一種基於集成ELM的配電網竊電嫌疑用戶智能識別方法與流程
2023-05-15 18:11:11 4
本發明涉及配電網反竊電技術領域,具體涉及一種基於集成ELM的配電網竊電嫌疑用戶智能識別方法。
技術背景
因用電用戶有意或無意的非法用電行為,導致營銷系統不能正常計費收費,給電力系統在運行過程中造成一定的損失,為了避免和減少這些損失,需要對用戶的用電使用情況實時監測,防止和減少竊電和漏電的情況出現。
傳統的防竊電措施通常是定期巡檢線路、定期校驗電錶、用戶舉報竊電等手段,這些手段效率低、對人的依賴大,目標也不明確,需要一個智能的分析手段來判定用戶的用電是否正常,再對重點監控的用戶實時告警,為現場勘察是否偷電提供依據,即採用大數據分析與挖掘技術對竊電嫌疑用戶進行智能識別。
目前,BP神經網絡算法憑藉強大的自學習與自適應能力較為廣泛應用於防竊電預測領域,但其收斂速度慢,對樣本依賴性強等缺點也影響了預測的效率及精度。基於上述背景,本發明提出了一種基於集成ELM(Extreme Learning Machine,極限學習機)的配電網竊電嫌疑用戶智能識別方法。該方法集合了ELM較快的學習速度與集成學習的高精度性,並從線損、竊電告警、電量及負荷多個維度分析用戶竊電嫌疑,能實現竊電行為的快速有效識別,從而將反竊電管理模式提升至「事前預防、事中控制」的管理水平。
技術實現要素:
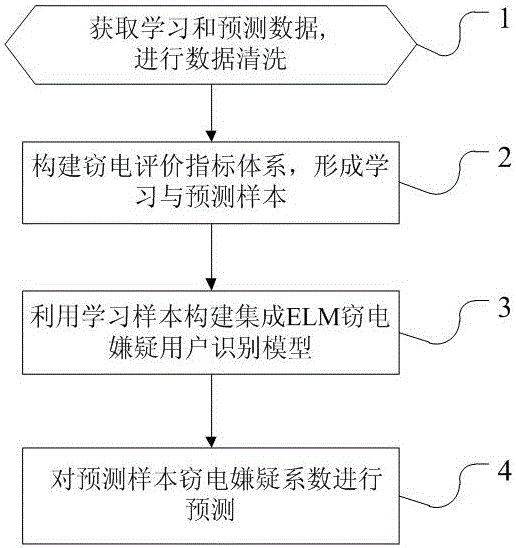
本發明涉及一種基於集成ELM的配電網竊電嫌疑用戶智能識別方法,主要包括以下步驟:
步驟1:獲取學習數據和預測數據並進行數據清洗;
步驟2:構建竊電評價指標體系:告警特徵、電量特徵及負荷特徵,形成學習樣本和預測樣本;
步驟3:將所述的學習樣本劃分為訓練集和測試集,利用所述的訓練集學習集成ELM竊電嫌疑用戶識別模型,並基於所述的測試集評估模型效果。
步驟4:將預測樣本作為所述的集成ELM竊電嫌疑用戶識別模型輸入量,輸出每一用戶的竊電嫌疑係數,鎖定竊電嫌疑用戶。
所述的基於集成ELM的配電網竊電嫌疑用戶智能識別方法,其特徵在於,所述的學習數據和預測數據,包含用戶檔案、告警、行度及負荷四種類型;所述的學習數據中必須包含正常用戶樣本與竊電用戶樣本,所述的測試數據僅包含竊電嫌疑線路下的部分用戶,而竊電嫌疑線路通過線損進行定位。
所述的基於集成ELM的配電網竊電嫌疑用戶智能識別方法,其特徵在於,所述的竊電評價指標體系,包含告警、電量及負荷三大特徵,所述的告警特徵為竊電告警係數,所述的電量特徵包括斜率及截距,所述的負荷特徵包括斜率及截距,為當前時間往前推移的天數。
所述的基於集成ELM的配電網竊電嫌疑用戶智能識別方法,其特徵在於,所述的竊電告警係數的計算公式為:
其中,表示所有竊電告警組合(包括單個的)的權重之和,表示天內出現的所有告警組合的最大子集的權重,而告警及其組合的權重將根據其對竊電的影響程度的大小有專業人員設定。
所述的基於集成ELM的配電網竊電嫌疑用戶智能識別方法,其特徵在於,所述的斜率、截距、斜率及截距將通過構建一元線性回歸方程得到,具體模型為:
,
其中,,,,為用電量,為時間編號(以天為單位),為負荷,故、分別表示在第天的前天的用電量及負荷,有,,,。
所述的集成ELM竊電嫌疑用戶識別模型,包含如下幾個步驟:
(1)初始化ELM模型參數,包括:極限學習機隱含層神經元個數,訓練極限學習機個數,基於準確率集成極限學習機分類器的個數,基於差異度集成的極限學習機的個數;
(2)基於不同,用訓練樣本(矩陣)訓練生成個極限學習機;
(3)用每個極限學習機識別測試集樣本,計算每一個極限學習機分類器的確率:
(4)根據識別率大小,選擇個識別效果較好的極限學習機。
(5)對於篩選出的個極限學習機,採用Q統計法計算任何,間的差異度,計算公式為:
其中,與表示極限學習機,均預測正確與均預測錯誤的樣本數,表示預測錯誤而預測正確的樣本數,相反,表示預測正確而預測錯誤的樣本數。
(6)將個極限學習機組合為個分類器集,計算每個分類器集的差異度:
表示第個分類器集中極限學習機間的差異度。
(7)比較所有極限學習機分類器集的差異度,最大對應的極限學習機集合則為集成ELM模型。
(8)當利用上述集成ELM模型進行預測時,採用投票法得到綜合判斷結果。
本發明提出的集成ELM竊電嫌疑用戶識別模型,綜合考慮了單一ELM的高學習效率與高泛化能力,針對單一ELM模型訓練精度較弱的缺點,對其採用集成學習的方式進行改進。同時,為保證集成ELM模型的多樣性及有效性,對於不同的單一ELM採用不同的網絡結構(隱含層神經元不同),並利用準確率與差異度對其進行篩選,使最終集成的組合ELM模型最優,對竊電嫌疑用戶的識別效果明顯優於傳統的單一ELM模型。在指標的選擇上,模型從與竊電有關告警、平均電量及其變化趨勢、平均負荷及其變化趨勢多個維度分析用戶竊電的可能性,能有效識別用戶竊電行為,將反竊電管理模式提升至「事前預防、事中控制」的管理水平。
附圖說明
圖1 基於集成ELM的配電網竊電嫌疑用戶智能識別方法的主要流程圖;
圖2 集成ELM模型的主要流程圖;
圖3 單一ELM模型的示意圖;
圖4 本發明模型的ROC曲線與傳統單一LM模型的比較圖。
具體實施方式
下面結合附圖和實施例對本發明的技術方案進行詳細的說明。
本實施例為基於本發明集成ELM竊電嫌疑用戶智能識別模型對廣東電網江門供電局蓬江竊電嫌疑用戶做出預測,結合圖1的模型建立與求解過程,具體步驟如下:
步驟1:獲取學習數據和預測數據並進行數據清洗;
步驟2:構建竊電評價指標體系:告警特徵、電量特徵及負荷特徵,形成學習樣本和預測樣本;
步驟3:將所述的學習樣本劃分為訓練集和測試集,利用所述的訓練集學習集成ELM竊電嫌疑用戶識別模型,並基於所述的測試集評估模型效果。
步驟4:將預測樣本作為所述的集成ELM竊電嫌疑用戶識別模型輸入量,輸出每一用戶的竊電嫌疑係數,鎖定竊電嫌疑用戶。
所述的步驟1具體說明如下:
本實施例涉及的數據來源於2016年1月至2016年10月廣東省江門市蓬江區內配網用戶檔案(用戶編號、用電類型)、竊電告警(用戶編號、告警名稱、告警時間)、行度(用戶編號、日期、日走字)、負荷(用戶編號,日期,負荷)數據,其中行度及告警數據的時間間隔為1小時。其中2016年1月份至9月份的竊電用戶及部分正常用戶組數據為學習數據,2016年10月份部分用戶數據為預測數據。本過程可以描述為:
S1.1:學習數據抽取。從江門供電局計量自動化系統抽取蓬江供電局2016年1月至2016年9月竊電用戶及部分正常用戶上述四種類型數據。
S1.2:預測數據抽取,具體包含以下3個子步驟:
1)篩選10月份月線損超出正常範圍線路為竊電嫌疑線路;
2)針對竊電嫌疑線路下用戶,結合用電類型,排除路燈專變、學校用電等竊電嫌疑微小用戶,並定義工業用電、商業用電等其餘用電戶為待預測用戶。
3)針對待預測用戶,從江門供電局計量自動化系統抽取2016年10月份數據組成測試數據。
S1.3:數據清洗,具體包括:缺失數據的插補與異常數據的處理。
所述的步驟2具體說明如下:
S2.1:針對清洗後的學習與預測數據,計算每個用戶每天的總電量及總負荷, 整理其告警組合;
S2.2:計算每一個用戶每一天的竊電告警係數:
其中,表示所有竊電告警組合(包括單個的)的權重之和,表示天內出現的所有告警組合的最大子集的權重,而告警及其組合的權重將根據其對竊電的影響程度的大小有專業人員設定。
S2.3:利用一元回歸模型計算每一個用戶每一天的電量特徵,即斜率、截距:
其中,,,為用電量,為時間編號(以天為單位),表示在第天的前天的用電量,有,,此處有的取值為5。
S2.4:利用一元回歸模型計算每一個用戶每一天的電量特徵,即斜率、截距:
其中,,,為負荷,為時間編號(以天為單位),表示在第天的前天的負荷,有,,此處有的取值為5。
S2.5:形成學習樣本和預測樣本。對於學習樣本,需根據用戶在某一日期是否竊電為每一條記錄打標籤,1表示竊電,0表示未竊電,最終形成學習樣本和預測樣本如表1,表2示例所示:
表1 學習樣本示例
表2 測試樣本示例
結合附圖2,所述的步驟3具體說明如下:
S3.1:劃分訓練集與測試集,比例為7:3;
S3.2:利用訓練集學習集成ELM模型;
S3.3:利用測試集評估集成ELM模型。
S3.2子步驟:
1)S3.1:初始化ELM模型參數,包括:極限學習機隱含層神經元個數,訓練極限學習機個數,基於準確率集成極限學習機分類器的個數,基於差異度集成的極限學習機的個數,本實施例中,、、、的取值分別為:、100、60、30。
2)S3.2:基於不同,用訓練樣本(矩陣)訓練生成個極限學習機,具體包括:
a.判斷生成的極限學習機的個數是否滿足,否,轉b,是,結束S3.2。
b.基於的取值範圍,隨機產生的具體數值;
c.基於和樣本特徵個數(本模型為5),隨機生成極限學習機輸入層到隱含層連接權重矩陣(ⅹ);
d.計算隱含層與輸出層間連接權重,得到單一極限學習機模型。返回a。
3)用每個極限學習機識別測試集樣本,計算每一個極限學習機分類器的確率:
4)根據識別率大小,選擇個識別效果較好的極限學習機。
5)對於篩選出的個極限學習機,採用Q統計法計算任何,間的差異度,計算公式為:
其中,與表示極限學習機,均預測正確與均預測錯誤的樣本數,表示預測錯誤而預測正確的樣本數,相反,表示預測正確而預測錯誤的樣本數。
6)將個極限學習機組合為個分類器集,計算每個分類器集的差異度:
表示第個分類器集中極限學習機間的差異度。
7)比較所有極限學習機分類器集的差異度,最大對應的極限學習機集合則為集成ELM模型。
8)當利用上述集成ELM模型進行預測時,採用投票法得到綜合判斷結果。
所述的S3.3的具體過程描述如下:
將測試集作為上述集成ELM模型的輸入,預測測試集中每一用戶在某一天的竊電嫌疑概率,並將0.5作為劃分是否竊電的閾值,並將結果繪製為ROC曲線。
ROC曲線是衡量一個分類模型分類效果高低的標準,一般情況下,ROC曲線包含的面積越大。圖3中本發明算法所代表的ROC曲線位於傳統單一ELM模型的上方,證明了集成ELM模型的識別效果優於傳統單一ELM。
所述的步驟4具體說明如下:
將預測樣本作為所述的集成ELM竊電嫌疑用戶識別模型輸入量,輸出每一用戶的竊電嫌疑係數,鎖定竊電嫌疑用戶,後續可繼續監測嫌疑用戶的用電行為再進行現場取證。
綜合以上分析,本發明提出的集成ELM竊電嫌疑用戶識別模型,綜合考慮了單一ELM的高學習效率與高泛化能力,且針對單一ELM模型訓練精度較弱的缺點,對其採用集成學習的方式進行改進。同時,為保證集成ELM模型的多樣性及有效性,對於不同的單一ELM採用不同的網絡結構(隱含層神經元不同),並利用準確率與差異度對其進行篩選,使最終集成的組合ELM模型最優,對竊電嫌疑用戶的識別效果明顯優於傳統的單一ELM模型。在指標的選擇上,模型從與竊電有關告警、平均電量及其變化趨勢、平均負荷及其變化趨勢多個維度分析用戶竊電的可能性,能有效識別用戶竊電行為,將反竊電管理模式提升至「事前預防、事中控制」的管理水平。