檢測CYP2C9和VKORC1基因多態性的引物、探針和試劑盒的製作方法
2023-12-01 11:58:16 3
本發明涉及基因多態性檢測技術領域,具體涉及檢測CYP2C9和VKORC1基因多態性的引物、探針和試劑盒。
背景技術:
華法林是目前臨床上廣泛使用的香豆素類口服抗凝藥,已被應用於多種疾病的抗凝治療,如靜脈血栓栓塞性疾病(VTE)的一級和二級預防、心房顫動血栓栓塞的預防、瓣膜病、人工瓣膜置換術和心腔內血栓形成等,但臨床療效和不良反應個體差異很大,劑量很難掌握,尤其是在使用華法林抗凝治療初期,極易導致嚴重的出血併發症。據估計,服用華法林的患者中,每年有15.2%的人發生出血副作用,其中致命性的大出血佔3.5%,不同個體間華法林穩定劑量的差異可達20倍以上。大量研究表明,華法林代謝酶CYP2C9基因和靶點基因VKORC1基因遺傳多態性與其抗凝療效密切相關,不同基因型患者所需華法林劑量差異明顯。
CYP2C9基因位於染色體的10q24.2區域,長約55kb,其最常見的等位基因被命名為CYP2C9*1(野生型)。目前大約有24個CYP2C9的非同義變異體已經被識別,其中對CYP2C9*2和CYP2C9*3(分別對應CYP2C9基因430C>T和1075A>C)的功能研究最為深入,CYP2C9*2蛋白的最大代謝率大約是野生型蛋白的50%,該變異蛋白對華法林的轉換率下降30%至50%。CYP2C9*3蛋白具有明顯升高的Km值和較低的內在清除率,可使S-華法林7-羥基化作用減少大約90%。分析表明,攜帶CYP2C9*2或CYP2C9*3變異型的患者需要相對較低的華法林維持劑量,對於攜帶CYP2C9*3基因型的患者,華法林治療劑量的減少更為顯著(劑量減少30%),出血副反應在攜帶CYP2C9*2和(或)CYP2C9*3等位基因的患者中幾乎加倍。
VKORC1是華法林的作用靶酶VKOR的編碼基因,位於染色體16p11.2,長約4kb。VKORC1的多個遺傳多態性位點也被證實與華法林的治療劑量相關,位於啟動子區的-1639G>A(rs9923231),內含子1的1173C>T(rs9934438)和3c-未翻譯區的3730G>A(rs7294),均被證實會對華法林劑量的個體差異產生影響。其中-1639G>A是目前研究的主要位點,突變型VKORC1基因轉錄活性下降,對華法林抵抗能力下降,-1639GG基因型對華法林的需求較-1639AA基因型高,同時研究表明該位點多態性存在民族差異,是影響華法林需求劑量中民族差異的主要因素。
目前,針對CYP2C9和VKORC1基因多態性檢測的方法有多種,主要包括DNA測序法、限制性片段長度多態性分析法(PCR-PFLP)、高解析度溶解曲線法(HRM)和基因晶片法(Genechips)等。DNA測序法是檢測金標準,但其對技術要求高、易汙染以及結果判讀耗時費力。PCR-PFLP步驟冗雜,靈敏度低。HRM簡單快速,但是不能檢測出純合突變,容易產生假陽性和假陰性。Genechips所需設備貴重,晶片造價高,難以普及。因此需要建立一種操作方便快速,特異性好,靈敏度高的基因檢測方法。
技術實現要素:
本發明要解決的技術問題是提供一組特異型號,靈敏度高的檢測CYP2C9和VKORC1基因多態性的引物和探針,本發明還提供了包括該引物和探針的試劑盒,以及該試劑盒的使用方法。
本發明經過大量試驗、研究和分析成功研究出能夠用於快速、靈敏、有效的檢測CYP2C9和VKORC1基因多態性檢測引物和探針。利用這組引物和探針可以檢測出CYP2C9*2、CYP2C9*3和VKORC1三個位點的基因多態性情況。
本發明提供的一組檢測CYP2C9和VKORC1基因多態性的引物和探針,包括以下核苷酸序列:
(1)檢測CYP2C9*2多態性的突變型上遊引物、野生型上遊引物以及公用的下遊引物和探針:
CYP2C9*2野生型ARMS上遊引物:
5』-GGGGAAGACGAGCATTGAGGAAC-3』(SEQ ID NO.1),
CYP2C9*2突變型ARMS上遊引物:
5』-ATGAGGAAGAGGAGCATTGAGGATT-3』(SEQ ID NO.2),
CYP2C9*2公用的下遊引物:
5』-GGTCACCCACCCTTGGTTTTTCT-3』(SEQ ID NO.3),
CYP2C9*2公用的探針:
5』-FAM/CAAGAGGAAGCCCGC/MGB-3』(SEQ ID NO.4);
(2)檢測CYP2C9*3多態性的突變型上遊引物、野生型上遊引物以及公用的下遊引物和探針:
CYP2C9*3野生型ARMS上遊引物:5』-GCACGATGTCCAGAGATAGA-3』(SEQ ID NO.5),
CYP2C9*3突變型ARMS上遊引物:5』-GCACGATGTCCAGAGATAGC-3』(SEQ ID NO.6),
CYP2C9*3公用的下遊引物:5』-CTTACCTTGGGAATGAGATAGT-3』(SEQ ID NO.7),
CYP2C9*3公用的探針:5』-FAM/ACCAGCCTGCCCCAT/MGB-3』(SEQ ID NO.8);
(3)檢測VKORC1基因-G1639A多態性的突變型上遊引物、野生型上遊引物以及公用的下遊引物和探針:
VKORC1位點野生型ARMS上遊引物:
5』-TAGACGTGAGCCACCGCAACC-3』(SEQ ID NO.9),
VKORC1位點突變型ARMS上遊引物:
5』-TAGGCGTGAGCCACCGCAACT-3』(SEQ ID NO.10),
VKORC1位點公用的下遊引物:
5』-GGGAAATATCACAGACGCCAGAGGA-3』(SEQ ID NO.11),
VKORC1位點公用的探針:
5』-FAM/ATCCCTTACTGTTGCAC/MGB-3』(SEQ ID NO.12);
所述探針均為MGB探針,探針核苷酸序列5』端標記螢光報告基團,3』端標記螢光淬滅基團。
本發明提供的檢測CYP2C9和VKORC1基因多態性的試劑盒,包括以上所述的檢測CYP2C9和VKORC1基因多態性的引物和探針。
優選地,上述檢測CYP2C9和VKORC1基因多態性的試劑盒,還包括內控引物對及內控探針,所述內控探針為Taqman探針,探針核苷酸序列5』端標記螢光報告基團,3』端標記螢光淬滅基團;
內控上遊引物:5』-GCCAAGGCTGTGGGCAAGGTC-3』(SEQ ID NO.13),
內控下遊引物:5』-CGCCTGCTTCACCACCTTCTTG-3』(SEQ ID NO.14),
內控探針:5』-JOE-CCTGCCGTCTAGAAAAACCTGCC-BHQ1-3』(SEQ ID NO.15)。
優選地,上述檢測CYP2C9和VKORC1基因多態性的試劑盒,還包括陽性對照,所述陽性對照為含有CYP2C9*2、CYP2C9*3和VKORC1基因三個SNP的6種質粒及內控質粒;所述內控質粒含有內控基因。
優選地,上述檢測CYP2C9和VKORC1基因多態性的試劑盒,還包括Fast master Premix。
Fast masterPremix為ABI公司的產品(即美國應用生物系統公司Applied Biosystems)的產品,其將NDA聚合酶與PCR緩衝液集成在一起。有利於使螢光定量PCR時Ct值提前,檢測結果更易判斷。
本發明提供的以上任一所述的檢測CYP2C9和VKORC1基因多態性的試劑盒的使用方法,包括:
(1)用內控引物及內控Taqman探針擴增陽性對照品,結果顯示JOE信號CT值小於25,表示試劑盒可用;
(2)將待檢樣品DNA分別用每個基因的突變型引物和探針,以及野生型引物和探針進行螢光定量PCR反應並獲得對應的突變型CT值和野生型CT值,該基因突變型CT值-野生型CT值=△Ct,△Ct>2.5為該基因的純野生型,△Ct<-2.5為該基因的純突變型,-2.5≤△Ct≤2.5為該基因的雜合型。
本發明涉及的檢測CYP2C9和VKORC1基因多態性的螢光定量PCR方法不包括對待測樣品處理和模板提取的步驟,但對EDTA抗凝血和口腔拭子提取的基因組DNA以及全血細胞去紅細胞後的白細胞都具有檢測能力。
與現有技術相比,本發明運用ARMS引物區分野生型和突變型基因,有如下有益效果和顯著進步:
(1)靈敏度高,可以準確檢出低至1ng的基因組DNA。對於保存時間過長以及口腔拭子這些提取濃度很低的樣本能準確檢出;
(2)特異性強,對於高至500ng及以上的基因組DNA不會出現非特異性的結果。可以減少稀釋樣本的過程,提取出的樣本直接上母液都能準確檢測而不會出現非特異性;
(3)適用於多種樣本類型:本發明不僅能檢測常規的EDTA抗凝的全血細胞DNA,還能檢測提取質量差的口腔拭子,還可以直接檢測全血細胞裂解紅細胞後的白細胞,檢測結果準確度高。
(3)成本低,ARMS分型法相對於Taqman探針分型法,不僅能保留Taqman的高靈敏度和高特異性,而且還能節約成本,ARMS引物合成快速簡單,合成成本低,擴增效果更佳。
(4)檢測速度快,整個檢測過程只需要90分鐘。
(5)應用Fast premix預混在反應體系中,減少了酶與樣本混合的步驟,減少了樣本的汙染,操作更簡單,一步加樣,避免了氣溶膠汙染引起的假陽性。
(6)安全:整個試劑盒不包含有毒有害物質,對操作人員和環境無危害。
總之,本發明涉及的CYP2C9和VKORC1基因多態性檢測試劑盒適用於臨床多種樣本類型選擇,具有特異性強,靈敏度高,實驗周期短,操作簡單,安全無毒,成本低等顯著優點。
附圖說明
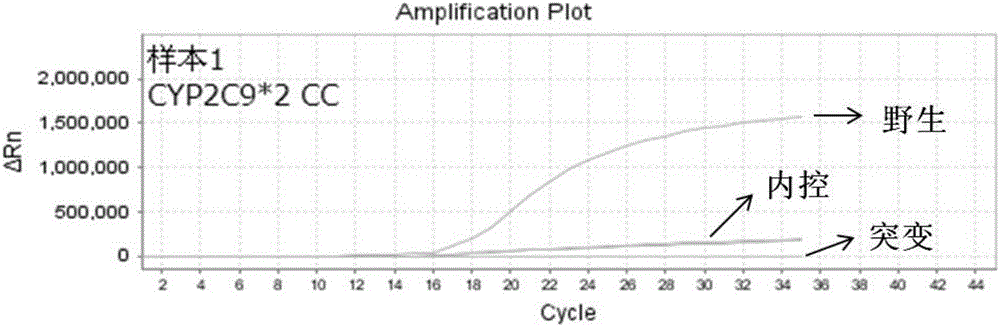
圖1是實施例2中樣本1的CYP2C9*2CC基因型的檢測結果;
圖2是實施例2中樣本1的CYP2C9*3CC基因型的檢測結果;
圖3是實施例2中樣本1的VKORC1GA基因型的檢測結果;
圖4是實施例2中樣本2的CYP2C9*2TT基因型的檢測結果;
圖5是實施例2中樣本2的CYP2C9*3CC基因型的檢測結果;
圖6是實施例2中樣本2的VKORC1GG基因型的檢測結果。
具體實施方式
下面結合具體實施例對本發明作進一步說明,以使本領域的技術人員可以更好地理解本發明並能予以實施,但所舉實施例不作為對本發明的限定。
以下實施例中所使用的技術,除非特別說明,均為本領域的技術人員已知的常規技術;所使用的儀器設備、試劑等,除非是本說明書特別說明,均為本領域的研究和技術人員可以通過公共途徑獲得的。
實施例1試劑盒組成
本發明所述的檢測試劑盒組成列舉以下兩種,分別見表1和表2。
表1試劑盒組成一
表2試劑盒組成二
Fast masterPremix為ABI公司的產品(即美國應用生物系統公司Applied Biosystems)的產品,其將NDA聚合酶與PCR緩衝液集成在一起。有利於使螢光定量PCR時Ct值提前,檢測結果更易判斷。
實施例2:臨床樣本DNA的提取
一、EDTA抗凝血
本實驗部分是從EDTA抗凝血中提取基因組DNA,並對其進行定量,作為PCR檢測的模板。採用天根公司的血液基因組DNA提取試劑盒,具體詳述如下。
1.處理血液材料:
a.當血液樣品體積小於200μL時,可加緩衝液GS補足體積至200μL,再進行下一步實驗(如血液樣品體積為200μL,可直接進行下一步實驗,不需加入GS)。
b.當血液樣品體積超過200μL時,需用細胞裂解液CL處理,具體步驟如下:在樣品中加入1~2.5倍體積的細胞裂解液CL,顛倒混勻,10,000rpm(~11,500×g)離心1min,吸去上清,留下細胞核沉澱(如果裂解不徹底,可重複以上步驟一次),向離心收集到的細胞核沉澱中加200μL緩衝液GS,振蕩至徹底混勻。
2.加入20μL Proteinase K溶液,混勻。
3.加200μL緩衝液GB,充分顛倒混勻,56℃放置10min,其間顛倒混勻數次,溶液應變清亮,
4.加200μL無水乙醇,充分顛倒混勻,此時可能會出現絮狀沉澱。
5.將上一步所得溶液和絮狀沉澱都加入一個吸附柱CB3中(吸附柱CB3放入收集管中),12,000rpm(~13,400×g)離心30sec,倒掉收集管中的廢液,將吸附柱CB3放入收集管中。
6.向吸附柱CB3中加入500μL緩衝液GD(使用前請先檢查是否已加入無水乙醇),12,000rpm(~13,400×g)離心30sec,倒掉收集管中的廢液,將吸附柱CB3放入收集管中。
7.向吸附柱CB3中加入600μL漂洗液PW(使用前請先檢查是否已加入無水乙醇),12,000rpm(~13,400×g)離心30sec,倒掉收集管中的廢液,將吸附柱CB3放入收集管中。
8.重複操作步驟7。
9. 12,000rpm(~13,400×g)離心2min,倒掉廢液。將吸附柱CB3置於室溫放置數分鐘,以徹底晾乾吸附材料中殘餘的漂洗液。
10.將吸附柱CB3轉入1.5ml離心管中,向吸附膜中間位置懸空滴加50-200μL洗脫緩衝液TB,室溫放置2-5min,12,000rpm(~13,400×g)離心2min,將溶液收集到離心管中。
11.定量
將提取的DNA用紫外分光光度計進行定量,稀釋DNA濃度到1ng/μL。二、口腔拭子樣本
本實驗部分是從口腔拭子中提取基因組DNA,並對其進行定量,作為PCR檢測的模板。採用康為世紀的口腔拭子基因組DNA提取試劑盒,具體詳述如下。
1.將口腔拭子的棉籤用剪刀從杆上剪下,置於2ml的離心管(自備)中,加入400μL Buffer GR。
注意:如需無RNA汙染的基因組DNA,可加入4μL濃度為100mg/ml的RNase A溶液(貨號:CW0601),震蕩混勻。
2.加入20μL Proteinase K和400μL Buffer GL,立即渦旋震蕩15秒,充分混勻。
注意:加入Buffer GL後立即充分混勻;不可將Proteinase K直接加入Buffer GL中使用。
3. 56℃放置10分鐘,短暫離心,使管壁上的溶液收集到管底。
4.加入400μL無水乙醇,渦旋震蕩充分混勻,短暫離心,使管壁上的溶液收集到管底。
5.將上步所得溶液和沉澱分兩次加入到已裝入收集管(Collection Tube2ml)的吸附柱(Spin Column DS)中,一次最多不超過700μL。12,000rpm(~13,400×g)離心1分鐘,倒掉收集管中的廢液,將吸附柱重新放回收集管中。
6.向吸附柱中加入500μL Buffer GW1(使用前檢查是否已加入無水乙醇),12,000rpm離心1分鐘,倒掉收集管中的廢液,將吸附柱重新放回收集管中。
7.向吸附柱中加入500μL Buffer GW2(使用前檢查是否已加入無水乙醇),12,000rpm離心3分鐘,倒掉收集管中的廢液,將吸附柱重新放回收集管中。
注意:如需進一步提高DNA純度,可重複步驟7。
8. 12,000rpm離心1分鐘,倒掉收集管中的廢液。將吸附柱置於室溫數分鐘,以徹底晾乾。
9.將吸附柱置於一個新的1.5ml離心管中,向吸附柱的中間部位懸空加入50μL Buffer GE或滅菌水,室溫放置2-5分鐘,12,000rpm離心1分鐘,收集DNA溶液,-20℃保存。
10.定量
將提取的DNA用紫外分光光度計進行定量,稀釋DNA濃度到1ng/μL。
實施例3:實時螢光PCR法擴增臨床樣本DNA
本實施例為採用本發明所提供的引物、探針擴增實施例2所提取的DNA樣品。
螢光定量PCR反應體系為:
PCR反應液:
MgCl2:2.0~5.0mmol,
dNTP:0.2~0.8mmol,
各條引物:0.1~1.0μmol,
各條探針:0.1~1.0μmol,
Fast master premix:6~10μL或熱啟動酶0.3~0.6μL,
模板:10μL,
總體積:40μL。
檢測方法如下:
1)每次PCR反應中,同時進行非模板對照(No Template Control;NTC)、陽性對照和待測樣本的檢測。
2)將陽性對照取出解凍後震蕩混勻,並離心30s。
3)將6聯PCR反應條取出解凍後離心30s,防止反應液在開蓋時濺出。
4)將ddH2O(NTC)、實施例2中提取的DNA樣本、陽性對照分別加入6聯PCR反應條,每孔10μL。
5)將以上6聯PCR反應條蓋好管蓋於離心機上離心30S,確保管壁上不沾有液滴。
6)將6聯PCR反應條放於實時PCR儀器中。
反應條件的設置:
第一階段:95℃4min;
第二階段:95℃5s,58℃30s,10個循環;
第三階段:95℃5s,58℃30s,72℃30s,35個循環;
信號收集:第三階段72℃時收集FAM和JOE信號。
利用ARMS引物區分野生型和突變型基因序列,通過反應體系的突變型和野生型FAM信號的螢光強度差異來判斷檢測結果;JOE是內控信號,用於檢測體系是否正常,樣本是否漏加及初步判斷樣本DNA量是否在允許範圍內,JOE信號應達到設定閾值(Ct值小於25);FAM是檢測信號,用於檢測樣本的基因多態性;在內控信號達到要求後,以每個SNP位點的突變型和野生型FAM信號達到設定閾值所需的循環次數Ct值的差值作為判斷標準。選擇1、2號管,根據FAM信號△Ct值判斷檢測樣本CYP2C9*2的等位基因型多態性;選擇3、4號管,根據FAM信號△Ct值判斷檢測樣本CYP2C9*3的等位基因型多態性;選擇5、6號管,根據FAM信號△Ct值判斷檢測樣本VKORC1的基因多態性,根據表3進行結果判定:
表3基因多態性檢測結果判定
其中,樣本列中,①~⑥分別指其對應的管號經過螢光定量PCR獲得的Ct值。
表4樣本檢測結果
說明:EDTA抗凝血提取的基因組DNA和口腔拭子提取的基因組DNA用本發明的試劑盒檢測的結果和「金標準」sanger測序的結果完全一致,試劑盒準確度高,適應樣本廣。
以上所述實施例僅是為充分說明本發明而所舉的較佳的實施例,本發明的保護範圍不限於此。本技術領域的技術人員在本發明基礎上所作的等同替代或變換,均在本發明的保護範圍之內。本發明的保護範圍以權利要求書為準。
SEQUENCE LISTING
武漢海吉力生物科技有限公司
檢測CYP2C9和VKORC1基因多態性的引物、探針和試劑盒
WH1610028-1
15
PatentIn version 3.3
1
23
DNA
人工序列
1
ggggaagacg agcattgagg aac 23
2
25
DNA
人工序列
2
atgaggaaga ggagcattga ggatt 25
3
23
DNA
人工序列
3
ggtcacccac ccttggtttt tct 23
4
15
DNA
人工序列
4
caagaggaag cccgc 15
5
20
DNA
人工序列
5
gcacgatgtc cagagataga 20
6
20
DNA
人工序列
6
gcacgatgtc cagagatagc 20
7
22
DNA
人工序列
7
cttaccttgg gaatgagata gt 22
8
15
DNA
人工序列
8
accagcctgc cccat 15
9
21
DNA
人工序列
9
tagacgtgag ccaccgcaac c 21
10
21
DNA
人工序列
10
taggcgtgag ccaccgcaac t 21
11
25
DNA
人工序列
11
gggaaatatc acagacgcca gagga 25
12
17
DNA
人工序列
12
atcccttact gttgcac 17
13
21
DNA
人工序列
13
gccaaggctg tgggcaaggt c 21
14
22
DNA
人工序列
14
cgcctgcttc accaccttct tg 22
15
23
DNA
人工序列
15
cctgccgtct agaaaaacct gcc 23