一種基於Lucene的支持表達式的自定義相關度排序算法的製作方法
2023-06-24 21:39:51 2
本發明屬於計算機技術領域,具體是一種基於lucene的支持表達式的自定義相關度排序算法。
背景技術:
目前,從海量信息中獲取有用信息的關鍵技術是信息檢索,信息檢索的核心問題就是預測文檔的相關度,並按照相關度對各文檔進行排序。一般而言,排在最頂端的文檔被認為最相關;因此,相關度的計算和排序算法就成為信息檢索的核心。
典型的檢索系統的排序技術主要有詞頻統計和詞位置加權排序算法、基於用戶反饋的directhit算法、pagerank超連結分析排序算法和hits排序算法。這些典型的相關度排序算法主要基於全文本分詞或其在網絡中的關注程度來對文檔進行排序,適用於普遍的全文本搜索,不能滿足用戶特定的需求。
隨著數據的爆炸式增長,大數據系統往往根據數據本身的特徵,分為不同的欄位進行存儲,所以在文檔檢索排序時,單單使用全文本相關度排序已不能得到用戶想要的結果,必須考慮更多的因素(即欄位)進行排序,並應該為用戶提供更為多樣靈活的相關度排序算法。
技術實現要素:
本發明為了解決現有傳統大數據系統欄位間運算支持的函數種類缺乏多樣性,欄位間運算和自定義排序缺乏靈活性的問題,提供了一種基於lucene的支持表達式的自定義相關度排序算法。
具體步驟如下:
步驟一、搭建算法運行所需的分布式環境,包括若干數據節點,一個管理節點和一個元數據節點;
數據節點存儲各欄位的數據,底層採用lucene索引作為存儲引擎;管理節點對數據存儲和查詢過程中的任務進行管理;元數據節點存儲各數據節點的數據分布情況和各欄位的類型等信息。
步驟二、對用戶發送的某個文檔或者文章,將內容劃分為不同欄位,並構造表達式作為相關度排序請求;
用戶將文檔或者文章中的不同內容存儲到不同的欄位中,在進行全文檢索時,不同的欄位作為不同的參數,構造不同內容的表達式作為相關度排序請求;每個文檔的相關度排序請求為一個或者多個。
步驟三、針對某個相關度排序請求,管理節點進行解析後同時發送給不同數據節點,每個數據節點分別獲取該請求的欄位信息;
欄位信息包括該欄位的數據類型和欄位名;文本類型的欄位還包括該欄位存儲時所採用分詞器。
管理節點解析該相關度排序請求,具體為:判斷表達式是否合法,如果合法,將表達式和作為參數的欄位名發送到各數據節點;否則,提示錯誤,結束。
表達式包括運算符表達式和函數表達式,針對運算符表達式,首先,判斷運算符中操作數的個數是否合法,然後,將非數學數字的操作數作為未知參數,進行預運算,如果預運算通過,則該運算符表達式合法;
針對函數表達式,根據函數對照表,匹配函數表達式的函數名跟對照表中的函數名是否一致,且該函數表達式的所有欄位名參數與元數據節點中的元數據表中的欄位名稱一一對比,如果全部對應,則該函數表達式合法。
步驟四、每個數據節點根據欄位信息的不同欄位名參數,在各自的數據節點中查詢對應的不同欄位數據;
步驟五、每個數據節點把各自的欄位數據分別帶入表達式,並調用函數對照表中對應的函數進行計算,將計算結果放入每個數據節點對應的堆中;
步驟六、對各堆中的相關度進行排序並調整,選擇最終排序結果。
具體為:
步驟601、針對某個相關度排序請求對應的各個堆,從每個堆中選出各自的最大值;
步驟602、將所有最大值合併,再選擇出其中的最大值作為最終結果;
步驟603、將最終結果從對應的堆中刪除,並在該堆中重新選擇最大值,與其餘堆的最大值進行合併;
步驟604、重複步驟602,直至得到符合用戶要求的最終結果。
步驟七、將最終自定義表達式的排序結果返回給用戶。
本發明的有益效果在於:
本發明提供了一種靈活的自定義相關度排序算法,支持多欄位間進行表達式計算,並按照其進行排序,優於單純的文檔打分排序機制,而且該發明支持更多的函數計算,且該算法適用於分布式的大數據平臺上。
附圖說明
圖1為本發明一種基於lucene的支持表達式的自定義相關度排序算法的示意圖;
圖2為本發明元數據結構的示意圖;
圖3為本發明管理節點進行表達式解析的程序流程圖;
圖4為本發明一種基於lucene的支持表達式的自定義相關度排序算法流程圖。
具體實施例
下面結合附圖對本發明的具體實施方法進行詳細說明。
本發明一種基於lucene的支持表達式的自定義相關度排序算法,包括四部分:解析表達式,計算表達式,排序相關度和整合結果;對應採用四個模塊:表達式解析模塊,表達式計算模塊,相關度排序模塊和結果整合模塊;
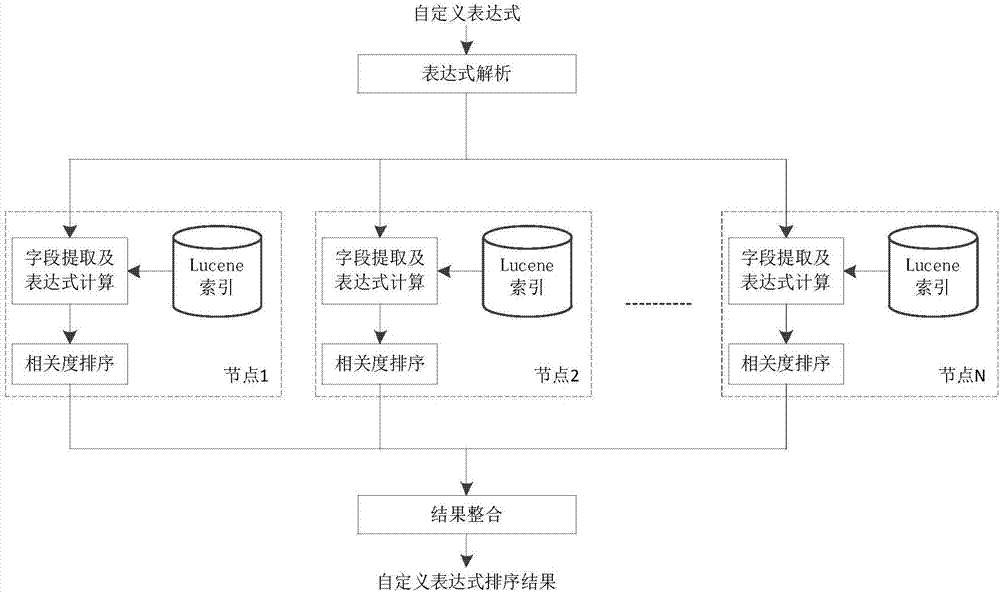
如圖1所示,首先,用戶輸入自定義表達式後,表達式解析模塊對用戶輸入的表達式進行合法性檢查,並轉化為系統可以計算的形式;
具體是:用戶輸入的表達式被管理節點進行解析,解析完成後,管理節點將表達式和表達式中參數(欄位名)發送給各個數據節點;
然後,各數據節點根據欄位名在底層的lucene索引中提取欄位所對應的數據,並將欄位數據帶入表達式,應用表達式計算模塊進行計算;
進而,相關度排序模塊對各數據節點中表達式的計算結果進行排序;
具體為:將計算結果放入堆,各數據節點在各自的堆中放入一個計算結果,對堆進行一次調整;
最後,結果整合模塊對各數據節點的堆頂元素進行比較,將最優結果從堆中取出,並對取出元素的堆進行調整;
由於本算法是基於分布式系統上的lucene索引進行計算的,所以需對各節點返回的計算結果進行整合,結果整合模塊就是對各個節點的自定義表達式排序結果整合為用戶需要的結果集進行返回。
如圖4所示,所述算法具體步驟如下:
步驟一、搭建算法運行所需的分布式環境,包括若干數據節點,一個管理節點和一個元數據節點;
數據節點存儲各欄位的數據,底層採用lucene索引作為存儲引擎;管理節點對數據存儲和查詢過程中的任務進行管理;元數據節點存儲集群的數據分布情況和各欄位的類型等信息。
在該實施實例中使用三臺實體機分別作為master、datanode1、datanode2,以hadoop作為底層存儲架構,利用zookeeper進行節點管理,在master節點上使用mysql存儲數據系統的元數據。
如圖2所示,設計數據的表結構,並將表結構相關數據存放到master節點的mysql元數據系統中;在數據系統通過基於lucene的數據錄入系統,向三個節點中錄入數據。
步驟二、針對用戶發送的某個文檔或者文章,將內容劃分為不同欄位,設計為表達式形式的相關度排序請求;
每個文檔的相關度排序請求為一個或者多個;
用戶將數據信息中的不同內容存儲到不同的欄位中,例如一篇博客可以分為:博客內容、評論數、評論內容、點讚數等,將這些信息存儲為不同欄位的數據信息,用戶在進行全文檢索時可以將這些欄位作為表達式中的參數,來影響最終的相關度排序結果。例如用博客的評論數和點讚數來影響最終的相關度排序結果,那麼在進行全文搜索時,就可以構造一個評論數和點讚數作為參數的表達式。
步驟三、針對某個相關度排序請求,管理節點進行解析後同時發送給不同數據節點,每個數據節點分別獲取該請求的欄位信息;
管理節點解析表達式:判斷表達式是否合法,如果合法,將表達式和作為參數的欄位名發送到各數據節點;否則,提示錯誤,結束。
用戶輸入表達式(例如:log10(field1)*sqrt(field2))進行檢測,然後形成系統可計算的表達式,並將參數和表達式傳送給各數據節點;
表達式包括運算符表達式和函數表達式;
針對運算符表達式,首先,判斷運算符中操作數的個數是否合法,然後,將非數學數字的操作數(如函數名、欄位名)作為未知參數,進行預運算,如果預運算通過則該運算符表達式合法;
針對函數表達式,根據函數對照表,匹配函數表達式的函數名跟對照表中的函數名是否一致,且該函數表達式的所有欄位名參數與元數據節點中的元數據表中的欄位名稱一一對比,如果全部對應,則該函數表達式合法。
管理節點進行表達式解析的程序流程如圖3所示,在表達式解析模塊中預設了函數對照表;對照函數映射表,檢測用戶輸入的表達式中的函數,並進行預編譯,然後提取數據系統中欄位名,檢查表達式中的參數是否為數據系統中欄位的欄位名。
針對元數據中的讀入欄位信息,進行函數檢查,檢查函數合法性;如果是函數,判斷參數是否合法,如果合法取出函數中參數體,再次進行函數檢查;不合法則拋出異常,結束。如果不是函數,判斷是否為常量或者操作符,如果是,再次判斷是否合法,直至結束。如果不是常量或者操作符,判斷是否為欄位名,如果是,則判斷是否合法,直至結束;否則,拋出異常結束。
本算法支持的運算類型及函數如下表所示:
欄位信息包括該欄位的數據類型、欄位名,文本類型的欄位還包括該欄位存儲時所採用分詞器。
如圖2所示,欄位數據的元數據結構,包括了欄位名、欄位類型,名稱為_score的欄位為預留的默認全文打分欄位,即lucene中默認的全文相關度打分欄位。
步驟四、每個數據節點分別根據欄位信息的不同欄位名參數,在各自的數據節點中查詢對應的不同欄位數據;
步驟五、每個數據節點把各自的欄位數據帶入各自的表達式,並調用函數對照表中對應的函數進行計算,並將計算結果放入每個數據節點對應的堆中;
表達式計算模塊根據表達式中的參數,在lucene索引中提取出參數相應欄位的值進行計算。由於本算法的設計目的是應用於分布式大數據系統中,在表達式分析模塊分析完後,將表達式及其參數傳送到每一個數據節點,在每一個節點中提取表達式參數相應欄位數據,並進行表達式計算,將計算結果放入堆中並調整。
步驟六、對各堆中的相關度進行排序並調整,選擇最終排序結果。
具體為:
步驟601、針對某個相關度排序請求對應的各個堆,從每個堆中選出各自的最大值;
步驟602、將所有最大值合併後,再次選擇出其中的最大值作為最終結果;
步驟603、將最終結果從對應的堆中刪除,並在該堆中重新選擇最大值,與其餘堆的最大值進行合併;
步驟604、重複步驟602,直至得到符合用戶要求的最終結果。
將各節點的計算結果進行整合,在各節點的結果堆中取出數據,對堆進行調整,將三個結點取出的數據進行比較,符合條件的從該結點中取出並調整結點的堆,符合條件的值放入最終結果的堆並調整。
步驟七、結果整合模塊將最終排序結果返回給用戶。
實施方式是基於本發明整體構思下的實現方式,而且本發明的保護範圍並不局限於此,任何熟悉本技術領域的技術人員在本發明揭露的技術範圍內,可輕易想到的變化或替換,都應涵蓋在本發明的保護範圍之內。