一種語音情感遷移方法與流程
2023-12-12 05:58:17 3
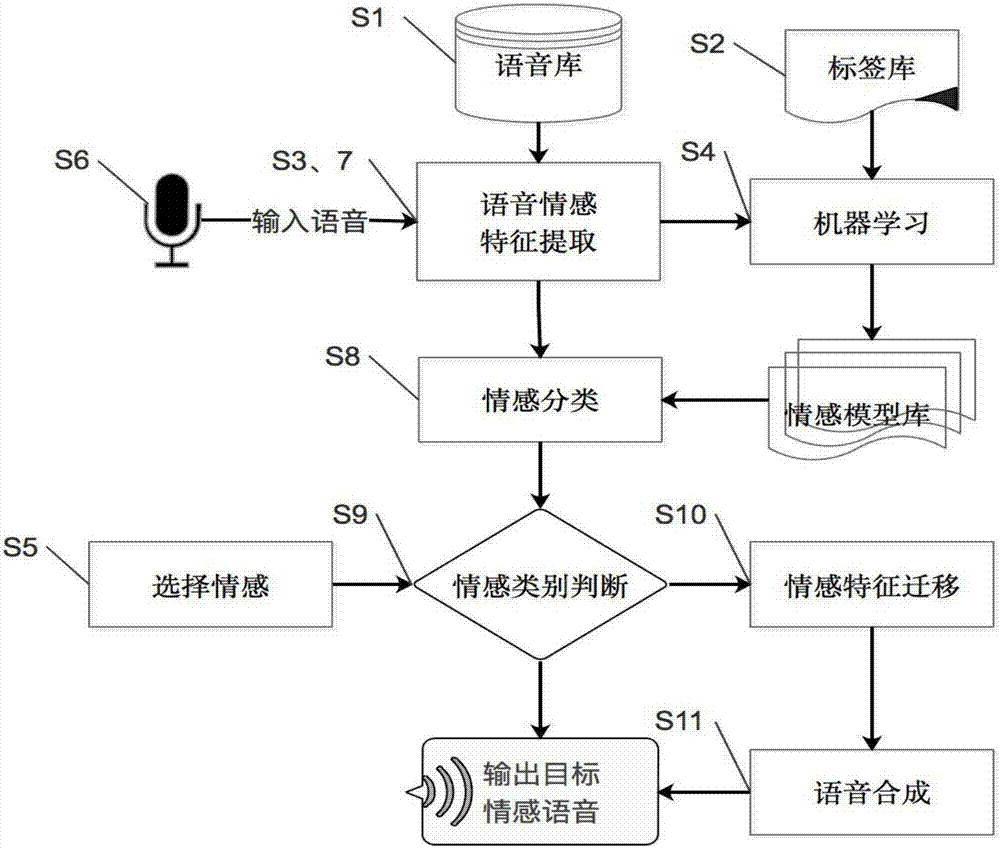
本發明屬於語音識別技術領域,涉及語音情感的遷移方法,具體涉及一種基於不同語音提供者模型的語音情感的遷移方法。
背景技術:
隨著智能晶片技術的發展,各種終端設備的智能化和集成化程度越來越高,設備的小型化、輕便化、網絡化使得人們的生活越來越便捷。用戶不斷的通過網絡終端進行語音視頻的交流,積累了海量的多媒體數據。隨著平臺數據的積累,智能問答系統也逐漸應運而生。這些智能問答系統包括了語音識別、性感分析、信息檢索、語義匹配、句子生成、語音合成等先端技術。
語音識別技術是讓機器通過識別技術和理解過程把語音信號轉化為所對應的文本信息或者機器指令,讓機器能夠聽懂人類的表達內容,主要包括語音單元選取、語音特徵提取、模式匹配和模型訓練等技術。語音單元包括單詞(句)、音節和音速三種,具體按照場景和任務來選擇。單詞單元主要適合小詞彙語音識別系統;音節單元更加適合於漢語語音識別;音素雖然能夠很好地解釋語音基本成分,但由於發音者的複雜多變導致無法得到穩定的數據集,目前仍在研究中。
另一個研究方向是語音的情感識別,主要由語音信號採集、情感特徵提取和情感識別組成。其中情感特徵提取主要有韻律學特徵、基於譜的相關特徵和音質特徵三種。這些特徵一般以幀為最小粒度來實現提取,並以全局特徵統計值的形式進行情感識別。在情感識別算法方面,主要包括離散語言情感分類器和維度語音情感預測器兩大類。語音情感識別技術也被廣泛應用於電話服務中心、駕駛員精神判別、遠程網絡課程等領域。
智能體被譽為是下一代人工智慧的綜合產物,不僅能夠識別周圍環境因素,理解人的行為表達和語言描述,甚至在與人的交流過程中,更需要去理解人的情感,並且能夠實現模仿人的情感表達,才能實現更為柔和的交互。目前智能體的情感研究主要集中在基於虛擬圖像處理,涉及計算機圖形學、心理學、認知學、神經生理學、人工智慧等多個領域有研究者的成果。據研究,人雖然90%以上的環境感知信息來自視覺,但是絕大部分的情感感知是來自語音。如何從語音領域建立類人智能體的情感體系,至今尚未有公開的研究發布。
技術實現要素:
本發明的目的是以機器學習方法為主要手段,提出一種人的語音情感表述方法,並在此基礎上使用深度學習和卷積網絡算法,從系統上實現語音情感的遷移。不僅對語音識別、情感分析提供了一定的借鑑方法,更能在未來類人智能體上得到廣泛應用。
為實現上述目的,本發明提出的技術方案為一種語音情感遷移方法,具體包含以下步驟:
步驟1、準備一個語音資料庫,通過標準採樣生成語音情感數據集s={s1,s2,…,sn};
步驟2、採用人工方式對步驟1的語音資料庫打標籤,標註每個語音文件的情感e={e1,e2,…,en};
步驟3、採用語音特徵參數模型對語音庫中的每個音頻文件si進行音頻特徵抽取,得到基本的語音特徵集fi={f1i,f2i,…,fni};
步驟4、採用機器學習工具對步驟3得到的每個語音特徵集與步驟2得到的語音情感標籤進行機器學習,得到每一類語音情感的特徵模型,構建情感模型庫eb;
步驟5、通過一個多媒體終端,選擇需要語音情感遷移的目標target;
步驟6、從多媒體終端輸入語音信號st;
步驟7、將當前輸入的st輸入到語音情感特徵提取模塊,得到當前語音信號的特徵集ft={f1t,f2t,…,fnt};
步驟8、採用與步驟4相同的機器學習算法,將步驟7得到的st的語音特徵集ft結合步驟步驟4得到的情感模型庫eb進行情感分類,得到st的當前情感類別se;
步驟9、判斷步驟8得到的se和步驟5輸入的target是否一致,如果se=targete,則將原始輸入語音信號直接作為目標情感語音輸出,如果setargete,則調用步驟10進行特徵情感遷移;
步驟10、將當前語音情感主要特徵向情感模型庫中的語音情感主要特徵進行遷移;
步驟11、採用語音合成算法對步驟10得到的特徵遷移後的語音特徵進行加工,合成最終目標情感語音輸出。
進一步,上述步驟1中,語音數據的採樣頻率為44.1khz,錄音時間在3~10s之間,並且保存為wav格式。
步驟1中,為了獲得較好的性能,採樣數據的自然屬性維度不能過於集中,採樣數據儘量在不同年齡、性別、職業等人中採集。
步驟6中,所述輸入可以是實時輸入,也可以是錄製完成後點擊遞交。
本發明具有以下有益效果:
1、本發明首先提出語音情感遷移的概念,可以為未來虛擬實境提供情感構建方法。
2、本發明提出的基於情感分類和特徵遷移的方法,能夠在不失原始說話人發聲特徵的前提下實現語音情感的變化。
附圖說明
圖1是本發明提供的語音情感遷移方法示意圖。
圖2是本發明原始輸入語音樣本的頻譜特徵圖。
圖3是本發明原始語音樣本經過情感轉化的頻譜特徵圖。
具體實施方式
現結合附圖對本發明作進一步詳細的說明。
本發明提供一種基於語音情感資料庫的用戶表達語音情感遷移方法,如圖1所示,該方法涉及的模塊或功能包括:
基礎語音庫,存有不同年齡、性別、場景下的語音原始數據。
標籤庫,對基礎語音庫進行情感標註,如平和、高興、生氣、憤怒、悲傷等。
語音輸入裝置,如麥克風,可以實現用戶的實時語音輸入。
語音情感特徵提取,通過聲音特徵分析工具,得到一般的聲音特徵,並根據人的語音信號特點以及情感表現特點,選取所需的特徵集作為語音情感特徵。
機器學習,採用機器學習算法印證語音情感標籤庫,對語音情感特徵集構建訓練模型。
情感模型庫,語音庫數據通過機器學習得到的按照性別、年齡、情感等維度分類後的語音情感模型庫。
選擇情感,用戶在輸入語音信號前選擇需要將當前語音實時轉化為的情感模式。
情感類別判斷,判斷當前用戶輸入的情感是否與選擇的情感一致。如果一致,則直接輸出目標情感語音。如果不一致,調用情感遷移模塊。
情感遷移,在用戶輸入語音和選擇情感不一致的情況下,將輸入語音情感特徵集與選擇情感特徵集進行特徵距離對比,調整輸入語音情感特徵空間表示,實現情感遷移。然後將調整好的情感語音作為目標情感語音輸出。
現提供一個實施例,以說明語音情感的遷移過程,具體包含以下步驟:
步驟1、該方法需要準備一個語音資料庫,作為優選,語音數據採用標準採樣44.1khz,錄下某個測試人員一句話,時間在3~10s之間,並且保存為wav格式,得到語音情感數據集s={s1,s2,…,sn}。為了獲得較好的性能,採樣數據盡力在不在年齡、性別、職業等人的自然屬性維度過於集中。
步驟2、採用人工的方式,對步驟1準備的語音資料庫打標籤,標註每個語音文件的情感e={e1,e2,…,en},如「擔心」,「吃驚」,「生氣」,「失望」,「悲傷」等
步驟3、採用語音特徵參數模型對語音庫中每個音頻文件si進行音頻特徵抽取,得到基本的語音特徵集fi={f1i,f2i,…,fni}等(圖2所示為原始語音樣本的頻譜特徵示意圖),如」包絡線(env)」,「語速(speed)」,」過零率(zcr)」,「能量(eng)」,「能量熵(eoe)」,「頻譜質心(spec_cent)」,「頻譜擴散(spec_spr)」,「梅爾頻率(mfccs)」,「彩度向量(chrona)」等。
步驟4、採用機器學習工具(如libsvm)對步驟3得到的每個語音文件的特徵集與步驟2所得到的語音情感標籤進行機器學習,得到每一類語音情感的特徵模型,構建情感模型庫eb。
步驟5、通過一個多媒體終端,選擇需要語音情感遷移目標targete,如「悲傷」。
步驟6、從多媒體終端輸入語音信號st,可以是實時輸入,也可以是錄製完成後點擊遞交。
步驟7、將當前輸入的st輸入到語音情感特徵提取模塊,得到當前語音信號的特徵集ft={f1t,f2t,…,fnt}。
步驟8、採用步驟4相同的機器學習算法,將步驟7得到的st的語音特徵集ft結合步驟步驟4得到的情感模型庫eb進行情感分類,得到st的當前情感類別se。
步驟9、判斷步驟8得到的se和步驟5輸入的targete是否一致,如果se=targete,則將原始輸入語音信號直接作為目標情感語音輸出。如果seitargete,則調用步驟10進行特徵情感遷移。
步驟10、將當前語音情感主要特徵向情感模型庫中語音情感主要特徵進行遷移(圖3所示為遷移後的頻譜特徵),如包絡線遷移resultenv=(senv+targetenv)/2,語速調整resultspeed=(sspeed+targetspeed)/2。
步驟11、採用一個語音合成算法(基音同步疊加技術,psola)對步驟10得到的特徵遷移過的語音特徵進行加工合成最終目標情感語音輸出。
以上所述僅為本發明的優選實施案例而已,並不用於限制本發明,儘管參照前述實施例對本發明進行了詳細的說明,對於本領域的技術人員來說,其依然可以對前述各實施例所記載的技術方案進行改進,或者對其中部分技術進行同等替換。凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護範圍之內。