一種基於大數據分析的性能自動調優方法及裝置與流程
2023-10-05 00:19:09 4
本發明涉及數據處理領域,具體涉及一種基於大數據分析的性能自動調優方法及裝置。
背景技術:
城市軌道交通信號控制系統,是鐵路運輸的基礎設備之一,它擔負著路網上行車設備的運行狀況、列車運行的實時狀態、運輸調度的指令控制等信息的傳遞與監控任務,在控制列車運行,保證列車安全,保證高效運營組織方面發揮著核心作用。
維護支持系統(Maintenance Support System,簡稱MSS),是軌道交通信號系統中的一個子系統,是管理軌道交通信號系統大量設備和維持信號系統設備高完好率的重要組成部分。是整個信號系統設備狀態監測和維護的輔助工具。
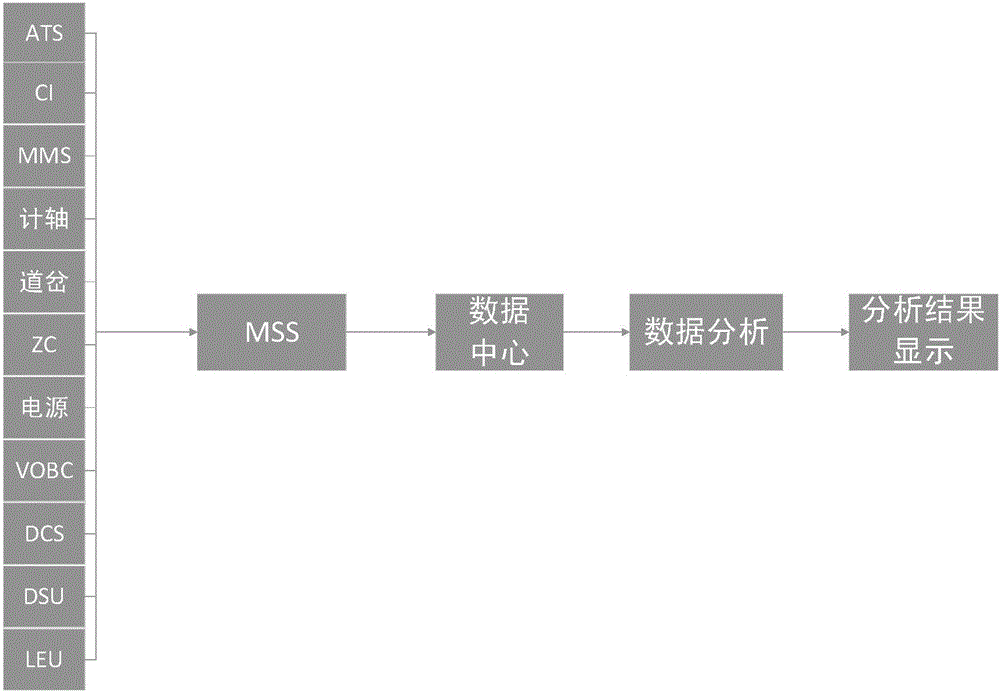
大數據平臺(Basic Data Management Stage,簡稱BDMS),是軌道交通信號維護系統的核心,其主要功能是對各信號系統進行軟硬體故障分析處理以及維護工單的下發等。大數據分析功能中,使用轉轍機舉例說明。如圖1所示,MSS採集轉轍機數據發送到大數據中心,大數據中心根據採集到的實時數據(油壓曲線、模擬量等)結合資產數據(資產號、設備號、使用年限、開始使用日期)和歷史數據(歷史故障次數、故障原因碼、歷史油壓、歷史電流、歷史轉轍機模擬量等)進行狀態預故障分析即數據分析,根據分析結論,給出需要對故障進行的補救和應急措施,如:購買設備、更換設備的某元器件、上油等。
通過歷史數據可以分析出設備的性能,包括最快轉轍速度、轉轍反應時間等,根據歷史故障和使用年限等數據,可分析出設備的老化程度,包括設備的磨損率、剩餘使用年限等。傳統的分析處理過程為人工製作某項功能的處理函數,此功能的處理方法永久維持不變,系統分析速度會隨著數據量的增大而減小。
目前信號系統的維護方式存在以下缺陷:
大數據平臺系統負責分析各子系統的狀態數據和設備信息,由於數據量龐大,數據結構複雜,在根據實時數據信息進行分析時,無法在規定時間(如3S)內計算出分析結論。
在大數據分析過程中,在分析數據時可能需要對某類數據進行查找,現已大家熟知的查找算法舉例說明,不同廠商可能採用不同的算法來對數據進行搜索,例如,廠商A可能採用二分查找法,廠商B可能採用順序查找法,廠商C可能採用分塊查找法。但是,缺陷在於,一旦採用了某類算法,就不再改變,由於數據量增減帶來的影響,導致分析速度時快時慢,不能保證系統始終保持最快分析速度,給軟體性能帶來嚴重影響。
技術實現要素:
鑑於上述問題,本發明提出了克服上述問題或者至少部分地解決上述問題的一種基於大數據分析的性能自動調優方法及裝置。
為此目的,第一方面,本發明提出一種基於大數據分析的性能自動調優方法,包括:
接收用戶輸入的設備類型、狀態數據類型、包括分析方式和設備標識的執行條件;
根據所述設備類型、狀態數據類型、執行條件,從數據中心篩選出預設時間段內待分析的數據量;
根據數據量、狀態數據類型、執行條件,確定算法動態庫中每一算法的性能值;
選取最高性能值對應的算法,依據執行條件對待分析的數據量進行分析,獲取分析結果。
可選地,所述方法還包括:
在人機互動界面顯示所述分析結果。
可選地,根據數據量、狀態數據類型、執行條件,確定算法動態庫中每一算法的性能值的步驟之前,所述方法還包括:
建立所述算法動態庫,
所述算法動態庫包括至少一個算法;
或者,所述算法動態庫包括至少一個算法及該算法對應的影響該算法性能值的各項的權重係數。
可選地,所述算法動態庫包括下述的一項或多項算法:
二分查找法、哈希表查找法、分塊查找法、順序查找法、堆排序算法。
可選地,所述方法還包括:
將所述狀態數據類型、數據量信息、最高性能值對應的算法作為配置組合進行存儲。
可選地,所述方法還包括:
在維護系統處於空閒狀態時,採用不同狀態數據類型的數據量、模擬執行條件,對算法動態庫中的各算法的性能值進行評估,獲取各算法對應的執行條件、數據量、狀態數據類型的權重係數。
可選地,根據數據量、狀態數據類型、執行條件,確定算法動態庫中每一算法的性能值的步驟,包括:
根據每一算法對應的執行條件、數據量、狀態數據類型的權重係數,確定算法動態庫中每一算法的性能值。
可選地,所述分析方式包括:
狀態預故障分析方式、狀態預處理分析方式、設備性能分析方式、設備老化程度分析方式、和/或設備最大可用期限分析方式。
另一方面,本發明還提供一種基於大數據分析的性能自動調優裝置,包括:
接收單元,用於接收用戶輸入的設備類型、狀態數據類型、包括分析方式和設備標識的執行條件;
數據篩選單元,用於根據所述設備類型、狀態數據類型、執行條件,從數據中心篩選出預設時間段內待分析的數據量;
性能值確定單元,用於根據數據量、狀態數據類型、執行條件,確定算法動態庫中每一算法的性能值;
選取單元,用於選取最高性能值對應的算法;
分析處理單元,用於採用選取的算法依據執行條件對待分析的數據量進行分析,獲取分析結果。
可選地,所述裝置還包括:
算法動態庫建立單元,用於建立算法動態庫;
所述算法動態庫包括至少一個算法;
或者,所述算法動態庫包括至少一個算法及該算法對應的影響該算法性能值的各項的權重係數。
由上述技術方案可知,本發明提出的基於大數據分析的性能自動調優方法及裝置,通過獲取數據量及數據結構,進而選擇最優性能值的算法,採用選擇的算法獲取分析結果,能夠提升系統處理事件的效率,減少人工等待分析時間,進一步地,優化執行速度,在相同數據量情況下,減少事件和空間複雜度,進而能夠處理更大量的數據,使得系統性能達到最佳狀態,系統以更加穩定的狀態高速運行。
附圖說明
圖1為現有技術中的數據分析的過程示意圖;
圖2為本發明一實施例提供的基於大數據分析的性能自動調優方法的流程示意圖;
圖3為本發明一實施例提供的數據分析的過程示意圖;
圖4為本發明一實施例提供的基於大數據分析的性能自動調優裝置的結構示意圖。
具體實施方式
為使本發明實施例的目的、技術方案和優點更加清楚,下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚地描述,顯然,所描述的實施例是本發明一部分實施例,而不是全部的實施例。
圖2示出了本發明一實施例提供的基於大數據分析的性能自動調優方法的流程示意圖,如圖2所示,本實施例的方法包括如下步驟:
201、接收用戶輸入的設備類型、狀態數據類型、包括分析方式和設備標識的執行條件。
本實施例中的設備類型為識別某類設備的標識。例如:轉轍機、信號機等;狀態數據類型是識別某類數據類別的標識。例如:電流值、油壓值等;執行條件是檢索和分析所有數據的條件,將負責此條件的數據抽取出來。例如:設備編號=001,將查找所有設備編號為001的數據。
本實施例中的設備類型、狀態數據類型可由數據中心統一編號實現。
舉例來說,狀態預故障分析方式、狀態預處理分析方式、設備性能分析方式、設備老化程度分析方式、和/或設備最大可用期限分析方式等。
202、根據所述設備類型、狀態數據類型、執行條件,從數據中心篩選出預設時間段內待分析的數據量;
203、根據數據量、狀態數據類型、執行條件,確定算法動態庫中每一算法的性能值。
本步驟的目的在於預先比較哪些數據類型和多少數據量更適應於哪些分析算法,針對不同的狀態數據類型和數據量的多少,選擇不同的算法,使得分析速度能夠更快。
本實施例中,性能值是反映算法執行效率的值,執行速度越快,性能值越高,使用性能值作為評估算法的依據。
舉例來說,本實施例的算法動態庫包括至少一個算法;例如,二分查找法、哈希表查找法、分塊查找法、順序查找法、堆排序算法等等,本實施例不對其進行限定。
204、選取最高性能值對應的算法,依據執行條件對待分析的數據量進行分析,獲取分析結果。
需要說明的是,現有技術中每一廠商固定使用一種算法,若採用上述圖2所示的方法比廠商固定使用算法效率高,可替換該廠商使用算法,實現對廠商算法的自動調優。
本實施例的方法,將傳統的分析方法自適應調整化,優先選取算法效率最高的方式,可使分析性能達到最大化,有效提升分析效率。
在實際應用中,上述圖2所示的方法還可包括下屬的圖中未示出的步驟205:
205、在人機互動界面顯示所述分析結果。
通常,人機互動界面可為維護系統用的人機互動界面。相應地,前述的步驟201中的接收用戶輸入的設備類型、狀態數據類型、包括分析方式和設備標識的執行條件等信息可具體為:
用戶在人機互動界面操作,如選擇設備類型、狀態數據類型等信息,進而輸入/選擇分析方式、設備標識等信息。
另外,前述的步驟203之前,上述圖2所示的方法還可包括下述的圖中未示出的步驟A01:
A01、建立所述算法動態庫,。
該處可以是人工預先將各種設備的算法/函數增加到算法動態庫中,也可以是軟體自動查找當前各廠商使用的各種算法/函數進行處理並合併。
例如,人工可以輸入與轉轍機相關的常用算法/函數。
本實施例中,算法動態庫可包括至少一個算法,如二分查找法、哈希表查找法、分塊查找法、順序查找法、堆排序算法等等。
舉例來說,算法動態庫中的二分查找法的特點是:查找速度最快,但是數據量較大時才會體現效果。通常,二分查找法適合數據量龐大,且無序存儲。如轉轍機電流數據,由於系統設計問題和採集周期較長,導致數據無序存儲。每天數據量大約800萬條。
順序查找法的特點是:查找速度一般,數據量較小時,速度快。通常,順序查找法適合數據量在1萬以下,最好有順序存儲的數據,如信號機的狀態數據,全部按照時間順序存儲。每天數據量大約8千條。
分塊查找法的特點是:查找速度介於二分法和順序法之間。通常,分塊查找法適合數據量較大,且無序存儲。如區段狀態信息。數據量較大。每天數據量在230萬條。
另外,在一種優選的實現方式中,上述步驟A01中的算法動態庫可包括至少一個算法及該算法對應的影響該算法性能值的各項的權重係數。
此時,前述步驟203可具體為:根據每一算法對應的執行條件、數據量、狀態數據類型的權重係數,確定算法動態庫中每一算法的性能值。
通常,在維護系統處於空閒狀態時,該系統可採用不同狀態數據類型的數據量、模擬執行條件,對算法動態庫中的各算法的性能值進行評估,獲取各算法對應的執行條件、數據量、狀態數據類型的權重係數。進而將獲取的權重係數等存儲在算法動態庫中。
可選地,在前述步驟204或步驟205之後,上述圖2所示的方法還可包括圖中未示出的步驟206:
206:將狀態數據類型、數據量信息、最高性能值對應的算法作為配置組合進行存儲。
上述方法針對數據分析過程中的算法進行優化配置,達到加快分析速度,優化分析結果,減少人工等待時間的效果。
以北京地鐵7號線平均每天的數據為例說明如下。
以下以轉轍機為例進行舉例說明,如上所述,道岔轉轍機的數據使用二分查找算法進行分析最合適,為了體現出本發明實施例中可自動調整算法的目的,因此將分析道岔轉轍機的電流數據的算法默認設置成分塊查找法。
目前,信號機、區段、轉轍機、應答器、電源、通信板等六個設備分別具有設備類型編號0x01~0x06。當接收到設備類型編號為0x03的數據時,認為是接收到了道岔轉轍機的數據。
由於是道岔轉轍機的數據,現有技術中會自動地調用分塊查找算法對道岔轉轍機的數據進行分析。大數據平臺(即圖3中的數據中心)中轉轍機的數據結構如下:此數據結構編號為」S1」,如下表一:
表一
在該數據結構中,轉轍機ID為數據中心對此轉轍機的唯一編號,對該轉轍機的電流值的一天的數據進行分析,其中,每隔10秒對道岔收集一次信息,道岔由於收集信息時間較長,電流的採集間隔10毫秒採集一次,導致收集一次道岔信息的電流曲線內部數據量較大,經計算,一個道岔,10秒採集1000個電流值,每天將採集864萬個電流值。
假如現在需要分析某個轉轍機的故障率,那麼分析故障率就是通過對某轉轍機一天的動作電流曲線進行檢索,如果電流超過35A,那麼就認為出現一次電流過大,現需要在864萬個電流值中掃描所有超過35A的電流值,此過程由於數據量較大,對算法要求較高,可見選擇一個合理的算法的重要性。
本實施例中通過性能值確定使用二分查找算法進行檢索分析,可以在1秒內完成。而採用現有技術中的某種固定在硬體內部的算法(分塊查找法),如果該算法不適合於分析轉轍機的數據,那麼將大大延長處理的時間,甚至是無法處理道岔轉轍機的所有數據,而無法實現分析目的。
另外,結合圖3對本發明的方法使用過程進行舉例說明。
上述圖2所示的方法可在圖3的虛線框的範圍內實現。在實際應用中,為更好的使用上述圖2所示的方法,本實施例中使用方法庫、算法庫等進行配置。
第一步:算法庫配置
(1)預先將大數據分析方式(狀態預故障分析、狀態預處理分析、設備性能分析、設備老化程度分析、設備最大可用期限分析等)寫入分析方法動態庫。
此時,調整該分析方法動態庫開放分析功能接口。即用戶可以通過界面選擇相應的分析方式;
接口參數包括:設備信息、狀態數據類型、需要分析的功能編號(1、預故障2、使用年限3、老化程度)等。
(2)預先將常用的算法(二分查找法、哈希表查找、分塊查找法、順序查找法、堆排序算法等)寫入算法動態庫。
另外,由於現有的哈希表和泛型算法的數據結構比較特殊,故可預先將哈希表和泛型等數據結構用法存入方法庫,用戶在選擇哈希表或泛型算法時直接調用開放的分析功能接口確定數據結構。
第二步:狀態數據類型識別
根據分析功能對所有狀態數據類型進行分類。
狀態數據類型:1:轉轍機位置,2:轉轍機油壓,3:轉轍機電流,4:轉轍機故障狀態。
狀態值:轉轍機位置信息值(定位0xaa、反位0xbb等),油壓值(轉轍機油壓曲線),電流值(轉轍機動作電流曲線),轉轍機故障狀態值(正常0x66、故障狀態0x55)。
第三步:算法性能評估
在進行數據分析前,自動獲取之前使用的算法,對之前數據量和當前數據量進行對比,根據評比結果計算數據對本算法的性能值,性能值為執行數據所消耗的時間(毫秒),時間越短,性能值越高。
例如:對轉轍機動作電流進行分析,此前使用順序查找算法,之前數據量為100萬,當前數據量為864萬,在算法庫中查找配置好的分塊查找法、二分法和順序查找法,分別在後臺運行以上三種算法,根據後臺對864萬數據量運行使用時間的記錄,二分法數據執行速度為230毫秒,分塊查找法執行速度為300毫秒,順序查找法執行速度為10000毫秒;因此,在分析電流值時,應該利用二分法。通過模擬真實計算分別計算出性能值。
在系統空閒狀態下,分別對各類數據自動進行不同數據量的模擬,將模擬出的數據注入到算法中,利用與分析轉轍機動作電流相同的分析方式自動對所有算法的性能值進行定期評估。
需要說明的是,由於部分算法可能對應特殊的數據結構,為此,在使用該算法時,預先將待分析的所有數據按照特定數據結構存儲,進而對存儲的對應該算法的數據結構使用相應算法進行計算。
第四步:算法自動調整
所有方法和算法根據配置進行存儲,預先根據配置和性能來評估出最佳配置組合,重新增加或者修改配置。
也就是說,對算法進行性能評估後,識別最快速的算法,將影響此算法的信息保存,以便進行計算時調用;
保存內容包括:數據結構編號(即狀態數據類型)、數據總量範圍、執行條件。
例如:
數據結構編號:「S1」轉轍機電流曲線數據結構
數據總量範圍:(864w)
執行條件:(設備類型=0x03,設備編號=001)。
本實施例的方法,通過獲取數據量及數據結構,進而選擇最優性能值的算法,採用選擇的算法獲取分析結果,能夠提升系統處理事件的效率,減少人工等待分析時間,進一步地,優化執行速度,在相同數據量情況下,減少事件和空間複雜度,進而能夠處理更大量的數據,使得系統性能達到最佳狀態,系統以更加穩定的狀態高速運行。
另外,本發明實施例還提供一種基於大數據分析的性能自動調優裝置,如圖4所示,本實施例的性能自動調優裝置包括:接收單元41、數據篩選單元42、性能值確定單元43、選取單元44、分析處理單元45;
其中,接收單元41用於接收用戶輸入的設備類型、狀態數據類型、包括分析方式和設備標識的執行條件;
數據篩選單元42用於根據所述設備類型、狀態數據類型、執行條件,從數據中心篩選出預設時間段內待分析的數據量;
性能值確定單元43用於根據數據量、狀態數據類型、執行條件,確定算法動態庫中每一算法的性能值;
選取單元44用於選取最高性能值對應的算法;
分析處理單元45用於採用選取的算法依據執行條件對待分析的數據量進行分析,獲取分析結果。
可選地,圖4所示的裝置還包括圖中未示出的算法動態庫建立單元46,該算法動態庫建立單元46用於建立算法動態庫;
所述算法動態庫包括至少一個算法;
或者,所述算法動態庫包括至少一個算法及該算法對應的影響該算法性能值的各項的權重係數。
當然,在實際應用中,上述的圖4所示的裝置還包括圖中未示出的存儲單元,該存儲單元用於存儲前述的配置組合,即所述數據結構類型、數據量信息、最高性能值對應的算法組成的配置組合。
本實施例的裝置可執行前述任意方法實施例的內容,詳見上述記載,該處不再詳述。
本實施例的裝置,位於維護系統中且連接維護系統的數據中心,使用本實施例的裝置能夠提升維護系統處理事件的效率,減少人工等待分析時間,進一步地,優化執行速度,在相同數據量情況下,減少事件和空間複雜度,進而能夠處理更大量的數據,使得系統性能達到最佳狀態,系統以更加穩定的狀態高速運行。
本領域的技術人員能夠理解,儘管在此所述的一些實施例包括其它實施例中所包括的某些特徵而不是其它特徵,但是不同實施例的特徵的組合意味著處於本發明的範圍之內並且形成不同的實施例。
本領域技術人員可以理解,實施例中的各步驟可以以硬體實現,或者以在一個或者多個處理器上運行的軟體模塊實現,或者以它們的組合實現。本領域的技術人員應當理解,可以在實踐中使用微處理器或者數位訊號處理器(DSP)來實現根據本發明實施例的一些或者全部部件的一些或者全部功能。本發明還可以實現為用於執行這裡所描述的方法的一部分或者全部的設備或者裝置程序(例如,電腦程式和電腦程式產品)。
雖然結合附圖描述了本發明的實施方式,但是本領域技術人員可以在不脫離本發明的精神和範圍的情況下做出各種修改和變型,這樣的修改和變型均落入由所附權利要求所限定的範圍之內。