用於人工神經網絡中比特深度減少的方法和系統與流程
2023-10-19 15:34:07 2
本申請要求2016年3月16日提交的,名稱為「通過使用硬體成本懲罰深度學習神經網絡優化」的美國臨時專利申請62/309,239的優先權,通過引用將其併入本申請。
技術領域
本發明涉及神經網絡,特別涉及權重大小的優化。
背景技術:
對於使用傳統電腦程式難以處理的大量複雜數據,人工神經網絡特別有用。不是使用指令編程,而是將訓練數據輸入到神經網絡,並與預期輸出進行比較,然後在神經網絡內進行調整,再次處理訓練數據,和輸出比較,再進一步調整神經網絡。在多次這樣的訓練周期之後,神經網絡被改變成可以有效地處理類似訓練數據和預期輸出的數據。神經網絡是機器學習的一個例子,因為神經網絡學習如何生成訓練數據的預期輸出。然後可以將類似訓練數據的實際數據輸入到神經網絡,以處理實時數據。
圖1顯示一個現有技術的神經網絡。輸入節點102、104、106、108接收輸入數據I1、I2、I3、...I4,而輸出節點103、105、107、109輸出神經網絡運算的結果:輸出數據O1、O2、O3、...O4。在這個神經網絡中有三層運算。節點110、112、114、116、118中的每一個節點都從一個或多個輸入節點102、104、106、108中獲取輸入,執行一些運算,諸如加、減、乘或更複雜運算,然後發送和輸出到第二層的節點。第二層節點120、122、124、126、128、129也接收多個輸入,合併這些輸入以產生一個輸出,並將輸出發送到第三層節點132、134、136、138、139,類似地合併輸入並產生輸出。
每層的輸入通常會被加權,因此在每個節點處生成加權總和(或其他加權運算結果)。這些權重可以表示為W31、W32、W32、W33、...W41等,在訓練期間權重值可以調整。通過不斷地試錯或其他訓練程序,最終可以將較高的權重分配給產生預期輸出的路徑,而將較小權重分配給不產生預期輸出的路徑。機器將學習哪些路徑會生成預期輸出,並為這些路徑上的輸入分配高權重。
這些權重可以存儲在權重存儲器100中。由於許多神經網絡都具有多個節點,所以在權重存儲器100中存儲有多個權重。每個權重需要多個二進位比特來表示該權重的可能值的範圍。權重通常需要8到16比特。權重存儲器100的大小通常與神經網絡的總體大小和複雜性成比例。
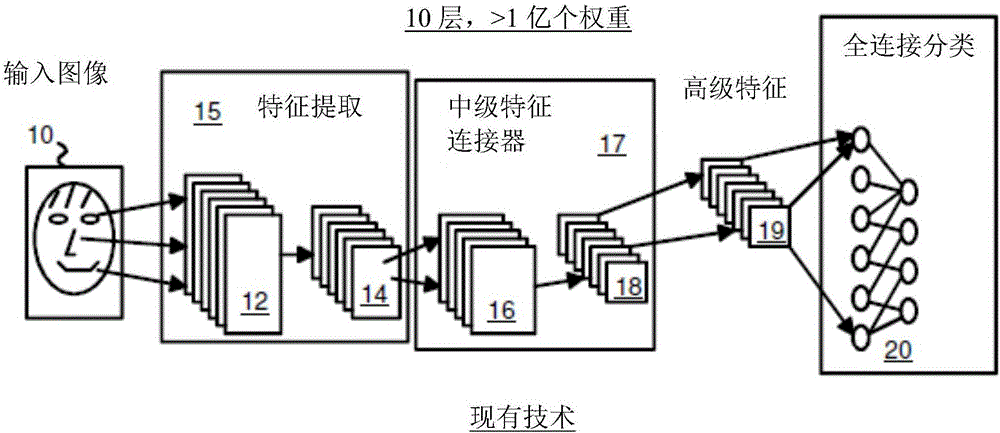
深度神經網絡具有多層節點,常用於諸如對象分類、語音識別、情感分析、圖像識別、面部檢測和其他圖形處理的應用。圖2顯示用於面部識別的神經網絡。圖像輸入10可以從一個較大的圖像中提取,例如通過軟體分離出人臉。特徵提取器15執行低級特徵提取、池化(pooling)和下採樣。例如,可以識別並提取諸如眼睛和嘴巴的面部特徵作為提取的特徵12。對這些提取的特徵12進行合成和下採樣以生成輸出14。
中級特徵連接器17檢查下採樣的提取特徵,生成連接16和中級特徵18,然後可以使用中級特徵18來生成高級特徵19。分類器20對特徵進行分類和完全連接,使得可以輸出面部特徵。
這樣的面部檢測可以通過使用有多個節點的10層神經網絡來實現。該神經網絡會使用超過1億個權重。
圖3顯示一個實施圖像識別處理器的神經網絡。輸入圖像10可能包含多個特徵,諸如幾個人、背景和前景對象、以及幾個幀。神經網絡的各層執行64-比特卷積22、256-比特卷積26、和512-比特卷積28。最大響應節點是由最大池化層(maxpooling layers)24產生,而最終softmax層30執行歸一化指數函數以限制輸出範圍。全連接FC層32通過允許每個節點查看前一層的所有輸入來執行高層次推理。
這種圖像處理可能需要16個隱藏層的神經網絡,有超過2億個權重。因此,權重存儲器100(圖1)所需的尺寸相當大。
現有的深度神經網絡可能有非常高的計算複雜度以提高神經網絡的精度。這些龐大的計算複雜性和成本通常是通過使用工業規模的計算集群和若干高性能圖形處理單元(GPU)來解決。然而,這類計算集群和GPU的功耗相當高。
傳統上神經網絡都是使用大規模計算,如大型機和計算機集群。在用戶終端設備(如智慧型電話)上拍攝的圖像可以發送到遠程大型機或計算集群,以被神經網絡進行處理。然後,結果被發送回智慧型手機。
然而,如果在用戶終端設備本身(如智慧型電話、相機、可穿戴設備和機器人設備)上就有這種神經網絡,那將是非常有用的。這些用戶終端設備通常需要實時響應、低延遲、有存儲器和功耗限制。
一種解決方案是添加專用硬體到用戶終端設備。可以向用戶終端設備添加一種包括神經網絡的專用集成電路(ASIC)。ASIC比GPU有更低的功耗,因為ASIC的神經網絡可以是專用於用戶終端設備執行的任務或操作,而GPU則是通用的。
一個專用神經網絡的門數、晶片面積、功耗和成本與權重的數量和大小或權重存儲器100的尺寸大致成比例。發明人希望降低權重存儲器100的尺寸,從而減少專用神經網絡的門數、晶片面積、功耗和成本。可以減小每個權重的大小或比特深度,但也將降低神經網絡的精度。
期望有一種減少尺寸和成本的神經網絡。期望通過選擇性地減小權重的大小或比特深度來減小神經網絡的尺寸和成本。期望減小權重的比特深度的方式不會在計算其輸出時顯著降低神經網絡的精度。期望在減小一些權重的比特深度的同時對精度的影響最小。
附圖說明
圖1是一個現有技術的神經網絡。
圖2是一個用於面部識別的神經網絡。
圖3是一個實施圖像識別處理器的神經網絡。
圖4是一個神經網絡優化器。
圖5是量化比特深度權重成本的曲線圖。
圖6A-B顯示了在訓練期間使用量化權重成本曲線進行選擇用於減少的權重。
圖7A-C顯示使用比特深度優化引擎的權重值的分布。
圖8是一個比特深度優化引擎的詳細框圖。
圖9顯示使用比特深度優化引擎來減少權重硬體成本的曲線圖。
圖10顯示具有權重比特深度優化的神經網絡的集成電路的設計和製造過程。
具體實施方式
本發明涉及神經網絡的改進。呈現以下描述以使本領域普通技術人員能夠製造和使用如在特定應用及其要求的上下文中提供的本發明。對優選實施例的各種修改對於本領域技術人員是顯而易見的,並且本文定義的一般原理可以應用於其他實施例。因此,本發明並不限於所顯示和描述的特定實施例,而是要求符合與本文披露的原理和新穎特徵一致的最寬範圍。
發明人已經發現,可以通過減少神經網絡中的權重大小或比特深度,來降低神經網絡的複雜性、成本和大小,同時仍然保持優化精度。具體來說,在優化期間添加比特深度複雜性懲罰,可以使神經網絡朝向較小權重存儲器。在優化迭代期間使用數字梯度的權重大小。發明人通過訓練過程減少神經網絡中權重所需的比特數,然後可以將其部署在諸如ASIC的專用硬體中。較小的優化神經網絡會減少ASIC的成本和尺寸。
圖4顯示了一種神經網絡優化器。神經網絡36可以是由設計工程師為一個特定應用而設計的一個神經網絡,或者是為特定應用而調整的一個通用神經網絡。例如,可以針對一個特定應用,來調整神經網絡中的中間層或隱藏層的數目,可以針對某些應用或要解決的問題來調整在節點中執行的運算類型和節點之間的連接性。例如,對於圖2的面部識別應用,通用神經網絡可以被擴展到10層,或對圖3的圖像處理應用,擴展到16層。
神經網絡36中使用的權重可以有初始值,如0到16K-1,其可以由一個14比特的權重表示。當執行訓練程序46時,訓練數據34被輸入到神經網絡36,允許評估神經網絡36的輸出。一種評估輸出質量的方法是計算成本。精度成本生成器42生成精度成本,該精度成本是當前周期的輸出與預期結果有多接近的一個測量。可以通過對單個輸出與該輸出的期望值的差求平方,並對所有輸出的這些平方求平均或求和,產生一個均方誤差(MSE)。
另一成本是神經網絡36的硬體成本。通常,可以通過增加神經網絡36中可用的硬體量來提高精度,因此在硬體成本和精度成本之間存在一個權衡。由硬體複雜度成本生成器44計算的典型的硬體成本因素包括一個在調整權重範圍時防止過度擬合的權重衰減函數,以及一個用於改善結構和規則性的稀疏函數。
硬體複雜度成本生成器44還包括一個新的成本組件,其檢查表示一個權重所需的二進位比特數。傳統的成本方法將權重作為一個連續統(continuum)。但是,硬體複雜度成本生成器44將權重成本量化。根據表示權重所需的二進位比特數而不是根據權重數值來計算權重成本。
來自精度成本生成器42的精度成本和來自硬體複雜度成本生成器44的硬體成本都用於調整權重,供訓練程序46的下一訓練周期使用。更新的權重被應用於神經網絡36,訓練數據34被再次輸入到神經網絡36,神經網絡36產生一組新的結果,該組新的結果由精度成本生成器42和硬體複雜度成本生成器44產生其成本。進行多個周期的調整權重和重新計算成本,直到達到一個期望的終點。然後,比特深度優化引擎48輸出具有最終權重的神經網絡36作為低比特深度神經網絡40。
舉個例子,神經網絡36中每個權重的平均比特數是14比特。比特深度優化引擎48將該平均比特深度減小到低比特深度神經網絡40中的10比特,即減少了4個二進位比特。這對於權重存儲器100(圖1)中關於權重的存儲要求就減少了28%。
圖5是量化比特深度權重成本的曲線圖。顯示了單個權重的成本。如之前的圖2-3所示,神經網絡可以有超過1億個權重。
傳統權重成本曲線142隨著權重值增加而有穩定增加的成本。量化權重成本曲線140有步階。這些步階出現在每次增加表示權重值所需的二進位比特數時。
例如,一個權重可以有一個值36。該值需要6個二進位比特。如果權重值降低到34,傳統權重成本降低,但是它仍然需要6個二進位比特,因此量化權重成本並不發生變化。
但是,當權重從36變化到31時,所需的二進位比特數從6減少到5,因為5個二進位比特可以覆蓋從0到31的值。雖然傳統權重成本曲線142所示的傳統權重減小了一個很少的量,但量化權重成本曲線140所示的量化權重成本減小了一個很大的量,因為其下降了一個步階。
量化權重成本曲線140中的步階出現在二進位比特數發生變化的地方。這些步階出現在2的冪次方處,例如在16、32、64、128、256、512、1024、2048、4096、8192、...65536…等的權重值處。一個權重值1024(11比特)減少1到1023(10比特)時,其成本顯著減少,但是減少權重值1023直到達到511,其量化權重成本都沒有任何變化,因為從1023到512的值都需要10個二進位比特。
圖6A-B顯示了在訓練期間使用量化權重成本曲線進行選擇用於減少的權重。在圖6A,為了清晰,將圖5中部分量化權重成本曲線140和傳統權重成本曲線142放大並分開。在量化權重成本曲線140上顯示了從11比特到12比特的步階,以及從11比特到12比特的另一步階。
顯示了四個單獨的權重θ5、θ6、θ7、和θ8。在傳統權重成本曲線142上,所有四個權重都有大致相同的斜率SL或梯度,因此在訓練期間使用傳統成本優化來減小其權重值時,所有這些權重都是等同的候選者。
在量化權重成本曲線140中,權重θ5和θ7遠離任何步階。權重值θ5和θ7附近的斜率是接近零的值,因為量化權重成本曲線140在步階之間是平坦的。因此,當選擇減小權重θ5和θ7時,成本減少很小或沒有減少。
然而,在量化權重成本曲線140中,權重θ6接近從11到12比特的那個步階。對該步階之前和之後的兩個點,量化權重成本曲線140的斜率很大。
當用於計算斜率的範圍包括步階之前一個點和之後一個點時,可以計算出一個大斜率或梯度。
在訓練優化期間,可以使用成本梯度來選擇哪些權重是減少成本的最佳選擇。選擇具有大梯度的權重優於選擇具有小梯度的權重,因為可以大幅降低硬體成本,而同時可能會小幅降低精度。
類似地,在量化權重成本曲線140中,權重θ8靠近從12到13比特的步階。權重θ8具有一個大斜率SL>>0。由於權重θ6和θ8都接近步階,具有大梯度,所以和具有零斜率的權重θ5和θ7相比,比特深度優化引擎48會優先選擇權重θ6和θ8。比特深度優化引擎48將稍微減小權重θ6和θ8的值,使得它們在圖6A向左偏移,出現在量化權重成本曲線140的所述步階之前。存儲這些權重所需的比特數已經被各自減少1比特。權重θ5和θ7保持不變,因此不會降低其精度。
圖6B顯示成本梯度的尖峰發生在當二進位比特的數量變化時的步階上。對於長範圍的步階之間的權重值,梯度曲線144是平坦的。梯度曲線144中的尖峰恰好出現在量化權重成本曲線140中的每個步階的右側處。該尖峰顯示當二進位比特的數量下降時,量化權重成本曲線140的斜率或梯度會急劇變化。
硬體複雜度成本生成器44可以為每個權重產生量化權重成本曲線140的梯度,比特深度優化引擎48可以在訓練優化期間搜索具有大成本梯度的權重,並選擇這些權重用於減小成本。經過多個周期的選擇,權重被減少並與精度權衡,直到獲得一個最優權重值用於低比特深度神經網絡40。
本發明人認識到,有許多權重值具有相同的硬體成本,因為它們需要相同數量的二進位比特。硬體複雜度成本生成器44(圖4)負責權重的比特深度成本。在訓練期間,選擇哪個權重去減小成本變成了優先選擇量化權重成本曲線140中剛好在下降(步階)之前的權重。和量化權重成本曲線140中那些遠離下一個步階的權重(大變化)相比,這些權重的較小變化可以有較大的硬體成本減少。
圖7A-C顯示使用比特深度優化引擎的權重值分布。在圖7A,顯示了量化權重成本曲線140。在二進位比特數增加時的步階上,硬體成本大幅跳躍。比特深度優化引擎48選擇量化權重成本曲線140中權重值剛好在步階之前(在右側)的權重,並略微減少這些值。如果由於權重是關鍵值,引起精度大幅降低,那麼該變化就可以在下一個訓練周期中被撤消,但通常和總體上,權重值略微減小,比特深度和存儲要求會大幅降低。
在圖7B,比特深度優化引擎48已經優先選擇了量化權重成本曲線140中靠近步階的權重,而且這些權重已經被減小。權重值的分布顯示在量化權重成本曲線140中尖峰都剛好在步階之後(左側)。選擇步階右側的權重並減小,以將它們放在該步階左側。因此,在步階之後比在步階之前有更多的權重,如圖7B所示。圖7C顯示了現有技術的權重分布。使用傳統權重成本曲線142,不考慮步階,因此在量化權重成本曲線140的步階之前和之後,權重分布是相對恆定的。
比特深度優化引擎48已經改變了低比特深度神經網絡40中數百萬個權重的分布。權重傾向於具有剛好在步階以下的二進位比特值。有較少權重值剛好在步階之前,因為這些是訓練和優化期間用於減少成本的候選值,大多數已經被偏移到步階之後了。
圖8是比特深度優化引擎的較詳細框圖。神經網絡36的權重是由權重初始化器58進行初始化,這些初始權重被輸入到神經網絡輸出生成器54,利用這些初始權重,神經網絡輸出生成器54使用由神經網絡36設定的節點和運算網絡,對訓練數據34進行運算以產生神經網絡36的結果或輸出。將這些結果與訓練數據34的預期輸出進行比較,以產生每個權重的誤差項或精度成本。在隨後的周期裡,更新的權重72被應用於神經網絡輸出生成器54。
根據當前權重,即初始權重或更新的權重72,硬體複雜度成本生成器52產生神經網絡36的硬體成本。總體硬體成本可以被近似為與權重存儲器100的成本成比例,其可以近似為神經網絡36中所有權重所需的總比特數。
正演計算50還包括正則化(regularization)生成器56,其產生其它硬體成本,如神經網絡36的稀疏性或規律性。正演計算50使用更新的權重72的當前值,產生神經網絡36的硬體和精度成本。
反演計算60從正演計算50接收成本,並產生梯度。梯度可以用於選擇哪些權重需要調整,如圖6A-B所示。由神經網絡輸出發生器54產生的每個權重的精度成本或誤差被輸入到誤差梯度生成器64,誤差梯度生成器64產生每個權重的誤差梯度。具有較高誤差梯度的權重是用於減少權重比特深度的差的選擇,因為精度會受到比例過大的影響。
來自硬體複雜度成本生成器52的硬體成本被輸入到硬體複雜度成本梯度生成器62。這些硬體成本包括比特深度成本。每個權重的硬體成本梯度是由硬體複雜度成本梯度生成器62計算的,並由權重選擇器70收集這些梯度。一些梯度,如誤差梯度,可以被反向傳播以使用一個鏈規則來找到每個參數上的梯度。來自其他正則化生成器56的正則化成本被輸入到正則化梯度生成器66,其產生正則化成本的梯度。
權重選擇器70合併來自硬體複雜度成本梯度生成器62、誤差梯度生成器64、和其他正則化梯度生成器66的梯度,以決定要調整哪些權重。權重選擇器70權衡精度誤差和硬體誤差,選擇最佳候選權重進行調整。權重選擇器70調整這些權重以產生更新的權重72。
終點終止器68將總權重和精度成本與目標進行比較,當還沒到達目標時,將更新的權重72發送回硬體複雜度成本生成器52、神經網絡輸出生成器54、和其他正則化生成器56用於另一個周期或迭代。一旦達到目標,將最後一組更新的權重72應用於神經網絡36以產生低比特深度神經網絡40。
神經網絡36中的14比特的平均比特深度已經被降低到低比特深度神經網絡40的10比特的平均比特深度。當使用數億的權重時,每個權重平均減少4個二進位比特對硬體成本來說是一個巨大節省。4比特的減少對權重存儲器100(圖1)中權重的存儲需求來說就是降低了28%。權重值的互聯和在每個節點上處理這些權重值的邏輯,同樣減少了。
圖9顯示使用比特深度優化引擎來減少權重硬體成本的曲線圖。本示例使用混合國家標準和技術研究所(MNIST)的手寫數字數據集作為訓練數據34。
精度顯示為一個存儲低比特深度神經網絡40中所有權重值所需的二進位比特總數的函數。傳統曲線150顯示沒有比特深度成本優化時精度與權重之間的函數關係。曲線152、154顯示使用比特深度優化引擎的精度與權重成本之間的關係。曲線152使用了一個5×10-7的定標參數γ,而曲線154使用了1×10-6的定標參數γ。定標參數γ乘以比特深度梯度成本,例如圖6B的曲線144。
在比特深度減小和精度之間存在權衡。比特深度優化引擎48將曲線向左移動,表示對於相同精度有較低的硬體成本。對一個97.4%的精度,硬體成本從傳統曲線150的1.1M比特減少到曲線152的840K比特以及曲線154的700K比特。在該示例中,浮點權重值被量化為15比特二進位值。
運行理論
以下是使用數學模型和近似的運行理論。這些模型僅用於提供信息的目的,而不是限制由權利要求限定的本發明。一個典型的神經網絡訓練涉及最小化成本函數J(θ):
J(θ)=E(θ)+λP(θ)+βKL(θ) (1)
公式(1)包括誤差度量E(θ)(如均方根(MSE))、用於防止過度擬合的加權衰減函數P(θ)、和被定義為Kullback-Leibler(KL)散度的稀疏函數KL(θ)。θ是一個包含神經網絡中所有參數權重的一維向量。θ充當優化問題中的決策變量。λ控制權重衰減項的大小,β控制稀疏項的大小。具體來說,權重懲罰項可以被定義為:
其中{θi}∈θ表示參數向量的元素。
發明人修改了公式(1)中的成本函數,來最小化基於權重比特深度的硬體複雜度成本。公式(2)中的權重懲罰項不能直接處理比特邊界特性。因此,比特深度懲罰γC(θ)被加到公式(1)的成本函數中,如公式:
J(θ)=E(θ)+λP(θ)+βKL(θ)+γC(θ) (3)
其中比特深度懲罰項C(θ)被定義為神經網絡的所有參數(權重和偏差)的比特深度總和。具體地,將一個參數θi的絕對值除以量化步長(2r/2b),其是最小的假設精度單位。r被定義為獲取神經網絡中央大約95%參數值的一個量值。這需要將某些神經網絡模型參數約束到一個給定範圍[-r,r],並將所有中間值線性量化成2b個二進位位,產生2r/2b的步長,其中b通常是從8到16範圍的量化比特,因為權重通常是使用介於8和16比特之間某個比特來表示它們的二進位值。然後,取對數以計算表示該整數大小所需的比特數。最後,一個比特用於整數大小的符號。懲罰項被定義為:
在每次優化迭代時,採取以下動作:
計算並生成成本J(θ):使用θ正向傳播數據以從成本J(θ)獲得一個值;
計算並生成一個梯度dJ(θ)/dθ:通過反向傳播算法計算一個分析梯度dJ(θ)/dθ。通過使用生成的梯度來改變權重,來更新定點表示的神經連接權重;和
重複執行上述步驟直到滿足終止條件。
在每次優化迭代結束時,用步長α(通常為α=1)更新θ,如公式:
其中t表示訓練中的迭代。
公式(5)中的梯度更新包含了比特深度懲罰γC(θ),如公式:
其中λ和β控制權重衰減項和稀疏項的大小,γ控制比特深度懲罰的大小。為了計算複雜度項的梯度dC(θ)/dθ,使用中心有限差分近似計算數值梯度,如公式:
其中∈是混合國家標準與技術研究所(MNIST)數據集的一個參數,定義為∈=0.02。公式(7)的含義是,如果θi在∈內的變化導致比特深度的變化,則C(θi)的梯度僅為非零。
為了進行說明,圖5顯示對數權重懲罰的成本log2(P(θi)0.5/(2r/2b))+1,以及比特深度懲罰的成本C(θi)。在圖5,比特深度懲罰的成本函數在比特邊界處跳躍以將比特數最小化。圖5描述比特深度懲罰如何鼓勵比特深度邊界附近的權重採用較低的比特深度值。
硬體成本降低
圖10顯示具有權重比特深度優化的神經網絡的集成電路的設計和製造過程。設計工程師創建神經網絡36的高級別設計,並輸入具有預期輸出的訓練數據34到神經網絡36,經過多個訓練周期,使用比特深度優化引擎48(圖4)優化權重比特深度。優化的結果是低比特深度神經網絡40。
低比特深度神經網絡40和該晶片上的其它電路,被轉換成邏輯門和導線的網表,然後通過布局和走線74轉換成物理布局76。物理布局76指定在每個晶片上的物理位置x、y,其中各種元件都布置在完成的集成電路(IC)晶片上。物理布局76被轉換為多個圖像層,其指定邏輯門位於何處、金屬線、通孔、以及層之間接觸的位置,以及襯底上氧化物和擴散區的位置。掩膜圖像78通常包括每層一個圖像。
掩膜製作機器讀取掩膜圖像78或另一個設計文件,將這些圖像物理地寫入或燒制到光掩膜82上。光掩膜82是一個有形產品,是優化軟體或程序產生低比特深度神經網絡40的一個結果,其是網表的一部分,最終通過布局軟體轉換成實際電晶體柵極和布線的掩膜圖像78。雖然優化軟體可以在通用計算機上執行,但是創建光掩膜82需要使用專用機器,其將布局數據寫入到各個掩膜上,例如通過由布局數據打開和關閉的光或電子束,同時在放置在空白光掩膜玻璃板上的未曝光的光致抗蝕劑聚合物層上以光柵化圖案進行掃描。光致抗蝕劑通過光或電子束在某些位置曝光,而在其它區域未曝光。然後,可以在化學顯影劑浴中洗曝光板,以除去曝光或未曝光的區域,從而產生光掩膜82。
在光掩膜製作80期間,光掩膜機產生多個板的光掩膜82,每個板對應每個半導體加工層。然後,將光掩膜82的板送到半導體工廠(fab)並裝載到光掩模機中,在IC製造過程84期間,其中穿過光掩膜82的光使得半導體晶片上的光致抗蝕劑樹脂曝光。在通過光掩模82的多層曝光處理以及諸如離子注入、擴散、氧化物生長、多晶矽和金屬沉積、通孔和接觸蝕刻、以及金屬和多晶矽蝕刻的其它處理之後,就通過IC製造過程84製造出了晶片86。晶片86是矽、砷化鎵、或其它在其表面上形成有圖案化層的半導體襯底。在每個晶片86上生成多個晶片。在初始晶片分類測試之後,將晶片86切割成小片,將其放入封裝中以生產IC 88。
因此,由比特深度優化引擎48產生的低比特深度神經網絡40,控制製造過程中的一系列步驟,最終生成光掩膜82和IC 88。控制這些機器的專用機器和計算機本身最終由低比特深度神經網絡40中的數據控制或指導以產生一個特定的IC 88晶片。設計工程師通過調整權重的比特深度而修改神經網絡36的設計,比特深度優化引擎48產生低比特深度神經網絡40。
IC 88可以是被安裝到諸如智慧型電話90的終端用戶設備中的ASIC或模塊。智慧型電話90可以包括相機92,使用IC 88內的神經網絡在智慧型電話90上處理相機92拍攝的圖像。神經網絡可以在智慧型電話90上本地執行諸如面部識別或圖像處理的操作。不需要使用大型機或計算集群上的遠程神經網絡。
其他實施方式
發明人還補充了幾個其它實施例。例如,低比特深度神經網絡40可以有許多應用,如用於自動駕駛汽車和其他駕駛員輔助系統的實時圖像識別、分析患者生命體徵的小型醫療可佩戴裝置、面部識別、其它圖像處理、語音識別、手寫識別、圖像去噪、圖像超解析度、對象檢測、圖像/視頻生成等。
一些實施例可以不使用所有組件。可以添加額外的組件。比特深度優化引擎可以使用各種成本生成器,諸如防止權重在多個周期的訓練優化後變得太大的權重衰減項、鼓勵節點將其權重歸零的稀疏懲罰,使得僅有一小部分總節點被有效地使用。剩餘的小部分節點是最相關的。雖然在運行理論中已經描述了含有各種成本函數的公式,但是可能有多種替換、組合和變化。可以向比特深度優化引擎48添加其它類型和種類的成本項。可以調整不同成本函數的相對定標因子的數值以平衡各種不同函數的影響。
浮點值可以轉換為定點值或二進位值。雖然已經顯示了二進位值權重,但是可以使用各種編碼,諸如二進位補碼、霍夫曼編碼、截斷二進位編碼等。表示權重值所需的二進位比特數目可以是指不分編碼方法的比特數,無論是二進位編碼、灰色碼編碼、定點、偏移等。
權重可以被限制在一個範圍值內。範圍不一定必須向下延伸到0,如511到0的範圍。權重的值可以被偏移以適合一個二進位範圍,如範圍10511到10000的權重,其可以被存儲為一個9比特二進位字,將偏移量10000添加到二進位字以生成實際權重值。也可以在優化期間調整範圍。偏移量可以被存儲,或可以被硬連線到低比特深度神經網絡40的邏輯。
訓練程序46有可能有多種變化。優化可以首先確定多個隱藏或中間層的節點,然後對權重進行優化。通過歸零一些權重以切斷節點之間的連結,權重可以確定節點的布局或連接性。當結構被優化時,稀疏成本可以用於初始優化循環,但當權重值被精調時,稀疏成本不用於隨後的優化循環。Sigmoid函數可以用於訓練隱藏層。查找表可以用於實施複雜函數,而不是算術邏輯單元(ALU)用於加速處理。
雖然MINST數據集已經用於測量比特深度優化引擎48可以提供的改進,但也可以使用其它訓練數據34。對於不同的應用和訓練集合,將有不同數量的成本降低。各種各樣的結構,不同數量和布置的隱藏層,可以用於輸入神經網絡36。特定應用可以使用某種類型的神經網絡或布置用於神經網絡36,或者可以使用通用神經網絡36作為起始點。自動編碼器、automax和softmax分類器以及其它種類的層可以被插入到神經網絡中。整個優化過程可以重複若干次,例如對於不同的初始條件,諸如對於不同數量的比特來量化浮點值或其它參數、不同精度、不同定標因子等等。可以針對各種條件組合來設置終點,例如期望的最終精度、精度硬體成本乘積、目標硬體成本等。
雖然低比特深度神經網絡40的實際成本取決於許多因素,例如節點數目、權重、互連、控制和接口,但是發明人將成本近似為與權重總和成比例。用於表示低比特深度神經網絡40中的所有權重的二進位比特總數是硬體成本的一個度量,即使只是一個近似度量。
硬體複雜度成本梯度可以有很大的梯度值,其至少是較小值的兩倍。當權重在比特深度步階的10%以內時,可能會出現很大值。可以使用其它閾值的大梯度值,以及到比特深度步階的距離。梯度值可以在比較之前或之後被縮放和改變。
各種其他IC半導體製造工藝有是可能的。光掩膜82可以用各種特殊機器和工藝製成,包括直接寫入以燒掉金屬層而不是光致抗蝕劑。擴散、氧化物生長、蝕刻、沉積、離子注入和其它製造步驟的多種組合可以由光掩膜控制在IC上產生圖案。
可以使用軟體、硬體、固件、程序、模塊、功能等的各種組合,以各種技術來實現比特深度優化引擎48和其它組件。最終產品,即低比特深度神經網絡40,可以在專用集成電路(ASIC)或其它硬體中實現以提高處理速度和降低功耗。
本發明的背景部分可以包含有關本發明問題或環境的背景信息,而不是由其他人描述的現有技術。因此,在背景部分中包括的材料不是申請人承認的現有技術。
在此描述的任何方法或過程是機器實施的或計算機實施的,並且旨在由機器、計算機或其它設備執行,並不旨在沒有這種機器輔助的情況下由人執行。生成的有形結果可以包括在諸如計算機監視器、投影設備、音頻生成設備和相關媒體設備的顯示設備上顯示的報告或其它機器生成的顯示,並且可以包括也是機器生成的硬拷貝列印輸出。其它機器的計算機控制是另一個有形結果。
所描述的任何優點和益處可能不適用於本發明的所有實施例。當在權利要求要素中陳述單詞「裝置」時,申請人意圖使權利要求要素符合35USC第112章第6段。通常,在單詞「裝置」之前有一個或多個單詞。在單詞「裝置」之前的一個或多個單詞是旨在便於引用權利要求要素,並不旨在傳達結構限制。這種裝置加功能的權利要求旨在不僅覆蓋這裡描述的用於執行功能及其結構等同物的結構,而且覆蓋等效結構。例如,雖然釘子和螺釘具有不同的構造,但是它們是等同的結構,因為它們都執行緊固的功能。不使用「裝置」一詞的權利要求不打算屬於35第112章第6段。信號通常是電子信號,但可以是光信號,例如可以通過光纖線路傳送的信號。
應當理解的是,以上實施例僅用以說明本發明的技術方案,而非窮舉或將本發明限制為所公開的精確形式。鑑於上述教導,可以對上述實施例所記載的技術方案進行修改,或者對其中部分技術特徵進行等同替換;而所有這些修改和替換,都應屬於本發明所附權利要求的保護範圍。