一種數據處理平臺和系統的製作方法
2023-05-11 08:15:06 3
本發明涉及數據處理技術領域,具體而言,涉及一種數據處理平臺和系統。
背景技術:
目前,隨著大數據時代的到來,大數據的存儲與查詢成為大數據領域的熱點之一。大數據就是巨量數據集合,通過分布式的方式存儲到大數據存儲系統中。大數據存儲系統會在已存儲存量數據的基礎上,對後來得到的增量數據繼續進行存儲。而對增量數據的處理可以實時動態的根據數據源的改變,對數據及時處理並將處理結果增量導入資料庫以備後續利用。
相關技術中,對增量數據進行處理時,spark集群會抽取增量數據並做同步分析和存儲,完成後spark集群將同步分析處理後的增量數據導入hbase;hbase對同步分析處理後的增量數據進行抽取,並將抽取的數據導入elasticsearch,elasticsearch建立導入的增量數據的索引,從而完成對增量數據的處理。
在實現本發明過程中,發明人發現現有技術中至少存在如下問題:
隨著時間的推移,spark集群中存儲的數據越來越多,存儲壓力越來越大。
技術實現要素:
有鑑於此,本發明實施例的目的在於提供一種數據處理平臺和系統,以減輕spark集群的存儲壓力。
第一方面,本發明實施例提供了一種數據處理平臺,包括:相互交互的spark集群、elasticsearch集群和hbase集群;
所述spark集群,用於監測資料庫產生的增量數據,對所述資料庫產生的增量數據進行處理,並把處理後的增量數據導入elasticsearch集群和hbase集群,其中,所述增量數據包括:數據類型標識;
所述hbase集群,用於存儲所述spark集群處理後的所述增量數據;
所述elasticsearch集群,用於將處理後的所述增量數據與快速查詢數據合併。
結合第一方面,本發明實施例提供了第一方面的第一種可能的實施方式,其中:所述elasticsearch集群,包括:多個elasticsearch節點;
所述多個elasticsearch節點分別與所述spark集群和所述hbase集群交互;
所述多個elasticsearch節點均用於將處理後的所述增量數據與快速查詢數據合併;
當所述多個elasticsearch節點中有elasticsearch節點出現故障時,故障elasticsearch節點獲取所述hbase集群中存儲的所述增量數據進行增量數據恢復。
結合第一方面,本發明實施例提供了第一方面的第二種可能的實施方式,其中:所述故障elasticsearch節點獲取所述hbase集群中存儲的所述增量數據進行增量數據恢復,包括:
所述故障elasticsearch節點向所述elasticsearch集群中其他elasticsearch節點發送第一增量數據恢復指令,所述第一增量數據恢復指令中攜帶有數據恢復時間段;
當在預設的恢復數據獲取時長內收到其他elasticsearch節點返回的所述數據恢復時間段內增量數據的恢復數據時,所述故障elasticsearch節點通過增量數據的恢復數據進行增量數據恢復;
當在預設的恢復數據獲取時長內未收到其他elasticsearch節點返回的所述數據恢復時間段內的增量數據恢復數據時,向所述hbase集群發送第二增量數據恢復指令,所述第二增量數據恢復指令中攜帶有數據恢復時間段和所述故障elasticsearch節點的標識;
所述故障elasticsearch節點獲取所述hbase集群返回的增量恢復數據,並通過所述增量恢復數據進行增量數據恢復。
結合第一方面,本發明實施例提供了第一方面的第三種可能的實施方式,其中:所述故障elasticsearch節點獲取所述hbase集群返回的增量恢復數據,並通過所述增量恢復數據進行增量數據恢復,包括:
所述故障elasticsearch節點獲取所述hbase集群返回的增量恢復數據,所述增量恢復數據攜帶有數據類型標識;
所述故障elasticsearch節點將所述數據恢復時間段內的增量數據刪除;
所述故障elasticsearch節點獲取預存的不同類型數據的索引文件,所述索引文件包括:索引標識;
當具有未查詢的索引標識時,所述故障elasticsearch節點根據索引文件中的索引標識,查詢出具有與所述索引標識相同的數據類型標識的增量恢復數據;
所述故障elasticsearch節點根據所述索引標識對應的索引文件,確定查詢出的增量恢復數據對應類型數據的存儲文件;
所述故障elasticsearch節點將查詢出的增量恢復數據合併到確定出的存儲文件中。
結合第一方面,本發明實施例提供了第一方面的第四種可能的實施方式,其中:當獲取到第二增量數據恢復指令時,所述hbase集群,具體用於:
查詢出所述第二增量數據恢復指令中攜帶的所述數據恢復時間段內的增量數據,將所述數據恢復時間段內的增量數據確定為所述增量恢復數據;
向所述故障elasticsearch節點的標識指示的故障elasticsearch節點返回所述增量恢復數據。
結合第一方面,本發明實施例提供了第一方面的第五種可能的實施方式,其中:所述多個elasticsearch節點均用於將處理後的所述增量數據與快速查詢數據合併,包括:
所述elasticsearch節點獲取預存的不同類型數據的索引文件,所述索引文件包括:索引標識;
當具有未查詢的索引標識時,所述elasticsearch節點根據索引文件中的索引標識,查詢出具有與所述索引標識相同的數據類型標識的增量數據;
所述elasticsearch節點根據所述索引標識對應的索引文件,確定查詢出的增量數據對應類型數據的存儲文件;
所述elasticsearch節點將查詢出的增量數據合併到確定出的存儲文件中,將處理後的所述增量數據與快速查詢數據合併。
結合第一方面,本發明實施例提供了第一方面的第六種可能的實施方式,其中:所述spark集群,監測資料庫產生的增量數據,對所述資料庫產生的增量數據進行處理包括:
監測所述資料庫產生的增量數據;
當所述資料庫產生的增量數據滿足預設的數據抽取條件時,從所述資料庫獲取增量數據;
對獲取到的所述增量數據進行提取、轉換和加載(extraction-transformation-loading,etl)處理;
針對不同的數據類型對提取、轉換和加載處理後的增量數據做簡單數據分析、數理統計和數據挖掘;
其中,所述數據抽取條件,包括以下條件中的至少一個:所述資料庫產生的增量數據數量達到預設數量閾值;所述資料庫產生的增量數據佔用的存儲空間達到預設存儲空間閾值;距離上次獲取增量數據的時長達到預設數據獲取周期。
結合第一方面,本發明實施例提供了第一方面的第七種可能的實施方式,其中:所述hbase集群,包括:多個hbase節點;
所述多個hbase節點分別與所述spark集群和所述elasticsearch集群交互;
所述多個hbase節點均用於存儲所述spark集群處理後的所述增量數據;
當所述多個hbase節點中有hbase節點出現故障時,故障hbase節點從正常工作hbase節點中獲取所述增量數據進行數據恢復操作。
第二方面,本發明實施例還提供一種數據處理系統,包括上述的數據處理平臺和資料庫;
所述數據處理平臺,包括:相互連接的spark集群、elasticsearch集群和hbase集群;
所述資料庫與所述spark集群連接;
所述資料庫,用於產生增量數據。
結合第二方面,本發明實施例提供了第二方面的第一種可能的實施方式,其中:還包括:商業智能平臺;
所述商業智能平臺,與所述spark集群連接;
所述商業智能平臺,用於獲取所述spark集群處理後的增量數據,並對所述spark集群處理後的增量數據進行商業分析。
本發明實施例提供的數據處理平臺和系統,通過數據處理平臺中的spark集群對資料庫產生的增量數據進行處理,並把處理後的增量數據導入elasticsearch集群和hbase集群,與相關技術中spark集群會存儲增量數據相比,spark集群僅對增量數據進行分析,無需對資料庫產生的增量數據進行存儲,減輕了spark集群的存儲壓力。
為使本發明的上述目的、特徵和優點能更明顯易懂,下文特舉較佳實施例,並配合所附附圖,作詳細說明如下。
附圖說明
為了更清楚地說明本發明實施例的技術方案,下面將對實施例中所需要使用的附圖作簡單地介紹,應當理解,以下附圖僅示出了本發明的某些實施例,因此不應被看作是對範圍的限定,對於本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他相關的附圖。
圖1示出了本發明實施例所提供的一種數據處理平臺和系統中,應用的伺服器的結構示意圖;
圖2示出了本發明實施例1所提供的數據處理平臺的結構示意圖;
圖3示出了本發明實施例1所提供的數據處理平臺中,對增量數據進行合併操作的流程;
圖4示出了本發明實施例2所提供的一種數據處理系統的結構示意圖。
圖標:100-spark集群;102-elasticsearch集群;104-hbase集群;200-伺服器;201-存儲器;202-處理器;203-網絡模塊;221-作業系統;222-服務模塊;400-數據處理平臺;402-資料庫;404-商業智能平臺;4000-spark集群;4002-elasticsearch集群;4004-hbase集群。
具體實施方式
為使本發明實施例的目的、技術方案和優點更加清楚,下面將結合本發明實施例中附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅僅是本發明一部分實施例,而不是全部的實施例。通常在此處附圖中描述和示出的本發明實施例的組件可以以各種不同的配置來布置和設計。因此,以下對在附圖中提供的本發明的實施例的詳細描述並非旨在限制要求保護的本發明的範圍,而是僅僅表示本發明的選定實施例。基於本發明的實施例,本領域技術人員在沒有做出創造性勞動的前提下所獲得的所有其他實施例,都屬於本發明保護的範圍。
本發明實施例所提供的數據處理平臺和系統可應用於如圖1所示的伺服器中。圖1示出了一種可應用於本發明實施例中的伺服器的結構框圖。如圖1所示,伺服器200包括:存儲器201、處理器202以及網絡模塊203。該伺服器可以用作本實施例中提到的spark節點、hbase節點、elasticsearch節點、資料庫和商業智能平臺。
存儲器201可用於存儲軟體程序以及模塊,如本發明實施例中的增量數據處理時使用的程序指令/模塊,處理器202通過運行存儲在存儲器201內的軟體程序以及模塊,從而執行各種功能應用以及數據處理,即實現本發明實施例中的數據處理方法。存儲器201可包括高速隨機存儲器,還可包括非易失性存儲器,如一個或者多個磁性存儲裝置、快閃記憶體、或者其他非易失性固態存儲器。進一步地,上述軟體程序以及模塊還可包括:作業系統221以及服務模塊222。其中作業系統221,例如可為linux、unix、windows,其可包括各種用於管理系統任務(例如內存管理、存儲設備控制、電源管理等)的軟體組件和/或驅動,並可與各種硬體或軟體組件相互通訊,從而提供其他軟體組件的運行環境。服務模塊222運行在作業系統221的基礎上,並通過作業系統221的網絡服務監聽來自網絡的請求,根據請求完成相應的數據處理,並返回處理結果給客戶端。也就是說,服務模塊222用於向客戶端提供網絡服務。
網絡模塊203用於接收以及發送網絡信號。上述網絡信號可包括無線信號或者有線信號。
可以理解,圖1所示的結構僅為示意,伺服器200還可包括比圖1中所示更多或者更少的組件,或者具有與圖1所示不同的配置。圖1中所示的各組件可以採用硬體、軟體或其組合實現。另外,本發明實施例中的伺服器還可以包括多個具體不同功能的伺服器。
在一個實現方式中,伺服器的硬體配置如下:
中央處理器cpu:
型號:xeone5-2670v3-12core;
數量:2個。
內存:
配置參數:ddr4rdimm-16gb-2133000khz-1.2v-ecc-2rank(1g*4bit);
數量:16個。
硬碟
配置參數:1200gb-sas12gb/s-10000rpm-2.5inch-熱插拔;
數量:8個。
磁碟陣列raid卡
配置參數:sr320bc1gbcache,支持-raid0,1,5,6,10,50,60-支持超級電容+850mmminisas模塊(8盤規格);
數量:1個。
目前,對增量數據進行處理時,spark集群會抽取增量數據並做同步分析和存儲,完成後spark集群將同步分析處理後的增量數據導入hbase;hbase對同步分析處理後的增量數據進行抽取,並將抽取的數據導入elasticsearch,elasticsearch建立導入的增量數據的索引,從而完成對增量數據的處理。隨著時間的推移,spark集群中存儲的數據越來越多,存儲壓力越來越大。基於此,本申請提供的一種數據處理平臺和系統。
需要注意的是,在本發明的描述中,術語「中心」、「上」、「下」、「左」、「右」、「豎直」、「水平」、「內」、「外」等指示的方位或位置關係為基於附圖所示的方位或位置關係,僅是為了便於描述本發明和簡化描述,而不是指示或暗示所指的裝置或元件必須具有特定的方位、以特定的方位構造和操作,因此不能理解為對本發明的限制。此外,術語「第一」、「第二」、「第三」僅用於描述目的,而不能理解為指示或暗示相對重要性。
另外,在本發明的描述中,除非另有明確的規定和限定,術語「安裝」、「相連」、「連接」應做廣義理解,例如,可以是固定連接,也可以是可拆卸連接,或一體地連接;可以是機械連接,也可以是電連接;可以是直接相連,也可以通過中間媒介間接相連,可以是兩個元件內部的連通。對於本領域的普通技術人員而言,可以具體情況理解上述術語在本發明中的具體含義。
實施例1
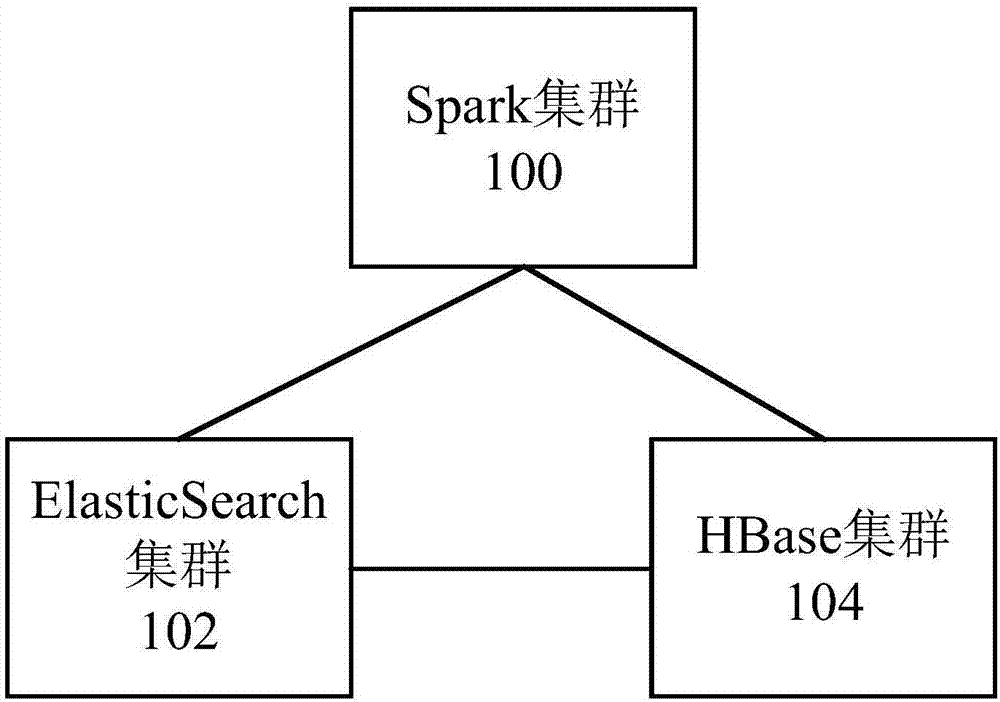
參見圖2所示的流程示意圖,本實施例提供一種數據處理平臺,包括:相互交互的spark集群100、elasticsearch集群102和hbase集群104;
上述spark集群100,用於監測資料庫產生的增量數據,對上述資料庫產生的增量數據進行處理,並把處理後的增量數據導入elasticsearch集群102和hbase集群104,其中,上述增量數據包括:數據類型標識;
上述hbase集群104,用於存儲上述spark集群100處理後的上述增量數據;
上述elasticsearch集群102,用於將處理後的上述增量數據與快速查詢數據合併。
其中,上述增量數據,是指在存量數據基礎上,符合預設的數據抽取條件的、由資料庫產生的源數據。增量數據除了具有數據類型標識和數據本身之外,還攜帶有生成時間信息。
上述數據抽取條件,包括以下條件中的至少一個:上述資料庫產生的增量數據數量達到預設數量閾值;上述資料庫產生的增量數據佔用的存儲空間達到預設存儲空間閾值;距離上次獲取增量數據的時長達到預設數據獲取周期。
源數據,是指資料庫生成的數據。
數據類型標識,用於elasticsearch集群102和hbase集群104對增量數據進行識別,從而根據數據類型標識對應的數據類型,對增量數據進行分類存儲和索引。
資料庫可以根據不同數據類型,產生針對不同類型應用或者不同應用場景的源數據。
數據類型標識,是資料庫在生成源數據時,根據所生成源數據的數據名稱進行哈希計算得到的。不同類型的源數據都具有唯一的數據名稱,所以通過哈希計算得到的數據類型標識也是唯一的。
上述hbase集群104,除了對增量數據均進行存儲外,還存儲有存量數據。上述存量數據,就是hbase集群104在獲取本次增量數據之前獲取並存儲的數據。
上述elasticsearch集群102,主要的作用是使用戶對hbase集群104中存儲的數據進行檢索。所以,elasticsearch集群102預先建立有索引文件,並存儲有與索引文件對應的快速查詢數據。從而在用戶搜索一些搜索頻率較高的數據時,無需elasticsearch集群102到hbase集群104中進行遍歷查詢,就可以在確定數據的索引文件後,根據索引文件的指示直接把存儲的快速查詢數據返回給用戶,提高了查詢效率。
在elasticsearch集群102中,一個索引文件對應一個類型的快速查詢數據。用戶可以根據應用場景的不同,在elasticsearch集群102中預先設置該應用場景下應用的不同類型數據的索引文件。而且,用戶還可以對elasticsearch集群102中設置的索引文件進行增加和刪除,使用戶可以根據自己的需求,對快速查詢數據進行更改,進一步提高了查詢效率。
上述快速查詢數據,為用戶經常搜索的數據。快速查詢數據的設置,使得elasticsearch集群102在確定用戶搜索這些數據時,無需到hbase集群104中進行遍歷查詢,根據索引文件的指示把相應的快速查詢數據返回給用戶,提高了查詢效率。
具體地,上述spark集群100,用於監測資料庫產生的增量數據,對上述資料庫產生的增量數據進行處理包括以下步驟(1)至步驟(4):
(1)監測上述資料庫產生的增量數據;
(2)當上述資料庫產生的增量數據滿足預設的數據抽取條件時,從上述資料庫獲取增量數據;
(3)對獲取到的上述增量數據進行提取、轉換和加載處理;
(4)針對實際需求對提取、轉換和加載處理後的增量數據做簡單數據分析、數理統計和數據挖掘。
其中,上述數據抽取條件,包括以下條件中的至少一個:上述資料庫產生的增量數據數量達到預設數量閾值;上述資料庫產生的增量數據佔用的存儲空間達到預設存儲空間閾值;距離上次獲取增量數據的時長達到預設數據獲取周期。
在上述步驟(2)中,上述spark集群100可以分批從資料庫獲取增量數據。
在上述步驟(3)中,上述spark集群100對獲取的增量數據進行etl處理,主要為清理增量數據中的無用信息,保證增量數據的正確性、完整性、一致性、有效性和時效性。
在上述步驟(4)中,可以採用現有任何簡單數據分析、數理統計和數據挖掘的操作對增量數據進行處理,這裡不再一一贅述。
綜上所述,本實施例提供的數據處理平臺,通過平臺中的spark集群對資料庫產生的增量數據進行處理,並把處理後的增量數據導入elasticsearch集群和hbase集群,與相關技術中spark集群會存儲增量數據相比,spark集群僅對增量數據進行分析,無需對資料庫產生的增量數據進行存儲,減輕了spark集群的存儲壓力。
相關技術中,若elasticsearch在運行過程中出現故障,由於目前的大數據存儲系統沒有對故障elasticsearch中的增量數據提供容錯和校驗機制,造成無法對故障elasticsearch中的增量數據進行恢復的問題。所以,為了對故障elasticsearch中的增量數據進行恢復,本實施例提出的數據處理平臺中的上述elasticsearch集群,包括:多個elasticsearch節點;
上述多個elasticsearch節點分別與上述spark集群和上述hbase集群交互;
上述多個elasticsearch節點均用於將處理後的上述增量數據與快速查詢數據合併;
當上述多個elasticsearch節點中有elasticsearch節點出現故障時,故障elasticsearch節點獲取上述hbase集群中存儲的上述增量數據進行增量數據恢復。
其中,多個elasticsearch節點分別用於合併以及存儲不同業務類型的增量數據。elasticsearch節點相當於數據處理平臺的快速查找機構,可以在用戶查詢時向用戶快速反饋查詢結果。
elasticsearch是一個即時的分布式查詢和分析引擎,用輕微的延遲去處理增量數據。可以實現分布式文件存儲,並將每一個欄位都編入索引,使其可以被查詢;可以實現全文搜索、結構化搜索以及實時分析;可以擴展到上百臺伺服器,處理pb級別的結構化或者非結構化數據。
具體地,上述故障elasticsearch節點獲取上述hbase集群中存儲的上述增量數據進行增量數據恢復,包括以下步驟(1)至步驟(4):
(1)上述故障elasticsearch節點向上述elasticsearch集群中其他elasticsearch節點發送第一增量數據恢復指令,上述第一增量數據恢復指令中攜帶有數據恢復時間段;
(2)當在預設的恢復數據獲取時長內收到其他elasticsearch節點返回的上述數據恢復時間段內增量數據的恢復數據時,上述故障elasticsearch節點通過增量數據的恢復數據進行增量數據恢復;
(3)當在預設的恢復數據獲取時長內未收到其他elasticsearch節點返回的上述數據恢復時間段內的增量數據恢復數據時,向上述hbase集群發送第二增量數據恢復指令,上述第二增量數據恢復指令中攜帶有數據恢復時間段和上述故障elasticsearch節點的標識;
(4)上述故障elasticsearch節點獲取上述hbase集群返回的增量恢復數據,並通過上述增量恢復數據進行增量數據恢復。
在上述步驟(1)中,數據恢復時間段包括數據恢復起始時間點和終止時間點。該數據恢復時間段由故障elasticsearch節點根據需要恢復的增量信息的生成時間信息確定。
在上述步驟(2)中,故障elasticsearch節點在獲取到其他elasticsearch節點的增量數據恢復數據時,直接通過獲取到的增量數據恢復數據對故障elasticsearch節點中需要恢復的增量數據進行更新,就可以完成增量數據恢復操作。
上述步驟(4)中,具體包括以下步驟(41)至步驟(46):
(41)上述故障elasticsearch節點獲取上述hbase集群返回的增量恢復數據,上述增量恢復數據攜帶有數據類型標識;
(42)上述故障elasticsearch節點將上述數據恢復時間段內的增量數據刪除;
(43)上述故障elasticsearch節點獲取預存的不同類型數據的索引文件,上述索引文件包括:索引標識;
(44)當具有未查詢的索引標識時,上述故障elasticsearch節點根據索引文件中的索引標識,查詢出具有與上述索引標識相同的數據類型標識的增量恢復數據;
(45)上述故障elasticsearch節點根據上述索引標識對應的索引文件,確定查詢出的增量恢復數據對應類型數據的存儲文件;
(46)上述故障elasticsearch節點將查詢出的增量恢復數據合併到確定出的存儲文件中。
在上述步驟(41)中,hbase集群返回的增量恢復數據,是由hbase集群中的任一hbase集群節點所確定的增量恢復數據。
在上述步驟(43)中,可以根據應用場景的不同,在elasticsearch集群的各個節點中設置針對不同應用場景的數據類型的索引文件。
不同類型數據的索引文件,用於預設在elasticsearch集群中,使elasticsearch集群對存儲的不同類型數據進行分類索引。
上述索引標識,由elasticsearch集群對用戶預設的數據名稱進行哈希算法得到的,存儲在索引文件中,可以用於查詢使用。
當用戶查詢時,上述elasticsearch集群執行以下具體步驟(431)至步驟(435):
(431)elasticsearch集群獲取用戶輸入的想要查詢的數據名稱;
(432)elasticsearch集群對用戶輸入的數據名稱進行哈希計算,得到數據名稱哈希值;
(433)elasticsearch集群通過數據名稱哈希值查詢出與數據名稱哈希值相同的索引標識,並得到具有該哈希值的索引文件;
(434)elasticsearch集群將該索引文件指示的存儲文件打開並取出存儲文件中的數據;
(435)elasticsearch集群將取出的數據返回給用戶。
通過以上步驟(431)至步驟(435)的描述,在索引文件設置索引標識,使得查詢的過程中可以通過查詢條件就可以確定用戶想要查詢的數據的索引文件,相當於建立了查詢條件到具體查詢內容的映射,方便用戶對數據的查詢。
在上述步驟(44)中,elasticsearch節點通過遍歷的方式,查詢出具有與上述索引標識相同的數據類型標識的增量恢復數據。
在上述步驟(46)中,elasticsearch節點採用現有的任何字符串拼接技術將查詢出的增量恢復數據合併到確定出的存儲文件中,這裡不再贅述。
相應的,當獲取到第二增量數據恢復指令時,上述hbase集群,具體執行以下步驟(1)至步驟(2):
(1)查詢出上述第二增量數據恢復指令中攜帶的上述數據恢復時間段內的增量數據,將上述數據恢復時間段內的增量數據確定為上述增量恢復數據;
(2)向上述故障elasticsearch節點的標識指示的故障elasticsearch節點返回上述增量恢復數據。
在上述步驟(1)中,上述hbase集群通過設置的協處理器調用預設的增量數據過濾器,將上述數據恢復時間段內的增量數據查詢出來。
上述步驟(1)至步驟(2),可以通過hbase集群中的任意hbase節點執行。
通過以上的描述可以看出,在elasticsearch出現故障時,數據處理平臺對故障elasticsearch中的增量數據提供容錯和校驗機制,無需spark集群再次從資料庫中獲取需要恢復的增量數據,使故障elasticsearch節點獲取hbase集群中存儲的增量數據就可以進行增量數據恢復,數據恢復效率高。
具體地,參見圖3所示的elasticsearch節點對增量數據進行合併操作的流程,多個elasticsearch節點均用於將處理後的上述增量數據與快速查詢數據合併,包括以下具體步驟:
步驟300、elasticsearch節點獲取預存的不同類型數據的索引文件,上述索引文件包括:索引標識;
步驟302、當具有未查詢的索引標識時,上述elasticsearch節點根據索引文件中的索引標識,查詢出具有與上述索引標識相同的數據類型標識的增量數據;
步驟304、上述elasticsearch節點根據上述索引標識對應的索引文件,確定查詢出的增量數據對應類型數據的存儲文件;
步驟306、上述elasticsearch節點將查詢出的增量數據合併到確定出的存儲文件中,將處理後的上述增量數據與快速查詢數據合併。
在上述步驟306中,elasticsearch節點將查詢出的增量恢復數據合併到確定出的存儲文件中的過程與上述步驟(46)類似,這裡不再贅述。
在一個實施方式中,hbase集群不僅可以對故障elasticsearch中的增量數據進行恢復,還可以對自身節點出現的故障進行數據恢復。上述hbase集群,包括:多個hbase節點;
上述多個hbase節點分別與上述spark集群和上述elasticsearch集群交互;
上述多個hbase節點均用於存儲上述spark集群處理後的上述增量數據;
當上述多個hbase節點中有hbase節點出現故障時,故障hbase節點從正常工作hbase節點中獲取上述增量數據進行數據恢復操作。
hbase節點作為高性能、列存儲、可伸縮、實時讀寫的分布式資料庫,可支持集群存儲海量數據,極大的彌補了傳統資料庫的不足。hbase節點在主鍵上建立了類b+樹索引,可以高效的實現基於主鍵的快速查詢。然而由於hbase缺少非主鍵索引能力,在接受以非主鍵查詢請求時,需要對全表進行掃描,導致查詢速度較慢,難以適應大數據時空數據存儲和高效率的增量數據插入在速度上對應的即時查詢。所以目前的大數據存儲系統,需要將hbase與elasticsearch配合使用。以體現出hbase和elasticsearch兩種不同檢索方法的優勢。
多個hbase節點均存儲上述spark集群處理後的上述增量數據的過程包括:在多個hbase節點中的每個hbase節點建表,接下來需要設計相應的rowkey從而滿足相應的業務需求。大數據平臺處理後的增量數據同一rowkey可能存在多條記錄,所以需要將相同rowkey下的數據合併後將結果flush到每個hbase節點中。
上述故障hbase節點從正常工作hbase節點中獲取上述增量數據進行數據恢復操作的過程可以採用現有的任何數據恢復方法進行數據恢復,這裡不再一一贅述。
通過以上的描述可以看出,hbase節點發生故障時,無需spark集群再次從資料庫中獲取需要恢復的增量數據,hbase其他節點可以保護數據,在保證數據安全性、容災性的同時對故障hbase節點的數據進行恢復,進一步提高了數據恢復效率。
實施例2
參見圖4,本實施例提供一種數據處理系統,包括上述實施例1中描述的數據處理平臺400和資料庫402;
上述數據處理平臺400,包括:相互交互的spark集群4000、elasticsearch集群4002和hbase集群4004;
上述資料庫402與上述spark集群4000連接;
上述資料庫402,用於產生增量數據。
在一個實施方式中,上述數據處理系統,還包括商業智能(businessintelligence,bi)平臺404;
上述bi平臺404,與上述spark集群4000連接;
上述bi平臺404,用於獲取上述spark集群4000處理後的增量數據,並對獲取到的增量數據進行商業分析。
上述bi平臺404,可以採用現有的任何使企業迅速收集、管理和分析數據,並將這些數據轉化為有用的信息,然後分發到企業各處的平臺技術,這裡不再贅述。
綜上所述,本實施例提供的數據處理系統,通過數據處理平臺中的spark集群對資料庫產生的增量數據進行處理,並把處理後的增量數據導入elasticsearch集群和hbase集群,與相關技術中spark集群會存儲增量數據相比,spark集群僅對增量數據進行分析,無需對資料庫產生的增量數據進行存儲,減輕了spark集群的存儲壓力。
以上所述,僅為本發明的具體實施方式,但本發明的保護範圍並不局限於此,任何熟悉本技術領域的技術人員在本發明揭露的技術範圍內,可輕易想到變化或替換,都應涵蓋在本發明的保護範圍之內。因此,本發明的保護範圍應所述以權利要求的保護範圍為準。