來源於解脂耶氏酵母和解腺嘌呤阿氏酵母的啟動子及其使用方法與流程
2023-12-05 09:51:26 6
相關申請
本申請要求於2014年7月25日提交的美國臨時專利申請號62/028,946的優先權的權益,其全部內容通過引用併入本文。
序列表
本申請包含以ascii格式電子提交的序列表,並通過引用全文納入本文。所述ascii副本,於2015年7月16日創建,名為ngx_03425_sl.txt,大小為71,975位元組。
背景技術:
含脂肪酵母例如解脂耶氏酵母(yarrowialipofytica)和解腺嘌呤阿氏酵母(arxulaadeninivorans)可以被工程改造用於脂質的工業生產,脂質是食品和化妝品工業中不可或缺的成分,並且是生物柴油和生物化學工業中的重要前體。可以通過上調或下調調節細胞代謝和脂質途徑的基因來提高含油生物體的脂質產量。
上調基因的一種方法是使用強組成型啟動子控制其表達。例如,可以使用強組成型啟動子來上調解脂耶氏酵母(y.lipolytica)二醯基甘油醯基轉移酶dga1,並且這種遺傳工程改造顯著增加生物體的脂質產量和生產力(參見例如tai和stephanopoulos,metabolicengineering12:1-9(2013))。
選擇用於控制基因表達的最佳啟動子是遺傳工程改造的關鍵部分,但不同的啟動子可能對於不同的應用是最佳的。例如,用於酵母的工業菌株的最佳啟動子可以不同於在實驗室菌株中最佳的啟動子。
已經鑑定和驗證了一些解脂耶氏酵母(y.lipolytica)和解腺嘌呤阿氏酵母(a.adeninivorans)(參見例如美國專利號7,259,255(通過引用併入)和7,264,949(通過引用併入);美國專利申請號2012/0289600(通過引用併入),2006/0094102(通過引用併入)和2003/0186376(通過引用併入);wartmann等,femsyeastresearch2:363-69(2002))。然而,兩種生物體都含有數百個尚待鑑定的啟動子,並且許多這些啟動子可用於工程改造酵母和其他生物體。此外,啟動子可以在相同物種的不同菌株之間顯著變化,並且這種遺傳多態性的鑑定和篩選為遺傳工程改造提供了更豐富的工具箱。
發明概述
公開了解腺嘌呤阿氏酵母(arxulaadeninivorans)和解脂耶氏酵母(yarrowialipolytica)的啟動子的核苷酸序列,其可以用於驅動細胞中的基因表達。驗證這些啟動子、篩選選擇的啟動子以確定哪些啟動子可用於增加含油酵母的脂質生產效率。
附圖說明
圖1描繪了pnc303構建體的圖譜,其用作模板以擴增包含釀酒酵母(saccharomycescerevisiae)轉化酶基因suc2和ter1終止子的dna片段。「scura3」表示用於在酵母中選擇的釀酒酵母ura3營養缺陷型標記;「2uori」表示來自2μm圓形質粒的釀酒酵母複製起點;「pmb1ori」表示來自pbr322質粒的大腸桿菌(e.coli)pmb1複製起點;「ampr」表示用作用氨苄青黴素選擇的標記的bla基因;「scfba1p」表示釀酒酵母fba1啟動子-822至-1;「hygr(ng4)」表示由genscript合成的大腸桿菌hygr基因cdna(seqidno:2);「scfba1t」表示終止後205bp的釀酒酵母fba1終止子;「ylteflp(pr3)」表示解脂耶氏酵母tef1啟動子-406至+125;「ng102」表示釀酒酵母suc2基因(seqidno:1);「ylcyclt(ter1)」表示在終止密碼子之後300bp的解脂耶氏酵母cyc1終止子。
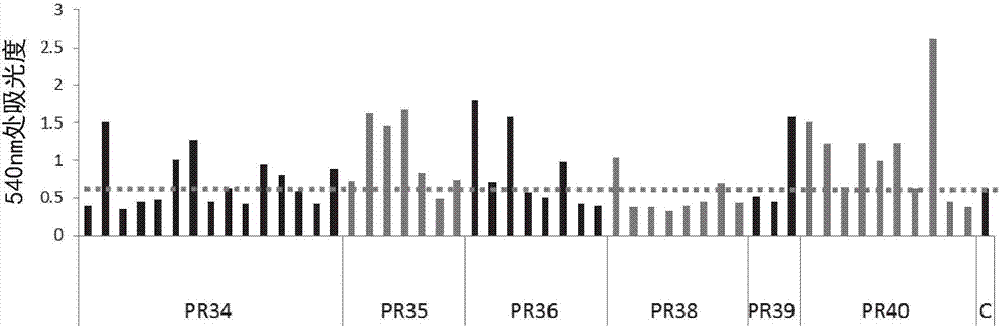
圖2描述了在14種不同啟動子和相同ter1終止子(終止密碼子後300bp的解脂耶氏酵母cyc1終止子)的控制下表達釀酒酵母轉化酶基因suc2的解脂耶氏酵母菌株ns18轉化體的轉化酶活性。x軸標記對應於表ii中的啟動子id。通過二硝基水楊酸(dns)試驗來測量活性。在30℃下在96孔板中的ypd培養基中細胞生長48小時後分析樣品。在不同的96孔板中分析2a和2b中的樣品。親本解脂耶氏酵母菌株ns18(「c」)用作每個平板上的陰性對照。
圖3描述了用於在解脂耶氏酵母菌株ns18和解腺嘌呤阿氏酵母菌株ns252中表達潮黴素抗性基因(hygr,seqidno:2)的pnc161構建體的圖譜。載體pnc161在轉化前通過paci/pmei限制性消化進行線性化。「pmb1ori」表示來自pbr322質粒的大腸桿菌pmb1複製起點;「ampr」表示用作用氨苄青黴素選擇的標記的bla基因;「scura3」表示用於在酵母中選擇的釀酒酵母ura3營養缺陷型標記;「2uori」表示來自2μm圓形質粒的釀酒酵母複製起點;「scfba1p」表示釀酒酵母fba1啟動子-822至-1;「hygr(ng4)」表示由genscript合成的大腸桿菌hygr基因cdna(seqidno:2);「scfba1t」表示在終止密碼子之後205bp的釀酒酵母fba1終止子。
圖4描述了在不同解腺嘌呤阿氏酵母啟動子的控制下表達大腸桿菌潮黴素抗性基因(seqidno:2)的解腺嘌呤阿氏酵母菌株ns2s2轉化體的瓊脂平板。標記對應於表i中的啟動子id。轉化體在含有ypd和300μg/μl潮黴素b的平板上在37℃下生長2天。陰性對照由親本解腺嘌呤阿氏酵母菌株ns252組成,用水代替dna。
圖5描述了在不同解腺嘌呤阿氏酵母啟動子的控制下表達大腸桿菌潮黴素抗性基因(seqidno:2)的解脂耶氏酵母菌株ns18轉化體的瓊脂平板。標記對應於表i中的啟動子id。轉化體在含有ypd和300μg/μl潮黴素b的平板上在37℃下生長2天。陰性對照由親本解脂耶氏酵母菌株ns18組成,用水代替dna。
圖6描述了用於在解脂耶氏酵母菌株ns18中過表達編碼二醯基甘油醯基轉移酶dga1(seqidno:3)的基因的pnc336構建體的圖譜。載體pnc336在轉化前通過paci/noti限制性消化進行線性化。「scura3」表示用於在酵母中選擇的釀酒酵母ura3營養缺陷型標記;「2uori」表示來自2μm圓形質粒的釀酒酵母複製起點;「pmb1ori」表示來自pbr322質粒的大腸桿菌pmb1複製起點;「ampr」表示用作用氨苄青黴素選擇的標記的bla基因;「pr14aateflp」表示解腺嘌呤阿氏酵母tef1啟動子-427至-1(seqidno:5);ng66(rtdga1)表示由genscript合成的紅冬孢酵母dga1cdna(seqidno:3);「ylcyclt(ter1)」表示在終止密碼子之後300bp的解脂耶氏酵母cyc1終止子;「sctef1p」表示釀酒酵母tef1啟動子-412至-1;「nat」表示用作用諾爾絲菌素選擇的標記物的鏈黴菌屬natl基因;「sccyclt」表示終止密碼子後275bp的釀酒酵母cyc1終止子。
圖7描述了在不同的解腺嘌呤阿氏酵母啟動子和相同的ter1終止子(終止密碼子之後300bp的解脂耶氏酵母cyc1終止子)的控制下表達紅冬孢酵母(rhodosporidiumtoruloides)dga1蛋白的解脂耶氏酵母菌株ns18轉化體的脂質試驗結果。x軸標記對應於表i中的啟動子id。對於每個構建體,通過實施例7中描述的脂質試驗分析12個轉化體。在含有脂質生產誘導培養基的96孔板中細胞生長72小時後分析樣品。樣品「c」描繪了親本菌株ns18作為對照,誤差棒描繪了從三種不同試驗獲得的一個標準偏差。
圖8描繪了在不同解脂耶氏酵母啟動子和相同ter1終止子(解脂耶氏酵母cyc1終止子,終止密碼子後300bp)控制下表達紅冬孢酵母dga1的解脂耶氏酵母菌株ns18轉化體的脂質試驗結果。x軸標記對應於表ii中的啟動子id。對於每個構建體,通過實施例7中描述的脂質試驗分析12個轉化體。在含有脂質生產誘導培養基的96孔板中細胞生長72小時後分析樣品。樣品「c」描繪了親本菌株ns18作為對照,誤差棒描繪了從三種不同試驗獲得的一個標準偏差。
圖9描述了用於在解腺嘌呤阿氏酵母菌株ns252中過表達編碼來自紅冬孢酵母的二醯基甘油醯基轉移酶dga1的基因的pnc378構建體的圖。載體pnc378在轉化前通過pmei/asci限制性消化進行線性化。「scura3」表示用於在酵母中選擇的釀酒酵母ura3營養缺陷型標記;「2uori」表示來自2μm圓形質粒的釀酒酵母複製起點;「pmb1ori」表示來自pbr322質粒的大腸桿菌pmb1複製起點;「ampr」表示用作用氨苄青黴素選擇的標記的bla基因;「pr26aapgklp」表示解腺嘌呤阿氏酵母pgk1啟動子-524至-1(seqidno:14);「pr25aaadh1p」表示解腺嘌呤阿氏酵母adh1啟動子-877至-1(seqidno:13);「ng66(rtdga1)」表示紅冬孢酵母dga1cdna;「scfbalt(ter6)」表示終止密碼子後205bp的釀酒酵母終止子;「nat」表示用作用諾爾絲菌素選擇的標記物的鏈黴菌屬(streptomycesnoursei)natl基因;「aacyclt」表示終止密碼子後301bp的解腺嘌呤阿氏酵母cyc1終止子。
圖10描述了解腺嘌呤阿氏酵母菌株ns252轉化體的脂質試驗結果,該轉化體表達在解腺嘌呤阿氏酵母啟動子adh1和ter16終止子(終止密碼子後301bp的解腺嘌呤阿氏酵母cyc1終止子)控制下的來自各種宿主生物的不同dga蛋白。x軸標記對應於表iii中的dga基因。對於每個構建體,通過實施例7和8中描述的脂質試驗分析8個轉化體。在含有脂質生產誘導培養基的96孔板中細胞生長72小時後分析樣品。樣品「c」描繪了親本菌株ns252作為對照,誤差棒描繪了從8種不同試驗獲得的一個標準偏差。
圖11描述了解腺嘌呤阿氏酵母菌株ns252轉化體的脂質試驗結果,該轉化體表達在解腺嘌呤阿氏酵母啟動子adh1和ter16終止子(終止密碼子後301bp的解腺嘌呤阿氏酵母cyc1終止子)控制下的來自各種宿主生物的不同dga蛋白。x軸標記對應於表iii中的dga基因。對於每個構建體,通過實施例7和8中描述的脂質試驗分析8個轉化體。在含有脂質生產誘導培養基的96孔板中細胞生長72小時後分析樣品。樣品「c」描繪了親本菌株ns252作為對照,誤差棒描繪了從8種不同試驗獲得的一個標準偏差。
圖12描述了解腺嘌呤阿氏酵母菌株ns252轉化體的脂質試驗結果,該轉化體表達在解腺嘌呤阿氏酵母啟動子adh1和ter16終止子(終止密碼子後301bp的解腺嘌呤阿氏酵母cyc1終止子)控制下的來自各種宿主生物的不同dga蛋白。x軸標記對應於表iii中的dga基因。對於每個構建體,通過實施例7和8中描述的脂質試驗分析8個轉化體。在含有脂質生產誘導培養基的96孔板中細胞生長72小時後分析樣品。樣品「c」描繪了親本菌株ns252作為對照,誤差棒描繪了從8種不同試驗獲得的一個標準偏差。
發明詳述
概述
在一些方面,本發明涉及載體,其包含編碼衍生自解腺嘌呤阿氏酵母或解脂耶氏酵母的啟動子的核苷酸序列,其中所述載體是質粒。在一些方面,本發明涉及載體,其包含編碼衍生自解腺嘌呤阿氏酵母或解脂耶氏酵母的啟動子的核苷酸序列,其中所述載體是線性dna片段。
在某些方面,本發明涉及包含遺傳修飾的轉化的細胞,其中所述遺傳修飾是用編碼衍生自解腺嘌呤阿氏酵母或解脂耶氏酵母的啟動子的核酸轉化。
在其它方面,本發明涉及在細胞中表達基因的方法,包括用編碼衍生自解腺嘌呤阿氏酵母或解脂耶氏酵母的啟動子的核酸轉化親本細胞。在一些實施方式中,核酸包含基因,並且基因和啟動子可操作地連接。在其他實施方式中,設計核酸使得啟動子在轉化親本細胞後變得可操作地連接到基因。
定義
本文使用冠詞「一個」和「一種」表示一個或一個以上的(即至少一個)該冠詞語法上的賓語。舉例而言,「一種元件」表示一個元件或者一個以上的元件。
術語「dgat2」是指編碼2型二醯甘油醯基轉移酶蛋白的基因,例如編碼dga1蛋白的基因。
「二醯基甘油酯」,「二醯基甘油」和「甘油二酯」是由甘油和兩種脂肪酸組成的酯。
術語「二醯基甘油醯基轉移酶」和「dga」是指催化由二醯基甘油形成三醯基甘油酯的任何蛋白質。二醯基甘油醯基轉移酶包括1型二醯基甘油醯基轉移酶(dga2)、2型二醯基甘油醯基轉移酶(dga1)和催化上述反應的所有同系物。
術語「二醯基甘油醯基轉移酶,2型」和「2型二醯基甘油醯基轉移酶」是指dga1和dga1直向同源物。
術語「結構域」是指蛋白質的胺基酸序列的一部分,其能夠摺疊成獨立於蛋白質其餘部分的穩定的三維結構。
「乾重」和「幹細胞重量」是指在相對不存在水時測定的平均重量。例如,以乾重提及油性細胞包括特定成分的指定百分比是指基本上所有的水已經被除去後,基於細胞的重量計算百分比。
術語「編碼」是指核苷酸序列,其(a)編碼胺基酸序列,(b)可以結合蛋白質例如聚合酶或轉錄因子,(c)調節結合核酸的蛋白質,例如作為轉錄起始位點,和(d)(a)、(b)和(c)中所述的核苷酸序列的互補序列。例如,核苷酸序列可以編碼結合聚合酶的基因,其編碼胺基酸序列和/或啟動子。dna和rna都可以編碼基因。dna和rna都可以編碼蛋白質。
術語「內源的」是指存在於天然的、未轉化的細胞中的任何物質,即,沒有被引入細胞的一切。「內源核酸」是存在於天然的、未轉化的細胞中的核酸,例如染色體或從染色體中天然存在的基因轉錄的mrna。內源核酸包括內源基因和內源啟動子。術語「內源基因」和「內源啟動子」是指天然存在於細胞基因組中的核苷酸序列,其沒有通過轉化或轉染引入。
術語「外源的」是指引入細胞的任何物質。「外源核酸」是通過細胞膜進入細胞的核酸。外源核酸可以含有先前不存在於細胞的天然基因組中的核苷酸序列和/或已經存在於基因組中但被重新引入基因組的核苷酸序列,例如通過用其他拷貝的核苷酸序列轉化。外源核酸包括外源基因和外源啟動子。「外源基因」是已經被引入細胞(例如通過轉化/轉染)並編碼rna和/或蛋白質的核苷酸序列,外源基因也稱為「轉基因」。類似地,「外源啟動子」是已被引入細胞(例如通過轉化/轉染)並編碼啟動子的核苷酸序列。包含外源基因或外源啟動子的細胞可以稱為重組細胞,其中可以引入額外的外源基因或啟動子。外源基因或外源啟動子可以來自相對於被轉化的細胞的相同物種或不同物種。因此,外源基因可以包括佔據細胞基因組中不同於內源基因的位置的基因,或者相對於基因的內源性拷貝處於不同的可操作的連接。類似地,外源啟動子可以包括佔據細胞基因組中不同於內源啟動子位置的啟動子或可操作地連接於與內源啟動子不同的基因的啟動子。外源基因或外源啟動子可以以超過一個拷貝存在於細胞中。外源基因或外源啟動子可以作為插入基因組(核或質體)或作為游離分子保持在細胞中。
術語「表達」是指細胞中核酸或胺基酸序列(例如肽,多肽或蛋白質)的量。基因的增加的表達是指該基因的增加的轉錄。胺基酸序列、肽、多肽或蛋白質的增加的表達是指增加的編碼胺基酸序列、肽、多肽或蛋白質的核酸的翻譯。
本文使用的術語「基因」可以包括含有內含子的基因組序列,特別是編碼涉及特定活性的多肽序列的多核苷酸序列。該術語還包括不衍生自基因組序列的合成核酸。在某些實施方式中,基因缺乏內含子,因為它們基於cdna和蛋白質序列的已知dna序列合成。在其它實施方式中,基因是合成的非天然cdna,其中已基於密碼子使用而優化密碼子以在解脂耶氏酵母或解腺嘌呤阿氏酵母腺中表達。該術語還可以包括包含上遊、下遊和/或內含子核苷酸序列的核酸分子,包括啟動子。
術語「遺傳修飾」是指轉化的結果。每個轉化通過定義(definition)引起遺傳修飾。
本文所用的術語「同源物」是指(a)相對於在研的未修飾蛋白質具有胺基酸取代、缺失和/或插入的肽、寡肽、多肽、蛋白質和酶,並且具有與它們來源的未修飾的蛋白質相似的生物學和功能活性,和(b)相對於在研的未修飾核酸具有核苷酸取代、缺失和/或插入的核酸,並且具有與它們來源的未修飾的核酸相似的生物學和功能活性。例如,解脂耶氏酵母可以與由相同轉錄調節子調節的解腺嘌呤阿氏酵母啟動子同源。
術語「整合的」是指作為插入細胞基因組中(例如插入染色體,包括插入質體基因組中)的插入物而維持在細胞中的核酸。
「可操作連接」是兩個核酸序列(例如控制序列(通常是啟動子)和連接的序列(通常是編碼蛋白質的序列,也稱為編碼序列)之間的功能性連接。如果啟動子可以介導基因的轉錄,則其與基因可操作地連接(或「可操作連接」)。
術語「天然」是指在轉化事件之前的細胞或親本細胞的組成。
術語「核酸」是指任何長度的核苷酸聚合形式,不論是脫氧核糖核苷酸或核糖核苷酸或它們的類似物。多核苷酸可以具有任意的三維結構,且可以執行任何功能。以下是多核苷酸的非限制性例子:基因或基因片段的編碼或非編碼區域、由連鎖分析定義的基因座、外顯子、內含子、信使rna(mrna)、轉移rna、核糖體rna、核酶、cdna、重組多核苷酸、支鏈多核苷酸、質粒、載體、任意序列的分離dna、任意序列的分離rna、核酸探針和引物。多核苷酸可包括修飾的核苷酸,如甲基化的核苷酸和核苷酸類似物。如果存在,對核苷酸結構的修飾可在聚合物的組裝之前或之後賦予。多核苷酸可進一步被修飾,如通過與標記組分結合。在本文提供的所有核酸序列中,u核苷酸可與t核苷酸互換。
術語「親本細胞」是指細胞從其傳承的每個細胞。細胞的基因組由親本細胞的基因組和對其基因組的任何後續遺傳修飾組成。
如本文所用,術語「質粒」是指與生物體的基因組dna物理分離的環狀dna分子。質粒可以在引入宿主細胞之前線性化(本文稱為線性化質粒)。線性化質粒可以不是自我複製的,而是可以整合到生物體的基因組dna中並與其一起複製。
「啟動子」是指導核酸轉錄的核酸控制序列。如本文所用,啟動子包括靠近轉錄起始位點的必需的核酸序列。啟動子還任選地包括遠端增強子或阻抑物元件,其可位於距轉錄起始位點多達幾千個鹼基對處。
「重組」是指由於外源核酸的引入或天然核酸的改變而被修飾的細胞,核酸,蛋白質或載體。因此,例如,重組細胞可以表達在天然(非重組)形式的細胞中沒有發現的基因,或者表達與非重組細胞表達的基因不同的天然基因。重組細胞可以包括但不限於編碼基因產物或抑制元件例如降低細胞中活性基因產物水平的突變、敲除、反義、幹擾rna(rnai)或dsrna的重組核酸。「重組核酸」衍生自最初在體外,通常通過操縱核酸,例如使用聚合酶、連接酶、外切核酸酶和內切核酸酶,或以其它方式在自然界中通常不存在的形式形成的核酸。可以產生重組核酸,例如,將兩個或更多個核酸置於可操作連接中。因此,出於本發明的目的,在體外通過將正常狀態天然不相連的dna分子連接形成的分離核酸或表達載體都被認為是重組的。一旦製備重組核酸並引入宿主細胞或生物體中,其可以使用宿主細胞的體內細胞機制進行複製;然而,此類核酸一旦重組產生,儘管隨後在細胞內複製,仍然被認為是用於本發明目的的重組。另外,重組核酸是指包含內源核苷酸序列和外源核苷酸序列的核苷酸序列;因此,已經與外源啟動子重組的內源基因是重組核酸。「重組蛋白」是使用重組技術,即通過表達重組核酸而製備的蛋白質。
術語「調節區」是指影響基因的轉錄或翻譯但不編碼胺基酸序列的核苷酸序列。調節區包括啟動子,操縱子,增強子和沉默子。
術語「子序列」是指在核苷酸序列內發現的小於全長核苷酸序列的連續核苷酸序列。例如,子序列可以由選自427個核苷酸長的seqidno:5所示的核苷酸序列的100個連續核苷酸組成;可以在427個核苷酸長的序列中發現328個100連續核苷酸長的子序列。由在全長核苷酸序列的3'-末端的100個連續核苷酸組成的子序列是指在該序列中發現的最後100個核苷酸。例如,子序列可以由seqidno:5的3'-末端的100個連續核苷酸組成,並且該子序列是seqidno:5的最後100個核苷酸。換句話說,seqidno:5的3'端的100個連續核苷酸是具有前327個核苷酸缺失的seqidno:5的核苷酸序列,其是單個子序列。如本文所用,子序列由至少50個核苷酸組成。
「轉化」是指將核酸轉移到宿主生物體或宿主生物體的基因組中,導致遺傳上穩定的遺傳。包含轉化的核酸片段的宿主生物體稱為「重組」、「轉基因」或「轉化」生物體。因此,本發明的分離的多核苷酸可以摻入能夠引入宿主細胞並在宿主細胞中複製的重組構建體,通常是dna構建體。這種構建體可以是包含能夠在給定宿主細胞中轉錄和翻譯多肽編碼序列的複製系統和序列的載體。通常,表達載體包括例如在5'和3'調節序列和可選擇標記的轉錄控制下的一個或多個克隆基因。這樣的載體還可以含有啟動子調節區(例如,控制誘導型或組成型,環境或發育調節或位置特異性表達的調節區),轉錄起始起始位點,核糖體結合位點,轉錄終止位點,和/或多聚腺苷酸化信號。或者,細胞可以用單個遺傳元件如啟動子轉化,其可以在整合到宿主生物體的基因組中,例如通過同源重組時導致遺傳上穩定的遺傳。
術語「轉化的細胞」是指經歷轉化的細胞。因此,轉化的細胞包含親本的基因組和可遺傳的遺傳修飾。
術語「三醯基甘油酯」,「三醯基甘油」,「甘油三酯」和「tag」是由甘油和三個脂肪酸組成的酯。
術語"載體"是核酸能增殖和/或在生物體、細胞或細胞組分之間轉移的方法。載體包括可能或可能不能自主複製或整合到宿主細胞的染色體中的質粒,線性dna片段,病毒,噬菌體,原病毒,噬菌粒,轉座子和人工染色體等。
微生物工程改造
a.概述
外源啟動子和基因可以引入許多不同的宿主細胞中。合適的宿主細胞是可廣泛存在於真菌家族中的微生物宿主。合適的宿主菌株的實例包括但不限於真菌或酵母物種,如阿氏菌屬(arxula)、麴黴屬(aspegillus)、奧蘭氏菌屬(aurantiochytrium)、念珠菌屬(candida)、麥角菌屬(claviceps)、隱球菌屬(cryptococcus)、小坎寧安黴屬(cunninghamella)、漢遜酵母屬(hansenula)、克魯維酵母屬(kluyveromyces)、白冬孢酵母屬(leucosporidiella)、油脂酵母屬(lipomyces)、被孢黴屬(mortierella)、歐格氏黴屬(ogataea)、畢赤酵母屬(pichia)、原囊藻屬(prototheca)、根黴屬(rhizopus)、紅冬孢酵母屬(rhodosporidium)、紅酵母屬(rhodotorula)、酵母菌屬(saccharomyces)、裂殖酵母屬(schizosaccharomyces)、銀耳屬(tremella)、絲孢酵母屬(trichosporon)和耶氏酵母屬(yarrowia)。解脂耶氏酵母和解腺嘌呤阿氏酵母非常適合用作宿主微生物,因為它們可以以三醯基甘油積累大部分的重量。
本發明的微生物經遺傳工程改造成含有外源啟動子,其可以是強啟動子或弱啟動子。強啟動子驅動可操作連接的基因的相當大的轉錄。弱啟動子對於許多應用可能是有價值的。例如,弱啟動子可優選用以驅動編碼在高濃度下顯示毒性的蛋白質的基因的轉錄或編碼針對必需蛋白質的幹擾rna的核苷酸序列的轉錄。因此,當強啟動子產生致死量的蛋白質產物時,優選弱啟動子用於表達蛋白質。類似地,當基底水平的靶標是細胞存活所必需的時,優選弱啟動子用於表達幹擾rna。
微生物表達系統和表達載體是本領域技術人員熟知的。任何這樣的表達載體可以用於將即時啟動子引入生物體。可以通過轉化技術將啟動子引入合適的微生物中,以指導可操作連接的基因的表達。例如,可將啟動子克隆到合適的質粒中,並用所得質粒轉化親本細胞。該方法可用於驅動與啟動子可操作地連接或在轉化事件後變得可操作地連接於啟動子的基因的表達。所述質粒沒有特別限制,只要其能產生對微生物後代可遺傳的所需啟動子。
用於轉化合適的宿主細胞的載體或盒是本領域熟知的。通常,載體或盒含有基因,指導相關基因的轉錄和翻譯的序列,包括啟動子,選擇標記和允許自主複製或染色體整合的序列。合適的載體包含具有啟動子和其它轉錄起始控制的基因的5'區域和控制轉錄終止的dna片段的3'區域。優選兩個控制區來源於與轉化的宿主細胞同源或來自密切相關物種的基因,儘管應理解這種控制區不需要來源於選擇作為生產宿主的特定物種的天然基因。例如,解腺嘌呤阿氏酵母啟動子可以用於驅動其他酵母菌種的表達。
啟動子,cdna和3'utr以及載體的其他元件可以通過使用從天然來源分離的片段的克隆技術產生(green和sambrook,《分子克隆:實驗室手冊》(第四版,2012);美國專利號4,683,202;通過引用併入)。或者,可以使用已知方法(gene164:49-53(1995))合成地產生元件。
b.啟動子序列
在一些實施方式中,本發明涉及啟動子。在一些實施方式中,啟動子包含seqidno:5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53中所示的核苷酸序列。啟動子可以包含保守取代、缺失和/或插入,同時仍然起驅動轉錄的作用。因此,啟動子序列可包含與seqidno:5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高相同性的核苷酸序列。
為了確定兩個核苷酸序列的百分比同一性,可以為了最佳比較目的而對序列進行比對(例如,可以在第一和第二核苷酸序列的一個或兩個中引入間隙用於最佳比對,並且出於比較目的可以不考慮非相同序列)。然後可以比較相應核苷酸位置處的核苷酸。當第一序列中的位置由與第二序列中的相應位置相同的核苷酸佔據時,則分子在該位置是相同的(如本文所使用的,核苷酸「同一性」等同於核苷酸「同源性」)。考慮到用於兩個序列的最佳比對而需要引入的間隙數目和每個間隙的長度,兩個序列之間的百分比同一性是序列共有的相同位置的數目的函數。
序列的比較和兩個序列之間百分比同一性的確定可以使用數學算法來完成。可用於測定兩個核苷酸序列之間同一性的示例性電腦程式包括但不限於blast程序套件,例如blastn、megablast和clustal程序,例如clustalw,clustalx和clustalomega。
當相對於genbankdna序列和其他公共資料庫中的核苷酸序列評估給定的核苷酸序列時,通常使用blastn程序進行序列搜索。使用例如clustal-w程序進行選定序列的比對以確定兩個或多個序列之間的「%同一性」。
在整個說明書中用於指包含核苷酸序列和/或由核苷酸序列組成的核酸的縮寫是常規的單字母縮寫。因此,當包括在核酸中時,天然存在的編碼核苷酸縮寫如下:腺嘌呤(a),鳥嘌呤(g),胞嘧啶(c),胸腺嘧啶(t)和尿嘧啶(u)。此外,本文呈現的核苷酸序列是5'→3'方向。
如本文所使用的,術語「互補」及其衍生物用於通過眾所周知的規則來配對核酸,即a與t或u配對,和c與g配對。互補可以是「部分的」或「完整的」。在部分互補中,根據鹼基配對規則只有一些核苷酸匹配;而在完全或全部互補中,所有鹼基根據配對規則匹配。核酸鏈之間的互補程度可以對本領域熟知的兩條核酸鏈之間的雜交效率和強度具有顯著的影響。雜交的效率和強度取決於檢測方法。
啟動子的全核苷酸序列對於驅動轉錄不是必需的,並且比啟動子的全核苷酸序列短的序列可以驅動可操作連接的基因的轉錄。稱為核心啟動子的啟動子的最小部分包括轉錄起始位點,rna聚合酶的結合位點和轉錄因子的結合位點。rna聚合酶結合到啟動子的3'末端。因此,啟動子可包含與seqidno:5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53的3』-端的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高相同性的核苷酸序列。
另外,可以組合兩個啟動子。例如,結合rna聚合酶的第一啟動子的區域可以與結合一種或多種轉錄因子的第二啟動子的區域組合以產生雜合啟動子。因此,啟動子的子序列可以與另一個啟動子組合以改變調節可操作地連接的基因的轉錄的轉錄因子。因此,啟動子可包含與seqidno:5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53中任何位置的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高相同性的核苷酸序列。
c.載體和載體組分
根據本發明的用於轉化微生物的載體可以通過本領域技術人員熟知的已知技術根據本文的公開內容製備。載體通常含有一個或多個基因,其中每個基因編碼所需產物(基因產物)的表達,並可操作地連接到調節基因表達的一個或多個調控序列(即啟動子),或載體將基因、控制序列或其它核苷酸序列靶向重組細胞中的特定位置。
任何核酸載體可以編碼啟動子。質粒可以是方便的載體,因為質粒可以在細菌宿主中操作和複製。在一些實施方式中,線性dna分子可以是優選的載體,例如,在轉化前消除質粒核苷酸序列。線性dna可以從質粒的限制性消化或通過pcr擴增獲得。pcr可用於通過擴增質粒dna、基因組dna、合成dna或任何其它模板產生線性dna載體。例如,pcr可用於從重疊的寡核苷酸片段產生線性dna載體。合適的載體不限於dna;例如,逆轉錄病毒載體的rna可用於轉化具有所需啟動子的細胞。
載體可以包含啟動子和基因,使得啟動子和基因可操作地連接。或者,可以設計載體使得啟動子在轉化親本細胞後變得可操作地連接到基因。例如,含有啟動子的第一載體可以設計為與含有基因的第二載體重組,從而成功的轉化和重組事件使得啟動子和基因在宿主細胞中可操作地連接。或者,可以將含有啟動子的載體設計為與宿主細胞基因組中的基因重組。在該實施方式中,外源啟動子取代內源啟動子。
1.控制序列
控制序列是調節編碼序列表達或將基因產物導向細胞內或細胞外特定位置的核酸。調節表達的調控序列包括例如調節編碼序列轉錄的啟動子和終止編碼序列轉錄的終止子。另一個控制序列是位於編碼多聚腺苷酸化信號的編碼序列末端的3'非翻譯序列。將基因產物導向特定位置的控制序列包括編碼信號肽的那些,其將它們所連接的蛋白質導向細胞內或細胞外的特定位置。
因此,用於在微生物中表達啟動子的示例性載體設計包含與在酵母中有活性的啟動子可操作連接的所需基因產物(例如,選擇性標記或酶)的編碼序列。或者,如果載體不含有與啟動子可操作連接的基因,則啟動子可以轉化到細胞中,使得其在載體整合的位點變得可操作地連接到內源基因。
用於表達基因的啟動子可以是與該基因天然連接的啟動子或不同的啟動子。
任選包括終止區控制序列,並且如果使用,則選擇主要是方便之一,因為終止區是相對可互換的。終止區可以對於轉錄起始區(啟動子)是天然的,對感興趣的dna序列可以是天然的,或者可以從另一個來源獲得(參見例如chen和orozco,nucleicacidsresearch16:8411(1988))。
2.基因
通常,基因包括啟動子,編碼序列和終止控制序列。當通過重組dna技術組裝時,基因可以稱為表達盒,並且可以側接限制性位點以方便地插入用於將重組基因導入宿主細胞的載體中。表達盒可以側接來自基因組或其他核酸靶的dna序列,以利於通過同源重組將表達盒穩定整合到基因組中。或者,載體及其表達盒可以保持未整合(例如附加體),在這種情況下,載體通常包括複製起點,其能夠提供載體dna的複製。
載體上存在的常見基因是編碼蛋白質的基因,該基因的表達允許含有該蛋白質的重組細胞與不表達該蛋白質的細胞進行區分。這樣的基因及其相應的基因產物稱為選擇性標記或選擇標記。在用於轉化本發明生物體的轉基因構建體中可以使用多種選擇標記中的任一種。
為了最佳表達重組蛋白,使用產生具有待轉化宿主細胞最佳使用的密碼子的編碼序列是有益的。因此,轉基因的正確表達可能需要轉基因的密碼子使用與其中表達轉基因的生物體的特異性密碼子偏好相匹配。這種效應背後的精確機制有許多,但包括可用的氨醯基化trna庫與細胞中合成的蛋白質的適當平衡,以及當滿足該需要時更高效地翻譯轉基因信使rna(mrna)。當不優化轉基因中的密碼子使用時,可用的trna庫不足以允許轉基因mrna的高效翻譯,導致核糖體停滯和終止以及轉基因mrna的可能的不穩定性。
d.同源重組
同源重組可用於用不同的核苷酸序列替代一個核苷酸序列。因此,可以使用同源重組來用外源啟動子的全部或部分來替代驅動生物體中的基因表達的內源啟動子的全部或部分。另外,同源重組可用於組合含有同源核苷酸序列的兩種核酸。
同源重組是互補dna序列比對和交換同源區的能力。例如,可以產生含有與被靶向的基因組序列(「模板」)同源的序列的轉基因dna(「供體」),並將其引入生物體中以與生物體的基因組序列進行重組。
在宿主生物體中進行同源重組的能力對於可以在分子遺傳水平上進行的事物具有許多實際意義,並且可用於生產產生所需產物的微生物。根據其本質,同源重組是精確的基因靶向事件;因此,用相同的靶向序列產生的大多數轉基因品系在表型方面將是基本相同的,需要篩選少得多的轉化事件。同源重組也將基因插入事件靶向宿主染色體,潛在地導致優異的遺傳穩定性,即使在沒有遺傳選擇的情況下。
因為同源重組是精確的基因靶向事件,所以其可以用於精確修飾目的基因或區域內的任何核苷酸,只要已經鑑定了足夠的側翼區。因此,同源重組可用於修飾影響rna和/或蛋白質表達的調節序列。其還可以修飾蛋白質編碼區,例如通過修飾酶活性例如底物特異性,結合親和力和km,因此其可以影響宿主細胞的代謝的所需變化。同源重組提供了操縱宿主基因組的有效手段,導致基因靶向,基因轉化,基因缺失,基因重複,基因倒置和交換基因表達調節元件,例如啟動子,增強子和3'utr。因此,同源重組允許用不同的啟動子取代生物體中的內源啟動子。外源啟動子可以提供優於內源啟動子的優點;例如,外源啟動子可以增加或降低可操作連接的基因的轉錄,或者外源啟動子可允許通過有關內源啟動子的不同細胞過程調節轉錄。
同源重組可以通過使用含有內源序列片段的靶向構建體來實現,以「靶向」內源性宿主細胞基因組內的感興趣的基因或區域。這種靶向序列可以位於感興趣的基因或區域的上遊或下遊,或位於感興趣的基因/區域的側翼。這種靶向構建體可以作為環狀質粒dna轉化到宿主細胞中,任選地包括來自質粒的核苷酸序列;線性化dna,例如質粒限制性消化;pcr產物,例如重疊寡核苷酸的擴增;或將dna引入細胞的任何其它方式。在一些情況下,可能有利的是通過用限制酶切割轉基因dna首先暴露轉基因dna(供體dna)內的同源序列,這可以提高重組效率並減少非特異性重組事件的發生。提高重組效率的其它方法包括使用pcr產生含有與被靶向的基因組序列同源的線性末端的轉化轉基因dna。
e.轉化
可以通過任何合適的技術轉化細胞,包括例如生物彈射,電穿孔,玻璃珠轉化和碳化矽晶須轉化。用於將轉基因導入微生物的任何方便的技術都可用於本發明。轉化可以通過例如d.m.morrison的方法(methodsinenzymology68:326(1979)),通過用氯化鈣增加受體細胞對dna的滲透性的方法(mandel&higa,j.molecularbiology,53:159(1970))等來實現。
在產油酵母(例如解脂耶氏酵母)中表達轉基因的實例可以在文獻中找到(bordes等人,j.microbiologicalmethods,70:493(2007);chen等人,appliedmicrobiology&biotechnology48:232(1997))。
用於轉化微生物的載體可以通過已知技術製備。在一個實施方式中,用於在微生物中表達基因的示例性載體包含編碼與啟動子可操作連接的蛋白質的基因。或者,如果啟動子不與感興趣基因可操作地連接,則啟動子可以轉化到細胞中,使得其在載體整合的位點變得可操作地連接到天然基因。另外,微生物可以用兩種載體同時轉化(參見,例如,protist155:381-93(2004))。轉化的細胞可以任選地基於其在未轉化的細胞不會生長的抗生素或其它選擇性標記存在的條件下生長的能力來選擇。
示例性核酸、細胞和方法
1.衍生自解腺嘌呤阿氏酵母和解脂耶氏酵母的核苷酸序列
在一些實施方式中,本發明涉及編碼啟動子的核酸分子。在一些實施方式中,啟動子來源於編碼下述的基因:翻譯延伸因子ef-1α;甘油-3-磷酸脫氫酶;磷酸丙糖異構酶1;果糖-1,6-二磷酸醛縮酶;磷酸甘油酸變位酶;丙酮酸激酶;輸出蛋白exp1;核糖體蛋白s7;醇脫氫酶;磷酸甘油酸激酶;己糖轉運蛋白;一般胺基酸通透酶;絲氨酸蛋白酶;異檸檬酸裂解酶;醯基輔酶a氧化酶;atp-硫酸化酶;己糖激酶;3-磷酸甘油酸脫氫酶;丙酮酸脫氫酶α亞基;丙酮酸脫氫酶β亞基;烏頭酸;烯醇酶;肌動蛋白;多藥耐藥蛋白(abc-轉運蛋白);泛素;gtp酶;質膜na+/pi共轉運蛋白;丙酮酸脫羧酶;植酸酶;或α-澱粉酶。在一些實施方式中,啟動子源自編碼下述的基因:tef1;gpd1;tpi1;fba1;gpm1;pyk1;exp1;rps7;adh1;pgk1;hxt7;gap1;xpr2;icl1;pox;met3;hxk1;ser3;pda1;pdb1;aco1;eno1;act1;mdr1;ubi4;ypt1;pho89;pdc1;phy;或amya。
在一些實施方式中,啟動子來源於編碼下述的基因:磷酸甘油酸激酶;己糖激酶;6-磷酸果糖激酶α亞基;磷酸丙糖異構酶1;3-磷酸甘油酸脫氫酶;丙酮酸激酶1;丙酮酸脫氫酶α亞基;丙酮酸脫氫酶β亞基;烏頭酸;烯醇酶;肌動蛋白;核肌動蛋白相關蛋白;多藥耐藥蛋白(abc-轉運蛋白);泛素;參與er/高爾基體囊泡運輸的親水蛋白;或質膜na+/pi共轉運蛋白。在一些實施方式中,啟動子來源於編碼下述的基因:pgk1;hxk1;pfk1;tpi1;ser3;pyk1;pda1;pdb1;aco1;eno1;act1;arp4;mdr1;ubi4;sly1;或ph089。
在一些實施方式中,核酸包含與seqidno:5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53所示序列具有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高序列同源性的核苷酸序列。在其他實施方式中,核酸包含與seqidno:5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53的子序列具有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高序列同源性的核苷酸序列。在一些實施方式中,核酸包含seqidno:5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53中所示的核苷酸序列。在其他實施方式中,核酸包含由seqidno:5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53的子序列組成的核苷酸序列。在某些實施方式中,所述子序列保留啟動子活性。在某些實施方式中,子序列保留全長核苷酸序列的至少1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、16%、17%、18%、19%、20%、21%、22%、23%、24%、25%、26%、27%、28%、29%、30%、31%、32%、33%、34%、35%、36%、37%、38%、39%、40%、41%、42%、43%、44%、45%、46%、47%、48%、49%、50%、51%、52%、53%、54%、55%、56%、57%、58%、59%、60%、61%、62%、63%、64%、65%、66%、67%、68%、69%、70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的啟動子活性。在某些實施方案中,子序列保留了全長核苷酸序列的啟動子活性。
在一些實施方案中,子序列為50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個核苷酸長或更長。在一些實施方案中,子序列包含seqidno:5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53中任意位置處的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸。在一些實施方案中,子序列包含seqidno:5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53的3』端的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸。
在一些實施方案中,核酸包含與seqidno:5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53中任意位置的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸具有至少70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高序列同源性的核苷酸序列。在一些實施方案中,核酸包含由seqidno:5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53中任意位置的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸組成的核苷酸序列。在某些實施方式中,核苷酸序列保留啟動子活性。在某些實施方式中,核苷酸序列保留全長核苷酸序列的至少1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、16%、17%、18%、19%、20%、21%、22%、23%、24%、25%、26%、27%、28%、29%、30%、31%、32%、33%、34%、35%、36%、37%、38%、39%、40%、41%、42%、43%、44%、45%、46%、47%、48%、49%、50%、51%、52%、53%、54%、55%、56%、57%、58%、59%、60%、61%、62%、63%、64%、65%、66%、67%、68%、69%、70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的啟動子活性。在某些實施方案中,核苷酸序列保留了全長核苷酸序列的啟動子活性。
在一些實施方案中,核酸包含與seqidno:5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53中的3』端的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸具有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高序列同源性的核苷酸序列。在一些實施方案中,核酸包含由seqidno:5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53中的3』端的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸組成的核苷酸序列。在某些實施方式中,核苷酸序列保留啟動子活性。在某些實施方式中,核苷酸序列保留全長核苷酸序列的至少1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、16%、17%、18%、19%、20%、21%、22%、23%、24%、25%、26%、27%、28%、29%、30%、31%、32%、33%、34%、35%、36%、37%、38%、39%、40%、41%、42%、43%、44%、45%、46%、47%、48%、49%、50%、51%、52%、53%、54%、55%、56%、57%、58%、59%、60%、61%、62%、63%、64%、65%、66%、67%、68%、69%、70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的啟動子活性。在某些實施方案中,核苷酸序列保留了全長核苷酸序列的啟動子活性。
2.包含源自解腺嘌呤阿氏酵母的啟動子的載體
在一些實施方案中,本發明涉及包含編碼來自解腺嘌呤阿氏酵母的啟動子的核苷酸序列的載體,其中所述啟動子來源於編碼下述的基因:翻譯延伸因子ef-1α;甘油-3-磷酸脫氫酶;磷酸丙糖異構酶1;果糖-1,6-二磷酸醛縮酶;磷酸甘油酸變位酶;丙酮酸激酶;輸出蛋白exp1;核糖體蛋白s7;醇脫氫酶;磷酸甘油酸激酶;己糖轉運蛋白;一般胺基酸通透酶;絲氨酸蛋白酶;異檸檬酸裂解酶;醯基輔酶a氧化酶;atp-硫酸化酶;己糖激酶;3-磷酸甘油酸脫氫酶;丙酮酸脫氫酶α亞基;丙酮酸脫氫酶β亞基;烏頭酸;烯醇酶;肌動蛋白;多藥耐藥蛋白(abc-轉運蛋白);泛素;gtp酶;質膜na+/pi共轉運蛋白;丙酮酸脫羧酶;植酸酶;或α-澱粉酶。
在一些實施方案中,載體是質粒。在其他實施方案中,載體是線性dna分子。
在一些實施方案中,載體包含編碼來自解腺嘌呤阿氏酵母的啟動子的核苷酸序列,其中所述啟動子源自編碼下述的基因:tef1;gpd1;tpi1;fba1;gpm1;pyk1;exp1;rps7;adh1;pgk1;hxt7;gap1;xpr2;icl1;pox;met3;hxk1;ser3;pda1;pdb1;aco1;eno1;act1;mdr1;ubi4;ypt1;pho89;pdc1;phy;或amya。
在一些實施方案中,核苷酸序列與seqidno:5、6、7、8、9、10、11、12、13、14、15、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53所示序列具有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高序列同源性。在其他實施方案中,核苷酸序列與seqidno:5、6、7、8、9、10、11、12、13、14、15、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53的子序列具有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高序列同源性。在一些實施方案中,核苷酸序列包含seqidno:5、6、7、8、9、10、11、12、13、14、15、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53所示序列。在其他實施方案中,核苷酸序列包含seqidno:5、6、7、8、9、10、11、12、13、14、15、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53的子序列。在某些實施方案中,所述子序列保留啟動子活性。在其他實施方式中,子序列保留全長核苷酸序列的至少1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、16%、17%、18%、19%、20%、21%、22%、23%、24%、25%、26%、27%、28%、29%、30%、31%、32%、33%、34%、35%、36%、37%、38%、39%、40%、41%、42%、43%、44%、45%、46%、47%、48%、49%、50%、51%、52%、53%、54%、55%、56%、57%、58%、59%、60%、61%、62%、63%、64%、65%、66%、67%、68%、69%、70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的啟動子活性。在某些實施方案中,子序列保留了全長核苷酸序列的啟動子活性。
在一些實施方案中,子序列為50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個核苷酸長或更長。在一些實施方案中,子序列包含seqidno:5、6、7、8、9、10、11、12、13、14、15、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53中任意位置處的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸。在一些實施方案中,子序列包含seqidno:5、6、7、8、9、10、11、12、13、14、15、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53中的3』端的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸。
在一些實施方案中,核苷酸序列與seqidno:5、6、7、8、9、10、11、12、13、14、15、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53中任意位置的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸具有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高序列同源性。在一些實施方案中,核苷酸序列包含seqidno:5、6、7、8、9、10、11、12、13、14、15、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53中任意位置處的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸。在某些實施方式中,核苷酸序列保留啟動子活性。在某些實施方式中,核苷酸序列保留全長核苷酸序列的至少1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、16%、17%、18%、19%、20%、21%、22%、23%、24%、25%、26%、27%、28%、29%、30%、31%、32%、33%、34%、35%、36%、37%、38%、39%、40%、41%、42%、43%、44%、45%、46%、47%、48%、49%、50%、51%、52%、53%、54%、55%、56%、57%、58%、59%、60%、61%、62%、63%、64%、65%、66%、67%、68%、69%、70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的啟動子活性。在某些實施方案中,核苷酸序列保留了全長核苷酸序列的啟動子活性。
在一些實施方案中,核苷酸序列與seqidno:5、6、7、8、9、10、11、12、13、14、15、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53的3』端的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸具有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高序列同源性。在一些實施方案中,核苷酸序列包含seqidno:5、6、7、8、9、10、11、12、13、14、15、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53的3』端的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸。在某些實施方式中,核苷酸序列保留啟動子活性。在某些實施方式中,核苷酸序列保留全長核苷酸序列的至少1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、16%、17%、18%、19%、20%、21%、22%、23%、24%、25%、26%、27%、28%、29%、30%、31%、32%、33%、34%、35%、36%、37%、38%、39%、40%、41%、42%、43%、44%、45%、46%、47%、48%、49%、50%、51%、52%、53%、54%、55%、56%、57%、58%、59%、60%、61%、62%、63%、64%、65%、66%、67%、68%、69%、70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的啟動子活性。在某些實施方案中,核苷酸序列保留了全長核苷酸序列的啟動子活性。
在一些實施方案中,載體還包含基因,並且基因和啟動子可操作地連接。在其它實施方案中,設計載體使得在用載體轉化細胞時啟動子與基因可操作地連接。
3.包含源自解脂耶氏酵母的啟動子的載體
在一些實施方案中,本發明涉及包含編碼來自解脂耶氏酵母的啟動子的核苷酸序列的載體,其中所述啟動子來源於編碼下述的基因:磷酸甘油酸激酶;己糖激酶;6-磷酸果糖激酶α亞基;磷酸丙糖異構酶1;3-磷酸甘油酸脫氫酶;丙酮酸激酶1;丙酮酸脫氫酶α亞基;丙酮酸脫氫酶β亞基;烏頭酸;烯醇酶;肌動蛋白;核肌動蛋白相關蛋白;多藥耐藥蛋白(abc-轉運蛋白);泛素;參與er/高爾基體囊泡運輸的親水蛋白;或質膜na+/pi共轉運蛋白。
在一些實施方案中,載體是質粒。在其他實施方案中,載體是線性dna分子。
在一些實施方案中,載體包含編碼來自解脂耶氏酵母的啟動子的核苷酸序列,其中所述啟動子衍生自編碼下述的基因:pgk1;hxk1;pfk1;tpi1;ser3;pyk1;pda1;pdb1;aco1;eno1;act1;arp4;mdr1;ubi4;sly1;或pho89。
在一些實施方案中,核苷酸序列與seqidno:16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33或34所示序列具有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高序列同源性。在其他實施方案中,核苷酸序列與seqidno:16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33或34的子序列具有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高序列同源性。在一些實施方式中,核苷酸序列包含seqidno:16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33或34所示的序列。在其他實施方式中,核苷酸序列包含seqidno:16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33或34的子序列。在某些實施方案中,所述子序列保留啟動子活性。在某些實施方式中,子序列保留全長核苷酸序列的至少1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、16%、17%、18%、19%、20%、21%、22%、23%、24%、25%、26%、27%、28%、29%、30%、31%、32%、33%、34%、35%、36%、37%、38%、39%、40%、41%、42%、43%、44%、45%、46%、47%、48%、49%、50%、51%、52%、53%、54%、55%、56%、57%、58%、59%、60%、61%、62%、63%、64%、65%、66%、67%、68%、69%、70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的啟動子活性。在某些實施方案中,子序列保留了全長核苷酸序列的啟動子活性。
在某些實施方案中,子序列為50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個核苷酸長或更長。在一些實施方案中,子序列包含seqidno:16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33或34中任意位置處的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸。在一些實施方案中,子序列包含seqidno:16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33或34的3』端的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸。
在一些實施方案中,核苷酸序列與seqidno:16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33或34中任意位置的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸具有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高序列同源性。在一些實施方案中,核苷酸序列包含seqidno:16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33或34中任意位置處的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸。在某些實施方式中,核苷酸序列保留啟動子活性。在某些實施方式中,核苷酸序列保留全長核苷酸序列的至少1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、16%、17%、18%、19%、20%、21%、22%、23%、24%、25%、26%、27%、28%、29%、30%、31%、32%、33%、34%、35%、36%、37%、38%、39%、40%、41%、42%、43%、44%、45%、46%、47%、48%、49%、50%、51%、52%、53%、54%、55%、56%、57%、58%、59%、60%、61%、62%、63%、64%、65%、66%、67%、68%、69%、70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的啟動子活性。在某些實施方案中,核苷酸序列保留了全長核苷酸序列的啟動子活性。
在一些實施方案中,核苷酸序列與seqidno:16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33或34的3』端的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸具有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高序列同源性。在一些實施方案中,核苷酸序列包含seqidno:16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33或34的3』端的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸。在某些實施方式中,核苷酸序列保留啟動子活性。在某些實施方式中,核苷酸序列保留全長核苷酸序列的至少1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、16%、17%、18%、19%、20%、21%、22%、23%、24%、25%、26%、27%、28%、29%、30%、31%、32%、33%、34%、35%、36%、37%、38%、39%、40%、41%、42%、43%、44%、45%、46%、47%、48%、49%、50%、51%、52%、53%、54%、55%、56%、57%、58%、59%、60%、61%、62%、63%、64%、65%、66%、67%、68%、69%、70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的啟動子活性。在某些實施方案中,核苷酸序列保留了全長核苷酸序列的啟動子活性。
4.包含源自解腺嘌呤阿氏酵母的啟動子的轉化的細胞和用源自解腺嘌呤阿氏酵母的啟動子轉化細胞的方法
在某些方面,本發明涉及包含遺傳修飾的轉化的細胞,其中所述遺傳修飾是用編碼來自解腺嘌呤阿氏酵母的啟動子的核酸轉化。在一些方面,本發明涉及在細胞中表達基因的方法,包括用編碼來自解腺嘌呤阿氏酵母的啟動子的核酸轉化親本細胞。在一些實施方案中,核酸包含基因,並且基因和啟動子可操作地連接。在其他實施方案中,設計核酸使得啟動子在轉化親本細胞後變得可操作地連接到基因。
在一些實施方案中,啟動子來源於編碼下述的基因:翻譯延伸因子ef-1α;甘油-3-磷酸脫氫酶;磷酸丙糖異構酶1;果糖-1,6-二磷酸醛縮酶;磷酸甘油酸變位酶;丙酮酸激酶;輸出蛋白exp1;核糖體蛋白s7;醇脫氫酶;磷酸甘油酸激酶;己糖轉運蛋白;一般胺基酸通透酶;絲氨酸蛋白酶;異檸檬酸裂解酶;醯基輔酶a氧化酶;atp-硫酸化酶;己糖激酶;3-磷酸甘油酸脫氫酶;丙酮酸脫氫酶α亞基;丙酮酸脫氫酶β亞基;烏頭酸;烯醇酶;肌動蛋白;多藥耐藥蛋白(abc-轉運蛋白);泛素;gtp酶;質膜na+/pi共轉運蛋白;丙酮酸脫羧酶;植酸酶;或α-澱粉酶。在一些實施方案中,啟動子源自編碼下述的基因:tef1;gpd1;tpi1;fba1;gpm1;pyk1;exp1;rps7;adh1;pgk1;hxt7;gap1;xpr2;icl1;pox;met3;hxk1;ser3;pda1;pdb1;aco1;eno1;act1;mdr1;ubi4;ypt1;pho89;pdc1;phy;或amya。
在一些實施方案中,核酸包含與seqidno:5、6、7、8、9、10、11、12、13、14、15、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53所示序列具有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高序列同源性的核苷酸序列。在其他實施方案中,核酸包含與seqidno:5、6、7、8、9、10、11、12、13、14、15、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53的子序列具有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高序列同源性的核苷酸序列。在一些實施方案中,核酸包含seqidno:5、6、7、8、9、10、11、12、13、14、15、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53所示的核苷酸序列。在其他實施方案中,核酸包含由seqidno:5、6、7、8、9、10、11、12、13、14、15、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53的子序列組成的核苷酸序列。在某些實施方案中,所述子序列保留啟動子活性。在某些實施方式中,子序列保留全長核苷酸序列的至少1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、16%、17%、18%、19%、20%、21%、22%、23%、24%、25%、26%、27%、28%、29%、30%、31%、32%、33%、34%、35%、36%、37%、38%、39%、40%、41%、42%、43%、44%、45%、46%、47%、48%、49%、50%、51%、52%、53%、54%、55%、56%、57%、58%、59%、60%、61%、62%、63%、64%、65%、66%、67%、68%、69%、70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的啟動子活性。在某些實施方案中,子序列保留了全長核苷酸序列的啟動子活性。
在一些實施方案中,子序列為50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個核苷酸長或更長。在一些實施方案中,子序列包含seqidno:5、6、7、8、9、10、11、12、13、14、15、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53中任意位置處的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸。在一些實施方案中,子序列包含seqidno:5、6、7、8、9、10、11、12、13、14、15、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53中的3』端的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸。
在一些實施方案中,核酸包含與seqidno:5、6、7、8、9、10、11、12、13、14、15、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53中任意位置的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸具有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高序列同源性的核苷酸序列。在一些實施方案中,核酸包含由seqidno:5、6、7、8、9、10、11、12、13、14、15、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53中任意位置處的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸組成的核苷酸序列。在某些實施方式中,核苷酸序列保留啟動子活性。在某些實施方式中,核苷酸序列保留全長核苷酸序列的至少1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、16%、17%、18%、19%、20%、21%、22%、23%、24%、25%、26%、27%、28%、29%、30%、31%、32%、33%、34%、35%、36%、37%、38%、39%、40%、41%、42%、43%、44%、45%、46%、47%、48%、49%、50%、51%、52%、53%、54%、55%、56%、57%、58%、59%、60%、61%、62%、63%、64%、65%、66%、67%、68%、69%、70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的啟動子活性。在某些實施方案中,核苷酸序列保留了全長核苷酸序列的啟動子活性。
在一些實施方案中,核酸包含與seqidno:5、6、7、8、9、10、11、12、13、14、15、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53的3』端的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸具有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高序列同源性的核苷酸序列。在一些實施方案中,核酸包含由seqidno:5、6、7、8、9、10、11、12、13、14、15、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52或53的3』端的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸組成的核苷酸序列。在某些實施方式中,核苷酸序列保留啟動子活性。在某些實施方式中,核苷酸序列保留全長核苷酸序列的至少1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、16%、17%、18%、19%、20%、21%、22%、23%、24%、25%、26%、27%、28%、29%、30%、31%、32%、33%、34%、35%、36%、37%、38%、39%、40%、41%、42%、43%、44%、45%、46%、47%、48%、49%、50%、51%、52%、53%、54%、55%、56%、57%、58%、59%、60%、61%、62%、63%、64%、65%、66%、67%、68%、69%、70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的啟動子活性。在某些實施方案中,核苷酸序列保留了全長核苷酸序列的啟動子活性。
5.包含源自解脂耶氏酵母的啟動子的轉化的細胞和用源自解脂耶氏酵母的啟動子轉化細胞的方法
在某些方面,本發明涉及包含遺傳修飾的轉化的細胞,其中所述遺傳修飾是用編碼來自解脂耶氏酵母的啟動子的核酸轉化。在一些方面,本發明涉及在細胞中表達基因的方法,包括用編碼來自解脂耶氏酵母的啟動子的核酸轉化親本細胞。在一些實施方案中,核酸包含基因,並且基因和啟動子可操作地連接。在其他實施方案中,設計核酸使得啟動子在轉化親本細胞後變得可操作地連接到基因。
在一些實施方案中,啟動子來源於編碼下述的基因:磷酸甘油酸激酶;己糖激酶;6-磷酸果糖激酶α亞基;磷酸丙糖異構酶1;3-磷酸甘油酸脫氫酶;丙酮酸激酶1;丙酮酸脫氫酶α亞基;丙酮酸脫氫酶β亞基;烏頭酸;烯醇酶;肌動蛋白;核肌動蛋白相關蛋白;多藥耐藥蛋白(abc-轉運蛋白);泛素;參與er/高爾基體囊泡運輸的親水蛋白;或質膜na+/pi共轉運蛋白。在一些實施方案中,啟動子來源於編碼下述的基因:pgk1;hxk1;pfk1;tpi1;ser3;pyk1;pda1;pdb1;aco1;eno1;act1;arp4;mdr1;ubi4;sly1;或pho89。
在一些實施方案中,核酸包含與seqidno:16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33或34所示序列具有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高序列同源性的核苷酸序列。在其他實施方案中,核酸包含與seqidno:16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33或34的子序列具有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高序列同源性的核苷酸序列。在一些實施方式中,核酸包含seqidno:16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33或34所示的核苷酸序列。在其他實施方式中,核酸包含由seqidno:16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33或34的子序列組成的核苷酸序列。在某些實施方案中,所述子序列保留啟動子活性。在某些實施方式中,子序列保留全長核苷酸序列的至少1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、16%、17%、18%、19%、20%、21%、22%、23%、24%、25%、26%、27%、28%、29%、30%、31%、32%、33%、34%、35%、36%、37%、38%、39%、40%、41%、42%、43%、44%、45%、46%、47%、48%、49%、50%、51%、52%、53%、54%、55%、56%、57%、58%、59%、60%、61%、62%、63%、64%、65%、66%、67%、68%、69%、70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的啟動子活性。在某些實施方案中,子序列保留了全長核苷酸序列的啟動子活性。
在某些實施方案中,子序列為50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個核苷酸長或更長。在一些實施方案中,子序列包含seqidno:16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33或34中任意位置處的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸。在一些實施方案中,子序列包含seqidno:16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33或34的3』端的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸。
在一些實施方案中,核酸包含與seqidno:16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33或34中任意位置的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸具有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高序列同源性的核苷酸序列。在一些實施方案中,核酸包含由seqidno:16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33或34中任意位置處的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸組成的核苷酸序列。在某些實施方式中,核苷酸序列保留啟動子活性。在某些實施方式中,核苷酸序列保留全長核苷酸序列的至少1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、16%、17%、18%、19%、20%、21%、22%、23%、24%、25%、26%、27%、28%、29%、30%、31%、32%、33%、34%、35%、36%、37%、38%、39%、40%、41%、42%、43%、44%、45%、46%、47%、48%、49%、50%、51%、52%、53%、54%、55%、56%、57%、58%、59%、60%、61%、62%、63%、64%、65%、66%、67%、68%、69%、70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的啟動子活性。在某些實施方案中,核苷酸序列保留了全長核苷酸序列的啟動子活性。
在一些實施方案中,核酸包含與seqidno:16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33或34的3』端的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸具有至少約70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或更高序列同源性的核苷酸序列。在一些實施方案中,核酸包含由seqidno:16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33或34的3』端的50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、105、110、115、120、125、130、135、140、145、150、155、160、165、170、175、180、185、190、195、200、205、210、215、220、225、230、235、240、245、250、255、260、265、270、275、280、285、290、295或300個連續核苷酸組成的核苷酸序列。在某些實施方式中,核苷酸序列保留啟動子活性。在一些實施方式中,核苷酸序列保留全長核苷酸序列的至少1%、2%、3%、4%、5%、6%、7%、8%、9%、10%、11%、12%、13%、14%、15%、16%、17%、18%、19%、20%、21%、22%、23%、24%、25%、26%、27%、28%、29%、30%、31%、32%、33%、34%、35%、36%、37%、38%、39%、40%、41%、42%、43%、44%、45%、46%、47%、48%、49%、50%、51%、52%、53%、54%、55%、56%、57%、58%、59%、60%、61%、62%、63%、64%、65%、66%、67%、68%、69%、70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的啟動子活性。在某些實施方案中,核苷酸序列保留了全長核苷酸序列的啟動子活性。
6.細胞,親本細胞和轉化的細胞的種類
細胞可以選自藻類,細菌,黴菌,真菌,植物和酵母。在一些實施方式中,細胞選自下組:阿氏菌屬(arxula)、麴黴屬(aspegillus)、奧蘭氏菌屬(aurantiochytrium)、念珠菌屬(candida)、麥角菌屬(claviceps)、隱球菌屬(cryptococcus)、小坎寧安黴屬(cunninghamella)、地黴屬(geotrichum)、漢遜酵母屬(hansenula)、克魯維酵母屬(kluyveromyces)、柯達酵母(kodamaea)、白冬孢酵母屬(leucosporidiella)、油脂酵母屬(lipomyces)、被孢黴屬(mortierella)、歐格氏黴屬(ogataea)、畢赤酵母屬(pichia)、原囊藻屬(prototheca)、根黴屬(rhizopus)、紅冬孢酵母屬(rhodosporidium)、紅酵母屬(rhodotorula)、酵母菌屬(saccharomyces)、裂殖酵母屬(schizosaccharomyces)、銀耳屬(tremella)、絲孢酵母屬(trichosporon)、威克漢姆酵母屬(wickerhamomyces)和耶氏酵母屬(yarrowia)。在某些實施方式中,細胞選自下組:解腺嘌呤阿氏酵母(arxulaadeninivorans)、黑麴黴(aspergillusniger)、米麴黴(aspergillusorzyae)、土麴黴(aspergillusterreus)、裂殖壺奧蘭氏菌(aurantiochytriumlimacinum)、產朊假絲酵母(candidautilis)、麥角菌(clavicepspurpurea)、淺白隱球酵母(cryptococcusalbidus)、彎曲隱球菌(cryptococcuscurvatus)、拉米隱球菌(cryptococcusramirezgomezianus)、地生隱球菌(cryptococcusterreus)、威氏隱球菌(cryptococcuswieringae)、刺孢小坎寧安黴(cunninghamellaechinulata)、貼梗海棠小坎寧安黴(cunninghamellajaponica)、發酵性地黴(geotrichumfermentans)、多形漢森酵母(hansenulapolymorpha)、乳酸克魯維酵母(kluyveromyceslactis)、馬克斯克魯維酵母(kluyveromycesmarxianus)、奧默柯達酵母(kodamaeaohmeri)、克雷氏白冬孢酵母(leucosporidiellacreatinivora)、產油油脂酵母(lipomyceslipofer)、斯達氏油脂酵母(lipomycesstarkeyi)、子囊菌油脂酵母(lipomycestetrasporus)、深黃被孢黴(mortierellaisabellina)、高山被孢黴(mortierellaalpina)、馬兜鈴歐格氏黴(ogataeapolymorpha)、塞佛式畢赤酵母(pichiaciferrii)、季氏畢赤氏酵母(pichiaguilliermondii)、巴斯德畢赤酵母(pichiapastoris)、葉柄畢赤酵母(pichiastipites)、小型原藻(protothecazopfii)、隱根根黴(rhizopusarrhizus)、巴氏紅冬孢酵母(rhodosporidiumbabjevae)、圓紅冬孢酵母(rhodosporidiumtoruloides)、帕魯氏紅冬孢酵母(rhodosporidiumpaludigenum)、粘紅酵母(rhodotorulaglutinis)、膠紅酵母(rhodotorulamucilaginosa)、釀酒酵母(saccharomycescerevisiae)、粟酒裂殖酵母(schizosaccharomycespombe)、腦狀銀耳(tremellaenchepala)、皮狀絲孢酵母(trichosporoncutaneum)、發酵性絲孢酵母(trichosporonfermentans)、塞佛式威克漢姆酵母(wickerhamomycesciferrii)、和解脂耶氏酵母(yarrowialipolytica)。因此,細胞可以是解脂耶氏酵母。細胞可以是解腺嘌呤阿氏酵母。
通過以下實施例進一步說明本說明書,這些實施例不應被解釋為以任何方式構成限制。所有引用文獻的內容(包括本申請通篇引用的文獻參考文獻,授權專利,公開的專利申請和genbank登錄號)通過引用明確地併入本文。當通過引用併入本文的文獻中的術語定義與本文所使用的定義衝突時,以本文使用的定義為主。
實施例
實施例1:測序解腺嘌呤阿氏酵母基因組和鑑定啟動子序列
鑑定並篩選解腺嘌呤阿氏酵母啟動子。首先,為了獲得選定基因的啟動子序列,解腺嘌呤阿氏酵母ns252株(atcc76597)的基因組進行測序,並通過合成基因組公司(syntheticgenomicsinc.)(美國加州)注釋。
基於關於酵母和真菌中常用的啟動子的公開數據列舉了可能特別用於驅動轉錄的啟動子。例如,鑑定和篩選涉及重要代謝途徑例如糖酵解的基因的啟動子。可特別用於驅動轉錄的解腺嘌呤阿氏酵母啟動子序列示於seqidno:5-15和35-53中,並列於下表i中。
表i,解腺嘌呤阿氏酵母啟動子
實施例2:解脂耶氏酵母啟動子的鑑定
解脂耶氏酵母基因組在kegg資料庫中是公開可獲得的,但是每個解脂耶氏酵母啟動子的精確序列尚未被鑑定或驗證。
基於關於酵母和真菌中常用的啟動子的公開數據列舉了可能特別用於驅動轉錄的啟動子。例如,鑑定和篩選涉及重要代謝途徑例如糖酵解的基因的啟動子。可特別用於驅動轉錄的解脂耶氏酵母啟動子序列示於seqidno:16-34中並列於下表ii中。
表ii.解脂耶氏酵母啟動子
*表示啟動子和連續轉錄序列。
實施例3:驗證解脂耶氏酵母啟動子序列並評估其使用轉化酶報告物基因的強度
使用釀酒酵母轉化酶基因suc2(seqidno:1)作為報告物,在解脂耶氏酵母菌株ns18中篩選選擇的解脂耶氏酵母啟動子的功能性和強度。轉化酶基因既用作選擇標記,篩選用於在蔗糖上生長的細胞,又用作用於定量評價啟動子強度的報告物。另外,通過實施例4中描述的dns試驗來測量啟動子強度。
釀酒酵母轉化酶基因在解脂耶氏酵母菌株ns18中在十四種不同的解脂耶氏酵母啟動子和相同的ter1終止子的控制下表達。使用含有與轉化酶基因的5'末端同源的30-35個鹼基對的反向引物,從宿主解脂耶氏酵母菌株ns18(從nrrl#yb-392獲得)的基因組dna擴增啟動子,以允許同源重組啟動子和轉化酶dna。從pnc303質粒擴增轉化酶核苷酸序列和ter1終止子(圖1)。將每個擴增的啟動子的dna與擴增的轉化酶-ter1片段的dna組合,並使用chen等人描述的轉化方案轉化到ns18菌株中(appliedmicrobiology&biotechnology48:232-35(1997))。啟動子dna片段和轉化酶-ter1dna片段在體內組裝並隨機整合到宿主解脂耶氏酵母菌株ns18的基因組中。
將轉化體鋪板,並在具有2%蔗糖的ynb板上選擇,並通過實施例4中所述的dns試驗篩選轉化酶活性。就每個啟動子分析了幾個轉化體。dns試驗的結果顯示在圖2中。大多數啟動子在轉化體之間顯示出顯著的集落變異,可能是由於轉化酶的整合位點對表達的影響。圖2證明所有十四個啟動子都允許轉化酶表達。對於具有較低表達水平和較低集落數(pr39,pr41,pr43,pr45和pr46)的那些啟動子,其轉化體在ynb+2%蔗糖選擇性平板上生長的事實表明啟動子能夠實現轉化酶的充分轉錄,以在蔗糖上生長。
實施例4:二硝基水楊酸試驗
將細胞在30℃下在ypd瓊脂平板上溫育1至2天。來自每個瓊脂平板的細胞用於在96孔板的孔中接種300μl培養基。96孔板用多孔蓋覆蓋並在inforsmultitronatr振蕩器中在30℃,70-90%溼度和900rpm下孵育。
將96孔板在3000rpm離心2分鐘。在新96孔板中,將50μl上清液加入到150μl含有40mm乙酸鈉,ph為4.5-5的50mm蔗糖中,並在30℃溫育30-60分鐘。
在新96孔板中,將30μl蔗糖/上清液混合物加入到60μldns試劑(1%二硝基水楊酸,30%酒石酸鈉鉀,0.4mnaoh)中並用pcr膜覆蓋。將板在熱循環器中加熱至99℃持續5分鐘。
然後將70μl混合物轉移至康寧96孔透明平底板中,在spectramaxm2分光光度計(分子裝置公司(moleculardevices))上監測540nm處的吸光度。
實施例5:利用hygr報告物基因驗證解腺嘌呤阿氏酵母啟動子序列
實施例3和4中所述的轉化酶報告物試驗不適用於解腺嘌呤阿氏酵母菌株ns252,因為該菌株具有在蔗糖上生長的天然能力。因此,大腸桿菌hygr基因(seqidno:2)用作解腺嘌呤阿氏酵母中的報告物並且用作通過潮黴素b(hyg)選擇的轉化選擇標記。在十一個選擇的啟動子和相同的終止子的控制下,hygr基因在解脂耶氏酵母和解腺嘌呤阿氏酵母中表達(圖4和5)。圖3顯示了使用來自釀酒酵母的fba1啟動子(seqidno:4)作為示例,用於在解脂耶氏酵母和解腺嘌呤阿氏酵母中過表達hygr基因的表達構建體pnc161的圖譜。fba1啟動子也用作陽性對照,因為它可以驅動解脂耶氏酵母和解腺嘌呤阿氏酵母中的hygr表達。所有hygr表達構建體與pnc161相同,除了啟動子序列。用水轉化細胞作為陰性對照。
在通過paci/pmei限制性消化轉化之前將表達構建體線性化。每個線性表達構建體包括hygr基因的表達盒和不同的啟動子。將表達構建體隨機整合到解脂耶氏酵母菌株ns18和解腺嘌呤阿氏酵母菌株ns252的基因組中,使用chen等人所述的轉化方案(appliedmicrobiology&biotechnology48:232-35(1997))。
在具有300μg/mlhyg的ypd平板上選擇轉化體,並基於在平板上生長的菌落的大小篩選啟動子強度。每個轉化體的ypd+hyg平板的照片示於圖4和5中。解腺嘌呤阿氏酵母的轉化效率遠低於解脂耶氏酵母,可能是因為轉化方案針對解脂耶氏酵母優化而不是解腺嘌呤阿氏酵母。轉化體的數目在不同構建體之間不同,可能是由於在不同轉化期間使用的dna量略有不同,儘管啟動子的強度可能導致這種變化。圖4和5仍然證明所有11種啟動子在解脂耶氏酵母和解腺嘌呤阿氏酵母中有功能。
不同的解腺嘌呤阿氏酵母啟動子的解腺嘌呤阿氏酵母轉化體的菌落大小沒有顯著變化,表明當與hygr報告物連接時天然的解腺嘌呤阿氏酵母啟動子具有相似效率。同時,解脂耶氏酵母菌落的大小顯著變化。該數據可以表明不同的解腺嘌呤阿氏酵母啟動子與解腺嘌呤阿氏酵母調節因子類似地相互作用,並與解脂耶氏酵母調節因子不同地相互作用。
在解腺嘌呤阿氏酵母和解脂耶氏酵母中篩選的每個啟動子能夠在解腺嘌呤阿氏酵母和解脂耶氏酵母中驅動基因表達,這表明seqidno:6-53中鑑定的所有啟動子在所有酵母中都是有功能的。
實施例6:使用dga2作為報告物評估解腺嘌呤阿氏酵母和解脂耶氏酵母啟動子序列的強度
選擇通過實施例3-5中所述的轉化酶和hygr試驗評估的最有效的啟動子,用於在解脂耶氏酵母中使用二醯基甘油醯基轉移酶dga1作為報告物進一步定量測試。dga1蛋白催化三醯基甘油(tag)合成的最後步驟,因此dga1是脂質合成途徑中的關鍵組分。dga1在解脂耶氏酵母中的過表達顯著增加其脂質生產效率。因此,在dga1試驗中啟動子的強度與脂質生產效率相關。
編碼來自紅冬孢酵母菌的dga1的基因(seqidno:3)在解脂耶氏酵母中在十二個選定的啟動子和相同的終止子的控制下表達。圖6顯示了作為示例的表達構建體pnc336的圖譜;該構建體用於用來自解腺嘌呤阿氏酵母的tef1啟動子(seqidno:5)過表達dga1。所有其他dga1表達構建體與pnc336相同,除了它們的啟動子序列。
在通過paci/noti限制性消化轉化之前將表達構建體線性化。每個線性表達構建體包括編碼dga1的基因的表達盒和用於通過諾爾絲菌素(nat)進行選擇的用作標記物的nat1基因的表達盒。將表達構建體隨機整合到解脂耶氏酵母菌株ns18的基因組中,使用chen等人所述的轉化方案(appliedmicrobiology&biotechnology48:232-35(1997))。在具有500μg/mlnat的ypd平板上選擇轉化體,並通過實施例7中所述的螢光染色脂質試驗來篩選累積脂質的能力。
使用實施例7中描述的螢光染色脂質試驗分析12個轉化體的每個表達構建體(圖7和8)。大多數構建體在轉化體之間顯示出顯著的集落變異,這可能是由於在僅獲得功能性nat1盒的一些轉化體中缺乏功能性dga1表達盒,或者dga1表達盒整合位點對dga1表達的負效應。然而,圖7和8證明所有十二種啟動子增加解脂耶氏酵母的脂質含量,這證實了每種啟動子用於增加脂質產生的功能性並再次確認它們驅動基因表達的功能性。
實施例7:脂質螢光試驗
將含有0.5gl尿素,1.5g/l酵母提取物,0.85g/l酪蛋白胺基酸,1.7glynb(無胺基酸和硫酸銨),100g/l葡萄糖和5.11gl鄰苯二甲酸氫鉀(25mm)的過濾滅菌的培養基裝入高壓滅菌的多孔板的每個孔中。針對24孔板,每孔使用1.5ml培養基,針對96孔板,每孔使用300μl培養基。或者,使用酵母培養物在高壓滅菌的250ml燒瓶中接種50ml滅菌的培養基。使用在30℃下在ypd瓊脂平板上溫育1-2天的酵母菌株接種多壁板的每個孔。
多孔板用多孔蓋覆蓋並在inforsmultitronatr振蕩器中在30℃,70-90%溼度和900rpm下孵育。或者,用鋁箔覆蓋燒瓶,並在newbrunswickscientific燒瓶中於30℃,70-90%溼度和900rpm下孵育。96小時後,將20μl100%乙醇加入到在分析微量培養板中的20μl細胞中,並在4℃下孵育30分鐘。然後將20μl細胞/乙醇混合物加入到costar96孔、黑色、透明底板中的80μl預混合的溶液中並覆蓋有透明密封物,該預混合的溶液含有50μl1m碘化鉀,1mmμlbodipy493/503,0.5μl100%dmso,1.5μl60%peg4000和27μl水。30℃下用spectramaxm2分子光度計(分子裝置公司)動力學試驗監測bodipy螢光,並通過用螢光除以600nm處的吸光度來標準化。
實施例8:解腺嘌呤阿氏酵母啟動子增加酵母中的脂質生產
選擇通過實施例5中所述的hygr試驗評估的啟動子,以篩選來自解腺嘌呤阿氏酵母中的各種生物體的編碼二醯基甘油醯基轉移酶(dga)的基因,從而增加脂質產生。dga蛋白催化三醯基甘油(tag)合成的最後步驟,因此dga是脂質合成途徑中的關鍵組分。
編碼來自各種宿主生物體的dga1,dga2和dga3的基因在解腺嘌呤阿氏酵母菌株ns252中在解腺嘌呤阿氏酵母adh1啟動子(seqidno:13)和cyc1終止子控制下表達,所述宿主生物體例如解腺嘌呤阿氏酵母、解脂耶氏酵母、紅冬孢酵母菌、斯達氏油脂酵母、土麴黴、麥角菌、裂殖壺奧蘭氏菌、球毛殼菌(chaetomiumglobosum)、牧草紅酵母(rhodotorulagraminis)、花葯黑粉菌(microbotryumviolaceum)、禾柄鏽菌(pucciniagraminis)、密粘褶菌(gloeophyllumtrabeum)、倒卵形紅冬孢酵母(rhodosporidiumdiobovatum)、三角褐指藻(phaeodactylumtricornutum)、蛾幼蟲被蟲草菌(ophiocordycepssinensis)、綠木黴(trichodermavirens)、蓖麻(ricinuscommunis)、和落花生(arachishypogaea)。圖9顯示了表達構建體pnc378的圖譜作為示例。該構建體用於用來自解腺嘌呤阿氏酵母的啟動子adh1(seqidno:13)過表達紅冬孢酵母dga1。所有其他dga表達構建體與pnc378相同,除了dga序列。使用解腺嘌呤阿氏酵母pgk1啟動子(seqidno:14)驅動所有構建體中選擇標記物nat的表達。
表iii.用解腺嘌呤阿氏酵母adh1啟動子篩選dga的列表
在通過pmei/asci限制性消化轉化之前將表達構建體線性化。每個線性表達構建體包括編碼dga的基因的表達盒和用於通過諾爾絲菌素(nat)進行選擇的用作標記物的nat1基因的表達盒。將表達構建體隨機整合到解腺嘌呤阿氏酵母菌株ns252的基因組中。簡言之,將5mlypd培養基用來自過夜集落的ns252在ypd平板上接種,並在37℃下孵育16-24小時。接下來,將2.5ml的過夜培養物用於在250ml搖瓶中接種22.5ml的ypd培養基。在37℃下3-4小時後,將培養物在3000rpm離心3分鐘。棄去上清液,用水洗滌細胞,離心,棄去上清液。
為了使細胞具有感受態,將2ml的100mmliac和40μl的2mdtt加入到細胞沉澱中並在37℃下孵育1小時。將細胞溶液以10,000rpm離心10秒,棄去上清液。先用水洗滌沉澱,然後用冷的1m山梨醇洗滌沉澱。將洗滌的沉澱重懸於2ml冷的1m山梨醇中並置於冰上。將40μl細胞-山梨糖醇溶液和5μl消化的構建體加入預冷的0.2cm電穿孔比色皿內。將細胞在25uf,200歐姆和1.5kv下電穿孔,時間常數為約4.9-5.0ms。在1mlypd中在37℃下回收細胞過夜。將100μl-500μl回收的培養物在具有50μg/mlnat的ypd平板上鋪板。
使用實施例7中描述的螢光染色脂質試驗分析每個表達構建體的八個轉化體。大多數構建體在轉化體之間顯示出顯著的集落變異,這可能是由於在僅獲得功能性nat1盒的一些轉化體中缺乏功能性dga表達盒,或者dga表達盒整合位點對dga表達的負效應。然而,圖10、11和12證明兩個解腺嘌呤阿氏酵母啟動子adh1和pgk1可用作構建可行的表達盒的工具。
參考文獻的引用
本文引用的所有專利,公開的專利申請和其他文獻通過引用併入本文。
等同形式
本領域技術人員應了解或能夠確定採用不超過常規實驗即可獲得本文所述的本發明具體實施方式的許多等同形式。這類等同形式應包含在所附權利要求書的範圍內。
序列表
諾沃吉股份有限公司(novogy,inc.)
來源於解脂耶氏酵母和解腺嘌呤阿氏酵母的啟動子及其使用方法
ngx-034.25
62/028,946
2014-07-25
53
patentinversion3.5
1
1599
dna
釀酒酵母(saccharomycescerevisiae)
1
atgcttttgcaagctttccttttccttttggctggttttgcagccaaaatatctgcatca60
atgacaaacgaaactagcgatagacctttggtccacttcacacccaacaagggctggatg120
aatgacccaaatgggttgtggtacgatgaaaaagatgccaaatggcatctgtactttcaa180
tacaacccaaatgacaccgtatggggtacgccattgttttggggccatgctacttccgat240
gatttgactaattgggaagatcaacccattgctatcgctcccaagcgtaacgattcaggt300
gctttctctggctccatggtggttgattacaacaacacgagtgggtttttcaatgatact360
attgatccaagacaaagatgcgttgcgatttggacttataacactcctgaaagtgaagag420
caatacattagctattctcttgatggtggttacacttttactgaataccaaaagaaccct480
gttttagctgccaactccactcaattcagagatccaaaggtgttctggtatgaaccttct540
caaaaatggattatgacggctgccaaatcacaagactacaaaattgaaatttactcctct600
gatgacttgaagtcctggaagctagaatctgcatttgccaatgaaggtttcttaggctac660
caatacgaatgtccaggtttgattgaagtcccaactgagcaagatccttccaaatcttat720
tgggtcatgtttatttctatcaacccaggtgcacctgctggcggttccttcaaccaatat780
tttgttggatccttcaatggtactcattttgaagcgtttgacaatcaatctagagtggta840
gattttggtaaggactactatgccttgcaaactttcttcaacactgacccaacctacggt900
tcagcattaggtattgcctgggcttcaaactgggagtacagtgcctttgtcccaactaac960
ccatggagatcatccatgtctttggtccgcaagttttctttgaacactgaatatcaagct1020
aatccagagactgaattgatcaatttgaaagccgaaccaatattgaacattagtaatgct1080
ggtccctggtctcgttttgctactaacacaactctaactaaggccaattcttacaatgtc1140
gatttgagcaactcgactggtaccctagagtttgagttggtttacgctgttaacaccaca1200
caaaccatatccaaatccgtctttgccgacttatcactttggttcaagggtttagaagat1260
cctgaagaatatttgagaatgggttttgaagtcagtgcttcttccttctttttggaccgt1320
ggtaactctaaggtcaagtttgtcaaggagaacccatatttcacaaacagaatgtctgtc1380
aacaaccaaccattcaagtctgagaacgacctaagttactataaagtgtacggcctactg1440
gatcaaaacatcttggaattgtacttcaacgatggagatgtggtttctacaaatacctac1500
ttcatgaccaccggtaacgctctaggatctgtgaacatgaccactggtgtcgataatttg1560
ttctacattgacaagttccaagtaagggaagtaaaatag1599
2
1026
dna
大腸桿菌(escherichiacoli)
2
atgaagaagcccgagctgaccgctacctctgttgagaagttcctgattgagaagtttgat60
tccgtttccgacctgatgcagctgtccgagggcgaggagtctcgagccttctcctttgac120
gtgggcggacgaggttacgttctgcgagtgaactcgtgtgccgacggcttctacaaggat180
cgatacgtctaccgacactttgcttctgccgctctgcccatccctgaggttctcgacatt240
ggcgagttctctgagtccctcacctactgcatctctcgacgagctcagggagtcaccctg300
caggacctccctgagactgagctgcctgctgtcctccagcctgttgctgaggccatggac360
gctatcgctgctgctgatctgtcccagacctcgggtttcggcccctttggacctcaggga420
attggacagtacaccacttggcgagacttcatctgtgctattgccgatcctcacgtctac480
cattggcagaccgttatggacgatactgtgtcggcttctgtcgctcaggctctggacgag540
ctgatgctctgggccgaggattgccccgaggttcgacacctggtgcatgctgacttcggt600
tccaacaacgttctcaccgacaacggccgaatcactgccgtgattgactggtccgaggct660
atgtttggcgactcgcagtacgaggtggccaacatcttcttttggcgaccctggctggct720
tgtatggagcagcagacccgatacttcgagcgacgacatcctgagctcgctggatcccct780
cgactgcgagcttacatgctccgaattggtctggaccagctctaccagtcgctggtggat840
ggcaactttgacgatgctgcctgggctcagggacgatgtgacgccatcgtgcgatctggc900
gctggaaccgtcggacgaactcagattgcccgacgatccgctgctgtctggaccgacgga960
tgcgtggaggtcctggctgattcgggtaaccgacgaccctctactcgacctcgagctaag1020
gagtaa1026
3
1047
dna
紅冬孢酵母(rhodosporidiumtoruloides)
3
atgggccagcaggcgacgcccgaggagctatacacacgctcagagatctccaagatcaag60
ttcgcaccctttggcgtcccgcggtcgcgccggctgcagaccttctccgtctttgcctgg120
acgacggcactgcccatcctactcggcgtcttcttcctcctctgctcgttcccaccgctc180
tggccggctgtcattgcctacctcacctgggtctttttcattgaccaggcgccgattcac240
ggtggacgggcgcagtcttggctgcggaagagtcggatatgggtctggtttgcaggatac300
tatcccgtcagcttgatcaagagcgccgacttgccgcctgaccggaagtacgtctttggc360
taccacccgcacggcgtcataggcatgggcgccatcgccaacttcgcgaccgacgcaacc420
ggcttctcgacactcttccccggcttgaaccctcacctcctcaccctccaaagcaacttc480
aagctcccgctctaccgcgagttgctgctcgctctcggcatatgctccgtctcgatgaag540
agctgtcagaacattctgcgacaaggtcctggctcggctctcactatcgtcgtcggtggc600
gccgccgagagcttgagtgcgcatcccggaaccgccgatcttacgctcaagcgacgaaaa660
ggcttcatcaaactcgcgatccggcaaggcgccgaccttgtgcccgtcttttcgttcggc720
gagaacgacatctttggccagctgcgaaacgagcgaggaacgcggctgtacaagttgcag780
aagcgtttccaaggcgtgtttggcttcaccctccctctcttctacggccggggactcttc840
aactacaacgtcggattgatgccgtatcgccatccgatcgtctctgtcgtcggtcgacca900
atctcggtagagcagaaggaccacccgaccacggcggacctcgaagaagttcaggcgcgg960
tatatcgcagaactcaagcggatctgggaagaatacaaggacgcctacgccaaaagtcgc1020
acgcgggagctcaatattatcgcctga1047
4
822
dna
釀酒酵母(saccharomycescerevisiae)
4
gatccaactggcaccgctggcttgaacaacaataccagccttccaacttctgtaaataac60
ggcggtacgccagtgccaccagtaccgttacctttcggtatacctcctttccccatgttt120
ccaatgcccttcatgcctccaacggctactatcacaaatcctcatcaagctgacgcaagc180
cctaagaaatgaataacaatactgacagtactaaataattgcctacttggcttcacatac240
gttgcatacgtcgatatagataataatgataatgacagcaggattatcgtaatacgtaat300
agttgaaaatctcaaaaatgtgtgggtcattacgtaaataatgataggaatgggattctt360
ctatttttcctttttccattctagcagccgtcgggaaaacgtggcatcctctctttcggg420
ctcaattggagtcacgctgccgtgagcatcctctctttccatatctaacaactgagcacg480
taaccaatggaaaagcatgagcttagcgttgctccaaaaaagtattggatggttaatacc540
atttgtctgttctcttctgactttgactcctcaaaaaaaaaaaatctacaatcaacagat600
cgcttcaattacgccctcacaaaaacttttttccttcttcttcgcccacgttaaatttta660
tccctcatgttgtctaacggatttctgcacttgatttattataaaaagacaaagacataa720
tacttctctatcaatttcagttattgttcttccttgcgttattcttctgttcttcttttt780
cttttgtcatatataaccataaccaagtaatacatattcaaa822
5
427
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
5
catggctcacttgcggtcaccgcttgcatgaagcgcagattaccacaaaggtcctagtag60
cttgaagggtgaaaacttgaggtttacaagggcccaaaaactcaattgcagccactaaaa120
tgagcattcaatctataatcagtccatagtcaacaagagcgctcaaaattgatacagttt180
agtgaatcttgctcgagatgagcgggcgatagttgcttttggggagccctaagtggtacg240
tgcggcgcgcgggatgtttccctattaggcaaaggccgaccgggtaacccctcgagaaaa300
aaaaatttttcgccgctaatctggtgttatataaagctccccctgctcttggattttttc360
cttgtcaactcacaccggaaatcgaaggcatttcattctgagtagttctcaaaaaacata420
atcaaca427
6
910
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
6
cctggtcgtcctcctcttcctcctggtgtggatcctgcaatacctcagcgatccggttcc60
atgcaattgcctgcgctcgtgtcaactggtactcaggccattgattggtgtagccagaat120
aggtgcgagagaagaacatcaaaatctgctgccagggctctactgcgctccggcggtcgc180
tttcatccatgtacgccatcaatggctcttccggttcattcttatcaacccgcatcgcgt240
cgtagatgatcggctggaaccctatcgatttaaggtgtagttcggcagacatgaacagcg300
actccatggcgttccaaattcgctcccgccattccaggtcttggccgctgctgttaacat360
gactgggcttttcgaccagagccgcaaggtcgatggggttaaaatctgccacgtactttc420
cggccgcccacttctctataaactggttgcgtgccatggcaatccacacgcgtcgtcaag480
ctaatgtcccttccacattactgcggctttgcaatgtgaggttcggtacaattacatcat540
acgccgcaactacaccagcaaccttaaagaactagtccgaatctgtccagaaaccaattg600
tcagcaaacaatcagacacacatacatgttttgaccacacaaacaccacaccattatgac660
cagtcatcattgcgtcctacaaggtcatgttaccatgactgcggtggtattttgtttgcc720
atttgtcataccttcattatgctgcaacgttagacggctgtgtcgatctccgtggtgaca780
ccacaataggccacgtttatccgttgttccgctcattactacaccccttgtgccctgtgt840
ttggtgttgtcatgcctttaattcagtatctgaggccactttaacggaatcacccctgag900
aatcgcaatc910
7
499
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
7
cgttccgttcactttcccgtcgcgaccaaattgacttctgttgcctatttttcaactctc60
cgggactggctcgtaagccgcacgcgcttgttatgacagggtcaagctgcccccaacaag120
ctttcaaggcacgccgttatgacgaattggatgacgattatgatcaaaccccgggtcaat180
cggccgcccgagagaccccttttcgacgcatttgaaaattcaaactcccctagcctagcc240
gacccgcattcggggagtccgcgaaaagttcccggaacagcccatacggtggcctaccgc300
ctcacttgctcggtaatcaccgtataaagccaataaggtgacagagctgttctttgtgac360
tgatagttcggttgatacaagaaggaaagaaaaaaatatcacaatggtgagtagaatttg420
cgagacgacagtatggcaattgattgtgacgctaacatttccgtaggctcgaaagttctt480
tgtcggaggaaacttcaag499
8
882
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
8
ttgctgccataccacagtccacctggtacatttctacgctgttccaaggggaataaccga60
gccgcatgataaccgacccgatcgcaagctcaacaaattgccgtacgggcatacgcgacg120
agaatttctcggagacctgggagtacggaaacgggtgtcggatttcagtccattggcaac180
tcaaaccgacaattgacaagactcaattgctggaagacaatgccaaaggtataacccacg240
ttacccgcctcactggctaccgggtccgcgatacgaggtccttgtcatgcaccgtggtca300
gggtccattgtacggtttgaatttgcggttgctcaggcggagccgaacaaaagtcgtggc360
acgagaataatcgtgcgggggtacacttccccatacctcgtgtatataagtatccatccc420
tactctgtttccatcacctcttgctacggtgaatacacaaaaggtaagtcaattgttggg480
acctctgtagtatgacgcattaggctaggctgtttttttttcaaacggtttcaccggcat540
caccgcagggtcagccttaggggccaccgttgcaaggtactgtttagtgggctcattgtg600
tgacggttgcagggcaggaattgacccctatctgaggcaaagacgtcattggccccgcaa660
ccaacacaaccagcccctattcacgccattgtcctgattagttttggcacaattgcaatt720
ggctcctaatgcagagagaaccctgcaaatgttgcttgattggtcgccccactacagata780
gtgatgtagtggtgaaccacccaacattggtgtgatatatataaaagcccttgtttgtct840
attgtgtcattctttcttgaaccaaaaaagactaattccaga882
9
741
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
9
ccaaacgcgaatccgcccgatgtagaagctccaaacagcggtttggattcagaactagag60
gtagtagtagtggcaggagtagtggatccagccgaagcgccaaacagtccccccgaagga120
ttgcccgccggcgtcgtcgacccaaaactgaacccgccctgtttaggagtggcagacccg180
ctgttctgtccaaacattgttgcactggtcaaacctgaaggttggtaaacagtagaaatg240
tgttttcgcacgtgccgtccacatgaacagagtcagatgacagtcagatgacatacggct300
ataaaagcgtcataaatcacctgactaccgcatgactaccacgcgataatcacctgacta360
caacccgaagattcatcacctcatacccctcggcagatgccgaaagtccgggcaattatc420
gtgataatcatgacgcccaattgggcaccaattgcgagagcaacaccaaacgacacgcag480
tgtcaccgcaattgggcctctggtgccactggtgctggcgctgacgttgcctgtcggaca540
aggaccaccgccctccaatctggccaccagcggcccacgttgatacgttggataagcctt600
tgttgggccgccagccgcgcacccgttgtgttttcagaactgtacctcagggtggtgagg660
ctgcaagggccaagcagtatatataggccccttcggaaccatgggatgtgattagttgaa720
cagacagcagctgattgaata741
10
983
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
10
gaacacttcaggcacccacacacataccaactcagacacaaacacaaacacagacaaaca60
caatcgtatgacctgacagcatagtgcattatctatgctcccttcccagctatacacgtc120
acaatctcagctaatagacctaatagggtgacagttgcactttcccccttgatgtctcat180
ccagaccctcgtcatcccatccgcccaatccttcccagtgcattccaacgccctctcaat240
ggcaaggccaacctctgagccattgacccttaaccagccatagtttactcaactggccga300
ccgccgtccctttacccattgccatacgcaatattccaatggcctagaggggctgtacgg360
cccattgtccattgtccattgttactgctggtatttttatctcaacgtccccaaaaccgt420
tgtggacagccgcgccgggtgtataggccgccgatcgcagcctctccggaagcggcgcag480
agcaaaacgagcccagtcgggagtcaaattccgctccttgtatgaattagtccggcacaa540
agagccccaacggggttaccatgagatgcggaacggcggcaatcagttcagaggctacag600
tcgtcccctaatcgccatcggatactgccgattgtcgttgtactttacagttttacaagc660
atagcgataagcccgaagccaaccactcatcaacgagcttaacctgttgggtcgcgtaag720
cgagcggggggatgctgagtcaggacaacatttgggttggtcagccgcggcccgtagggt780
agtcgtcgctgaggtcacggctgagtaagcggcaccaattaatccgtttgttacatccgt840
atgggtggttgcttttttttacctgtacggtttggaacaacaaaaatttggcagggaccc900
attttttttccttttcccttataagcacctcctaggtcccttttagtagcattcgaattt960
ttgacacacacaaaaaaggtacc983
11
930
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
11
gggtgcggcatttagacagcaacaaagactgcgatcggcgatcagcactaccgttccctg60
taaatggtatcaacaaagagcgttccaattcgtcgcttccagcgccggtacccgtaattt120
tctacgtaaaagtgcccccagcactgctgcgcccatgtctaacctaatcataggctcagt180
gggaaccaccagaccaccctccgactgtgtctgactgtctctgactctctctggccccag240
aacggctaccgcggagaaagggtaatcggaactttgttctgatgggttgcatgtttgttt300
tgtcccaatggggttagtgcggcaggtacggcaggtgacaggatggcatcgtctcacaag360
ggaacgcagtggaagatgagttttggggggaattagacagagaaatgggcaatttggtgg420
actagggagcagtccatgtgtatctagcagtctccatttagtggcctatgttttttctta480
tttcttttttgtcaaaaaggagcatttacgtaaccatctacaaaaaaaagaattactaaa540
atgacacaaaccggggggagccgggatgccgctcacagggtacgcagcgtttgtgcaatt600
caataaccaccaacaataggagaatatattaacaaagcatacaacagatgtatccccctt660
ggctttgtgcatcgcactgtacctttaatgtttgtgttgacagtcctcagacgcaacccg720
attgtcccgagtctttgtgatcaaaccgcctcattgtgcatctatttcccattcgggctt780
gtttgcttatttcccaaaagcaatcccccagggtatataaaggcgcaacgacccgcaccg840
acggggaactgataaactaagtacagttgttttcaccgttaccggattgattaatctttt900
ttttaactaaaaactactagtacaacaaac930
12
602
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
12
cgaggcagtaacctcccgttgtcgtcagtaattggggccgaagccgagagaattgacgac60
ggggtgactaccgaatggaggcaggaaacctgttcgtttgtgttccatgtatacgagggc120
aaaggtcggaccatcgtacacactgagaatgaggaaaagataattgaatgggaaaaggca180
gatactttctgcgttcccagctgggcaaagtttcggcacattgctgagggaaacgctgac240
ggcccagcttatttgtttagtttttcagacaagccattactagatagcttggccttttac300
cgagcaaatagcgtatagcaatacattctatatttttttcgagttaaaggtactgataag360
ataagggatccgtcacccattttttgacttgacaccacgactgggagcggagagccgcac420
aacggttttgtatggggcacagcgaaagggagggagggaaaaaatgaaaaaaatgtgagc480
cgcattagccctaagcagtcacacgcggacccacgattactcctctcccatcgcagcacc540
atacagagtaaggacgattcaaactgtcaaagtgttcgactgcccaactgaagactcaca600
tc602
13
877
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
13
tgcgtcggaacgggatatgcattcccctagtttcgccgcagtgcagaatcaggcggtttc60
tttgcaccacaccacatacggaggatgacgggcattattgatgttgaatagtaacctgat120
cgtgactagtatgacggaacccaacagcaacagccgaccgtttgtgagcgtttttgcggc180
cggtcaggcgagtttttccggcctgccaatggtccttccgtaccctttaccctgtacgct240
gtacctgccacggataggccgtgctccacctgctcactatggtgggtgcggggaaaacaa300
caggcaggctcaattgctctgcaaatgggttgagggggtgattgatgtcactggtacacc360
aacaggggaatgctcggcgttgattttgggccacctcttttgtttgccagagcttgtctc420
tattgtcaaatttaacggtctgcaactgttgcccaaaatgggacaatgatccgatgcctg480
catagacaccctgcttgagggtgcgatcgccctaatacgaggcaaaccaagttttccaat540
tgaccttcaattgacgagcggttgttgcgacaggggactggagtgctacctgtttagagt600
tcaaatccgtcacccagcattgaaagtttttccccgcattggatgattgcaatgccgcta660
acccgctcatccgccaaagttcatagtcccaccctgcctcgacttatcggaccacatggg720
gctcccttatgcgcgcgcatatggcgcttgattgctttttggtcaacgtttgggacaaat780
ttcctttgttaaggcggacccgccagcagatacgaaggtataaatagggctcactttcac840
catcttgtccattcaattgcaagactcaaaagtaata877
14
524
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
14
cccagcccgacttttaacctcaatagctagctacgcaacagacagttaaagctacgtact60
caactatatattccattgacaattgacaattacaactgtttcttctcctgcatcgttctc120
atcctcattggcttatctcctgttatcaattaattataataatatagtagttctgaacta180
attacgtgatcgcacgcagtacggctgacgcgtattattggaccaacaaaccctaaaaat240
tgtttcatccaattgaacagttcacgcaaccgtgattgtgccaaaaaggcattgccggcc300
tcaagtaggcgcccatgctacgactactgcggtctaggcgctcccgtatccctcaatcgt360
ggcccttttccggtctacccgctgagtcagccccgcccaacaaaaaaagcacaccacaag420
ttcgacatggtccaggggcacggctgcagggttgcggtataaatacagtcaccatttcca480
ccgcacctccgtgctttgtttttcaattggcaacctataacaca524
15
668
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
15
caggtcgcatgtatgcacggtttttccggcagcaatgctgccgcctcccttgggagtaac60
atgaacactcacaccaatgtgtggtccaaaaaactgctgacattagttgcaactccggat120
ctttttgccaacggtttgccccggcaccgcccatggggccccagtatacggggttaactt180
acagtcccactggaagcctttgttcaccgatggcaatgtcgcaccggaccgtgagccgta240
catgagacgcacgcaaaactttgtagccgaggcgaaggacaacaattgggttgaatagag300
ccaggggagagctcagggtccctcgggttttgaattatccctgaacctctagcaaaaggt360
tccaaactaagggttgcgcttaactgtacgccttttgatttccggcctgtgaattgttgc420
cccattagggactcaaaccctctaccggcacctcccgaccgagggccgtcctgtgccgaa480
aaagcaatgtgagattcccttgtggcaggttgggatttgttataatttttttttttatgg540
ttggttgaatatataaagaagcagaggcccccaatagaattgtcatcagtcactttttaa600
cactgaactaacaatcatacattaccattaattgatagacattggagaaggaaaagtact660
aactctaa668
16
1366
dna
解脂耶氏酵母(yarrowialipolytica)
16
tggcagacagtgacgagtcatacattctccgtataatatcgtgtatgtccagacgatagt60
cgtactcgtactcgttactgtaactactgtgcgagtactcgtgcatgtatcgtaggtatt120
gtatgttcgagtacatacacatacgataccaaacactgcccactgttctgtcatgttaga180
tcatggccaatccacgtgacttgcatgcaggtttggcattgaatattcagcgtggctact240
acaagtagtacatactgtatcaatacgattgtacatacggtactcaccctttgctacagt300
atgtacatacaagggcgcacatggcagaataccatgggagaattggcccgcatggagttc360
agatgagccctaacaacgcccctgttcggcttcagaagcaattggcttttggaaattatt420
tggcgagtgaacaatggcgtgtatggagccgtattcgtgctggtgcttgttgaatcagcc480
cattgcgcgaaattgttggctctcacaactcaacggtctcttttaccctgtcgtgacgag540
acgctactgtagcgcttgtcggtcggaccacaccaaaactgggcctgtattgcattgtac600
tcagatgtaagcaccaagagctgggatccacgtgatcgcccccacacaagacgcgtccat660
ctgtctattgctcattctccccggcgctctccgatctcttccgacgaaaatgagcacatt720
tcacacgcatctcaagtcagtttggaggcagtagggcgagggtagaggtctggataggga780
aaacgagtgtggaaccttattatttggttgggcacatcccaaagacctccacgtttcgaa840
atcagttgtgttctttttctttgaacttcacgatatttcgtttattcaggtgagtaccca900
cgaaacgcagccaattggttccaattgagtcctagggaggtgacacaaacacacagcgac960
acagagacggacacacagggctccgtctgtggtgagagatacactagtaaccactactgg1020
ggcgcccaatgccgtgagcgagagtgtcagcaaagtagtatatggagctatgcacaaatg1080
ctaaggcaaattgggatgcacggtgtgtcaatgggataacgcaagttgtgttgctacgcc1140
actggtgactctcttgtctggtgatgttgtcttggtgcagtgttggggttgagctcttgt1200
gctgttgggtccgtctgtgtggatgatttgacctatttctgtgtcaagtccacatacaaa1260
caggatctatcaatgccacggaccagtcacaacactgccacgtccgcctctgcgaccttc1320
tacctcctcttcgactgcacatgttccctcattctaactaactcag1366
17
1000
dna
解脂耶氏酵母(yarrowialipolytica)
17
gggagagcatggagcagaaacggttcgatgcttcaagttcgagtacaagtgcacagtgat60
gttgcaacacagtcaccactgcctgagtcactctggctgcctatcaggatgtactctcac120
acatctcacgttcggctcacctcttctttgtcaaggcataaagttcttagaccattgtga180
ctacgcagtttgctccgaaaagatgcatgatcccacccacttgcgcctggaaccggtgga240
cgtgtgctaccagcaggacgtgtatggcacgcgatttattgttgagtaccaaaatagtac300
ttgtagaacgtattccaattcacctttggcttcaccgttgttgtgacccgagctactgta360
cttcctgtacttccaatctaggcctattcgccacttatagcaaggcaatggtatcaacgg420
tgcgtcgtaactgcggcagtatgcggagagcaggcgtatctatgacgtcggtcggcccgt480
gggcagtggggaatcaggtcatgtgtttgtttctttgccatattttgcttgtccaatgag540
ctgagtcagaagttcactaagcatcgatctttatggaacaccacgggtactgtagctatg600
gtgacgtaattgttagactacgtagcacaccagactacaagtccatacatccagacagag660
agtgctaaaaagaaaatatggggcagcatagacatcggaaaccatgggcgatgatagcta720
cccaccacacccaaacagtcagggtaccgtacgtacctgtagtgtgtacttaaccagctc780
gggtccagtctcgtgccaaacctccgatccactcttcctggtcatctcactttatctggc840
agtaactctggtccccataccttgctgtcagactctccgcatttaacctgcacaacccta900
attcggcctcacacactctccaaatacagataaaacacaaaggtttcgttcaccctatac960
tccgaatcaacgctacctactgcatttctctaccgcaaca1000
18
971
dna
解脂耶氏酵母(yarrowialipolytica)
18
gaggtacggcctcgttcaggctatacggaaaagttttcttttgacgtttttttgagtgga60
tttccacgagccatttaggtcatggttggatatcaggtcatggccttggtacgagaagca120
tcttgtcgactgattagcttggactcatgttatctgcctcggtagcaactccagtgcgaa180
caagcacactgtactgctgctcacatgcggtttcaaatgcacggggagacgcccagtgcc240
aatgtcgccacatttccaggtcgtcgagttgaccttttccgcacaattgagtccacattg300
tctacttggtcctggtactacactcgtaccggtaccttttgatccgatggttacttttta360
tgttctattttacattagcgtggaaatagaccatgccatctttggcaccccggaaaaact420
tgatccaatagagttgttgggtggagctagtgactggcggcaattggagagcttctagaa480
gacgaaccaggagcccgataggaactccgttggcgtgagtcggccccccagtagcaattc540
gaatcacgtgacgtggagttttccctcgcccgcgttcctggattgtcccggtgtgacgag600
gccgactggatttgatcacccaaccccacacgacgcataatgtaaatgtatcatcataca660
gtacatgcccgagtctaatgattggctggttcacggggaccgggagcgtccagtgggccg720
tatggcggtggttcaaacacctcagatcagctcactatcggctgagacaatccttaactg780
ttggtcggttgccgtttttgcctgctcctaacagctcgcaccgactctaaaaaacctata840
cgacctggccggcgtaactttgagtgtcgtcaaactctgatatatatatagagagacgta900
tcccaacagttgatagtcgacaaacgcaaaacagacggacactgaaccccccgcgcttca960
aaacaccgaca971
19
1076
dna
解脂耶氏酵母(yarrowialipolytica)
19
gttggatttagttagaaattagttgactggaaaagtcacctgggggttcatttctggtgt60
tacaagaatggaagaacattgagatgtagtttagtagatggagaagacttgagttctaaa120
caaaagagctgaaatcatatccttcagtagtagtatagtcctgttatcacagcatcaatt180
acccccgtccaagtaagttgattgggatttttgtttacagatacagtaatatacttgact240
atttctttacaggtgactcagaaagtgcatgttggaaatgagccacagaccaagacaaga300
tatgacaaaattgcactattcgatgcagaattcgacggtgtttccattggtgttatgaca360
ttcatctgcattcatacaaaaaagtcttggtagtggtacttttgcgttattacctccgat420
atctacgcaccccccaacccccctgctacagtaaagagtgtgagtctactgtacatgctt480
actaaaccacctactgtacagcgaaacccctcagcaaaatcacacaatcagctcattaca540
acacacccaatgacctcaccacaaattctatacgccttttgacgccattattacagtagc600
ttgcaacgccgttgtcttaggttccatttttagtgctctattacctcacttaacccgtat660
aggcagatcaggccatggcactaagtgtagagctagaggttgatatcgccacgagtgctc720
catcagggctagggtggggttagaaatacagtccgtgcgcactcaaaaggcgtccgggtt780
agggcatccgataatatcgcctggactcggcgccatattctcgacttctgggcgcgttgt840
attcatctcctccgcttcccaacacttccacccgtttctccatcccaaccaatagaatag900
ggtaaccttattcgggacactttcgtcatacatagtcagatatacaagcaatgtcactct960
ccttcgtactcgtacatacaacacaactacattcaaaatggtgagtgattgaggagacaa1020
ttggccggcggtcaattgagcgacacaaaaccccgcgcgcgcacgcactaacacag1076
20
997
dna
解脂耶氏酵母(yarrowialipolytica)
20
cccttccgtacctctctgccccttctggacaggtcaatgatagactcagagcgacacaca60
tgtctgacgtaccatgttagaccttgtattgacctggacgaatgtgtgtgaggagtgagg120
caggccaagacgaaccacggtctttatatatgcccacggagtgacacggtctgtgtcgtc180
accgcagctccactcaccacccgcatcatgatcgtccaaccagaacccactccccagttt240
cgacccaacaccattctcaactgtaagtatgagtaccacagtgatactcgcccagtgccg300
cactcgtactgtagccactccactgcaacatccgtatcgtattgcaccgccccgattcac360
ctgcttccttcaagccttcaaccacgtactgctccacctcctaccgttgagcccactcgg420
atcggccagagtcatgtcttagggtttggctgcagttgtggcgtaaactatggagaaggc480
gacggaaacgagagcgctaccggtagcgacttggcgacacgtctggctcgggaagggggc540
cgttgcagagaccaagacttccgtcacgtgaccgctgtttggtcaattctaacgcagtta600
ttttccgtctgattcgctgatacgagtactcgcttgctgtagatgactcagaccaagaca660
agagaaggggaaataaaaaaaacttccaaaaaaaacttccaaaaaaaaaaaatcaaaatt720
tgacaaaccttttctgcctgggaccaggaactttgtgagtccattgagggagttagccac780
ccatcagccacagccacagtttggacaagaagtaaaagtggatatatttatgttatggag840
accatgtagtgttgtgggagggaggggtttttttgtttgttttggctgagtaatcaacag900
caagtggcgtatatcgtatatctatcgtgactcagactattcaccgcttgtatggtgcta960
tctcgacttgtgcttagtctcaggtacacgtgattgc997
21
1691
dna
解脂耶氏酵母(yarrowialipolytica)
21
tgcaaccagtctccgtggtgtgcagcatacattgttcccgcctctccttgtcttgttgga60
aggccgatgtcgctgactgtatgtaccgttttttttgtaccgtagtacatgcagggcttg120
gtattttccaactacagtacatacaggtcttagagtgctgattggagatagatatgaatg180
gagtgtacgagtggaaacaaagcgggttagatatgtgtacttgtacatctgtgatattgg240
tagtattgacaagcggtagtcatttcagtgcatcgccgtgccctttctactatccccttg300
cgccatcaatctcccccttcatcaatccacctctggcagctcttctagaagaccttttta360
cagtctcccaattttatcgtctagtgacggcagaccttgtaagcagatatgtatcatgag420
tcacgatagctggacagaccaatggcatgcgggcaaataactcccacagacgctctccct480
ccggcgcacaaagcctcgtgctctgaacacgccccagttgatttgacagctctcaacatt540
cgtgtgaacttttttagcgggaaaaagtaacatgacgttgaccgtgcggggctacatgta600
gcagctgggtgtgctaactacggatacatgcctacaacccccacaagtcaagaccattgc660
gacgcggaaacaggagcccgcaaaagaggagaaaaacaacggcgagactcgggggcggag720
tgggtcacgtgactttcctttttcccctcacctggcccgctccgtccatatctctgtcgt780
acaagacaatattgtcgcaacgcaaaaggtccataaattactgggtagacgcaactctat840
ttgaaggcaacctaccgtttgcttttagtgttttggttttgttaccatatccaaaaaaaa900
accatatatccaaaaattccgctgcaccatctcttcttctctccatcaactacccctgcg960
gagaaattcacaccacagttacaatgatttacaccgccaattcgtccccttccaccaacc1020
tgcagtggctcagtaccctgaacacggatgacattcccaccaagaactaccgaaagtcgt1080
ccatcattggtactatcggtgagtatacttatccacagaccagacgccgattgcgcggtt1140
tggtgcacaattcgacgagcccacaagaggtaggcgtcacaggataacggacccgctcat1200
gtgaacatgtggcgagcccattgtacccgtgtcgcctgcccccaagtcgattcgccgaat1260
gcgctcaaacgctggctcggtctccgcctcaggcctcagtaaaaacggcaaactaacagc1320
aggtcccaacacaaactccgccgagatgatctccaagcttcgacaaggtgagtaaccata1380
atgcgacagcagtgtgcgccgtgacccgattcgcggtggccacgtctatctgtcccttct1440
ttcgttaccccaattggcaccgtcgccttattttttggctttggtttcccgggtttgtcc1500
aatacacggctcatgcgcatgcacattttttccggtcggataaacccaacgaactctaag1560
tgacaaacatgaaatgaaaacgacgcaagtggtaagggcgctaatggtgacgttcatgac1620
gttgccagtctggtgcccttatcgatgacgtatggacccatgtgtctatcatgccgcaat1680
actaaccacag1691
22
996
dna
解脂耶氏酵母(yarrowialipolytica)
22
tccagactacttgccacaaatgcagcgagctgcacattgatgcgttcatgcaagctacaa60
gtacgagtaatttgacgtattgggcacttcaaggcagtctttcgaaatggccaatctggg120
agctcgctcaccctccgagataactgttgggcacaccagcaggtctcagcaacggttgaa180
aatgggctctcagttcaactaatgatccaagaaaatacaagtacgatgttgtgattggtc240
ggactacttgtagacgacactagccaaagcgaaaaggcacccaccctatctgaatgctga300
gctgtgttcagccccaactcggaatgctgaactgttgtaagtcgatagccgatagatata360
tatcgtagcaaacacaagttgttgactcaaacgcattgacaaggaagtacagatccgaga420
aattgtgccgtgtcaactgctcccaggcacggtctcaattggggctatatctctgtatag480
agtaagccaggttggccccccacccacgagaaatgcaccaaccagtcggcgagctcaaca540
gccgtatgggagcctctcgtttgatgtatgtgtgacaggaggtgtatattggggctactg600
ggtgaaaataaaaacgcgagagagaatataggggtttcagcgaaatcccagtggagagac660
cgaatcatagtattataactatgacagtatcgtgcgctctcctctttcatcacttctctc720
caatatgcgtaccatctatcaccactctcttgcttagcctccctccctccctctctctct780
gttagacccccacacgctcaacagtactcaatatccgcgcagaaaaataaggttggtggg840
acatttctccggtgtgagcgattagtgggttgtggtggtgcccatagcagacctaaaatt900
gactctcctcacttgacaacacacagatagaacctgcaacttcatccaagtggcgctttt960
ctcaatccagtccgtgtgaaaacaagacaattgacc996
23
985
dna
解脂耶氏酵母(yarrowialipolytica)
23
gaccaacctaaattagtccgggtggacgtgtcactagaacgttgtaataccaaggtagtt60
gcgcttgttttgaccaaaaatgtgtgacaaaacattgccagtgtatccagtctgggaatt120
gagtcgttctataaccgtcatttccactccacttccgcgcaacgcgctgctgagcactcg180
gaaaattagctcgaaaagtttttccgggttatgtgacccgccagcaggttaggctctatt240
ctgttgggaaataactctcaaccgcccctccgagctaaatctctcactacaagactcttc300
atcgacaaacgatatctgagatctttttcggtcccacagcaacaagccacaaacatgtct360
gccatcaagcaattgaaccgtctggccgccaccgccaagacctctgttctcaagcccgcc420
tccaagcagattctgctgcccactgctggccagcaggctgccatccgaatgatgggccag480
acccgagctgcctcaaccgaaggcggcgccactaacgtgagtattttttgtgtgaacgac540
acgatatatacacgacggccgtgcgcttgcggcttcgcgatgcgccctgaatggggcaac600
tcgagcgttgtgtaacgggtgttcatcaacagcaaacagtgcttttcggacttaagacat660
ggcagaagaagcaaacacggttatagcgagagagatcacaatggagtgacgagctttcag720
tgatatttgccaccagtcaaattttcagcaactcctgaaacgcacccattttatcatcat780
tgtgacgcggacattcagcctcatgctgtaactgcactccgtgtctggagctgccggagt840
tatcaaagctgtaggtgccaattgtgaaatagcgattcggcgattcagccgttgattgcg900
ttcctgctatgtcgcaattgtacaatgctctgtacacttccaacaacatcaacatgacaa960
cacccaaaacaacgtactaacctag985
24
999
dna
解脂耶氏酵母(yarrowialipolytica)
24
ggtgagtcgtgtcgctaaaaggtttgcaatgggctcccccaaaggcttttggtggtttgt60
agggcggtgaaaaatttgtccattttagggccaagatttagacgtgtcgagatggggagg120
ttttggaacacgccgaatcgcatcgacacgactcccctccgcctgaaccacaacctcgcc180
ggtcacatgacatggctcctgcacttcggatacggaagcccggatcctttatgctctacc240
ccggagttgtacctgtccaatagaacaagagtcaattggccttactcgcatgcaactcaa300
acttgggccggggttgagaggtacagttgacaacgtgaaaataagaggggggggaggtta360
aggcctcaggggcgaatttgagagcacttatatagacaaatccgcaccgaagtgacaaca420
tggacaatgtgacacgtagatacacgccggatccagctgtccacacacatttatcccgaa480
aaatagcccgcatcacatgcacgtctcgtaaaaaaaaaagagctgcgggccaaaggacca540
ataagtgccgaggaatgttaagccaaaagaacaacgacgatcgccagacaggtttagtgg600
gagcagcagcagcagaggccgtgcaacggcaggagagagaggtctggcgaaaaggaggag660
acggggtgttaattgatttgcggattttccgcccagccacaaaaatggcctattttggcg720
ggtttaacggcgtcccctccaattaatccgaaccccgtttaccacgcagcctacactatg780
tactgttgacaacaccccatgacggtagtctccggagccgagccggacttgtgtttaaaa840
tcggcacgattttgttcagaggttagggttcaccctggctaatagattggcgctgattgg900
cccgaccaaacccaaaatgggcactctgcagtgtttataaaacctctccgaggcccacga960
ttcaactttctcctttccgctctaacaccacatatcaca999
25
999
dna
解脂耶氏酵母(yarrowialipolytica)
25
atggtgcgtggaggctttggcatcctttctacttgtagtggctatagtacttgcagtcca60
agcaaacatgagtatgtgcttgtatgtactgaaacccgtctacggtaatattttagagtg120
tggaactatgggatgagtgctcattcgatactatgttgtcacccgatttgccgtttgcga180
ggtaagacacattcggtggttcaggcggctacttgtatgtagcatccacgttcatgtttt240
gtggatcagattaatggtatggatatgcacggggcgtttccccggtaacgtgtaggcagt300
ccagtgcaacccagacagctgagctctctatagccgtgcgtgtgcggtcatatcacgcta360
cacttagctacagaataaagctcggtagcgccaacagcgttgacaaatagctcaagggcg420
tggagcacagggtttaggaggttttaatgggcgagaaggcgcgtagatgtagtcttcctc480
ggtcccatcggtaatcacgtgtgtgccgatttgcaagacgaaaagccacgagaataaacc540
gggagaggggatggaagtccccgaacagcaaccagcccttgccctcgtggacataacctt600
tcacttgccagaactctaagcgtcaccacggtatacaagcgcacgtagaagattgtggaa660
gtcgtgttggagactgttgatttgggcggtggaggggggtatttgagagcaagtttgaga720
tttgtgccattgagggggaggttattgtggccatgcagtcggatttgccgtcacgggacc780
gcaacatgcttttcattgcagtccttcaactatccatctcacctcccccaatggctttta840
actttcgaatgacgaaagcacccccctttgtacagatgactatttgggaccaatccaata900
gcgcaattgggtttgcatcatgtataaaaggagcaatcccccactagttataaagtcaca960
agtatctcagtatacccgtctaaccacacatttatcacc999
26
999
dna
解脂耶氏酵母(yarrowialipolytica)
26
tgaccaaccttgtttggtagatgggggggaagcgaaccggcaatattccacaatgtgctg60
gcatttacttgtgctggcaaaagaggcacaaagaatacttgtagtcggagccactcactg120
tcccacaaatagctccccgctgtcaatctctcctgcaccgcctgctcacatggatgctaa180
gccgcactaggtcgcatatatggctctgcactaaaaattaggggtcaaccacagtgcggt240
atttttagattcgcaccaagcagcgagtaagcaaaaatacgcctaccggggtccgatatt300
attcaggaggtgccattagaggagggcagatgagagtcggatatcggagatattaccgag360
gctataattaccccatccacgcctttcacccctcccactctctccctcaccgcacaccaa420
cccaccactttcaaaatataccgcaacattgacataatctccggtacagtggttagcacc480
gagaggaccccaaaaagcttgggggagatagaggtaggcttttttttgtcagtcaaatcg540
tatatgccaatacacacacacacacacacacacacacacagtttcgtacataacagtata600
ttggaagggagtgtgcttggcaaagacaggagaagacggtgctgttagagggcaatccag660
acgggctagagctctgtaactttcggatcgatttcaattcctctagaataccaaatacca720
gtggttaagcggctcatttaccagtcctaataccccctccaccagccaccttcccctatt780
cctcggcagtgcttttttacctttgagatgtggccttgtctccgttacttcccaaccgtg840
agtgctgtgtggtgtgctggacagtgcgacataactaaccctaacccagacgagccagcg900
caccccaattttgtgtttgccaactcctacttttctcctctcctccatcggtatttcatc960
gacaaatctctttgctaccaacaaccacacaaattaaaa999
27
452
dna
解脂耶氏酵母(yarrowialipolytica)
27
tgtgtgtttggtcgaggtttttttctgttcagtacagaccttgtgtggtgaggaacagca60
atagcaagggtggcttttgattgggtgcaggtgcccttaccctgttgggaggtttgtcta120
ggtgcctgggatggaggacaatgttttgtcactgtcaagacgggatattgtggggatttg180
agaaatatatttgatcagccggtctcgaagattatattcgcgctttcgcctttgaaattg240
ctccttttgttgccgtttcgaactgtagtctcgtgctactgagtctcatgttaatttttg300
tttcggcctcgacttaattaactctaaccaatgttattttcgtgcattaacgaaactcga360
acgcacgatcagtcacactctccaccatcaaatatcacgtacagactggtaccccataca420
tactaccatctgaagacgacacaccacccatc452
28
1000
dna
解脂耶氏酵母(yarrowialipolytica)
28
ctcgaataaggcactatttaggaccagaccacaccccgcggatgtcaagccgaaccttgt60
tgcataaagataatactagtcaagtggggtgtcgacccgatgagagaataaaccgattgc120
aacggtttttatttcattcgcttcttccagcagacactcttggttttcttcctcacagct180
ttccgccattatcagctgcgtgtatcgtgagtatattgggagtgagagatgccctcacga240
taagacaacagctatagtacaaatgttaacacagatgtcagatcaagcgccgccaaactc300
gcccggaacacgggtaccaggggagatcggtccccaacaatcttcccagcaagttcccat360
ggcttataccatcccaggaacaacaagtacagctctagatgaggagatctcggagtaccg420
tgacaccaaccgaacgaccaagacccctgggatagacgagctgacacccacagcgtttta480
tgacaatcgtggtgttaggcatgagcataggggaatatctgaagagatgaagaaggagct540
caagagacaggagagacgccagcacgagatgttgcaacagaagcagcttgagctgagaca600
acaggaagccctacaccaacaccaaatgcttatcattgagcagcagaagcaagatcagat660
tattcaacagcagaaacagctgcaacaactgcagcggcagcaacaggaagaggtggtcag720
acaacagcagctgcagcaacagcagcaactgtaccagtactatcagcaacagcaacagca780
gcaacagcagtatgccgcacacatgttacaattcgagcaacaaaggcgggagcagatgcg840
acaacttcagttggcccagtaccaggcatctcaggctgttcagacacatcatcaagatgt900
ttctcatctaaccccgtctgttcccgtacctgcagccgtaacacagcctcctgcctccgt960
agcacgtacggcatcagtctcagacatgttggtacctcct1000
29
1000
dna
解脂耶氏酵母(yarrowialipolytica)
29
gtagatacacggtaagtacatactatatctatagatgatacattttctttttataccgac60
cgcccaagccacacggcaccttaattaaacggccactttgacatgagaccgagctacaaa120
ccagtcgactacaagtactgtcaaagagtcgaaatttgtggagtcgggagtttataatgt180
ccatccaagaacaccctcatttcctgctcgtcttgtgtttcagtagctaatttcacatgt240
aaaacggcggtcttgatccaccctgtcttaactccggtcggactttgctgccataacgtt300
cggacacgcaactctttcccaaatccaacttacagcatcttacctaatcacacctgccct360
cacattaggcaccaacctaaacccaagctcaaccgtcgtcgactcagccccgaagaagca420
ggtactcgtgcaaatatataacgaacagtttaacggcggcccggaaaaagattcggtcgt480
cacgtgacctacctccaccctaagccggtcccttcaccccccacttttctcactgttctc540
acttttctcacccccactgtggctctatcaaactctacgatgacacacaatggcagaaaa600
gtgcctctgcatacacgatccaataaaacggtcagtacacgcaacttagtgagggggagg660
ggttacatccagcaggtggtgctaatgttacggcagcttttcagtagtgtgctcgatatt720
tcagcccccgttggaccgcgaaaagcactctacactcgtcttctagtatgttcggtcgtg780
tcccacgcacttagttgcgataagcgctaatcatgcttttctttgtctgtgcggtggcga840
ttcggaacataatcactgtaagcggcgcatgttgaaccttattttgcctttgagcccaca900
catggataacacctcatatataacctgtcccctccgctaactctcttgcttctctacaac960
ataacctgttgaaccacaaaacacctaatcaacaaacaac1000
30
989
dna
解脂耶氏酵母(yarrowialipolytica)
30
gtcttagtgggactggaaggagtatcagtctcactggttaactgtactggctagaccccg60
gaaagggatggctgtgtgcttgtggttcattgggtgcggtgtggtgtctacaactcgtgt120
tgccagacctggacaagggcatttgtgaatgtgacggtactcgtaggttcaccagagatg180
gtgtcgaacgacacatgatgagagtggaagctccttggatgccatcgacatcacgtgaac240
ctgtctgatcgtccatcgctggtttgtaggacgcgtttgaaggttccgacttgacgttgt300
tggtatgatgcacgagtacaggcgattgtaaggtggtcgagcgtgttttaatgtacaggt360
ggaagtaattgtacttgtatcagggcctcttgcagctcgtcttgtgttgttcgcatcaaa420
tgacactcgtcttgtacagtacagtctccatgacttgctccagattatgtatccaaaaca480
ggggttgtatacttgcagagtacaagcacaggcatacgtatgtacaagcctctttatatc540
tttaagagtacaagtaaacgtactcgcacttgtacttgcaccggcgagatgtatggtcgc600
agaaaacctgtcggcagccctccgtcctccacatacgaacatgactgacttgcatctttc660
acctgttcagcaagtttcatactgcactagtccaaataggtaaatcaccttggcctccta720
tttgggacagggtaagggcgtccagaagaggacaccagtgaaattacataatacaagctg780
cagtacttgtccgatacgacctgtctcgaaacagccgtttggagcagcgcatttcttgcc840
caatcaattccctgactactctcactcttccccaacacggtgctttttccccattctggt900
cacatgactgacacgctccacctaaccttatctccaaagaccacgacatacgcatctctc960
cttcagaggagtttcggaagtctagccca989
31
940
dna
解脂耶氏酵母(yarrowialipolytica)
31
aaggcgagcgaacggctttgtccagtggtcaattttcaagtcaatttttggctaaaaaaa60
agaccaaattgcagccatccaaactggtcactactcgaccaatatggccgatatttcaat120
ccacatcgaaccagtaaatcagaatgaaccaccagatcaatgaagaacaacaaaatcaaa180
cgaaaaactccctcgggcccgcatgctcccgccaaatcgacaaaatctcttctcccatag240
gcgacattgaccccatgcaatatcggtgacatttgtaaataagatctgaactttaaatta300
tcatactttggtggtgtatggtgcgtggtccacgtggggtaggggaataaaaaaattgga360
acaaattgggaaatatataaaaattgaaaaataaatggaaaataaaaaaaacgtggatct420
ttcgatgaataaaaatcaggctaatcccagacaaagatcgggagtctttctccctgagcc480
aacgtcatcctgactaatgaaaacatcaaataaaataaatctgacacctaaactaaccaa540
ctttatttgggccaatgagacggctgaaagtccgcacgttgtggggggaaatggacaaag600
tttattttaaacgtgaaaagttggggggaaaaaacaaaaaaatacgaaaatgtagccctg660
atcggtcacagcccaattatcccctcgaaaaaaatcccctccaaatccccatttttctac720
cgccattttcgtccatacttttcgataaccctaaaaaaggtcatctatcagtctaaatct780
tgtattaacctcgaagactaaccgtaacttagactaatgctaacgttaaaatacaactct840
aaatattaaccgacatcaaaccccgaaaagaatatataatcgtgaggccatcctgaggat900
tttgtctccatcgaattcgaccaccacaaactcctctaca940
32
709
dna
解脂耶氏酵母(yarrowialipolytica)
32
tggcagacagtgacgagtcatacattctccgtataatatcgtgtatgtccagacgatagt60
cgtactcgtactcgttactgtaactactgtgcgagtactcgtgcatgtatcgtaggtatt120
gtatgttcgagtacatacacatacgataccaaacactgcccactgttctgtcatgttaga180
tcatggccaatccacgtgacttgcatgcaggtttggcattgaatattcagcgtggctact240
acaagtagtacatactgtatcaatacgattgtacatacggtactcaccctttgctacagt300
atgtacatacaagggcgcacatggcagaataccatgggagaattggcccgcatggagttc360
agatgagccctaacaacgcccctgttcggcttcagaagcaattggcttttggaaattatt420
tggcgagtgaacaatggcgtgtatggagccgtattcgtgctggtgcttgttgaatcagcc480
cattgcgcgaaattgttggctctcacaactcaacggtctcttttaccctgtcgtgacgag540
acgctactgtagcgcttgtcggtcggaccacaccaaaactgggcctgtattgcattgtac600
tcagatgtaagcaccaagagctgggatccacgtgatcgcccccacacaagacgcgtccat660
ctgtctattgctcattctccccggcgctctccgatctcttccgacgaaa709
33
997
dna
解脂耶氏酵母(yarrowialipolytica)
33
gttggatttagttagaaattagttgactggaaaagtcacctgggggttcatttctggtgt60
tacaagaatggaagaacattgagatgtagtttagtagatggagaagacttgagttctaaa120
caaaagagctgaaatcatatccttcagtagtagtatagtcctgttatcacagcatcaatt180
acccccgtccaagtaagttgattgggatttttgtttacagatacagtaatatacttgact240
atttctttacaggtgactcagaaagtgcatgttggaaatgagccacagaccaagacaaga300
tatgacaaaattgcactattcgatgcagaattcgacggtgtttccattggtgttatgaca360
ttcatctgcattcatacaaaaaagtcttggtagtggtacttttgcgttattacctccgat420
atctacgcaccccccaacccccctgctacagtaaagagtgtgagtctactgtacatgctt480
actaaaccacctactgtacagcgaaacccctcagcaaaatcacacaatcagctcattaca540
acacacccaatgacctcaccacaaattctatacgccttttgacgccattattacagtagc600
ttgcaacgccgttgtcttaggttccatttttagtgctctattacctcacttaacccgtat660
aggcagatcaggccatggcactaagtgtagagctagaggttgatatcgccacgagtgctc720
catcagggctagggtggggttagaaatacagtccgtgcgcactcaaaaggcgtccgggtt780
agggcatccgataatatcgcctggactcggcgccatattctcgacttctgggcgcgttgt840
attcatctcctccgcttcccaacacttccacccgtttctccatcccaaccaatagaatag900
ggtaaccttattcgggacactttcgtcatacatagtcagatatacaagcaatgtcactct960
ccttcgtactcgtacatacaacacaactacattcaaa997
34
983
dna
解脂耶氏酵母(yarrowialipolytica)
34
tgcaaccagtctccgtggtgtgcagcatacattgttcccgcctctccttgtcttgttgga60
aggccgatgtcgctgactgtatgtaccgttttttttgtaccgtagtacatgcagggcttg120
gtattttccaactacagtacatacaggtcttagagtgctgattggagatagatatgaatg180
gagtgtacgagtggaaacaaagcgggttagatatgtgtacttgtacatctgtgatattgg240
tagtattgacaagcggtagtcatttcagtgcatcgccgtgccctttctactatccccttg300
cgccatcaatctcccccttcatcaatccacctctggcagctcttctagaagaccttttta360
cagtctcccaattttatcgtctagtgacggcagaccttgtaagcagatatgtatcatgag420
tcacgatagctggacagaccaatggcatgcgggcaaataactcccacagacgctctccct480
ccggcgcacaaagcctcgtgctctgaacacgccccagttgatttgacagctctcaacatt540
cgtgtgaacttttttagcgggaaaaagtaacatgacgttgaccgtgcggggctacatgta600
gcagctgggtgtgctaactacggatacatgcctacaacccccacaagtcaagaccattgc660
gacgcggaaacaggagcccgcaaaagaggagaaaaacaacggcgagactcgggggcggag720
tgggtcacgtgactttcctttttcccctcacctggcccgctccgtccatatctctgtcgt780
acaagacaatattgtcgcaacgcaaaaggtccataaattactgggtagacgcaactctat840
ttgaaggcaacctaccgtttgcttttagtgttttggttttgttaccatatccaaaaaaaa900
accatatatccaaaaattccgctgcaccatctcttcttctctccatcaactacccctgcg960
gagaaattcacaccacagttaca983
35
1000
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
35
tgcacctccaggctcagggtccccctgtccactgtcctatccaccatccactgttccacc60
ccctcttagacctcagccagacgccgcagcgggcaagcagcccgggtttacagagcgctg120
cgggcatcggcatgatgcgacagggcctcgatgagcggggatactggaccagaccacgga180
ataaatccttcggaaaagtgcgctttttgaaattggccgacccggcgaatcaggccaggt240
caaatcccgcccccgcttccccacaattgaccgatcctgaacatgcacaatctatgacaa300
tggtccgcatcaaattcgcttgcaatagcacttagcggtcgaggtgtctaaccctgtcga360
ggtttgtgaccgctaacttcttgcaagagcgaaggatgcaaggcgctccttcctgaatag420
gcaattgagccccatgtcgtgaggcttaaagcgtgcttcttgccgaatccggaaacaacg480
ccgccgatgatatgacaaaagccaacaaaatacccgctggagcgataacgtaaggggttg540
gggtatcaacggacgcggcaaacaagcctgtgaaccctttgcgagccatggtttggcctt600
agtttttgtctcccgctatggttacattggctctcgcatgctatggtacctcatctcatc660
gaaaatttttcaagaggcgcataatggctgtctcgggcaacggtttgcacacggctacgt720
cggttctcggcctatgattggctctggctttatctctatccgcccacacatacttcaaaa780
ggaaattgagactatgcaaaaagcaattctgggtgtcggagtgctgtatgacgattccat840
aagattttgccgggtcgtatcgaataaaaacccctcttttccccccattgtcaccagatt900
cctgttgtgtttttttaataatctccttttcaacccgcttgttggtggtttgaaaatata960
cccattttttctaatttaatttgctctttgttagcgtaaa1000
36
1000
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
36
caacttgtgtagtagacaaagtgtaaaagaaagcaatttgcgactttagcgctgctctgg60
cacgtgtatacccggtcagagtgatgcaattgagtgagcctggcatggagattatgaccg120
ggcccatcggattccgagttttttgatcccggctccaacttcattgctcatcgcacccta180
ctgtattgaactgacgaccaacagggccagtttctccaaccaaaacagtgcagtctaatt240
agtttgtaattggcaactttagccttagtctctctgaagagttctaccccaattccccct300
ggaccaccccagaacccatgttgaccaggatagcgccgcatgcaggggccacgtgaagca360
gcgcgataagattgataattgataatgttgcggtgcatggccagaggcagagcgacggtg420
ctgaacacacaactggcgcaacattggtgtatatgactgccggggcactgtatccgtgtt480
gacacggtgtgctcaccgttgctagcaaagttagggtttaatcggctattaatggtaggt540
gttgagttggttgagttgggatgagcctcaggatcgccgcacagggctatacgctcacac600
gagcaacgcgacaaatgacgtaaccttgagggttaatatgagctctgtggacgctcgttc660
ttgttgcaaacgttctgagagaacactcacggtgtagcgatcgaagcgcgcgtgggttgt720
tatacctgtgtccagcgctcctggcagtgcacttttgatatcagtgtgttccgtgccccc780
gcttcttatctgagccgcaccgcttatcccgacacaagaaaactataaagaaggctggac840
ccccagattgctcatcatcttgccacaggaactctgagatacctgtggatatacagcttt900
ctcaggtctagactgcgcgttttctgttttattttccctttttagatcgactggattgat960
tcctagttgatttcatttttattccgtttgtctgaacaca1000
37
1000
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
37
agctaggtcaagcgacgcctgttagcgataacgaccttgaaatatctacgcgtgggccgt60
gtgtcgtaactgtacagtgacgttacgaccagacaatagtggtggaggggtagccagtgg120
gaatggagcttgagcgagagaaaaatgacatcaccgaaaaaaaggcggtgagggttttgt180
tactggggagacgcgcgtgcgccccgtggtgtgcggcgtggggctcggcagtgccgaccc240
atttcacccatggaatcgtctagacaggcaaaatggcgtgagcgcctgccggagatacta300
aagtttgcagcgaaagaaggagaacaaacgcacgaaccaaatcagagccaaattggccag360
gtggcaaagccaacgggcaagtccacgggcaattgcattgcccttgcccctctttggccg420
atactcggacatggtcgggatagaattgtgaagaacgataagctttagttaaaactgagt480
cattccctcatcggctaacgtgatggaggcacgtgattctccgggggtttttcgctcggt540
caggctcggccgaccgtcggacggcacggcgcggtaattgtccggcccccttgtgagtgt600
cacctaccctgcagggcccaggcaattagtcaatcccgaggacagatggacgagaggtta660
ggcggtattttgagaggatgttggccattgtgtagaatataaaggagactaaaaaattgc720
gagaatttttccgagtagaaccatgtaacttttgtctgtccaaatcggtacatttccgtg780
tctttgtttggaaaagctgtctctccttccctccctaagcccgaatctggggtgcagacg840
ataaccccagaccacgaggctgcctcggccctcggatcattgacagaacaagaatgaatc900
acctgaaaatttggtctatataaagggccccatcccctctccatgttcgatcattaatca960
accaattggtttttaagttattgacattataaaaacaaaa1000
38
1000
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
38
gccgcgggtgtattttcaatccaataattcacagttctgagcgttgtgaatagcatctcc60
cgataacttcaggcatcatgccacagatcagcaacccgagtacacacacgtgaccagtag120
gcacgtgacatccccccatttcggcatttgcgatcgttcatgtgccagcatatgaccaca180
gagcttgtgatagtttagctccatcaggtgattttattagaattatcaacctctggagtg240
gtcagagatggcaccaggggcacccgaagtgtagtggtgcgtgcagacatccaatgtccg300
aagggcttattgacccttctgccatagtgtgcaagtagagccgacgagatcggtccagca360
ccgctttgtcaattaattttttcccttgtaaaaaggctgcttgccattgtctcgacaaat420
cgactgaaaagtggcccgatttggatctcgacaatcatttgcaatcatttggagaggcca480
cagttgtctgcggtggcattgtcatgtccccctgttgctatgtgtgccagtgactcgctc540
cgcctgcaatttagttccccattcataccccgtaaccccggggcgtttccccagatttcc600
tcggcaccgctcaccgaagcccttaaccccccgagtgccgaaaagtcggtattctcggaa660
ggcatatagagaattatgaaataaaaagaggacaataaagcacgccggatacagagcgag720
cggtagccaaccctctaccgtcttgtcccattctctagcatcatttctccgtccgtacct780
tcacccaatcctacctcccggacttgtcctacgcgggtcccatcgccgagcgcagccgca840
cactttcacgagccgaggtccaccccccttcttcttctttgggaccacacacttccccca900
cattgcacatataaagctcccgaatcagccatcatacgacttcctcacaaagcctttggc960
cggttctattttatcacaaaaccttcgataatataacaca1000
39
1000
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
39
attgggtgtggacaaagctgctagccccgagcccgaggaggatgaacaggaggattctga60
caagcgtgagtatcccatgatggagaccctccctcaccctcgattcaatgctgctacatg120
cgtagttgatgacactctatttatctttggaggcacctatgaggatggcgagcgggagat180
ttatctcaattccatgtatgcagttgatctaggccgtctggatggtgttagggtgttctg240
ggaggatctacgggagctggagcaggccggctcagacgatgaagacgatgacgacgatga300
agatgatgacgaagaggacgatgatggtgaagatggagaggatcacgacgaggatcagga360
tcaagtcgaagccgaggacgaaaaggacaatcaagaagaggaggaggaagctgaaaagag420
cgacatgaccattccagatcctcgaccttggctgcctcatcccaagccattcgaatcgct480
ccgagcattctaccagcgaacgggacctcaattcctggaatgggccctgtccaaccatcg540
ggacgctagaggaaaggacttgaagcgaattgcatttgaactgagcgaagaccgatggtg600
ggagcgacgagaggaggttcgtatctccgaggaccagtttgaagagatgggcggagtcgg660
tgaggtcattgaaaaggacgctcctagaaaagcacgacgataaatagactaatccatcta720
tcggtatcaggctatgaaactatcaatctgtcaaaatctgtcaacatatcagctactaat780
cctacgaagcctacactaccaatcctaatcctatcaatcctatcagcctatcaagctatc840
aactaccaacccatcaacctaccatcctaacaaacctatcaacctatcaacctatcaacc900
tatcaacctatcaatcctatcaacctgtcaacctaccaacccaccagcctataaaccctg960
tatgtgttgctccgcaatccccggtggcccgcagattaat1000
40
1000
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
40
taagtcttgtatctgttacgacgctcccagtctccgcccttgtcgatgagcagtttgacc60
gcctccagctcctgggccacaaacaccttgtcgtcgaaaaagaagccaatacggatgatg120
gttagcgaaatgtcaatcttgactccggacgagcccgtgagctcaaacgcctttcgcagc180
gtcgaaatggcctgctcgcggtcgccaatcttagcgtagtactctccgagcttgacccag240
ttttctacaatcgcaagctcttcctcctcctcctctgcctcggcaatcttcttctgcagc300
tcctctacctgctgctggttctccttcttaagctcctcgtacaacgactcgtcccactcc360
agcactcctggcagaccctcggtgtgaaggtactgatataatggggccagcttttccttt420
ttgatttctgtcatgagcgtctttttagcctggtcatgctgcggtttgagaaacggcgtc480
ttcagcacaaagatgcattgcgccagattataatcgggcactcggtcaattggagtcgcg540
gctccttcgttcacacccatcctacctgtctatttactccagcagtgtgtgttagtggca600
actgggaagtgtcgctggttttggtgtcgatggtgcagccgtgccgtatgagccaccact660
agccacaatctcccgccggtgtggcggtgctcgctctatttatacagcaaatgtgcaaca720
caactgtagttttgttgtaattctgccaattgcacaacaaattcacagaaaaattcacaa780
gaatgttctactaacgtagcagtacccttggccaagtaatcgtatcgatcgatcgcaatc840
ctgatctcaatcggtcccaattctggatcccctttaccctagtctcctcccctgctggtc900
ccctactaccagcgtaaacaaggcggaagaccctgcgttcctctgcggtggagcaaacct960
ctctctgtcactttcacttttttcactagcagcttgtaca1000
41
1000
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
41
gtctgagtttggtcagattttcaaaaacccatcaaaggagttcttccagaaggcagagct60
tcgagctgccagagcgacatggcccaagatgtcccacattcacaaccgtgtggccatcga120
gttggctttagtaaaggcaattcacaagcttcgtgcccgtattgtatctcagagcgtcca180
tgagcctggcagttctctacaagtacatgctgctaatgacgaaggcaccctagcacctat240
tcgccgtcgccattcttcgaccaagcttcaccatagacgacaacggtccgatggaatggc300
cgtgaaatacttggtccgcagacattcgctacagtactttggcactgagggccctggtcc360
cgctgcgctatctcgtaaaaagagttcggccgggcttacccaggctcatactcctacgcc420
ttcactgaccaacagcgttagtgtagggggcagtccaaggcaccgtcgcttcactactag480
ctctagacagtcctcaggagaccatttggaaatgttctctcaaaatcatccgctagaacg540
tatctctaccggctgaccgcaacggtcttcattcatggcaattagacagctttaaattat600
ttagaactacaaactaccaatgcatgctttacgacctttacgacctctacgaccgttaac660
aaccgtaacaaccttgtgtctaattatcacagtctatcacagtctattacagtccatcac720
agttcatgtcgtattcatctataaccttccatgacttccctcgtccctgtcgaaggccat780
cgaacttgcccgtagttattaatttgtccgtcatcatcaagctgcatgacccccgacgcc840
gcacgccccggccgaccaaccatcaaaggcgataagaatgagtcaaaaaggactaaatat900
tccggatcacgtaatcggcgcagtataaaactgagctcatccgcatatttctaggcactg960
aaaattccaaagactttttcaactctaatcaaaaacaaaa1000
42
1000
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
42
tcagaatgttatcgacgaggccaacaaggccacccaatcttaatgatctacgattggact60
ttgtacgacatagggatgacgatttttagattagtaatatataaccgaagacaataaaga120
tatttgtggattctattaacaaactcactaaaagaataggatgatacgaagcaattgagg180
tcccaatgcttactggagcctggggaaaaatgccagtaaggtgccagcatggcaggggtt240
tgcggtgggtcggttaggcgcgtttggacaggggtcaggtacagcggaaagctgaccatt300
caacgcaaacctaataactggaatttttgtagttttattctacatgttcaattgctggtt360
ttactcaaattctgaaccatgcgagcgcttgtctacaggtcctaaagtccctacagctcc420
gtgtatgcagcttgtcaacaggtgtgacgagcactacacgtttcagcacaattgcgttcg480
taacagatttttccaaggcttactagcctgtcactattattctaccggccaaattataca540
ctttcaagcaattacttttataattgcaactctactttgcaattgttaattgtccacgac600
cgtcgatgacatgggtccctaatgcgtgggggccgcgcgcacggctgggaggactcgaca660
taataaattattgcaacaaagccaaatcaattaggtgagggctgcaacgcattggcaacg720
agtgaccgtatctgaccaatgtccaatctgcctactgaaagctgccattgcgtcgtatac780
ccctgatttgtgacatatcagccattgcctccttaattgtcatgctcatatactctttct840
acactaaataaaccccctcacggggaacgccggcaacccgcagcataacccgagtaacgc900
tcccaacaaatttggcacggcccggtagataccggaaaaaggctcggaaaaaaatctaaa960
taactttgcaactgacccttcaaaggttgaacagtacatc1000
43
1000
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
43
ggagaagatgtgggatattattggtcttgtaggagcccgattagggtatgattgggaccg60
acaaggaaggattgtctagactagtctagcctagtccagactaggtctgtaccattacga120
gtcgagaactgcactctgatcttgtgctatgtacgtgtgatgtaaatgaatgacgaacaa180
tatgacgcagacgtggatgttaatctttggatggacacatttatatgatggtggaatggt240
ggtcgttgtgaacagtatttaacaaccagattcccacactcaacttaatacaaggactca300
atggctctaaatagagctgaataagtacaaggcattgttactttataccaattgagctat360
ccaattgagttatatcaaccgtttgacgatccataattctcagtgctgtctacctcgaat420
aactggaactactggctccaattgaccggcccagccagtgccagacagtaccaattagtc480
caaccactcccatatcaccaattgaacaaatccaattcccctaccaccgttacctgtaac540
tcaccccatttcaatttgcctgtccagcttatccagcttatccatccgggattccgtttc600
ctttctcatcgctgttggacccccactctttccctaacacactatttactctagtacaca660
actaattataatactattctcacctcacctccattcctcctcactaattgccactgaacc720
tgccacaaccaccgcaccgtaccatactaattatcctggccaatttcgccagccaattcc780
atccacttgtctcgaatgtttacatcgctactttccctacacgcttcctcgacccgggct840
ttgccagcgtccagcggggttcccaactagtgcacggcagacccgggtagggcccccaac900
taatgatacctaccgggccactctgaaaaaaagacgccgttcgagccggatttttccgtt960
gtatttggtcagaactttttttcctactcctgtattaaca1000
44
1000
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
44
tatattgaattgatacctaatatacaatagattgtccctgggacattacacgtagacgtt60
gaattgtcaactacagtatcgtcaacaggaagaacattctgtatgcccgaattgccatta120
ccaatcctggtattcaattccctgtcccctgctgtctcttgctgtctctgtggtctctat180
tcctagaatacactggccgagagttcggctcagtgcctgctcgtgatactcggtacgaag240
cctaaattgtccccgcatggttcgattccaactggaatcattttctggagtaaaatcctc300
ggcccacgacaataatccgggtgacgtcatgtgaccctaggagggcaaacgccggcgttt360
cgcaacaaagcagccccagaaggccccgtttgaagcgccagaaccgctctccagcgagac420
tacaacccgtactacgtatctacccgttttgtagcgatttccagcgtcaatttcatgtcc480
ttttcttcatctccagcttctccagttcactctccagcccttctgttcatctccttactc540
cgaatcgggggatttttggcaagggttgtccgattcgtcggtcgggctgcggcttgggtg600
cccattaacgtgaccgaatgccgcactccccccgattgacgaaacaaaggaaagcaataa660
ctggggtaagaggagattgggtcgcaatgattgcacgagcccggacggtagcgcaattga720
gcaccattgtcggcggtcgactgcctgggcttctggtatgcctgcaaatgccggcagcat780
ctccgaccaattaccgtagtgaattttgtgcagcattttttaccattaacccgatgcccg840
aatcggccccgacacctgcgtttgtgtaattgcgagcccatgattggttgccccggacag900
gcgtggctttccggccccaaagtatataacaaactgcaatcgcaaattcgcatttttttt960
tccgtcgtctagttgcaagtccaattcgcggagatttacc1000
45
1000
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
45
tcgcaggccgctaatagaacagtgggctcatttgggcggctcaagccgcattaccactgt60
ggcctcacggggcttacggggctcctgcggctcctgcggcgcacaaccgtgtatatattt120
ccgctggattccacgcccacggtagtctaatccatgtaacgggttgctaaattgtctaga180
attgctaaacttgctaaattgctaaacttctgaacgctaaaactgctaaattgcttactt240
ctactactgccattaacactctggctattgcttatccctatacctacctgttcttcgctt300
ttctatagctattttcacactgcccattggtttcccattggttagaacccgagggtcccg360
atgccggcagccgtacaccctggcgtctttgtccaaaactgggccgtatcgcggtcagac420
aacaggccattctcgggtggtatgagagacggactaatgcgctagtaacatccggtctat480
accattgagcgcctgagtaaccacaattgcgtgactaattctgtttgcattcggttaacc540
cctctctgctctgatactaatcgtgacggcgcggcgcaattatcgtgtttgttgggcgtc600
ccctgtccgagatttgaaggtcccgataattatcgtcggcaaaaaccgttactataatgc660
atttgacggacccaaatgatgagttggcaaccgtttgcaatcacaatgaccccaaatcct720
gatggaaaatgccttgaaaggtacatttccacatttagtccactcccccccttggtcttg780
ttgagcgccccactgcgtctcattcaatgctgattggttctttttgaccaaacggtggta840
tattatctaacgcaccatcacacaagggcgaggctagttgctacatggcatcatgctgca900
gatgatatatatataaagccctctcccacccgcaggaccaacaagaaaaagtttcacacc960
aaagtccgtgtatcttttttgtccaaaaaaaataacaaca1000
46
1000
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
46
aaaaggggagacgtcagccatcctgttagtgtcagtttgccctacatttgcgcgtccctg60
tgtccttttatattcctctctcctgaagccgaaaaaagtaattgcaaactaccatgcggt120
ggggacatgatggcagataatcaccgatgatgattatcgcacaccgtgattagcggctca180
tgtcccatgatgtggcgctaccctgccggagcgccgaaaaacctaccgcagcagctagtt240
tccccaggctgccacatgaaacgaggagaaatagcaatcccttggccgcgggaccagttg300
ggggccagctgggggccattgaggtgtcattgaagtgtcattggcttgccatagaatcta360
tccatagtagagaacgtccactttttgttcttggatatgcataagcgactccagggtggg420
taaggattatccatcttctatcttggcacataggtagaagtccgcattcttgccgagtag480
ccgacaatatatccttaagctccacaattgactttcagattagaggtttacccaagtagt540
accaaggagtaccaagtagtaccaaatagtaccaactagcagttgtgaactcatataact600
gtttcatttggtggatggaaatcgtcaatagcggagttccatagaacggttgtataatac660
ggaagggacacactttgttggttccattccaattgtgctagccaagcaatagtcggattg720
cctgcaggttaaagttagtcacgggtacagatcccgagttcagcttcgagggagtagcct780
cgtggcagttgtccacgagcatcaatggatcaagccacatggttttcagttctcaatttc840
aaagaaaccatcgcatagcatcgacttagtccaattcttgagctcttgggtgcgcatctc900
ggtcgtggtcagggactgggaaaaaatgcgccgcatacacagcggcgtgcggccattacc960
ttcacgcgcagagtcgcgtttgtgttgtcacgaatgacgg1000
47
1000
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
47
agcaatccaaacagtcacgtggccgttgtcaagtgaggactgcccgtgagtgcccccgcc60
atggatgtgtcattatcacgtgactctgacaaccaagccaattgcccccgtgtctcacac120
tcacattccagcaactgggcgccgatggagtgttacgagcggtgagtcatcagatgtgtc180
aactacgtacgagaacaatacacttgatcattctccgttcccctgacgtgccccttgcca240
tggtgatagaactaaaggatggtgcggcaaacttttcctttcttctcaaaacggaaagga300
gtgtttcggatacgggagcgcgcgcagactccggtccggagtttgacaagactcaggggc360
ttctgacaggccttattgtgaagaaaccagcacttttctccagtaactatcctcacagga420
tgccatacacgtagattagtaccaatttaccctcagtacattgctcattgagcaaacttt480
ccaattcaatctagaatgatgtccggcgattctcgccataacgggtaccggcgatctccc540
tgcgccgcacgtgcgcctcttggacgttcggcactccgaatatccactgttttgccttgc600
ctgtggtgcggaggatgagtaaccagtgggtacaattggctccagtttgccatcatcatg660
tagataagaatagaagcaaactggacagctgtagtcgccaccactagacagttgcaattg720
ccactcacgggttctatacaccaaaccacggtctggttctgcccctttatttgaccgttg780
tcgttggctcttgtcctcaacaaagctcgcctacctcgcatacgaggtagcatgcgcctc840
acttttttaaatacgaaaaagaaattcttgggcaaatacggaaaagaaattattgggctt900
ttcgtccccgccgatcaacgcagtgatcttgcgaagacgatatataaacagccaagagtc960
cccgaatcataaactttttcatccgcgaattagtgctgaa1000
48
1000
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
48
ctaattcaagcccactgttgctaatctctcgacaaagcgttgagaaactgtcagaggatg60
ctcaaacggttgtggatccatcggtattcaggggtaacattgtcatctctggtacaccag120
catacaaggaagacgaatggaactatatatcaattgccggacagcggtaccggctcctgg180
gcccttgtcgtcgttgcaacatggtatgtgtgaatggccaaggagagatcaattcggaac240
cctattttgcactacatcgtaccagaaagacccaaggcaaactactattcggtcagcaca300
tgactcttgatcaacctactgattcactgaaccctgcagaagctacaattaaagtaggcc360
aattgttcactcctatctgagacagttcacctgcagccgtgcaaactgtcaacgagggcc420
gaatgatatggaaataatgattatgccgttatgactgtaatatgaatgaaaaaattttcc480
ttatgcattattaaagacccaaaataaacattcctgcccctgatttacaggtttatccgg540
aaggacccggtcaaagaaaagttttccatgcgtaaaaataatattctgcgtggggggtcg600
gctcccgactgtggccctatcaatagtgcggctgaagagcttacagaccaagctttttag660
ctccggacaaatgaatttggtaacaagcatacaattttgttagaagtattgcgcttcttt720
ggtaattttttagtatctttagtagtctttatccaatttatgttcatttatactttgact780
tggccccctcgttatcttaacggtgccaggacactatcgtgcattatcggaccggatacg840
gccgataaagcgggtcaatgtcacagttaccgattgcttacataaaagtggcgcggcgaa900
ccgtctagaatggtggcgagtatataaggaggccatagcctagctctggacacatcacat960
aaacaactacaaacttttacatttacacgtcgcatctacc1000
49
1000
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
49
acggcggtatccgcagctttgttgacgacaaggctctgcgatggttggcagtcaactttg60
cataccacgaccttctggcgtcttcggcgtgctcccgcaacactcactttccatccgcag120
aatacgatcacgtcatgaagcatggctacggtctggatgctctcacgggctgctgccagc180
ctctgttcaagattctggccgagatttccgagctcgccgtcaagtggcagcgagtggacg240
atgcgtccttggaaaagctccgaatggtccaggtccgcgttagcgctctggagcagaagc300
ttgaatcttgtcaccctgatcctctagacatgatctccctttctccccagcagcttgacc360
tccaattgattctatttgacaccgtcaagattaccgccaggctccacctgcgccagtcgg420
ttctgcgtctcaatgctgcctcccttgacatgcaatgccttgtcaaacagctcaacaaga480
acttggagctggtgctgggtacccaggtcgaagggttggcggtgttccctctgtttgtgg540
ctggtatccattgcgtgaccacctcagacagagagctcatcaccaaacgcattgatgact600
actactctcgcaacctggcccgcaacatttctagagcaaaagatctcatggaggaggtgt660
ggtctcttgatgatcacggctctcgtcacgttgattggtaccgaatcatccaggctagag720
gatgggatatctgttttgcctaacagctaacacgtaacgacttatgactactaactgcat780
atcaactatcaacaatactatccttattcaatcaactatactatctttattaagatcatc840
tactatccttattcaaatcatctatcaactatcctcaaatttcgtctgtatgtgatccat900
gcacgtgacctttacccgtgaccacatcccgtgacaatacacgtgaacagttgtgccaac960
tcagcaccaaatcccctttcgagcttaaccgacgacagca1000
50
1000
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
50
aatgattgatacaccttgttacgaccttgctgcgtggtgggcaagtaaactggaacttga60
tatatgcgtgccgtttatctgtcataagccaatcgtcaatcacacaatcaaatcaaaaac120
tactgctagcatggcgaacctaaatgggcatcaatggaaattatacaaacagtacgagat180
gaaaacagtcagctatgtcatggtgtgatagttaccaggttcattttctgatttcctttg240
ccagttctgtgcgcctgcctcattggatttgactctttttggcatcatgctcacctctgg300
tgatacacgagctagactgctgaaagaagtatcagcacagccaacgaggttgcagcaaat360
agggcatacctgttatcgccgaccaggcattatcgaccaccagctatttgcgtctcatgc420
atcccatttcctgatgaagctgtgtcccgtcgattacgcctatccttctttgccaagcct480
taccagggacccaatcatatcgggaccctacgcaacgtgaatccggggtaggatatcgag540
ctcccgaacgttgaaccaaattttaacggtggtgggagatcacagatcagcgacaccact600
ataatctgcagtcgcaaccatcacagacctccgtgaagtgatatagaatcgctccagaaa660
gactatggcaggctcgtttttcccagtgcaagagctatttcgggcgagcttctagcggct720
cccattgtcagaccttaattgtgctccatttaggcacgtggaggtgccaagattagtgtt780
tgaggattctccctgttgccaagtctctaaagaagatagacagtgttaagctactgagct840
tggcacttgactacccaatgagaaggatgagccaacccacctgatgagtaggtatcaggt900
aacggttgaccatagaacgagtcaattgtggaaatataaaaagggagccaaattggattg960
attcaccaagaatccaataaaaaaaagaagtcactgaaaa1000
51
1000
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
51
agctcgttccaccccctttccccctgtctccaccctaaccctccggtcatactagcacca60
ctaccgaatgagagtagcaccatgtatcataataaccgcgccagggcgacacaacattga120
ccgaacaatatcaatatcgaggtacaataactgcgtgtctgtgaggccagattacatgcg180
tctgcacgtttgtgaccgatatcaggcggcggccgataagggcaagtgaaatttcacgtg240
gaccgtctcacgtgaacacgggatggcggcagcaatcgttggcccaccgtactggccaag300
caggcccaacaataaagaaattcagtggaaaaacccagaccaggggacgcagcgcacccc360
tgtaaccgcccggcacgcccggcgcgattgagaccaccgcagagtttttccggcacagtt420
tttccggcctggggtgacccttgagcgcgccggaatggcccgtatcaccctactccgaca480
gaacccggtgcggcgagctgaggcggtgggacgattgcggcggcctgcggcgcatttcgg540
gaccgccttccttgttatgatacgattgcggcaccgtgaggcgttcctgatggttccgag600
attcagcgcaaccttgatgcaacaagtaatcaattcgcagccagaatggtggcaatttgg660
tgagcaatagtaaaaaaacagtagaatataggtgtaggaaaacgtagacagtaggctttt720
tgggtccctttagccattgtaactaaatagctggacctgcaggacaaagaccctgtacac780
ggaacaatttaagcccttagctgtacccacaggcatcccccaccgttttaagggacgtcg840
caactaacgcctaaacggaacaaggacccggaaagtcgtacgtctaatacggcaaagtgg900
gctataaaagggggcgctactgccaacccaatgagttcatccgatcaccattgacagttg960
tcaattaacaatacacatccatcttgtaccctaaacaata1000
52
1000
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
52
tctaccatcaggaaactggaggggcgtcttcagtacgacaaggcggagaggtatcgtact60
ctttggcaactgctcctaggatcgattctactcctttgtgtctatgccattactaatttt120
ttattttttatggccgaagaaccgaccctggattccagcagcacttggaagtctcgttgg180
ttcattctggaagaatttcctaatctggtttacttcgttgactttagcgttattgcctac240
atttggcggcccaatactaacgacgtcaggttcatgtcgtccaagattgcccaggatgag300
aatgaagttcaagagtttgaaattggatctctccgagagtctatggacgagtaagagata360
ttaaggaattgaaaaagggcaagaaaagagcgatgagcgtagaaattgcgtagaaattgt420
agcagtatcaatacccttaccatcacctaaagcaaaccaaaagatcccgggtgaatctcc480
gggacctgagtagatggtaatacagaatactggcagaatactgcactcagaagaactctg540
gaagaactctggaagcagtctaacggaccccagtttggctcttgaacattcacgtgactg600
gaaacttaacatcacgtgacctcgtccagtctggattgaaatagggctgaaataaaaaat660
cagtacacaatgagagtttggccgagtggtctatggcgtcagatttaggtaaaccctaaa720
gtgaattctctgatatcttcggatgcgcgagttcgaatctcgtagctctcattatctttt780
ttactccctttccgtttcggactaaccacggataccttttccaagcaatttgcgatccaa840
ttatttttgttcttttaattaaatttagtttcattcatctccggtcccccttgatagatg900
aacgtccgtatttaccgttaagccgcataaccgccaggaaagccccgatctgtcaacctt960
ggcatctactacgtttcgtttataactctcgctcgtttta1000
53
1000
dna
解腺嘌呤阿氏酵母(arxulaadeninivorans)
53
gcccagtgcattgtccttgtcattctaggagtggcctttttcattgcatttgtacttgta60
gaacgagctgtggacacccctctagtaccggttcgcaagtttaacactaatatggccaga120
gtgctcgcttgtgtggcctttggatggggcacttttggtatctggatttactacctttgg180
cagattatggaatacctgcgacacaactccccattgttggcttcagctcagttctctcca240
gctgccgcgatgggtgccattgctgcaattgctactggatacctcatgtcaaagctacat300
cctttccgagtgctggcaatttccctgttggcgttcctggtcgcttcaattatcaccgcc360
acggcgcctgtaaaccaaacgttctgggctcagacgtttgtatcaatcttagtagcttct420
tggggtatggacatgaacttccctgctgcgacccttatcttatcagagaccgtgcccagg480
gaacagcagggaattgccgcctctttagtggccactgtggtcaattattcaatctcccta540
agcctgggagttgcaggtactatcattgagcaggtatctccaggtttggaccctaattca600
tatttaaagggcgtccgaagcgccctatatttctgcattggcctctctgccgccggcctt660
cttgtcgctctctatggtgtcatcagagacgacattcttgctaaccatgggaaatcctct720
aacgacgaagaaaagaatactgcttgaaatgcttttttaatagaattttgctcttatttg780
tcctatttaatctatatttcatgtacgaatcgatttctaatcttaacaccgcggagattc840
ttttgttattactaaatcaggaaaagatgcacggagaactcggcccgagttggatttgat900
ggcatctcggtccgagttaaacgtggggtaatcttttagcggggaaagttataaaacccc960
tacaaagcccaggatttgtgaattcacatttgacaacaca1000