基尼指數與誤分類代價敏感決策樹構建方法與流程
2023-06-26 18:17:06 2
本發明涉及人工智慧、機器學習技術領域。
背景技術:
在歸納學習技術中如何儘量減少誤分類錯誤是主要焦點,例如CART和C4.5。在歸納問題上誤分類不僅是一個錯誤,即錯誤分類所帶來的代價不容忽略。分裂屬性選擇是決策樹構建的一個關鍵又基本過程,最流行的屬性選擇方法側重於測量屬性的信息增益。當錯誤分類所引起的代價不容忽視時,很自然地把降低代價機制和屬性信息結合起來作為分裂屬性選擇標準,屬性選擇的目標是最小化誤分類總代價。最小化誤分類總代價被稱為基於CAI的分裂屬性選擇,這種方法基於單一代價機制。由於CAI算法局限性,誤分類代價和屬性信息之間的平衡性未得到很好的解決,從而影響精度和整體誤分類代價。
技術實現要素:
針對上述不足,本發明提出了聯合誤分類代價和屬性信息作為分裂屬性選擇標準的方法。
本發明所要解決技術問題是決策過程中誤分類代價和屬性信息之間的平衡性問題,以此同時構成的決策樹具有更小的誤分類代價。
本發明所採用的技術方案是:基尼指數與誤分類代價敏感決策樹構建方法,該方法聯合誤分類代價和屬性信息—ASF(S)作為候選屬性選擇標準,選擇更大ASF(S)值作為節點G,根據gini(Si)分裂因子指標來選擇滿足條件splitS=splitSi的分支,循環執行上述操作,就可以遍歷整個訓練樣本集,得到既能反映屬性信息的純度又使誤分類代價達到最小的決策樹模型。
本發明的有益效果是:
1、考慮了誤分類代價和屬性信息之間的平衡性,在決策過程中,使得誤分類代價達到最小,同時又能反映屬性信息量和純度。
2、對屬性信息增益進行優化處理,避免因屬性信息增益過小而忽略了屬性信息的風險。
附圖說明
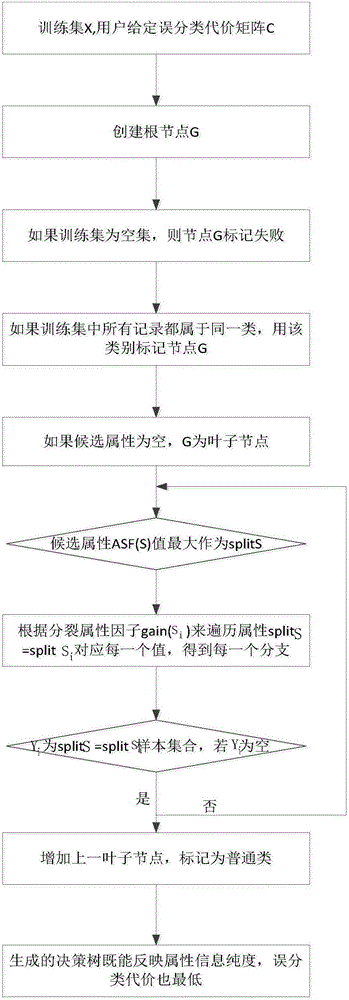
基尼指數與誤分類代價敏感決策樹結構流程圖
具體實施方式
以下結合流程圖,對本發明的進行詳細說明。
本發明的具體實施步驟如下:
步驟1.設訓練集中有X個樣本,屬性個數為n,即n=(s1,s2,…sn),同時分裂屬性sr對應了m個類L,其中Li∈(L1,L2…,Lm),r∈(1,2…,n),i∈(1,2…,m),設誤分類代價矩陣為C,類別標識個數為m,則該數據的代價矩陣m×m方陣是:
其中Cij表示第j類數據分為第i類的代價,如果i=j為正確分類,則Cij=0,否則為錯誤分類Cij≠0,其值由相關領域用戶給定,這裡i,j∈(1,2,…,m);
步驟2:創建根節點G;
步驟3:如果訓練數據集為空,則返回節點G並標記失敗;
步驟4:如果訓練數據集中所有記錄都屬於同一類別,則以該類型標記節點G;
步驟5:如果候選屬性為空,則返回G為葉子節點,標記為訓練數據集中最普通的類;
步驟6:根據本發明代價敏感的分裂屬性因子ASF候選屬性中選擇splitS,
候選屬性因子ASF:
gini(S)為選擇屬性S的信息量,averageL(S,i)為把屬性S誤分為i類的平均總誤分類代價,當選擇屬性splitS滿足目標函數ASF(S)最大時,則找到標記節點G;
步驟7:標記節點G為屬性splitS;
步驟8:根據基尼指數gini(Si)值延伸出滿足條件為splitS=splitSi分支;
步驟8.1::假設Yi為訓練數據集中splitS=splitSi的樣本集合,如果Yi為空,加上一個葉子節點,標記為訓練數據集中最普通的類;
步驟9:非步驟8.1中情況,則遞歸調用步驟6至步驟8。
步驟10:更新訓練數據集,保存新的示例數據。
上述步驟所涉及到的公式計算及定義,詳細如下:
一、所述步驟6,選擇屬性的基尼指數gini(S)計算如下:
其中k為splitS=splitSi的屬性值個數,Xi為子結點splitSi的記錄數,X為splitS處的記錄數,其中分裂屬性的基尼指數gini(Si)值具體計算如下(此計算也適用於步驟8關於基尼指數gini(Si)的計算):
設訓練數據集X,其類有m個,那麼其gini指標為:
其中p(Li/Si)為分裂屬性Si屬於Li類的相對頻率,當gini(Si)=0,即在此結點處所有樣例都屬於同一類,表示能得到最大有用信息;當此結點所有樣例對於類別欄位來講均勻分布時,gini(Si)最大,表示能得到最小的有用信息。
二、所述步驟6關於目標函數ASF的計算,其中所涉及到的有誤分類代價指標函數L(Si,i)、屬性S平均總誤分類代價,其具體的求解過程如下:
步驟6.1:求解誤分類代價指標函數L(Si,i)
根據步驟1的誤分類代價矩陣,對於任一屬性值Si,如果將其分為第i類,那麼可能此時屬性值Si的誤分類為i的代價是:
其中L(Si,i)為將Si分為第i類的預測總代價,p(j/Si)為在屬性值Si中第j類的概率,C(i,j)為把j類錯分為第i類的代價花費;
步驟6.2:求解屬性S的平均總誤分類代價averageL(S,i)
其中k為splitS=splitSi的屬性值個數;
步驟6.3:求解候選屬性因子ASF
根據前面幾個步驟,可得出:
候選屬性因子:
選擇屬性的基尼指數gini(S)經過式子2gini(S)-1處理,可以預防因屬性值信息量小而忽略的風險。
三、算法偽代碼計算過程
輸入:X個樣本訓練集,訓練集的誤分類代價矩陣C。
輸出:基尼指數與誤分類代價敏感決策樹。