糖體蛋白s25。