基於緊湊型神經網絡的深度學習模型的交通標誌識別系統的製作方法
2023-09-12 00:33:05 4
本發明涉及一種計算機視覺和機器學習技術,屬於目標檢測和識別的方法,具體涉及一種基於緊湊型神經網絡的深度學習模型的交通標誌識別方法和系統,適用於圖像或視頻中的交通標誌的檢測和識別。
背景技術:
近年來,無人駕駛發展愈發成熟,而輔助駕駛已經進入實用階段,交通標誌的識別是目前智能輔助輔助駕駛系統最重要的模塊之一,並且是無人駕駛技術的重要組成部分。
交通標誌識別模塊通常包含定位檢測和分類識別兩個方面。
在交通標誌的定位方面,可以定位出可能存在交通標誌的區域。已有成果均採用基於顏色的方法實現圖像分割,適合於交通標誌圖像分割的顏色空間包括rgb空間、hsi空間等,而本發明運用的是rgb空間。
在交通標誌的識別方便,絕大部分學者均採用傳統的卷積神經網絡識別分類交通標誌,但是有著模型大,計算代價高,不適合移植至移動平臺的缺陷。
因此,計算代價低、模型可移植、模型體積小、準確率高的交通標誌識別模塊在無人駕駛和輔助駕駛中發揮著重要的作用。
技術實現要素:
本發明的目的是為了克服現有基於傳統深度學習的交通標誌識別系統複雜高、參數多、難以移植至移動平臺等缺陷。
本發明改進的技術問題是傳統卷積神經網絡的計算量大,導致在移動平臺上識別速度慢的問題,提出了一種基於緊湊型神經網絡的深度網絡模型的交通標誌識別方法。
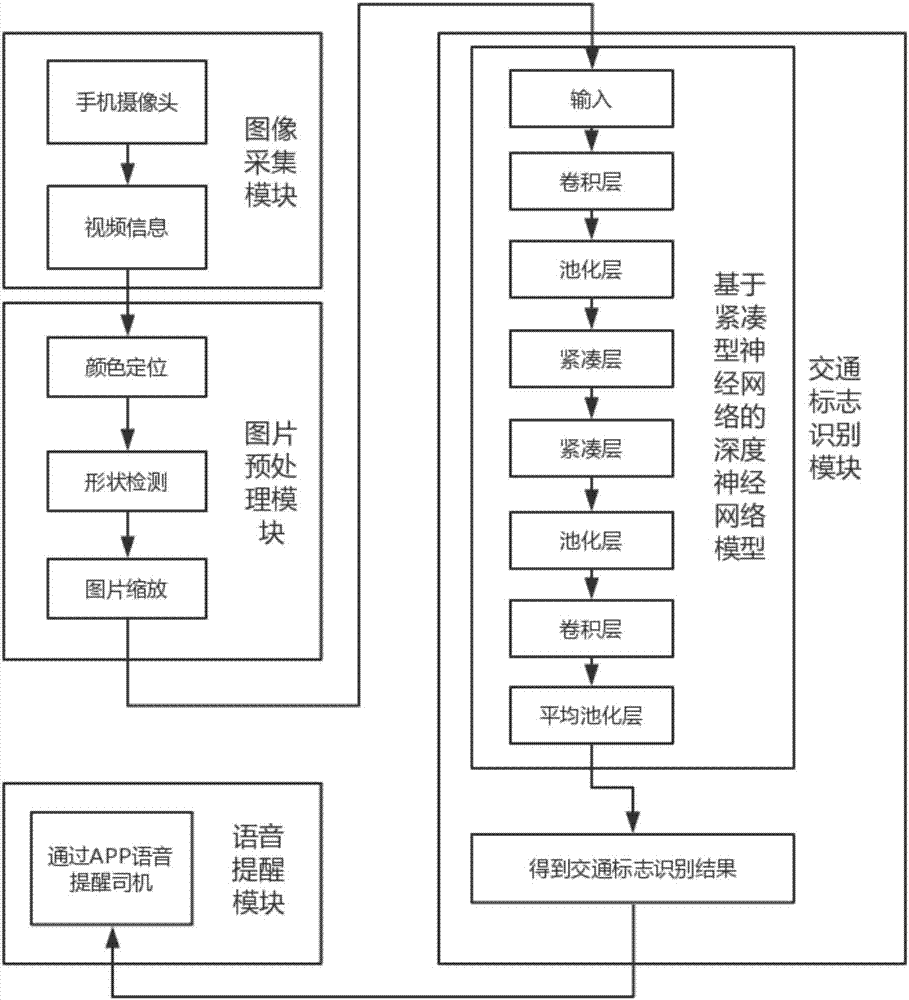
本發明技術方案包含圖像採集、圖片預處理、交通標誌識別、語音提醒四個模塊,如圖1。
1.圖像採集部分
該系統移植至移動平臺(android平臺),通過手機攝像頭或者車載行車記錄儀獲取每幀圖像輸入圖片預處理模塊。
2.圖片預處理部分
圖片預處理分為三個模塊:顏色定位、形狀檢測、圖片縮放。
顏色定位:利用交通標誌的顏色特徵(紅、黃、藍三色)可初步將交通標誌提取出來。
形狀檢測:在顏色定位的基礎上,利用交通標誌的形狀特徵(三角形、圓形、矩形),檢測出包含交通標誌的區域並截取出來。
圖片縮放:為了規範截取的圖片,將其統一為32*32的尺寸,並輸入交通標誌識別模塊,處理後如圖2所示。
3.交通標誌識別部分
交通識別模塊的技術方案是基於緊湊型神經網絡的深度學習網絡並利用遷移學習使其適應交通標誌識別。緊湊型神經網絡的設計原理為利用1x1的卷積核代替3x3卷積核,減少9倍參數輸入,其核心構件為緊湊層,即將一層卷積層用壓縮層和擴展層代替,壓縮層為1x1卷積層,擴展層為1x1與3x3組合得到的組合層。為了適應交通標誌識別,將圖3改進為如圖4所示網絡架構。
4.語音提醒部分
該網絡具有速度快,體積小,準確率符合基本應用標準的特點,適用於移動平臺,並嵌入app當中,將分類識別出的交通標誌已語音提醒的方式提醒司機。
本發明的優點和積極效果在於:
本發明提供一種基於緊湊型神經網絡的深度學習模型的公路交通標誌自動識和提醒系統,此系統運用緊湊型神經網絡進行遷移學習,有很高的實時性和很低的運算量,可移植至移動手機平臺,只需利用手機便可實現基本的公路交通標誌識別和語音提醒,避免司機行車過程中疏忽導致的事故。
本發明的前期圖像預處理可以降低深度學習的輸入維數和圖像體積,並突出交通標誌的特徵。
本發明的深度神經網絡模型在使用訓練集為gtsrb(德國交通標誌識別基準,germantrafficsignrecognitionbenchmark)中的訓練集,包含訓練圖片39,209張,測試圖片12630張)時,參數比傳統的模型參數少上百倍,訓練完成的權重參數文件只有4mb左右卻達到93.5%的測試精度。
本發明具有識別交通標誌的種類多、精度高、實時性好等優勢,降低了光照變化、顏色褪色、運動模糊、複雜的背景等因素對圖像識別的影響,提高了抗幹擾能力,識別準確率高,誤識別率低。
附圖說明
下面結合附圖和實施例對本發明進一步說明。
圖1本發明交通標誌識別系統的模塊示意圖。
圖2本發明的圖片預處理前後對比圖。
圖3本發明的緊湊層結構示意圖。
圖4本發明的基於緊湊型神經網絡的深度神經網絡架構圖。
具體實施方式
下面結合附圖和實施例對本發明的技術方案進行詳細說明。
如圖所示,本發明的基於緊湊型神經網絡的深度學習模型的交通標誌識別方法和系統包括圖像採集、圖片預處理、交通標誌識別、語音提醒四個模塊。其中,圖像採集主要負責採集包含交通標誌的圖像;圖像預處理模塊主要負責檢測獲取的圖像中的交通標誌並把其區域提取出來,在進行統一尺寸的縮放;交通標誌識別模塊為核心模塊,利用遷移學習後的緊湊型神經網絡進行交通標誌識別分類;語音提醒模塊負責將識別出的交通標誌提醒司機。
模塊一:圖像採集模塊。
本發明實施例中採用自主研發的android手機app,該app使用手機自帶的攝像頭以每秒20-30幀的速度進行錄像操作並將視頻文件保存下來,並將保存的圖片實時傳輸至預處理模塊。
模塊二:圖片預處理模塊。
本發明預處理模塊分為三部分,分別為顏色定位、形狀檢測、圖片縮放三個子模塊,並已此步驟進行圖片預處理。
步驟一:首先將獲取到的每幀圖片進行高斯模糊處理,利用二維高斯函數計算圖片矩陣權重(x,y為周邊坐標對於中心像素的相對坐標,σ為模糊半徑):
計算圖片的高斯模糊值:將得到權重矩陣與原有的色值矩陣相乘,得到高斯模糊後的中心像素色值。
設置紅黃藍三色的閥值,根據閥值構建掩膜,並與高斯模糊處理後的圖片進行像素相加的位運算,運用大律法進行二值化處理,得到藍(紅或黃)色的主體位置,即顏色定位。
步驟二:首先定義與交通標誌形狀大小相符的結構元素(矩形、三角形、圓形),得到形態學內核,再結合此內核利進行形態學閉運算(先膨脹後腐蝕),計算形態學梯度(膨脹圖與腐蝕圖之差)保留輪廓。
最後提取所得到的輪廓並利用多邊形(矩形,三角形,圓形)逼近算法得到最大矩形的輪廓,以其為標準截取出矩形圖像,排除誤差的情況下此圖像包含識別所需的交通標誌。其次步驟三:利用雙線性插值法對圖像進行縮放,得到統一的尺寸(由相鄰的四像素計算)
(dst為輸出圖像,src為輸入圖像,對於一個目的像素,設置坐標通過反向變換得到的浮點坐標為(i+u,j+v),其中i、j均為浮點坐標的整數部分,u、v為浮點坐標的小數部分,則這個像素得值dst(i+u,j+v)可由輸入圖像中坐標為(i,j)、(i+1,j)、(i,j+1)、(i+1,j+1)所對應的周圍四個像素的值決定)
dst(i+u,j+v)=(1-u)*(1-v)*src(i,j)+(1-u)*v*src(i,j+1)+u*(1-v)*src(i+1,j)+u*v*src(i+1,j+1)
模塊三:交通標誌識別模塊。
步驟一:基於緊湊型神經網絡的深度神經網絡模型構建。
本模型的核心層為緊湊層,由1x1卷積核得到的卷積層(壓縮層)分別接上1x1卷積核的卷積層與3x3卷積核得到的卷積層,並組合此兩卷積層得到擴展層,如圖。
由於圖片預處理模塊得到的圖像為32x32像素,輸入為32x32x3的像素矩陣。
第一層為卷積層,卷積核3x3,步長為1,有效填充,得到的卷積層為28x28x36,並用relu函數激活。
第二層為池化層,2x2最大池化得到14x14x36矩陣。
第三層為緊湊層,首先利用壓縮層,將14x14x36輸入1x1的卷積核,深度為16,步長為1,有效填充,得到14x14x16的壓縮層,其次分別用1x1卷積核和3x3卷積核進行深度為32的擴展,進行組合得到14x14,x64的fire層,並用relu函數激活。
第四層為緊湊層,將第三層輸入1x1的卷積核進行深度為64的壓縮,再分別通過1x1x72、3x3x72的卷積核進行擴展並組合得到14x14x144的fire層,relu函數激活。
第五層為池化層,通過2x2的最大池化得到7x7x144的池化層。
第六層為卷積層,通過1x1的卷積核,深度為43,步長為一,有效填充,得到7x7x43的壓縮卷積層。
第七層為平均池化層,通過7x7x43的平均池化操作得到1x1x43的平均池化層。
通過平鋪操作轉化為43的1維矩陣並與偏置相加得到43個類型的輸出。
模型框架圖3,步驟二:訓練模型。
訓練集為gtsrb(德國交通標誌識別基準,germantrafficsignrecognitionbenchmark)中的訓練集,包含訓練圖片39,209張,測試圖片12630張。
訓練集並不需要圖片預處理。
初始化參數,將各層的權重通過正態分布的隨機初始化,均值為0,標準差為0.1,並設定隨機梯度下降學習率為0.0009,循環次數為25。
訓練組為每次隨機選取的128個樣本。
訓練樣本(x,y)分別為輸入和結果的比對標準。
將訓練樣本輸入至上述構建的基於緊湊型神經網絡的深度網絡模型,得到最終的43個分類結果。
保存訓練完成的模型。
步驟三:測試模型。
將測試集用於測試保存的模型,檢測模型的準確率,並與個傳統模型比對。
模塊四:語音提醒模塊。
首先,連接圖像採集、圖片預處理、語音提醒模塊。其次,將得到的預處理後的圖像輸入訓練好的模型,得出結果,並通過app軟體的語音提醒功能提醒司機。
最後,司機可以在歷史記錄中反饋結果,用於修改優化模型。
以上對本發明的具體實施例進行了描述。需要理解的是,本發明並不局限於上述特定實施方式,本領域技術人員可以在權利要求的範圍內做出各種變形或修改,這並不影響本發明的實質內容。