引力搜索RNA‑GA的催化裂化主分餾塔神經網絡建模方法與流程
2023-12-09 11:12:56 5
本發明屬於化工過程控制領域,具體涉及一種引力搜索rna-ga的催化裂化主分餾塔神經網絡建模方法。
背景技術:
催化裂化是石油煉製的重要生產過程之一,是在熱和催化劑的作用下使重油發生裂化反應,轉變為裂化氣、汽油和柴油等的生產過程。催化裂化主分餾塔作為催化裂化裝置的主分離設備是實現產品分離的關鍵單元,是催化裂化過程中重要的一環。建立精確的催化裂化主分餾塔模型有助於實現流化催化裂化裝置的先進控制與優化,同時對於降低催化裂化裝置能耗和提高產品質量具有重要的意義。
由於催化裂化主分餾塔是一個具有滯後和耦合的非線性系統,傳統的機理建模方法難以滿足高精度建模的需要,因此神經網絡受到人們的關注。神經網絡是模擬大腦神經突觸聯接的結構進行信息處理的計算模型,具有逼近任意非線性函數的能力。但是神經網絡也存在易於陷入局部極小、收斂速度慢等問題。
本發明提出一種引力搜索rna遺傳算法(rna-ga),在rna-ga中加入基於萬有引力定律和牛頓第二定律的引力搜索操作,並將引力搜索rna遺傳算法用於催化裂化主分餾塔的神經網絡建模,取得了較理想的效果,該方法也適用於其他複雜非線性系統的建模。
技術實現要素:
本發明針對現有技術的不足,提出了一種引力搜索rna-ga的催化裂化主分餾塔神經網絡建模方法
引力搜索rna-ga的催化裂化主分餾塔神經網絡建模方法,它的步驟如下:
步驟1:獲得催化裂化主分餾塔的輸入輸出數據作為樣本數據,其中輸入數據為頂循流量q1、一中流量q2和二中流量q3,輸出數據為塔頂溫度t1、粗汽油幹點t2和輕柴油傾點t3;
步驟2:建立催化裂化主分餾塔rbf神經網絡模型,模型採用一個三層rbf神經網絡結構;
設定t為採樣時刻,q1(t)、q2(t)和q3(t)分別為t時刻的頂循流量、一中流量和二中流量數據,t1(t)、t2(t)和t3(t)分別為t時刻的塔頂溫度、粗汽油幹點和輕柴油傾點數值,rbf神經網絡模型輸入變量個數為nin,輸入向量x為
[q1(t)q2(t)q3(t)t1(t-1)t1(t-2)…t1(t-n)t2(t-1)t2(t-2)…t2(t-n)t3(t-1)t3(t-2)…t3(t-n)]
其中n為整數,設定n=3n+3,輸出變量個數為nout=3,輸出變量為[t1(t)t2(t)t3(t)],從輸入層到輸出層映射可用以下函數表示:
其中x為輸入向量,||·||表示歐幾裡得範數,d表示隱層數,w1(i)、w2(i)和w3(i)分別是神經網絡輸出結點權值向量中的第i個分量,由遞推最小二乘法確定;ci是神經網絡第i個隱層的徑向基函數中心向量,徑向基函數φ(·)採用薄板樣條函數,表示為:
φ(v)=v2ln(v)
其中v表示任意數;
步驟3:選擇樣本數據中的一部分數據作為訓練樣本,將數據輸入到步驟2建立的rbf神經網絡模型中;
步驟4:設置建立的rbf神經網絡模型中的徑向基函數中心;
步驟5:利用引力搜索rna遺傳算法對步驟2建立的rbf神經網絡模型的徑向基函數中心進行尋優,獲得rbf神經網絡的徑向基函數中心的最優解;
步驟6:利用步驟5獲得的最優解作為催化裂化主分餾塔神經網絡模型徑向基函數中心,並利用測試樣本檢驗神經網絡模型。
催化裂化主分餾塔的輸入輸出數據可通過現場採集或實驗獲得。
上述步驟5可採用如下具體步驟實現:
步驟5.1:設定引力搜索rna-ga的參數,包括:種群數s、輸入變量個數n、個體編碼長度l、最大迭代次數gmax、轉位換位概率pc、置換交叉概率pt、自適應變異概率pml和pmh;設定引力搜索rna-ga終止規則為:引力搜索rna-ga迭代次數達到最大迭代次數gmax;
步驟5.2:對神經網絡模型的徑向基函數中心進行鹼基編碼,隨機生成一個初始種群,種群中包含s個個體,每個參數均由字符集{0,1,2,3}編碼為一個長度為l的rna子序列,rbf神經網絡模型的參數有n×d個,一個rna序列的編碼長度為n×d×l,每個個體代表的參數如下:
其中c(i)表示第i個個體,cd,n表示個體中第d個隱層對應的神經網絡徑向基函數中心向量中的第n個分量;
步驟5.3:將種群中每個rna序列解碼為rbf神經網絡模型的參數,並採用最小二乘法計算出相應的神經網絡輸出結點權值向量,將不同時刻催化裂化主分餾塔神經網絡模型的輸出值和與催化裂化主分餾塔的實際輸出值t1、t2和t3的誤差絕對值之和作為引力搜索rna-ga的催化裂化主分餾塔神經網絡模型參數尋優的適應度函數,表示為:
式中和分別表示第j組模型輸出的塔頂溫度、粗汽油幹點和輕柴油傾點數值,t1(j)、t2(j)和t3(j)則為第j組塔頂溫度、粗汽油幹點和輕柴油傾點數據實際數值,nt是樣本數據個數;
步驟5.4:根據適應度函數值,利用輪盤賭法來選擇個體,並利用適應度函數值選擇適應度函數值最優的s/2個個體組成的中性個體集合en與適應度函數值最差的s/2個個體組成的有害個體集合ed構成新的種群e;
步驟5.5:在中性個體集合en中,以轉位換位概率pc執行相應的轉位操作或換位操作,產生有s/2個個體的集合ec1,具體操作步驟為:
1)在0~1之間隨機選擇一個數h,若h小於概率pc時,進行轉位操作;
2)當h大於等於概率pc時,進行換位操作;
步驟5.6:在中性個體集合en中,以置換交叉概率pt執行置換操作,產生s/2個個體,集合為ec2;
步驟5.7:在集合[ec1;ec2;ed]中,以高位變異概率pmh和低位變異概率pml執行自適應變異操作,得到集合e2,其中自適應變異概率為:
其中,a1是初始變異概率,b1為變異概率變化範圍,aa為變異速率,g為當前進化代數,g0為轉折點;
步驟5.8:在集合e2中找出適應度函數值最優的個體bests;
步驟5.9:檢查迭代次數是否達到終止條件,若滿足要求則獲得神經網絡徑向基函數中心,否則到步驟5.10;
步驟5.10:將集合e2進行引力搜索,得到新的種群,回到步驟5.3,進行下一輪迭代。
上述步驟5.10中引力搜索可採用如下具體步驟實現:
1)計算每個個體對應的質量,計算公式如下:
其中m表示個體的質量,worst表示種群中最差個體的適應度函數值,best表示種群中最優個體的適應度函數值,f表示該個體的適應度函數值;
2)計算引力常數,計算公式如下:
其中g0=100,α=20,g表示當前迭代次數,gmax表示最大迭代次數,g為引力常數,e是自然常數;
3)計算引力加速度
其中,ai,k為第i個個體的第k個隱節點對應的引力加速度向量,g為當前迭代中的引力常數,rand為0~1的隨機數向量,mj是第j個個體對應的質量,表示對應元素相乘,eps為非0常數,ei,k和ej,k分別為第i個個體和第j個個體第k個隱節點對應的向量,rk表示第i個個體與第j個個體對應第k個隱節點的歐幾裡得範數,表示為:
rk=||ei,k-ej,k||
4)根據加速度和初始速度,每次迭代記為一次移動,由此獲得新種群,相關計算公式如下:
e′=e+v
v′表示新的速度矩陣,v表示速度矩陣,rn為隨機數矩陣,a表示加速度矩陣,e為種群,e′表示為新的種群。
本發明利用引力搜索rna遺傳算法對催化裂化主分餾塔神經網絡模型的徑向基函數中心進行尋優,獲得催化裂化主分餾塔的神經網絡模型。後續實施例中數據也表明該建模方法在實際使用時能取得理想的效果,該方法不僅適用於催化裂化主分餾塔,也可用於其他複雜系統的建模。
附圖說明
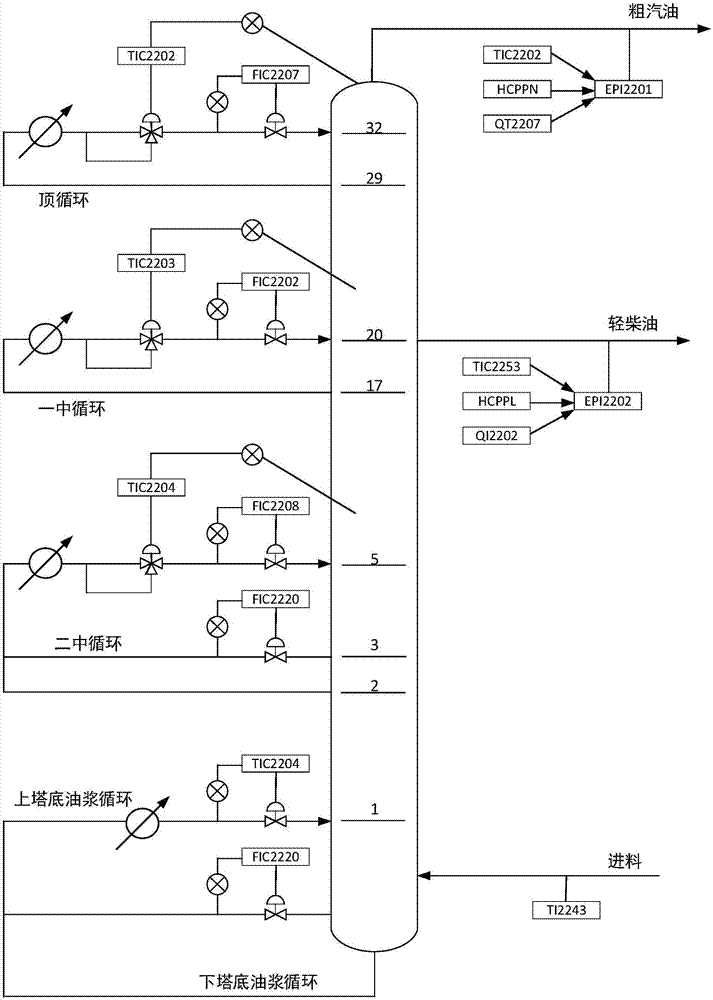
圖1為催化裂化主分餾塔系統圖;
圖2為催化裂化主分餾塔神經網絡模型示意圖;
圖3為基於引力搜索rna-ga流程圖;
圖4為塔頂溫度t1採樣輸出和神經網絡模型輸出對比圖;
圖5為粗汽油幹點t2採樣輸出和神經網絡模型輸出對比圖;
圖6為輕柴油傾點t3採樣輸出和神經網絡模型輸出對比圖。
具體實施方式
下面結合附圖和具體實施方式對本發明做進一步闡述。
催化裂化主分餾塔的系統流程圖如圖1所示,催化裂化主分餾塔是一個多輸入多輸出系統,本發明目的在於建立能夠預測塔頂溫度t1、粗汽油幹點t2和輕柴油傾點t3三個指標的神經網絡模型。本發明中引力搜索rna-ga的催化裂化主分餾塔神經網絡模型示意圖如圖2所示,該模型中徑向基函數中心的尋優算法如圖3所示,建模方法的具體步驟如下:
步驟1:通過採樣獲得催化裂化主分餾塔的輸入輸出數據作為神經網絡模型的樣本數據(採樣數據來源於鍾璇、張泉靈、王樹青催化裂化主分餾塔產品質量的廣義預測控制策略[j].控制理論與應用2001(18):134-137中的主分餾塔模型所產生),其中輸入數據為頂循流量q1、一中流量q2和二中流量q3,輸出數據為塔頂溫度t1、粗汽油幹點t2和輕柴油傾點t3。以頂循流量q1、一中流量q2和二中流量q3同時分別經歷0→0.2→0.6,0→0.5→0.8和0→0.4→0.6共600組數據作為輸入數據,相應的變量塔頂溫度t1、粗汽油幹點t2和輕柴油傾點t3數據作為輸出數據;
步驟2:建立催化裂化主分餾塔rbf神經網絡模型,模型採用一個三層rbf神經網絡結構;
設定t為採樣時刻,q1(t)、q2(t)和q3(t)分別為t時刻的頂循流量、一中流量和二中流量數據,t1(t)、t2(t)和t3(t)分別為t時刻的塔頂溫度、粗汽油幹點和輕柴油傾點數值,rbf神經網絡模型輸入變量個數為nin,輸入向量x為
[q1(t)q2(t)q3(t)t1(t-1)t1(t-2)t1(t-3)t2(t-1)t2(t-2)t2(t-3)t3(t-1)t3(t-2)t3(t-3)]
其中有n=12,輸出變量個數為nout=3,輸出變量為[t1(t)t2(t)t3(t)],從輸入層到輸出層映射可用以下函數表示:
其中x為輸入向量,||·||表示歐幾裡得範數,d表示隱層數,具體d=50,w1(i)、w2(i)和w3(i)分別是神經網絡輸出結點權值向量中的第i個分量,由遞推最小二乘法確定,ci是神經網絡第i個隱層的徑向基函數中心向量,徑向基函數φ(·)採用薄板樣條函數,表示為:
φ(v)=v2ln(v)
其中v表示任意數;
步驟3:選擇樣本數據中的400組數據作為訓練樣本,將數據輸入到步驟2建立的rbf神經網絡模型中;
步驟4:設置建立的rbf神經網絡模型中待尋優參數(徑向基函數中心);
步驟5:提出引力搜索rna遺傳算法,將其用於對步驟2提出的rbf神經網絡的徑向基函數中心進行尋優,運行引力搜索rna遺傳算法,獲得rbf神經網絡的徑向基函數中心的最優解;該步驟的具體實現方式為:
步驟5.1:設定引力搜索rna-ga的參數:種群數s=30、輸入變量個數n=12、個體編碼長度l=8、最大迭代次數gmax=20、轉位換位概率pc=0.8、置換交叉概率pt=0.8、自適應變異概率pml和pmh,設定引力搜索rna-ga終止規則為:引力搜索rna-ga迭代次數達到最大迭代次數gmax;
步驟5.2:對神經網絡模型中待尋優參數(徑向基函數中心)進行鹼基編碼,隨機生成一個初始種群,種群中包含s個個體,每個參數均由字符集{0,1,2,3}編碼為一個長度為l的rna子序列,rbf神經網絡模型的參數有n×d個,則一個rna序列的編碼長度為n×d×l,每個個體代表的參數如下:
其中c(i)表示第i個個體,cd,n表示個體中第d個隱層對應的神經網絡徑向基函數中心向量中的第n個分量;
步驟5.3:將種群中每個rna序列解碼為rbf神經網絡模型的參數,並採用最小二乘法計算出相應的神經網絡輸出結點權值向量,將不同時刻催化裂化主分餾塔神經網絡模型的輸出值和與催化裂化主分餾塔實際輸出t1、t2和t3實際數據間的誤差絕對值之和作為引力搜索rna-ga的催化裂化主分餾塔神經網絡模型參數尋優的適應度函數,表示為:
式中和分別表示第j組模型輸出的塔頂溫度、粗汽油幹點和輕柴油傾點數據,t1(j)、t2(j)和t3(j)則為第j組塔頂溫度、粗汽油幹點和輕柴油傾點數據實際數據,nt是樣本數據個數;
步驟5.4:根據適應度函數值,利用輪盤賭法來選擇個體,並利用適應度函數值選擇適應度函數值最優的s/2個個體組成的中性個體集合en與適應度函數值最差的s/2個個體組成的有害個體集合ed組成新的種群e;
步驟5.5:在中性個體集合en中,以轉位換位概率pc執行相應的轉位操作或換位操作,產生有s/2個個體的集合ec1,具體操作步驟為:
1)在0~1之間隨機選擇一個數h,若h小於概率pc時,進行轉位操作;
2)當h大於等於概率pc時,進行換位操作;
步驟5.6:在中性個體集合en中,以置換交叉概率pt執行置換操作,產生s/2個個體,集合為ec2;
步驟5.7:在集合[ec1;ec2;ed](3/2×s個個體)中,以高位變異概率pmh和低位變異概率pml執行自適應變異操作,得到集合e2,其中自適應變異概率為:
其中,a1是初始變異概率,b1為變異概率變化範圍,aa為變異速率,g為當前進化代數,g0為轉折點;
步驟5.8:在集合e2中找出適應度函數值最優的個體bests;
步驟5.9:檢查迭代次數是否達到終止條件,若滿足要求則獲得神經網絡的最優解,作為徑向基函數中心,否則到步驟5.10;
步驟5.10:將集合e2進行引力搜索,得到新的種群,回到步驟5.3,進行下一輪迭代。引力搜索的具體步驟如下:
1)計算每個個體對應的質量,相應的計算公式如下:
其中m表示個體的質量,worst表示種群中最差個體的適應度函數值,best表示種群中最優個體的適應度函數值,f表示該個體的適應度函數值;
2)計算引力常數,計算公式如下:
其中g0=100,α=20,g表示當前迭代次數,gmax表示最大迭代次數,g為引力常數,e是自然常數;
3)計算引力加速度
其中,ai,k為第i個個體的第k個隱節點對應的引力加速度向量,g為當前迭代中的引力常數,rand為0~1的隨機數向量,mj是第j個個體對應的質量,表示對應元素相乘,eps為非0常數,ei,k和ej,k分別為第i個個體和第j個個體第k個隱節點對應的向量,rk表示第i個個體與第j個個體對應第k個隱節點的歐幾裡得範數,表示為:
rk=||ei,k-ej,k||
4)根據加速度和初始速度,每次迭代記為一次移動,由此獲得新種群,相關計算公式如下:
e′=e+v
v′表示新的速度矩陣,v表示速度矩陣(各變量初始速度均為1),rn為隨機數矩陣,a表示加速度矩陣,e為種群,e′表示為新的種群;
步驟5.10:對步驟5.3~5.9進行迭代,若當前迭代次數滿足要求,則獲得神經網絡的最優解,作為徑向基函數中心,否則回到步驟5.3。
步驟6:利用步驟5獲得的最優解作為催化裂化主分餾塔神經網絡模型徑向基函數中心,並利用測試樣本檢驗神經網絡模型,以驗證其準確性。
按上述方法將頂循流量q1、一中流量q2和二中流量q3同時分別經歷1→0.5→1→0.7,1→0.6→1→0.4和1→0.7→1→0.5共800組數據作為測試輸入數據,得到相應的變量塔頂溫度t1、粗汽油幹點t2和輕柴油傾點t3數據分別為圖4、圖5和圖6。從測試結果圖4、圖5和圖6可以看出,基於引力搜索rna-ga的催化裂化主分餾塔神經網絡模型能夠準確反映實際系統特性。因此,上述模型可用於準確預測催化裂化主分餾塔中的t1、t2和t3三個變量,作為控制催化裂化系統的依據。