一種高招大本數據採集系統及方法與流程
2023-10-11 15:41:34 7
本發明涉及一種數據採集方法,更具體的,涉及一種高招大本數據採集系統及方法。
背景技術:
在普通高校的招生過程中,考生填報志願不僅關係著能否被高校錄取,更為重要的是:填志願時選擇專業、學校內在地規定了學生未來的學業及職業發展路線及發展狀態。通常所說的考生志願,指考生所選報的院校和專業,是考生的志向、願望、愛好、個性和能力等因素的綜合反映。而其中往年錄取數據是考生在填報學校時的最重要的依據,這關係著考生是否能夠考生該所學校。
通常情況下,各省都會派發對應的《高考填報指南》,其中就包含著該省往年的所有學校的錄取數據。但這類書籍頁數多,數據量大,考生在翻閱該書籍時難以快速準確捕獲自己所需要的信息,因此將該類書籍數據電子化有其必要性。
目前主流的將書籍數據電子化的方式是人工錄入,但這種方式耗費時間較長,且因有非常重的人工幹預的成分,難以保證數據的準確性和完整性。從2016年開始,高招大本的書籍出版都很晚,將數據電子化需要在非常短的時間內完成,否則失去意義。所以全、準、快是錄入高招大本數據的基本原則,顯然人工錄入的方式並不能達成這三項標準。
技術實現要素:
本發明旨在至少解決現有技術中存在的技術問題之一。
為此,本發明的目的在於,提供一種快捷、流程化的數據採集方法處理高招大本數據,避免數據的缺失,保證其準確性,幫助考生便捷地查看往年錄取數據。
為實現上述目的,本發明提供了一種一種高招大本數據採集方法,包括如下步驟:
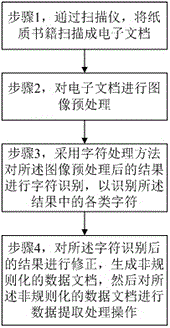
步驟1,通過掃描儀,將紙質書籍掃描成電子文檔;
步驟2,對電子文檔進行圖像預處理;
步驟3,採用字符處理方法對所述圖像預處理後的結果進行字符識別,以識別所述結果中的各類字符;
步驟4,對所述字符識別後的結果進行修正,生成非規則化的數據文檔,然後對所述非規則化的數據文檔進行數據提取處理操作。
本發明還提供了一種高招大本數據採集系統,該系更具體的,所述步驟2中對電子文檔進行圖像預處理包括:
步驟1.1,圖像二值化處理,採用閾值分割技術,設定灰度閾值,若圖像像素點灰度值大於或等於所述閾值,則被判定為屬於某一特定區域,用 255 表示其灰度值,否則,像素點將被排除在特定區域之外而被判定為背景或其他無用區域,用0表示其灰度值;
步驟1.2,圖像增強處理,通過基於空間域的增強和基於頻率域的增強處理方法,以減少所獲取圖像的小的空間改變;
步驟1.3,噪聲處理,使用濾波器對所述圖像增強處理後的結果進行濾波,去除噪聲。
更具體的,所述步驟3中的字符識別包括:
步驟3.1,漢字字符識別:採用水平方向上、豎直方向上、45度角方向、反45度角方向4個特定方向上的矢量準確地描述出一個漢字的基本字形特徵;
步驟3.2,英文字符識別:採用基於字符結構的方法對字符進行識別,根據字符在水平方向、豎直方向、筆畫的特點,對字符進行逐級的分類,形成一顆判定樹,每個字符就是一個葉子,依據字符自身的結構特徵進行逼近識別;
步驟3.3,阿拉伯數字識別:先計算歐拉數,再提取凹陷區的特徵,最後根據特徵組合識別字符。
更具體的,所述步驟4中的對識別後的結果進行修正包括:
利用上下文信息、語法及邏輯,對識別的結果進行修正,生成非規則化的數據文檔。
更具體的,所述步驟4中對所述非規則化的數據文檔進行數據提取處理操作包括:
步驟4.1,把非規則化的數據文檔按照文件名的規則順序處理,把表格的行轉換為普通文本格式的行;
步驟4.2,查看轉換出來的文本格式,確定分割條件,分割的條件包括:文理科段落的區分、各個院校段落的區分、院校下各個專業段落的區分條件;
步驟4.3,分別提取所述步驟4.2中的各個所述的段落,合併斷行和上下文回溯;
步驟4.4,通過所述步驟4.3得到一個相對規格化的段落的數據文本後,再針對步驟4.2中的各類具體情況提取需要的信息;
步驟4.5,對步驟4.4得到的信息結果做合併,把某些可能混合在其它段落中的信息作預設的上下文推斷填充,至此完成數據提取處理操作。
本發明還提供了一種高招大本數據採集系統,該系統包括書籍掃描模塊、圖像預處理模塊、字符識別模塊、修正模塊,其中,
書籍掃描模塊,用於通過掃描儀,將紙質書籍掃描成電子文檔;
圖像預處理模塊,用於對電子文檔進行圖像預處理;
字符識別模塊,採用字符處理方法對所述圖像預處理後的結果進行字符識別,以識別所述結果中的各類字符;
修正模塊,用於所述對字符識別後的結果進行修正,生成非規則化的數據文檔,然後所述對非規則化的數據文檔進行數據提取處理操作。
更具體的,所述圖像預處理模塊包括:圖像二值化模塊,採用閾值分割技術,設定灰度閾值,若圖像像素點灰度值大於或等於所述閾值,則被判定為屬於某一特定區域,用 255 表示其灰度值,否則,像素點將被排除在特定區域之外而被判定為背景或其他無用區域,用0表示其灰度值;
圖像增強模塊,通過基於空間域的增強和基於頻率域的增強處理方法,以減少所獲取圖像的小的空間改變;
噪聲處理模塊,使用濾波器對圖像進行濾波,去除噪聲。
更具體的,所述字符識別模塊包括:
漢字字符識別模塊:採用水平方向上、豎直方向上、45度角方向、反45度角方向4個特定方向上的矢量準確地描述出一個漢字的基本字形特徵;
英文字符識別模塊:採用基於字符結構的方法對字符進行識別,根據字符在水平方向、豎直方向、筆畫的特點,對字符進行逐級的分類,形成一顆判定樹,每個字符就是一個葉子,依據字符自身的結構特徵進行逼近識別;
阿拉伯數字識別模塊:先計算歐拉數,再提取凹陷區的特徵,最後根據特徵組合識別字符。
更具體的,所述修正模塊包括非規則化數據文檔生成模塊和數據提取處理模塊,其中,
非規則化數據文檔生成模塊,利用上下文信息、語法及邏輯,對字符識別的結果進行修正,生成非規則化的數據文檔;
數據提取處理模塊,用於對所述非規則化的數據文檔進行文理、院校、專業等的提取和合併處理操作。
更具體的,所述數據提取處理模塊具體還包括順序處理模塊、分割模塊、合併斷行和上下文回溯模塊、信息提取模塊、合併模塊,其中,
順序處理模塊,把非規則化的數據文檔按照文件名的規則順序處理,把表格的行轉換為普通文本格式的行;
分割模塊,查看轉換出來的文本格式,確定分割條件,分割的條件包括:文理科段落的區分、各個院校段落的區分、院校下各個專業段落的區分條件;
合併斷行和上下文回溯模塊,分別提取分割模塊中分割後的所述的段落,進行合併斷行和上下文回溯操作;
信息提取模塊,通過所述合併斷行和上下文回溯模塊操作得到一個相對規格化的段落的數據文本後,再針對所述分割模塊中的各類具體情況提取需要的信息;
合併模塊,對信息提取模塊中得到的信息結果做合併,把某些可能混合在其它段落中的信息作預設的上下文推斷填充,完成數據提取處理操作。
本發明的高招大本數據採集方法採用OCR (Optical Character Recognition,光學字符識別)文字識別和非規則文本提取的形式,將書籍數據快速電子化,提高了效率,降低了成本,且避免了人為的錯誤。
本發明與現有的人工錄入數據相比,本發明具有如下有益技術效果:(1)通過自動化代替手工,相比於人工錄入,本發明大大降低了人工操作的成本,避免了重複的勞動力;(2)提高效率;通過自動化處理的方式,有效地減少了時間成本,且保證了數據的準確性和完整性;(3)數據ETL化;通過將高招大本的數據進行抽取、轉換、加載的處理,變成預先定義好的數據倉庫模型,最大化地利用已存在的數據資源,節省了大量時間和資金。
本發明的附加方面和優點將在下面的描述部分中給出,部分將從下面的描述中變得明顯,或通過本發明的實踐了解到。
附圖說明
本發明的上述和/或附加的方面和優點從結合下面附圖對實施例的描述中將變得明顯和容易理解,其中:
圖1示出了根據本發明一種高招大本數據採集方法的流程圖;
圖2示出了對非規則化的數據文檔進行數據提取處理操作方法流程圖;
圖3示出了本發明一實施例的一種高招大本數據採集方法流程圖;
圖4示出了根據本發明一種高招大本數據採集系統的整體系統框圖。
具體實施方式
為了能夠更清楚地理解本發明的上述目的、特徵和優點,下面結合附圖和具體實施方式對本發明進行進一步的詳細描述。需要說明的是,在不衝突的情況下,本申請的實施例及實施例中的特徵可以相互組合。
在下面的描述中闡述了很多具體細節以便於充分理解本發明,但是,本發明還可以採用其他不同於在此描述的方式來實施,因此,本發明的保護範圍並不受下面公開的具體實施例的限制。
為實現上述的發明目的,本發明主要通過如下幾點實現:
一、將文件錄入,通過掃描儀掃描為電子文檔,如將高招大本書籍掃描成PDF文檔。
二、對電子文檔通過圖像二值化處理、圖像增強處理及噪聲處理等進行圖像預處理。
三、採用字符處理方法對所述圖像預處理後的結果進行字符識別,以識別所述結果中的各類字符。
四、對所述字符識別後的結果進行修正,生成非規則化的數據文檔,然後對所述非規則化的數據文檔進行數據提取處理操作。
為了更好的說明本發明的方案,下面將結合說明書附圖進行說明。
圖1示出了根據本發明一種高招大本數據採集方法的流程圖。
如圖1所示,根據本發明的一種高招大本數據採集方法,包括:
步驟1,通過掃描儀,將紙質書籍掃描成電子文檔;
步驟2,對電子文檔進行圖像預處理;
步驟3,採用字符處理方法對所述圖像預處理後的結果進行字符識別,以識別所述結果中的各類字符;
步驟4,對所述字符識別後的結果進行修正,生成非規則化的數據文檔,然後對所述非規則化的數據文檔進行數據提取處理操作。
具體的,步驟1中的文件錄入操作,如將高招大本書籍掃描成PDF文檔。
更具體的,所述步驟2中對電子文檔進行圖像預處理包括:
步驟1.1,圖像二值化處理,採用閾值分割技術,設定灰度閾值,若圖像像素點灰度值大於或等於所述閾值,則被判定為屬於某一特定區域,用 255 表示其灰度值,否則,像素點將被排除在特定區域之外而被判定為背景或其他無用區域,用0表示其灰度值。
圖像二值化擅長處理物體與背景具有較強對比度的圖像分割,計算簡單,能夠用封閉、連通的邊界區分出不交疊的區域。列印或手寫的文檔一般背景與字符的差別較大,適合於進行二值化處理,可以直接設定閾值進行二值化。
步驟1.2,圖像增強處理,通過基於空間域的增強和基於頻率域的增強處理方法,以減少所獲取圖像的小的空間改變;
空間域的增強通過減少圖像採集系統產生的偽跡來改善圖像的完整性。雖然圖像可能是原始圖像的扭曲變形,感興趣區域通常因為它的高對比度特點而保持完好。通過灰度圖像展現的噪聲可以被視為像素值相對於原始值的小的隨機變化,這個步驟一般能夠減少獲取圖像的小的空間改變。
步驟1.3,噪聲處理,如使用高斯平滑濾波器對所述圖像增強處理後的結果進行濾波,去除噪聲。
更具體的,所述步驟3中的字符識別包括:
步驟3.1,漢字字符識別:採用水平方向上、豎直方向上、45度角方向、反45度角方向4個特定方向上的矢量準確地描述出一個漢字的基本字形特徵。
在漢字的基本筆畫裡,採用水平方向上、豎直方向上、45度角方向、反45度角方向4個特定方向上的矢量,他們能很好地對應於標準的橫線和豎線,也能比較好的反映出撇和捺的特徵。另一方面,由於除了點以外的其他基本筆畫也可以看成是由這四個基本筆畫所組合而成的,所以這四個方向上的矢量就可以相當準確地描述出一個漢字的基本字形特徵。
步驟3.2,英文字符識別:採用基於字符結構的方法對字符進行識別,根據字符在水平方向、豎直方向、筆畫的特點,對字符進行逐級的分類,形成一顆判定樹,每個字符就是一個葉子,依據字符自身的結構特徵進行逼近識別。
字符結構在水平方向上有三種類型:左右對稱,左大右小,左小右大;豎直方向上也有三種類型:上下對稱,上大下小,上小下大。筆畫也有兩大類:直筆畫和弧筆畫,直筆畫又可分為橫筆畫、豎筆畫、左斜筆畫;弧筆畫是一條曲線段,可分為兩類:開弧筆畫和閉弧筆畫。所謂開弧筆畫,指該弧筆畫沒有形成封閉環,如字母「C」。根據字符的這些特點,可以對字母進行逐級的分類,形成一顆判定樹,每個字符就是一個葉子。這種方法不需要對分割得到的字符進行大小歸一化,也不需要建立樣本庫,完全依據字符自身的結構特徵進行逼近識別。
步驟3.3,阿拉伯數字識別:先計算歐拉數,再提取凹陷區的特徵,最後根據特徵組合識別字符。
歐拉數是一種應用廣泛的對物體進行識別的特徵,定義為連同成分數減去洞數,E=C-H,其中E、C和H分別為歐拉數、連同成分數和洞數。
更具體的,所述步驟4中的對識別後的結果進行修正包括:
利用上下文信息、語法及邏輯,對識別的結果進行修正,生成非規則化的數據文檔。
識別結束後,由於不同文檔的清晰度不同,其識別後的結果可能會有較大差別,利用上下文信息、語法及邏輯,對識別的結果進行修正,往往能改善和提高系統的整體性能。修正處理結束後,非規則化的數據文檔即可生成。
更具體的,圖2示出了所述步驟4中對所述非規則化的數據文檔進行數據提取處理操作方法流程圖。
如圖2所示,步驟包括:
步驟4.1,把非規則化的數據文檔按照文件名的規則(省份、頁碼)順序處理,把表格的行轉換為普通文本格式的行;
步驟4.2,查看轉換出來的文本格式,確定分割條件,分割的條件包括:文理科段落的區分、各個院校段落的區分、院校下各個專業段落的區分條件;
步驟4.3,分別提取所述步驟4.2中的各個所述的段落,合併斷行和上下文回溯。比如文理段落可能是在原來紙質書籍上的居中部分,在進行OCR識別時該部分數據可能會插到院校或者專業段落,這個需要回溯或區分。
步驟4.4,通過所述步驟4.3得到一個相對規格化的段落的數據文本後,再針對步驟4.2中的各類具體情況提取需要的信息;
步驟4.5,對步驟4.4得到的信息結果做合併,把某些可能混合在其它段落中的信息作預設的上下文推斷填充,如學費/學制等信息有可能一部分在院校段落,一部分在專業段落,因此需要做預設的上下文推斷填充,至此完成處理工作至此完成數據提取處理操作。
圖3示出了本發明一實施例的一種高招大本數據採集方法流程圖。
如圖3所示,首先,將高招大本書籍掃描成PDF文檔;對PDF文檔進行二值化、圖像增強、噪聲處理圖像預處理;進行字符識別,其中分為漢字字符識別、英文字符識別、阿拉伯數字識別處理;利用上下文信息、語法及邏輯,對字符識別的結果進行修正,生成非規則化的數據文檔,然後對所述非規則化的數據文檔進行數據提取處理操作。
圖4示出了本發明一種高招大本數據採集系統的整體系統框圖。
如圖4所示,該系統包括:書籍掃描模塊、圖像預處理模塊、字符識別模塊、修正模塊,其中,
書籍掃描模塊,用於通過掃描儀,將紙質書籍掃描成電子文檔;
圖像預處理模塊,用於對電子文檔進行圖像預處理;
字符識別模塊,採用字符處理方法對所述圖像預處理後的結果進行字符識別,以識別所述結果中的各類字符;
修正模塊,用於所述對字符識別後的結果進行修正,生成非規則化的數據文檔,然後所述對非規則化的數據文檔進行數據提取處理操作。
更具體的,所述圖像預處理模塊包括:圖像二值化模塊,採用閾值分割技術,設定灰度閾值,若圖像像素點灰度值大於或等於所述閾值,則被判定為屬於某一特定區域,用 255 表示其灰度值,否則,像素點將被排除在特定區域之外而被判定為背景或其他無用區域,用0表示其灰度值;
圖像增強模塊,通過基於空間域的增強和基於頻率域的增強處理方法,以減少所獲取圖像的小的空間改變;
噪聲處理模塊,使用濾波器對圖像進行濾波,去除噪聲。
更具體的,所述字符識別模塊包括:
漢字字符識別模塊:採用水平方向上、豎直方向上、45度角方向、反45度角方向4個特定方向上的矢量準確地描述出一個漢字的基本字形特徵;
英文字符識別模塊:採用基於字符結構的方法對字符進行識別,根據字符在水平方向、豎直方向、筆畫的特點,對字符進行逐級的分類,形成一顆判定樹,每個字符就是一個葉子,依據字符自身的結構特徵進行逼近識別;
阿拉伯數字識別模塊:先計算歐拉數,再提取凹陷區的特徵,最後根據特徵組合識別字符。
更具體的,所述修正模塊包括非規則化數據文檔生成模塊和數據提取處理模塊,其中,
非規則化數據文檔生成模塊,利用上下文信息、語法及邏輯,對字符識別的結果進行修正,生成非規則化的數據文檔;
數據提取處理模塊,用於對所述非規則化的數據文檔進行文理、院校、專業等的提取和合併處理操作。
更具體的,所述數據提取處理模塊具體還包括順序處理模塊、分割模塊、合併斷行和上下文回溯模塊、信息提取模塊、合併模塊,其中,
順序處理模塊,把非規則化的數據文檔按照文件名的規則順序處理,把表格的行轉換為普通文本格式的行;
分割模塊,查看轉換出來的文本格式,確定分割條件,分割的條件包括:文理科段落的區分、各個院校段落的區分、院校下各個專業段落的區分條件;
合併斷行和上下文回溯模塊,分別提取分割模塊中分割後的所述的段落,進行合併斷行和上下文回溯操作;
信息提取模塊,通過所述合併斷行和上下文回溯模塊操作得到一個相對規格化的段落的數據文本後,再針對所述分割模塊中的各類具體情況提取需要的信息;
合併模塊,對信息提取模塊中得到的信息結果做合併,把某些可能混合在其它段落中的信息作預設的上下文推斷填充,完成數據提取處理操作。
本發明的高招大本數據採集方法採用OCR (Optical Character Recognition,光學字符識別)文字識別和非規則文本提取的形式,將書籍數據快速電子化,提高了效率,降低了成本,且避免了人為的錯誤。
以一本500頁的高招大本的數據為例,按照一個人一個小時錄入一頁的速度計算,需要500小時的工作量。而採用本發明的技術方案,主要時間將花在OCR識別過程上,大概只需不到40小時的時間,即可完成數據的入庫工作。因此本發明對於資源的節約有著明顯的作用。
本專利可應用各種複雜的數據採集錄入操作,在任何需要將書籍錄入為電子化應用場景下都可以使用。
以上所述僅為本發明的優選實施例而已,並不用於限制本發明,對於本領域的技術人員來說,本發明可以有各種更改和變化。凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護範圍之內。