Hadoop數據倉庫的自動導入數據方法及系統與流程
2023-05-05 10:50:06 1
本發明涉及了一種hadoop數據倉庫的自動導入數據方法及系統。
背景技術:
隨著企業要存儲和分析處理的數據量越來越大,hadoop越來越受到重視,hadoop是apache軟體基金會的開源項目。hadoop實現了一個分布式文件系統(hadoopdistributedfilesystem),簡稱hdfs。由於hadoop在可伸縮性、健壯性、計算性能和成本上具有無可替代的優勢,已然成為當前主流的大數據存儲和分析平臺。
目前應用於大數據分析的基礎數據通常是保存於如mysql、sqlsever、db2等關係型資料庫中,由於對數據分析和處理的需要,需要將這些基礎數據進行篩選並導入至hadoop的hive數據倉庫中,通過hadoop平臺的運算處理能力實現針對大數據的數據分析。sqoop是一款開源工具,利用sqoop我們能夠在hadoop生態圈中建立一個供其他伺服器調用的接口,通過調用該接口可以實現將關係型資料庫中指定的數據導入到hadoop的hdfs中,hadoop最終再將這些hdfs文件導入至hive數據倉庫中。由於用於分析的數據經常性會變動,每次進行數據更新時,都需要採用人工敲入代碼的方式來調用數據傳輸接口,面對複雜的傳輸和處理流程,要求工作人員必須定時定期操作,因此費時費力。
技術實現要素:
針對現有技術的不足,本發明提供了一種hadoop數據倉庫的自動導入數據方法及系統,解決了現有技術中每次將關係型資料庫中的數據傳輸至hadoop的數據倉庫時需要人工操作的不便之處。
為實現上述目的,本發明提供了一種hadoop數據倉庫的自動導入數據方法,包括:
步驟一:搭載hadoop數據倉庫的伺服器c預先配置用於從搭載關係型資料庫的伺服器a中獲取數據的數據傳輸接口;
步驟二:搭載作業調度器的伺服器b預先配置用於調用所述數據傳輸接口的調用命令以及執行該調用命令的執行周期;
步驟三:伺服器b按照執行周期定期執行調用命令;
步驟四:伺服器c從伺服器a中獲取數據並生成hdfs分布式文件系統文件;
步驟五:伺服器c將生成的hdfs文件導入至hive數據倉庫中。
作為本發明的進一步改進,
所述步驟一具體包括:
伺服器c預先配置數據傳輸接口的接口參數,該接口參數包括用於和伺服器a建立連接關係的伺服器a的資料庫地址、資料庫用戶名和密碼、伺服器c的主機名以及用戶名和密碼,以及用於獲取指定數據的數據篩選條件、表名以及列名。
作為本發明的進一步改進,
所述步驟三和步驟四之間還包括:
步驟a:伺服器b監控伺服器a中hdfs文件的生成情況;
所述步驟四和步驟五之間還包括:
步驟b:伺服器b在監控到伺服器a中hdfs文件生成完畢後向伺服器c發送將hdfs數據導入至hive數據倉庫的指令。
本發明還提供了一種hadoop數據倉庫的自動導入數據系統,包括:
伺服器a,用於搭載存儲基礎數據的關係型資料庫;
伺服器b,用於搭載作業調度器,用於預先配置調用所述數據傳輸接口的調用命令,以及按照執行周期定期執行調用命令;
伺服器c,用於搭載hadoop數據倉庫,用於預先配置從搭載關係型資料庫的伺服器a中獲取數據的數據傳輸接口,用於從伺服器a中獲取數據並生成hdfs文件,以及將生成的hdfs文件導入至hive數據倉庫中。
作為本發明的進一步改進,
所述伺服器b包括:
調用命令配置模塊,用於輸入數據傳輸接口的調用命令;
執行周期配置模塊,用於配置執行調用指令的執行周期。
作為本發明的進一步改進,
所述伺服器c包括:
數據傳輸接口配置模塊,用於配置數據傳輸接口;
hdfs文件生成模塊,用於將獲取的數據轉化為hdfs文件;
hive數據倉庫導入模塊,用於將生成的hdfs文件導入至hive數據倉庫中。
作為本發明的進一步改進,
所述調用命令配置模塊包括:
接口參數配置單元:用於配置數據傳輸接口的接口參數,接口參數包括數據篩選條件、伺服器a的資料庫地址、表名以及列名。
作為本發明的進一步改進,
所述伺服器b還包括:
hdfs文件監控模塊:用於監控伺服器c中hdfs文件的生成情況;
指令發送模塊:用於向伺服器c發送將hdfs數據導入至hive數據倉庫的指令。
本發明的有益效果是:本申請技術方案提供的hadoop數據倉庫的自動導入數據方法及系統,應用於關係型資料庫到分布式系統架構中hive數據倉庫的數據導入,實現了關係型資料庫的數據能夠定時定期地導入至hadoop的hive數據倉庫中。與傳統技術相比,面對複雜的傳輸和處理流程不需要人工進行操作,節省了工作人員的時間,而且不容易出錯。
附圖說明
圖1為本發明hadoop數據倉庫的自動導入數據方法實施例的流程圖;
圖2為本發明hadoop數據倉庫的自動導入數據系統實施例的結構框圖;
圖3為本發明hadoop數據倉庫的自動導入數據系統實施例中伺服器b的結構框圖;
圖4為本發明hadoop數據倉庫的自動導入數據系統實施例中伺服器c的結構框圖;
圖5為本發明hadoop數據倉庫的自動導入數據系統實施例中調用命令配置模塊的結構框圖。
具體實施方式
為使本發明的目的、技術方案及優點更加清楚明白,以下參照附圖並舉實施例,對本發明進一步詳細說明。
本發明hadoop數據倉庫的自動導入數據方法的實施例,如圖1所示,包括:
步驟一100:搭載hadoop數據倉庫的伺服器c預先配置用於從搭載關係型資料庫的伺服器a中獲取數據的數據傳輸接口;
步驟二101:搭載作業調度器的伺服器b預先配置用於調用所述數據傳輸接口的調用命令以及執行該調用命令的執行周期;
步驟三102:伺服器b按照執行周期定期執行調用命令;
步驟四103:伺服器c從伺服器a中獲取數據並生成hdfs文件;
步驟五104:伺服器c將生成的hdfs文件導入至hive數據倉庫中。
在本實施例中,所述步驟一具體包括:
伺服器c預先配置數據傳輸接口的接口參數,該接口參數包括用於和伺服器a建立連接關係的伺服器a的資料庫地址、資料庫用戶名和密碼、伺服器c的主機名以及用戶名和密碼,以及用於獲取指定數據的數據篩選條件、表名以及列名。
伺服器b通過調用伺服器a中預先配置的數據傳輸接口能夠實現伺服器a和伺服器c之間建立連接關係,並且伺服器c從伺服器a中獲取指定的數據。
在本實施例中,
所述步驟三102和步驟四103之間還包括:
步驟a110:伺服器b監控伺服器a中hdfs文件的生成情況;
伺服器c在從伺服器a中獲取數據時,會生成相應的hdfs文件,伺服器b定時通過hadoopfs-get語句獲取此hdfs文件,以此判斷數據獲取是否完成。
所述步驟四103和步驟五104之間還包括:
步驟b120:伺服器b在監控到伺服器a中hdfs文件生成完畢後向伺服器c發送將hdfs數據導入至hive數據倉庫的指令。
在此過程中,伺服器b向伺服器c發送hive接口的load指令,伺服器c在收到伺服器b發送的指令後將hdfs文件導入至hive數據倉庫中。
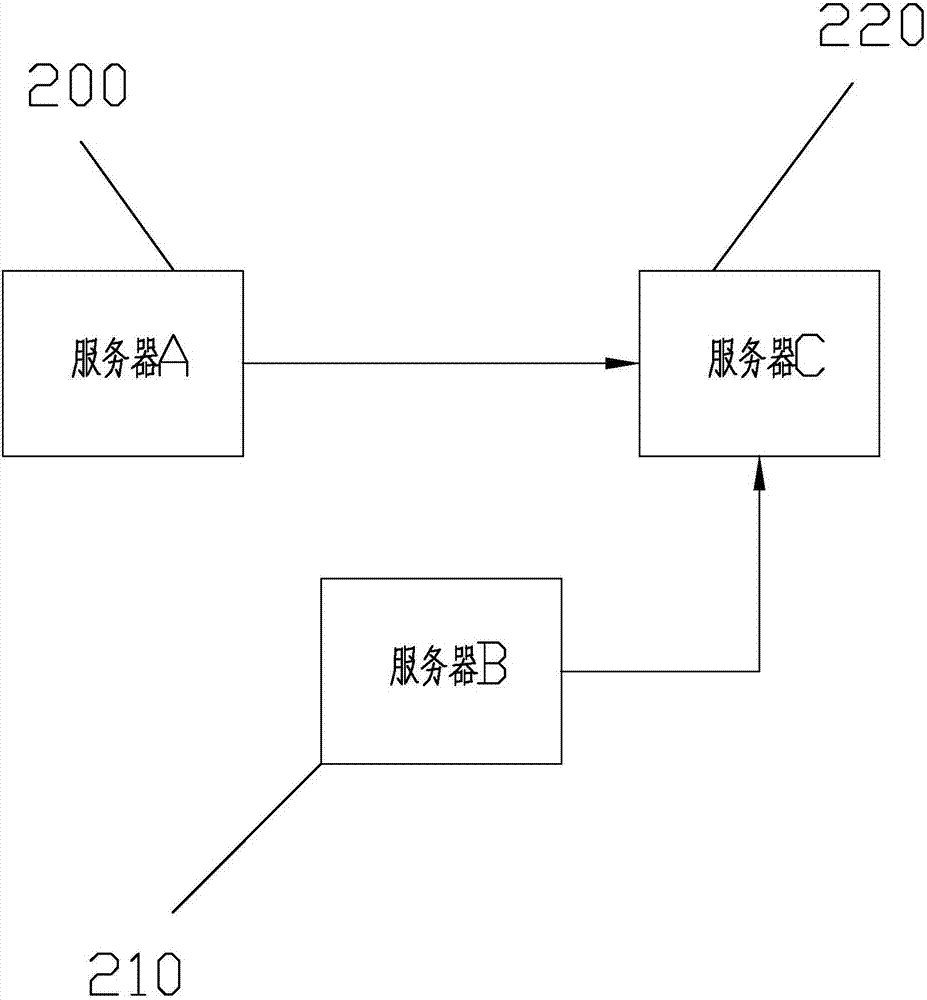
本發明hadoop數據倉庫的自動導入數據系統的實施例如圖2-5所示,包括:
伺服器a200,用於搭載存儲基礎數據的關係型資料庫;
伺服器b210,用於搭載作業調度器,用於預先配置調用所述數據傳輸接口的調用命令,以及按照執行周期定期執行調用命令;
伺服器c220,用於搭載hadoop數據倉庫,用於預先配置從搭載關係型資料庫的伺服器a200中獲取數據的數據傳輸接口,用於從伺服器a200中獲取數據並生成hdfs文件,以及將生成的hdfs文件導入至hive數據倉庫中。
在本實施例中,所述伺服器b210包括:
調用命令配置模塊211,用於輸入數據傳輸接口的調用命令;
執行周期配置模塊212,用於配置執行調用指令的執行周期。
在本實施例中,所述伺服器c220包括:
數據傳輸接口配置模塊221,用於配置數據傳輸接口;
hdfs文件生成模塊222,用於將獲取的數據轉化為hdfs文件;
hive數據倉庫導入模塊223,用於將生成的hdfs文件導入至hive數據倉庫中。
在本實施例中,所述調用命令配置模塊211包括:
接口參數配置單元211a:用於配置數據傳輸接口的接口參數,接口參數包括數據篩選條件、伺服器a200的資料庫地址、表名以及列名。
作為本發明的進一步改進,
所述伺服器b210還包括:
hdfs文件監控模塊213:用於監控伺服器c220中hdfs文件的生成情況;
指令發送模塊214:用於向伺服器c220發送將hdfs數據導入至hive數據倉庫的指令。
本發明應用於關係型資料庫到分布式系統架構中hive數據倉庫的數據導入,實現了關係型資料庫的數據能夠定時定期地導入至hadoop的hive數據倉庫中。與傳統技術相比,面對複雜的傳輸和處理流程不需要人工進行操作,節省了工作人員的時間,而且不容易出錯。
需要說明的是,本發明中所述的伺服器b和伺服器c可以是同一伺服器,當伺服器b和伺服器c為同一伺服器時,該伺服器同時搭載有hadoop集群和作業調度器,通過在該伺服器端進行相應的配置,同樣能夠實現本發明所能達到的效果。
以上實施例,只是本發明優選地具體實施例的一種,本領域技術人員在本發明技術方案範圍內進行的通常變化和替換都包含在本發明的保護範圍內。