一種基於貨車監控數據的裝卸貨地點識別方法與流程
2023-12-03 13:26:06 5
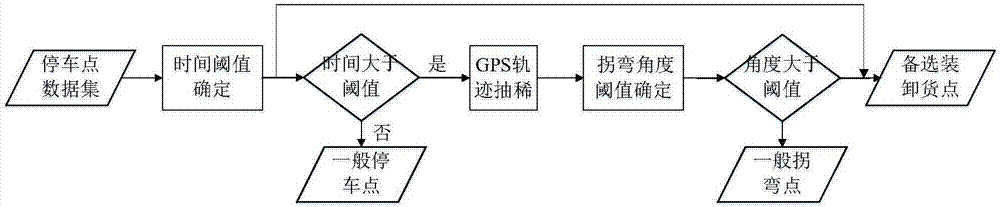
本發明屬於數據挖掘技術領域,具體涉及一種基於貨車監控數據的裝卸貨地點識別方法。
背景技術:
國家要求道路營運車輛必須安裝車輛監控系統,車輛運行的時候會產生大量的數據,挖掘車輛監控數據分析駕駛員偏好特徵可以為他們提供更加個性化的地理信息服務。通過判斷速度和gps點的有無,以及包絡半徑可以找出所有的停車點,但是很多停車點往往是紅綠燈,司機的沿途休息、吃飯地點。又因為越來越多的貨物運輸採用甩掛運輸形式,裝卸貨時間很短,不能僅僅依靠貨車停車時間的長短判斷車輛的裝卸貨地點,如何從貨車監控數據中挖掘貨車的裝卸貨地點,對有效識別在貨車駕駛員的特定行為,分析駕駛員在各位置之間的關係以及預測貨車駕駛員在這些位置之間的活動有重要意義。
技術實現要素:
有鑑於此,本發明的目的是提供一種基於貨車監控數據的裝卸貨地點識別方法,可以識別出真正的裝卸貨地點。
本發明的一種基於貨車監控數據的裝卸貨地點識別方法,包括如下步驟:
步驟1、貨車監測數據的清洗與修復,具體為:
s11、軌跡數據分段:按照檢測數據的時間戳順次檢查車輛歷史數據,針對監控數據的時間戳tτ,若tτ-tτ-1>4小時,則時間戳tτ之前的監控數據構成一個新的軌跡段,針對該軌跡段,再進一步進行判斷是否滿足tτ-1-t1<1小時,如果不滿足,保留該軌跡段;如果滿足,則捨棄該軌跡段;剩餘監控數據從時間戳tτ開始順次進行判斷;
s12、順次檢索車速數據,將車速小於0km/h或大於150km/h的點記為缺失數據,並對缺失數據進行修復;
s13、針對s12得到的監控數據,順次檢索車輛加速度數據,判斷加速度是否滿足車輛運動學規律,如果不滿足,則記為缺失數據,並對缺失數據進行修復;
s14、對s13得到的監控數據進行數據平滑;
步驟2、對裝卸貨停車點進行判別,具體為:
s21、計算停留時間閾值th;
s22、找出車輛速度小於設定閾值vh的點,則初步判斷為停車點;對停車點進行聚類,對每一類聚類點計算其停車時間,若停車時間大於停留時間閾值th,則認為是停車點,否則認為是一般停車點;
s23、軌跡抽稀
a、針對每一個軌跡段,確定軌跡段中的停車點後,相鄰兩個停車點之間軌跡作為車輛的一次出行軌跡;
b、針對每個出行軌跡,連接出行軌跡的首端點和末端點,記為線段l;若出行軌跡中某個軌跡點對線段l的垂足在線段l外,則將該出行軌跡以此軌跡點為界分割成兩個子軌跡;
c、然後按照b的方法分別處理兩個子軌跡,直到子軌跡沒有軌跡點的垂足在線段之外,此時判斷子軌跡首末端點的距離是否滿足要求,如果滿足:將子軌跡中除首、末端點之外的軌跡點刪除;如果不滿足,繼續將子軌跡進行分割,直到子軌跡的首末端點的距離滿足要求,並將子軌跡中除首、末端點之外的軌跡點刪除;
d、按照b和c的方法處理每一次出行軌跡,完成每一個軌跡段的抽稀;
s24、折返點判定:針對抽稀後的各個軌跡段,根據設定的折返角閾值判斷其中的每個軌跡點是否為折返點,如果是,則認為是折返點;如果否,認為是一般拐彎點;
步驟3、將s22判定的停車點以及s24認定的折返點作為備選裝卸貨停車點,針對備選裝卸貨停車點,根據車輛到達裝卸備選點前和離開備選點後車的總質量判斷備選裝卸貨停車點是否為真的裝卸貨停車點。
較佳的,s12中,當只有當前一個點為缺失數據時,稱為孤立缺失數據,對孤立缺失數據的修復,採用缺失數據之前和之後的數據值加權平均方法進行修復。另一種為連續缺失數據;孤立缺失數據是指該數據前後的數據都存在,,連續缺失數據是指其前部或後部有連續三個點(包括當前點)缺失的數據。修複方法如式所示:
式中,vτ為使用加權平均方法的車速修復結果,wi為加權係數,w為所有加權係數之和,為修複數據所用相鄰數據的最大間隔;vτ+i離缺失數據vτ越遠,加權係數wi的值越小;
較佳的,s12中,當前缺失數據點之前和/或之後有連續三個數據點缺失的數據稱為連續缺失數據;對於連續缺失數據的修復,採用指數平滑方法,如式所示:
vτ+r=aτ+bτ·r
式中,r=0,1,2,…,r-1;r為缺失數據累計序號,r為連續缺失數據個數,aτ,bτ為中間變量,分別由下式確定:
式中,α為平滑係數,α∈(0,1),為一次指數平滑值,為二次指數平滑值,其值分別由下式確定:
較佳的,s13中,判別軌跡點的加速度是否滿足車輛運動學規律的方法為:車輛加速度小於0.9g,則正常數據;若加速度大於或等於0.9g,軌跡數據記為缺失數據;缺失的軌跡點數據直接用插值法對數據進行修。
較佳的,s14中,採用移動平均方法對數據進行平滑處理。
較佳的,s21中,計算停留時間閾值th的方法為:
選取n個(這裡n取100)停車點作為樣本,按照停留時間t從1分鐘到60分鐘間隔為1分鐘順序遞增,計算不同停留時間下樣本的綜合評價指標ef,選取ef最大時的t作為停留時間閾值th;綜合評價指標ef的計算公式如下:
式中ep為準確率,er為召回率,準確率和召回率的計算公式如下式所示:
式中np是檢索到的真正裝卸貨點數量,nw是檢索到的錯誤的裝卸貨點數量,nreal是n個停車點中實際的裝卸貨點總數。
較佳的,s22中,用基於密度聚類方法dbscan對停車點進行聚類。
較佳的,s22中,其停車時間的計算方法為,每一個停車點聚類中,停車時間最大值與最小值的差值即為該聚類的停車時間。
較佳的,s23的步驟c中,刪除首末端點之外的軌跡點的方法為:如果所有點的垂足都在線段上,則求所有點與線段的距離,並找出最大距離值dmax,用dmax與垂直距離閾值dh相比,dh取值如下式所示:
式中dl是線段l的長度;若dmax4小時,則{d1,d2,…,dτ-1,dτ}構成一個新的軌跡段,再進一步進行判斷:若tτ-1-t1<1小時,則捨棄該軌跡段,剩餘監控數據從dτ開始順次處理。
2)車速數據清洗與修復。順次檢索車速數據,車速小於0km/h或大於150km/h的點,以-1替代,記為缺失數據。缺失數據分為兩種:一種為孤立缺失數據,另一種為連續缺失數據;孤立缺失數據是指該數據前後的數據都存在,只有當前一個點缺失的數據,連續缺失數據是指其前部或後部有連續三個點(包括當前點)缺失的數據。對孤立缺失數據的修復,採用加權平均方法修復,修複方法如式所示:
式中,vτ為使用加權平均方法的車速修復結果,wi為加權係數,w為所有加權係數之和,為修複數據所用相鄰數據的最大間隔;vτ+i離缺失數據vτ越遠,加權係數wi的值越小;對於連續缺失數據的修復,採用指數平滑方法,如式所示:
vτ+r=aτ+bτ·r
式中,r=0,1,2,…,r-1;vτ+r為使用了指數平滑法的車速修復結果,r為缺失數據累計序號,r為連續缺失數據個數,aτ,bτ為中間變量,分別由下式確定:
式中,α為平滑係數,α∈(0,1),為一次指數平滑值,為二次指數平滑值,其值分別由下式確定:
3)軌跡數據的清洗與修復
考慮gps的定位精度和信號強度問題,車輛在行駛過程中記錄的軌跡可能包含一些異常情況,出現gps信號的漂移或軌跡點的粗大誤差,大誤差點的判別準則是當前點的加速度是否滿足車輛運動學規律。計算車輛的加速度考慮路面附著係數,車輛加速度應小於0.9g,則若加速度大於或等於0.9g,軌跡數據出現漂移,將這些數據點的經度和緯度坐標以0替代,記為缺失數據。
缺失的軌跡點數據直接用插值法對數據進行修復,公式如下。
4)數據平滑。異常數據清洗修復後,數據中仍然存在一些噪聲數據,影響數據的魯棒性,導致後續的計算產生偏差,為減少噪聲數據的影響,這裡採用移動平均方法對數據進行處理,軌跡數據及車速數據扭矩數據的數據平滑公式如下所示,式中n取2。
2.停車點判別
1)計算停留時間閾值th。選取n個(這裡n取100)停車點作為樣本,按照停留時間t從1分鐘到60分鐘間隔為1分鐘順序遞增,計算不同停留時間下樣本的綜合評價指標ef,選取ef最大時的t作為停留時間閾值th。綜合評價指標ef的計算公式如下:
式中ep為準確率,er為召回率,準確率和召回率的計算公式如下式所示。
式中np是檢索到的真正裝卸貨點數量,nw是檢索到的錯誤的裝卸貨點數量,nreal是n個停車點中實際的裝卸貨點總數。
2)以速度判斷車輛的停車點,找出車輛速度小於閾值vh的點,並針對找到的點用基於密度聚類方法dbscan(density-basedspatialclusteringofapplicationswithnoise)對停車點進行聚類,對每一類聚類點計算其停車時間,若停車時間大於停留時間閾值th,則認為是停車點,否則認為是一般停車點。其中,停車時間的計算方法為,每一個停車點聚類中,停車時間最大值與最小值的差值即為該聚類的停車時間。
3)軌跡抽稀
a、針對每一個軌跡段,確定軌跡段中的停車點後,相鄰兩個停車點之間軌跡作為車輛的一次出行軌跡;
b、針對每個出行軌跡,連接出行軌跡的首端點和末端點,記為線段l;若出行軌跡中某個軌跡點對線段l的垂足在線段l外,則說明末端點不是離首端點最遠點,則將該出行軌跡以此軌跡點為界分割成兩個子軌跡;
c、然後按照b的方法分別處理兩個子軌跡,直到子軌跡沒有軌跡點的垂足在線段之外,此時判斷子軌跡首末端點的距離是否滿足要求,如果滿足:將子軌跡中除首、末端點之外的軌跡點刪除;如果不滿足,繼續將子軌跡進行分割,直到子軌跡的首末端點的距離滿足要求,並將子軌跡中除首、末端點之外的軌跡點刪除;
d、按照b和c的方法處理每一次出行軌跡,完成軌跡的抽稀;
其中,在步驟c中,如果所有點的垂足都在線段上,則求所有點與線段的距離,並找出最大距離值dmax,用dmax與垂直距離閾值dh相比,dh取值如式所示。
式中dl是線段l的長度,單位km,若dmax<dh,這條曲線上的中間點全部捨去,若dmax≥dh,保留dmax對應的坐標點,並以該點為界,把曲線分為兩部分,對這兩部分重複使用該方法。
4)折返角度閾值確定
針對抽稀後的軌跡找轉折點就好,找轉折點的方法就是判斷夾角大小,正常沿直線行走,夾角應該接近於0°,如果達到了接近180°的時候說明這是一個折返點。本發明中定義折返角度為150°。對每一個抽稀後的點計算其折返角度,若折返角度大於150°,則認為是折返點,否則認為是一般拐彎點。
其中,針對認定的停車點,採用以下方法剔除非裝卸貨停車點,具體為:計算逆地理編碼,刪除幹擾停車點;逆地理編碼是指輸入地理坐標信息,獲得該坐標的地址信息。用百度地圖api,輸入經緯度坐標,得到經緯度點的位置信息,刪除含有「加油站」、「服務區」等關鍵詞的位置點。
將判定的停車點以及認定的折返點作為備選裝卸貨停車點。
3.車輛載重變化判別
備選的裝卸車地點獲得後,如果車輛的載重發生變化,才認為該點為車輛裝卸貨地點。具體流程如下:
(1)車輛載重計算
發動機瞬時功率的計算如下式所示:
p=rmp×torque×2π/60
式中,p為發動機瞬時功率,單位:瓦特;rpm為轉速,單位:r/min;torque為扭矩,單位:n.m;又已知
f=ma
式中m為車輛和貨物的總質量,a為車輛運行加速度。綜合上式,可得車輛和貨物的總質量m
在具體計算中,需選取某段時間內勻加速行駛行為,才能較好的符合牛頓第二定律的使用條件。本研究選取每輛卡車連續勻加速10秒鐘及以上的點,作為研究個案數據。
(2)車輛載重變化判別
計算貨車到達裝卸備選點前和離開備選點後車的總質量,比較兩種情況下車輛質量是不是有明顯差別,若差別明顯,認為該點是裝卸貨點,否則認為該點為一般停車點。差別明顯的判斷標準看前後車重相差是否超過10%。
綜上所述,以上僅為本發明的較佳實施例而已,並非用於限定本發明的保護範圍。凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護範圍之內。