用於二進位算術編/解碼的概率更新方法及使用該方法的熵編/解碼器與流程
2023-05-15 01:49:16 4
本公開涉及熵編碼和熵解碼,更具體地,涉及在基於上下文的二進位算術編碼和解碼中使用的概率模型更新方法和設備。
背景技術:
在h.264和mpeg-4中,視頻信號分層次地分成序列、幀、片、宏塊和塊。塊成為最小的處理單元。就編碼而言,通過幀內預測或幀間預測來獲得塊的殘留數據。此外,通過變換、量化、掃描、行程長度編碼和熵編碼來壓縮殘留數據。作為熵編碼技術,存在基於上下文的自適應二進位算術編碼(在下文中稱為cabac)。根據cabac,使用上下文索引ctxldx來確定一個上下文模型;確定所確定的上下文模型的最小可能符號(lps)或最大可能符號(mps)的發生概率以及關於0和1之間的哪個二進位值對應於mps的信息valmps;以及基於valmps和lps的概率執行二進位算術編碼。
技術實現要素:
本公開要解決的技術問題是:通過改進在基於上下文的二進位算術編碼/解碼處理期間執行的概率更新過程,來提高圖像壓縮效率。
技術問題
根據本公開實施方式,基於二進位位的自相關值或二進位位的熵值來確定縮放因子,並且通過使用確定的縮放因子來更新在二進位算術編碼和解碼中使用的概率。
本發明的有益效果
根據本公開實施方式,可通過最小化二進位位值和二進位位預測概率之間的誤差值來減少由算術編碼引起的位發生量(bitoccurrenceamount)。
附圖說明
圖1是根據本公開實施方式的視頻編碼設備的框圖;
圖2是根據本公開實施方式的視頻解碼設備的框圖;
圖3是根據本公開實施方式用於描述編碼單元的概念的圖;
圖4是根據本公開實施方式基於編碼單元的圖像編碼器的框圖;
圖5是根據本公開實施方式基於編碼單元的圖像編碼器的框圖;
圖6是示出根據本公開實施方式基於深度的較深層編碼單元和分區的圖;
圖7是根據本公開實施方式用於描述編碼單元和變換單元之間的關係的圖;
圖8示出根據本公開實施方式的根據深度的多條編碼信息;
圖9是根據本公開實施方式的根據深度的較深層編碼單元的圖;
圖10、圖11和圖12是根據本公開實施方式描述編碼單元、預測單元和頻率變換單元之間關係的圖;
圖13是根據表格1的編碼模式信息描述編碼單元、預測單元和變換單元之間關係的圖;
圖14是根據本公開實施方式的熵編碼設備的框圖;
圖15a和圖15b示出在基於上下文的自適應二進位算術編碼(cabac)中使用的概率更新過程;
圖16是根據本公開實施方式的概率更新過程的流程圖;
圖17a和圖17b是用於說明自相關值的參考圖;
圖18是根據本公開實施方式用於二進位算術編碼的概率更新方法的流程圖;
圖19是根據本公開的另一實施方式在cabac中使用的概率更新方法的流程圖;
圖20a和圖20b示出基於cabac執行二進位算術編碼的過程;
圖21是根據縮放因子的數量基於自相關值rk確定的縮放因子α的變化的圖;
圖22是根據縮放因子的數量的均方誤差(mse)的變化的圖;
圖23是根據本公開實施方式的熵解碼設備的框圖;
圖24是根據本公開實施方式用於二進位算術解碼的概率更新方法的流程圖;
圖25是根據本公開的另一實施方式用於二進位算術解碼的概率更新方法的流程圖。
具體實施方式
根據本公開實施方式,用於二進位算術解碼的概率更新方法包括:接收要進行二進位算術解碼的預定數量的二進位位(bin);通過使用接收到的預定數量的二進位位的值來獲得每個二進位位的自相關值;基於所述自相關值確定用於更新二進位值的概率的至少一個縮放因子;通過使用所確定的至少一個縮放因子來更新在基於上下文的自適應二進位算術解碼中使用的概率;以及通過使用更新的概率對當前二進位位進行算術解碼。
根據本公開實施方式,用於二進位算術編碼的概率更新方法包括:接收要進行二進位算術編碼的預定數量的二進位位;通過使用接收到的預定數量的二進位位的值來獲得每個二進位位的自相關值;基於所述自相關值確定用於更新二進位值的概率的至少一個縮放因子;通過使用所確定的至少一個縮放因子來更新在基於上下文的自適應二進位算術編碼中使用的概率;以及通過使用更新的概率對當前二進位位進行算術編碼。
根據本公開實施方式,用於二進位算術解碼的概率更新方法包括:接收要進行二進位算術解碼的預定數量的二進位位;通過使用具有不同縮放因子的多個概率模型來獲得指示二進位位的平均位值的熵值;確定用於在多個概率模型中獲得最小熵值的概率模型的縮放因子;以及對二進位位執行基於上下文的自適應二進位算術解碼,其中所述自適應二進位算術解碼包括利用所確定的縮放因子執行概率更新過程。
根據本公開實施方式,用於二進位算術編碼的概率更新方法包括:接收要進行二進位算術編碼的預定數量的二進位位;通過使用具有不同縮放因子的多個概率模型來獲得指示二進位位的平均位值的熵值;確定用於在多個概率模型中獲得最小熵值的概率模型的縮放因子;以及對二進位位執行基於上下文的自適應二進位算術編碼,其中所述自適應二進位算術編碼包括使用所確定的縮放因子執行概率更新過程。
根據本公開實施方式,熵解碼設備包括逆二值化器、上下文建模器和常規解碼器,其中,逆二值化器配置成將預定語法元素的值映射到二進位值的二進位位;上下文建模器配置成:接收要進行二進位算術解碼的預定數量的二進位位,通過使用接收到的預定數量的二進位位的值來獲得每個二進位位的自相關值,基於自相關值確定用於更新二進位值的概率的至少一個縮放因子,並通過使用確定的至少一個縮放因子更新在基於上下文的自適應二進位算術解碼中使用的概率;以及常規解碼器配置成通過使用更新的概率對當前二進位位進行算術解碼。
根據本公開實施方式,熵編碼設備包括二值化器、上下文建模器和常規編碼器,其中,二值化器配置成將預定語法元素的值映射到二進位值的二進位位;上下文建模器配置成:接收要進行二進位算術編碼的預定數量的二進位位,通過使用接收到的預定數量的二進位位的值來獲得每個二進位位的自相關值,基於自相關值確定用於更新二進位值的概率的至少一個縮放因子,並通過使用確定的至少一個縮放因子來更新在基於上下文的自適應二進位算術編碼中使用的概率;以及常規編碼器配置成通過使用更新的概率對當前二進位位進行算術編碼。
根據本公開實施方式,熵解碼設備包括逆二值化器、上下文建模器和常規解碼器,其中,逆二值化器配置成將二進位值的二進位位映射到預定語法元素的值;上下文建模器配置成:接收要進行二進位算術解碼的預定數量的二進位位,通過使用具有不同縮放因子的多個概率模型來獲得指示二進位位的平均位值的熵值,確定用於在多個概率模型中獲得最小熵值的概率模型的縮放因子,並使用所確定的縮放因子執行概率更新過程;以及常規解碼器配置成通過使用更新的概率對當前二進位位進行算術解碼。
本發明的詳細描述
將參照附圖對本公開的優選示例進行詳細描述。
圖1是根據本公開實施方式的視頻編碼設備的框圖。
根據實施方式的視頻編碼設備100包括最大編碼單元(lcu)分割器110、編碼單元確定器120和輸出器130。
lcu分割器110可基於lcu分割當前畫面,其中lcu是圖像當前畫面所具有的最大尺寸的編碼單元。如果當前畫面大於lcu,則當前畫面的圖像數據可被分割成至少一個lcu。根據實施方式的lcu可以是具有32×32、64×64、128×128、256×256等尺寸的數據單元,其中數據單元的形狀是具有寬度和長度均為2的倍數並大於8的正方形。圖像數據可根據至少一個lcu輸出至編碼單元確定器120。
根據實施方式的編碼單元可由最大尺寸和深度來表徵。深度表示編碼單元在空間上從最大編碼單元開始被分割的次數,且隨著深度加深,根據深度的較深層編碼單元可以從最大編碼單元被分割到最小編碼單元。最大編碼單元的深度是最上層深度,最小編碼單元的深度是最下層深度。由於與每個深度對應的編碼單元的尺寸隨著最大編碼單元的深度加深而減小,因而與較上層深度對應的編碼單元可包括與更下層深度對應的多個編碼單元。
如上所述,根據編碼單元的最大尺寸,將當前畫面的圖像數據分割成最大編碼單元,且最大編碼單元中的每一個可包括根據深度分割的較深層編碼單元。由於根據實施方式的最大編碼單元根據深度分割,因而最大編碼單元中所包括的空間域的圖像數據可根據深度被分層地分類。
可預先確定編碼單元的、限制最大編碼單元的高度和寬度被分層分割的總次數的最大深度和最大尺寸。
編碼單元確定器120對通過根據深度分割最大編碼單元的區域而獲得的至少一個分割區域進行編碼,並且根據所述至少一個分割區域確定輸出最終編碼圖像數據的深度。換句話說,通過對根據當前畫面的最大編碼單元、基於深度的較深層編碼單元中的圖像數據進行編碼、以及選擇具有最小編碼誤差的深度,編碼單元確定器120確定編碼深度。將確定的編碼深度和每個lcu的圖像數據輸出至輸出器130。
基於與等於或低於最大深度的至少一個深度對應的較深層編碼單元對最大編碼單元中的圖像數據進行編碼,並且對基於較深層編碼單元中的每個編碼圖像數據的結果進行比較。可在對比較深層編碼單元的編碼誤差之後選擇具有最小編碼誤差的深度。可為每個最大編碼單元選擇至少一個編碼深度。
隨著編碼單元根據深度被分層分割以及隨著編碼單元的數量增加,最大編碼單元的尺寸被分割。此外,即使各編碼單元對應於一個最大編碼單元中的同一深度,依然通過分別測量每個編碼單元的圖像數據的編碼誤差來確定是否將對應於同一深度的編碼單元中每一個分割到更下層深度。因此,即使當圖像數據包含在一個最大編碼單元中時,圖像數據仍將根據深度被分割成各區域,且在一個最大編碼單元中編碼誤差可能根據區域而不同,因而在圖像數據中編碼深度可根據區域而不同。因此,可在一個最大編碼單元中設置一個或多個編碼深度,並且可以根據至少一個編碼深度的編碼單元將最大編碼單元的圖像數據劃分開。
因此,根據實施方式的編碼單元確定器120可確定在當前最大編碼單元中所包括的具有樹結構的編碼單元。根據實施方式的「具有樹結構的編碼單元」包括:最大編碼單元中所包括的所有較深層編碼單元之中、與確定為編碼深度的深度相對應的編碼單元。在最大編碼單元的同一區域中,可根據深度分層確定具有編碼深度的編碼單元;以及在不同的區域中,可獨立確定具有編碼深度的編碼單元。同樣地,可獨立於另一個區域中的編碼深度,確定當前區域中的編碼深度。
根據實施方式的最大深度是與從最大編碼單元到最小編碼單元的分割次數相關的索引。根據實施方式的第一最大深度可表示從最大編碼單元到最小編碼單元的分割次數的總數。根據實施方式的第二最大深度可表示從最大編碼單元到最小編碼單元的深度層級的總數。例如,當最大編碼單元的深度是0時,最大編碼單元進行一次分割的編碼單元的深度可設置為1,而最大編碼單元進行兩次分割的編碼單元的深度可設置為2。這裡,如果最小編碼單元是其中最大編碼單元被分割四次的編碼單元,則存在深度0、1、2、3和4的深度層級,因此第一最大深度可設置為4,第二最大深度可設置為5。
可根據最大編碼單元執行預測編碼和頻率變換。還根據最大編碼單元、基於深度等於或小於最大深度的較深層編碼單元,執行預測編碼和頻率變換。
由於不論何時根據深度分割最大編碼單元,較深層編碼單元的數量均增大,因此對深度加深時所生成的所有較深層編碼單元執行編碼(包括預測編碼和頻率變換)。為描述的方便,現在將基於最大編碼單元中的當前深度編碼單元對預測編碼和頻率變換進行描述。
根據實施方式的視頻編碼設備100可選擇用於圖像數據編碼的不同尺寸或形狀的數據單元。為了對圖像數據進行編碼,可執行諸如預測編碼、頻率變換和熵編碼等操作,此時對所有操作可使用相同的數據單元或者對每一個操作可使用不同的數據單元。
例如,視頻編碼設備100不僅可選擇用於對圖像數據編碼的編碼單元,還可選擇與編碼單元不同的數據單元,以對編碼單元中的圖像數據執行預測編碼。
為了在最大編碼單元中執行預測編碼,可基於與編碼深度相對應的編碼單元(即基於不再分割為與更下層深度相對應的編碼單元的編碼單元)執行預測編碼。在下文中,現將不再進行分割並成為預測編碼的基礎單元的編碼單元稱為「預測單元」。通過分割預測單元獲得的分區可包括通過分割預測單元的高度和寬度中的至少一個獲得的預測單元或數據單元。
例如,當2n×2n(其中n是正整數)的編碼單元不再進行分割並且成為2n×2n的預測單元時,則分區的尺寸可為2n×2n、2n×n、n×2n或n×n。分區類型的示例可包括通過對稱地分割預測單元的高度或寬度獲得的對稱分區,並且可選擇性地包括通過對預測單元的高度或寬度進行不對稱分割(諸如1:n或n:1)獲得的分區、通過對預測單元進行幾何分割獲得的分區、具有任意形狀的分區等。
預測單元的預測模式可以是幀內模式、幀間模式和跳過模式中的至少一者。例如,可對2n×2n、2n×n、n×2n或n×n的分區執行幀內模式和幀間模式。此外,可僅對2n×2n的分區執行跳過模式。對編碼單元中的一個預測單元獨立地執行編碼,由此選擇具有最小編碼誤差的預測模式。
根據實施方式的視頻編碼設備100不僅可基於用於對圖像數據進行編碼的編碼單元來對編碼單元中的圖像數據執行頻率變換,還可基於與編碼單元不同的數據單元對圖像數據執行頻率變換。
為了在編碼單元中執行頻率變換,可基於具有等於或小於編碼單元的尺寸的數據單元執行頻率變換。例如,用於頻率變換的數據單元可包括幀內模式的數據單元和幀間模式的數據單元。
用作頻率變換的基礎的數據單元稱為「變換單元」。類似於編碼單元,可將編碼單元中的變換單元遞歸地分割為更小尺寸的區域,從而可以區域為單位獨立確定變換單元。因此,可基於根據變換深度的、具有樹結構的變換單元對編碼單元中的殘差數據進行分割。
還可以在根據實施方式的變換單元中設置指示通過對編碼單元的高度和寬度進行分割來達到變換單元的分割次數的變換深度。例如,在2n×2n的當前編碼單元中,當變換單元的尺寸為2n×2n時,變換深度可以為0,當變換單元的尺寸為n×n時,變換深度可以為1,並且當變換單元的尺寸為n/2×n/2時,變換深度可以為2。換句話說,可根據變換深度設置具有樹結構的變換單元。
根據與編碼深度對應的編碼單元的編碼信息不僅需要關於編碼深度的信息,還需要關於與預測編碼和變換有關的信息。因此,編碼單元確定器120不僅確定具有最小編碼誤差的編碼深度,還確定將預測單元分割成分區的分區類型、根據預測單元的預測模式以及用於頻率變換的變換單元的尺寸。
下面將參考圖3至圖12詳細描述根據實施方式、基於最大編碼單元中的樹結構的編碼單元和確定分區的方法。
編碼單元確定器120可通過使用基於拉格朗日乘數的速率失真優化來測量根據深度的較深層編碼單元的編碼誤差。
輸出單元130以比特流輸出最大編碼單元的圖像數據和根據深度的編碼模式信息,其中所述圖像數據基於由編碼單元確定器120確定的至少一個編碼深度被編碼。
可通過對圖像的殘差數據進行編碼來獲得編碼圖像數據。
根據深度的編碼模式信息可包括編碼深度信息、預測單元的分區類型信息、預測模式信息和變換單元尺寸信息。
可通過使用根據深度的分割信息來定義指定是否對更下層深度而不是當前深度的編碼單元執行編碼的編碼深度信息。如果當前編碼單元的當前深度是編碼深度,則對當前編碼單元進行編碼,因此分割信息可被定義為不將當前編碼單元分割至更下層深度。在之相反,如果當前編碼單元的當前深度不是編碼深度,則必須對更下層深度的編碼單元執行編碼,因此當前深度的分割信息可被定義為將當前編碼單元分割至更下層深度的編碼單元。
如果當前深度不是編碼深度,則對被分割為更下層深度的編碼單元的編碼單元來執行編碼。由於在當前深度的一個編碼單元中存在更下層深度的至少一個編碼單元,因此對更下層深度的每個編碼單元重複執行編碼,因此,可針對具有相同深度的編碼單元遞歸地執行編碼。
由於對一個最大編碼單元確定具有樹結構的編碼單元,並且對編碼深度的編碼單元確定與至少一個編碼模式有關的信息,因此可對一個最大編碼單元確定與至少一個編碼模式有關的信息。此外,由於圖像數據根據深度進行分層分割,因此最大編碼單元的圖像數據的編碼深度可根據位置而不同,因此,可針對圖像數據設置與編碼深度和編碼模式有關的信息。
因此,根據實施方式的輸出單元130可將與相應編碼深度和編碼模式有關的編碼信息分配給最大編碼單元中所包括的編碼單元、預測單元和最小單元中的至少一個。
根據實施方式的最小單元是通過將構成最低深度的最小編碼單元分割4次所獲得的矩形數據單元。可替代地,最小單元可以是最大矩形數據單元,該數據單元可包括最大編碼單元中所包括的所有的編碼單元、預測單元、分區單元和變換單元中。
例如,由輸出單元130輸出的編碼信息可被分類為根據較深層編碼單元的編碼信息和根據預測單元的編碼信息。根據較深層編碼單元的編碼信息可包括預測模式信息和分區尺寸信息。根據預測單元的編碼信息可包括關於幀間模式期間的估計方向的信息、關於幀間模式的參考圖像索引的信息、關於運動矢量的信息、關於幀內模式的色度分量的信息和關於幀內模式的插值方法的信息。此外,與根據畫面、切片或gop定義的編碼單元的最大尺寸有關的信息以及與最大深度有關的信息可插入到比特流的頭部中。
根據視頻編碼設備100的最簡單的實施方式,較深層編碼單元可以是通過將上一層的上層深度編碼單元的高度或寬度分割2次所獲得的編碼單元。也就是說,在當前深度的編碼單元的尺寸為2n×2n時,更下層深度編碼單元的尺寸為n×n。此外,具有2n×2n的尺寸的當前編碼單元最多可包括具有n×n的尺寸的四個更下層深度的編碼單元。
因此,視頻編碼設備100可通過基於考慮當前畫面的特性所確定的最大編碼單元的尺寸和最大深度,對每個最大編碼單元確定具有最佳形狀和最佳尺寸的編碼單元,來形成具有樹結構的編碼單元。此外,由於可通過使用各種預測模式和頻率變換中的任一者來對每個最大編碼單元執行編碼,因此可通過考慮各種圖像尺寸的編碼單元的特性來確定最佳編碼模式。
因此,如果以傳統的宏塊對具有高解析度或大數據量的圖像進行編碼,則每個畫面的宏塊數量過度增加。因此,針對每個宏塊所生成的壓縮信息的條數增加,因此難以發送壓縮信息並且降低數據壓縮效率。然而,通過使用根據實施方式的視頻編碼設備,由於在考慮圖像尺寸的情況下增加編碼單元的最大尺寸,並且在考慮圖像特性的情況下調整編碼單元,因此可提高圖像壓縮效率。
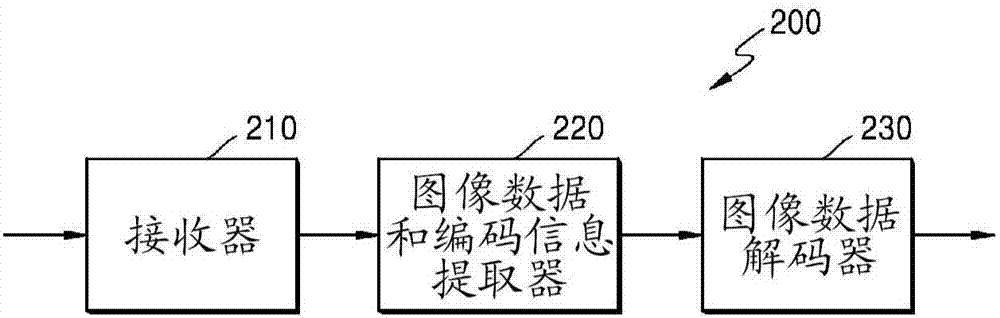
圖2是根據本公開實施方式的視頻解碼設備的框圖。
根據實施方式的視頻解碼設備200包括接收器210、圖像數據和編碼信息提取器220以及圖像數據解碼器230。用於視頻解碼設備200的各種處理的各種術語(諸如編碼單元、深度、預測單元、變換單元和關於各種編碼模式的信息)的定義與參照圖1和視頻編碼設備100描述的那些術語相同。
接收器210接收並解析編碼視頻的比特流。圖像數據和編碼信息提取器220從解析的比特流中提取每個編碼單元的編碼圖像數據,並將提取的圖像數據輸出到圖像數據解碼器230,其中編碼單元根據每個最大編碼單元具有樹結構。圖像數據和編碼信息提取器220可從關於當前畫面的頭部中提取關於當前畫面的編碼單元的最大尺寸信息。
此外,圖像數據和編碼信息提取器220從解析的比特流中提取與根據每個最大編碼單元具有樹結構的編碼單元有關的編碼深度和編碼模式信息。提取的編碼深度和編碼模式信息輸出到圖像數據解碼器230。換句話說,比特流中的圖像數據被分割為最大編碼單元,使得圖像數據解碼器230對每個最大編碼單元的圖像數據進行解碼。
可針對一條或多條編碼深度信息來設置與每個最大編碼單元的編碼深度和編碼模式有關的信息。與每個編碼深度的編碼模式有關的信息可包括編碼單元的分區類型信息、預測模式信息、變換單元的尺寸信息等。此外,可提取根據深度的分割信息作為與編碼深度有關的信息。
與根據實施方式的視頻編碼設備100類似,由圖像數據和編碼信息提取器220提取的、與每個最大編碼單元的編碼深度和編碼模式有關的信息是與這樣的編碼深度和編碼模式有關的信息,其中所述編碼深度和編碼模式被確定為在編碼結束時通過根據每個最大編碼單元、對每一深度的每個編碼單元重複執行編碼來生成最小編碼誤差。因此,視頻解碼設備200可通過根據生成最小編碼誤差的編碼模式對數據進行解碼來恢復圖像。
根據實施方式的與編碼深度和編碼模式有關的編碼信息可分配至編碼單元、預測單元和最小單元中的預定數據單元,因此圖像數據和編碼信息提取器220可根據預定數據單元提取與編碼深度和編碼模式有關的信息。當將相應的最大編碼單元的編碼深度和編碼模式信息分配給預定數據單元中的每一個時,分配有相同編碼深度和編碼模式信息的預定數據單元可推斷為包括在同一最大編碼單元中的數據單元。
圖像數據解碼器230通過基於與根據每個最大編碼單元的編碼深度和編碼模式有關的信息對每個最大編碼單元中的圖像數據進行解碼,來恢復當前畫面。也就是說,圖像數據解碼器230可基於包括在每個最大編碼單元中的、具有樹結構的編碼單元中每個編碼單元的讀取分區類型、預測模式和變換單元,來對編碼圖像數據進行解碼。解碼操作可包括預測(包括幀內預測和運動補償)和逆變換。
圖像數據解碼器230可基於與根據編碼深度的編碼單元的預測單元有關的分區模式信息和預測類型信息,根據每個編碼單元的分區和預測模式執行幀內預測或運動補償。
此外,圖像數據解碼器230可基於與每個編碼深度有關的編碼單元的變換單元的尺寸信息,根據每個編碼單元中的每個變換單元執行逆變換,從而根據每個最大編碼單元執行頻率逆變換。
圖像數據解碼器230可通過使用根據深度的分割信息來確定當前最大編碼單元的編碼深度。如果分割信息指示圖像數據在當前深度下不再被分割,則當前深度是編碼深度。因此,圖像數據解碼器230可通過使用與當前深度相對應的每個編碼單元的、與預測單元的分區模式、預測類型和變換單元尺寸有關的信息,對當前最大編碼單元的圖像數據進行解碼。換句話說,可通過觀察為編碼單元、預測單元和最小單位之中的預定數據單元分配的編碼信息集來收集包括編碼信息(包括相同分割信息)的數據單元,且收集的數據單元可被視為將由圖像數據解碼器230以相同的編碼模式進行解碼的一個數據單元。
視頻解碼設備200可獲得與當對每個最大編碼單元遞歸地執行編碼時生成最小編碼誤差的至少一個編碼單元有關的信息,並且可使用該信息來對當前畫面進行解碼。也就是說,可對被確定為每個最大編碼單元中被確定為最佳編碼單元的具有樹結構的編碼單元進行解碼。
因此,即使圖像具有高解析度或具有過大的數據量,也可通過使用編碼單元的尺寸和編碼模式有效地對圖像進行解碼和恢復,其中通過使用從編碼器接收的最佳編碼模式信息根據圖像的特性適應性地確定所述編碼單元的尺寸和編碼模式。
現在將參照圖3至圖13描述根據本公開實施方式的確定具有樹結構的編碼單元、預測單元和變換單元的方法。
圖3示出分層編碼單元的概念。
編碼單元的尺寸可由寬×高來表示,可以是64×64、32×32、16×16和8×8。64×64的編碼單元可被分割為64×64、64×32、32×64或32×32的分區,32×32的編碼單元可被分割為32×32、32×16、16×32或16×16的分區,16×16的編碼單元可被分割為16×16、16×8、8×16或8×8的分區,8×8的編碼單元可被分割為8×8、8×4、4×8或4×4的分區。
在視頻數據310中,解析度為1920×1080,編碼單元的最大尺寸為64,最大深度為2。在視頻數據320中,解析度為1920×1080,編碼單元的最大尺寸為64,最大深度為3。在視頻數據330中,解析度為1920×1080,編碼單元的最大尺寸為16,最大深度為1。圖3中所示的最大深度表示從最大編碼單元到最小編碼單元的分割總數。
如果解析度高或數據量大,則編碼單元的最大尺寸可能較大,從而不僅提高了編碼效率,還精確地反映出圖像的特性。因此,解析度高於視頻數據330的視頻數據310和320的編碼單元的最大尺寸可選擇為64。
由於視頻數據310的最大深度為2,因此,由於通過將最大編碼單元分割兩次,深度加深到兩層,因此視頻數據310的編碼單元315可包括具有長軸尺寸為64的最大編碼單元,以及具有長軸尺寸為32和16的編碼單元。由於視頻數據330的最大深度為1,因此,由於通過將最大編碼單元分割一次,深度加深到一層,因此視頻數據330的編碼單元335可包括具有長軸尺寸為16的最大編碼單元,以及具有長軸尺寸為8的編碼單元。
由於視頻數據320的最大深度為3,因此,由於通過將最大的編碼單元分割三次,深度加深到3層,因此視頻數據320的編碼單元325可包括具有長軸尺寸為64的最大編碼單元和具有長軸尺寸為32、16和8的編碼單元,。隨著深度加深,可提高對於細節信息的表達能力。
圖4是根據本公開實施方式基於編碼單元的圖像編碼器的框圖。
根據實施方式的圖像編碼器400包括視頻編碼設備100的編碼單元確定器120的操作,以對圖像數據進行編碼。也就是說,幀內預測器410在幀內模式下對當前幀405中的編碼單元執行幀內預測,運動估計器420和運動補償器425在幀間模式下通過使用當前幀405和參考幀495,對編碼單元分別執行幀間估計和運動補償。
從幀內預測器410、運動估計器420和運動補償器425輸出的數據通過變換器430和量化器440被輸出作為量化的變換係數。量化的變換係數通過逆量化器460和逆變換器470恢復為空間域中的數據,並且,恢復的空間域中的數據在通過去塊濾波器480和環路濾波器490進行後處理之後被輸出為參考幀495。量化的變換係數可通過熵編碼器450被輸出為比特流455。
為了將視頻編碼器400應用於視頻編碼設備100中,視頻編碼器400的所有元件(即幀內預測器410、運動估計器420、運動補償器425、頻率變換器430、量化器440、熵編碼器450、逆量化器460、頻率逆變換器470、去塊濾波器480和環路濾波器490)必須在考慮每個最大編碼單元的最大深度時,基於具有樹結構的編碼單元中的每個編碼單元執行操作。
具體地,幀內預測器410、運動估計器420和運動補償器425在考慮了當前最大編碼單元的最大尺寸和最大深度的情況下,確定具有樹結構的編碼單元之中每個編碼單元的分區和預測模式,並且頻率變換器430確定具有樹結構的編碼單元之中每個編碼單元中的變換單元的尺寸。
圖5是根據本公開實施方式基於編碼單元的圖像解碼器的框圖。
解析器510從比特流505中解析出作為解碼目標的編碼圖像數據和解碼所需的與編碼有關的信息。編碼圖像數據通過熵解碼器520和逆量化器530輸出為逆量化的數據,逆量化的數據通過頻率逆變換器540被恢復為空間區域中的圖像數據。
幀內預測器550針對空間域中的圖像數據在幀內模式下對編碼單元執行幀內預測,運動補償器560通過使用參考幀585在幀間模式下對編碼單元進行運動補償。
通過幀內預測器550和運動補償器560的空間域中的圖像數據可在通過去塊濾波器570和環路濾波器580進行後處理之後輸出為恢復幀595。此外,通過去塊濾波器570和環路濾波器580進行後處理的圖像數據可輸出為參考幀585。
為了視頻解碼設備200的圖像數據解碼器230對圖像數據進行解碼,根據實施方式的圖像解碼器500可執行在解析器510之後執行的操作。
為了將視頻解碼器500應用於視頻解碼設備200中,視頻解碼器500的所有元件(即解析器510、熵解碼器520、逆量化器530、頻率逆變換器540、幀內預測器550、運動補償器560、去塊濾波器570和環路濾波器580)針對每個最大編碼單元基於具有樹結構的編碼單元執行操作。
具體地,幀內預測器550和運動補償器560確定對於具有樹結構的每個編碼單元的分區和預測模式,並且頻率逆變換器540必須確定對於每個編碼單元的變換單元的尺寸。
圖6是示出根據本公開實施方式基於深度的較深層編碼單元和分區的圖。
根據實施方式的視頻編碼設備100和根據實施方式的視頻解碼設備200使用分層編碼單元以考慮圖像的特徵。可根據圖像的特性自適應地確定編碼單元的最大高度、最大寬度和最大深度,或者可以根據用戶要求進行各種設置。可根據編碼單元的預定最大尺寸確定根據深度的較深層編碼單元的尺寸。
在根據實施方式的編碼單元的層次結構600中,編碼單元的最大高度和最大寬度均為64,最大深度為4。由於深度沿著編碼單元的層次結構600的縱軸加深,因此較深層編碼單元的高度和寬度均被分割。另外,沿著層次結構600的橫軸示出作為每個較深層編碼單元的預測編碼的基礎的預測單元和分區。
換句話說,編碼單元610是層次結構600中的最大編碼單元,其中深度為0,尺寸(即寬度乘高度)為64×64。深度沿縱軸加深,從而存在具有尺寸32×32且深度1的編碼單元620、尺寸16×16且深度2的編碼單元630、尺寸8×8且深度3的編碼單元640,以及具有尺寸4×4且深度4的編碼單元650。具有尺寸4×4且深度4的編碼單元650是最小編碼單元。
編碼單元的預測單元和分區根據每個深度沿橫軸布置。換句話說,如果具有尺寸64×64和深度0的編碼單元610是預測單元,則預測單元可被分割成包括在具有尺寸64×64的編碼單元610中的分區,即具有尺寸64×64的分區610、具有尺寸64×32的分區612、具有尺寸32×64的分區614或具有尺寸32×32的分區616。
同樣,具有尺寸32×32且深度1的編碼單元620的預測單元可分割成包括在具有尺寸32×32的編碼單元620中的分區,即具有尺寸32×32的分區620、具有尺寸32×16的分區622、具有尺寸16×32的分區624和具有尺寸16×16的分區626。
同樣,具有尺寸16×16且深度2的編碼單元630的預測單元可分割成包括在具有尺寸為16×16的編碼單元630中的分區,即具有尺寸16×16的分區630、具有尺寸16×8的分區632、具有尺寸8×16的分區634和具有尺寸8×8的分區636。
同樣地,具有尺寸8×8且深度3的編碼單元640的預測單元可分割成包括在具有尺寸為8×8的編碼單元640中的分區,即具有尺寸8×8的分區640、具有尺寸8×4的分區642、具有尺寸4×8的分區644以及具有尺寸4×4的分區646。
具有尺寸4×4且深度4的編碼單元650是最小編碼單元和最下層深度的編碼單元。編碼單元650的預測單元僅分配給具有尺寸4×4的分區。
為了確定最大編碼單元610的編碼深度,視頻編碼設備100的編碼單元確定器120必須對包括在最大編碼單元610中的、分別對應於各深度的編碼單元執行編碼。
隨著深度加深,包括處於相同範圍和相同尺寸的數據的、根據深度的較深層編碼單元的數量增加。例如,需要四個與深度2對應的編碼單元以覆蓋包括在與深度1對應的一個編碼單元中的數據。因此,為了比較相同數據根據深度的編碼結果,對與深度1對應的編碼單元和四個與深度2對應的編碼單元各自進行編碼。
為了根據每個深度執行編碼,可通過沿編碼單元的層次結構600的橫軸,對根據深度的編碼單元的預測單元中每個執行編碼,來選擇作為相應深度的代表性編碼誤差的最小編碼誤差。可替代地,可通過隨著深度沿層次結構600的縱軸加深對每個深度執行編碼來比較根據深度的最小編碼誤差,從而搜索最小編碼誤差。在最大編碼單元610中具有最小編碼誤差的深度和分區可被選為最大編碼單元610的編碼深度和分區類型。
圖7是根據本公開實施方式用於描述編碼單元與變換單元之間的關係的圖。
根據實施方式的視頻編碼設備100或根據實施方式的視頻解碼設備200針對每個最大編碼單元、根據具有小於或等於最大編碼單元的尺寸的編碼單元來對圖像進行編碼或解碼。可基於不大於相應編碼單元的數據單元來選擇編碼期間用於頻率變換的變換單元的尺寸。
例如,在視頻編碼設備100或視頻解碼設備200中,當編碼單元710的尺寸為64×64時,可通過使用具有尺寸32×32的變換單元720來執行頻率變換。
此外,可通過對小於64×64的尺寸為32×32、16×16、8×8和4×4的變換單元中的每一個執行頻率變換來對具有尺寸64×64的編碼單元710的數據進行編碼,然後可選擇相對於原始圖像具有最小編碼誤差的變換單元。
圖8示出根據本公開實施方式的多條編碼信息。
視頻編碼設備100的輸出單元130可對與編碼深度對應的每個編碼單元的分區類型信息800、預測模式信息810和變換單元尺寸信息820進行編碼,並作為編碼模式信息發送這些信息。
分區類型信息800指示與通過對當前編碼單元的預測單元進行分割而獲得的分區的形狀有關的信息,其中所述分區是用於對當前編碼單元進行預測編碼的數據單元。例如,具有尺寸2n×2n的當前編碼單元cu_0可被分割成具有尺寸2n×2n的分區802、具有尺寸2n×n的分區804、具有尺寸n×2n的分區806和具有尺寸n×n的分區808中的任意一個。在這種情況下,關於當前編碼單元的分區類型信息800被設置為指示具有尺寸2n×2n的分區802、具有尺寸2n×n的分區804、具有尺寸n×2n的分區806和具有尺寸n×n的分區808中的一個。
預測模式信息810指示每個分區的預測模式。例如,預測模式信息810可指示對由分區模式信息800指示的分區執行的預測編碼的模式,即幀內模式812、幀間模式814或跳過模式816。
變換單元尺寸信息820代表當對當前編碼單元執行頻率變換時所基於的變換單元。例如,變換單元可以是第一幀內變換單元822、第二幀內變換單元824、第一幀間變換單元826或第二幀間變換單元828。
視頻解碼設備200的圖像數據和編碼信息提取器220可針對每個較深編碼單元提取和使用分區類型信息800、預測模式信息810和變換單元尺寸信息820。
圖9是根據本公開實施方式基於深度的較深層編碼單元的圖。
分割信息可用於指示深度的改變。分割信息指示當前深度的編碼單元是否被分割為更下層深度的編碼單元。
用於對具有深度0和尺寸2n_0×2n_0的編碼單元900進行預測編碼的預測單元910可包括以下分區類型的分區:具有尺寸2n_0×2n_0的分區類型912、具有尺寸2n_0×n_0的分區類型914、具有尺寸n_0×2n_0的分區類型916和具有尺寸n_0×n_0的分區類型918。僅示出通過對預測單元對稱地分割而獲得的分區912、914、916和918,但是如上所述,分區類型不限於此,並且可包括不對稱分區、具有預定形狀的分區和具有幾何形狀的分區。
根據每個分區類型,對一個具有尺寸2n_0×2n_0的分區,兩個具有尺寸2n_0×n_0的分區,兩個具有尺寸為n_0×2n_0的分區和四個具有尺寸n_0×n_0的分區重複執行預測編碼。可對具有尺寸2n_0×2n_0、n_0×2n_0、2n_0×n_0和n_0×n_0的分區執行幀內模式和幀間模式下的預測編碼。可以僅對具有尺寸2n_0×2n_0的分區執行跳過模式下的預測編碼。
如果在具有尺寸2n_0×2n_0、2n_0×n_0和n_0×2n_0的912、914和916的分區類型之一中編碼誤差最小,則可不將預測單元910分割至更下層的深度。
如果在具有尺寸n_0×n_0的分區類型918中編碼誤差最小,則將深度從0改變為1並執行分割(操作920),並且可對具有深度2且尺寸n_0×n_0的分區類型的編碼單元930重複執行編碼,以搜索最小編碼誤差。
用於對具有深度1和尺寸2n_1×2n_1(=n_0×n_0)的編碼單元930執行預測編碼的預測單元940可包括以下分區類型的分區:尺寸2n_1×2n_1的分區類型942,尺寸2n_1×n_1的分區類型944,尺寸n_1×2n_1的分區類型946和尺寸n_1×n_1的分區類型948。
如果在具有尺寸n_1×n_1的分區類型948中編碼誤差最小,則將深度從1改變為2並執行分割(在操作950中),並且對具有深度2和尺寸n_2×n_2的編碼單元960重複執行編碼,以搜索最小編碼誤差。
當最大深度為d時,可設置根據深度的分割信息,知道深度對應於d-1,並且可設置分割信息,直到深度對應於d-2。也就是說,當對與d-2的深度對應的編碼單元被分割之後執行到深度為d-1時的編碼(在操作970中)時,用於對具有深度d-1和尺寸2n_(d-1)×2n(d-1)的編碼單元980進行預測編碼的預測單元990可包括以下分區類型的分區:尺寸2n_(d-1)×2n(d-1)的分區類型992、尺寸2n_(d-1)×n_(d-1)的分區類型994,尺寸n_(d-1)×2n(d-1)的分區類型996,以及尺寸n_(d-1)×n_(d-1)的分區類型998。
可對分區類型之中的一個具有尺寸2n_(d-1)×2n(d-1)的一個分區、兩個具有尺寸2n_(d-1)×n_(d-1)的分區、兩個具有尺寸n_(d-1)×2n(d-1)的分區、四個具有尺寸n_(d-1)×n_(d-1)的分區重複執行預測編碼,以搜索生成最小編碼誤差的分區類型。
即使當具有尺寸n_(d-1)×n_(d-1)的分區類型998有最小編碼誤差時,但由於最大深度為d,因此具有深度d-1的編碼單元cu_(d-1)不再被分割到更下層深度,並且構成當前最大編碼單元900的編碼單元的編碼深度被確定為d-1,可將當前最大編碼單元900的分區類型確定為n_(d-1)×n_(d-1)。此外,由於最大深度為d,因此不設置對具有深度d-1的編碼單元952的分割信息。
數據單元999可以是當前最大編碼單元的「最小單元」。根據實施方式的最小單元可以是通過將具有最下層編碼深度的最小編碼單元分割4次而獲得的矩形數據單元。通過重複執行編碼,根據實施方式的視頻編碼設備100可通過比較根據編碼單元900的深度的編碼誤差選擇具有最小編碼誤差的編碼深度來確定深度,並且將相應的分區類型和預測模式設置為編碼深度的編碼模式。
這樣,在0,1,...,d-1,d的所有深度中比較根據深度的最小編碼誤差,且可將具有最小編碼誤差的深度確定為編碼深度。編碼深度、預測單元的分區類型和預測模式可作為關於編碼模式的信息被編碼和發送。由於編碼單元從深度0分割到編碼深度,所以僅編碼深度的分割信息設定為「0」,而排除編碼深度之外的深度的分割信息設定為「1」。
根據實施方式的視頻解碼設備200的圖像數據和編碼信息提取器220可提取並使用關於編碼單元900的編碼深度和預測單元信息,以對編碼單元912進行解碼。視頻解碼設備200可通過使用根據深度的分割信息確定分割信息為0的深度為編碼深度,並且使用關於相應深度的編碼模式的信息進行解碼。
圖10、圖11和圖12是根據本公開實施方式描述編碼單元、預測單元和頻率變換單元之間關係的圖。
編碼單元1010是最大編碼單元之中、由視頻編碼設備100確定的根據編碼深度的較深層編碼單元。預測單元1060是根據編碼深度的編碼單元1010中每一個的預測單元的分區,變換單元1070是根據編碼深度的編碼單元中每一個的變換單元。
當編碼單元1010中的最大編碼單元的深度為0時,編碼單元1012和1054的深度為1,編碼單元1014、1016、1018、1028、1050和1052的深度為2,編碼單元1020、1022、1024、1026、1030、1032和1048的深度為3,編碼單元1040、1042、1044和1046的深度為4。
在預測單元1060中,通過對編碼單元1010中的編碼單元進行分割來獲得一些編碼單元1014、1016、1022、1032、1048、1050、1052和1054。也就是說,分區1014、1022、1050和1054是具有尺寸2n×n的分區類型,分區1016、1048和1052是具有尺寸n×2n的分區類型,並且分區1032是具有尺寸n×n的分區類型。編碼單元1010的預測單元和分區小於或等於每個編碼單元。
在變換單元1070中,以小於編碼單元1052的數據單位對編碼單元1052的圖像數據執行頻率變換或頻率逆變換。此外,變換單元1760中的編碼單元1014、1016、1022、1032、1048、1050、1052和1054在尺寸和形狀方面與預測單元1060中的編碼單元1014、1016、1022、1032、1048、1050、1052和1054不同。也就是說,根據實施方式的視頻編碼設備100和視頻解碼設備200可對相同編碼單元中的各個數據單元執行幀內預測/運動估計/運動補償/以及頻率變換/逆變換。
因此,對最大編碼單元的每個區域中具有層次結構的編碼單元中的每一個遞歸地執行編碼,以確定最佳編碼單元,從而可獲得具有遞歸樹結構的編碼單元。編碼信息可包括關於編碼單元的分割信息、分割類型信息、預測模式信息和變換單元尺寸信息。下表1示出可由根據實施方式的視頻編碼設備100和視頻解碼設備200設置的編碼信息。
表1
根據實施方式的視頻編碼設備100的輸出單元130可輸出與具有樹結構的編碼單元有關的編碼信息,根據實施方式的視頻解碼設備200的圖像數據和編碼信息提取器220可從接收的比特流中提取與具有樹結構的編碼單元有關的編碼信息。
分割信息指示當前編碼單元是否被分割成更下層深度的編碼單元。如果當前深度d的分割信息為0,則當前編碼單元不再被分割為更下層深度的深度是編碼深度,因此可針對編碼深度定義分區類型信息、預測模式信息和變換單元尺寸信息。如果當前編碼單元根據分割信息被進一步分割,則編碼必須對更下層深度的四個分割編碼單元獨立執行編碼。
預測模式可以是幀內模式、幀間模式和跳過模式中的至少一個。可以在所有分區類型中定義幀內模式和幀間模式,並且僅在具有尺寸2n×2n的分區類型中定義跳過模式。
分區類型信息可指示通過對預測單元的高度或寬度進行對稱分割而獲得的具有尺寸2n×2n、2n×n、n×2n和n×n的對稱分區類型,以及通過對預測單元的高度或寬度進行不對稱分割而獲得的具有尺寸2n×nu、2n×nd、nl×2n和nr×2n的不對稱分區類型。可通過按照1:3和3:1對預測單元的高進行分割而分別獲得具有尺寸2n×nu和2n×nd的不對稱分區類型,並且可通過按照1:3和3:1對預測單元的寬進行分割而分別獲得具有尺寸nl×2n和nr×2n的不對稱分區類型。
變換單元的尺寸可設置成幀內模式下的兩種類型和幀間模式下的兩種類型。也就是說,如果變換單元的分割信息為0,則變換單元的尺寸可以為2n×2n,這是當前編碼單元的尺寸。如果變換單元的分割信息為1,則可通過對當前編碼單元進行分割來獲得變換單元。此外,如果具有尺寸2n×2n的當前編碼單元的分區類型是對稱分區類型,則變換單元的尺寸可以是n×n,且如果當前編碼單元的分區類型是不對稱分區類型,則變換單元的尺寸可以是n/2×n/2。
根據實施方式與具有樹結構的編碼單元有關的編碼信息可分配給與編碼深度、預測單元和最小單元相對應的編碼單元中的至少一個。對應於編碼深度的編碼單元可包括具有相同編碼信息的預測單元和最小單元中的至少一個。
因此,通過比較鄰近數據單元的多條編碼信息,來確定鄰近數據單元是否包括在對應於相同編碼深度的編碼單元中。此外,通過使用數據單元的編碼信息來確定與編碼深度相對應的相應編碼單元,從而可推斷最大編碼單元中的編碼深度的分布。
因此,如果基於鄰近數據單元的編碼信息來預測當前編碼單元,則可直接進行參考和使用與當前編碼單元鄰近的較深層編碼單元中的數據單元的編碼信息。
在另一實施方式中,如果基於鄰近數據單元的編碼信息來預測當前編碼單元,則可通過使用數據單元的編碼信息來搜索與當前編碼單元鄰近的數據單元,並且可參考所搜索到的鄰近編碼單元來預測當前編碼單元。
圖13根據表格1的編碼模式信息示出編碼單元、預測單元和變換單元之間的關係。
最大編碼單元1300包括多個編碼深度的編碼單元1302、1304、1306、1312、1314、1316和1318。這裡,由於編碼單元1318是編碼深度的編碼單元,因此分割信息可設置成0。具有尺寸2n×2n的編碼單元1318的分區類型信息可設置成包括2n×2n1322、2n×n1324、n×2n1326、n×n1328、2n×nu1332、2n×nd1334、nl×2n1336和nr×2n1338的分區類型之一。
當分區類型信息被設置成對稱分區類型2n×2n1322、2n×n1324、n×2n1326和n×n1328中的一個時,如果變換單元分割信息(tu尺寸標誌(tusizeflag))為0,則可以設置具有尺寸2n×2n的變換單元1342,如果變換單元分割信息為1,則可以設置具有尺寸n×n的變換單元1344。
當分區類型信息被設置成不對稱分區類型2n×nu1332、2n×nd1334、nl×2n1336和nr×2n1338中的一個時,如果變換單元分割信息(tu尺寸標誌)為0,則可以設置具有尺寸2n×2n的變換單元1352,並且如果變換單元分割信息為1,則可以設置具有尺寸n/2×n/2的變換單元1354。
在下文中,將對由根據圖4的實施方式的圖像編碼設備400的熵編碼器450和圖5的圖像解碼設備500的熵解碼器520所執行的熵編碼和解碼過程進行詳細描述。
如上所述,根據本公開實施方式的圖像編碼設備400通過使用從最大編碼單元分層分割的編碼單元來執行編碼。熵編碼器450對編碼過程期間生成的多條編碼信息進行編碼,例如,諸如量化的變換係數、預測單元的預測模式、量化參數、運動矢量等語法元素。作為熵編碼技術,可使用基於上下文的二進位算術編碼(在下文中稱為「cabac」)。
表2是在高效率視頻編碼(hevc)和h.264/avc下通過cabac進行熵編碼的語法元素的示例。以hevc和h.264/avc對語法元素中每一個的語義進行描述,因此將省略其詳細描述。
表2
圖14是根據本公開實施方式的熵編碼設備的框圖。
參照圖14,熵編碼設備1400包括二值化器1410、上下文建模器1420和二進位算術編碼器1430。此外,二進位算術編碼器1430包括常規編碼引擎1432和旁路編碼引擎1434。
二值化器1410將輸入的語法元素映射到二進位符號的二進位位。一個二進位位表示一個具有值0或1的位並通過執行cabac進行編碼。一組二進位位可稱為二進位位字符串。二值化器1410可根據語法元素的類型應用固定長度二值化、截斷萊斯二值化、第k次指數哥倫布(exp-golomb)二值化和哥倫布-萊斯(golomb-rice)二值化之一,並且將語法元素的值映射和輸出為0和1的二進位位。
常規編碼引擎1432或旁路編碼引擎1434對二值化器1410輸出的二進位位進行算術編碼。當自語法元素二進位化的二進位位均勻分布時,即當數據具有相同頻率的0和1時,通過將二進位化的二進位位輸出到不使用概率值的旁路編碼引擎1434,來對二進位化的二進位位進行編碼。可根據語法元素的類型預先確定是否通過使用常規編碼引擎1432和旁路編碼引擎1434之中的編碼引擎來對當前二進位位進行算術編碼。
常規編碼引擎1432可基於由上下文建模器1420確定的概率模型對二進位位執行算術編碼。上下文建模器1420向常規編碼引擎1432提供關於二進位位的概率模型。具體地,上下文建模器1420基於先前編碼的二進位位確定預先確定的二進位值的概率,更新用於對先前二進位位的二進位值編碼的概率,以及向常規編碼引擎1432輸出更新的概率。傳統地,通過使用上下文索引ctxldx確定一個上下文模型,並且確定所確定的上下文模型的最小可能符號(lps)或最大可能符號(mps)的發生概率以及關於0和1之間的哪個二進位值對應於mps的信息。另一方面,根據本公開實施方式的上下文建模器1420確定先前確定的二進位值(例如在不區分mps和lps的情況下,基於先前編碼的二進位位指示「1」的發生概率的p(1)),並向常規編碼引擎1432提供已確定的預定二進位值的概率。
根據本公開實施方式的上下文建模器1420可通過使用所接收的二進位位的值來獲得每個二進位位的自相關值,基於自相關值確定用於更新二進位值的概率的至少一個縮放因子值,以及通過使用所確定的至少一個縮放因子來更新二進位值的概率。
此外,根據本公開另一實施方式的上下文建模器1420可通過應用具有不同縮放因子的多個概率模型來獲得指示二進位位的平均位值的熵值,確定用以獲得多個概率模型中的最小熵值的概率模型的縮放因子,並且通過使用所確定的縮放因子來更新二進位值的概率。
常規編碼引擎1432基於上下文建模器1420提供的預定二進位值的概率和當前二進位位的二進位值來執行二進位算術編碼。換句話說,常規編碼引擎1432可基於上下文建模器1420提供的預定二進位值的概率來確定「1」的發生概率p(1)和「0」的發生概率p(0),根據當前二進位值分割所確定的0和1的發生概率p(0)和p(1)和指示概率區間的範圍,並輸出代表值屬於分割範圍的二進位值,從而執行二進位算術編碼。
圖15a和圖15b示出在cabac中使用的概率更新過程。
參照圖15a,將在hevc中使用的上下文模型等定義為64個先前確定的概率狀態。每個概率狀態可表徵為狀態索引iplps和mps的值vmps。當通過使用先前確定的狀態轉換表對概率進行更新時,可以呈現要從當前概率狀態轉移的概率狀態。可根據當前算術編碼二進位位的值是否為mps或lps來改變概率狀態進行。例如,如果當前二進位位的值是mps,則概率狀態從當前概率狀態iplps改變為其中lps概率降低的前向狀態iplps+1,並且如果當前二進位位的值為lps,將概率狀態從當前概率狀態iplps改變為lps概率增加的後向狀態iplps-1。在圖15a中,trmps{}指示mps處理後的概率狀態轉移方向,而trlps{}指示lps處理後的概率狀態轉移方向。
在mps或lps處理期間改變的概率具有如圖15a中所示的指數下降的形式。n個上下文模型的概率pn可表示為以下等式:pn=0.5(1-α)n,其中(1-α)=(0.01875/0.5)1/63。
參照圖15b,lps的接近0的概率分布是緻密的,並且lps的接近1/2的概率分布是稀疏的。因此,當二進位值0和1的發生概率相似時,即當二進位值0和1的發生概率接近1/2時,由於概率稀疏分布,概率預測誤差可能增加。此外,當使用取冪形式的概率函數時,由於接近0的概率值需要進行詳細地表達,因此可能增加呈現概率值的比特深度。因此,可能增加用於存儲具有取冪形式的概率函數的概率模型的查找表大小。此外,當使用密集概率值來更新概率或分割概率區間時,乘法運算量增加,這在硬體上可能是繁重的。因此,通過將圖15a中所示的概率plps映射到經過捨入算術運算的預定值,可以使用其中的概率值不是指數級而是分層級縮小的概率。
將在下文詳細描述由上下文建模器1420執行的更新概率模型的過程。
可以根據下面的等式1來執行cabac中使用的概率更新過程。
[等式1]
pi(t)=αiy+(1-αi)pi(t-1)
在上面的等式1中,pi(t)表示更新的概率,pi(t-1)表示前一個二進位位的概率,αi(0≤αi≤1,αi是實數)表示縮放因子,而y表示輸入的當前二進位位的值。i是指示縮放因子的編號的整數。隨著使用的縮放因子的數量增加,預測概率的精度可以增加,然而算術複雜度也會增加。因此,下面將描述i為1或2的情況,即通過使用一個縮放因子或兩個縮放因子來更新概率。然而,根據本公開的概率更新方法也可應用於通過使用兩個或更多縮放因子來概率更新的情況。
在二進位算術編碼器中,可處理具有值0和1的任意序列的二進位位。如果將0和1中任一個的二進位位的概率確定為a(0≤a≤1,a是實數),則可將另一二進位位的概率確定為(1-a)。在上面的等式1中,當二進位位的輸入值為1時,即當y=1時,由於pi(t)的值增加,所以等式1中的pi(t)指示「1」的概率,即下一個二進位位是「1」的概率。可考慮概率值的範圍,以確定0和1中的哪一個是mps或lps。例如,如果指示1的概率的pi(t)具有[1/2;1],即(1/2)和1之間的值,則mps為1,如果pi(t)具有[0;1/2],即0和(1/2)之間的值,則0對應於mps。可將cabac中使用的lps的可能值確定為pi(t)和(1-pi(t))之間的小值。
基於等式1更新概率的重要參數是縮放因子αi。根據縮放因子αi的值,可確定指示cabac中使用的概率被多麼敏感地更新的敏感度和關於cabac中使用的概率是否有誤差地反應的魯棒性。
根據本公開實施方式的上下文建模器1420可通過使用一個或多個縮放因子αi來生成一個或多個更新的概率,並且可最終將一個或多個更新的概率的加權平均值確定為更新的概率。
具體地,如果通過將多個縮放因子αi應用於等式1來獲得多個概率pi(t),則上下文建模器1420通過根據以下等式2計算多個概率pi(t)的加權平均值來獲得最終的更新概率p(t)。
[等式2]
ωi表示應用到多個概率pi(t)的權重。可考慮縮放因子的數量確定ωi。如果所使用的縮放因子的數量是n(n是整數),則ωi=(1/n)。例如,當使用兩個縮放因子α1和α2時,基於以上等式1得到p1(t)=α1y+(1-α1)p1(t-1)和p2(t)=α2y+(1-α2)p2(t-1)。在這種情況下,將作為兩個概率p1(t)和p2(t)的平均值的(p1(t)+p2(t))/2確定為更新概率p(t)。
另一方面,為了在更新概率上省略乘法處理,縮放因子可具有像1/2p這樣的分母為2的冪的值。也就是說,多個縮放因子αi可具有像下面的等式αi=1/(2^mi)(mi是整數)的值。在這種情況下,可用包括在上述等式1中的乘法算術運算來代替如下述等式3所示的移位算術運算。在等式3中,「>>」是寫入移位算術運算符。
[等式3]
pi(t)=(y>>mi)+pi(t-1)-(pi(t-1)>>mi)
在描述的示例中,當設定α1=1/16=1/24且α2=1/128=1/27時,可以通過像p1(t)=(y>>4)+p1(t-1)-(p1(t-1)>>4)的僅包括移位算術運算和加法和減法算術運算的等式獲得p1(t)=α1y+(1-α1)p1(t-1)。同樣,p2(t)=α2y+(1-α2)p2(t-1)可被替換為p2(t)=(y>>7)+p2(t-1)-(p2(t-1)>>7)。在硬體或軟體中移位算術運算比乘法或除法運算操作可更容易實現,因此縮放因子可確定為2的冪的預定值作為分母。
圖16是根據本公開實施方式的概率更新過程的流程圖。
參照圖16,在操作1610中,上下文建模器1420通過應用多個縮放因子來獲得多個更新的概率。如以上示例中所述,當使用兩個縮放因子α1=1/16=1/24和α2=1/128=1/27時,上下文建模器1420通過p1(t)=(y>>4)+p1(t-1)-(p1(t-1)>>4)和p2(t)=(y>>7)+p2(t-1)-(p2(t-1)>>7)獲得兩個更新概率p1(t)和p2(t),並確定p1(t)和p2(t)的平均值的(p1(t)+p2(t))/2為最終更新概率p(t)。可通過像(p1(t)+p2(t))>>1的移位算術運算來實現(p1(t)+p2(t))/2。
在cabac編碼和解碼過程中,在預定數據單元中執行熵復位。例如,可以在切片單元和編碼單元中執行熵復位。熵復位意思是捨棄當前概率值並基於預定概率值來重新執行cabac。在這樣的復位處理之後執行的概率更新過程中,設置為初始值的概率值不是最優值,而是通過多次更新處理收斂至某個概率值。當通過使用一個縮放因子更新概率時,概率更新使得概率中的快速變化並因此更新的概率快速的收斂至適當的值,而重複更新容易產生波動。當通過使用多個縮放因子更新概率時,雖然概率變化不快,但是當更新的概率收斂到適當值附近時,由于波動發生得較不頻繁,所以更新的概率不會敏感地對錯誤或噪音起反應並穩定地操作。因此,在操作1620中,上下文建模器1420每次概率更新增加一個計數器,並且在操作1630中,基於計數器值確定當前更新的概率是否與初始二進位位相關。考慮到初始二進位位小於預定數字,例如,50或更少的初始二進位位,在操作1640中,可通過使用單個縮放因子來執行概率更新。考慮到在初始二進位位之後輸入二進位位,例如第50個二進位位,在操作1650中,可執行通過使用兩個縮放因子而確定的概率更新過程。
在上述概率更新過程期間,通過使用具有預定值的縮放因子,例如將2的冪的值作為分母,來執行概率更新。
根據本公開實施方式的上下文建模器1420通過使用接收到的二進位位的值來獲得每個二進位位的自相關值,基於自相關值確定用於更新二進位值的概率的至少一個縮放因子,然後通過使用所確定的至少一個縮放因子來更新二進位值的概率。
圖17a和17b是用於說明自相關值的參考圖。
使用間隔預定距離k(k是整數)的二進位位的值、二進位位的平均值m和二進位位的方差σ來根據預定距離k來獲得自相關值rk,如下面等式4中所示。
[等式4]
在上面的等式4中,二進位位的數量是(n+1)(n是整數)且(n+1)個二進位位的值是yj(j是從0到n的整數)。
參考圖17a和圖17b,{y0,y1,y2,...,y7}指示8個二進位位,且yi值為0或1。如果假設二進位位的值如圖17a和17b所示分布,則二進位位的平均值m具有圖17a和17b中值的1/2。
方差σ是在每個二進位位的值yi和平均值m之間的均方誤差的平均值,並且具有圖17a和圖17b中值的(1/2)^2*8*(1/8)=1/4。
當預定距離k為1時,即如果通過使用鄰近二進位位的值來計算自相關值,則當鄰近二進位位的值類似圖17a中所示分布時的自相關值大於當鄰近二進位位的值類似圖17b中所示不均勻分布時的自相關值。
圖18是根據本公開實施方式用於二進位算術編碼的概率更新方法的流程圖。
如上所述,根據本公開實施方式的概率更新方法通過使用輸入的二進位位來計算自相關值,並使用基於自相關值確定的每個二進位位的概率與每個二進位位的值之間的均方誤差最小的值作為縮放因子。
在操作1810中,上下文建模器1420通過cabac接收將要進行二進位算術編碼的預定數量的二進位位。在操作1820中,上下文建模器1420基於上面的等式3獲得每個二進位位的自相關值。
在操作1830中,上下文建模器1420基於自相關值rk確定用於更新二進位值的概率的至少一個縮放因子。
具體地,假定{yi}表示具有值0和1之一的n個二進位位。也就是說,j具有從0到(n-1)的值。
根據上面的等式1,使用先前二進位位的概率、先前二進位位的值和縮放因子α來表示在第j個二進位位的算術編碼之後更新的概率pj,如下面的等式5所示。
[等式5]
pj=α*yj+(1-α)*pj-1=α*yj+(1-α)*(α*yj-1+(1-α)*pj-2)
=α*yj+(1-α)*(α*yj-1+(1-α)*(α*yj-2+(1-α)*pj-3)))
=α*yj+(1-α)*(α*yj-1+(1-α)*(α*yj-2+(1-α)*(α*yj+(1-α)*(α*yj-1+(1-α)*(α*yj-3+(1-α)*pj-4))))))
=........
等式5概括為下面等式6中所示。
[等式6]
每個二進位位的概率和值之間的均方誤差(「mse」)如下面的等式中7所示。
[等式7]
如等式7中所示,mse具有相對於縮放因子α變化的值。為了確定縮放因子α,確定產生mse的值α。為此,等式7的mse相對於α進行偏微分,並且確定產生mse具有0的值。
也就是說,確定產生為0的縮放因子α。如果計算偏微分方程的值,則如下面等式8中所示,可通過使用自相關值rk來確定縮放因子α。
[等式8]
如上所述,使用兩個縮放因子α1和α2來獲得p1,j=α1y+(1-α1)p1,j-1和p2,j=α2y+(1-α2)p2,(j-1),並且當兩個概率p1,j和p2,j的平均值(p1,j+p2,j)/2確定為更新概率pj時,如下面的等式9中所示,通過代入(p1,j+p2,j)/2代替等式7的pj來計算每個二進位位的概率與值之間的mse。
[等式9]
在等式9中,βi=1-αi。也就是說,β1=1-α1,並且β2=1-α2。
通過將等式9相對於α1和α2進行偏微分根據自相關值的範圍來獲得最小值,如下所示。
當rk∈[-1,1/7],α1=0,α2=0;
當rk∈[1/7,1/2]時,α2=0;
當rk∈[1/2,5/7]時,α1=1,α2=0;
當rk∈[5/7,1]時,α1=1,
如上所述,如果通過使用二進位位的自相關值確定了一個或多個縮放因子,則在操作1840中,上下文建模器1420通過使用所確定的縮放因子來更新先前的概率值,並將更新的概率值提供給常規編碼引擎1432。在操作1850中,常規編碼引擎1432通過使用更新的概率值對下一個二進位位執行二進位算術編碼。
圖19是根據本公開的另一實施方式在cabac中使用概率更新方法的流程圖。
根據本公開的另一實施方式的上下文建模器1420可獲得指示通過應用具有不同縮放因子的多個概率模型對一個二進位位進行編碼所需的平均位值的熵值,確定具有用以獲得最小熵值的概率模型的縮放因子,並且通過使用確定的縮放因子來執行概率更新。
參考圖19,在操作1910中,上下文建模器1420接收要進行二進位算術編碼的預定數量的二進位位。
在操作1920中,上下文建模器1420通過將具有不同縮放因子的多個概率模型應用於所接收的二進位位中的一個來獲得熵值。
定義m概率模型是pmi(i是從0到(m-1)的整數),並且概率模型pmi的縮放因子是αi。上下文建模器1420通過使用概率模型pmi的縮放因子αi來對當前二進位位執行概率更新。如上面的等式1中所示,上下文建模器1420根據pi(t)=αiyi+(1-αi)pi(t-1)執行概率更新。
上下文建模器1420通過在位單元中應用多個概率模型來計算熵。具體地,如下面的等式10中所示,上下文建模器1420根據當前二進位位y的值獲得參數biti。
[等式10]
biti=(y==1)?-log2pi(t):-log2(1-pi(t))
參照等式10,在當前二進位位y的值為1時,參數biti具有值log2pi(t);在當前二進位位的y的值為0時,參數biti具有值-log2(1-pi(t))。
如下面的等式11中所示,通過使用參數biti來獲得當前二進位位的熵si(t)。
[等式11]
si(t)=biti*αi+(1-αi)*si(t-1)
在等式11中,si(t-1)是相對於當前二進位位的先前二進位位而獲得的熵值。基於等式11,如果獲得相對於當前二進位位的多個熵值,則上下文建模器1420將熵si(t)中最小熵值中使用的縮放因子αi確定為最終縮放因子。
例如,對於當前二進位位y,假設通過應用縮放因子α1獲得的熵值是s1(t),並且通過應用縮放因子α2獲得的熵值是s2(t)。在s1(t)s2(t)的情況下,將用於獲得具有較小熵值的s2(t)的縮放因子α2確定為概率更新的縮放因子,並且根據p2(t)=α2y+(1-α2)p2(t-1)更新概率。
圖20a和圖20b示出基於cabac執行二進位算術編碼的過程。
參照圖20a,上下文建模器1420向常規編碼引擎1432提供預定二進位值,例如「1」的發生概率p(1)。常規編碼引擎1432考慮輸入的二進位位是否為1來分割概率區間並執行二進位算術編碼。在圖20a中,假設「1」的發生概率為p(1)=0.8,並且「0」的發生概率為p(0)=0.2。雖然為了描述的緣故所述的p(1)和p(0)是不變的,但是如上所述,每當對一個二進位位編碼時,可以更新p(1)和p(0)的值。常規編碼引擎1432由於先前輸入的二進位位s1具有值1而在(0,1)區間中選擇值「1」的概率區間(0,0.8),由於隨後輸入的二進位位s2具有值0而選擇與(0,0.8)區間的上側的0.2相對應的概率區間(0.64,0.8),並且由於最終輸入的二進位位s3具有值1而最後確定接近(0.64,0.8)的0.8的區間(0.64,0.7768)。常規編碼引擎1432選擇0.75作為指示(0.64,0.788)區間的代表值,並輸出對應於0.75的二進位值0.11中的小數位「11」作為比特流。也就是說,輸入的二進位位「101」被映射到「11」並輸出。
參照圖20b,通過更新當前可用範圍rs和範圍rs的下邊界值rlb來執行根據cabac的二進位算術編碼過程。當二進位算術編碼開始時,設置rs=510,rlb=0。在當前二進位位的值vbin為mps時,範圍rs變為rmps。在當前二進位位的值vbin為lps時,將範圍rs改變為rlps,並且對下邊界值rlb進行更新以指示rlps。如上面圖20a中的示例所示,在二進位算術編碼處理期間根據當前二進位位的值是mps還是lps來更新預定區間rs,並且輸出指示更新區間的二進位值。
圖21是根據縮放因子的數量基於自相關值rk確定的縮放因子α的變化的圖。
在圖21中,x軸指示自相關值(rk=ρ),而y軸指示縮放因子。當相對於輸入的二進位位確定最優縮放因子時,如果使用一個縮放因子α1或α2(2120),則縮放因子值可能會太慢或太快地收斂到預定值。因此,可優先使用兩個縮放因子(2110)而不是一個縮放因子。
圖22是根據縮放因子的數量的mse的變化的圖。
在圖22中,參考標記2210表示當使用一個縮放因子時的mse,並且參考標記2220表示當使用兩個縮放因子時的mse。在圖22中,x軸指示自相關值(rk=ρ),而y軸指示mse。參照圖22,使用兩個縮放因子時的mse(2220)小於使用一個縮放因子時的mse(2210)。也就是說,通過使用當使用兩個比例因子時的自相關值rk概率可以比通過使用一個比例因子時的自相關值rk更精確地更新概率。
圖23是根據本公開實施方式的熵解碼設備2300的框圖。
參照圖23,熵解碼設備2300包括上下文建模器2310、常規解碼器2320、旁路解碼器2330和逆二值化器2340。熵解碼設備2300執行由上述熵編碼設備1400執行的熵編碼過程的逆過程。
通過旁路編碼進行編碼的二進位位由旁路解碼器2330輸出和解碼。由常規編碼進行編碼的二進位位由常規解碼器2320進行解碼。常規解碼器2320通過使用基於在由上下文建模器2310提供的當前二進位位之前解碼的先前二進位位確定的二進位值的概率,對當前二進位位進行算術解碼。
上下文建模器2310向常規解碼器2320提供對應於二進位位的概率模型。具體地,上下文建模器2310基於先前解碼的二進位位確定預定二進位值的概率,更新用於解碼先前二進位位的二進位值的概率,並將更新的概率輸出到常規解碼器2320。根據本公開實施方式的上下文建模器2310可通過使用二進位位的值來獲得每個二進位位的自相關值,基於自相關值確定用於更新二進位值的概率的至少一個縮放因子,然後通過使用所確定的至少一個縮放因子來更新二進位值的概率。
此外,根據本公開的另一實施方式的上下文建模器2310可通過應用具有不同縮放因子的多個概率模型獲得指示二進位位的平均位值的熵值,確定具有用於在多個概率模型中獲得最小熵值的概率模型的縮放因子,並且對通過使用所確定的縮放因子更新二進位值的概率。由上下文建模器2310執行的概率更新過程與包括在上述編碼過程中的概率更新過程相同,因此在此省略其詳細說明。
逆二值化器2340通過將二進位位字符串再次映射到語法元素來恢復由常規解碼器2320或旁路解碼器2330恢復的二進位位字符串。
圖24是根據本公開實施方式用於二進位算術解碼的概率更新方法的流程圖。
在操作2410中,上下文建模器2310接收要進行二進位算術解碼的預定數量的二進位位。
在操作2420中,上下文建模器2310通過使用所接收的預定數量的二進位位的值來獲得二進位位的自相關值。如上面等式3中所示,通過使用間隔預定距離k(k為整數)的二進位位的值、二進位位的平均值m和二進位位的方差σ來獲得自相關值rk。
在操作2430中,上下文建模器2310基於自相關值確定用於更新二進位值的概率的至少一個縮放因子。如上所述,根據本公開實施方式的概率更新方法使用在基於自相關值確定的每個二進位位的概率與每個二進位位的值之間具有最小mse的值作為縮放因子。當使用一個縮放因子時,可像上述等式8中那樣獲得一個最優縮放因子。當使用兩個比例因子α1和α2時,可通過代入(p1,j+p2,j)/2替換等式7中的pj來計算每個二進位位的概率和值之間的mse並且可確定產生最小mse的的縮放因子α1和α2。
如果通過使用二進位位的自相關值來確定一個或多個縮放因子,在操作2440中,上下文建模器2310通過使用所確定的一個或多個縮放因子來更新在基於上下文的自適應二進位算術解碼中使用的概率,並且向常規解碼器2320提供更新的概率。在操作2450中,常規解碼器2320通過使用更新的概率對下一個二進位位進行二進位算術解碼。
圖25是根據本公開的另一實施方式用於二進位算術解碼的概率更新方法的流程圖。
在操作2510中,上下文建模器2310接收要進行二進位算術解碼的預定數量的二進位位。
在操作2520中,上下文建模器2310通過應用具有不同縮放因子的多個概率模型來獲得指示二進位位的平均位值的熵值。
與上述二進位算術編碼過程類似,上下文建模器2310通過在二進位位單元中應用多個概率模型來計算熵。換句話說,上下文建模器2310根據當前二進位位y的值獲得類似等式10的參數biti,並且通過使用根據等式11的參數biti來獲得當前二進位位的熵si(t)。
在操作2530中,上下文建模器2310將通過應用多個縮放因子獲得的在多個熵值中的最小熵值中使用的縮放因子αi確定為最終縮放因子。
在操作2540中,上下文建模器2310通過使用確定的縮放因子來更新先前二進位值的概率,並將概率輸出到常規解碼器2320,並且常規解碼器2320通過使用更新的概率對下一個二進位位執行基於上下文的自適應二進位算術解碼。
本公開還可實施為在非暫態計算機可讀記錄介質上的計算機可讀代碼。非暫態計算機可讀記錄介質是可以存儲數據隨後可由計算機系統讀取的任意數據存儲設備。非暫態計算機可讀記錄介質的示例包括rom、ram、cd-rom、磁帶、軟盤、光學數據存儲設備等。非暫態計算機可讀記錄介質也可以分布在網絡聯接的計算機系統,使得計算機可讀代碼以分布式的方式被存儲和執行。
雖然已經參考附圖描述了實施方式,但是本領域普通技術人員將會理解,在沒有背離由所附權利要求限定的精神和範圍的情況下,可以在形式和細節上進行各種改變。因此,本公開的範圍不由本公開的詳細描述限定而是由所附權利要求限定,並且該範圍內的所有差異將解釋為包括在本公開中。