音頻數據可視化方法及裝置與流程
2023-12-04 08:36:56 6
本發明屬於信號處理技術領域,尤其涉及一種音頻數據可視化方法及裝置。
背景技術:
現有的部分音樂軟體帶有可視化功能,例如形狀、圖形、顏色等的變換。而這些變換都是根據能量簡單地生成的,並不具有情感表達能力和娛樂性。類似的可視化地表達音樂情感的方法是根據音樂段落尋找相匹配的視頻,或使用直接的音樂聲學特徵與視頻特徵的匹配。
在實現本發明過程中,發明人發現現有技術中至少存在如下問題:現有技術採用視頻的搜索與匹配技術,即根據給定的音樂段落,在特定的視頻資料庫裡找尋在時序上最匹配的視頻。然而對於任意音樂段落,不一定能找出與之在時序上足夠匹配的視頻。同時,針對不同的特定模式,例如舞蹈、音樂噴泉、煙火等,視頻尋找的方法更是沒法滿足匹配的一致性。
技術實現要素:
有鑑於此,本發明實施例提供了一種音頻數據可視化方法及裝置,以解決現有技術中對於任一音頻數據不能搜索出在時序上足夠匹配的視頻的問題。
本發明實施例的第一方面,提供了一種音頻數據可視化方法,包括:
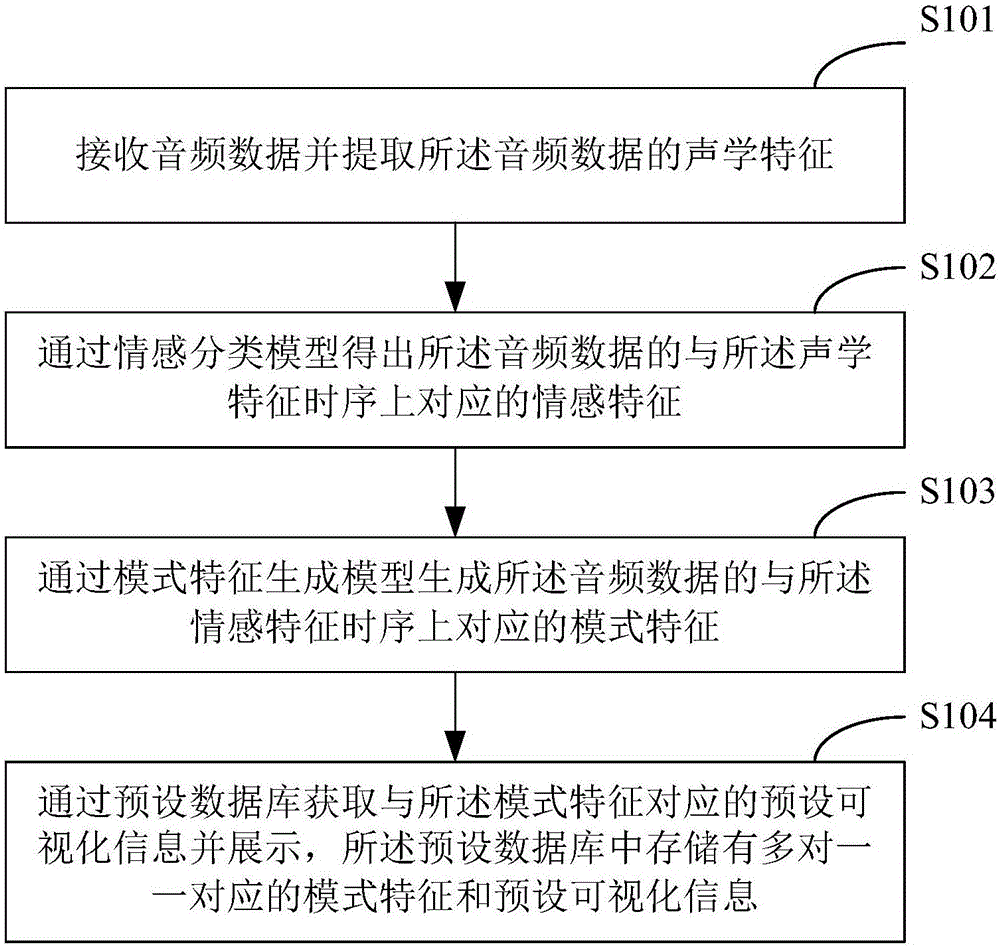
接收音頻數據並提取所述音頻數據的聲學特徵;
通過情感分類模型得出所述音頻數據的與所述聲學特徵時序上對應的情感特徵;
通過模式特徵生成模型生成所述音頻數據的與所述情感特徵時序上對應的模式特徵;
通過預設資料庫獲取與所述模式特徵對應的預設可視化信息並展示,所述預設資料庫中存儲有多對一一對應的模式特徵和預設可視化信息。
本發明實施例的第二方面,提供了一種音頻數據可視化裝置,包括:
聲學特徵提取模塊,用於接收音頻數據並提取所述音頻數據的聲學特徵;
情感特徵獲取模塊,用於通過情感分類模型得出與所述聲學特徵時序上對應的情感特徵;
模式生成模塊,用於通過模式特徵生成模型生成與所述情感特徵時序上對應的模式特徵;
可視化模塊,用於通過預設資料庫獲取與所述模式特徵對應的預設可視化信息並展示;所述預設資料庫中存儲有多對一一對應的模式特徵和預設可視化信息。
本發明實施例相對於現有技術所具有的有益效果:提取所述音頻數據的聲學特徵,通過情感分類模型得出所述音頻數據的與所述聲學特徵時序上對應的情感特徵,通過模式特徵生成模型生成所述音頻數據的與所述情感特徵時序上對應的模式特徵,通過預設資料庫獲取與所述模式特徵對應的預設可視化信息並展示,只需預先定義模式特徵的組合,即可根據任意音頻數據生成對應的模式特徵並予以顯示,而且聲學特徵、情感特徵和模式特徵之間在時序上相對應,因此相對於現有技術,音頻數據與可視化信息之間具有更好的一致性和匹配度。
附圖說明
為了更清楚地說明本發明實施例中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對於本領域普通技術人員來講,在不付出創造性勞動性的前提下,還可以根據這些附圖獲得其他的附圖。
圖1是本發明實施例提供的音頻數據可視化方法的流程圖;
圖2是本發明實施例提供的通過情感分類模型得出所述音頻數據的與所述聲學特徵時序上對應的情感特徵的流程圖;
圖3是本發明實施例提供的通過模式特徵生成模型生成所述音頻數據的與所述情感特徵時序上對應的模式特徵的流程圖;
圖4是本發明實施例提供的音頻數據可視化裝置的結構框圖。
具體實施方式
以下描述中,為了說明而不是為了限定,提出了諸如特定系統結構、技術之類的具體細節,以便透徹理解本發明實施例。然而,本領域的技術人員應當清楚,在沒有這些具體細節的其它實施例中也可以實現本發明。在其它情況中,省略對眾所周知的系統、裝置、電路以及方法的詳細說明,以免不必要的細節妨礙本發明的描述。
為了說明本發明所述的技術方案,下面通過具體實施例來進行說明。
實施例一:
圖1示出了本發明實施例一提供的音頻數據可視化方法的實現流程,詳述如下:
在步驟S101中,接收音頻數據並提取所述音頻數據的聲學特徵。
本實施例中,音頻數據採用包括但不限於wav編碼格式。其中,所述提取所述音頻數據的聲學特徵包括:
按照預設條件將所述音頻數據切分成多段子音頻數據;所述預設條件包括預設時長間隔;
對每段所述子音頻數據提取聲學特徵。
具體的,對接收到的音頻數據,按照預設條件先進行子音頻數據切分,使得每一子音頻數據儘可能只保留一種情感類別。例如,按照每隔兩秒時長的條件,將所述音頻數據切分成多個子音頻數據。
另外,還可以對所述音頻數據進行分幀,然後再使用基於Matlab的MIRToolbox工具來提取四種幀級別的特徵,分別是動態(dynamic)特徵、頻譜(spectral)特徵、音色(timbre)特徵以及聲調(tonal)特徵。分幀的窗寬可以是0.025秒,滑動距離0.01秒。
優選的,在執行步驟S102之前,本實施例的音頻數據可視化方法還包括:通過第一樣本數據對所述情感分類模型進行訓練,確定所述情感分類模型的參數。
本實施例中,情感分類模型的訓練需要第一樣本數據。所述第一樣本數據包括音頻段落的聲學特徵和與所述音頻段落的聲學特徵在時序上對應的情感標籤。作為一種可實施方式,情感標籤可以為激勵(arousal)和價(valence)的高低值。情感標籤可以由相關專業人士對音頻數據的時序切分進行標記。
訓練情感分類模型前,先對情感類別進行定義。由於情感激勵低時,價的高低不容易檢測,因此根據激勵和價分成三個情感類別,分別為高激勵-高價,高激勵-低價,低激勵。需要說明的是,在其他實施例中,情感分類還可以採用更為精細的分級,而不是僅僅是高-低分級。
本實施例中,使用隱馬爾可夫模型的結構訓練情感分類模型,使得每一幀音頻數據的情感類別能夠跟前面的幀存在依賴關係。在訓練情感分類器時,每一個情感類別構建一個隱狀態馬爾科夫模型,每個情感類別模型有三個可發射隱藏狀態,以及兩個不可發射隱藏狀態作為開始和結束。三個可發射隱藏狀態可以互相跳轉以及自跳轉。隱馬爾可夫模型的發射模型使用高斯混合模型。模型訓練使用第一樣本數據作為訓練數據,其情感類別標籤序列作為情感標籤,獲得優化的高斯混合模型參數和跳轉概率。隱馬爾可夫模型的訓練可以使用HTK工具進行。
在步驟S102中,通過情感分類模型得出所述音頻數據的與所述聲學特徵時序上對應的情感特徵。
本實施例中,提取出所述音頻數據的聲學特徵以後,通過情感分類模型得出所述音頻數據的與所述聲學特徵對應的情感特徵。其中,所述情感分類模型優選為基於隱馬爾可夫模型的情感分類模型。另外,情感分類模型還可以為基於遞歸神經網絡的情感分類模型等。本實施例中,以所述情感分類模型優選為基於隱馬爾可夫模型的情感分類模型為例進行說明,但並不以此為限。
具體的,對接收到的音頻數據,先進行音頻數據切分,使得每一子音頻數據儘可能只保留一種情感類別。例如,切成每兩秒時長一子音頻數據。對每一切分好的子音頻數據提取上述聲學特徵,再使用所述情感分類器得出所述音頻數據的與所述聲學特徵對應的情感特徵。
在步驟S103之前,本實施例的音頻數據可視化方法還包括:通過第二樣本數據對所述模式特徵生成模型進行訓練,確定所述模式特徵生成模型的參數。
本實施例中,模式特徵生成模型的訓練需要第二樣本書劇。所述第二樣本數據包括音頻段落的情感特徵和與所述音頻段落的情感特徵在時序上對應的模式特徵。模式特徵可以根據實際需要進行設定。以音樂噴泉為例,可以先定義噴泉的噴口數目,例如8個噴泉口。對於每個噴泉口,可以定義噴泉的高度和顏色,以及旋轉時的夾角和方向。然後錄製音樂噴泉的音樂-噴泉視頻,再由人工對視頻中的噴泉模式每隔一小段時間進行一次標記。
為了生成模式特徵,首先需要訓練模式特徵生成模型,本實施例中使用基於混合密度網絡的模式特徵生成模型,但並不以此為限。混合密度網絡是神經網絡的變種,本實施例中使用深度長短時記憶的神經網絡框架,輸出是混合高斯模型的參數,即權重、均值和方差。為了降低模式特徵生成模型的複雜性,本實施例中高斯函數均使用球體方差的形式。
訓練數據使用第二樣本數據,先對第二樣本數據內音頻數據進行情感特徵提取,然後使用前後連續的多幀情感特徵作為混合密度網絡的輸入特徵。例如,可以使用前後連續的11幀情感特徵作為混合密度網絡的輸入特徵,當並不以此為限。訓練的標籤是音樂段落對應的模式特徵以及其一階和二階差分。進一步的,由於模式特徵採樣率一般低於聲學特徵的分幀率,因此可對模式特徵進行平滑插值,使得採樣率跟聲學特徵的分幀率一致。訓練混合密度網絡時,訓練的目標函數是混合高斯模型的最大似然準則。
在步驟S103中,通過模式特徵生成模型生成所述音頻數據的與所述情感特徵時序上對應的模式特徵。
本實施例中,得出所述音頻數據的情感特徵以後,通過模式特徵生成模型生成所述音頻數據的與所述情感特徵對應的模式特徵。其中,所述模式特徵生成模型優選為基於混合密度網絡的模式特徵生成模型。另外,模式特徵生成模型還可以為基於遞歸神經網絡的模式特徵生成模型等。通過訓練後的所述模式特徵生成模型,根據步驟S102中得出的所述音頻數據的情感特徵,即可生成所述音頻數據的與所述情感特徵對應的模式特徵。
在步驟S104中,通過預設資料庫獲取與所述模式特徵對應的預設可視化信息並展示。
其中,所述預設資料庫中存儲有多對一一對應的模式特徵和預設可視化信息。在步驟S103S中生成所述音頻數據的模式特徵後,通過預設資料庫獲取與所述模式特徵對應的預設可視化信息。然後通過顯示裝置將該預設可視化信息按照時序進行顯示,從而完成將音頻數據可視化的過程。
優選的,預設資料庫中可以包括多類預設可視化信息,以滿足用戶多元化的需求。每一類預設可視化信息對應不同的可視化裝置。其中,可視化裝置可以包括噴泉等實體裝置用於對可視化信息進行展示。可視化裝置也可以包括相關應用程式虛擬工具用於對可視化信息進行顯示。用戶可以根據實際需要選定對應類的可視化信息。在選定可視化信息後,步驟S104會將所述模式特徵對應到選定類的可視化信息進行顯示。
上述音頻數據可視化方法,提取所述音頻數據的聲學特徵,通過情感分類模型得出所述音頻數據的與所述聲學特徵對應的情感特徵,通過模式特徵生成模型生成所述音頻數據的與所述情感特徵對應的模式特徵,通過預設資料庫獲取與所述模式特徵對應的預設可視化信息並展示,只需預先定義模式特徵的組合,即可根據任意音頻數據生成對應的模式特徵並予以顯示,而且聲學特徵、情感特徵和模式特徵之間在時序上相對應,因此相對於現有技術,音頻數據與可視化信息之間具有更好的一致性和匹配度。
實施例二:
圖2為本發明實施例提供的通過情感分類模型得出所述音頻數據的與所述聲學特徵時序上對應的情感特徵的流程圖,詳述如下:
在步驟S201中,通過基於隱馬爾科夫模型的情感分類模型,計算所述音頻數據的每一可發射隱藏狀態的後驗概率。
在步驟S202中,將所述音頻數據的各個可發射隱藏狀態的後驗概率形成特徵向量,所述特徵向量為所述音頻數據的情感特徵。
其中,對於所述音頻數據的每一情感類別的隱馬爾可夫模型,計算每一幀音頻數據歸類成每一類情感的每一可發射隱藏狀態的後驗概率。將計算出的這些後驗概率組成一組多維的特徵向量。例如,可以將這些後驗概率組成一組9維的特徵向量。上述特徵向量即為所述音頻數據的情感特徵。
優選的,為了解決過程中可能遇到的數值問題,後驗概率使用log後驗概率代替。
實施例三:
圖3為本發明實施例提供的通過模式特徵生成模型生成所述音頻數據的與所述情感特徵時序上對應的模式特徵的流程圖,詳述如下:
在步驟S301中,對於所述音頻數據的情感特徵,通過基於混合密度網絡的模式特徵生成模型,確定所述音頻數據的高斯混合模型參數。
在步驟S302中,對所述高斯混合模型,通過最大似然參數生成算法生成模式特徵。
其中,對於一段給定的音頻數據,使用實施例一種所述的模式特徵生成模型獲得每一幀音頻數據對應的高斯混合模型參數後,再使用最大似然參數生成算法生成模式特徵,再重新採樣為需要的模式特徵採樣率。
應理解,上述各個實施例中各步驟的序號的大小並不意味著執行順序的先後,各過程的執行順序應以其功能和內在邏輯確定,而不應對本發明實施例的實施過程構成任何限定。
實施例四:
對應於上文實施例所述的音頻數據可視化方法,圖4示出了本發明實施例提供的音頻數據可視化裝置的結構框圖。為了便於說明,僅示出了與本實施例相關的部分。
參照圖4,該裝置包括:聲學特徵提取模塊401、情感特徵獲取模塊402、模式生成模塊403和可視化模塊404。
聲學特徵提取模塊401,用於接收音頻數據並提取所述音頻數據的聲學特徵。情感特徵獲取模塊402,用於通過情感分類模型得出與所述聲學特徵時序上對應的情感特徵。模式生成模塊403,用於通過模式特徵生成模型生成與所述情感特徵時序上對應的模式特徵。可視化模塊404,用於通過預設資料庫獲取與所述模式特徵對應的預設可視化信息並展示;所述預設資料庫中存儲有多對一一對應的模式特徵和預設可視化信息。
進一步的,音頻數據可視化裝置還可以包括:
情感分類模型參數確定模塊,用於通過第一樣本數據對所述情感分類模型進行訓練,確定所述情感分類模型的參數;所述情感分類模型為基於隱馬爾科夫模型的情感分類模型;所述第一樣本數據包括音頻段落的聲學特徵和與所述音頻段落的聲學特徵在時序上對應的情感特徵。其中,在情感分類模型參數確定模塊確定完所述情感分類模型的參數之後,情感特徵獲取模塊402再通過情感分類模型得出與所述聲學特徵時序上對應的情感特徵。
進一步的,音頻數據可視化裝置還可以包括:
模式特徵生成模型參數確定模塊,用於通過第二樣本數據對所述模式特徵生成模型進行訓練,確定所述模式特徵生成模型的參數;所述模式特徵生成模型為基於混合密度網絡的模式特徵生成模型;所述第二樣本數據包括音頻段落的情感特徵和與所述音頻段落的情感特徵在時序上對應的模式特徵。其中,在模式特徵生成模型參數確定模塊確定完所述模式特徵生成模型的參數之後,模式生成模塊403再通過模式特徵生成模型生成與所述情感特徵時序上對應的模式特徵.
優選的,所述情感特徵獲取模塊包括:
計算單元,用於通過基於隱馬爾科夫模型的情感分類模型,計算所述音頻數據的每一可發射隱藏狀態的後驗概率;
情感特徵生成單元,用於將所述音頻數據的各個可發射隱藏狀態的後驗概率形成特徵向量,所述特徵向量為所述音頻數據的情感特徵。
優選的,模式生成模塊包括:
參數確定單元,用於對於所述音頻數據的情感特徵,通過基於混合密度網絡的模式特徵生成模型,確定所述音頻數據的高斯混合模型參數;
模式生成單元,用於對所述高斯混合模型,通過最大似然參數生成算法生成模式特徵。
優選的,所述聲學特徵提取模塊包括:
音頻切分單元,用於按照預設條件將所述音頻數據切分成多段子音頻數據;所述預設條件包括預設時長間隔;
聲學特徵提取單元,用於對每段所述子音頻數據提取聲學特徵。
上述音頻數據可視化裝置,提取所述音頻數據的聲學特徵,通過情感分類模型得出所述音頻數據的與所述聲學特徵時序上對應的情感特徵,通過模式特徵生成模型生成所述音頻數據的與所述情感特徵時序上對應的模式特徵,通過預設資料庫獲取與所述模式特徵對應的預設可視化信息並展示,只需預先定義模式特徵的組合,即可根據任意音頻數據生成對應的模式特徵並予以顯示,而且聲學特徵、情感特徵和模式特徵之間在時序上相對應,因此相對於現有技術,音頻數據與可視化信息之間具有更好的一致性和匹配度。
所屬領域的技術人員可以清楚地了解到,為了描述的方便和簡潔,僅以上述各功能單元、模塊的劃分進行舉例說明,實際應用中,可以根據需要而將上述功能分配由不同的功能單元、模塊完成,即將所述裝置的內部結構劃分成不同的功能單元或模塊,以完成以上描述的全部或者部分功能。實施例中的各功能單元、模塊可以集成在一個處理單元中,也可以是各個單元單獨物理存在,也可以兩個或兩個以上單元集成在一個單元中,上述集成的單元既可以採用硬體的形式實現,也可以採用軟體功能單元的形式實現。另外,各功能單元、模塊的具體名稱也只是為了便於相互區分,並不用於限制本申請的保護範圍。上述系統中單元、模塊的具體工作過程,可以參考前述方法實施例中的對應過程,在此不再贅述。
本領域普通技術人員可以意識到,結合本文中所公開的實施例描述的各示例的單元及算法步驟,能夠以電子硬體、或者計算機軟體和電子硬體的結合來實現。這些功能究竟以硬體還是軟體方式來執行,取決於技術方案的特定應用和設計約束條件。專業技術人員可以對每個特定的應用來使用不同方法來實現所描述的功能,但是這種實現不應認為超出本發明的範圍。
在本發明所提供的實施例中,應該理解到,所揭露的裝置和方法,可以通過其它的方式實現。例如,以上所描述的系統實施例僅僅是示意性的,例如,所述模塊或單元的劃分,僅僅為一種邏輯功能劃分,實際實現時可以有另外的劃分方式,例如多個單元或組件可以結合或者可以集成到另一個系統,或一些特徵可以忽略,或不執行。另一點,所顯示或討論的相互之間的耦合或直接耦合或通訊連接可以是通過一些接口,裝置或單元的間接耦合或通訊連接,可以是電性,機械或其它的形式。
所述作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位於一個地方,或者也可以分布到多個網絡單元上。可以根據實際的需要選擇其中的部分或者全部單元來實現本實施例方案的目的。
另外,在本發明各個實施例中的各功能單元可以集成在一個處理單元中,也可以是各個單元單獨物理存在,也可以兩個或兩個以上單元集成在一個單元中。上述集成的單元既可以採用硬體的形式實現,也可以採用軟體功能單元的形式實現。
所述集成的單元如果以軟體功能單元的形式實現並作為獨立的產品銷售或使用時,可以存儲在一個計算機可讀取存儲介質中。基於這樣的理解,本發明實施例的技術方案本質上或者說對現有技術做出貢獻的部分或者該技術方案的全部或部分可以以軟體產品的形式體現出來,該計算機軟體產品存儲在一個存儲介質中,包括若干指令用以使得一臺計算機設備(可以是個人計算機,伺服器,或者網絡設備等)或處理器(processor)執行本發明實施例各個實施例所述方法的全部或部分步驟。而前述的存儲介質包括:U盤、移動硬碟、只讀存儲器(ROM,Read-Only Memory)、隨機存取存儲器(RAM,Random Access Memory)、磁碟或者光碟等各種可以存儲程序代碼的介質。
以上所述實施例僅用以說明本發明的技術方案,而非對其限制;儘管參照前述實施例對本發明進行了詳細的說明,本領域的普通技術人員應當理解:其依然可以對前述各實施例所記載的技術方案進行修改,或者對其中部分技術特徵進行等同替換;而這些修改或者替換,並不使相應技術方案的本質脫離本發明各實施例技術方案的精神和範圍,均應包含在本發明的保護範圍之內。