機器人的交互方法及系統與流程
2023-12-04 14:48:51 2
本發明實施例涉及機器人技術領域,尤其涉及一種機器人的交互方法及系統。
背景技術:
機器人(robot)是自動執行工作的機器系統。它既可以接受人類指揮,又可以運行預先編排的程序,也可以根據以人工智慧技術制定的原則綱領行動,用於協助或取代人類工作。
目前,隨著科學技術的快速發展,機器人不僅僅可以應用於商業或工業,還可以作為用戶的玩伴,能夠實現與人類的正常交互。在現有技術中,由於機器人接收到外界語音後,會對接收到的語音進行解析,再匹配出與該語音相對應的文字作為應答,因此並不能快速的做出應答。
技術實現要素:
本發明實施例提供一種機器人的交互方法及系統,能夠改善機器人與人類交互中反應速度慢的現象。
第一方面,本發明實施例提供了一種機器人的交互方法,包括:
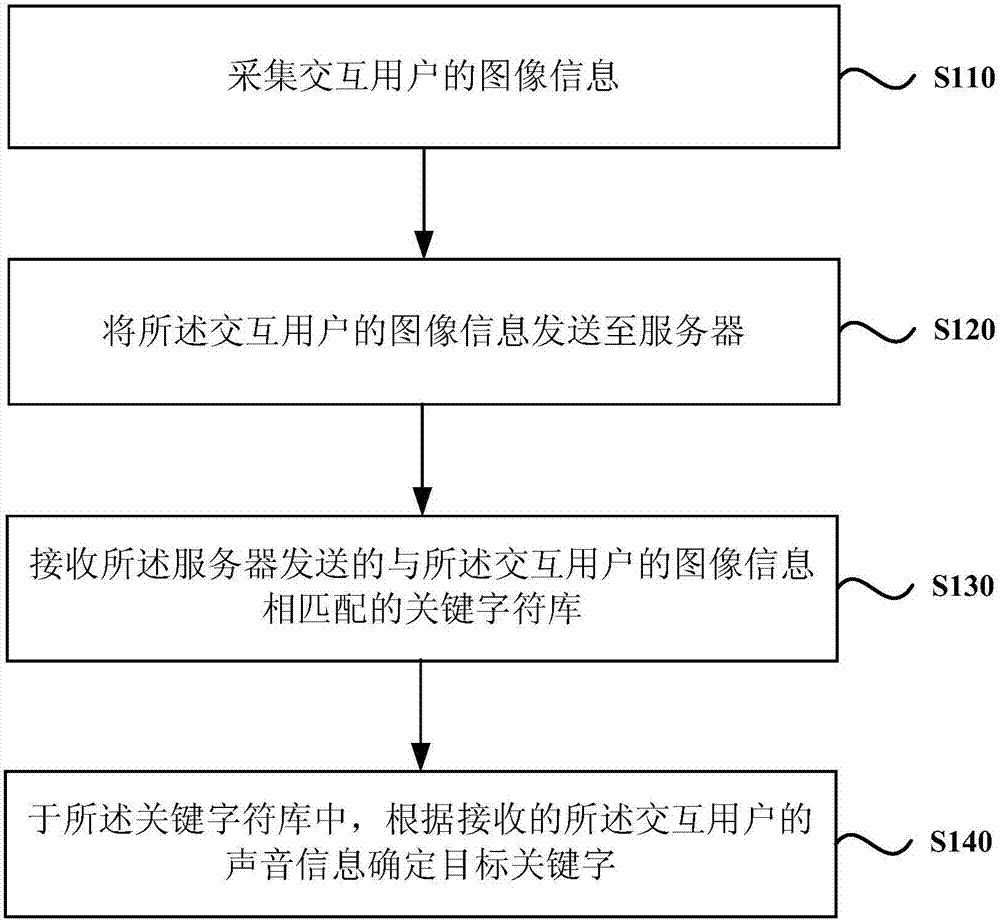
採集交互用戶的圖像信息;
將所述交互用戶的圖像信息發送至伺服器;
接收所述伺服器發送的與所述交互用戶的圖像信息相匹配的關鍵字符庫;
於所述關鍵字符庫中,根據接收的所述交互用戶的聲音信息確定目標關鍵字。
進一步的,所述將所述交互用戶的圖像信息發送至伺服器包括:
將所述交互用戶的圖像信息以圖片格式發送至所述伺服器;
或者,若所述圖像信息為視頻信息時,將所述交互用戶的圖像信息以幀圖格式發送至所述伺服器。
進一步的,所述交互用戶的圖像信息包括所述交互用戶的面部表情或者動作。
進一步的,還包括:
基於所述伺服器中預存的日常圖像信息,將所述日常圖像信息進行分類並匹配相應的關鍵字符庫。
進一步的,所述將所述日常圖像信息進行分類包括;
按照發生情景對所述日常圖像信息進行分類;
或者,按照所述交互用戶的情緒對所述日常圖像信息進行分類。
第二方面,本發明實施例還提供了一種機器人的交互系統,包括:
圖像信息採集模塊,用以採集交互用戶的圖像信息;
圖像信息發送模塊,用以將所述交互用戶的圖像信息發送至伺服器;
關鍵字符庫接收模塊,用以接收所述伺服器發送的與所述交互用戶的圖像信息相匹配的關鍵字符庫;
目標關鍵字確定模塊,用以於所述關鍵字符庫中,根據接收的所述交互用戶的聲音信息確定目標關鍵字。
進一步的,所述圖像信息發送模塊具體用以:
將所述交互用戶的圖像信息以圖片格式發送至所述伺服器;
或者,若所述圖像信息為視頻信息時,將所述交互用戶的圖像信息以幀圖格式發送至所述伺服器。
進一步的,所述交互用戶的圖像信息包括所述交互用戶的面部表情或者動作。
進一步的,還包括:
分類模塊,用以基於所述伺服器中預存的日常圖像信息,將所述日常圖像信息進行分類並匹配相應的關鍵字符庫。
進一步的,所述分類模塊具體用以:
按照發生情景對所述日常圖像信息進行分類;
或者,按照所述交互用戶的情緒對所述日常圖像信息進行分類。
本發明實施例提供了一種機器人的交互方法及系統,若採集交互用戶的圖像信息;將所述交互用戶的圖像信息發送至伺服器;接收所述伺服器發送的與所述交互用戶的圖像信息相匹配的關鍵字符庫;於所述關鍵字符庫中,根據接收的所述交互用戶的聲音信息確定目標關鍵字,通過交互用戶的圖像信息縮小原有關鍵字符庫的範圍,在該關鍵字符庫中匹配出目標關鍵字,能夠改善機器人與人類交互中反應速度慢的問題,提高機器人交互中的應答速度。
附圖說明
圖1是本發明實施例一中的一種機器人的交互方法的流程圖;
圖2是本發明實施例二中的一種機器人的交互系統的結構圖。
具體實施方式
下面結合附圖和實施例對本發明作進一步的詳細說明。可以理解的是,此處所描述的具體實施例僅僅用於解釋本發明,而非對本發明的限定。另外還需要說明的是,為了便於描述,附圖中僅示出了與本發明相關的部分而非全部結構。
實施例一
圖1為本發明實施例一提供的一種機器人的交互方法的流程圖,本實施例可適用於機器人的交互情況,該方法可以由本發明實施例提供的機器人的交互系統來執行。如圖1所示,具體包括:
s110、採集交互用戶的圖像信息。
其中,交互用戶可以是機器人固定服務的專屬用戶,也可以是任何出現在機器人視覺系統中的任意用戶。圖像信息可以包括圖片信息與視頻信息。當光線照射在一個物體上時,物體的表面就會反射光線。反射光進入我們的眼睛,使我們看見東西。同理,機器人能夠看見交互用戶也是基於這個原理。又由於光的傳播速度大於聲音的傳播速度,因此機器人的視覺系統能夠先看見交互用戶的圖像信息,而後聽覺系統才能接收到交互用戶的聲音信息。
因此,機器人可以先採集交互用戶的圖像信息,根據該圖像信息分析交互用戶所在的場景或者情緒,再根據該場景或者情緒縮小機器人回復給交互用戶的應答範圍。
示例性的,所述交互用戶的圖像信息包括所述交互用戶的面部表情或者動作。
具體的,交互用戶的圖像信息內容可以包括近距離拍攝的交互用戶的面部表情,也可以是遠距離拍攝的交互用戶的動作行為。例如,機器人的視覺系統若在預設時間閾值內檢測到交互用戶無明顯動作幅度,則可以近距離拍攝交互用戶的面部表情;若在預設時間閾值內檢測到交互用戶具有重複性的動作行為,則也可以近距離拍攝交互用戶的動作行為;若在預設時間閾值內檢測到交互用戶有明顯的動作幅度,則可以遠距離拍攝交互用戶的面部表情。具體例如,若交互用戶一直走路或者坐在椅子上不動,則可以近距離拍攝交互用戶細微的面部表情;若交互用戶走路突然跌倒時,可以遠距離拍攝交互用戶的動作行為。
s120、將所述交互用戶的圖像信息發送至伺服器。
由於機器人也屬於一種智能設備,而智能設備的弊端是存儲器內存容量有限以及計算處理效率慢等。因此,大多數智能終端均會與伺服器相連,將存儲以及計算處理的任務轉移至伺服器,由伺服器進行處理。在本實施例中,當機器人的視覺系統採集到交互用戶的圖像信息後,也會將該圖像信息發送至伺服器。
示例性的,所述將所述交互用戶的圖像信息發送至伺服器包括:將所述交互用戶的圖像信息以圖片格式發送至所述伺服器;或者,若所述圖像信息為視頻信息時,將所述交互用戶的圖像信息以幀圖格式發送至所述伺服器。
由於機器人的視覺系統檢測到交互用戶後,採集圖像信息可以是以不斷拍攝交互用戶的方式,以圖片格式的圖像信息發送至伺服器,也可以是以連續拍攝關於交互用戶的視頻信息的方式,將視頻信息拆分成一幅幅幀圖像,以幀圖格式發送至伺服器,或者還可以是直接將拍攝的關於交互用戶的視頻信息發送至伺服器。
s130、接收所述伺服器發送的與所述交互用戶的圖像信息相匹配的關鍵字符庫。
其中,關鍵字符庫為伺服器存儲的用於機器人語音輸出的文字的集合。關鍵字符庫中包含了所有的字、詞以及語句,且關鍵字符庫中包含的語言種類不做限定。
具體的,伺服器當接收到機器人上傳的關於交互用戶的圖像信息後,將對該圖像信息進行處理。例如,伺服器可以提取圖像信息中含有的交互用戶的圖像,對交互用戶的動作或者面部表情進行分析,從而確定與之相匹配的關鍵字符庫。並將該關鍵字符庫發送至機器人。
通過篩選出與交互用戶的圖像信息相匹配的關鍵字符庫,避免了機器人在檢測到交互用戶的聲音信息後,在包含全部字、詞或語句中的關鍵字符庫中進行匹配,由於縮小了關鍵字符庫的範圍,因此機器人的應答速度大幅度提高。
示例性的,還包括:基於所述伺服器中預存的日常圖像信息,將所述日常圖像信息進行分類並匹配相應的關鍵字符庫。
具體的,伺服器中可以預存日常圖像信息,用於輔助對接收到的交互用戶的圖像信息進行分析。其中,日常圖像信息可以是存入的各種場景的圖像,也可以是輸入的電視劇或者電影場景。將日常圖像信息進行歸類並匹配上與該日常圖像信息相對應的關鍵字符庫,其中,與該日常圖像信息相對應的關鍵字符庫中包含的文字全部適用於該日常圖像信息。
示例性的,所述將所述日常圖像信息進行分類包括;按照發生情景對所述日常圖像信息進行分類;或者,按照所述交互用戶的情緒對所述日常圖像信息進行分類。
由於交互用戶可以在任何情境下跟機器人進行互動,因此,日常圖像信息可以根據發生場景進行分類。例如,若交互用戶在家裡寫作業,與之相對應的關鍵字符庫可以包含學習類的文字。又例如,若交互用戶在室外打球,與之相對應的關鍵字符庫可以包含球類相關的文字,或者鼓勵類的文字。
或者,日常圖像信息可以是按照交互用戶的情緒進行分類。例如,若交互用戶的心情很差,在圖像信息的表現方式可以是撅嘴或者流眼淚,這時與之相對應的關鍵字符庫可以包含安慰類的文字。又例如,若用戶的心情很好,在圖像信息的表現方式可以是笑臉或者歡呼雀躍,這時與之相對應的關鍵字符庫可以包含慶祝類的文字。
s140、於所述關鍵字符庫中,根據接收的所述交互用戶的聲音信息確定目標關鍵字。
具體的,機器人在接收到伺服器已縮小了範圍的關鍵字符庫後,在接收到交互用戶的聲音信息後,對聲音信息進行分析,在範圍縮小後的關鍵字符庫中匹配出與聲音信息對應的關鍵字,並將該對應的關鍵字作為目標關鍵字進行輸出。
需要說明的是,現有技術中的機器人與交互用戶之間的交互都是基於檢測到交互用戶的聲音後,將採集的交互用戶的語音轉化為文字,再對該文字進行識別分析,從而在包含所有字、詞與語句的關鍵字符庫中匹配出與聲音。本實施例通過預先對拍攝的圖像信息處理,能夠縮小元還有關鍵字符庫的範圍,從而提高機器人的應答效率。
例如,交互用戶為小孩,一個小孩在跟機器人玩耍時,不小心摔倒。一般情況下,小孩會想讓機器人提供安慰的回應。因此,機器人拍攝到小孩摔倒的圖像信息,該圖像信息包含小孩摔倒的動作以及小孩的面部表情,那麼機器人將該圖像信息上傳至伺服器,接收由伺服器匹配出與該圖像信息相對應的關鍵字符庫,該關鍵字符庫只包含了安慰類以及摔倒等相關的關鍵字,排除了開心、興奮等其他情緒,也排除了寫作業、吃飯以及打球等其他情景。隨後,機器人在檢測到小孩的聲音信息後,可以直接在該關鍵字符庫中進行匹配目標關鍵字並轉化為語音進行輸出。
本發明實施例提供了一種機器人的交互方法,若採集交互用戶的圖像信息;將所述交互用戶的圖像信息發送至伺服器;接收所述伺服器發送的與所述交互用戶的圖像信息相匹配的關鍵字符庫;於所述關鍵字符庫中,根據接收的所述交互用戶的聲音信息確定目標關鍵字,通過交互用戶的圖像信息縮小原有關鍵字符庫的範圍,在該關鍵字符庫中匹配出目標關鍵字,能夠改善機器人與人類交互中反應速度慢的問題,提高機器人交互中的應答速度。
實施例二
圖2為本發明實施例二提供的一種機器人的交互系統的結構示意圖,本實施例可適用於各種機器人的交互情況。如圖2所示,具體包括:圖像信息採集模塊21、圖像信息發送模塊22、關鍵字符庫接收模塊23和目標關鍵字確定模塊24。
圖像信息採集模塊21,用以採集交互用戶的圖像信息;
圖像信息發送模塊22,用以將所述交互用戶的圖像信息發送至伺服器;
關鍵字符庫接收模塊23,用以接收所述伺服器發送的與所述交互用戶的圖像信息相匹配的關鍵字符庫;
目標關鍵字確定模塊24,用以於所述關鍵字符庫中,根據接收的所述交互用戶的聲音信息確定目標關鍵字。
在上述實施例基礎上,所述圖像信息發送模塊22具體用以:將所述交互用戶的圖像信息以圖片格式發送至所述伺服器;或者,若所述圖像信息為視頻信息時,將所述交互用戶的圖像信息以幀圖格式發送至所述伺服器。
在上述實施例基礎上,所述交互用戶的圖像信息包括所述交互用戶的面部表情或者動作。
在上述實施例基礎上,還包括:分類模塊25;
分類模塊25,用以基於所述伺服器中預存的日常圖像信息,將所述日常圖像信息進行分類並匹配相應的關鍵字符庫。
在上述實施例基礎上,所述分類模塊25具體用以:按照發生情景對所述日常圖像信息進行分類;或者,按照所述交互用戶的情緒對所述日常圖像信息進行分類。
本實施例所述機器人的交互系統用於執行上述各實施例所述的機器人的交互方法,其技術原理和產生的技術效果類似,這裡不再贅述。
注意,上述僅為本發明的較佳實施例及所運用技術原理。本領域技術人員會理解,本發明不限於這裡所述的特定實施例,對本領域技術人員來說能夠進行各種明顯的變化、重新調整和替代而不會脫離本發明的保護範圍。因此,雖然通過以上實施例對本發明進行了較為詳細的說明,但是本發明不僅僅限於以上實施例,在不脫離本發明構思的情況下,還可以包括更多其他等效實施例,而本發明的範圍由所附的權利要求範圍決定。