一種基於監督局部子空間的人體姿態估計方法與流程
2023-05-10 04:56:36 3
本發明屬於計算機視覺技術領域,涉及人體姿態估計方法。
背景技術:
隨著當今社會人機互動技術的快速發展,人與機器之間自然的、多模態的交互成為人與機器之間交互的主要方式。人類首先遇到的問題就是需要機器能夠正確地認識和理解人的行為,正是在這種背景情況下,姿態估計被人們提出來了。它是目前人機互動的重要技術之一,能夠應用在人體運動分析、虛擬實境、智能監控、製作遊戲等領域,人體姿態估計潛在的巨大應用價值,引起了學術界、工業界的廣泛關注。現有的人體姿態估計工作可以分為無模型、基於模型的兩類方法。
無模型的人體姿態估計方法又可以劃分為基於學習的方法和基於樣本方法。
(1)基於學習的方法:使用訓練樣本學習到一個從圖像特徵空間到人體姿態空間的映射,若從新的觀測圖像中提取圖像特徵輸入到從訓練樣本中學習得到的映射之中,即可估計出對應的人體姿態。例如文獻Ankur Agarwal,Bill Triggs.3D human pose from silhouettes by relevance vector regression,Computer Vision and Pattern Recognition,vol.2,no.2,pp.882-888,2004中作者使用人體輪廓的形狀上下文作為特徵,採用相關向量機作為回歸器,用稀疏貝葉斯非線性回歸方法學習得到一個緊湊的映射,並將特徵空間映射到姿態空間,對輸入特徵直接輸出其相應的人體姿態相關的數值。在參考文獻Romer Rosales,Assilis Athitsos,Leonid Sigal,et al.3D Hand Pose Reconstruction Using Specialized Mappings,ICCV,vol.1,pp.378-385,2001中則是將輸入空間分成許多簡單的小區域,這裡的每個小區域都有相對應的映射函數,並使用了一種反饋匹配機制對姿態進行重構,由於訓練數據範圍較小,映射函數有較好的擬合效果,所以這種方法能夠很大程度上提高估計準確度。雖然基於學習的方法執行速度快,不需要專門初始化,具有較小的存儲代價,且無需保存樣本資料庫,但是基於學習方法的估計結果往往受訓練樣本規模的影響較大。
(2)基於樣本的方法:首先需要建立模板庫,這個模板庫中存儲了大量特徵以及人體姿態的訓練樣本。當輸入估計測試圖像時,提取相應特徵再用某種度量與模板庫裡的樣本進行比較,即找到和待估計圖像相似的訓練樣本,最後使用最近鄰算法估計測試圖像的人體姿態。人體姿態十分複雜,不同的姿態所投影得到的圖像特徵描述符可能非常相似,即特徵描述符與姿態空間之間是一對多的關係。例如,在文獻Nicholas R.Howe.Silhouette Look up for Automatic Pose Tracking,Computer Vision and Pattern Recognition Workshop,pp.15-22,2004中作者從模板資料庫中檢索出多個接近的候選樣本,再用時域相似性約束得到這些樣本中的最佳匹配。基於樣本的方法必須要有足夠的樣本覆蓋人體所有可能的姿態,但是因為人體姿態過於複雜,有限的樣本難以覆蓋整個人體姿態空間,因此基於樣本的方法只適用於特定姿態的估計。
基於模型的方法將人體劃分成一些相互聯繫的部件,用圖模型表示人體架構,並使用圖推理方法優化人體姿態,即在進行人體姿態估計的過程中使用先驗的人體模型,並且模型的參數也隨著當前狀態的變化而更新。基於模型的人體姿態估計中主要由圖模型、優化算法、部件的觀測模型三部分組成。圖模型用來表示部件連接之間的約束關係,其中樹模型是最常用的模型,樹模型是根據部件之間的連接情況來定義的,所以相對直觀。觀測模型對人體部件的表觀建立模型,它是用來度量人體部件的圖像相似度,從而確定人體部件的具體位置。
優化算法是利用建立好的圖模型和部件觀測模型來估計得到人體姿態。其中置信度傳播是較為常用的算法,但是由於在人體姿態估計中,人體部件的狀態向量維數相對較高,直接使用置信度傳播算法不現實。在文獻Deva Ramanan.Learning to parse images of articulated bodies,Neural Information Processing Systems,pp.1129-1136,2006中作者提出了和積算法,它繼承了消息傳遞機制,但通過引入因子圖將全局的概率密度函數分解成若干個局部概率密度函數的乘積,將算法使用範圍拓展到了無向圖(比如條件隨機場)上,但和積算法仍然有一個限制,它只有在無環的因子圖上才可以保證算法收斂。
基於模型的人體姿態估計方法具有較強的通用性,同時也減少了訓練樣本的存儲代價。對於人體模型,人們可以方便地利用先驗知識來解決自遮擋以及其他遮擋問題,估計準確度相對較高,適用於人體姿態分析等領域的應用,但是缺點也比較明顯:(1)優化速度相對較慢,一般不能滿足實時性要;2)初始化的好壞對姿態優化的結果影響很大。
技術實現要素:
本發明的任務是提供了一種基於監督局部子空間的人體姿態估計方法,它屬於無模型中基於學習的估計方法,該方法從稀疏和非均勻採樣的訓練集中建立局部線性模型,很好地解決了以往學習算法遭受的通用性和魯棒性問題,減少了估計過程中受稀疏和非均勻訓練樣本對估計結果的影響。並且在算法訓練過程中對基礎算法進行了一定的改進,在保證精確度的同時,很大程度上提高了運算效率,因此它能更好地實現實時人體姿態估計的任務。
為了方便地描述本發明內容,首先對一些術語進行定義。
定義1:人機互動。人機互動是一門研究系統與用戶之間的交互關係的學科。系統可以是各種各樣的機器,也可以是計算機的系統和軟體。人機互動界面通常是指用戶可見的部分。用戶通過人機互動界面與系統交流,並進行操作。
定義2:人體姿態。人體的姿態分二維和三維兩種情況。二維人體姿態是指人體各關節在圖像二維平面分布的一種描述,通常用線段或者矩形來描述人體各關節在圖像二維平面的投影,線段的長度和角度分布或者矩形的大小和方向就代表了人體二維姿態,二維姿態不存在二義性問題;三維人體姿態是指人體目標在真實三維空間中的位置和角度信息,通常用關節樹模型來表述估計的姿態,也有一些研究者採用更加複雜的模型,三維姿態的獲取通常是通過模型反投影的方法。
定義3:過擬合。在機器學習中通過訓練樣本進行分類或回歸模型訓練時,模型得到的輸出值和真實目標值基本一致,但在測試樣本集上模型得到的輸出值和目標值相差卻很大,這類為了得到一致假設而使假設變得過度複雜的現象稱為過擬合。
定義4:前景。前景是指圖像中靠近鏡頭位置的人物或景物。
定義5:背景。背景是指圖像中主體背後的景物,能表現任務和事物所處的時空環境。
定義6:形狀上下文特徵。形狀上下文在2002年提出的,最初用於檢測物體形狀之間匹配點。形狀上下文描述子可充分地利用像素點周圍的上下文信息,對圖像內部區域的形狀特徵進行很好地描繪,在形狀匹配問題中,具有非常好的魯棒性。該描述子的基本原理是:對於給定的一幅圖像,首先用邊緣特徵提取算法(如Canny邊緣檢測器)檢測出它的邊緣信息;然後對邊緣像素點進行採樣,提取出一系列特徵點(這些特徵點可以是內部邊緣上的點,也可以是外部邊緣上的點,並且不需要是邊緣曲線上曲率最大處的點,可以通過均勻採樣獲得。);針對每一個特徵點,以其為原點建立起極坐標系,根據角度的變化將其周圍的空間劃分成一系列扇形區域,同時根據半徑的大小將周圍空間劃分成一系列同心圓,統計分布每一個區域的特徵點的個數;(見圖1中(c))最後根據統計得到的數據建立相應的向量,即為相應像素點形狀上下文特徵向量。
定義7:K均值算法。K均值算法是一種基於距離的迭代式算法,它將m個觀測樣本分類到k個聚類中,以使得每個觀察樣本距離它所在的聚類中心點比距離其它聚類中心點的距離更小。具體過程為:
1)假設樣本空間為其中m表示樣本的個數,n表示每一個訓練樣本的維數。然後從訓練樣本空間中隨機選取k個聚類中心點,分別為
2)重複下面的過程直至收斂:
對於每一個樣本i∈[1,m],計算它應該屬於哪一個聚類:
對於每一個聚類j∈[1,k],重新計算該聚類的中心:
其中,1{ci=j}為示性函數,當ci=j條件滿足時函數值等於1,否則為0。經過若干次迭代後,算法達到收斂即聚類中心不再變化或者變化很小了,測試可以得到我們想要的k個聚類中心點以及每個樣本所屬的聚類。
定義8:BVH格式。BVH文件包含角色的骨骼和肢體關節旋轉數據。BVH是一種通用的人體特徵動畫文件格式,廣泛地被當今流行的各種動畫製作軟體支持。通常可從記錄人類行為運動的運動捕獲硬體獲得。
按照本發明的一種基於監督局部子空間的人體姿態估計方法,它包含以下步驟:
步驟1:對需要進行人體姿態估計的原始圖像,去除背景並得到人體輪廓信息,達到突出前景的作用;
步驟2:對步驟1獲得圖像進行二值化,再對上述人體輪廓圖片提取形狀上下文特徵,其中提取形狀上下文特徵的算法相關參數分別是採樣點個數為200,圓形極坐標均分為12個扇形區域,半徑分為5份;因此對於每一個訓練樣本,它所對應的形狀上下文特徵為一個60*200維矩陣即200個60維的形狀上下文向量;
步驟3:採用降維操作將每張圖片的形狀上下文特徵降到100維獲得圖像特徵X;
步驟4:將步驟3獲得的圖像特徵X通過姿態角度Θ進行局部子空間重構,具體公式為
其中,f是人體姿態空間到圖像特徵空間的映射函數,是指第i個局部子空間對應的參數集合,是子空間的中心,是切線空間的主要成分,為第i個子空間中心所對應的人體姿態角度,m為子空間的數量,d為樣本的輸入特徵維數;
步驟5:將步驟4中的近似函數f(Θ)進行一階泰勒展開;由某一局部子空間對每個訓練樣本進行重構,如果姿態角度為θp的訓練樣本xp在參數決定的子空間中,就將xp近似成:
xp≈ci+Gi△θpi
其中,同時定義且N(θp)表示鄰近θp的子空間索引序號;
步驟6:根據步驟5確定出該算法的誤差函數為
其中第一項為每個訓練樣本(xp,θp)由近鄰子空間重構所造成的重構誤差的加權和,近鄰子空間的選取依據是子空間中心所對應的姿態角度與θp歐氏距離的大小關係;第二項進行正則化,通過近鄰子空間將每個子空間的均值進行重構;這個步驟確保了子空間參數的平穩變化,並且能夠從稀疏的非均勻的數據中估計出來;其中λ=(n/m)2是一個正則化參數,它等於訓練樣本個數n除以子空間個數m的平方,wpi定義了每個近鄰子空間對數據樣本重構的權重,具體公式為:
其中,是測量角度θp和之間相似性的正值函數,函數表達式為:
步驟7:令表示子空間的中心,表示子空間的基,其中d是輸入的維數,在本專利中d為100,m為子空間的個數,之後採用閉合解算法優化計算得到C和G;
步驟8:對於一個新的測試樣本點的圖像特徵xt,為了提高效率;本算法採用如下兩個步驟從子空間中確定該測試樣本的近鄰子空間:
(1)首先找出2|Γt|個候選子空間;|Γt|為我們設定的近鄰子空間個數,一般為2~16。這些子空間的中心ci在輸入空間中最接近xt,然後根據公式算出θti,其中為選取出的某近鄰子空間的基,為選取出的某近鄰子空間的中心;θti表示對於一個新的測試數據點xt它根據子空間i重構所得到的姿態角度θti;
(2)比較重構誤差的大小,從2|Γt|個候選中選擇出|Γt|個近鄰子空間,並將最小重構誤差所對應的θti,記作測試數據點xt對應的姿態角度θt0,其中重構誤差的公式為:
最後,最佳的θt通過最小化公式得到,其中權重wti由上述θt0算出,具體公式為最後可以得到測試樣本點xt對應的最佳姿態角度θt:
步驟9:將得到的θt解析成BVH格式的文本並表示成相應人體姿態圖像。
進一步的,所述步驟3的具體步驟為:
首先將所有訓練樣本中的形狀上下文特徵矩陣從左到由合併在一起,然後採用K均值算法得到100個60維的向量,我們稱這些向量為數據空間的聚類中心。最後每個樣本的200個形狀上下文向量帶有高斯權重地向這100個聚類中心進行投票,具體的投票方式為形狀上下文與某個聚類中心的歐氏距離越近就越趨於1,越遠就趨於0。最後可以得到後面步驟所需要的圖像特徵X,其中第i列對應第i個訓練樣本的圖像特徵且每個樣本的特徵為100維。
進一步的,所述步驟7的具體步驟為:
具體做法為:用U=[C,G]代替C和G,則可以將步驟6中的誤差函數改寫為:
其中e∈11×d,Wp=diag{wpi,i∈Γp},Wj=diag{wji,i∈Γj},另外,是一個0-1選擇矩陣,該矩陣對角線上非零元素的序號為訓練樣本xp對應的近鄰子空間的序列,其餘元素均為0,例如訓練樣本xp對應的近鄰子空間的序號分別為2,4,5,6,則在中有且僅有元素S22,S44,S55,S66為1,其他元素均為0;也是一個0-1選擇矩陣,該矩陣對角線上非零元素的序號為每個子空間中心cj對應的近鄰子空間的序列;s為一個m×m的單位矩陣,sj為一個m維列向量,I是一個m×m的單位矩陣,E(U)是關於U的一個凸二次函數。最後得到U的解的表達式為:U=A(B(x)+B(c))-1
其中,A,B(x),B(c),C,G分別為:
C=U[1:d,1:m]
G=U[1:d,1+m:56×m]
通過數次迭代優化後,C和G能迅速收斂,C和G此時得到和的近似最優解。
本發明的創新之處在於:
本專利提出了在人體姿態估計問題中引入基於監督局部子空間的估計方法,它屬於無模型中基於學習的估計方法,該算法從稀疏和非均勻採樣的訓練集中建立局部線性模型,很好地解決了以往學習算法遭受的通用性和魯棒性問題,減少了估計過程中受稀疏和非均勻訓練樣本對估計結果的影響。同時提出了一種閉合解算法優化局部子空間參數,比之前的交替優化算法更快地達到收斂,在保證精確度的同時,很大程度上提高了運算效率,因此它能更好地實現實時人體姿態估計的任務。此外,由於該算法是一個生成的模型,它也能夠很好的處理圖像噪聲。
附圖說明:
圖1形狀上下文特徵描述;
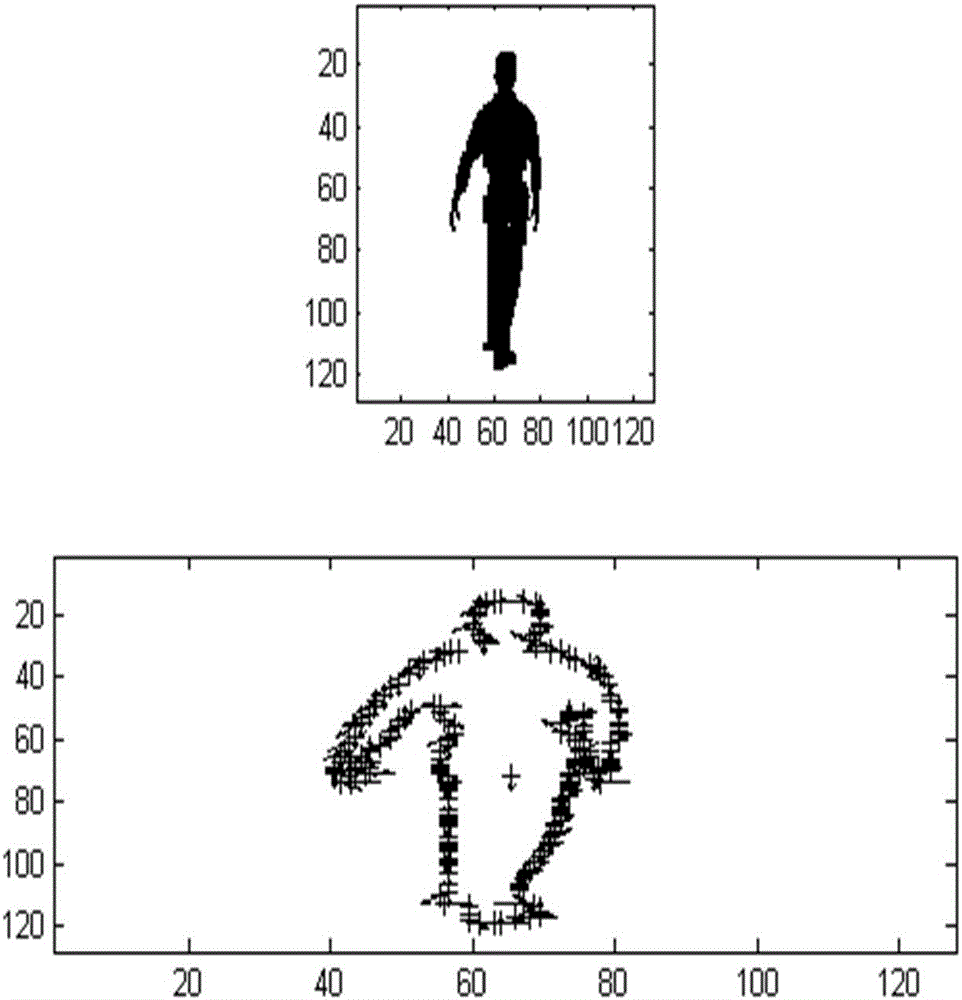
圖2對人體輪廓提取形狀上下文特徵時200個採樣點的分布;
圖3去除背景後的人體輪廓圖;
圖4姿態估計結果展示。
圖1中(c)圖表示處於極坐標原點的樣本點的形狀信息,周圍與它相鄰的點(在極坐標覆蓋的範圍之內)落於不同的小格子,就表示不同的相對向量,這些相對向量就成為這個點的形狀上下文;同時圖(a)和圖(b)中菱形點和方塊點,他們的形狀上下文直方圖(d)、(e)圖,基本上一致,而三角形點的形狀上下文就有不同,這和我們實際的觀察基本上是一致的。圖4中左邊為我們輸入的人體輪廓信息,右邊為我們估計並解析出的BVH格式的人體姿態。
具體實施方式:
結合說明書附圖對本發明的一種基於監督局部子空間的人體姿態估計方法進行說明,它包含以下步驟:
步驟1:對需要進行人體姿態估計的原始圖像,去除背景並得到人體輪廓信息,達到突出前景的作用(見圖3);
步驟2:對上述人體輪廓圖片提取形狀上下文特徵,其中提取形狀上下文特徵的算法相關參數分別是採樣點個數為200(見圖2),圓形極坐標均分為12個扇形區域,半徑分為5份;因此對於每一個訓練樣本,它所對應的形狀上下文特徵為一個60*200維矩陣即200個60維的形狀上下文向量;
步驟3:採用降維操作將每張圖片的形狀上下文特徵降到100維獲得圖像特徵X;具體操作為:首先將所有訓練樣本中的形狀上下文特徵矩陣從左到由合併在一起,然後採用K均值算法得到100個60維的向量,我們稱這些向量為數據空間的聚類中心。最後每個樣本的200個形狀上下文向量帶有高斯權重地向這100個聚類中心進行投票,具體的投票方式為形狀上下文與某個聚類中心的歐氏距離越近就越趨於1,越遠就趨於0。最後可以得到後面步驟所需要的圖像特徵X,其中第i列對應第i個訓練樣本的圖像特徵且每個樣本的特徵為100維。
該步驟中在選取100個中心點過程中,可以用任意的聚類算法,我們採用K-Means算法一是因為它運行簡單快速,而是因為它為後面形狀上下文特徵向量進行投票中的高斯權重提供了相應的均值u和方差σ2。
步驟4:將步驟3獲得的圖像特徵X通過姿態角度Θ進行局部子空間重構,具體公式為
其中,f是人體姿態空間到圖像特徵空間的映射函數,是指第i個局部子空間對應的參數集合,是子空間的中心,是切線空間的主要成分,為第i個子空間中心所對應的人體姿態角度,m為子空間的數量,d為樣本的輸入特徵維數;
步驟5:將步驟4中的近似函數f(Θ)進行一階泰勒展開;由某一局部子空間對每個訓練樣本進行重構,如果姿態角度為θp的訓練樣本xp在參數決定的子空間中,就將xp近似成:
xp≈ci+Gi△θpi
其中,同時定義且N(θp)表示鄰近θp的子空間索引序號;
步驟6:根據步驟5確定出該算法的誤差函數為
其中第一項為每個訓練樣本(xp,θp)由近鄰子空間重構所造成的重構誤差的加權和,近鄰子空間的選取依據是子空間中心所對應的姿態角度與θp歐氏距離的大小關係;第二項進行正則化,通過近鄰子空間將每個子空間的均值進行重構;這個步驟確保了子空間參數的平穩變化,並且能夠從稀疏的非均勻的數據中估計出來;其中λ=(n/m)2是一個正則化參數,它等於訓練樣本個數n除以子空間個數m的平方,wpi定義了每個近鄰子空間對數據樣本重構的權重,具體公式為:
其中,是測量角度θp和之間相似性的正值函數,函數表達式為:
步驟7:令表示子空間的中心,表示子空間的基,其中d是輸入的維數,在本專利中d為100,m為子空間的個數,之後採用閉合解算法優化計算得到C和G;
具體做法為:用U=[C,G]代替C和G,則可以將步驟6中的誤差函數改寫為:
其中e∈11×d,Wp=diag{wpi,i∈Γp},Wj=diag{wji,i∈Γj},另外,是一個0-1選擇矩陣,該矩陣對角線上非零元素的序號為訓練樣本xp對應的近鄰子空間的序列,其餘元素均為0,例如訓練樣本xp對應的近鄰子空間的序號分別為2,4,5,6,則在中有且僅有元素S22,S44,S55,S66為1,其他元素均為0;也是一個0-1選擇矩陣,該矩陣對角線上非零元素的序號為每個子空間中心cj對應的近鄰子空間的序列;s為一個m×m的單位矩陣,sj為一個m維列向量,I是一個m×m的單位矩陣,E(U)是關於U的一個凸二次函數。最後得到U的解的表達式為U=A(B(x)+B(c))-1
其中,A,B(x),B(c),C,G分別為:
C=U[1:d,1:m]
G=U[1:d,1+m:56×m]
通過數次迭代優化後,C和G能迅速收斂,C和G此時得到和的近似最優解。
步驟8:對於一個新的測試樣本點的圖像特徵xt,為了提高效率;本算法採用如下兩個步驟從子空間中確定該測試樣本的近鄰子空間:
(1)首先找出2|Γt|個候選子空間;|Γt|為我們設定的近鄰子空間個數,一般為2~16。這些子空間的中心ci在輸入空間中最接近xt,然後根據公式算出θti,其中為選取出的某近鄰子空間的基,為選取出的某近鄰子空間的中心;θti表示對於一個新的測試數據點xt它根據子空間i重構所得到的姿態角度θti;
(2)比較重構誤差的大小,從2|Γt|個候選中選擇出|Γt|個近鄰子空間,並將最小重構誤差所對應的θti,記作測試數據點xt對應的姿態角度θt0,其中重構誤差的公式為:
最後,最佳的θt通過最小化公式得到,其中權重wti由上述θt0算出,具體公式為最後可以得到測試樣本點xt對應的最佳姿態角度θt:
步驟9:將得到的θt解析成BVH格式的文本並表示成相應人體姿態圖像。(見圖3)
根據本發明的方法,首先利用Matlab語言編寫基於監督局部子空間學習算法的程序;接著選取若干圖片對算法進行訓練,求解子空間中心和基向量參數;最後將需要進行姿態估計的含人體的圖片輸入到算法中,即可得到由該算法預測出的人體姿態。本發明的方法,可以用於自然場景中人體的姿態估計,如行為檢測,人機互動。最後我們將我們的算法在Poser dataset資料庫上進行測試,該數據集由選取其中的1691張作為訓練樣本,418張為測試樣本。當在算法中選擇子空間個數為61,近鄰子空間個數為8時,在該數據集上能得到最佳的測試誤差為7.125°。