一種面向CT影像的腫瘤分割方法及其系統
2024-04-14 03:03:05 1
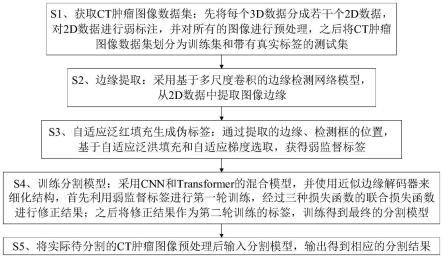
一種面向ct影像的腫瘤分割方法及其系統
技術領域
1.本發明涉及計算機視覺處理技術領域,尤其是涉及一種面向ct影像的腫瘤分割方法及其系統。
背景技術:
2.圖像分割技術是當前人工智慧領域,特別是計算機視覺中的重要研究方向,也是幫助機器進行語義理解的重要組成部分,在計算機輔助診療中,面向醫療影像的分割任務是輔助醫生進行病灶定位、度量等的重要環節。
3.計算機輔助診療是指通過影像學分析、生理、生化手段等結合計算機圖像處理、機器學習建模等方法對醫療數據進行分析和計算,輔助發現病灶或確定病灶性質提高診斷準確率。其中,準確分割器官或病灶部位可以為後續診斷提供重要參考。現有基於深度學習的醫療影像分割方法大多使用全監督進行模型訓練,即需要人工逐像素標註所有病灶部分的分割標籤,然而,在實際情況下,這種標註方法費時費力,且難以獲得大量準確標註的樣本。
4.自2015年之後,基於深度學習的方法成為計算機處理醫療影像分割的主要方法。jonathan等提出了使用全卷積代替全連接的fcn;olaf等提出了基於skipconnection的u-net;fausto等提出了針對3d醫療數據的分割模型v-net;zhou 等針對u-net的局限性設計了更加完善的u型網絡結構u-net++。面向ct影像的肺部腫瘤分割問題同樣具有較高的研究價值和實際意義,reza等在u-net基礎上增加了lstm結構提出了bcdu-net,li等提出了一個聯合學習切片內特徵和切片之間的特徵的模型h-denseunet。然而,和所有醫療影像分割任務一樣,現有基於深度學習的方法大多採用全監督的訓練方式,即需要人工逐像素標註出目標病灶的分割信息,將耗費大量人力成本,且效率低、無法保證標註的準確性。
5.因此,不僅是在面向ct圖像的肺部腫瘤分割任務,包括其他的醫療影像分割任務中,如何有效減少在深度學習模型訓練中由於需要逐像素標註而造成的大量人力物力浪費的問題是非常有實際應用價值的。此外,在通用視覺分割任務中,使用的自然圖像通常包含豐富的語義信息,即每個需要分割的實例對象都有較為明顯且豐富的特徵,標註難度較低,不需要很高的領域知識門檻。然而,在醫學影像中,需要分割的病灶部分往往沒有像自然圖像一樣具有豐富準確的語義信息因此,如何充分使用醫學圖像特徵也是醫學多模態任務的關鍵之一。
6.綜上所述,如何通過自動生成標籤的方式減少大量人力標註,以及如何從有限的醫療語義信息中訓練出分割精度更準確的模型是當前計算機輔助醫療分割的重要難題,具有較高的研究意義和實際臨床應用價值。
技術實現要素:
7.本發明的目的就是為了克服上述現有技術存在的缺陷而提供一種面向ct影像的腫瘤分割方法及其系統,能夠高效準確生成標籤後進行模型訓練,從而解決全監督標註所產生的費時費力問題,提高分割任務的效率及準確性。
8.本發明的目的可以通過以下技術方案來實現:一種面向ct影像的腫瘤分割方法,包括以下步驟:
9.s1、獲取ct腫瘤圖像數據集:先將每個3d數據分成若干個2d數據,對2d 數據進行弱標註,並對所有的圖像進行預處理,之後將ct腫瘤圖像數據集劃分為訓練集和帶有真實標籤的測試集;
10.s2、邊緣提取:採用基於多尺度卷積的邊緣檢測網絡模型,從2d數據中提取圖像邊緣;
11.s3、自適應泛紅填充生成偽標籤:通過提取的邊緣、檢測框的位置,基於自適應泛洪填充和自適應梯度選取,獲得弱監督標籤;
12.s4、訓練分割模型:採用cnn和transformer的混合模型,並使用近似邊緣解碼器來細化結構,首先利用弱監督標籤進行第一輪訓練,經過三種損失函數的聯合損失函數進行修正結果;之後將修正結果作為第二輪訓練的標籤,訓練得到最終的分割模型;
13.s5、將實際待分割的ct腫瘤圖像預處理後輸入分割模型,輸出得到相應的分割結果。
14.進一步地,所述步驟s1中對2d數據進行弱標註的具體過程為:在2d數據上針對病灶區域,使用標註軟體在數據上點兩個點,用於分別指明此區域存在以及不存在腫瘤,以獲得相應的json文件。
15.進一步地,所述預處理的具體過程為:將圖像調整成統一的352
×
352尺寸,並作標準化處理。
16.進一步地,所述步驟s2具體是將預處理後的2d數據輸入多尺度邊緣檢測網絡模型,輸出得到邊緣特徵圖。
17.進一步地,所述步驟s3的具體過程為:
18.將邊緣特徵圖、json文件作為輸入,採用自適應泛洪填充來獲得偽標籤,其中,泛洪半徑設置為:
[0019][0020]
式中,i為輸入圖像,r(i)為輸入圖像i對應的掩碼半徑,hi和wi分別為輸入圖像的長度和寬度,γ為設定的超參數;
[0021]
此外,標註的ground truth為:
[0022][0023]
式中,sb和分別為背景像素和第i個標記的腫瘤對象的位置坐標;
[0024]
用於泛洪填充的圓掩模的集合定義為:
[0025][0026]
式中,c為使用下角標變量作為中心、使用上角標變量作為半徑的圓;
[0027]
之後結合邊緣特徵圖,將圖像分成多個連通的區域:
[0028]
[0029]
式中,f(i)為泛洪填充後獲得的連通區域,e(i)為邊緣特徵圖,e(
·
)表示邊緣檢測器,i為輸入圖像。
[0030]
進一步地,所述步驟s4中cnn和transformer的混合模型包括embedding部分、encoder部分和decoder部分,其中,embedding部分使用resnet來抽取3個stage的特徵圖,再基於transformer進行patch_embedding;
[0031]
encoder部分包括12個attentionencodeblock,每個block都依照visiontransformer的設定,即attention模塊和mlp模塊;
[0032]
decoder部分由兩個組件組成,一個visiontransformer(vit)解碼器和一個近似邊緣檢測器。
[0033]
進一步地,所述vit解碼器包括四個級聯卷積層,每層都有批處理歸一化(bn)層、relu激活層和上採樣層,以編碼器部分的特徵輸出作為輸入,並將各層解碼器的相應特徵表示為d={di|i=1,2,3,4}。
[0034]
進一步地,所述近似邊緣檢測器的輸出為:
[0035]
fe=σ(cat(r3,d2))
[0036]
其中,σ代表一個3
×
3的卷積層,該卷積層包括bn和relu層。
[0037]
進一步地,所述步驟s4中訓練過程具體為:
[0038]
第一輪訓練使用弱監督標籤進行訓練,訓練的輸入為:2d預處理之後的ct切片圖像、預處理之後的邊緣圖像以及ct圖像長寬對齊的弱標籤圖;
[0039]
模型訓練採用sgd優化器,學習率根據訓練epoch進行自適應衰減,每10個epoch進行一次衰減,衰減比率為0.1,並採用二元交叉熵損失、局部交叉熵損失和門控crf損失,對於邊緣解碼器分支,使用二元交叉熵損失來約束e:
[0040][0041]
其中,y為真實標籤,e表示邊緣圖,r和c表示圖像的行坐標和列坐標,而解碼器分支則使用局部交叉熵損失和門控crf損失,局部交叉熵損失設計的目的是讓模型只關注確定區域而忽略不確定區域:
[0042][0043]
其中,j表示標記區域,g表示groundtruth,s表示預測的腫瘤圖;
[0044]
門控crf損失為:
[0045][0046]
其中,ki為像素i周圍的k
×
k範圍所覆蓋的區域,d(i,j)定義為:
[0047]
d(i,j)=|s
i-sj|
[0048]
其中,si和sj為位置i和j處s的置信度值,|
·
|表示l1距離,f(i,j)為高斯核帶寬濾波器:
[0049][0050]
其中,為歸一化的權值,i(
·
)和pt(
·
)為像素的灰度值和像素的位置,σ
pt
和σi為控制高斯核尺度的超參數,由此定義總損失函數為:
[0051]
l
final
=α1l
bce
+α2l
pbce
+α3l
gcrf
[0052]
其中,α1,α2,α3分別為二元交叉熵損失、局部交叉熵損失和門控crf損失對應的權重;
[0053]
第二輪訓練使用第一輪訓練生成的新的修正標籤作為ground truth來監督模型,對其分割能力進行進一步優化,這種自監督的訓練方式可以有效地增強模型對醫療影像語義的理解,提升腫瘤的分割精度,將第二輪訓練後得到的模型作為最終的分割模型。
[0054]
一種面向ct影像的腫瘤分割系統,包括醫學圖像預處理模塊、邊緣檢測模塊、弱標籤生成模塊和cnn-vit混合分割模塊,所述圖像預處理模塊用於對ct影像圖像進行預處理,以及將醫學圖像數據集劃分為測試集和訓練集,將3d格式的數據轉化為2d數據;
[0055]
所述邊緣檢測模塊基於rcf網絡模型,通過多尺度卷積,並結合設定的閾值參數來獲取圖像的邊緣信息;
[0056]
所述弱標籤生成模塊採用點標註作為監督信號輸入,在邊緣圖像上通過自適應泛洪填充算法得到弱標籤;
[0057]
所述cnn-vit混合分割模塊採用混合embedding模式,並將邊緣加入解碼器,設置三種損失函數組合進行第一輪訓練,再使用第一輪生成的標籤作為新的監督訓練第二輪得到最終的分割模型。
[0058]
與現有技術相比,本發明提出一種面向ct影像的弱監督深度學習腫瘤分割方案,通過簡單的弱標註與邊緣檢測算法自動生成標籤,並且通過影像樣本和生成的標籤訓練分割模型,以對ct影像中的肺部腫瘤進行分割,無需人工對ct影像中的腫瘤目標進行逐像素的精細勾畫,即可省時省力自動生成粗標註以輔助分割模型進行訓練,解決了現有方法需要全監督標註帶來的費時費力問題,能夠高效準確地自動生成標籤,進而確保後續分割模型訓練的速度及準確度,提升分割任務的效率及準確性。
[0059]
本發明考慮到醫學實際問題和腫瘤ct圖像的特點,並沒有使用完整的勾畫標註作為模型訓練的監督信息,取而代之使用的是對於醫生標註起來更加簡易的點標註方式,通過獲取一定程度的邊緣信息,採用自適應泛洪填充來獲取偽標籤,從而完成弱監督標籤的生成,不僅限於ct腫瘤影像,這種弱監督的思路能夠廣泛應用到各種醫學場景任務中。
[0060]
本發明在訓練分割模型時,採用兩輪訓練方式,使用第一輪生成的標籤作為新的監督訓練第二輪得到最終的分割模型,並且在第一輪訓練時,提出了一種針對於醫學ct腫瘤分割任務的聯合損失函數——包括二元交叉熵損失、局部交叉熵損失和門控crf損失,使腫瘤部位和正常的部位更加容易被區分,即腫瘤和正常組織之間的差異被局部交叉熵損失拉開更遠的距離,而門控條件隨機場也能夠讓相對粗糙的弱標籤訓練出更好的結果,進而有效提高ct腫瘤分割任務的性能。
附圖說明
[0061]
圖1為本發明的方法流程示意圖;
[0062]
圖2為實施例中用於ct腫瘤影像分割任務的弱監督學習方法的流程圖;
[0063]
圖3是實施例中使用到的圖像組-標籤構成圖;
[0064]
圖4是實施例中編碼塊的結構圖;
[0065]
圖5是實施例中加入近似邊緣解碼器的結構圖。
具體實施方式
[0066]
下面結合附圖和具體實施例對本發明進行詳細說明。
[0067]
實施例
[0068]
如圖1所示,一種面向ct影像的腫瘤分割方法,包括以下步驟:
[0069]
s1、獲取ct腫瘤圖像數據集:先將每個3d數據分成若干個2d數據,對2d 數據進行弱標註,並對所有的圖像進行預處理,之後將ct腫瘤圖像數據集劃分為訓練集和帶有真實標籤的測試集;
[0070]
s2、邊緣提取:採用基於多尺度卷積的邊緣檢測網絡模型,從2d數據中提取圖像邊緣;
[0071]
s3、自適應泛紅填充生成偽標籤:通過提取的邊緣、檢測框的位置,基於自適應泛洪填充和自適應梯度選取,獲得弱監督標籤;
[0072]
s4、訓練分割模型:採用cnn和transformer的混合模型,並使用近似邊緣解碼器來細化結構,首先利用弱監督標籤進行第一輪訓練,經過三種損失函數的聯合損失函數進行修正結果;之後將修正結果作為第二輪訓練的標籤,訓練得到最終的分割模型;
[0073]
s5、將實際待分割的ct腫瘤圖像預處理後輸入分割模型,輸出得到相應的分割結果。
[0074]
本實施例應用上述技術方案,在構建分割模型時,如圖1所示,主要包括以下內容:
[0075]
(1)獲取帶有類別標籤的ct腫瘤圖像數據集,先將其中每個3d數據分成若干個2d數據,對2d數據進行弱標註,並將所有的圖像進行預處理,其中帶有類別標籤的用意是使用在測試部分,以對後續訓練後的模型進行評估。
[0076]
弱標註包括:在2d數據上對於病灶區域,使用labelme等簡易標註軟體在數據上點兩個點來分別指明此區域存在以及不存在腫瘤,從而獲得相應的json文件。
[0077]
本實施例中,使用luna16數據集中584個ct腫瘤圖像,同樣真實標籤用於測試。主要的圖像格式為mhd和raw格式。然後將圖像轉化為2d數據並進行標準化處理,將圖像裁剪為352
×
352大小,轉換為特徵向量供模型使用。
[0078]
(2)使用一個基於多尺度卷積的邊緣檢測網絡模型,用於提取融合多尺度信息的邊緣圖像。
[0079]
本實施例中,邊緣檢測模型採用的是rcf網絡,該網絡是基於vgg16構造了一個多尺度網絡。將卷積分為5個stage,相鄰兩個stage和一般的神經網絡模型類似地通過池化層來實現降採樣的功能,以達到將不同尺度特徵融合的效果。同時每個卷積層使用一個卷積核大小為1
×
1並且通道深度是21的卷積操作,然後將每個部分的輸出進行元素相加操作來得到一個複合特徵。接下來後面再加一個用於放大特徵圖尺寸的上採樣層。在每個上採樣
層後面使用一個交叉熵損失與sigmoid 層,然後所有的上採樣層的輸出進行concatenated形式的疊加,隨後使用一個1
×
1 的卷積對各個上採樣層的輸出進行融合,最後使用一個與上述相同的層得到輸出。
[0080]
具體過程為:獲取rcf網絡的公開模型,使用性能最好的checkpoint進行推理,數據格式為pth,採用多尺度推理模式,經過多次測試,[1.5,2,2.5]是一組較好的參數閾值,能達到較好的邊緣提取效果、同時對機器沒有過高的要求,在每個尺度進行推理之後將其疊加在一起,即得到最終的邊緣圖。
[0081]
(3)通過提取的多尺度邊緣、檢測框的位置,基於自適應泛洪填充和自適應梯度選取,獲得弱監督標籤。
[0082]
在步驟(1)中已經得到了每個圖像的帶有點標註信息的json文件,然後將邊緣圖像、json文件信息作為輸入,採用自適應泛洪填充來獲得偽標籤,泛洪半徑設置如下:
[0083][0084]
其中i為輸入圖像,r(i)為輸入圖像i對應的掩碼半徑。hi和wi分別表示輸入圖像的長度和寬度,γ表示超參數,可以在不同的任務中自行設置。
[0085]
本方法標註的ground truth表示為:
[0086][0087]
其中,sb和分別為背景像素和第i個標記的腫瘤對象的位置坐標。那麼用於泛洪填充的圓掩模的集合可以定義為:
[0088][0089]
其中,c表示使用下角標變量作為中心、使用上角標變量作為半徑的圓。對於步驟(2)中使用邊緣檢測器來檢測圖像的邊緣表示為:e(i),其中,e(
·
)表示邊緣檢測器,i表示輸入圖像,e表示生成的邊緣。通過上述定義的變量,將圖像分成多個連通的區域:
[0090][0091]
其中f(i)表示泛洪填充後獲得的連通區域,因此對於json文件中標註為前景標籤的點,本實施例中,採用γ=20,即圖像長寬較小者長度的1/20作為泛洪填充的半徑,對於背景的點,本實施例採用γ=8,即圖像長寬較小者的1/8作為泛洪填充的半徑。
[0092]
具體過程為:讀取邊緣圖像和帶有點標註的json文件,其中使用labelme進行標註的點是以字典的形式存放相應的信息,其中的「shape」欄位代表的就是點的信息,這個欄位中的數據是一個列表,列表中的每一個元素代表一個點。然後根據上述公式設置泛洪的半徑,以及rgb三個通道上阻止泛洪的像素值域,由於圖像原本是灰度圖,所以這三個通道設置相同的值即可,本實施例中採用的泛洪截斷像素值為(10,10,10),而每個數據中也包含一個「label」欄位,在本實施例中分為兩類,一類是腫瘤部位,例如將欄位定為「foreground」,反之正常部位則為「background」,分別進行兩次泛洪填充得到兩種圖像,一種是偽標籤圖,即只包含病灶區域的mask圖,還有一種是同時包含病灶點區域和正常點區域的mask的圖像,它的作用是進行局部交叉熵的損失計算。
[0093]
(4)訓練分割模型,採用cnn和transformer的混合模型,並且根據不同的預設參數,調節使用不同的embedding模型。
[0094]
在embedding部分,使用resnetv2來抽取3個stage的特徵圖(分別為stage 2,stage 3,stage 5),再基於vit進行patch embedding。
[0095]
接下來在encoder部分設計了12個attention encode block,每個block都依照 vit的設定,即attention模塊和mlp模塊。
[0096]
decoder部分由兩個組件組成,一個vit解碼器和一個近似邊緣檢測器,vit 解碼器是四個級聯卷積層,每層都有批處理歸一化層、relu激活層和上採樣層,以編碼器部分的特徵輸出作為輸入,並將各層解碼器的相應特徵表示為d= {di|i=1,2,3,4};此外,由於弱監督標註缺乏結構和細節,本技術方案設計了一個近似邊緣解碼器作為一個近似的邊緣檢測器來生成結構以克服這一缺點,具體來說,近似邊緣檢測器的輸出可以表示為fe=σ(cat(r3,d2)),其中σ代表一個3
×
3的卷積層,該卷積層包括歸一化和relu層,邊緣特徵圖e可以通過在fe之後添加一個 3
×
3卷積層得到,接著通過將fe與d3、cat(fe,d3)合併,並通過兩個卷積層,得到多通道特徵fs。類似於e,最後的單一通道特徵圖s也可以用同樣的方法得到。
[0097]
具體實施操作是操作為:首先根據需要設置bool變量來判斷是否使用混合模型,若使用則代表需要在transformer中需要訓練邊緣重構能力。那麼在patchembedding之前使用resnetv2預訓練模型抽取特徵,所抽取的特徵是resnetv2 的stage 2、3、5這三個特徵,作為解碼器的輸入之一。該部分的配置和resnetv2 的配置保持一致。在進行vit的部分中,patch大小採用的是16,embedding的維度採用的大小是768。encoder中也基本與常規的vit保持一致,本實施例使用12 個block組成encoder,同樣與常規的vit配置保持一致。
[0098]
(5)利用步驟(3)中的弱監督方式得到的標籤,進行步驟(4)中的模型第一輪訓練,訓練的輸入為:2d預處理之後的ct切片圖像、預處理之後的邊緣圖像以及和ct圖像長寬對齊的弱標籤圖。本技術方案中,採用二元交叉熵損失、局部交叉熵損失和門控crf損失構造聯合損失函數。對於邊緣解碼器分支,使用二值交叉熵損失來約束e:
[0099][0100]
其中y為真實標籤,e表示邊緣圖,r和c表示圖像的行坐標和列坐標。而解碼器分支則使用了局部交叉熵損失和門控crf損失。部分二元交叉熵損失設計的目的是讓模型只關注確定區域而忽略不確定區域:
[0101][0102]
其中j表示標記區域,g表示ground truth,s表示預測的腫瘤圖。為了儘可能學習更好的對象結構,在損失函數中還使用門控crf:
[0103][0104]
其中ki為像素i周圍的k
×
k範圍所覆蓋的區域,d(i,j)定義為:
[0105]
d(i,j)=|s
i-sj|
[0106]
其中si和sj為位置i和j處s的置信度值,|
·
|表示l1距離。f(i,j)為高斯核帶寬濾波器:
[0107][0108]
其中為歸一化的權值,i(
·
)和pt(
·
)為像素的灰度值和像素的位置,σ
pt
和σi為控制高斯核尺度的超參數。所以總損失函數定義為:
[0109]
l
final
=α1l
bce
+α2l
pbce
+α3l
gcrf
[0110]
其中,α1,α2,α3是三個損失函數對應的權重。本實施例中,均設置為1。
[0111]
具體實施如下:將原圖、只包含腫瘤部位弱標籤、包含腫瘤和正常部位的弱標籤、邊緣圖作為輸入,並將其均轉成352
×
352的大小的tensor形式變量。初始化網絡之後,第一輪訓練的參數配置分別是:batch size為32,優化器使用sgd優化器,初始學習率為0.01,動量為0.9,初始衰減率為0.1,每10個epoch進行一次衰減更改,設置衰減最低下降到5
×
10-4
,訓練長度為100個epoch。
[0112]
圖2是本實施例中數據中的圖像組-標籤對構成示意圖。其中,原圖是基於 luna16數據集的mhd格式數據,可視化結果如圖,所示的第二張是預處理的示意圖,將肺部的主要部分切分出來而捨棄其他冗餘的部分。所示的第三張圖是邊緣圖的示意圖,通過邊緣檢測網絡得到的邊緣圖大致如此,該邊緣圖既用於自適應泛洪填充,又用於監督近似邊緣解碼器的重結果的過程。最後一張圖就是本實施例的點監督標註的示意圖,對於標記為病灶或者腫瘤的部位點為第一種顏色點,另外將正常的非病灶區域位置隨機的點,在圖上表示為第二種顏色點。
[0113]
圖3是本實施例中transformer編碼塊的結構圖。將通過embedding之後的特徵表示f0,輸入到混合模型的transformer的中,如圖3所示。其中為了抑制下遊任務的過擬合,在多頭注意力層和前饋神經網絡層前新增了歸一化操作。多頭注意力層是為了識別不同的模式,設計的多個注意力來學習不同的投影方法。前饋神經網絡層(feed forward network),簡稱ffn,ffn的結構如下:
[0114]
ffn(hi)=gelu(hiw1+b1)w2+b2[0115]
其中,hi是隱藏層的向量。w1,b1,w2,b2是ffn的參數,gelu為激活函數。如圖3所示,在整個模型中該模塊被堆疊了12次,embedding之後的f0作為編碼器的第一次輸入,輸出為f1,以此類推,最終構成該模型的編碼器。
[0116]
圖4是本發明的實施例中加入近似邊緣解碼器的結構圖。近似邊緣檢測器的輸出可以表示為fe=σ(cat(r3,d2)),其中σ代表一個3
×
3的卷積層,該卷積層包括 bn和relu層,將之前得到的邊緣圖作為監督。最後的邊緣特徵圖e可以通過在 fe之後添加一個3
×
3卷積層得到,接著通過將fe與d3以cat(fe,d3)的形式合併,並通過兩個卷積層,得到多通道特徵fs。類似於e,最後添加對應的卷積層來得到單一通道特徵圖s。
[0117]
可以看出,本技術方案充分考慮醫學實際問題和腫瘤ct圖像的特點,並沒有使用完整的勾畫標註作為模型訓練的監督信息,取而代之使用的是對於醫生標註起來更加簡易的點標註,隨即而來的就是損失一些精細的結構信息。然而本技術方案在加入近似邊緣解
碼器之後,就能夠逐步將病灶位置的相關結構細化,此外本技術方案還提出了一種針對於醫學腫瘤分割任務的聯合損失函數,使腫瘤部位和正常的部位可以更加容易被區分,即腫瘤和正常組織之間的差異被局部交叉熵損失拉開更遠的距離,而門控條件隨機場也可以讓相對粗糙的弱標籤訓練的更好,進而為ct 腫瘤分割任務帶來一定程度的性能提升。
[0118]
本實施例還提供了一種面向ct影像的腫瘤分割系統,包括:
[0119]
醫學圖像預處理模塊,利用上述步驟(1)中的方法進行醫學圖像預處理;
[0120]
邊緣檢測模塊,利用上述步驟(2)中的方法進行邊緣檢測,得到的結果將用於自適應泛洪填充和監督近似邊緣解碼器。
[0121]
弱標籤生成模塊,利用上述步驟(3)中的方法,只需要點標註作為監督信號輸入,在邊緣圖像上通過自適應泛洪填充算法即可得到弱標籤,該弱標籤作用於模型第一次訓練。
[0122]
cnn-vit混合分割模塊,利用上述步驟(4)~(5)中的方法,分割網絡模型採用混合embedding模式,並將邊緣加入解碼器,設置三種損失函數組合進行訓練。再使用第一輪生成的標籤作為新的監督訓練第二輪得到最終的分割模型。
[0123]
綜上可知,本技術方案為實現高效準確的分割任務,首先獲取ct腫瘤圖像數據集,先將其每個3d數據分成若干個2d數據,對此數據進行弱標註,並將所有的圖像進行預處理,同時將ct影像數據集劃分為測試集和訓練集;之後預訓練一個基於多尺度卷積的邊緣檢測網絡模型,用於提取多尺度邊緣,獲得相應的醫學語義級的邊緣;再通過提取的多尺度邊緣、檢測框的位置,基於自適應泛洪填充和自適應梯度選取,獲得弱監督標籤;最後訓練分割模型,採用cnn和transformer 的混合模型,並且根據不同的數據,調節使用不同的模型;一方面將弱監督標籤進行第一輪訓練經過條件隨機場等聯合損失函數修正結果;另一方面使用修正結果作為第二輪訓練的標籤訓練得到最終的分割模型。
[0124]
由此,本技術方案適用於在計算機輔助診療場景下,自動生成可訓練的偽標籤並建立面向ct影像的腫瘤分割模型,能夠很好地用於臨床腫瘤分割任務。本技術方案無需人工對ct影像中的腫瘤目標進行逐像素的精細勾畫,而使用省時省力的自動生成的粗標註幫助分割模型進行訓練。同時本技術方案具有較高的適應性,對於現階段流行的卷積神經網絡模型和transformer模型均可實現快速部署。本技術方案不僅能夠減少大量人力標註,同時也能從有限的醫療語義信息中訓練出分割精度更準確的模型,從而確保分割任務的效率和準確性。