一種人臉自發表情的識別方法及系統與流程
2023-10-06 14:52:19 4
本發明涉及表情識別領域,具體的涉及一種人臉自發表情的識別方法及系統。
背景技術:
人臉表情識別(facialexpressionrecognition)是人工智慧領域近年來一個備受關注的研究方向,它是指利用計算機視覺技術對人臉表情信息進行特徵提取和表情分類。在人臉表情識別的研究領域中,主要分為兩個大類:「人為表情識別」和「自發表情識別」。人為表情(poseexpression)指的是在搜集表情數據集時,在實驗室等特定場景中要求人做出的標準的誇張的表情,而非自發的表情;自發表情(spontaneousexpression)指的是自然表現的、無偽裝的表情,它是人們日常生活中自然產生的、複雜多變的表情。目前,國內外對於人臉表情識別的研究大都集中於人為表情識別,並取得了較好的研究成果,而自發表情識別仍處於起步階段。
為了克服自然環境下的自發表情識別中的多噪聲幹擾問題,近年來,一些研究者亦做了一些工作,利用高性能的機器學習算法,如深度學習、決策森林、svm等,來提高自發表情的識別效果。隨機森林(randomforests)有快速高效的決策能力和數據處理能力,易於實現,且具有一定的抗噪能力,可以對全局的人臉特徵進行識別,但是對悲傷和厭惡等區分度不高的表情具有一定的局限性。svm多依賴於精確的局部特徵訓練,對遮擋等噪聲魯棒性不高。深度學習的準確率高,自動學習特徵能力強,但是由於多層網絡學習和反饋,計算時間長,多依賴於高性能計算機系統和大量的訓練集。然而自然環境中,一方面多噪聲使人臉的局部精確特徵難以提取,另一方面現有的自發表情數據集樣本數量較少,單個分類器都有各自的不足之處。
技術實現要素:
本發明所要解決的技術問題是提供一種人臉自發表情的識別方法及系統,可以解決自發表情中的自動特徵提取和多噪聲幹擾等問題,快速精準的識別各類自發表情。
本發明解決上述技術問題的技術方案如下:一種人臉自發表情的識別方法,包括以下步驟,
s1,提取圖像中人臉的顯著優化深度卷積特徵;
s2,估計圖像中的頭部姿態,建立與頭部姿態相關的表情先驗條件概率模型;
s3,在表情先驗條件概率模型確定的頭部姿態的先驗條件下,基於已訓練的條件深度網絡增強決策森林對顯著優化深度卷積特徵進行學習和分類,預測圖像中人臉的自發表情的類型。
本發明的有益效果是:在本發明一種人臉自發表情的識別方法中,首先,為了消除自然環境中人臉遮擋和光照等噪聲影響,提高自發表情特徵的區分力,在圖像人臉中提取顯著優化深度特徵;其次,頭部姿態運動是自發表情特有的特徵,為了消除頭部姿態運動的影響,估計圖像中的頭部姿態建立與頭部姿態相關的表情先驗條件概率模型;最後,基於條件深度網絡增強決策森林分類自發表情;本發明的方法可以解決自發表情中的自動特徵提取和多噪聲幹擾等問題,快速精準的識別各類自發表情。
在上述技術方案的基礎上,本發明還可以做如下改進。
進一步,s1具體為,
s11,從圖像中獲取人臉區域;
s12,在所述人臉區域中隨機稠密抽取多個人臉子區域;
s13,提取每一個人臉子區域中的顯著優化深度卷積特徵。
採用上述進一步方案的有益效果是:本發明中顯著優化深度卷積特徵提取的步驟簡單。
進一步,在s11採用基於haar特徵的層級式adaboost算法從圖像中提取人臉區域。
採用上述進一步方案的有益效果是:採用基於haar特徵的層級式adaboost算法從圖像中提取人臉區域,可以提高提取精度。
進一步,s13具體為,
s131,通過gbvs算法在每一個人臉子區域中提取視覺顯著區域,並利用relu激活函數對視覺顯著區域進行優化;
s132,通過深度卷積網絡cnn模型對優化後的視覺顯著區域進行顯著優化深度卷積特徵提取。
採用上述進一步方案的有益效果是:深度卷積網絡cnn模型具體為卷積神經網絡vgg-face的框架,vgg-face是基於百萬張人臉圖片訓練的深度卷積網絡cnn網絡模型;通過已有的卷積神經網絡vgg-face的框架,遷移學習魯棒的顯著優化深度特徵表達,通過遷移學習模型,基於vgg-face已有的cnn網絡參數,可以通過少量表情數據集微調網絡參數提取顯著優化深度特徵。
進一步,在s131中,利用relu激活函數對視覺顯著區域進行優化的模型為,
p=relu(x-mean)
其中,p為優化後的視覺顯著區域,x為優化前的視覺顯著區域,mean為優化前的視覺顯著區域的灰度均值,relu為激活函數,且
進一步,在s132中,顯著優化深度卷積特徵的表達式為,
其中,i,j定義為視覺顯著區域的位置,tanh是hyperbolictangent函數,b是視覺顯著區域的矩陣的偏置,為視覺顯著區域通過第l層卷積層的輸出描述符,且
其中,wi,j,k為視覺顯著區域在第l層的權值,dl為第l層卷積層的卷積核長度,s定義為第l-1卷積層的特徵圖的數量。
進一步,s2具體為,在不同的頭部姿態條件下,構造多個先驗的條件深度網絡增強決策森林,並將不同的頭部姿態與多個先驗的條件深度網絡增強決策森林之間建立映射關係形成表情先驗條件概率模型。
採用上述進一步方案的有益效果是:表情先驗條件概率模型是將頭部姿態與條件深度網絡增強決策森林之間建立聯繫,可以校正頭部姿態運動對表情分類的影響。
進一步,所述表情先驗條件概率模型具體為,
p(y|f)=∫p(y|θ)p(θ|f)dθ
其中,θ為頭部姿態,y為自發表情的類別,f為顯著優化深度卷積特徵。
進一步,s3具體為,
s31,在表情先驗條件概率模型確定的頭部姿態的先驗條件概率下,利用已訓練的對應的條件深度網絡增強決策森林對顯著優化深度卷積特徵進行學習條件深度特徵表達,並對表達後的學習條件深度特徵進行強化;
s32,通過節點學習選擇強化後的學習條件深度特徵,建立條件深度網絡增強決策森林的分裂節點;
s33,通過條件深度網絡增強決策森林的分裂節點學習和權重投票決策,確定自發表情的類型。
採用上述進一步方案的有益效果是:條件深度網絡增強決策森林在有限的數據集上達到大數據集的訓練效果,可以快速精確的實現自發表情識別。
基於上述一種人臉自發表情的識別方法,本發明還提供一種人臉自發表情的識別系統。
一種人臉自發表情的識別系統,包括顯著優化深度卷積特徵提取模塊、表情先驗條件概率模型生成模塊和條件深度網絡增強決策森林預測模塊,
顯著優化深度卷積特徵提取模塊,其用於提取圖像中人臉的顯著優化深度卷積特徵;
表情先驗條件概率模型生成模塊,其用於估計圖像中的頭部姿態,建立與頭部姿態相關的表情先驗條件概率模型;
條件深度網絡增強決策森林預測模塊,其用於在確定的頭部姿態的先驗條件下,基於已訓練的條件深度網絡增強決策森林對顯著優化深度卷積特徵進行學習和分類,預測圖像中人臉的自發表情的類型。
本發明的有益效果是:在本發明一種人臉自發表情的識別系統中,首先,為了消除自然環境中人臉遮擋和光照等噪聲影響,提高自發表情特徵的區分力,通過顯著優化深度卷積特徵提取模塊在圖像人臉中提取顯著優化深度特徵;其次,頭部姿態運動是自發表情特有的特徵,為了消除頭部姿態運動的影響,通過表情先驗條件概率模型生成模塊估計圖像中的頭部姿態,建立與頭部姿態相關的表情先驗條件概率模型;最後,基於條件深度網絡增強決策森林訓練模塊分類自發表情;本發明的系統可以解決自發表情中的自動特徵提取和多噪聲幹擾等問題,快速精準的識別各類自發表情。
附圖說明
圖1為本發明一種人臉自發表情的識別方法的流程圖;
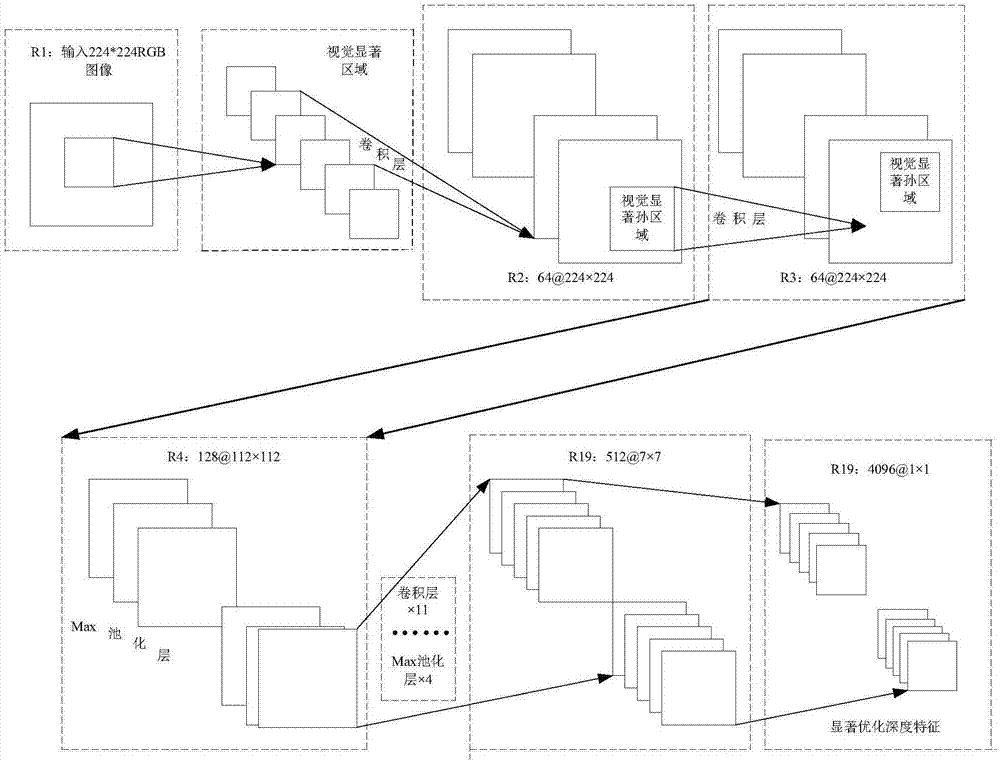
圖2為本發明一種人臉自發表情的識別方法中深度卷積網絡cnn模型;
圖3為本發明一種人臉自發表情的識別方法中與頭部姿態相關的表情先驗條件概率模型;
圖4為本發明一種人臉自發表情的識別方法中條件深度網絡增強決策森林的算法結構示意圖;
圖5為本發明一種人臉自發表情的識別系統的結構框圖。
具體實施方式
以下結合附圖對本發明的原理和特徵進行描述,所舉實例只用於解釋本發明,並非用於限定本發明的範圍。
如圖1所示,一種人臉自發表情的識別方法,包括以下步驟,
s1,提取圖像中人臉的顯著優化深度卷積特徵;
s2,估計圖像中的頭部姿態,建立與頭部姿態相關的表情先驗條件概率模型;
s3,在表情先驗條件概率模型確定的頭部姿態的先驗條件下,基於條件深度網絡增強決策森林對顯著優化深度卷積特徵進行學習和分類,預測圖像中人臉的自發表情的類型。
以下為本具體實施例中對s1、s2和s3進行進一步的解釋說明:
s1具體包括s11-s13,
s11,從圖像中獲取人臉區域;其中採用基於haar特徵的層級式adaboost算法從圖像中提取人臉區域。
s12,在所述人臉區域中隨機稠密抽取多個人臉子區域;本具體實施例在人臉區域通過隨機稠密抽取200個的人臉子區域。
s13,提取每一個人臉子區域中的顯著優化深度卷積特徵;
其中s13中提取每一個人臉子區域中的顯著優化深度卷積特徵,如圖2所示,提取的原理為,通過已有的卷積神經網絡vgg-face的框架,遷移學習魯棒的顯著優化深度特徵表達。vgg-face是基於百萬張人臉圖片訓練的深度卷積網絡cnn模型,包含13個卷積層,5個池化層,3個全連接層,共計21層;本發明通過遷移學習模型,基於vgg-face已有的cnn網絡參數,通過少量表情數據集微調網絡參數,在第一層全連接層後提取顯著優化深度特徵;具體實現如下s31-s32:
s131,通過gbvs算法在每一個人臉子區域中提取視覺顯著區域(視覺顯著區域是指人臉子區域中具有強區分力和抗噪聲能力的區域),並利用relu激活函數對視覺顯著區域進行優化;其中,視覺顯著性區域是指人臉子區域中具有強區分力和抗噪聲能力的區域。
利用relu激活函數對視覺顯著區域進行優化的模型為,
p=relu(x-mean)
其中,p為優化後的視覺顯著區域,x為優化前的視覺顯著區域,mean為優化前的視覺顯著區域的灰度均值,relu為激活函數,且
s132,通過深度卷積網絡cnn模型對優化後的視覺顯著區域進行顯著優化深度卷積特徵提取;參考facevgg-16網絡模型,包括5個卷積層和池化層,3個全連接層,一個softmax分類層,通過實驗證明,本發明選擇第一層全連接層(fc6)作為特徵提取層,可以獲得最佳的分類結果,fc6的特徵維度為4096;顯著優化深度卷積特徵的表達式為(其具體為基於遷移性學習的顯著優化深度卷積特徵表達式),
其中,i,j定義為視覺顯著區域的位置,tanh是hyperbolictangent函數(雙曲正切函數),b是視覺顯著區域的矩陣的偏置,為視覺顯著區域通過第l層卷積層的輸出描述符,且
其中,wi,j,k為視覺顯著區域在第l層的權值,dl為第l層卷積層的卷積核長度,s定義為第l-1卷積層的特徵圖的數量。
s2具體為:在不同的頭部姿態條件下,構造多個先驗的條件深度網絡增強決策森林,並將不同的頭部姿態與多個先驗的條件深度網絡增強決策森林之間建立映射關係形成表情先驗條件概率模型。
具體的如圖3所示,在不同的頭部姿態條件下,構造多個條件深度網絡增強決策森林,當視覺顯著區域塊樣本p={fi,j}進行分類測試時(fi,j是顯著優化深度卷積特徵),根據頭部姿態估計先驗條件概率選擇相應的條件深度網絡增強決策森林識別表情。
所述表情先驗條件概率模型(也可以稱為基於頭部姿態先驗條件概率的表情分類模型)具體為,
p(y|f)=∫p(y|θ)p(θ|f)dθ
其中,θ為頭部姿態,y為自發表情的類型,f為顯著優化深度卷積特徵。
為了獲得p(y|θ),訓練集可分為不同的子集,θ的參數空間可離散化為不相交的子集ω,公式p(y|f)=∫p(y|θ)p(θ|f)dθ可轉化為:
p(y|f)=∑i(p(y|ωi)∫p(θ|f)dθ)
其中:p(θ|f)由條件深度網絡增強決策森林多分類方法獲得,條件概率p(y|ωi)可通過基於不相交的子集ωi訓練獲得。
s3具體為:s31,在表情先驗條件概率模型確定的頭部姿態的先驗條件概率下,利用已訓練的對應的條件深度網絡增強決策森林對顯著優化深度卷積特徵進
學習條件深度特徵表達具體為dn(pn,y|ωi)=σ(fn(pn,y|ωi)),其中,y是自發表情類別,σ是sigmoid函數,ωi為頭部姿態先驗條件概率;
條件深度網絡增強決策森林的訓練方法為:在ck+自發表情數據集、lfw人臉數據集和bu-3dfe多姿態自發表情數據集上進行。將三個數據集按頭部姿態的水平旋轉角度分為離散的7個表情訓練子集,在不同的子集中基於顯著優化深度卷積特徵訓練表情分類器,得到條件深度網絡增強決策森林。在本發明中,數據集是提前分為訓練集和測試集的,本發明採用8-交叉驗證的方法進行測試,80%的數據用以訓練,20%的數據用以測試。
s32,通過節點學習選擇強化後的學習條件深度特徵,建立條件深度網絡增強決策森林的分裂節點;其中,節點學習具體為增強節點學習函數,分裂節點包括左子節點和右子節點;另外,當樹的深度達到最大或者迭代收斂後,生成決策森林的葉子節點,反之重複執行s32直至深度達到最大或者迭代收斂。
s33,通過條件深度網絡增強決策森林的分裂節點學習和權重投票決策,確定自發表情的類型;具體的為,從訓練的條件深度網絡增強決策森林的根節點開始學習至葉子節點,採用權重稀疏投票算法對葉子節點上有效的人臉顯著子區域塊的表情概率進行投票,獲得表情類別的概率p(y|ωi)。
下面分層介紹s31-s33,s3採用的主要算法結構如下圖4所示:
條件cnn層:在已估計的不同頭部姿態下,對顯著優化深度卷積特徵進行學習條件特徵表達{pn=(fi,j,θi),y}({pn=(fi,j,θi),y}為一個特徵集合)。其中fi,j是顯著優化深度卷積特徵,θi為已估計的頭部姿態,y是自發表情類別。
增強聯合層:基於深度卷積網絡cnn模型中全聯接層的聯接函數,提出一個聯合強化函數fn,用以強化視覺顯著區域的學習條件特徵表達pn,用強化後的學習特徵表達作為條件深度網絡增強決策森林的節點特徵選擇dn,
dn(pn,y|ωi)=σ(fn(pn,y|ωi))
其中,y是自發表情類別,σ是sigmoid函數,ωi為頭部姿態條件下的表情子森林。
節點學習層:條件深度網絡增強決策森林的節點數量即為增強聯合層的輸出數量。採用信息增益(ig)最大作為節點學習的度量函數,當ig達到最大時則學習完成,生成節點;當樹的深度達到最大或者迭代收斂後,生成子節點,否則繼續迭代節點學習;其中,l、r分別為節點特徵分裂後的左子節點和右子節點,
決策投票層:採用權重稀疏投票算法對子節點πl上有效的人臉顯著子區域塊的表情概率進行投票,獲得表情類別的概率p(y|ωi),其中at為森林ωi中的樹,ca為樹的權值,k為樹的棵樹。
本發明在ck+自發表情數據集、lfw人臉數據集和bu-3dfe多姿態自發表情數據集上進行了訓練和預測。ck+是應用最廣的人臉表情數據集,它採集了128人的6種表情序列表情,每個表情包括593張圖片。為了增強數據的多樣性,本發明對ck+數據集進行人為的遮擋、加高斯和椒鹽噪聲處理。lfw是公共的自然環境下的人臉數據集,它包括了5749人的不同表情、姿態、環境、光照等因素,為了進行訓練和預測,本發明對該資料庫進行6類表情的標註。bu-3dfe是一個公共的多姿態自發表情數據集,該數據集採集了100個人的不同表情和姿態的2d和3d圖像,包含不同的年齡,性別等。本發明採用8-交叉驗證的方法進行測試,80%的數據用以訓練,20%的數據用以預測。本發明在三個數據集上的平均識別率分別為99.6%,86.8%和95.1%。可見,本發明提出的條件深度網絡增強決策森林,可以在有限的數據集上,達到大數據集的訓練效果,具有強的抗噪性和區分力。
基於上述一種人臉自發表情的識別方法,本發明還提供一種人臉自發表情的識別系統。
如圖5所示,一種人臉自發表情的識別系統,包括顯著優化深度卷積特徵提取模塊、表情先驗條件概率模型生成模塊和條件深度網絡增強決策森林預測模塊,
顯著優化深度卷積特徵提取模塊,其用於提取圖像中人臉的顯著優化深度卷積特徵;
表情先驗條件概率模型生成模塊,其用於估計圖像中的頭部姿態,建立與頭部姿態相關的表情先驗條件概率模型;
條件深度網絡增強決策森林預測模塊,其用於在表情先驗條件概率模型確定的頭部姿態的先驗條件下,基於已訓練的條件深度網絡增強決策森林對顯著優化深度卷積特徵進行學習和分類,預測圖像中人臉的自發表情的類型。
在本發明一種人臉自發表情的識別系統中,首先,為了消除自然環境中人臉遮擋和光照等噪聲影響,提高自發表情特徵的區分力,通過顯著優化深度卷積特徵提取模塊在圖像人臉中提取顯著優化深度特徵;其次,頭部姿態運動是自發表情特有的特徵,為了消除頭部姿態運動的影響,通過表情先驗條件概率模型生成模塊估計圖像中的頭部姿態,建立與頭部姿態相關的表情先驗條件概率模型;最後,基於條件深度網絡增強決策森林訓練模塊分類自發表情;本發明的系統可以解決自發表情中的自動特徵提取和多噪聲幹擾等問題,快速精準的識別各類自發表情。
以上所述僅為本發明的較佳實施例,並不用以限制本發明,凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護範圍之內。