一種基於神經網絡的水質評價分類方法與流程
2023-04-28 23:50:02 5
本發明涉及模式識別與機器學習領域,特別涉及一種融合了lda,bpnn與adaboost的水質評價分類方法。
背景技術:
水質的預測與評價是水資源開發利用的重要組成部分,隨著人口與經濟發展,世界水資源的需求量不斷增加,我國水資源也面臨著質與量的雙重挑戰,其中水質挑戰尤為突出。水質的好壞關係到人民的健康安全,關係到國民的生活品質,因此迫切需要解決我國的水質安全問題。所以研究水質評價分類方法有重要意義。但由於評價指標與水質等級間的非常複雜的非線性關係,以及水體汙染的隨機性和模糊性,對於水質評價至今沒有一個被廣泛接受的評價模型。目前水質評價方法有單因子評價法與綜合評價法兩大類。
美國是較早開始水質評價的國家。1965年,horton提出了水質質量指數(wqi),nemerow提出了內梅羅法,ross提出了利用生化需氧量,氨氮,懸浮物及溶解氧四項指標評價水質。目前水質評價不僅考慮物理和化學指標,還考慮生物指標,使得水質評價更加全面科學。我國水質評價工作開始於1973年,大體經過了4個階段:初步嘗試階段,廣泛探索階段,全面發展階段和環境影響評價階段。初期僅限於城市或小範圍區域的現狀評價,如官廳水庫環境質量評價,北京西郊環境質量評價等,之後開展了松花江,白洋澱,武昌東湖,昆明滇池,太湖等水環境的專題質量評價工作。20世紀90年代後,各種數學方法和模型的廣泛應用使得水質評價方法得到進一步擴展。常見的有神經網絡法,投影尋蹤方法,灰色指數法,物元分析法等。現在,水質評價幾乎成了所有綜合環境質量評價中不可缺少的重要內容。
現在實行的地表水環境質量標準(gb3838-2002)中要求,地表水環境質量評價應根據應實現的水域功能類別,選取相應類別標準,進行單因子評價,即以單項指標最差所屬級別確定其綜合水質級別,這是符合實際的,因為若某項指標濃度嚴重超標,已不適合飲用,卻仍評為可作為飲用水源地的三類水,將給人民生命健康帶來威脅。但是單因子評價法各個參數之間沒有聯繫,缺乏可比性,因此需要一種綜合的水質評價方法。bpnn是一種行之有效的數據處理與分析算法,它的應用領域在不斷擴大並逐漸完善,立足於bpnn,同時為提高魯棒性,本方法提出使用lda算法對水質特徵參數進行預處理,使用adaboost計算框架綜合各個神經網絡的運算結果以提高評價分類的精度。
技術實現要素:
本發明的目的正是為了克服傳統單因子水質評價分類方法的缺點與不足,提供一種綜合的水質評價分類方法,本發明使用lda線性判別分析對水質特徵進行初始融合,使用bpnn算法訓練多個神經網絡,最後使用adaboost計算框架綜合各個神經網絡的計算結果對水質進行評價分類。
用於水質評價分類的測定方法,包括以下具體步驟:
步驟一:獲取各個水域中各類水質參數,包括ph,溫度,電導率,氧化還原電位,溶解氧,氨氮,高錳酸鹽指數,總磷,銅,鉛,錫共10項作為評價指標,並進行參數歸一化處理。
步驟二:使用lda線性判決分析算法將原始的帶標籤的10維水質特徵數據變換為5維水質特徵數據。
步驟三:構建5*6*6的神經網絡結構,第一層為輸入層,第二層為隱藏層,第三層為輸出層,第一層節點對輸入不進行函數變換,第二層以及第三層節點的轉換函數為sigmoid函數,隨機初始化網絡權值,訓練神經網絡使得損失函數達到最小值,從而獲得優化的網絡連接權重。
步驟四:依據adaboost算法更新每個樣本的權重,重新執行步驟三。
步驟五:重複執行步驟四直到訓練所得神經網絡分類準確率達到90%。
步驟六:使用adaboost算法綜合步驟三,四,五訓練得到的各個神經網絡的運算結果,對水質做出評價預測。
進一步地,步驟一中由於獲得的各類水質參數數值波動範圍不一致,因此需要對水質參數進行歸一化處理。
進一步地,在構建神經網絡時,輸入層的節點數由輸入數據維數決定,輸出層的節點數由水質分類的種類數決定,中間隱藏層的節點數與輸入輸出直接相關,即其中n為隱藏層節點個數,i為輸入層節點個數,o為輸出層節點個數,ceil(*)為一個向上取整函數。
4.進一步地,步驟四在更新權值時,減小被正確分類的樣本的權重,增大被錯誤分類的樣本的權重。在調整神經網絡的權值時加入了衝量與動態的學習速率;
權值更新函數定義為:
其中δw(k)為第k次更新時權值的變化,η(k)為動態的學習速率,mse表示神經網絡預測值與實際值之間的誤差,w表示當前網絡權值,mo(k)表示衝量,α為一個常數;
誤差函數定義為:
其中n表示神經網絡輸出層的節點數,yi表示神經網絡預測的第i個節點的輸出,oi表示實際值;
自適應的學習速率函數定義為:
其中mse(k)表示第k次更新時的誤差,mse(k-1)表示第k-1次更新時的誤差;
衝量函數定義為:
mo(k)=δw(k-1)
其中mo(k)表示第k次權值更新時的衝量,δw(k-1)表示第k-1次權值更新時權值的變化量。
進一步地,步驟六在神經網絡訓練結束後利用adaboost計算框架對各神經網絡的評價結果進行線性組合運算求取最後的預測結果。
進一步地,步驟六中,使用adaboost綜合各個神經網絡的分類結果,取結果最大的那一維序號作為對應水質的類別;綜合各個神經網絡分類結果的計算公式為:
其中t表示訓練得到的神經網絡個數,wt為各個神經網絡的權重,ht(x)為各神經網絡的輸出結果。
本發明與現有技術相比,具有如下優點和有益效果:
1、特徵太多會造成模型複雜,訓練速度過慢,因此本發明引入了特徵融合。本發明用lda線性判決分析算法進行水質特徵融合,增大了類間距離,縮小了類內距離,減小了分類器的分類難度。
2、在使用梯度下降法最優化目標函數時,容易陷入局部最小值,因此本方法在神經網絡權值更新時加入了衝量進行優化。
3、神經網絡算法的突出問題是收斂速度問題,本方法通過對連續兩次mse誤差的比較,動態調整學習速率,使得本方法對誤差曲面的變化更為敏感,使其具有更快的收斂速率。
4、adaboost針對同一個訓練集訓練了多個神經網絡分類器,將這些分類器綜合起來可以構成一個更強的最終分類器。使用adaboost可以排除一些不必要的訓練數據,而將重點放在關鍵的訓練數據上,從而提高了分類準確度。
5、本方法綜合了多個水質參數的影響,相比傳統的單因子評價法更加全面。
附圖說明
圖1是本算法融合了lda,bpnn,adaboost三種算法後的基本執行流程圖。
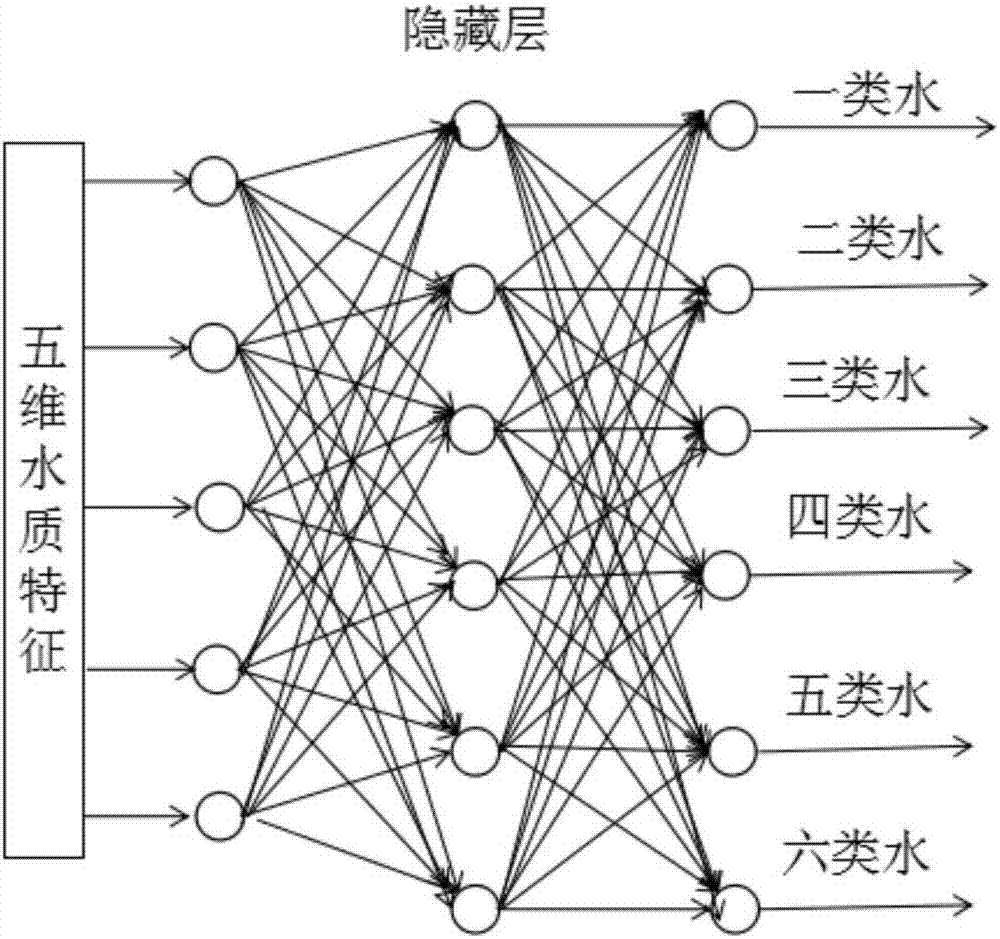
圖2是本算法所構建的神經網路的模型結構圖。
圖3是bpnn與adaboost結合的模型結構圖。
具體實施方式
為了使本發明的目的,技術方案和優點更加清楚明白,以下結合具體實施方案,對本發明的實施作進一步的詳細說明。
步驟一:獲取各個水域中各類水質參數,包括ph,溫度,電導率,氧化還原電位,溶解氧,氨氮,高錳酸鹽指數,總磷,銅,鉛,錫共10項,再對參數做歸一化處理,如公式所示:
其中x*表示歸一化處理後的參數值,x表示原參數值,min表示該參數在本樣本空間中的最小值,max表示該參數在樣本空間中的最大值。
步驟二:利用lda線性判決分析方法進行水質特徵融合,這樣有利於bpnn進行訓練。lda算法是一種有監督的特徵融合算法,若樣本類型數為n,那麼融合後樣本特徵維數為n-1,而水質類型有6類,因此10維水質特徵數據進行特徵融合之後維數變為5。
步驟三:參考gb3838-2002中國地表水環境質量標準,標準中將地表水分為6類,故輸出層神經元個數確定為6。
輸出水質分類為1-6類分別編碼為:
一類水:[0.9,0.1,0.1,0.1,0.1,0.1]
二類水:[0.1,0.9,0.1,0.1,0.1,0.1]
三類水:[0.1,0.1,0.9,0.1,0.1,0.1]
四類水:[0.1,0.1,0.1,0.9,0.1,0.1]
五類水:[0.1,0.1,0.1,0.1,0.9,0.1]
六類水:[0.1,0.1,0.1,0.1,0.1,0.9]
本訓練網絡使用含一個隱藏層的神經網絡。隱藏層節點個數與輸入節點數以及輸出節點數有關,即其中n為隱藏層節點個數,i為輸入層節點個數,o為輸出層節點個數,ceil(*)為一個向上取整函數。因此構建5*6*6的神經網絡,初始化神經網絡中的權值為介於[-0.1,0.1]的隨機值,節點輸入層節點對輸入信號不進行變換,隱藏層與輸出層節點轉換函數使用sigmoid函數。在權值更新迭代時使用動態的學習速率,同時添加衝量以減小陷入局部最小的概率。
權值更新函數定義為:
其中δw(k)為第k次更新時權值的變化,η(k)為動態的學習速率,mse表示神經網絡預測值與實際值之間的誤差,w表示當前網絡權值,mo(k)表示衝量,α為一個常數,值為0.3。
誤差函數定義為:
其中n表示神經網絡輸出層的節點數,yi表示神經網路預測的第i個節點的輸出,oi表示樣本標籤向量第i維度的實際值。
自適應的學習速率函數定義為:
其中mse(k)表示第k次權值更新時的誤差,mse(k-1)表示第k-1次權值更新時的誤差。
衝量函數定義為:
mo(k)=δw(k-1)
其中δw(k-1)表示第k-1次權值更新時權值的變化量。
利用反向傳播和隨機梯度下降算法有監督地最小化誤差函數,從而獲得優化的網絡連接權值,再計算分類的準確率。
步驟四:根據上一次的預測結果更新每個樣本的權值。計算該神經網絡在各樣本下的總誤差εt:
其中n表示樣本總數。dt(i)表示對於第t個神經網絡,第i個樣本所佔的權重。yt(xi)表示第t個神經網絡,第i個樣本對應的輸出。oi表示第i個樣本的實際值。yt(xi)=oi表示神經網絡輸出值與樣本實際值相等,若兩個值相等i(yt(xi)=oi)等於1,否則i(yt(xi)=oi)等於0。
樣本的權值更新函數為:
其中dt(i)表示第t個神經網絡中第i個樣本的權重,dt-1(i)表示第t-1個神經網絡中第i個樣本的權重,樣本被正確分類則εt前取負號,否則取正號。zt是使得的歸一化因子。
神經網絡輸出在最後結果中所佔權重為:
重新執行步驟三。
步驟五:重複執行步驟四直到訓練所得神經網絡分類準確率達到90%。
步驟六:對步驟三,四,五所得的神經網絡輸出的結果向量做線性組合運算,取結果最大的那一維序號作為對應水質的類別。
線性組合函數定義為:
其中x表示輸入樣本,t表示訓練所得的神經網絡的數量,wt為各個神經網絡的權重,ht(x)為各神經網絡的輸出結果。
本發明引入了特徵融合。本發明用lda線性判決分析算法進行水質特徵融合,增大了類間距離,縮小了類內距離,減小了分類器的分類難度。在使用梯度下降法最優化目標函數時,容易陷入局部最小值,因此本方法在神經網絡權值更新時加入了衝量進行優化。本方法通過對連續兩次mse誤差的比較,動態調整學習速率,使得本方法對誤差曲面的變化更為敏感,使其具有更快的收斂速率。adaboost針對同一個訓練集訓練了多個神經網絡分類器,將這些分類器綜合起來可以構成一個更強的最終分類器。使用adaboost可以排除一些不必要的訓練數據,而將重點放在關鍵的訓練數據上,從而提高了分類準確度。