基於評論文本挖掘的產品特徵結構樹構建方法與流程
2023-05-10 18:59:25 1
本發明屬於產品質量管理領域,涉及一種基於評論文本挖掘的產品特徵結構樹構建方法。
背景技術:
:
產品的質量安全問題是當今社會的永恆課題,它不僅包含產品的本質安全,也包含了產品的使用安全。產品的質量安全問題不僅影響消費者的權益(生命、財產、健康等),也會給製造企業帶來巨大的經濟損失,關係到製造企業的生存和發展。運用科學的、高效的管理方法和手段,儘早發現各種潛在的產品質量安全問題,通過技術創新和技術突破,對產品存在的問題進行改進和提升,提高產品在市場上的競爭力和影響力。
隨著網際網路技術的發展與普及,網絡正逐漸改變著人們的生活和表達方式。由於不同的用戶有不同的質量、安全需求,也可能在不同的環境、工況、負載下,產品在使用過程中會暴露出很多意料之外的質量安全問題,用戶通常會選擇藉助網絡平臺進行交流,發表使用評價信息。這些用戶的評價信息蘊含著豐富的、有價值的信息。製造企業如果能夠快速、有效地從中提取反映產品質量的信息,將會為改進、完善產品開發設計提供重要的依據,提高用戶的滿意度,增強企業的市場競爭力,同時,也會降低由於產品質量問題造成事故給企業帶來的經濟損失。
然而,由於網際網路的開放性,用戶對產品質量安全的評價信息具有多源、異構的特點,面對紛繁複雜的海量網絡評論數據,亟需一種機製做正確的監測,科學地分析各種潛在的質量問題,建立完善的質量安全監管技術體系,從而有效規避產品質量安全問題給企業帶來的經濟、信譽等損失,增強制造企業應對產品質量安全風險的能力。
技術實現要素:
:
為了能快速、有效地從多源異構的海量產品質量安全信息中提取產品特徵,且對其進行產品特徵結構樹構建、定量描述、結構樹擴展等操作,本發明提供了一種基於評論文本挖掘的產品特徵結構樹構建方法,是一種高效的、便捷的產品質量管理的方法,也是對傳統產品質量管理方法的一種擴充。
本發明解決其技術問題所採用的技術方案如下述內容:
基於評論文本挖掘的產品特徵結構樹構建方法,其特徵在於:該方法包括下述步驟:
步驟1,語料庫獲取:利用網絡爬蟲軟體,制定爬取規則,抓取與指定產品相關的電商網站以及論壇上的用戶評論文本進行預處理並以結構化形式保存到資料庫中;
步驟2,產品特徵提取:2.1利用分詞器對語料庫進行分詞及詞性標註,從初次分詞結果中通過新詞發現方法,識別領域新詞,添加到用戶詞典中,再基於用戶詞典對語料庫進行優化分詞;2.2將優化分詞結果進行詞性標註集轉換,用中文自然語言處理工具包對轉換後的優化分詞結果進行依存關係分析;2.3用整理的情感詞詞典對依存關係分析結果中的支配詞進行標註,得到以詞語為基本記錄單元的結構化數據;2.4將情感分析的結果分為訓練集和測試集,制定條件隨機場特徵模板,利用開源工具包,對已經標註產品特徵的訓練集進行訓練,生成條件隨機場模型,再利用該模型對測試集進行產品特徵標註,並對測試結果進行評測;2.5從語料庫中將標記的產品特徵提取出來;
步驟3,產品特徵結構樹的構建:3.1定義產品特徵的類型,構建特徵類型的層次結構;3.2對於每個產品特徵,定位它在優化分詞結果中的位置,對於位置的前面的信息,統計在同一條評論語句中、且是第一個能與產品特徵表匹配的、不是本產品特徵的產品特徵出現的頻數,將匹配的非本產品特徵、非本產品特徵的類型、非本產品特徵頻數統計結果保存到結果數組中;對於位置的後面的信息,與位置前面的信息處理結果相同;3.3對結果數組中的信息按照出現的頻數從大到小進行排序,基於特徵類型的層次結構,在結果數組中尋找本產品特徵的類型的上層類型,則對應的非本產品特徵就是尋找的關聯特徵;3.4遍歷產品特徵結構樹,當不存在本產品特徵時,將本產品特徵-關係-關聯特徵這個分支保存到分支數組中;當存在本產品特徵時,先判斷產品特徵樹中是否存在該分支,當不存在該分支時,將關聯特徵作為本產品特徵的子節點,添加到產品特徵結構樹中;否則,不變;3.5將分支數組中的本產品特徵與產品特徵結構樹中的節點進行匹配,當存在時,將該分支添加到樹中對應節點上,並刪除分支數組中的該分支,整理數組;否則,不變;
步驟4,產品特徵的定量分析:4.1統計優化分詞結果中所有產品特徵出現的頻數;4.2基於產品特徵結構樹和已統計的產品特徵頻數,統計產品特徵中部件特徵的頻數;4.3分析句法分析結果中產品特徵的支配詞和上下文,查找情感詞、程度副詞和否定詞語素,計算產品特徵的情感得分;4.4可視化產品特徵頻數的統計結果和情感得分,分析用戶對產品的關注點;
步驟5,產品特徵結構樹的擴展:5.1對同義子節點的擴展,通過定量計算特徵相似度的方法,計算新產生的產品特徵與產品特徵結構樹中的節點之間的相似度,來確定新產品特徵的父節點,並將其添加到產品特徵結構樹中;5.2對隸屬子節點的擴展,通過定量計算特徵相關度的方法,計算新產生的產品特徵與產品特徵結構樹中的節點之間的相關度,來確定新產品特徵的父節點,並將其添加到產品特徵結構樹中。
在上述的基於評論文本挖掘的產品特徵結構樹構建方法中,在所述的步驟1中,對保存到本地資料庫的原始評論文本進行預處理,其中預處理包括刪除冗餘評論文本,刪除無中文的評論文本,刪除重複標點,修改錯別字等操作。
在上述的基於評論文本挖掘的產品特徵結構樹構建方法中,在所述的步驟2中,對初次分詞結果通過新詞發現方法,識別領域新詞,其中新詞發現方法包括構造重複串、頻率過濾、內聚性過濾和左右熵過濾操作。其中,構造重複串操作是以初始分詞結果為基礎,利用N-Gram模型(N表示重複串的最大長度,由用戶設定),對初始分詞結果進行詞頻統計、過濾、構造操作;頻率過濾操作是將構造的重複串中頻率低於設定值的部分過濾掉;內聚性過濾操作是將頻率過濾後的重複串計算內聚性,過濾掉內聚性低於閾值的部分;左右熵過濾操作是計算內聚性過濾後的重複串的左熵和右熵,若某一個熵值低於閾值,則將其過濾掉。
在上述的基於評論文本挖掘的產品特徵結構樹構建方法中,在所述的步驟2中,訓練集是對從情感分析結果裡隨機抽取的實驗語料中出現的產品特徵進行人工標註。訓練集的欄位共六列,按順序排列分別是:詞形、詞性、依存關係、支配詞、支配詞的情感判斷、人工標註的產品特徵標記。其中,產品特徵的標註符號集為{B,I,L,O,U},它們分別表示產品特徵開頭(B),產品特徵內部(I),產品特徵結尾(L),非產品特徵(O)和單個產品特徵(U)。
在上述的基於評論文本挖掘的產品特徵結構樹構建方法中,在所述的步驟2中,條件隨機場特徵模板的制定,採用的模板類型是Unigram Template,特徵模板分為兩類,為詞形特徵對應的特徵模板(原子型)和依存關係特徵、支配詞特徵、支配詞的情感判斷特徵對應的特徵模板(複合型)。
在上述的基於評論文本挖掘的產品特徵結構樹構建方法中,在所述的步驟3中,產品特徵可分為五大類,分別表示「產品的整體」、「產品的部件」、「產品的屬性」、「產品的功用」和「產品的問題」,相應地,我們將其命名為產品特徵、部件特徵、屬性特徵、功用特徵、問題特徵。從產品的角度來看,這五類詞語之間是存在聯繫的。在特徵結構樹中,用四種關係符描述五類產品特徵之間的語義關係,分別是part-of、use-of、attribute-of和problem-of。另外,結合產品特徵可能存在多個同義詞的實際情況,再定義一種關係符equal-to表示描述同義產品特徵之間的關係。產品特徵是從產品特徵表中選取的,產品特徵表是由產品特徵和產品特徵類型組成的。
在上述的基於評論文本挖掘的產品特徵結構樹構建方法中,在所述的步驟4中,計算產品特徵中部件特徵的頻數是基於產品特徵結構樹,從葉子節點往根節點的方向計算的;除葉子節點外,部件特徵的頻數計算公式為:
Sum部件=Sum同義+μ×(Sum屬性+Sum功用+Sum問題)
其中,Sum部件表示部件特徵的頻數;Sum同義表示子節點上與部件特徵之間是equal-to關係的產品特徵頻數之和;Sum屬性、Sum功用、Sum問題分別表示子節點上與部件特徵之間是use-of、attribute-of、problem-of關係的產品特徵頻數之和;μ表示隸屬節點的轉換率,範圍為[0,1]。以柱狀圖的形式將產品特徵頻數統計結果進行可視化。
在上述的基於評論文本挖掘的產品特徵結構樹構建方法中,在所述的步驟4中,用戶的褒貶態度可以用詞語的情感傾向表達;情感詞典中詞語來源於網際網路,人工挑選了網絡中常用的情感詞。經過情感極性判斷,將情感詞分為三類:褒義、中性、貶義,並對其進行情感強度定義。
在上述的基於評論文本挖掘的產品特徵結構樹構建方法中,在所述的步驟4中,1)如果一個產品特徵在一條評論中出現多次,則只討論情感強度最大的情感詞;2)不同極性的情感詞,產品特徵情感得分的計算方法是不同的;3)在計算一條用戶評論中的產品特徵的情感得分時,根據情感詞極性的不同分為三種情況:
第一種情況:修飾產品特徵的是褒義情感詞,情感得分為情感詞的情感強度;
第二種情況:修飾產品特徵的是貶義情感詞,情感得分為情感詞的情感強度的負值;
第三種情況:修飾產品特徵的是中性情感詞,情感得分的計算採用結合上下文語境的方法:以本條評論中所有情感詞的情感強度均值作為該產品特徵的情感得分。
在上述的基於評論文本挖掘的產品特徵結構樹構建方法中,在所述的步驟4中,程度副詞會影響情感詞的情感強度;程度副詞詞典是基於知網的程度級別詞語集,從中選取了部分詞語,並另外加入了一些網絡評論中常出現的程度副詞。人工地對程度副詞詞典中的詞語進行強度定義。當某個產品特徵的支配詞是情感詞,且情感詞的前面3個詞語中存在程度副詞時,該產品特徵的情感得分變為情感得分和程度副詞強度的乘積;否則,情感得分不變。
在上述的基於評論文本挖掘的產品特徵結構樹構建方法中,在所述的步驟4中,否定詞詞典中詞語來源於評論文本數據和網絡中常用的否定詞;在計算某條評論中產品特徵的情感得分時,當句子表達的是否定的意思時,僅依靠情感詞典往往會得到相反的結果,所以需要考慮句子中存在的否定詞。當某個產品特徵的支配詞是情感詞,且情感詞的前面4個詞語中存在否定詞時,該產品特徵的情感得分變為情感得分的負值;否則,情感得分不變。
在上述的基於評論文本挖掘的產品特徵結構樹構建方法中,在所述的步驟4中,產品特徵情感得分計算方法如下:
從語料庫中提取的產品特徵組成了特徵集合{fw1,fw2,...,fwn},對於每個產品特徵fwi,定義了一個產品特徵的情感得分Sco(fwi),範圍為[0,100],Sco(fwi)分值越高,說明用戶對該產品特徵的評價越高,Sco(fwi)的計算公式為:
其中,a、b、c分別表示修飾產品特徵fwi的情感詞為褒義、貶義、中性情感詞的評論條數,ScoP(fwi)、ScoN(fwi)、ScoM(fwi)分別是計算褒義、貶義、中性情感詞得到的情感得分,它們的計算公式如下:
其中,PW(k)表示第k條評論中修飾產品特徵fwi的褒義情感詞,Str(i,PW(k))表示產品特徵fwi的第k個褒義情感詞的情感強度;NW(k)表示第k條評論中修飾產品特徵fwi的貶義情感詞,Str(i,NW(k))表示產品特徵fwi的第k個貶義情感詞的情感強度;p(k)、n(k)分別表示在修飾產品特徵的情感詞為中性的第k條評論中,褒義情感詞的個數和貶義情感詞的個數,PW(k,j)表示在修飾產品特徵的情感詞為中性的第k條評論中的第j個褒義情感詞,NW(k,t)表示在修飾產品特徵的情感詞為中性的第k條評論中的第t個褒義情感詞。
在上述的基於評論文本挖掘的產品特徵結構樹構建方法中,在所述的步驟5中,採用基於字面相似度的詞語相似性算法和基於語境的詞語相似性算法,計算兩個產品特徵之間的相似性。
在上述的基於評論文本挖掘的產品特徵結構樹構建方法中,在所述的步驟5中,基於字面相似度的詞語相似性算法受數量因素和位置因素影響,其中,數量因素指兩個詞語之間含有相同漢字的個數,位置因素指相同漢字在各個詞語中的位置權重。字面相似度的相似性計算方法如下:
假設A和B表示需要計算相似度的兩個產品特徵,A和B之間的字面相似度記為SimWord(A,B),且0≤SimWord(A,B)≤1。則SimWord(A,B)的計算公式為:
其中,α和β分別表示數值因素相似度和位置因素相似度在整個詞語相似度中所佔的權重係數,且α+β=1;dp表示為兩個產品特徵的漢字個數之比,且Weight(A,i)表示A中第i個漢字的權重,且|A|和|B|分別表示特徵A和特徵B所包含的漢字個數;A(i)表示A中的第i個漢字;SameHZ(A,B)表示特徵A和B中共同包含的相同漢字的集合,|SameHZ(A,B)|表示SameHZ(A,B)集合的大小,即特徵A和B中共同包含的相同漢字的個數。
在上述的基於評論文本挖掘的產品特徵結構樹構建方法中,在所述的步驟5中,基於語境的詞語相似度計算方法如下:產品特徵Featurei用一個n維的向量表示為Featurei=(Si1,Si2,...,Sij,...,Sin),其中,Sij是Featurei與常用情感詞組中的第j個情感詞的共現頻率。將詞語相似度計算轉化為向量的相似度計算,兩個向量之間的相似度用夾角餘弦來衡量,計算公式為
在上述的基於評論文本挖掘的產品特徵結構樹構建方法中,在所述的步驟5中,通過計算新產生的產品特徵與產品結構樹中特徵的相關度來確定新特徵的父節點,相關度的計算公式為:
其中,Fab表示產品特徵Featurea和Featureb的共現頻數,Fa和Fb表示每個產品特徵單獨出現的頻數。
本發明可以獲取海量與指定產品相關的、多源異構的網絡評論文本,經過淺層和深層的中文文本信息處理技術,提取產品特徵;對提取的產品特徵進行構建特徵結構樹、定量描述、產品特徵結構樹擴展等。利用本發明的方法,製造企業可以快速、有效的了解用戶使用產品過程中對產品各個方面的評價,可以有效減少及預防產品質量安全事件對製造企業帶來的經濟損失,全面提高製造企業對潛在的產品質量安全危害的主動管理能力,提高企業在市場中的競爭力。
附圖說明:
圖1是本發明的整體流程圖。
圖2是本發明的語料庫獲取流程圖。
圖3是本發明的產品特徵提取技術路線圖。
圖4是本發明的產品特徵提取的數據表欄位變化圖。
圖5是本發明的產品特徵提取的評測結果圖。
圖6是本發明的產品特徵類型的層次結構圖。
圖7是本發明的產品特徵結構樹構建原理圖。
圖8是本發明的產品特徵結構樹構建示例流程圖。
圖9是本發明的部分產品特徵結構樹示例圖。
圖10是本發明在不同大小窗口的情況下,否定詞識別的實驗測評結果。
圖11是本發明的產品特徵情感得分計算流程圖。
圖12是本發明的部分產品特徵分布的定量描述柱狀圖。
圖13是本發明的部分產品特徵分析的定量描述柱狀圖。
具體實施方式:
下面結合具體附圖對本發明作進一步的說明。
本發明是對多源異構的海量用戶評論文本進行中文文本信息處理,提取產品特徵,且對提取的特徵進行一系列分析操作,挖掘評論文本中蘊含的有價值的信息,提高製造企業的市場競爭力。
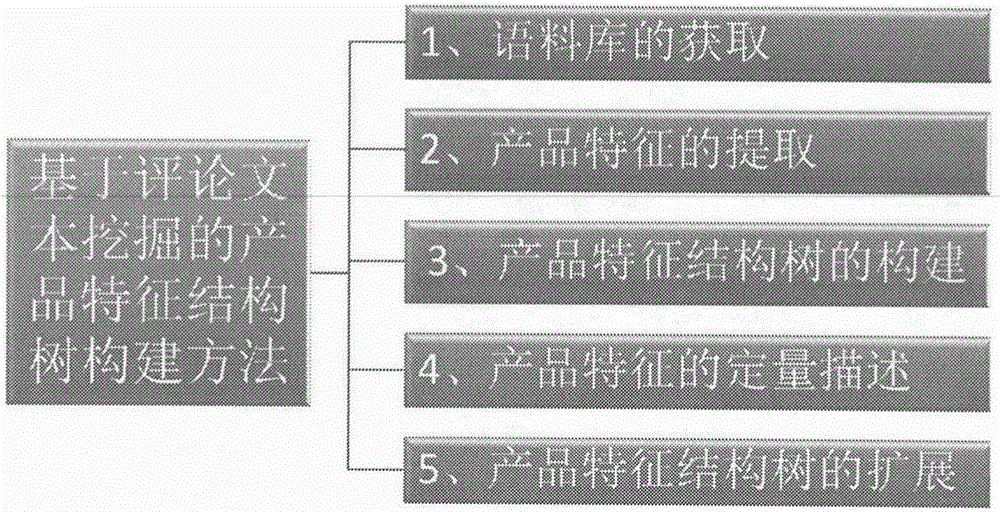
基於評論文本挖掘的產品特徵結構樹構建方法,包括語料庫的獲取、產品特徵的提取、產品特徵結構樹的構建、產品特徵的定量分析和產品特徵結構樹的擴展五個方面,如圖1所示。下面分別對這各個步驟進行詳細的說明。
步驟1,語料庫的獲取:利用網絡爬蟲軟體,制定爬取規則,抓取與指定產品相關的電商網站以及論壇上的用戶評論文本,並對原始評論文本進行預處理,以結構化形式保存到資料庫中。
語料庫獲取的流程如圖2所示。制定網絡爬蟲的爬取規則,抓取相關的電商網站、論壇等平臺,獲得原始評論文本並存儲到本地資料庫中,對原始評論文本進行刪除冗餘評論文本,刪除無中文的評論文本,刪除重複標點,修改錯別字等的預處理操作,得到語料庫。
步驟2,產品特徵的提取:2.1利用分詞器對語料庫進行初次分詞及詞性標註,從初次分詞結果中通過新詞發現方法,識別領域新詞,並將其添加到用戶詞典中,再基於用戶詞典對語料庫進行優化分詞;2.2將優化分詞結果進行詞性標註集轉換,用中文自然語言處理工具包對轉換後的優化分詞結果進行依存關係分析;2.3用整理的情感詞詞典對依存關係分析結果中的支配詞進行標註,得到以詞語為基本記錄單元的結構化數據;2.4將情感分析的結果分為訓練集和測試集,制定條件隨機場特徵模板,利用開源工具包,對已經標註產品特徵的訓練集進行訓練,生成條件隨機場模型,再利用該模型對測試集進行產品特徵標註,並對測試結果進行評測;2.5從語料庫中將標記的產品特徵提取出來。
本發明提供了從多源異構的海量評論文本語料庫中快速、高效提取產品特徵的方法,方法的技術流程圖如圖3所示。對語料庫依次進行分詞及詞性標註(初次分詞、識別領域新詞和優化分詞操作)、句法分析(詞性標註集轉換和依存關係轉換操作)、情感分析(情感詞標註)、產品特徵標註(條件隨機場模型訓練和利用模型處理數據)和產品特徵提取等操作,各操作步驟結束後資料庫表的欄位變化如圖4所示,具體分析各個操作步驟如下:
分詞及詞性標註操作是現代自然語言處理工作的基礎。隨著社會的發展,出現了很多新詞,未更新的分詞器就不能識別詞語,一般要將它分開成為2個詞,這使得分詞結果不能滿足實驗的要求。為了解決這個問題,我們引入新詞發現技術,在對語料庫通過分詞器進行初次分詞後(評論記錄被分成一個一個的詞語記錄,表格欄位共2列,分別是詞形和詞性),對初次分詞結果進行構造重複串、頻率過濾、內聚性過濾和左右熵過濾等四步操作,識別出部分領域新詞,再通過人工刪選、詞性標註,將新詞添加到用戶詞典中;用擴充的用戶詞典,再對語料庫進行優化分詞(基於用戶詞典,評論記錄被分成詞語記錄,表格欄位也是詞形和詞性這2列),從而提高分詞的準確率。
由於分詞器與中文自然語言處理工具包使用的詞性標註集不同,在進行依存關係分析之前,要先對經過詞性標註的語料庫進行詞性標註集轉換,為接下來的操作做準備工作。中科院的分詞器採用教育部語用所詞性標記集(共計99個,22個一類,66個二類,11個三類),而中文自然語言處理工具包採用863詞性標註集,共劃分出28種詞性。根據人工整理的一套標註集的轉換規則進行轉換,使詞性符合實驗要求。
依存句法分析認為:句子中的述語動詞或形容詞是句子的核心詞,它不受其它任何詞語的支配,而除核心詞之外的所有詞語都受另一個詞語的支配,這種支配用詞與詞之間的依存關係來表示。一個依存關係連接兩個詞,其中一個是支配詞,另一個是從屬詞,依存關係的類型表明了支配詞與從屬詞之間的依存關係類型。依存句法分析可以反映出句子各成分之間的語義修飾關係,可以獲得長距離的搭配信息,並與句子成分的物理位置無關。依存關係對產品特徵的識別起到了一定的幫助作用。此時表格的欄位共4列,分別是詞形、詞性、依存關係和支配詞。
通過人工整理的情感詞典對依存關係分析結果中的支配詞進行情感標註,判斷該支配詞是否是情感詞,當是情感詞時,則將它標記為「Y」,反之則標記為「N」。此時表格的欄位共5列,分別是詞形、詞性、依存關係、支配詞和支配詞的情感判斷。
將情感分析結果隨機抽取一些記錄成為訓練集,則剩餘記錄為測試集。對訓練集進行人工標註產品特徵,利用訓練集訓練出條件隨機場模型,再利用模型對測試集進行特徵標記,然後刪選、提取出產品特徵。訓練集的欄位共6列,分別是詞形、詞性、依存關係、支配詞、支配詞的情感判斷和人工標註的產品特徵標記,其中產品特徵的標註符號集為{B,I,L,O,U},它們分別表示產品特徵開頭(B),產品特徵內部(I),產品特徵結尾(L),非產品特徵(O),單個產品特徵(U)。利用條件隨機場開源工具包進行訓練,訓練出Model文件,對測試集進行特徵標註。而測試集的欄位共7列,分別是詞形、詞性、依存關係、支配詞、支配詞的情感判斷、電腦程式自動標註的產品特徵標記和訓練出的模型標註的產品特徵標記。
為了對產品特徵的提取效果進行測評,採用了三個最常用的測評指標:準確率(P)、召回率(R)和F指標。一般情況下,準確率和召回率是相互制約的,提高準確率的同時會使召回率降低,反之亦然,所以只用準確率和召回率這兩個測評指標無法綜合衡量產品產品特徵的提取效果,還需要使用兩者的調和均值:F指標。三個指標的公式如下:
其中,N1表示在測試語料中,人工標記為產品特徵的詞語總個數;N2表示在測試語料中,模型標記為產品特徵的詞語總個數;N3表示在測試語料中,人工標記和模型標記均為產品特徵,且標記符號相同的詞語總個數,也就是說,人工標記和模型標記必須同時是B、I、L、U中的一種,如果人工標記為B,而模型標記為U,則不計入N3。圖5就是通過PER測評工具對使用了CRF++進行產品特徵提取資料庫進行的效果測評結果圖。
步驟3,產品特徵結構樹的構建:3.1定義產品特徵的類型,構建特徵類型的層次結構;3.2對於每個產品特徵,定位它在優化分詞結果中的位置,對於位置的前面的信息,統計在同一條評論語句中、且是第一個能與產品特徵表匹配的、不是本產品特徵的產品特徵出現的頻數,將匹配的非本產品特徵、非本產品特徵的類型、非本產品特徵頻數統計結果保存到結果數組中;對於位置的後面的信息,與位置前面的信息處理結果相同;3.3對結果數組中的信息按照出現的頻數從大到小進行排序,基於特徵類型的層次結構,在結果數組中尋找本產品特徵的類型的上層類型,則對應的非本產品特徵就是尋找的關聯特徵;3.4遍歷產品特徵結構樹,當不存在本產品特徵時,將本產品特徵-關係-關聯特徵這個分支保存到分支數組中;當存在本產品特徵時,先判斷產品特徵樹中是否存在該分支,當不存在該分支時,將關聯特徵作為本產品特徵的子節點,添加到產品特徵結構樹中;否則,不變;3.5將分支數組中的本產品特徵與產品特徵結構樹中的節點進行匹配,當存在時,將該分支添加到樹中對應節點上,並刪除分支數組中的該分支,整理數組;否則,不變。
如圖6所示,產品特徵分為產品特徵、部件特徵、屬性特徵、功用特徵、問題特徵五大類;在特徵結構樹中,用五種關係符描述各類產品特徵之間的語義關係,分別是part-of、attribute-of、use-of、problem-of和equal-to。下面對每種關係符的含義和適用範圍進行說明:
(1)part-of:如「A part-of B」,表示B是A的部件特徵,其中B是部件產品特徵,A是部件產品特徵或產品產品特徵;
(2)attribute-of:如「A attribute-of B」,表示A是B的屬性特徵,其中A是屬性產品特徵,B是部件產品特徵或產品產品特徵;
(3)use-of:如「A use-of B」,表示A是B的功用特徵,其中A是功用產品特徵,B是部件產品特徵或產品產品特徵;
(4)problem-of:如「A problem-of B」,表示A是B的問題特徵,其中A是問題產品特徵,B是部件產品特徵或產品產品特徵;
(5)equal-to,如「A equal-to B」,表示A是B的同義詞。
圖7是產品特徵結構樹構造的原理圖,概括地描述就是在優化分詞結果中找到每個產品特徵的關聯特徵,並保存到特徵結構樹資料庫表中。如圖7所示,遍歷分詞結果,定位產品特徵的位置,找到與產品特徵A在同一條評論中、在A的位置前面、且是第一個非A的產品特徵Ai,統計各個Ai出現的頻數,將Ai、Ai的類型、Ai的頻數保存到list結構中;找到與產品特徵A在同一條評論中、在A的位置後面、且是第一個非A的產品特徵Ai,統計各個Ai出現的頻數,將Ai、Ai的類型、Ai的頻數保存到list結構中;遍歷完優化分詞結果後,Ai按出現的頻數從大到小的順序進行排序,根據特徵類型層次結構和產品特徵A的類型T,從排序結果中找到第一個T的上一層類型T1,則該T1所對應的產品特徵A1就是產品特徵A的關聯特徵;根據產品特徵A、A和A1之間的關係relation、關聯特徵A1組成結構樹的分支,判斷特徵結構樹是否存在產品特徵A,當不存在時,將A-relation-A1分支保存到分支數組中;當存在時,判斷特徵結構樹是否存在該分支,當不存在時,將A1添加到A的子節點上;當存在時,不變;再次遍歷特徵結構樹和分支數組,判斷分支數組中的產品特徵A是否能與產品特徵結構樹上的節點匹配,當能匹配時,將匹配的分支添加到結構樹上,刪除分支數組中的該條記錄;當不匹配時,則不變。
圖8是以產品特徵之一的「屏幕」為例說明尋找關聯特徵步驟的流程圖,使我們能詳細的了解每個步驟的執行。如圖8所示,尋找關聯特徵步驟如下:從featureword表(存放產品特徵的表)中取出產品特徵---屏幕和它的類型---部件,對total_fenci表(存放優化分詞結果的表)進行遍歷,定位屏幕在total_fenci表中的位置---第j條評論的第k位置,在第j條評論中,從第k-1位置開始往前尋找第一個產品特徵Af,遍歷featureword表,找到Af的類型lx,將Af存到data的list中,當data中存在Af時,則將頻數結果+1;當data中不存在Af時,將Af、lx和1保存到data中;從第k+1位置開始往後的操作與往前操作相同;然後,判斷第j條評論中是否還有存在屏幕,當存在時,操作與前一個屏幕的操作相同;當不存在時,則判斷優化分詞結果是否遍歷完,當沒有遍歷完時,繼續向下遍歷,定位下一個屏幕的位置;當遍歷完時,將data中的信息按Af出現的頻數從大到小排序;接著,遍歷data,當出現Af的類型lx為產品名時,lx對應的Af就是屏幕的關聯特徵。
圖9是部分產品特徵結構樹的示例圖,反映了資料庫表中記錄的存儲形式,為接下來的產品特徵定量分析和特徵結構樹的擴展提供研究對象,特徵結構樹的節點表示產品特徵,枝幹方向是從根節點到葉子節點,枝幹表示兩個節點之間的關係。
步驟4,產品特徵的定量分析:4.1統計優化分詞結果中所有產品特徵出現的頻數;4.2基於產品特徵結構樹和已統計的產品特徵頻數,統計產品特徵中部件特徵的頻數;4.3分析句法分析結果中產品特徵的支配詞和上下文,查找情感詞、程度副詞和否定詞語素,計算產品特徵的情感得分;4.4可視化產品特徵頻數的統計結果和情感得分,分析用戶對產品的關注點。
在提取句子中的否定詞時,我們以情感詞為中心,在其情感詞的前面查找否定詞,當找到否定詞時,情感詞的極性取反;否則,不變。查找範圍是由以情感詞為中心的檢測窗口決定。為了確定窗口的大小,我們選取了評論數據中一定數量的帶有否定詞的用戶評論作為實驗語料,進行了六組不同大小窗口的否定詞識別實驗,實驗結果用準確率(P)、召回率(R)和F值進行測評,其中,準確率(P)、召回率(R)和F值的計算方法如下:
其中,F1表示測試集中存在的否定句總數,F2表示程序識別出的否定句總數,F3表示程序正確識別的否定句總數。
如圖10所示,根據測試結果,我們可以發現準確率(P)隨著窗口的增大而減小,召回率(R)隨著窗口的增大而變大,當窗口大小為4時,綜合指標F值最大,所以最佳窗口的大小為4。由此,我們設定查找情感詞的否定詞是在情感詞位置的上面四個詞語的範圍內。同理,我們可以通過實驗知道程度副詞的最佳窗口是3,所以設置查找情感詞的程度副詞是在情感詞位置的上面三個詞語的範圍內。
圖11是產品特徵情感得分的計算流程圖。如圖11所示,從Featurewordtree表(保存產品特徵結構樹節點信息的表)中取一個節點A,對jufafenxi表(保存句法分析結果的表)進行遍歷,定位A在句法分析中的位置,尋找A相應的支配詞Z;判斷Z是否是情感詞,當Z不是情感詞時,定位下一個A的位置,重複上述步驟;當Z是情感詞時,遍歷情感詞詞典,獲得Z的類型和情感強度S,判斷Z的類型,當Z的類型是P(褒義)時,Z的情感強度就是S;當Z的類型是N(貶義)時,Z的情感強度就是-S;當Z的類型是P(中性)時,Z的情感強度就是A所在評論的全部情感詞的情感強度的算術平均數;在A所在位置的後面且在一條評論中尋找離A最近的情感詞Q,判斷Q的前面三個詞語是否有程度副詞D,當有程度副詞D時,遍歷程度副詞表獲得D的強度SD,則產品特徵A的情感得分S變為SD×S;當沒有程度副詞D時,不變;接著判斷Q的前面四個詞語是否有否定詞N,當有否定詞N時,產品特徵A的情感得分S變為-S;當不存在否定詞N時,不變;然後,判斷該條評論中是否還存在A,當存在時,計算出A的情感強度Si,比較各個Si的大小,取最大的S作為產品特徵A的情感得分;當不存在時,則不執行操作;接著,將情感得分S存到Featurewordtree表中相對應的位置,判斷jufafenxi表是否已經遍歷完,當沒遍歷完時,重複以上步驟;當遍歷完時,判斷是否遍歷完Featurewordtree表,當遍歷完時,結束程序;當沒有遍歷完時,從Featurewordtree表中取下一個產品特徵,重複上述步驟,直到遍歷完Featurewordtree表。
圖12是產品特徵的定量描述的結果,我們將之進行可視化,讓我們直觀地了解各種統計結果。柱狀圖的橫坐標表示產品特徵,縱坐標表示產品特徵出現的頻數,在每個柱形條上顯示了產品特徵對應的頻數結果。圖13是產品特徵分析的定量描述,柱狀圖的橫坐標表示產品特徵,縱坐標表示產品特徵的情感得分,在每個柱形條上顯示了產品特徵對應的情感得分計算結果。
步驟5,產品特徵結構樹的擴展:5.1對同義子節點的擴展,通過定量計算特徵相似度的方法,計算新產生的產品特徵與產品特徵結構樹中的節點之間的相似度,來確定新產品特徵的父節點,並將其添加到產品特徵結構樹中;5.2對隸屬子節點的擴展,通過定量計算特徵相關度的方法,計算新產生的產品特徵與產品特徵結構樹中的節點之間的相關度,來確定新產品特徵的父節點,並將其添加到產品特徵結構樹中。
在評論數據更新時,會產生新的產品特徵,這時候需要對產品特徵結構樹進行擴展。特徵結構樹的擴展分為兩類,一類是基於詞語相似性的同義子節點擴展,同義子節點指與父節點詞義相同的產品特徵,所以新加入的產品特徵與其父節點的語義關係為equal-to,另一類是基於詞語相關性的隸屬子節點擴展,隸屬子節點指與父節點是上下位關係的產品特徵,隸屬子節點與其父節點的語義關係為part-of、attribute-of、use-of和problem-of中的一種,具體的取值由產品特徵的種類確定。
本發明能夠利用爬蟲軟體抓取網絡上與指定產品相關的用戶評論數據,並從中發現蘊含著的有價值的產品信息,改進產品的設計,使得產品更符合人機關係。利用本發明的方法,製造企業可以快速、有效地了解用戶反饋的使用產品信息,有助於進行用戶與企業之間的對話,幫助企業進行產品設計的改進。