一種數據廣播系統、數據廣播方法及設備與流程
2023-10-10 11:41:59 2
本發明涉及大數據領域,尤其涉及一種數據廣播系統、數據廣播方法及設備。
背景技術:
隨著大數據時代的到來,基於內存的並行計算平臺Spark已經廣泛成為業界處理海量數據的流行框架,與Hadoop相比,Spark更適合基於迭代的機器學習算法和圖算法,加上Spark開源社區非常活躍,基於Spark並行框架的生態圈也日益豐富,例如Spark-SQL,Spark-Streaming等。
Spark的運行模式有幾種模式:例如:local、standalone、yarn、mesos等。彈性分布式數據集(英文:Resilient Distributed Dataset,簡稱:RDD)是Spark的核心概念之一,表示只讀、可分區、容錯、可以全部或部分緩存到內存中、在多次並行計算間重用。
當一個RDD需要操作另一個RDD的數據時,Spark支持將較小RDD廣播到每個數據節點上,優化關聯操作;
現有技術中,Spark集群模式運行情況下,當廣播一個變量時,會按照數據節點上啟動任務執行器(executor)的個數N,分發廣播變量N份到該數據節點上,導致系統網絡IO(Input/Output)和內存資源多餘佔用,從而引發任務失敗。
技術實現要素:
本發明實施例提供了一種數據廣播系統、數據廣播方法及設備,能夠減少對系統網絡IO和內存資源的佔用。
第一方面,本發明實施例提供了一種數據廣播方法,該方法應用於數據廣播系統,該數據廣播系統包括:控制節點和至少一個數據節點,每個數據節點上運行有至少一個任務執行器,每個數據節點上包括堆外內存,所述堆外內存存儲的數據可被至少一個任務執行器使用,該方法包括:
控制節點生成廣播數據,並設置第一數據節點上的其中一個任務執行器為主任務執行器,第一數據節點為至少一個數據節點中的一個數據節點;主任務執行器獲取廣播數據,並將廣播數據保存至目標堆外內存,將目標堆外內存的地址發送至非主任務執行器,其中,目標堆外內存為第一數據節點上的堆外內存,非主任務執行器為第一數據節點上除主任務執行器以外的其他任務執行器;非主任務執行器根據目標堆外內存的地址,從目標堆外內存中獲取廣播數據。
本發明實施例中,並不是每個數據節點上的每個任務執行器都從控制節點獲取廣播數據,而是由控制節點在每個數據節點上設置一個主任務執行器,僅由主任務執行器獲取廣播數據,將獲取的廣播數據存儲至數據節點上的堆外內存中,該數據節點上的其他任務執行器從堆外內存中獲取廣播數據。因此,在同一個數據節點上,只需要分發一份廣播數據,從而能夠減少對系統網絡IO和內存資源的佔用。
結合第一方面,在第一方面的第一種可能的實現方式中,該方法還包括:
控制節點在非主任務執行器獲取廣播數據後,發送廣播數據清除消息給主任務執行器;主任務執行器接收控制節點發送的廣播數據清除消息後,清除目標堆外內存中存儲的廣播數據。
可選的,非主任務執行器在獲取廣播數據後,通知控制節點廣播數據獲取完成。
因此,控制節點能獲取各數據節點上的廣播數據的獲取情況,當數據節點上的各非主任務執行器獲取到廣播數據後,指示主任務執行器清除堆外內存中存儲的廣播數據,從而能夠減少對系統內存資源的佔用,提高內存利用率。
結合第一方面,或第一方面的任一種實現方式,在第一方面的第二種可能的實現方式中,控制節點設置第一數據節點上的其中一個任務執行器為主任務執行器包括:控制節點根據第一數據節點中每個任務執行器的負載信息設置一個任務執行器為主任務執行器。
如此,控制節點根據各任務執行器的負載情況選擇主任務執行器,例如:選擇一個負載較小的任務執行器為主任務執行器,從而能夠使各任務執行器負載均衡。
結合第一方面,或第一方面的任一種實現方式,在第一方面的第三種可能的實現方式中,控制節點設置第一數據節點上的其中一個任務執行器為主任務執行器包括:控制節點隨機選擇一個任務執行器,將該任務執行器設置為主任務執行器。
結合第一方面,或第一方面的任一種實現方式,在第一方面的第四種可能的實現方式中,該方法還包括:控制節點生成廣播優化執行計劃,廣播優化執行計劃包括主任務執行器計劃和非主任務執行器計劃;控制節點將廣播優化執行計劃發送至第一數據節點上的每個任務執行器;主任務執行器從廣播優化執行計劃中選擇主任務執行器計劃執行;非主任務執行器從廣播優化執行計劃中選擇非主任務執行器計劃執行。
其中,主任務執行器計劃包括第一方面中主任務執行器執行的步驟,非主任務執行器計劃包括第一方面中非主任務執行器執行的步驟。
第二方面,本發明實施例提供了一種數據廣播方法,該方法應用於數據廣播系統,數據廣播系統包括控制節點和至少一個數據節點,每個數據節點上運行有至少一個任務執行器,每個數據節點上包括堆外內存,堆外內存存儲的數據可被至少一個任務執行器使用,該方法包括:
第一數據節點上的主任務執行器獲取廣播數據,將廣播數據保存至目標堆外內存,並將目標堆外內存的地址發送至非主任務執行器,第一數據節點上的非主任務執行器根據目標堆外內存的地址,從目標堆外內存中獲取廣播數據。其中,目標堆外內存為第一數據節點上的堆外內存,主任務執行器為控制節點在第一數據節點上所指定的一個任務執行器,非主任務執行器為第一數據節點上除主任務執行器之外的其他任務執行器,第一數據節點為至少一個數據節點中的一個數據節點。
本發明實施例中,每個數據節點上,只有主任務執行器去獲取廣播數據,將獲取的廣播數據存儲至數據節點上的堆外內存中,其他任務執行器從堆外內存中獲取廣播數據。因此,在同一個數據節點上,只需要分發一份廣播數據,從而能夠減少對系統網絡IO和內存資源的佔用。
結合第二方面,在第二方面的第一種可能的實現方式中,該方法還包括:
主任務執行器接收控制節點發送的廣播數據清除消息,之後,清除目標堆外內存中存儲的廣播數據。從而可以及時清理內存中緩存的數據,減少對內存的佔用,提高內存利用率。
結合第二方面,或第二方面的任一種可能的實現方式,在第二方面的第二種可能的實現方式中,該方法還包括:第一數據節點上的每個任務執行器接收控制節點發送的廣播優化執行計劃,廣播優化執行計劃包括主任務執行器計劃和非主任務執行器計劃;主任務執行器從廣播優化執行計劃中選擇主任務執行器計劃執行以執行第二方面及第二方面的第一種可能的實現方式中的步驟;非主任務執行器從廣播優化執行計劃中選擇非主任務執行器計劃執行以執行第二方面中所描述的步驟。
第三方面,本發明實施例提供了一種數據廣播方法,該方法應用於數據廣播系統,數據廣播系統包括控制節點和至少一個數據節點,每個數據節點上運行有至少一個任務執行器,每個數據節點上包括堆外內存,堆外內存存儲的數據可被至少一個任務執行器使用,該方法包括:
控制節點生成廣播數據;控制節點設置第一數據節點上的多個任務執行器中的一個任務執行器為主任務執行器,第一數據節點為至少一個數據節點中的一個數據節點;主任務執行器用於獲取廣播數據,並將廣播數據保存至目標堆外內存,將目標堆外內存的地址發送至非主任務執行器,非任務執行器為第一數據節點上除主任務執行器之外的其他任務執行器,非主任務執行器用於根據目標堆外內存的地址,從目標堆外內存獲取廣播數據,目標堆外內存為第一數據節點上的堆外內存。
本發明實施例中,是由控制節點在每個數據節點上設置一個主任務執行器,僅由主任務執行器獲取廣播數據。因此,在同一個數據節點上,只需要分發一份廣播數據,從而能夠減少對系統網絡IO和內存資源的佔用。
結合第三方面,在第三方面的第一種可能的實現方式中,控制節點設置第一數據節點上的多個任務執行器中的一個任務執行器為主任務執行器包括:控制節點根據第一數據節點中每個任務執行器的負載信息設置一個任務執行器為主任務執行器。從而可以儘可能均衡每個任務執行器負載。
結合第三方面,或第三方面的任一種可能的實現方式,在第三方面的第二種可能的實現方式中,該方法還包括:當非任務執行器獲取廣播數據後,控制節點發送廣播數據清除消息給主任務執行器,廣播數據清除消息用於使主任務執行器清除目標堆外內存中存儲的廣播數據。從而可以及時清理內存中緩存的數據,減少對內存的佔用,提高內存利用率。
結合第三方面,或第三方面的任一種可能的實現方式,在第三方面的第三種可能的實現方式中,該方法還包括:控制節點生成廣播優化執行計劃,廣播優化執行計劃包括主任務執行器計劃和非主任務執行器計劃;將廣播優化執行計劃發送至第一數據節點上的每個任務執行器,以使得第一數據節點上的每個任務執行器根據控制節點所設置的任務執行器類型,從主任務執行器計劃和非主任務執行器計劃中選擇一個進行執行,任務執行器類型包括主任務執行器和非主任務執行器。
第四方面,本發明實施例還提供了一種數據伺服器,該數據伺服器應用於數據廣播系統,該數據廣播系統包括控制伺服器和至少一個數據伺服器,數據伺服器包括:處理器、存儲器和IO接口;處理器上運行有多個任務執行器,任務執行器包括主任務執行器和非主任務執行器,主任務執行器為控制伺服器在第一數據伺服器上所指定的一個任務執行器,非主任務執行器為第一數據伺服器上除主任務執行器之外的其他任務執行器;存儲器中包括堆外內存,堆外內存存儲的數據可被至少一個任務執行器使用;存儲器還用於存儲程序代碼,主任務執行器調用存儲器中的程序代碼,以執行以下操作:
通過IO接口獲取廣播數據,將廣播數據保存至目標堆外內存,並將目標堆外內存的地址發送至非主任務執行器,其中,目標堆外內存為第一數據伺服器上的堆外內存;非主任務執行器調用存儲器中的程序代碼,以執行以下操作:根據目標堆外內存的地址,從目標堆外內存中獲取廣播數據。
結合第四方面,在第四方面的第一種可能的實現方式中,主任務執行器還用於執行以下操作:接收控制節點發送的廣播數據清除消息,再清除目標堆外內存中存儲的廣播數據。
結合第四方面,或第四方面的任一種可能的實現方式,在第四方面的第二種可能的實現方式中,數據伺服器上的每個任務執行器,還用於接收控制節點發送的廣播優化執行計劃,廣播優化執行計劃包括主任務執行器計劃和非主任務執行器計劃;主任務執行器,還用於從廣播優化執行計劃中選擇主任務執行器計劃執行;非主任務執行器,還用於從廣播優化執行計劃中選擇非主任務執行器計劃執行。
第五方面,本發明實施例還提供了一種控制伺服器,控制伺服器應用於數據廣播系統,數據廣播系統包括控制伺服器和至少一個數據伺服器;數據伺服器上有多個任務執行器;控制伺服器包括:處理器、存儲器及IO接口,存儲器用於存儲程序代碼,處理器調用存儲器中的程序代碼,以執行以下操作:
生成廣播數據,設置數據伺服器上的多個任務執行器中的一個任務執行器為主任務執行器;主任務執行器用於獲取廣播數據,並將廣播數據保存至目標堆外內存,將目標堆外內存的地址發送至非主任務執行器,非主任務執行器用於根據目標堆外內存的地址,從目標堆外內存獲取廣播數據,其中,非主任務執行器為數據伺服器上除主任務執行器之外的其他任務執行器,目標堆外內存為數據伺服器上的堆外內存,堆外內存存儲的數據可被多個任務執行器使用。
結合第五方面,在第五方面的第一種可能的實現方式中,處理器調用存儲器中的應用程式,具體執行:根據第一數據節點中每個任務執行器的負載信息設置一個任務執行器為主任務執行器。
結合第五方面,或第五方面的任一種可能的實現方式,在第五方面的第二種可能的實現方式中,處理器還用於執行:當非任務執行器獲取廣播數據後,發送廣播數據清除消息給主任務執行器,廣播數據清除消息用於使主任務執行器清除目標堆外內存中存儲的廣播數據。
結合第五方面,或第五方面的任一種可能的實現方式,在第五方面的第三種可能的實現方式中,處理器還用於執行:生成廣播優化執行計劃,廣播優化執行計劃包括主任務執行器計劃和非主任務執行器計劃;將廣播優化執行計劃發送至數據伺服器上的每個任務執行器,以使得數據伺服器上的每個任務執行器根據控制伺服器所設置的任務執行器類型,從主任務執行器計劃和非主任務執行器計劃中選擇一個進行執行,任務執行器類型包括主任務執行器和非主任務執行器。
第六方面,本發明實施例還提供了一種數據廣播系統,該系統包括第四方面提供的控制伺服器和至少一個第五方面所提供的數據伺服器。
第七方面,本發明實施例還提供了一種數據伺服器,該數據伺服器應用於數據廣播系統,該數據廣播系統包括控制伺服器和至少一個數據伺服器,數據伺服器包括多個任務執行器,任務執行器包括主任務執行器和非主任務執行器,主任務執行器為控制伺服器在第一數據伺服器上所指定的一個任務執行器,非主任務執行器為第一數據伺服器上除主任務執行器之外的其他任務執行器;
所述主任務執行器包括:
廣播數據獲取單元,用於獲取廣播數據;
廣播數據存儲單元,用於將廣播數據保存至目標堆外內存,其中,目標堆外內存為第一數據伺服器上的堆外內存;
堆外內存地址廣播單元,用於將目標堆外內存的地址發送至非主任務執行器;
所述非主任務執行器包括:
廣播數據獲取單元,用於根據目標堆外內存的地址,從目標堆外內存中獲取廣播數據。
第八方面,本發明實施例還提供了一種控制伺服器,控制伺服器應用於數據廣播系統,數據廣播系統包括控制伺服器和至少一個數據伺服器;數據伺服器上有多個任務執行器;控制伺服器包括:
廣播數據生成單元,用於生成廣播數據;
主任務執行器設置單元,用於設置數據伺服器上的多個任務執行器中的一個任務執行器為主任務執行器;主任務執行器用於獲取廣播數據,並將廣播數據保存至目標堆外內存,將目標堆外內存的地址發送至非主任務執行器,非主任務執行器用於根據目標堆外內存的地址,從目標堆外內存獲取廣播數據,其中,非主任務執行器為數據伺服器上除主任務執行器之外的其他任務執行器,目標堆外內存為數據伺服器上的堆外內存,堆外內存存儲的數據可被多個任務執行器使用。
從以上技術方案可以看出,本發明實施例具有以下優點:
本發明實施例中的數據廣播系統包括控制節點和至少一個數據節點,每個數據節點上運行有至少一個任務執行器;控制節點生成廣播數據,對於每個數據節點,控制節點設置數據節點上的其中一個任務執行器為主任務執行器,主任務執行器獲取廣播數據,將廣播數據保存至堆外內存,將堆外內存的地址發送至該數據節點上的其他任務執行器;其他任務執行器從堆外內存的地址獲取廣播數據。本發明實施例中是由主任務執行器從其他節點獲取廣播數據,其他任務執行器僅需要從本節點上的堆外內存中獲取廣播數據,因此,在同一個數據節點上,只需要分發一份廣播數據,從而能夠減少對系統網絡IO和內存資源的佔用。
附圖說明
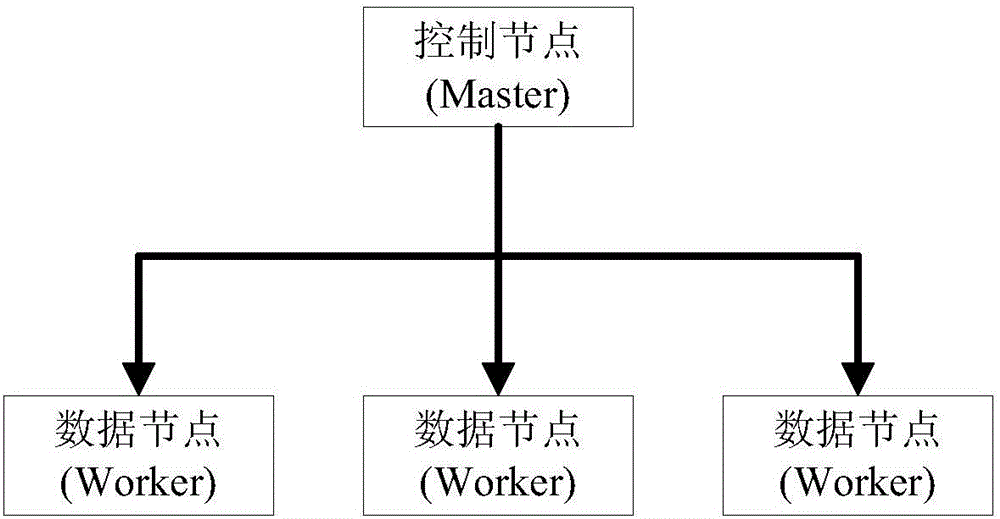
圖1為本發明實施例中的一種並行化架構示意圖;
圖2為本發明實施例中的一種Spark運行模式示意圖;
圖3為現有技術中的一種廣播變量廣播方法的示意圖;
圖4為現有技術中的一種Spark數據廣播原理示意圖;
圖5為現有技術中的Spark數據廣播內存膨脹對比圖;
圖6為現有技術中的Spark數據廣播網絡IO開銷對比圖;
圖7為本發明實施例中數據廣播系統及數據廣播優化原理示意圖;
圖8為本發明實施例中數據廣播信息交互流程圖;
圖9為本發明實施例中的數據伺服器和控制伺服器的硬體結構示意圖。
具體實施方式
為了使本發明的技術方案及有益效果更加清楚,以下結合附圖及實施例,對本發明進行進一步詳細說明。應當理解,此處所描述的具體實施例僅僅用以解釋本發明,並不用於限定本發明。
Spark為一種基於內存的並行計算框架,由UCBerkeley的AMP實驗室開發。Spark不同於MapReduce的是,Spark的Job中間輸出和結果可以保存在內存中,從而不再需要讀寫Hadoop分布式文件系統(英文:Hadoop Distributed File System,簡稱:HDFS),因此Spark能更好地適用於數據挖掘與機器學習等需要迭代的算法。
本發明實施例中的數據廣播系統、數據廣播方法及設備應用於Spark集群,Spark集群模式包括但不限於StandAlone、yarn-client、yarn-cluster、Mesos等模式。
Spark集群在部署時,可以採用如圖1所示的並行化架構。並行化架構是一種可以加速任務運行的一種技術,具體是將輸入數據在多個數據節點上均衡分布,任務啟動時在多個數據節點上並行計算,從而可以加速任務的運行。
如圖1所示的並行化架構中包括控制節點(Master),一個Master節點連接多個數據節點(Worker)。其中每一個控制節點和數據節點都有獨立的處理器(英文:Central Processing Unit,CPU)和存儲資源(包括:內存、磁碟),不同節點通過高速網絡(如乙太網、光纖交換網絡)進行連接,其中:
控制節點負責管理整個集群中每個數據節點,對外提供任務提交接口和任務查詢等接口,接收客戶端提交的作業,將外部任務請求分解到數據節點上並行執行,並收集執行結果反饋給客戶端。
數據節點受控制節點控制,負責管理本節點的資源,定期向控制節點匯報心跳,接收控制節點的命令,執行提交的作業,按控制節點執行模型訓練等。
圖2為基於Spark on yarn一種Spark運行模式架構圖,從集群部署的角度來看,Spark集群由以下部分組成:
集群管理器(Cluster Manager):Spark的集群管理器,承擔如圖1中所示的控制節點(Master節點)的角色,主要負責資源的分配與管理。
數據節點(Worker):承擔如圖1中所示的數據節點(Worker節點)角色,每個Worker上有至少一個任務執行器(Executor),Worker負責創建Executor,將資源和任務進一步分配給Executor,同步資源信息給Cluster Manager。
任務管理器(Executor):是Spark上的某個應用(Application)運行在worker節點上的一個進程,該進程負責運行任務(Task),並且負責將數據存在內存或者磁碟上。每個應用(Application)都有各自獨立的任務執行器。
客戶端驅動程序(Driver App):為客戶端應用程式,用於將任務程序轉換為彈性分布式數據集(英文:Resilient Distributed Datasets,簡稱:RDD),並與Cluster Manager進行通信與調度。
彈性分布式數據集RDD是Spark最核心的概念,表示已被分區,不可變的並能夠被並行操作的數據集合,RDD通常被分區到集群的每個數據節點上,不同的數據集格式對應不同的RDD實現。Spark的計算過程主要是RDD的迭代計算過程。
當一個RDD需要訪問另一個RDD的數據時,則Spark可以通過將承載數據量較小的RDD廣播到每個任務執行器上,優化關聯操作。
將較小的RDD廣播到每個任務執行器上可以採用廣播(broadcast)變量的方式。Spark源碼中Hadoop RDD的實現中,就採用廣播(broadcast)變量進行Hadoop JobConf的傳輸。
Broadcast變量是Spark所支持的兩種共享變量(shared variables)的一種,為共享分布式計算過程中各個task都會用到的只讀變量,broadcast變量只會在每個任務執行器上保存一份,而不會每個task都傳遞一份,節省空間,效率也高。Spark使用高效的廣播算法去分配廣播變量,以降低通信成本。
圖3為現有技術中的一種數據廣播的方法示意圖。圖中的m表示廣播變量(Broadcast變量),Spark應用驅動(Spark application Driver)相當於圖1所示的並行化框架中的控制節點,從屬數據節點(Slave Worker)就相當於圖1所示的並行化框架中的數據節點Worker,Worker上運行有Executor,Executor運行有多個task。
現有Spark集群模式運行,當廣播變量m時,每個任務執行器都會從控制節點拉取廣播變量,按照某一數據節點上啟動的任務執行器的個數N,分發廣播變量N份到該數據節點上,導致系統網絡IO和內存資源多餘佔用,從而引發任務失敗。
圖4以Spark on yarn運行模式為示例,說明了Spark在廣播數據時,每個數據節點上被分發了多份廣播數據的問題。圖中的driver_master與圖3中的Spark應用驅動、與圖1中的Master節點一樣,都表示控制節點。
Spark任務運行時,都是以Executor為基本單位,而每個Executor各自對應一個數據管理器(BlockManager),driver_master側有一個數據管理控制器(BlockManagerMaster)。每個Executor上的BlockManager用於從集群的其他節點(driver_master節點或其他數據節點)上拉取數據,讀取本地數據緩存到內存或磁碟,在拉取完數據後,向driver_master的BlockManagerMaster匯報Block的信息和接收來自BlockManagerMaster的消息。因此,每個Executor都需要從集群的其他節點拉取數據,並向driver_master匯報。
這種廣播數據的實現方式,存在嚴重的內存多餘佔用和網絡IO通信開銷。例如:以10個數據節點為集群、每個數據節點上啟動9個任務管理器、廣播數據大小為2GB,廣播分塊大小為4MB為例。現有Spark廣播數據方法,當廣播數據的大小為2GB的時候,需要2GB*9*10=180GB的內存開銷,廣播變量的內存膨脹對比如圖5所示,2GB的廣播數據大小需要180GB的內存開銷;當廣播數據的大小為2GB的時候,廣播數據塊為2GB/4MB=512,廣播數據塊傳輸次數需要(2GB/4MB)*10*9=46080次,網絡IO開銷對比圖如圖6所示,廣播數據塊為512時,實際需要傳輸46080次。
本發明中提出一種Spark在集群模式下數據廣播系統、數據廣播方法及設備,能夠減少對系統網絡IO和內存資源的佔用。下面進行詳細介紹。
圖7為本發明實施例中的數據廣播系統,該系統包括:
控制節點(圖7中所示的driver_master)和至少一個數據節點(圖7中所示的Worker),每個數據節點上運行有至少一個任務執行器。
除此之外,每個數據節點上包括堆外內存(off-heap memory),堆外內存中存儲的數據可被該數據節點上的所有任務執行器訪問。堆外內存是與堆內內存(on-heap memory)相對的概念,堆內內存是把內存對象分配在Java虛擬機的堆內的內存,由Java虛擬機進行管理;堆外內存是把內存對象分配在Java虛擬機的堆以外的內存,這些內存直接受作業系統管理,而不是受Java虛擬機管理,不會因為系統內存不夠而讓虛擬機進行垃圾回收,也能使得資源隔離的多個進程之間可以共享堆外數據的讀取。因此數據節點的堆外內存中存儲的數據可被該節點上的多個任務執行器訪問。
控制節點與各數據節點中的任務執行器進行通信,任務執行器包括主任務執行器(圖7中的ExecutorMaster)和非主任務執行器(圖7中的Executor1……ExecutorN),主任務執行器為控制節點在數據節點上所指定的一個任務執行器,具體的指定過程請參閱圖8所示的實施例中的步驟802中的描述。非主任務執行器為該數據節點上除主任務執行器之外的其他任務執行器。
控制節點與與其連接的多個數據節點中進行通信,下面以控制節點和其中一個數據節點(為了描述方便,稱之為第一數據節點)之間的信息交互為例,對本發明實施例中的廣播方法進行詳細介紹,如圖8所示。
801、控制節點生成廣播數據;
控制節點driver_master從所有任務執行器上收集待廣播數據到本地,形成完整數據源,並按照任務運行時指定的廣播數據塊大小參數(broadcast_block_size),將廣播數據分塊,構造數據塊,並構造廣播數據的元數據信息,元數據信息包括:「分塊塊數量、分塊總字節大小、元數據編號」等。
可選的,為了在元數據上進行區分,在構造廣播數據的元數據信息時,在元數據信息中加入「是否優化廣播」欄位,「是否優化廣播」欄位用於標識每個任務執行器在執行廣播數據相關任務時的數據讀取方式,如果該欄位的值是「是」時,表示任務執行器是採用本發明中的方式讀取的數據,如果該欄位的值是「否」時,表示該任務執行器是採用的現有技術中的方式讀取數據。
802、控制節點設置第一數據節點上的其中一個任務執行器為主任務執行器;
控制節點從第一數據節點上選取一個任務執行器作為主任務執行器,具體的選取方式包括但不限於以下幾種:
第一種:控制節點從數據節點上隨機選取一個任務執行器作為主任務執行器(ExecutorMaster),其他任務執行器為非主任務執行器(Executor1……ExecutorN)。
第二種:控制節點按照每個任務執行器的負載信息情況選擇主任務執行器,例如:選擇其中負載最小的一個任務執行器作為主任務執行器。
具體的,控制節點設置主任務執行器的方式包括:
控制節點給第一數據節點上的每個任務執行器下發標誌位,以標識當前任務執行器是否被選中為主任務執行器,例如:當某一任務標識器接收的標誌位為1時,表示該任務執行器被設置為主任務執行器,某一任務標識器接收的標識位為0時,表示該任務執行器被設置為非主任務執行器。
需要說明的是,步驟801中生成廣播數據和步驟802中的設置主任務執行器之間的執行順序不做具體限制,可以先生成廣播數據,再設置主任務執行器,也可以先設置主任務執行器,再生成廣播數據,也可以並行執行。
在現有技術中,控制節點通過下發廣播執行計劃(或廣播任務執行計劃)給各任務執行器,各任務執行器按照廣播執行計劃中的指示從數據源節點(控制節點或其他數據節點)拉取廣播數據。可選的,為了使方案更完善,本發明實施例在廣播執行計劃中新增以下執行計劃,以形成廣播優化執行計劃:
1)控制節點執行計劃:控制節點從數據節點上選取ExecutorMaster,指定選取的具體策略,步驟802中控制節點從第一數據節點上選取一個任務執行器作為主任務執行器時所使用的策略為廣播任務執行計劃中所指定的策略。
2)主任務執行器計劃:數據節點上的ExecutorMaster執行廣播數據的拉取和保存,將廣播數據保存至堆外內存,通知廣播數據的保存地址到該數據節點的非主任務執行器(Executor1……ExecutorN)中;
3)非主任執行器計劃:數據節點上的非主任務執行器不需要執行廣播數據的拉取,只要等待ExecutorMaster發送廣播數據的保存地址,再從本地堆外內存(本數據節點的堆外內存)中讀取廣播數據。
控制節點下發廣播優化執行計劃(主任務執行器計劃和非主任務執行器計劃)到各任務執行器上。
可選的,控制節點在下發廣播優化執行計劃時,可以是下發主任務執行器計劃到主任務執行器上,並下發非主任務執行器計劃到非主任務執行器上。還可以是,將主任務執行器計劃和非主任務執行器計劃下發到每個任務執行器上,由主任務執行器選擇主任務執行器計劃執行,非主任務執行器選擇非主任務執行器計劃執行。
803、主任務執行器獲取廣播數據;
主任務執行器根據收到的廣播優化任務執行計劃,執行從待廣播數據源上按指定策略拉取廣播數據,拉取廣播數據的策略根據各節點間通信方式的不同而不同:
如果各節點間採用超文本傳輸協議(英文:HyperText Transfer Protocol,簡稱:HTTP)方式通信,則主任務執行器從控制節點上拉取所有廣播數據塊。
如果各節點採用對等網絡傳輸(英文:Peer to Peer,簡稱:P2P)方式通信,則第一輪拉取是由各數據節點上的各主任務執行器從控制節點拉取廣播數據塊,廣播數據塊被打散分塊到各數據節點上,之後,第一數據節點的主任務執行器從其他數據節點上拉取廣播數據的其他塊,通過多次拉取,能夠獲得完整的廣播數據。
804、主任務執行器將廣播數據保存至目標堆外內存;
主任務執行器將拉取的廣播數據塊保存至第一數據節點上的堆外內存中(目標堆外內存),通過多次拉取,使得保存在目標堆外內存中的數據為廣播數據的完整分塊。
可選的,ExecutorMaster的BlockManager通知BlockManagerMaster廣播數據拉取已完成。
805、主任務執行器將目標堆外內存的地址發送至非主任務執行器;
ExecutorMaster發送消息到第一數據節點的其餘任務執行器(即非主任務執行器)上,將廣播數據所在的目標堆外內存的地址發送給非主任務執行器。
具體的,ExecutorMaster通過Akka消息機制將目標堆外內存的地址發送給非主任務執行器。
其中,Akka消息機制是一種可在Java虛擬機上提供分布式、高並發、容錯的消息傳輸工具包,可實現並發、容錯的分布式系統;通過異步、非阻塞方式,進行消息或事件傳送;具有高性能、易擴展、以構建應用等優勢,開源並行計算框架Spark就是基於Akka實現控制節點和數據節點之間消息的傳遞。
806、非主任務執行器根據目標堆外內存的地址,從目標堆外內存中獲取廣播數據。
第一數據節點上的非主任務執行器在接收到主任務執行器發送的目標堆外內存地址後,根據非主任務執行器計劃中的指示,根據目標堆外內存的地址,從目標堆外內存中獲取廣播數據,各任務執行器上的Task再進行運算。
除此之外,每個非主任務執行器在從目標堆外內存獲取廣播數據後,通知driver_master上的BlockManagerMaster廣播數據獲取完成,driver_master接收第一數據節點上的所有的非主任執行器發送的廣播數據獲取完成消息後,表示廣播任務已完成,driver_master發通知消息到每個數據節點上的ExecutorMaster,清除廣播數據。
可選的,為了更好地兼容本發明實施例中的方案與現有技術中的方案,本發明實施例通過在driver_master側配置開關變量,表明是否開啟廣播數據的優化選項;當開關變量開啟時,則driver_master和數據節點上的各任務執行器執行上述步驟801至步驟806;當開關變量不開啟時,則driver_master和數據節點上的各任務執行器不執行上述步驟801至步驟806,而是執行現有技術中的方案。
需要說明的是,圖8所示的實施例只是以第一數據節點與控制節點的信息交互對本方案進行說明,在實際應用中,控制節點同時與其控制的多個數據節點進行交互,實施本發明實施例中的方案。
本發明實施例基於堆外內存和Akka消息機制,優化Spark廣播數據的方案,由driver_master在每個數據節點上設置一個任務執行器為ExecutorMaster,由ExecutorMaster負責從數據源處拉取廣播數據,並保存廣播數據到堆外內存中,然後該ExecutorMaster發送消息通知該數據節點上其餘Executor廣播數據的堆外內存地址,使得該數據節點上的其餘Executor可以從堆外內存中獲取廣播數據。從而使得同一個數據節點上,只需要有一個executor從數據源處拉取廣播數據,只需要複製分發一份廣播數據,從而能夠減少對系統網絡IO和內存資源的佔用。
通過本發明實施例中的方案,則只需要給每個數據節點ExecutorMaster分發一份數據,則只需要2GB*10=20GB內存開銷,廣播數據塊傳輸次數只需要(2GB/4MB)*10=5120次。而現有技術中的方案需要2GB*9*10=180GB的內存開銷,廣播數據塊傳輸次數需要(2GB/4MB)*10*9=46080次。相比之下,本發明實施例能夠節省系統網絡開銷和減少對內存的佔用。
以上是對本發明實施中的數據廣播方法的介紹,上述控制節點和控制節點可以是伺服器,控制節點和數據節點可以是位於不同的伺服器上,也可以位於同一臺伺服器上。本發明實施例以位於不同伺服器上為例進行說明。其中,控制節點為控制伺服器,數據節點為數據伺服器。
下面對本發明實施例中的控制伺服器和數據伺服器分別進行介紹。
應用伺服器和數據伺服器硬體結構都可以是如圖9所示的伺服器結構示意圖,只是應用伺服器和數據伺服器的處理器執行的應用程式的不同,從而具備不同的功能。
圖9是本發明實施例提供的一種伺服器結構示意圖,該伺服器900可因配置或性能不同而產生比較大的差異,可以包括一個或一個以上處理器922和存儲器932,一個或一個以上存儲應用程式(或程序代碼)942或數據944的存儲器930(例如一個或一個以上海量存儲設備)。其中,存儲器930可以是短暫存儲或持久存儲。存儲在存儲介質930的程序可以包括一個或一個以上模塊(圖示沒標出),每個模塊可以包括對伺服器中的一系列指令操作。更進一步地,處理器922與存儲器930通信,在伺服器900上執行存儲器930中的一系列指令操作。
伺服器900還可以包括一個或一個以上電源926,一個或一個以上有線或無線網絡接口950,一個或一個以上輸入輸出(I/O)接口958,和/或,一個或一個以上作業系統941,例如Windows ServerTM,Mac OS XTM,UnixTM,LinuxTM,FreeBSDTM等等。
處理器922,可以是CPU或者是特定集成電路ASIC(Application Specific Integrated Circuit),或者是被配置成實施本發明實施例的一個或多個集成電路,用於執行作業系統與應用程式。
基於以上硬體結構,下面先介紹數據伺服器所具備的功能。
本發明實施例中的數據伺服器中的處理器922上處理器上運行有多個任務執行器,任務執行器包括主任務執行器和非主任務執行器,主任務執行器為控制伺服器在第一數據伺服器上所指定的一個任務執行器,非主任務執行器為第一數據伺服器上除主任務執行器之外的其他任務執行器;
數據伺服器中存儲器932中包括堆外內存,堆外內存存儲的數據可被至少一個任務執行器使用;
處理器922中的主任務執行器調用存儲器930中的程序代碼942,執行上述圖8所示的實施例中的主任務執行器所執行的步驟,同樣,非主任務執行器調用存儲器930中的程序代碼,執行上述圖8所示的實施例中的非主任務執行器所執行的步驟。具體請參閱圖8所示的實施例,此處不再贅述。
基於以上硬體結構,下面介紹控制伺服器所具備的功能。
本發明實施例中的控制伺服器中的處理器922調用所述存儲器930中的所述程序代碼942,執行上述圖8所示的實施例中的控制節點(即driver_master)所執行的步驟,具體請參閱圖8所示的實施例,此處不再贅述。
另外,處理器922通過伺服器的內部總線和I/O連接,I/O再和外部設備連接,最終實現處理器922和外部設備的信息傳輸,用戶可以通過I/O對處理器922下達命令。外部設備包括例如滑鼠、鍵盤、印表機等。
另外,本發明實施例還提供了一種數據廣播系統,該系統示意圖可以參閱圖7,包括圖9中所述的控制伺服器和至少一個圖9中所述的數據伺服器,數據伺服器對應於圖7中所示的數據節點,控制伺服器對應於圖7中所示的driver_master。此處不再贅述。
所屬領域的技術人員可以清楚地了解到,為描述的方便和簡潔,上述描述的系統,裝置和單元的具體工作過程,可以參考前述方法實施例中的對應過程,在此不再贅述。
在本申請所提供的幾個實施例中,應該理解到,所揭露的系統,裝置和方法,可以通過其它的方式實現。例如,以上所描述的裝置實施例僅僅是示意性的,例如,所述單元的劃分,僅僅為一種邏輯功能劃分,實際實現時可以有另外的劃分方式,例如多個單元或組件可以結合或者可以集成到另一個系統,或一些特徵可以忽略,或不執行。另一點,所顯示或討論的相互之間的耦合或直接耦合或通信連接可以是通過一些接口,裝置或單元的間接耦合或通信連接,可以是電性,機械或其它的形式。
所述作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位於一個地方,或者也可以分布到多個網絡單元上。可以根據實際的需要選擇其中的部分或者全部單元來實現本實施例方案的目的。
另外,在本發明各個實施例中的各功能單元可以集成在一個處理單元中,也可以是各個單元單獨物理存在,也可以兩個或兩個以上單元集成在一個單元中。上述集成的單元既可以採用硬體的形式實現,也可以採用軟體功能單元的形式實現。
所述集成的單元如果以軟體功能單元的形式實現並作為獨立的產品銷售或使用時,可以存儲在一個計算機可讀取存儲介質中。基於這樣的理解,本發明的技術方案本質上或者說對現有技術做出貢獻的部分或者該技術方案的全部或部分可以以軟體產品的形式體現出來,該計算機軟體產品存儲在一個存儲介質中,包括若干指令用以使得一臺計算機設備(可以是個人計算機,伺服器,或者網絡設備等)執行本發明各個實施例所述方法的全部或部分步驟。而前述的存儲介質包括:U盤、移動硬碟、只讀存儲器(ROM,Read-Only Memory)、隨機存取存儲器(RAM,Random Access Memory)、磁碟或者光碟等各種可以存儲程序代碼的介質。
以上所述,以上實施例僅用以說明本發明的技術方案,而非對其限制;儘管參照前述實施例對本發明進行了詳細的說明,本領域的普通技術人員應當理解:其依然可以對前述各實施例所記載的技術方案進行修改,或者對其中部分技術特徵進行等同替換;而這些修改或者替換,並不使相應技術方案的本質脫離本發明各實施例技術方案的精神和範圍。