一種用於說話人識別系統的後端i‑vector增強方法與流程
2024-01-22 17:26:15 3
本發明屬於說話人識別技術領域,特別指一種用於說話人識別系統的後端i-vector增強方法。
背景技術:
說話人識別(speakerrecognition,sr)又稱聲紋識別,是利用語音信號中含有的特定說話人信息來識別說話者身份的一種生物認證技術。近年來,基於因子分析的身份認證矢量(identityvector,i-vector)說話人建模方法的引入使得說話人識別系統的性能有了明顯的提升。實驗表明,在對說話人語音的因子分析中,通常信道子空間中會包含說話人的信息。因此,i-vector用一個低維的總變量空間來表示說話人子空間和信道子空間,並將說話人語音映射到該空間得到一個固定長度的矢量表徵(即i-vector)。基於i-vector的說話人識別系統主要包括充分統計量提取、i-vector映射、似然比得分計算3個步驟。首先提取語音信號特徵來訓練表徵語音空間的gauss混合模型-通用背景模型(gaussianmixturemodel-universalbackgroundmodel,gmm-ubm),利用訓練好的ubm計算每幀語音特徵的充分統計量,並將該充分統計量映射到總變量空間得到每條說話人語音的i-vector。最後利用概率線性鑑別式分析(probabilisticlineardiscriminantanalysis,plda)模型對i-vector建模並計算似然比得分,根據設定的閾值做出最終判決。但是,在應用環境中存在背景的情況下,系統的性能會急劇下降。這也是現在說話人識別技術走向商業化的一大障礙。
近年來,隨著機器學習算法性能的提升和計算機存儲、計算能力的提高,深層神經網絡(deepneuralnetwork,dnn)被應用到各個領域中並取得了顯著的效果。dnn對非線性函數關係具有很強的擬合能力,經過訓練後的dnn可以用來表示輸入數據和輸出數據之間的非線性映射關係。近年來,在語音增強領域,利用dnn的這種非線性結構,通過學習含噪語音特徵和純淨語音特徵之間的非線性映射關係,將dnn設計成一個降噪濾波器,達到語音增強的目的。該方法如果簡單作為說話人識別系統的前端模塊,在一定程度上提高系統性能的同時,也使系統結構複雜化,增加了對語音信號處理的計算量,因此該方法與說話人識別系統的融合成為當前技術難點。
技術實現要素:
本發明所要解決的技術問題是針對上述現有技術的不足,提供一種基於dnn的用於說話人識別系統的i-vector後端增強方法。
本發明解決該技術問題所採用的技術方案如下:一種用於說話人識別系統的i-vector後端增強方法,包括以下步驟:分為訓練和識別兩個階段,訓練階段步驟如下:
a-1),對訓練說話人語音信號進行預處理,包括預加重、端點檢測、分幀、加窗;
a-2),利用所述mfcc提取法,提取說話人語音信號的mfcc特徵;具體有:對分幀加窗後的各幀信號進行快速傅立葉變換得到各幀的頻譜。並對語音信號的頻譜取模平方得到語音信號的功率譜,設語音信號的dft為:
式中x(n)為輸入的語音信號,n表示傅立葉變換的點數。
將能量譜通過一組mel尺度的三角形濾波器組,定義一個有m個濾波器的濾波器組(濾波器的個數和臨界帶的個數相近),採用的濾波器為三角濾波器,中心頻率為f(m),m=1,2,...,m。m通常取22-26。各f(m)之間的間隔隨著m值的減小而縮小,隨著m值的增大而增寬。
經離散餘弦變換(dct)得到mfcc係數:
將上述的對數能量帶入離散餘弦變換,求出l階的梅爾頻率倒譜參數。l階指mfcc係數階數,通常取12-16。這裡m是三角濾波器個數。
a-3),根據a-2)提取的mfcc特徵訓練gmm-ubm模型來對語音聲學特徵進行對準,並計算得到特徵的高維充分統計量;
a-4),根據a-3)得到的特徵充分統計量訓練i-vector特徵提取器,利用該提取器提取說話人語音信號的i-vector;
a-5),根據a-4)訓練得到的i-vector特徵提取器,提取純淨語音和含噪語音的i-vector,其中,含噪語音的i-vector作為dnn訓練數據,純淨語音的i-vector作為標籤數據;
a-6),根據a-4)得到的訓練數據和標籤數據,使用以下所述方法對深度神經網絡模型進行訓練,經過訓練後的神經網絡模型作為i-vector後端增強模塊,與i-vector/plda說話人識別模型融合;dnn訓練步驟如下:
(a-6-1)利用cd算法逐層預訓練構成dbn網絡的rbm參數,採用自底向上的方法訓練多個rbm,每個rbm隱含層作為下一rbm輸入層,逐層累加得到多層結構;
(a-6-2)在訓練好的dbn頂部添加線性輸出層得到dnn結構,利用誤差反向傳播算法,將mmse函數作為優化函數,通過最小化優化函數得到最優參數;
識別步驟為:
b-1),對識別語音進行預加重、端點檢測、分幀、加窗,並提取識別語音的mfcc特徵;
b-2),根據權利要求1中訓練得到的i-vector特徵提取器,提取待識別說話人每條註冊語音和識別語音的i-vector,並將這些i-vector分別作為權利要求1所述的dnn模型的輸入,該模型的輸出為增強後的i-vector;
b-3),將待識別說話人註冊語音增強後的i-vector和識別語音增強後的i-vector輸入plda模型打分,將plda輸出的似然比得分與設定的閾值比較,做出最終判決結果。
有益效果
本發明與傳統說話人識別系統相比,將dnn與說話人識別系統模型相融合,結合dnn在語音增強領域的顯著效果,本發明公開的說話人識別方法在存在背景噪聲的環境下能夠有效提升系統的識別性能,在降低噪聲對系統性能影響、提高系統噪聲魯棒性的同時,優化系統結構,使識別實時性得到有效增強,提高相應說話人識別產品的競爭力。
附圖說明
圖1為基於i-vector後端增強的說話人識別系統結構圖;
圖2為mfcc特徵提取流程圖;
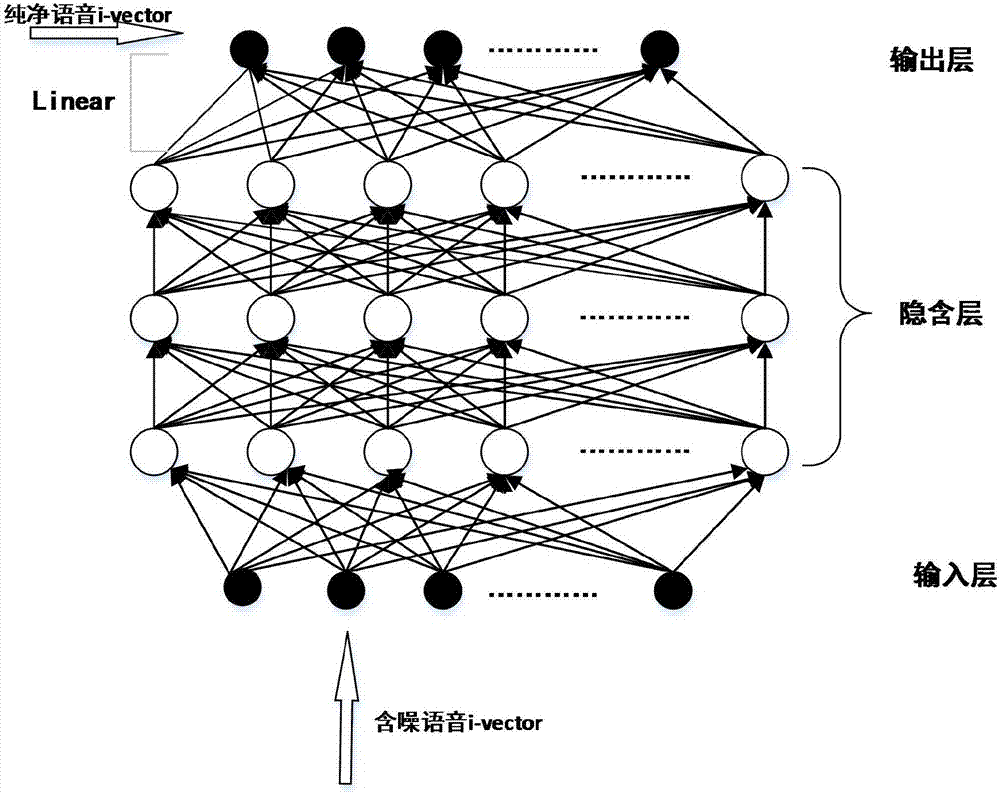
圖3為神經網絡結構圖;
圖4(a)為car噪聲下系統det曲線圖;
圖4(b)為babble噪聲下系統det曲線圖。
具體實施方式
下面將結合附圖對本發明具體實施方式做進一步說明:如圖1所示,本發明採用的技術方案如下:一種基於dnn的用於說話人識別系統的i-vector後端增強方法包括以下步驟:分為訓練和識別兩個階段,所述的訓練步驟是:
第一步,對說話人語音信號進行預處理,包括預加重、端點檢測、分幀、加窗。
(1)預加重
預加重處理是將語音信號通過一個高通濾波器:
h(z)=1-μz-1
式中μ的值介於0.9-1.0之間,我們通常取0.97。預加重的目的是提升高頻部分,使信號的頻譜變得平坦,保持在低頻到高頻的整個頻帶中,能用同樣的信噪比求頻譜。同時,也是為了消除發生過程中聲帶和嘴唇的效應,來補償語音信號受到發音系統所抑制的高頻部分,也為了突出高頻的共振峰。
(2)分幀
先將n個採樣點集合成一個觀測單位,稱為幀。通常情況下n的值為256或512,幀長約為20~30ms左右。為了避免相鄰兩幀的變化過大,因此會讓兩相鄰幀之間有一段重疊區域,此重疊區域包含了m個取樣點,通常m的值約為n的1/2或1/3。
(3)加窗(hammingwindow)
將每一幀乘以漢明窗,以增加幀左端和右端的連續性。假設分幀後的信號為s(n),n=0,1,…,n-1,n為幀的大小,那麼乘上漢明窗後s′(n)=s(n)×w(n),w(n)形式如下:
不同的a值會產生不同的漢明窗,一般情況下a取0.46。
第二步,如圖2所示,利用所述mfcc提取法,提取說話人語音信號的mfcc特徵,mfcc特徵提取步驟如下:
(1)對分幀加窗後的各幀信號進行快速傅立葉變換得到各幀的頻譜。並對語音信號的頻譜取模平方得到語音信號的功率譜。設語音信號的dft為:
式中x(n)為輸入的語音信號,n表示傅立葉變換的點數。
(2)將能量譜通過一組mel尺度的三角形濾波器組,定義一個有m個濾波器的濾波器組(濾波器的個數和臨界帶的個數相近),採用的濾波器為三角濾波器,中心頻率為f(m),m=1,2,...,m。m通常取22-26。各f(m)之間的間隔隨著m值的減小而縮小,隨著m值的增大而增寬。
(3)經離散餘弦變換(dct)得到mfcc係數:
將上述的對數能量帶入離散餘弦變換,求出l階的mel-scalecepstrum參數。l階指mfcc係數階數,通常取12-16。這裡m是三角濾波器個數。
第三步,根據步驟二提取的mfcc特徵訓練gmm-ubm模型來對語音聲學特徵進行對準,並計算得到特徵的高維充分統計量。具體地,
其中,和分別表示第k段語音段在第c個gmm高斯分量上的零階統計量、一階統計量和二階統計量,表示第k段語音段的第t個時間段的語音特徵表示,表示語音特徵對第c個gmm混合分量的後驗概率,可通過下式計算得到:
其中,c為混合高斯分量總數,μc和∑c分別對應第c個高斯分量的權重、均值和協方差。
第四步,根據步驟三得到的特徵充分統計量訓練i-vector特徵提取器,利用該提取器提取說話人語音信號的i-vector。具體地,i-vector因子分析模型建立在gmm-ubm所表徵的均值超向量空間之上。給定一段語音,其gauss均值超矢量m可以分解為如下形式:
m=m+tω
其中:m是說話人和信道無關分量,通常可以採用ubm的均值超矢量來代替;t是總體變化子空間矩陣;ω是包含了說話人和信道信息的變化因子,即i-vector。
第五步,根據步驟四訓練得到的i-vector特徵提取器,提取純淨語音和含噪語音的i-vector,其中,含噪語音的i-vector作為dnn訓練數據,純淨語音的i-vector作為標籤數據。
第六步,根據步驟四得到的訓練數據和標籤數據,使用以下所述方法對深度神經網絡模型進行訓練,經過訓練後的神經網絡模型作為i-vector後端增強模塊,與i-vector/plda說話人識別模型融合。深層神經網絡訓練步驟如下:
(1)利用對比散度算法(contrastivedivergence,cd)逐層預訓練構成dbn網絡的rbm參數,採用自底向上的方法訓練多個rbm,每個rbm隱含層作為下一rbm輸入層,逐層累加得到深度置信網絡(deepbeliefnetwork,dbn)模型。rbm是一種包含一層可見層和一層隱含層的2層無向圖模型,相同層的節點之間無連接。假設v和h分別表示可見層節點和隱含層節點,定義(v,h)間的聯合分布如下所示:
其中w表示可見層節點和隱含層節點間的權重矩陣,b和c分別是可見層節點和隱含層節點的偏置,z是歸一化因數。rbm的優化目標是要最大化可見層節點概率分布在訓練過程中可以通過梯度下降和cd算法估計得到模型參數。
(2)如圖3所示,在訓練好的dbn頂部添加線性輸出層得到dnn回歸模型。利用誤差反向傳播(bp)算法,將mmse函數作為優化函數,通過最小化優化函數得到最優參數。具體地,bp算法分為兩步:(1)前向響應傳播,即將輸入通過各隱層獲得相應,前一層響應作為後一層輸出依次向前傳播,直到最後一層輸出預測值。每層隱層的激活函數選擇為sigmoid函數,表達式為:
sigmoid函數單調遞增、無限可微的非線性特性使使神經網絡能夠很好地擬合含噪語音i-vector和純淨語音i-vector之間的非線性映射關係。
(2)誤差反向傳播,即將前向傳播輸出的預測值與參考值之間的誤差進行反向傳播,誤差計算公式如下:
其中,w,b分別為模型的權重和偏置參數。根據反向傳播到每層的誤差來更新神經網絡每層的權重和偏置:
這裡,σ表示學習率,為l層第i個單元的權重,當進行bp算法的迭代時,權重更新的關係表達式為:
wn=wn-1+δw
即第n次迭代後的權重等於第n-1次迭代權重加上權重的更迭量。
所述的識別步驟為:
第一步,對識別語音進行預加重、端點檢測、分幀、加窗,並提取識別語音的mfcc特徵。
第二步,利用訓練得到的i-vector特徵提取器,提取待識別說話人每條註冊語音和識別語音的i-vector,並將這些i-vector分別作為訓練得到的dnn模型的輸入,該模型的輸出為增強後的i-vector。
第三步,將待識別說話人註冊語音增強後的i-vector和識別語音增強後的i-vector輸入plda模型打分,將plda輸出的似然比得分與設定的閾值比較,做出最終判決結果。
下面結合實例來說明此發明的實際效果,給定一段測試語音,仿真混合0db-27db之間隨機信噪比的加性babble和car噪聲,提取含噪語音的i-vector之後利用本發明所述的dnn模型進行增強。分別對純淨語音、含噪語音、i-vector增強下語音進行打分測試,處理結果如圖4(a),圖4(b)所示。
圖4(a),圖4(b)分別給出了在car和babble背景噪聲環境下,系統在純淨語音、含噪語音、和i-vector增強下語音的det曲線,可以明顯看出,經i-vector增強後的系統相比噪聲環境下性能有了顯著的提高,本發明有效的提高了系統的噪聲魯棒性。
本發明實例只是介紹其具體實施方式,不在於限制其保護範圍。本行業技術人員在本實例的啟發下可以做某些修改,故凡依照本發明專利範圍所做的等效變化或修飾,均屬於本發明專利權利要求範圍內。