一種報警方法及裝置與流程
2023-05-20 10:21:11 2
本發明涉及異常檢測技術領域,特別涉及一種報警方法及裝置。
背景技術:
異常檢測旨在檢測出不符合期望行為的數據,因而適應於故障診斷、入侵和欺詐檢測以及數據預處理等多個領域。時間序列是指將同一統計指標的數值按其發生的時間先後順序排列而成的數列,時間序列在工業、金融業以及通信業等各個領域普遍存在,因此基於時間序列的異常檢測有著非常重要的作用。
實際應用中,對每一個需要進行異常檢測的對象進行監控時,對所監控到的時間序列進行曲線擬合處理,可以得到該對象對應的曲線。
以it運維為例,無論是網絡流量的監控、磁碟容量的監控、還是響應時間的監控,時間序列異常檢測均可以幫助用戶及時發現服務運行中出現的問題,比如曲線出現突變、曲線中的某一點與歷史數據不相符等等,發現異常時,通常還會對檢測到的異常進行報警,以提醒用戶對異常進行處理。目前,時間序列異常檢測系統使用通用的異常檢測算法來檢測異常,並且對檢測到的每個異常都會進行報警。
然而用戶對於異常的報警需求是不盡相同的。以出現突變的異常為例,對於磁碟剩餘容量的監控,用戶只對磁碟剩餘容量的突然減小感興趣,因為此時他們需要增加硬碟或者刪除文件,而磁碟剩餘容量的突然增加並不會導致問題的出現,因此在磁碟剩餘容量突然減小時應當報警、而突然增加的情況無需報警;進一步的,在磁碟剩餘容量突然減小時,用戶a認為在磁碟剩餘容量減小到閾值t1時需要報警,而用戶b認為在磁碟剩餘容量減小到閾值t2時才需要報警。
從上述例子可以發現,相同類型的異常,有些情況需要報警而有些情況下不需要報警,即相同異常的報警規則是不一樣的。目前,傳統的異常檢測系統對於相同異常只能提供一種統一的報警規則,導致報警的準確率不高。
技術實現要素:
本發明實施例的目的在於提供一種報警方法及裝置,以提高報警的準確率。具體技術方案如下:
為達到上述目的,本發明實施例公開了一種報警方法,所述方法包括:
獲得目標曲線中預設時長內的目標曲線段,其中,所述目標曲線段中包含目標異常點;
從所述目標曲線段中提取所述目標異常點對應的目標特徵信息;
根據所述目標特徵信息和預先構建的所述目標曲線對應的目標預測模型,預測所述目標異常點所對應的目標異常處理類別,其中,所述目標預測模型是基於標記樣本以及所述標記樣本對應的特徵信息進行訓練得到的,所述標記樣本為所述目標曲線中標記有異常處理類別的異常點;
當所述目標異常處理類別為預設報警類別時,針對所述目標異常點進行報警。
可選的,按照以下方式訓練所述目標預測模型:
獲得所述目標曲線對應的標記樣本;
提取所述標記樣本對應的特徵信息;
根據所述標記樣本的特徵信息和對應的異常處理類別,訓練所述目標預測模型。
可選的,按照以下方式訓練所述目標預測模型:
獲得所述目標曲線對應的標記樣本和非標記樣本,其中,所述非標記樣本為未標記異常處理類別的異常點;
分別提取所述標記樣本和所述非標記樣本對應的特徵信息;
根據所述非標記樣本的特徵信息、所述標記樣本的特徵信息和對應的異常處理類別,訓練所述目標預測模型。
可選的,在所述針對所述目標異常點進行報警之後,還包括:
在接收到用戶對所述目標異常點標記的異常處理類別時,將所述目標異常點作為標記樣本,對所述目標預測模型進行再次訓練,得到新的目標預測模型。
可選的,所述目標預測模型為隨機森林模型。
為達到上述目的,本發明實施例還公開了一種報警裝置,所述裝置包括:
獲得模塊,用於獲得目標曲線中預設時長內的目標曲線段,其中,所述目標曲線段中包含目標異常點;
提取模塊,用於從所述目標曲線段中提取所述目標異常點對應的目標特徵信息;
預測模塊,用於根據所述目標特徵信息和預先構建的所述目標曲線對應的目標預測模型,預測所述目標異常點所對應的目標異常處理類別,其中,所述目標預測模型是基於標記樣本以及所述標記樣本對應的特徵信息進行訓練得到的,所述標記樣本為所述目標曲線中標記有異常處理類別的異常點;
報警模塊,用於當所述目標異常處理類別為預設報警類別時,針對所述目標異常點進行報警。
可選的,所述裝置還包括:
第一訓練模塊,用於訓練所述目標預測模型;
其中,所述第一訓練模塊,包括:
第一獲得子模塊,用於獲得所述目標曲線對應的標記樣本;
第一提取子模塊,用於提取所述標記樣本對應的特徵信息;
第一訓練子模塊,用於根據所述標記樣本的特徵信息和對應的異常處理類別,訓練所述目標預測模型。
可選的,所述裝置還包括:
第二訓練模塊,用於訓練所述目標預測模型;
其中,所述第二訓練模塊,包括:
第二獲得子模塊,用於獲得所述目標曲線對應的標記樣本和非標記樣本,其中,所述非標記樣本為未標記異常處理類別的異常點;
第二提取子模塊,用於分別提取所述標記樣本和所述非標記樣本對應的特徵信息;
第二訓練子模塊,用於根據所述非標記樣本的特徵信息、所述標記樣本的特徵信息和對應的異常處理類別,訓練所述目標預測模型。
可選的,所述裝置還包括:
第三訓練模塊,用於在所述報警模塊針對所述目標異常點進行報警之後,在接收到用戶對所述目標異常點標記的異常處理類別時,將所述目標異常點作為標記樣本,對所述目標預測模型進行再次訓練,得到新的目標預測模型。
可選的,所述目標預測模型為隨機森林模型。
由以上可見,本發明實施例提供的報警方法及裝置,對於目標曲線中的異常點,可以利用目標預測模型來預測該異常點的異常處理類別,當異常處理類別為預設報警類別時,會針對該異常點進行報警。目標預測模型是基於目標曲線中的標記樣本以及標記樣本對應的特徵信息進行訓練得到的,由於不同用戶對同一曲線的異常點所標記的異常處理類別可能不同、同一用戶對不同曲線的異常點所標記的異常處理類別也可能不同,因此對於不同的用戶或不同的曲線,可以得到相應的預測模型,進而可以對不同的用戶或不同的曲線,有針對性地進行報警,提高報警的準確率。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對於本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
圖1為本發明實施例提供的一種報警方法的流程示意圖;
圖2為本發明實施例提供的一種報警裝置的結構示意圖。
具體實施方式
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅僅是本發明一部分實施例,而不是全部的實施例。基於本發明中的實施例,本領域普通技術人員在沒有作出創造性勞動前提下所獲得的所有其他實施例,都屬於本發明保護的範圍。
為解決現有技術問題,本發明實施例提供了一種報警方法及裝置。下面首先對本發明實施例所提供的一種報警方法進行詳細說明。
圖1為本發明實施例提供的一種報警方法的流程示意圖,如圖1所示,該方法包括:
s101,獲得目標曲線中預設時長內的目標曲線段,其中,目標曲線段中包含目標異常點。
可以理解的,在基於時間序列的異常檢測中,每一個監控對象對應一個曲線,例如,如果同時監控一臺伺服器的網絡流量、磁碟容量,則可以得到兩條曲線,即該伺服器的網絡流量對應的曲線和磁碟容量對應的曲線,如果同時監控兩臺伺服器的網絡流量,則可以得到兩條曲線,即每臺伺服器的網絡流量對應的曲線。
實際應用中,目標曲線可以由異常檢測系統在監控過程中根據檢測到的時間序列生成的。進一步的,異常檢測系統可以根據預設的判斷標準,判斷目標曲線中的每一個點是否是異常點,具體的,異常檢測系統對於異常點的判斷標準可以參考現有技術的方法,本實施例對此不做贅述。需要強調的是,本實施例並不對目標曲線的獲得方式以及目標異常點的獲得方式進行限定。
s102,從目標曲線段中提取目標異常點對應的目標特徵信息。
可以理解的,目標曲線段所包含的點對應的數據可以理解為與目標異常點相應的歷史數據,則目標曲線段的特徵信息可以理解為對應目標異常點對應的目標特徵信息。
實際應用中,曲線段中可以提取的特徵信息包括:曲線周期性、趨勢、季節性、自相關性、偏度、峰度、線性程度、自相似性、混沌係數、t時間內異常點個數,等等中的一個或多個,其中t可以取半小時。具體的,從曲線段中提取特徵信息的方法為現有技術,在此不做贅述。
s103,根據目標特徵信息和預先構建的目標曲線對應的目標預測模型,預測目標異常點所對應的目標異常處理類別。
其中,目標預測模型是基於標記樣本以及標記樣本對應的特徵信息進行訓練得到的,標記樣本為目標曲線中標記有異常處理類別的異常點。
實際應用中,用戶可以將異常處理類別劃分為:需要報警、是異常但是不需要報警、不是異常等類別;也可以劃分為:一類、二類、三類等類別,其中,一類可以表示需要報警、二類可以表示是異常但是不需要報警、三類可以表示不是異常。其中,根據用戶的需要,需要報警的類別還可以進一步劃分,例如,報警後需要立即處理、報警後不需要立即處理等類別。當然,還可以按照其它方式進行劃分,本實施例對此不做限定。
在本實施例中,目標預測模型的輸入為目標異常點對應的目標特徵信息,輸出為目標異常點所對應的目標異常處理類別。上述目標預測模型可以為隨機森林模型,隨機森林模型也稱為協同森林模型,隨機森林顧名思義,是用隨機的方式建立一個森林,森林裡面有很多決策樹組成,每一棵決策樹之間是沒有關聯的,在得到森林之後,當有一個新的輸入樣本進入的時候,就讓森林中的每一棵決策樹分別進行一下判斷,看看這個樣本應該屬於哪一類,然後看看哪一類被選擇最多,就預測這個樣本為那一類。
在一種實現方式中,可以按照以下方式訓練目標預測模型:
獲得目標曲線對應的標記樣本;
提取標記樣本對應的特徵信息;
根據標記樣本的特徵信息和對應的異常處理類別,訓練目標預測模型。
提取標記樣本對應的特徵信息,也就是從目標曲線中預設時長的曲線段中提取特徵信息,該曲線段中包含標記樣本。具體的,提取標記樣本對應的特徵信息的方式與上述提取目標異常點對應的目標特徵信息的方式相同,在此不做贅述。
本領域技術人員可以理解的是,上述訓練目標預測模型的方式為機器學習中的有監督式學習(supervisedlearning)算法。由於上述有監督學習的訓練方式只能利用目標曲線中的標記有異常處理類別的異常點、無法利用未標記異常處理類別的異常點,因此需要較多的標記樣本進行訓練,以提高目標預測模型的預測精度。
而實際上,用戶不一定對所有出現的異常點都進行標記,而是只對部分異常點標記了異常處理類別,因此並不是所有的異常點都是標記樣本,即標記樣本的數量有限,這樣導致有監督式學習算法所訓練出的預測模型的準確度不高。
那麼在這種情況下,為了提高目標預測模型的預測精度,在一種較佳的實現方式中,可以利用機器學習算法中的無監督式學習(unsupervisedlearning)算法,同時利用標記樣本和未標記樣本進行訓練得到預測模型。
具體的,可以按照以下方式訓練目標預測模型:
獲得目標曲線對應的標記樣本和非標記樣本,其中,非標記樣本為未標記異常處理類別的異常點;
分別提取標記樣本和非標記樣本對應的特徵信息;
根據非標記樣本的特徵信息、標記樣本的特徵信息和對應的異常處理類別,訓練目標預測模型。
下面對上述「根據非標記樣本的特徵信息、標記樣本的特徵信息和對應的異常處理類別,訓練目標預測模型」的步驟進行詳細說明:
步驟1、只利用標記樣本的集合l中的標記樣本,訓練出一個初始的隨機森林,其中有n棵樹,一種特徵信息對應一棵樹;
步驟2、對每棵樹hi,從未標記樣本的集合u中選擇置信度最高的未標記樣本,如果該未標記樣本的置信度超過閾值p,則將其加入集合li,並將該未標記樣本的異常處理類別標記為多數樹的分類結果;
其中,該未標記樣本的置信度為集合hi中的樹對該未標記樣本的分類結果的一致程度,集合hi是由除該樹hi以外的其它樹所組成的集合;如果集合hi中的樹對該未標記樣本的分類結果都相同,那麼該未標記樣本的置信度為1;
舉例而言,如果n=8,則集合hi中包含7棵樹,對於集合u中的每一個未標記樣本u,根據該未標記樣本u的的特徵信息可以確定集合hi中的每一棵樹對該未標記樣本u的分類結果,如果有2棵樹將該未標記樣本u的異常處理類別歸為一類、其它5棵樹將該未標記樣本u的異常處理類別歸為二類,則該未標記樣本u的置信度為5/7,如果5/7大於預設的閾值p,則表示該未標記樣本u可以用來訓練樹hi,並且該未標記樣本u的異常處理類別應當標記為二類;
步驟3、對每棵樹hi,重新利用集合l∪li中的標記樣本進行單棵樹的訓練;
步驟4、重複步驟2~步驟3,直至所有樹的訓練結果均不再變化。
需要說明的是,本領域技術人員可以理解的,本質上,這種協同訓練方式的半監督式學習方法在訓練預測模型時,用的也是有監督式學習算法,區別在於標記樣本集合中標記樣本數量可以不斷增加,而增加的標記樣本是由機器對未標記樣本進行標記所獲得的、不是用戶標記的樣本。利用有監督式學習算法訓練出初始隨機森林模型後,由於標記樣本的數量比較少,初始隨機森林模型不太可靠,為了增加可用的樣本數,從未標記樣本中選擇一些置信度較高的加入標記樣本集合。之後用新的標記樣本集合進行訓練,這其實也是有監督式學習,只是標記樣本集合裡面有一些樣本的標記是由機器判斷的。按照這種方法,不斷重複來擴大標記樣本集合,可以使得最終得到的隨機森林模型更加準確、可靠。
s104,當目標異常處理類別為預設報警類別時,針對目標異常點進行報警。
實際應用中,可以預先設置一種或多種異常處理類別為報警類別,例如將需要報警或者一類異常處理類別設置為報警類別。當預測得到的目標異常處理類別為需要報警或者一類異常處理類別時,針對目標異常點進行報警,輸出報警信息。在報警信息中還可以攜帶本次報警的標識信息和目標曲線的標識信息,以便於進行區分和管理,報警的標識信息可以理解為每條報警信息的id(identification,身份標識號),也稱為報警id。
報警的方式可以為聲、光及其組合的方式,也可以為其它的能夠提醒或警示用戶的方式,本實施例對此不做限定。進一步的,當設置了多種異常處理類別為報警類別時,還可以對不同的報警類別按照不同的方式進行報警,例如以不同顏色的光來區分不同的報警類別。
當然,當目標異常處理類別不是預設報警類別時,也可以輸出該目標異常點的目標異常處理類別,以使用戶可以了解和掌握所監控的對象的運行狀況。
在一種實現方式中,在針對目標異常點進行報警之後,該方法還可以包括:
在接收到用戶對目標異常點標記的異常處理類別時,將目標異常點作為標記樣本,對目標預測模型進行再次訓練,得到新的目標預測模型。
可以理解的,在針對目標異常點進行報警之後,用戶可能對該目標異常點的異常處理類別重新進行了標記,例如,在預測得到目標異常點的目標異常處理類別為預設報警類別的情況下,用戶經過分析發現該目標異常點並不需要報警,則用戶可以重新標記該目標異常點的異常處理類別。
當接收到用戶對目標異常點的標記信息後,表示目標預測模型的預測結果並不符合用戶的需求,因此為了提高目標預測模型預測的準確性,可以將目標異常點作為標記樣本,按照上述訓練方法對目標預測模型進行再次訓練,得到新的目標預測模型。
實際應用中,當用戶所監控的對象較多時,為了便於管理,可以為每個檢測的曲線賦予一個標識信息,如曲線id,與該曲線對應的預測模型、預測模型的訓練、用戶反饋的標記信息都可以通過該曲線id進行關聯。
用戶對於接收到的報警信息,可以標記所報警的異常點的異常處理類別,並通過報警id進行反饋,相當於用戶幫助系統對所報警的異常點進行了樣本標記。在接收到用戶的反饋信息後,可以將該異常點的特徵信息及所標記的異常處理類別存儲到資料庫中,如關係型資料庫管理系統mysql,以便於後續利用該異常點對預測模型進行再次訓練。
每條曲線對應的預測模型可以存儲在資料庫中,如mongodb(一個基於分布式文件存儲的資料庫,由c++語言編寫),訓練完成某條曲線對應的預測模型後,會將該預測模型存入資料庫中,如果該曲線已有預測模型,則會覆蓋已有的預測模型,這樣在該曲線有新的異常點時可以直接使用新的預測模型。
需要強調的是,本實施例提供的方案利用機器學習訓練預測模型,其中,基於半監督式學習算法,只需要用戶對接收到的一部分異常點的報警信息進行簡單的反饋,即可學習出用戶的個性化報警需求,同時利用標記樣本和未標記樣本進行學習,輸出與用戶相關的預測模型,提高了報警的準確率,減少了用戶人工配置報警規則的時間,而建立報警規則需要用戶對所監控的服務以及使用的異常檢測算法都有一定的了解,因此還可以降低用戶的技能要求。本實施例提供的方案可以使用在各種流量、磁碟、qps(queriespersecond,每秒查詢率)等時間序列的監控系統中,提供簡單、準確、個性化的報警服務。
由以上可見,本實施例提供的報警方法,對於目標曲線中的異常點,可以利用目標預測模型來預測該異常點的異常處理類別,當異常處理類別為預設報警類別時,會針對該異常點進行報警。目標預測模型是基於目標曲線中的標記樣本以及標記樣本對應的特徵信息進行訓練得到的,由於不同用戶對同一曲線的異常點所標記的異常處理類別可能不同、同一用戶對不同曲線的異常點所標記的異常處理類別也可能不同,因此對於不同的用戶或不同的曲線,可以得到相應的預測模型,進而可以對不同的用戶或不同的曲線,有針對性地進行報警,提高報警的準確率。
與上述的報警方法相對應,本發明實施例還提供了一種報警裝置。
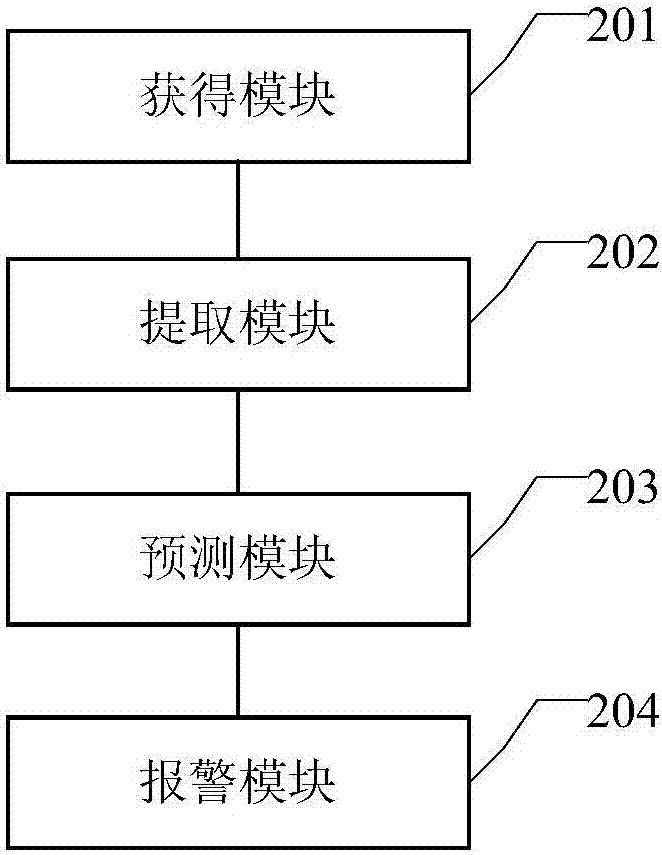
與圖1所示的方法實施例相對應,圖2為本發明實施例提供的一種報警裝置的結構示意圖,該裝置可以包括:
獲得模塊201,用於獲得目標曲線中預設時長內的目標曲線段,其中,所述目標曲線段中包含目標異常點;
提取模塊202,用於從所述目標曲線段中提取所述目標異常點對應的目標特徵信息;
預測模塊203,用於根據所述目標特徵信息和預先構建的所述目標曲線對應的目標預測模型,預測所述目標異常點所對應的目標異常處理類別,其中,所述目標預測模型是基於標記樣本以及所述標記樣本對應的特徵信息進行訓練得到的,所述標記樣本為所述目標曲線中標記有異常處理類別的異常點;
報警模塊204,用於當所述目標異常處理類別為預設報警類別時,針對所述目標異常點進行報警。
由以上可見,本實施例提供的報警裝置,對於目標曲線中的異常點,可以利用目標預測模型來預測該異常點的異常處理類別,當異常處理類別為預設報警類別時,會針對該異常點進行報警。目標預測模型是基於目標曲線中的標記樣本以及標記樣本對應的特徵信息進行訓練得到的,由於不同用戶對同一曲線的異常點所標記的異常處理類別可能不同、同一用戶對不同曲線的異常點所標記的異常處理類別也可能不同,因此對於不同的用戶或不同的曲線,可以得到相應的預測模型,進而可以對不同的用戶或不同的曲線,有針對性地進行報警,提高報警的準確率。
具體的,所述裝置還可以包括:
第一訓練模塊(圖中未示出),用於訓練所述目標預測模型;
其中,所述第一訓練模塊,可以包括:
第一獲得子模塊(圖中未示出),用於獲得所述目標曲線對應的標記樣本;
第一提取子模塊(圖中未示出),用於提取所述標記樣本對應的特徵信息;
第一訓練子模塊(圖中未示出),用於根據所述標記樣本的特徵信息和對應的異常處理類別,訓練所述目標預測模型。
具體的,所述裝置還可以包括:
第二訓練模塊(圖中未示出),用於訓練所述目標預測模型;
其中,所述第二訓練模塊,可以包括:
第二獲得子模塊(圖中未示出),用於獲得所述目標曲線對應的標記樣本和非標記樣本,其中,所述非標記樣本為未標記異常處理類別的異常點;
第二提取子模塊(圖中未示出),用於分別提取所述標記樣本和所述非標記樣本對應的特徵信息;
第二訓練子模塊(圖中未示出),用於根據所述非標記樣本的特徵信息、所述標記樣本的特徵信息和對應的異常處理類別,訓練所述目標預測模型。
具體的,所述裝置還可以包括:
第三訓練模塊(圖中未示出),用於在所述報警模塊針對所述目標異常點進行報警之後,在接收到用戶對所述目標異常點標記的異常處理類別時,將所述目標異常點作為標記樣本,對所述目標預測模型進行再次訓練,得到新的目標預測模型。
具體的,所述目標預測模型可以為隨機森林模型。
需要說明的是,在本文中,諸如第一和第二等之類的關係術語僅僅用來將一個實體或者操作與另一個實體或操作區分開來,而不一定要求或者暗示這些實體或操作之間存在任何這種實際的關係或者順序。而且,術語「包括」、「包含」或者其任何其他變體意在涵蓋非排他性的包含,從而使得包括一系列要素的過程、方法、物品或者設備不僅包括那些要素,而且還包括沒有明確列出的其他要素,或者是還包括為這種過程、方法、物品或者設備所固有的要素。在沒有更多限制的情況下,由語句「包括一個……」限定的要素,並不排除在包括所述要素的過程、方法、物品或者設備中還存在另外的相同要素。
本說明書中的各個實施例均採用相關的方式描述,各個實施例之間相同相似的部分互相參見即可,每個實施例重點說明的都是與其他實施例的不同之處。尤其,對於裝置實施例而言,由於其基本相似於方法實施例,所以描述的比較簡單,相關之處參見方法實施例的部分說明即可。
以上所述僅為本發明的較佳實施例而已,並非用於限定本發明的保護範圍。凡在本發明的精神和原則之內所作的任何修改、等同替換、改進等,均包含在本發明的保護範圍內。