未登錄詞的識別方法及識別系統與流程
2023-04-26 11:26:51 6
本發明涉及計算機技術領域,具體而言,涉及一種未登錄詞的識別方法和一種未登錄詞的識別系統。
背景技術:
未登錄詞即沒有被收錄在分詞詞表中但必須切出來的詞,隨著未登錄詞的不斷產生,未登錄詞識別也變得越來越重要,可以說詞是做自然語言處理的第一步也是最重要的一步,只有當有詞以後才可以對文本進行分詞、詞性標註、關鍵詞提取、數據檢索等後續操作。
近年來,未登錄詞識別已經有很多技術,例如可以通過隱馬爾可夫模型、條件隨機場等模型在文本中進行未登錄詞識別。
隱馬爾可夫模型(Hidden Markov Model,HMM)是統計模型,它用來描述一個含有隱含未知參數的馬爾可夫過程。隱馬爾可夫模型作為一種統計分析模型,創立於20世紀70年代,80年代得到了傳播和發展,成為信號處理的一個重要方向,現已成功地用於語音識別,行為識別,文字識別以及故障診斷等領域。
條件隨機場(Conditional Random Fields,簡稱CRF,或CRFs),是一種判別式概率模型,是隨機場的一種,常用於標註或分析序列資料,如自然語言文字或是生物序列。
但是,現有的隱馬爾可夫模型、條件隨機場等模型在文本中未登錄詞識別的過程中仍存在一定的缺陷:它們都需要通過人工的方法來發現字與字的特徵,需要花費大量的時間觀察大量的數據去總結。因此,現有技術中利用隱馬爾可夫模型、條件隨機場等模型的計算代價高,耗時長。
技術實現要素:
本發明正是基於上述技術問題至少之一,提出了一種新的未登錄詞的識別方案,可以高效、準確地從大數據量的業務數據中提取出未登錄詞。
有鑑於此,本發明提出了一種未登錄詞的識別方法,包括:對獲取到的業務數據進行預處理,以得到分詞結果;根據所述分詞結果,創建包括多個候選未登錄詞的候選詞集合;對所述候選詞集合中的候選未登錄詞進行過濾處理,以得到過濾後的候選未登錄詞;將所述過濾後的候選未登錄詞添加至目標詞庫中。
在該技術方案中,通過對獲取到的業務數據進行預處理,以得到分詞結果,並根據分詞結果創建包括多個候選未登錄詞的候選詞集合,對候選詞集合中的候選未登錄詞進行過濾處理,以得到過濾後的候選未登錄詞,並將過濾後的候選未登錄詞添加至目標詞庫中,使得無需事先訓練大規模語料庫即可從業務數據中提取出過濾後的未登錄詞,且整個處理過程高效、準確。
在上述技術方案中,優選地,所述根據所述分詞結果,創建包括多個候選未登錄詞的候選詞集合的步驟,具體包括:根據所述分詞結果,構建左右PAT-ARRAY樹,其中,所述左右PAT-ARRAY樹中包含有多個重複串;從所述PAT-ARRAY樹中,提取詞頻大於或等於第一閾值且長度在預定範圍內的重複串;將提取出的重複串作為候選未登錄詞,並創建所述候選詞集合。
在該技術方案中,PAT-ARRAY(PAT數組結構)樹是一種能高效地識別前綴的數據結構,通過對分詞結果構建左右PAT-ARRAY樹,並從PAT-ARRAY樹中,提取詞頻大於或等於第一閾值且長度在預定範圍內的重複串作為候選未登錄詞,提高了整個提取過程的效率,其中,對分詞結果構建左右PAT-ARRAY樹包括初始化位置數組信息(即保存詞在分詞結果中的位置),對位置數組按詞序進行排序,計算相鄰位置數組的詞串的共有前綴或共有後綴。
在上述任一項技術方案中,優選地,所述第一閾值為2,所述預定範圍為大於等於2且小於等於4。
在上述任一項技術方案中,優選地,所述對所述候選詞集合中的候選未登錄詞進行過濾處理,以得到過濾後的候選未登錄詞的步驟,具體包括:計算所述候選詞集合中的候選未登錄詞的互信息以及左右信息熵;過濾所述候選詞集合中互信息小於第二閾值和/或左後信息熵小於第三閾值的候選未登錄詞;根據互信息的取值,對過濾後的候選詞集合中的候選未登錄詞進行降序排列,並將前N個候選未登錄詞作為所述過濾後的候選未登錄詞,或對過濾後的候選詞集合中的候選未登錄詞進行升序排列,並將後N個候選未登錄詞作為所述過濾後的候選未登錄詞。
在該技術方案中,通過計算候選詞集合中的候選未登錄詞的互信息以及左右信息熵,並根據互信息和左右信息熵對候選未登錄詞進行過濾,並對過濾後的候選詞集合中的候選未登錄詞進行排列,僅提取其中部分候選未登錄詞作為過濾後的候選未登錄詞添加至目標詞庫,使得篩選出的未登錄詞更準確,其中,N可取過濾後的候選詞集合中所有候選未登錄詞的30%至40%。
在上述任一項技術方案中,優選地,所述第二閾值為6,所述第三閾值為1.5。
在上述任一項技術方案中,優選地,所述對獲取到的業務數據進行預處理的步驟,具體包括:對所述業務數據進行分詞處理、消歧處理、以及詞性標註處理。
在該技術方案中,通過對業務數據進行分詞處理、消歧處理、以及詞性標註處理等預處理,為後續根據預處理得到的分析結果篩選候選未登錄詞提供了前提保障。
根據本發明的第二方面,提出了一種未登錄詞的識別系統,包括:第一處理單元,用於對獲取到的業務數據進行預處理,以得到分詞結果;創建單元,用於根據所述分詞結果,創建包括多個候選未登錄詞的候選詞集合;第二處理單元,用於對所述候選詞集合中的候選未登錄詞進行過濾處理,以得到過濾後的候選未登錄詞;添加單元,用於將所述過濾後的候選未登錄詞添加至目標詞庫中。
在該技術方案中,通過對獲取到的業務數據進行預處理,以得到分詞結果,並根據分詞結果創建包括多個候選未登錄詞的候選詞集合,對候選詞集合中的候選未登錄詞進行過濾處理,以得到過濾後的候選未登錄詞,並將過濾後的候選未登錄詞添加至目標詞庫中,使得無需事先訓練大規模語料庫即可從業務數據中提取出過濾後的未登錄詞,且整個處理過程高效、準確。
在上述技術方案中,優選地,所述創建單元具體用於:根據所述分詞結果,構建左右PAT-ARRAY樹,其中,所述左右PAT-ARRAY樹中包含有多個重複串;從所述PAT-ARRAY樹中,提取詞頻大於或等於第一閾值且長度在預定範圍內的重複串;將提取出的重複串作為候選未登錄詞,並創建所述候選詞集合。
在該技術方案中,PAT-ARRAY樹是一種能高效地識別前綴的數據結構,通過對分詞結果構建左右PAT-ARRAY樹,並從PAT-ARRAY樹中,提取詞頻大於或等於第一閾值且長度在預定範圍內的重複串作為候選未登錄詞,提高了整個提取過程的效率,其中,對分詞結果構建左右PAT-ARRAY樹包括初始化位置數組信息(即保存詞在分詞結果中的位置),對位置數組按詞序進行排序,計算相鄰位置數組的詞串的共有前綴或共有後綴。
在上述任一項技術方案中,優選地,所述第一閾值為2,所述預定範圍為大於等於2且小於等於4。
在上述任一項技術方案中,優選地,所述第二處理單元包括:計算單元,用於計算所述候選詞集合中的候選未登錄詞的互信息以及左右信息熵;過濾單元,用於過濾所述候選詞集合中互信息小於第二閾值和/或左後信息熵小於第三閾值的候選未登錄詞;確定單元,用於根據互信息的取值,對過濾後的候選詞集合中的候選未登錄詞進行降序排列,並將前N個候選詞作為所述過濾後的候選未登錄詞,或對過濾後的候選詞集合中的候選未登錄詞進行升序排列,並將後N個候選未登錄詞作為所述過濾後的候選未登錄詞。
在該技術方案中,通過計算候選詞集合中的候選未登錄詞的互信息以及左右信息熵,並根據互信息和左右信息熵對候選未登錄詞進行過濾,並對過濾後的候選詞集合中的候選未登錄詞進行排列,僅提取其中部分候選未登錄詞作為過濾後的候選未登錄詞添加至目標詞庫,使得篩選出的未登錄詞更準確,其中,N可取過濾後的候選詞集合中所有候選未登錄詞的30%至40%。
在上述任一項技術方案中,優選地,所述第二閾值為6,所述第三閾值為1.5。
在上述任一項技術方案中,優選地,所述第一處理單元具體用於:對所述業務數據進行分詞處理、消歧處理、以及詞性標註處理。
在該技術方案中,通過對業務數據進行分詞處理、消歧處理、以及詞性標註處理等預處理,為後續根據預處理得到的分析結果篩選候選未登錄詞提供了前提保障。
通過以上技術方案,可以高效、準確地從大數據量的業務數據中提取出未登錄詞。
附圖說明
圖1示出了根據本發明的一個實施例的未登錄詞的識別方法的示意流程圖;
圖2示出了根據本發明的實施例的未登錄詞的識別系統的示意框圖;
圖3示出了根據本發明的另一個實施例的未登錄詞的識別方法的示意流程圖。
具體實施方式
為了能夠更清楚地理解本發明的上述目的、特徵和優點,下面結合附圖和具體實施方式對本發明進行進一步的詳細描述。需要說明的是,在不衝突的情況下,本申請的實施例及實施例中的特徵可以相互組合。
在下面的描述中闡述了很多具體細節以便於充分理解本發明,但是,本發明還可以採用其他不同於在此描述的其他方式來實施,因此,本發明的保護範圍並不受下面公開的具體實施例的限制。
圖1示出了根據本發明的一個實施例的未登錄詞的識別方法的示意流程圖。
如圖1所示,根據本發明的一個實施例的未登錄詞的識別方法,包括:
步驟102,對獲取到的業務數據進行預處理,以得到分詞結果。
步驟104,根據所述分詞結果,創建包括多個候選未登錄詞的候選詞集合。
步驟106,對所述候選詞集合中的候選未登錄詞進行過濾處理,以得到過濾後的候選未登錄詞。
步驟108,將所述過濾後的候選未登錄詞添加至目標詞庫中。
在該技術方案中,通過對獲取到的業務數據進行預處理,以得到分詞結果,並根據分詞結果創建包括多個候選未登錄詞的候選詞集合,對候選詞集合中的候選未登錄詞進行過濾處理,以得到過濾後的候選未登錄詞,並將過濾後的候選未登錄詞添加至目標詞庫中,使得無需事先訓練大規模語料庫即可從業務數據中提取出過濾後的未登錄詞,且整個處理過程高效、準確。
在上述技術方案中,優選地,所述根據所述分詞結果,創建包括多個候選未登錄詞的候選詞集合的步驟,具體包括:根據所述分詞結果,構建左右PAT-ARRAY樹,其中,所述左右PAT-ARRAY樹中包含有多個重複串;從所述PAT-ARRAY樹中,提取詞頻大於或等於第一閾值且長度在預定範圍內的重複串;將提取出的重複串作為候選未登錄詞,並創建所述候選詞集合。
在該技術方案中,PAT-ARRAY樹是一種能高效地識別前綴的數據結構,通過對分詞結果構建左右PAT-ARRAY樹,並從PAT-ARRAY樹中,提取詞頻大於或等於第一閾值且長度在預定範圍內的重複串作為候選未登錄詞,提高了整個提取過程的效率,其中,對分詞結果構建左右PAT-ARRAY樹包括初始化位置數組信息(即保存詞在分詞結果中的位置),對位置數組按詞序進行排序,計算相鄰位置數組的詞串的共有前綴或共有後綴。
在上述任一項技術方案中,優選地,所述第一閾值為2,所述預定範圍為大於等於2且小於等於4。
在上述任一項技術方案中,優選地,所述對所述候選詞集合中的候選未登錄詞進行過濾處理,以得到過濾後的候選未登錄詞的步驟,具體包括:計算所述候選詞集合中的候選未登錄詞的互信息以及左右信息熵;過濾所述候選詞集合中互信息小於第二閾值和/或左後信息熵小於第三閾值的候選未登錄詞;根據互信息的取值,對過濾後的候選詞集合中的候選未登錄詞進行降序排列,並將前N個候選未登錄詞作為所述過濾後的候選未登錄詞,或對過濾後的候選詞集合中的候選未登錄詞進行升序排列,並將後N個候選未登錄詞作為所述過濾後的候選未登錄詞。
在該技術方案中,通過計算候選詞集合中的候選未登錄詞的互信息以及左右信息熵,並根據互信息和左右信息熵對候選未登錄詞進行過濾,並對過濾後的候選詞集合中的候選未登錄詞進行排列,僅提取其中部分候選未登錄詞作為過濾後的候選未登錄詞添加至目標詞庫,使得篩選出的未登錄詞更準確,其中,N可取過濾後的候選詞集合中所有候選詞的30%至40%。
在上述任一項技術方案中,優選地,所述第二閾值為6,所述第三閾值為1.5。
在上述任一項技術方案中,優選地,所述對獲取到的業務數據進行預處理的步驟,具體包括:對所述業務數據進行分詞處理、消歧處理、以及詞性標註處理。
在該技術方案中,通過對業務數據進行分詞處理、消歧處理、以及詞性標註處理等預處理,為後續根據預處理得到的分析結果篩選候選未登錄詞提供了前提保障。
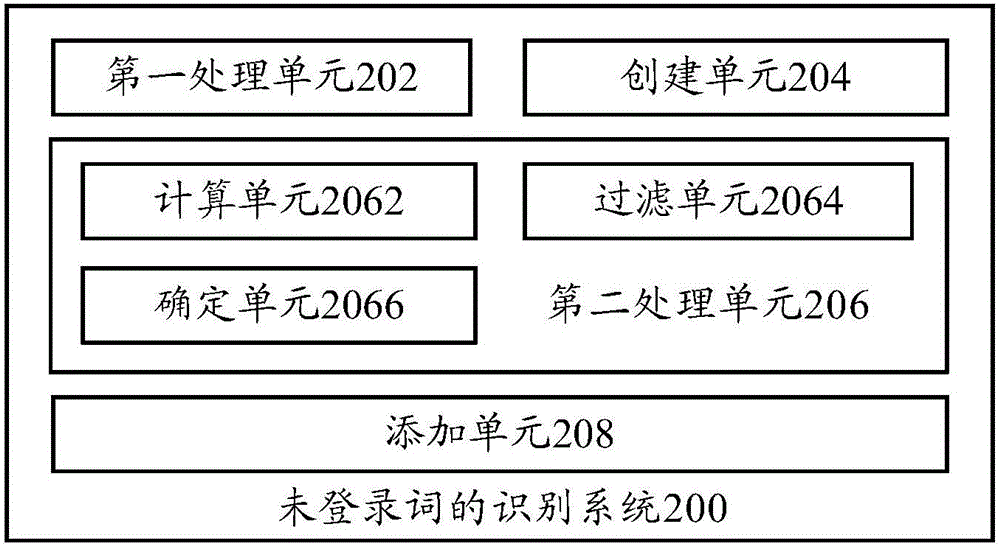
圖2示出了根據本發明的實施例的未登錄詞的識別系統的示意框圖。
如圖2所示,根據本發明的實施例的未登錄詞的識別系統200,包括:第一處理單元202、創建單元204、第二處理單元206和添加單元208。
其中,第一處理單元202用於對獲取到的業務數據進行預處理,以得到分詞結果;創建單元204用於根據所述分詞結果,創建包括多個候選未登錄詞的候選詞集合;第二處理單元206用於對所述候選詞集合中的候選未登錄詞進行過濾處理,以得到過濾後的候選未登錄詞;添加單元208用於將所述過濾後的候選未登錄詞添加至目標詞庫中。
在該技術方案中,通過對獲取到的業務數據進行預處理,以得到分詞結果,並根據分詞結果創建包括多個候選未登錄詞的候選詞集合,對候選詞集合中的候選未登錄詞進行過濾處理,以得到過濾後的候選未登錄詞,並將過濾後的候選未登錄詞添加至目標詞庫中,使得無需事先訓練大規模語料庫即可從業務數據中提取出過濾後的候選未登錄詞,且整個處理過程高效、準確。
在上述技術方案中,優選地,所述創建單元204具體用於:根據所述分詞結果,構建左右PAT-ARRAY樹,其中,所述左右PAT-ARRAY樹中包含有多個重複串;從所述PAT-ARRAY樹中,提取詞頻大於或等於第一閾值且長度在預定範圍內的重複串;將提取出的重複串作為候選未登錄詞,並創建所述候選詞集合。
在該技術方案中,PAT-ARRAY樹是一種能高效地識別前綴的數據結構,通過對分詞結果構建左右PAT-ARRAY樹,並從PAT-ARRAY樹中,提取詞頻大於或等於第一閾值且長度在預定範圍內的重複串作為候選未登錄詞,提高了整個提取過程的效率,其中,對分詞結果構建左右PAT-ARRAY樹包括初始化位置數組信息(即保存詞在分詞結果中的位置),對位置數組按詞序進行排序,計算相鄰位置數組的詞串的共有前綴或共有後綴。
在上述任一項技術方案中,優選地,所述第一閾值為2,所述預定範圍為大於等於2且小於等於4。
在上述任一項技術方案中,優選地,所述第二處理單元206包括:計算單元2062,用於計算所述候選詞集合中的候選未登錄詞的互信息以及左右信息熵;過濾單元2064,用於過濾所述候選詞集合中互信息小於第二閾值和/或左後信息熵小於第三閾值的候選未登錄詞;確定單元2066,用於根據互信息的取值,對過濾後的候選詞集合中的候選未登錄詞進行降序排列,並將前N個候選未登錄詞作為所述過濾後的候選未登錄詞,或對過濾後的候選詞集合中的候選未登錄詞進行升序排列,並將後N個候選未登錄詞作為所述過濾後的候選未登錄詞。
在該技術方案中,通過計算候選詞集合中的候選未登錄詞的互信息以及左右信息熵,並根據互信息和左右信息熵對候選未登錄詞進行過濾,並對過濾後的候選詞集合中的候選未登錄詞進行排列,僅提取其中部分候選未登錄詞作為過濾後的候選未登錄詞添加至目標詞庫,使得篩選出的未登錄詞更準確,其中,N可取過濾後的候選詞集合中所有候選詞的30%至40%。
在上述任一項技術方案中,優選地,所述第二閾值為6,所述第三閾值為1.5。
在上述任一項技術方案中,優選地,所述第一處理單元202具體用於:對所述業務數據進行分詞處理、消歧處理、以及詞性標註處理。
在該技術方案中,通過對業務數據進行分詞處理、消歧處理、以及詞性標註處理等預處理,為後續根據預處理得到的分析結果篩選候選未登錄詞提供了前提保障。
以下對本發明的技術方案作進一步說明。
在本實施例中,可對業務數據進行分詞,並對分詞結果建立左右PAT-ARRAY樹,然後提取候選未登錄詞,計算候選未登錄詞的互信息及左右信息熵,並根據候選未登錄詞的互信息及左右信息熵來過濾候選未登錄詞,將過濾後的候選未登錄詞加入到分詞庫中。
採用MySQL資料庫,以政務事項數據為例進行說明,如圖3所示,未登錄詞的識別方法包括:
步驟302,讀取資料庫中的事項數據。
步驟304,對每一個事項,將其各個屬性值合併成一個大文本。
步驟306,對上一步生成的文本進行分詞(如全切分)、消歧、詞性標註。
步驟308,對上一步分詞結果建立左右PAT-ARRAY樹。
步驟310,提取詞頻大於等於2、長度在2至4之間的重複串作為候選未登錄詞。
步驟312,合併從每一個事項中提取的候選未登錄詞。
步驟314,計算候選未登錄詞的互信息及左右信息熵。
步驟316,過濾互信息小於6、左右信息熵小於1.5的候選未登錄詞。
步驟318,根據互信息降序排列候選未登錄詞,取前N個候選未登錄詞加入至分詞庫中,並重複步驟306至316直到新的候選未登錄詞數小於閾值為止。
以上結合附圖詳細說明了本發明的技術方案,本發明的技術方案提出了一種新的未登錄詞的識別方案,可以高效、準確地從大數據量的業務數據中提取出未登錄詞。
以上所述僅為本發明的優選實施例而已,並不用於限制本發明,對於本領域的技術人員來說,本發明可以有各種更改和變化。凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護範圍之內。