基於EMD‑GRA‑MPSO‑LSSVM模型的負荷預測方法與流程
2023-07-03 21:06:26 5
本發明屬於短期電力負荷預測技術領域,尤其涉及一種基於emd-gra-mpso-lssvm模型的負荷預測方法。
背景技術:
隨著國民經濟的不斷發展,電力負荷預測技術在電力工業領域中扮演著越來越重要的角色,負荷預測的精確度將直接影響電力系統的可靠性,進而影響國民經濟的發展。電力負荷預測的主要工作是預測未來電力負荷的時間分布和空間分布,將預測結果作為電力系統規劃的重要組成部分和電力系統經濟運行的基礎,短期負荷預測是指根據歷史負荷、氣象因素、節假日等因素,對未來24小時甚至幾天內的負荷進行預測。然而短期負荷具有一定的隨機性,並且預測精確度易受到噪聲的影響,因此選擇合適的預測算法和降噪方法,構建合理有效的預測模型,對於實現精確的短期負荷預測有著重大的意義。近年來,隨著人工智慧技術的發展,在負荷預測領域,人工智慧預測技術逐漸取代了經典預測技術,實現了良好的預測效果。人工神經網絡和支持向量機均是一種常用的人工智慧預測技術,人工神經網絡是理論化的人腦神經網絡數學模型,具有大規模並行處理、分布式信息存儲、良好的自組織自學習能力,並且具有很強的非線性擬合能力,可映射任意複雜的非線性關係,學習規則簡單,便於計算機實現,然而人工神經網絡收斂速度較慢,訓練時間較長,計算結果容易陷入局部最優,且易出現「過擬合」的現象。支持向量機具有較好的魯棒性,泛化能力強,計算速度快,且能較好的解決神經網絡算法易陷入局部最優的問題。最小二乘支持向量機(lssvm)是採用最小二乘價值函數和等式約束對標準支持向量機的一種改進算法,其具有更快的訓練速度和更好的收斂精度。採用最小二乘支持向量機進行負荷預測時,需要確定正則化參數和徑向基核函數參數的取值,這兩個參數的取值直接影響預測的精度。為此,研究者們運用多種方法對lssvm的參數進行優化,例如遺傳算法,蟻群算法,人工蜂群算法,差分進化算法等優化算法,然而這些算法的搜索效率低,收斂速度慢,且易陷入局部最優。由於短期負荷易受外界因素影響且隨機性較強,研究者們一般在選擇合適的預測模型的基礎上,運用時間序列分解技術對原始負荷數據進行分解,將非平穩時間序列分解為多個平穩時間序列,然後對其進行預測和序列重構,大大提高預測的效率和精確度。小波分解是一種常用的時間序列分解方法,但是該方法解析度較低且受小波基選擇的影響較大。
技術實現要素:
針對上述問題與缺陷,提出一種基於emd-gra-mpso-lssvm(經典模態分解-灰色關聯分析-改進的粒子群優化算法-最小二乘支持向量機)模型的負荷預測方法,包括以下步驟:
步驟一:採集樣本數據並對樣本數據進行預處理,採集的樣本數據包括歷史負荷、當日最高溫度、當日最低溫度、當日平均溫度、相對溼度、風力、日期類型,然後對氣象因素進行歸一化處理;
步驟二:降噪處理;採用emd-gra(經典模態分解-灰色關聯分析)模型對原始負荷序列進行降噪處理,通過對原始負荷序列進行emd分解,再利用gra(灰色關聯分析)算法計算各個imf(本徵模函數)與原始序列的灰色關聯度,並將計算所得的灰色關聯度進行排序,剔除關聯度最低的imf;
步驟三:負荷預測;採用mpso-lssvm(改進的粒子群優化算法-最小二乘支持向量機)模型對降噪處理後的imf分別進行預測,並對預測的結果進行重構,得到最終的預測結果。
進一步的,所述emd-gra模型的降噪方法是利用分解非平穩信號以獲得一組性能優化的本徵模函數,並剔除信號中的無用成分,具體包括以下步驟:
步驟1:對原始時間序列x(t),x1(t),x2(t),…xn-1(t),xn(t)進行emd分解,對應得到有限個imf分量,分別標記為imf1(t),imf2(t),imf3(t),…,imfn(t);
步驟2:利用gra算法計算每個imf與原始序列之間的灰色關聯度r1,r2,…,rn,並進行關聯度排序,其中rk=min{r1,r2,…,rn},rk表示最低關聯度;
步驟3:剔除與原始序列關聯度最低的imf,對剔除噪聲後的序列進行重構,得到降噪後的時間序列:
式中,imfi(t)為原始時間序列經emd分解後對應的第i個imf分量,xn(t)為原始時間序列,imfk(t)為最小灰色關聯度對應的imf分量。
進一步的,所述mpso-lssvm模型的預測方法包括以下步驟:
(a)設定pso算法的參數,初始化粒子群;
(b)計算每個粒子的適應值,找出當前個體極值位置和全局極值位置;
(c)計算種群的平均粒距d(t)和適應度方差σ2,判斷粒子是否陷入早熟收斂狀態,當d(t)和σ2均滿足早熟收斂狀態條件時,則判斷種群出現早熟收斂現象,粒子陷入局部最優,此時保留粒子群歷史最優位置,並對粒子解空間進行重新分配,從而引導粒子快速跳出局部最優,否則算法繼續;
(d)更新粒子的速度和位置,產生新種群,計算適應值,並與歷史值進行比較,更新個體極值位置和全局極值位置,循環這一過程直到達到迭代次數,得到優化結果;
(e)將優化後的參數值賦給lssvm,進行回歸預測。
其中,平均粒距的計算公式為:
式中,l為搜索空間對角最大長度,m為粒子數目,n為解空間維數,xid表示第i個粒子的第d維坐標值,表示所有粒子第d維坐標值的均值。
適應度方差的計算公式為:
其中:
式中,m為種群粒子數,fi為第i個粒子當前的適應度,為種群當前的平均適應度,f為歸一化定標因子。
本發明的有益效果在於:
本發明提出的一種基於emd-gra-mpso-lssvm模型的負荷預測方法是一種複雜的組合預測方法,該預測方法通過對非平穩時間序列的分解與降噪,實現了不同算法的優勢互補。基於emd算法的解析度較高,具有自適應的特點,同時考慮到短期負荷數據含有一定的噪聲,本發明在emd算法的基礎上引入gra算法,對原始負荷序列進行降噪處理,並對原始負荷數據進行分解,進一步提高了負荷預測的精確度。mpso算法引入了平均粒距和變異算子,使得改進後的粒子群算法具有調整參數較少,搜索效率高,收斂速度快的優點,且全局搜索能力大大提高,可以有效避免陷入局部最優。本發明綜合了多種預測方法,消除了原始數據的混沌,使其更具有規律性,通過優化算法的改進,實現了預測模型參數的合理選擇,提高了預測精度,同時具備更強大的泛化能力和魯棒性,預測結果具有可靠性和有效性。
附圖說明
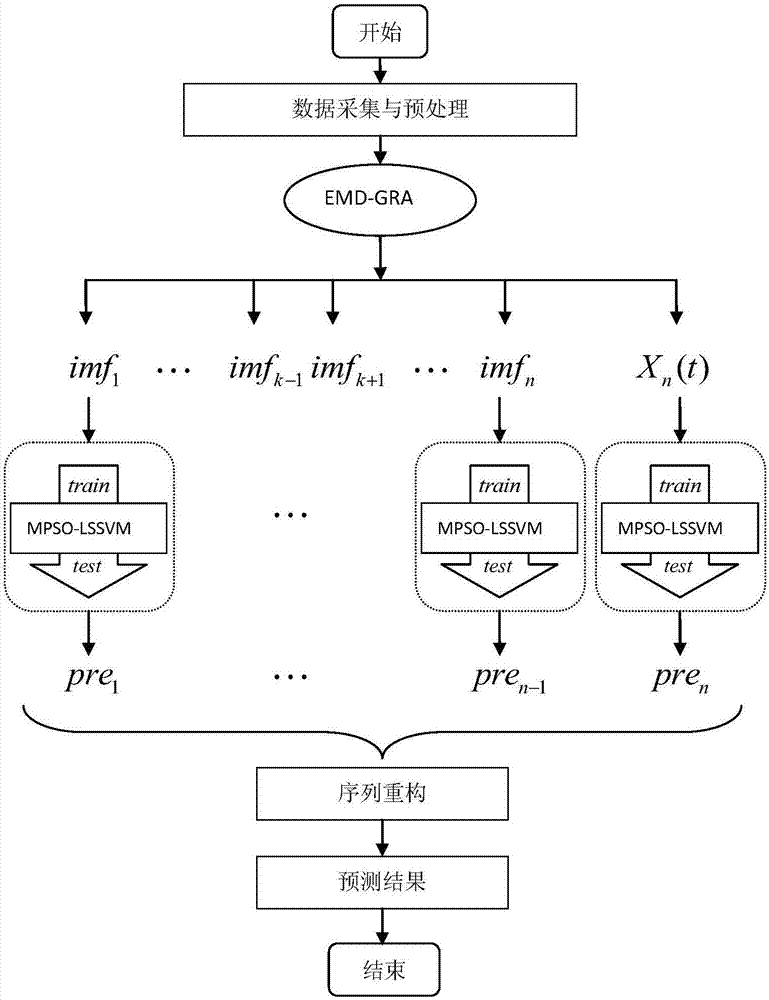
附圖1為基於emd-gra-mpso-lssvm模型的預測模型圖;
附圖2為emd-gra降噪流程圖;
附圖3為mpso優化lssvm參數流程圖;
附圖4為原始負荷數據經emd分解的波形圖;
附圖5為灰色關聯度排序結果圖;
附圖6為最終預測結果和相對誤差圖;
附圖7為多種預測模型的相對誤差箱線圖;
具體實施方式
下面結合附圖和實施例對本發明進行詳細說明。
附圖1為基於emd-gra-mpso-lssvm模型的預測模型圖,如圖1所示,該模型的預測方法主要包括降噪和預測兩部分,具體步驟如下所述:首先進行數據採集與預處理。其中採集的樣本數據包括歷史負荷、當日最高溫度、當日最低溫度、當日平均溫度、相對溼度、風力、日期類型等。然後對採集的樣本數據進行預處理,對氣象因素進行歸一化處理,日期類型中節假日用1表示,工作日用0表示;其次對預處理後的樣本數據進行降噪處理。由於在負荷預測過程中,原始歷史負荷數據往往含有噪聲汙染,導致在進行負荷預測時難以準確的分析出負荷的真實變化規律,此時需要對原始負荷數據進行降噪處理。本發明採用emd-gra(經典模態分解-灰色關聯分析)的組合算法對原始負荷序列進行降噪處理,通過對原始負荷序列進行經典模態分解,計算各個imf與原始序列的灰色關聯度,並進行排序,剔除關聯度最低的imf。最後進行負荷預測,採用mpso-lssvm模型對降噪處理後的imf分別進行預測,並對預測的結果進行重構,得到最終的預測結果。
進一步的,在降噪處理過程中,本發明採用emd-gra模型對原始負荷序列進行降噪處理,所述emd-gra降噪是將經驗模態分解和灰色關聯度分析相結合的一種數據處理模型,其核心思想是分解非平穩信號以獲得一組性能較好的本徵模函數,並剔除信號中的無用成分。具體方法如圖2所示,附圖2為emd-gra降噪流程圖,降噪的基本步驟如下所述:首先對原始時間序列x(t),x1(t),x2(t),…xn-1(t),xn(t)進行emd分解,相應的得到有限個imf,分別為imf1(t),imf2(t),imf3(t),…,imfn(t);其次計算每個imf與原始序列之間的灰色關聯度r1,r2,…,rn,並進行關聯度排序;最後剔除與原始序列關聯度最低的imf(噪聲)rk,其中rk=min{r1,r2,…,rn},對剔除噪聲後的序列進行重構,得到如式(1)所示降噪後的時間序列。
在emd-gra的組合算法中,emd(經驗模態分解)是一種新型自適應信號時頻處理方法,該方法依據數據自身的時間尺度特徵可將複雜信號分解為有限個本徵模函數(imf),所分解出來的各imf分量包含了原信號的不同時間尺度的局部特徵信號,且imf須滿足以下兩個性質:其一,信號的極值點和過零點數目相等或最多相差一個;其二,信號的上包絡線和下包絡線的平均值為零。對於給定的信號x(t),其emd步驟如下:
步驟1:找到x(t)所有的局部極值點,用三次樣條函數分別擬合x(t)的上包絡線fa(t)和下包絡線fb(t);
步驟2:計算上包絡線和下包絡線的平均值fm(t);
步驟3:計算x(t)與fm(t)的差值,e(t)=x(t)-fm(t);
步驟4:將e(t)作為原始序列重複步驟(1)~(3),當包絡均值fm(t)趨於0時,得到第一個imf分量imf1(t);
步驟5:令x1(t)=x(t)-imf1(t),將x1(t)作為原始序列重複步驟1~4,得到第二個imf分量imf2(t),重複這一過程,直到得到的差值函數xn(t)為常值函數或者單調函數時,停止分解。此時,原始序列表示為:
在emd-gra的組合算法中,gra(灰色關聯度分析)是一種多因素統計分析方法,該方法通過對動態過程發展態勢的量化分析,完成對系統內時間序列有關統計數據幾何關係的比較,求出參考數列與各比較數列之間的灰色關聯度。與參考數列關聯度越大的比較數列,其發展方向和速率與參考數列越接近,與參考數列的關係越緊密。gra分析的核心是計算灰色關聯度,具體計算步驟如下:
步驟1:確定分析序列;
首先設參考序列:
x0=(x0(1),x0(2),…,x0(n))(6)
比較序列:
步驟2:對變量序列進行無量綱化;
k=1,2,…,n,i=0,1,2,…,m
步驟3:計算關聯繫數
yj(k)與y0(k)的關聯繫數為:
ρ∈(0,1),k=1,2,…,n,j=1,2,…,m
步驟4:計算關聯度
xj與x0的灰色關聯度為:
k=1,2,…,n,j=1,2,…,m
步驟5:關聯度排序
將比較序列按照灰色關聯度大小排序,灰色關聯度越大,表明該比較序列與參考序列變化的態勢越一致。
進一步的,在負荷預測過程中,本發明採用的是mpso-lssvm模型進行負荷預測。由於採用徑向基核函數rbf的lssvm進行回歸預測,需要確定正則化參數c和徑向基核函數參數g的取值,這兩個參數的取值直接影響回歸預測的精度。因此,本文選擇mpso算法對lssvm的參數進行優化,優化步驟如圖3所示:
step1:設定pso算法的參數,初始化粒子群;
step2:計算每個粒子的適應值,找出當前個體極值位置和全局極值位置。
step3:計算種群的平均粒距和適應度方差,判斷粒子是否陷入早熟收斂狀態,如果粒子陷入局部最優,重新分配粒子空間,引導粒子跳出局部極值。否則算法繼續。
step4:更新粒子的速度和位置,產生新種群,計算適應值,並與歷史值進行比較,更新個體極值位置和全局極值位置,循環這一過程直到達到迭代次數,得到優化結果。
step5:將優化後的參數值賦給lssvm,進行回歸預測。
在mpso-lssvm的組合算法中,mpso(改進的粒子群優化算法)是基於標準pso(粒子群優化算法)的改進算法,粒子群優化算法是一種基於迭代計算的群智能優化算法,該算法在可解空間中初始化一群隨機粒子,每個粒子代表優化問題的一個潛在最優解,粒子特徵包括位置、速度和適應度值。適應度值是由適應度函數計算得出的用來表徵粒子優劣的指標。在每一次迭代中,粒子通過跟蹤個體極值位置和全局極值位置來更新粒子自身的速度和在下一輪迭代中的位置。
假設在一個d維的搜索空間中,有n個粒子組成一個種群,其中第i個粒子表示為一個d維的向量xi=(xi1,xi2,…,xid)t,i=1,2,...,n,即第i個粒子在d維的搜索空間中的位置。第i個粒子的速度為vi=(vi1,vi2,…,vid)t,第i個粒子目前搜索到的最優位置為pi=(pi1,pi2,…,pid)t,整個種群目前搜索到的最優位置為pg=(pg1,pg2,…,pgd)t。
每一次迭代中,粒子通過公式(6)和(7)對自身的速度和位置進行更新:
式中,k為當前迭代次數,ω為慣性權重,c1和c2是加速度因子,r1和r2是[0,l]之間的隨機數。
然而對於複雜的優化問題,標準粒子群優化算法容易出現早熟收斂的現象,針對這一問題,本發明通過引入平均粒距和變異算子,指導初始種群的選取,判斷粒子早熟收斂情況,避免陷入局部最優。初始粒子群的選取是隨機的,理想狀況下有限個粒子應均勻分布在整個解空間,但實際上這一點很難實現,為此,本發明引入平均粒距的概念以增加搜索到全局最優解的概率,避免陷於局部最優。平均粒距定義如公式(2)所示。
標準粒子群優化算法在運行初期,收斂速度較快,後期減慢,容易陷入局部最優而喪失種群進化的能力。由於粒子位置決定其適應度的大小,因此,根據種群中所有粒子適應度的整體變化可以判斷出種群當前所處的狀態進而判斷粒子的早熟收斂情況。若第i個粒子當前的適應度為fi,種群當前的平均適應度為可定義種群的適應度方差如式(3)所示,f為用來限制σ2大小的歸一化定標因子,計算方法如公式(4)所示。適應度方差反映的是種群中粒子的離散度,σ2越小,則種群中粒子的離散度越小;反之,則離散度越大。隨著迭代次數的增加,d(t)和σ2越來越小,當d(t)<0.001且σ2<0.01時,則判斷算法進入後期搜索階段,種群出現早熟收斂現象,此時保留粒子群歷史最優位置,並對粒子解空間進行重新分配,從而引導粒子快速跳出局部最優。
在mpso-lssvm的組合算法中,lssvm(最小二乘支持向量機)是對svm的一種改進方法,在svm的基礎上,通過採用最小二乘價值函數和等式約束,將二次規劃問題轉化為線性問題,加快了訓練速度和收斂精度。運用lssvm解決回歸優化問題時,優化目標中的損失函數為誤差的二次項,約束條件為等式約束,如下所示:
式中,ω為高維特徵空間權向量,||ω||2控制模型的複雜度,c為正則化參數,ξi為誤差,b為偏置常數。引入lagrange乘子αi,式(13)可轉化為:
根據karush-kuhn-tucher條件,得:
消去ω和ξ,得到線性方程組:
式中,是滿足mercer條件的核函數。通過最小二乘法求得αi和b,得到非線性預測模型如下所示:
實施例1
下面以具體實施方式對本發明做詳細說明。首先選取樣本,以冀北地區為例,選取冀北地區2016年1月1日至3月14日的整點有功負荷、日最高溫度、日最低溫度、日平均溫度、相對溼度、風力、日期類型作為訓練樣本,預測3月15日24小時的整點負荷。模型的輸入數據包括:預測日前一周歷史負荷值、預測日最高溫度、預測日最低溫度、預測日平均溫度、預測日相對溼度、預測日風力、預測日日期類型,其中氣象數據取冀北五市的平均值;模型的輸出為預測日24小時的整點負荷。其次,基於emd-gra-mpso-lssvm的負荷預測方法,對原始歷史負荷數據進行經典模態分解,附圖4為原始負荷數據經emd分解的波形圖,如圖4所示,將冀北地區2016年1月1日至3月15日1800個整點有功負荷作為信號序列輸入emd模型,得到九個imf和一個餘項,然後計算各imf與原始序列的灰色關聯度,並進行排序,排序結果如圖5所示,由圖5可知,imf4與原始序列灰色關聯度最小,因此剔除該序列,對其餘的imf以及餘項運用mpso-lssvm模型分別進行預測,接下來對imf子序列的預測結果進行重構,得到3月15日24小時的整點負荷預測結果以及相對誤差如圖6所示,從圖6可以看出,運用emd-gra-mpso-lssvm模型對冀北地區2016年3月15日24小時的整點負荷進行預測,預測曲線擬合程度較好,預測精度較高,各個預測點的相對誤差均不超過3%。為了驗證本發明所提出的emd-gra-mpso-lssvm負荷預測模型的優越性和有效性,本文分別運用bp神經網絡、svm、lssvm、pso-lssvm、mpso-lssvm、emd-mpso-lssvm等模型分別對同一樣本數據進行負荷預測,並將預測結果相對誤差進行對比,如圖7所示,在圖7的箱線圖中顯示了各個模型預測的相對誤差的五個統計量,分別為:最小值、第一四分位數、中位數、第三四分位數、最大值。從圖7可以看出,emd-gra-mpso-lssvm模型的預測誤差最小、其次為emd-mpso-lssvm模型,bp神經網絡的預測誤差最大,所有模型預測相對誤差均不超過8%。
此實施例僅為本發明較佳的具體實施方式,但本發明的保護範圍並不局限於此,任何熟悉本技術領域的技術人員在本發明揭露的技術範圍內,可輕易想到的變化或替換,都應涵蓋在本發明的保護範圍之內。因此,本發明的保護範圍應該以權利要求的保護範圍為準。