多人說話時自動分離語音 谷歌發布逆天深度學習模型
2025-04-26 00:54:24 1
在一段音頻中消除背景噪音,讓人的語音更清晰已經是十分成熟的技術。然後谷歌這次把人聲處理提升到了一個新高度:在多人同時說話的視頻中屏蔽其他人語音,只播放一個人的語音。(文中圖片於Google Research Blog)
Google Research Blog在4月11日發布了一篇圖/文/視頻並茂的文章概述了這項叫「Audio-Visual Speech Separation(音頻視覺分離)」的深度學習技術。
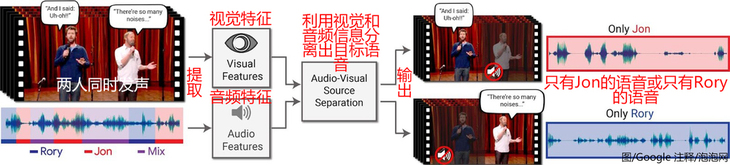
為了達到預想的效果,研究人員先人工分離了10萬個不同視頻中人的語音。研究人員把這些語音和相對應的人說話時面部動作,以及背景噪音交給了一個基於多串流卷積神經網絡的深度學習模型。該模型通過這些數據自主學習,最終獲得了音頻視覺分離的能力。

谷歌給出了幾個視頻例子,可以聽出該模型的音頻分離非常準確清晰。如果這項技術繼續發展,我們很可能會能在公共場合監控視頻裡分離並加強人群中一個人的語音。這可以被利用於犯罪偵查與反恐,但也有潛力變成窺探個人隱私的隱患。或者該技術也能幫手機智能助手更好地分辨出主人的聲音。
本文編輯:張哲
關注泡泡網,暢享科技生活。








