一種Hadoop資料庫HBase的查詢方法及裝置與流程
2023-05-02 19:32:56 6
本發明涉及資料庫領域,特別涉及一種Hadoop資料庫HBase的查詢方法及裝置。
背景技術:
HBase(Hadoop Database,Hadoop資料庫)是一個開源、分布式、面向列存儲、可伸縮的非關係資料庫,HBase構建在HDFS(Hadoop Distributed File System,Hadoop分布式文件系統)之上,用於對海量數據隨機、實時的訪問。HBase採用RPC(Remote Procedure Call Protocol,遠程過程調用協議)機製作為主要通信手段。客戶端Client通過RPC機制與HMaster(Hadoop Master,Hadoop管理器)和HRegionServer(Hadoop Region Server,Hadoop地區伺服器)進行通信以發送操作請求。HMaster響應管理類的操作,HRegionServer響應數據的讀寫操作。
現有HBase的查詢方法採用基於單請求隊列CallQueue的優先級調度策略,作業隊列維護開銷大。當有新作業到達時,需要對整個隊列重新排序,增加了等待作業隊列的維護開銷。而嚴格地按優先級次序來完成作業調度,還可能導致低優先級的作業長期得不到執行,使得整個HBase集群的服務質量無法保證。且未考慮如何為高優先級用戶提供更優質的服務體驗。
現有HBase的查詢方法主要針對單一應用、用戶的詳單查詢業務。當多個用戶同時使用HBase做詳單查詢時,無法靈活地根據用戶身份、優先級,來分配合適的查詢資源,無法實現雲計算形態的大數據服務。
技術實現要素:
本發明要解決的技術問題是提供一種Hadoop資料庫HBase的查詢方法及裝置,解決現有技術中HBase的查詢方法無法保證整體用戶的體驗,不能為 高優先級用戶提供更優質服務,無法實現雲計算形體的大數據服務的問題。
為解決上述技術問題,本發明的實施例提供一種Hadoop資料庫HBase的查詢方法,包括:
接收用戶的查詢請求,並將所述查詢請求反序列化成Call查詢作業;
獲取所述Call查詢作業所歸屬用戶的用戶優先級;
根據預先設置的用戶優先級和查詢優先級的對應關係,將所述Call查詢作業放到多個請求隊列CallQueue中的一個請求隊列CallQueue中,其中每個請求隊列CallQueue具有一個查詢優先級,不同請求隊列CallQueue之間的查詢優先級不同;
根據所述請求隊列CallQueue的查詢優先級,處理所述請求隊列CallQueue中的Call查詢作業,得到查詢結果;以及
將所述查詢結果返回給用戶。
其中,所述查詢方法還包括:
建立一個資源跟蹤線程,監聽每個請求隊列CallQueue的隊列信息,並根據所述隊列信息對所述請求隊列CallQueue進行動態資源調度。
其中,所述隊列信息包括負載數量和平均響應時延,所述動態資源包括請求隊列CallQueue的隊列資源;
相應地,所述建立一個資源跟蹤線程,監聽每個請求隊列CallQueue的隊列信息,並根據所述隊列信息對所述請求隊列CallQueue進行動態資源調度,具體包括:
建立一個資源跟蹤線程,監聽每個請求隊列CallQueue的負載數量和平均響應時延;
根據所述負載數量和所述平均響應時延,對所述請求隊列CallQueue的隊列資源進行調度。
其中,所述根據所述負載數量和所述平均響應時延,對所述請求隊列CallQueue的隊列資源進行調度,具體包括:
根據所述負載數量和所述平均響應時延,從多個請求隊列CallQueue中,獲取負載數量小於隊列資源限定的最大門限值,且平均響應時延大於預設閾值的請求隊列CallQueue的空閒隊列資源;
將所述空閒隊列資源分配給負載數量大於隊列資源限定的最大門限值或平均響應時延小於預設閾值的請求隊列CallQueue。
其中,每個請求隊列CallQueue預先配置有不同的處理線程資源,所述隊列信息包括Call查詢作業數量和平均響應時延,所述動態資源包括請求隊列CallQueue的處理線程資源;
相應地,建立一個資源跟蹤線程,監聽每個請求隊列CallQueue的隊列信息,並根據所述隊列信息對所述請求隊列CallQueue進行動態資源調度,具體包括:
建立一個資源跟蹤線程,監聽每個請求隊列CallQueue的Call查詢作業數量和平均響應時延;
根據所述Call查詢作業數量和所述平均響應時延,對所述請求隊列CallQueue的處理線程資源進行調度。
其中,所述根據所述Call查詢作業數量和所述平均響應時延,對所述請求隊列CallQueue的處理線程資源進行調度,具體包括:
根據所述Call查詢作業數量和所述平均響應時延,從多個請求隊列CallQueue中,獲取Call查詢作業數量小於處理線程資源具有的線程數量,且平均響應時延大於預設閾值的請求隊列CallQueue的空閒處理線程資源;
將所述空閒處理線程資源分配給Call查詢作業數量大於處理線程資源具有的線程數量或平均響應時延小於預設閾值的請求隊列CallQueue。
其中,所述獲取所述Call查詢作業所歸屬用戶的用戶優先級,具體為:
根據所述Call查詢作業的網絡互聯協議IP位址,獲取所述Call查詢作業所歸屬用戶的用戶優先級。
為解決上述技術問題,本發明的實施例還提供一種Hadoop資料庫HBase的查詢裝置,包括:
接收模塊,用於接收用戶的查詢請求,並將所述查詢請求反序列化成Call查詢作業;
獲取模塊,用於獲取所述Call查詢作業所歸屬用戶的用戶優先級;
存放模塊,用於根據預先設置的用戶優先級和查詢優先級的對應關係,將所述Call查詢作業放到多個請求隊列CallQueue中的一個請求隊列CallQueue 中,其中每個請求隊列CallQueue具有一個查詢優先級,不同請求隊列CallQueue之間的查詢優先級不同;
處理模塊,用於根據所述請求隊列CallQueue的查詢優先級,處理所述請求隊列CallQueue中的Call查詢作業,得到查詢結果;以及
返回模塊,用於將所述查詢結果返回給用戶。
其中,所述查詢裝置還包括:
調度模塊,用於建立一個資源跟蹤線程,監聽每個請求隊列CallQueue的隊列信息,並根據所述隊列信息對所述請求隊列CallQueue進行動態資源調度。
其中,所述隊列信息包括負載數量和平均響應時延,所述動態資源包括請求隊列CallQueue的隊列資源;
相應地,所述調度模塊具體包括:
第一監聽模塊,用於建立一個資源跟蹤線程,監聽每個請求隊列CallQueue的負載數量和平均響應時延;
第一調度子模塊,用於根據所述負載數量和所述平均響應時延,對所述請求隊列CallQueue的隊列資源進行調度。
其中,每個請求隊列CallQueue預先配置有不同的處理線程資源,所述隊列信息包括Call查詢作業數量和平均響應時延,所述動態資源包括請求隊列CallQueue的處理線程資源;
相應地,所述調度模塊具體包括:
第二監聽模塊,用於建立一個資源跟蹤線程,監聽每個請求隊列CallQueue的Call查詢作業數量和平均響應時延;
第二調度子模塊,用於根據所述Call查詢作業數量和所述平均響應時延,對所述請求隊列CallQueue的處理線程資源進行調度。
其中,所述獲取模塊進一步用於根據所述Call查詢作業的網絡互聯協議IP位址,獲取所述Call查詢作業所歸屬用戶的用戶優先級。
本發明的上述技術方案的有益效果如下:
在本發明實施例中,首先將接收的用戶的查詢請求反序列化成Call查詢作業;然後獲取Call查詢作業所歸屬用戶的用戶優先級;再根據預先設置的用戶優先級和查詢優先級的對應關係,將Call查詢作業放到多個請求隊列 CallQueue中的一個請求隊列CallQueue中,其中每個請求隊列CallQueue具有一個查詢優先級,不同請求隊列CallQueue之間的查詢優先級不同;然後根據請求隊列CallQueue的查詢優先級,處理請求隊列CallQueue中的Call查詢作業,得到查詢結果;最後將查詢結果返回給用戶。通過採用多請求隊列CallQueue調度,使不同優先級的用戶查詢請求享有不同的查詢資源,在保證整體用戶體驗的同時,為高優先級用戶提供了更優質的服務體驗,實現了雲計算形態的大數據服務。
附圖說明
圖1為本發明實施例的Hadoop資料庫HBase的查詢方法流程圖;
圖2為本發明實施例的Hadoop資料庫HBase的查詢方法一具體實現系統的第一結構示意圖;
圖3為本發明實施例的Hadoop資料庫HBase的查詢方法一具體實現系統的第二結構示意圖;
圖4為本發明實施例的Hadoop資料庫HBase的查詢方法應用一具體實現系統的流程圖;
圖5為本發明實施例的Hadoop資料庫HBase的查詢裝置的結構示意圖。
具體實施方式
為使本發明要解決的技術問題、技術方案和優點更加清楚,下面將結合附圖及具體實施例進行詳細描述。
本發明實施例的Hadoop資料庫HBase的查詢方法,在保證整體用戶體驗的同時,為高優先級用戶提供了更優質的服務體驗。
如圖1所示,本發明實施例的Hadoop資料庫HBase的查詢方法,包括:
步驟11,接收用戶的查詢請求,並將所述查詢請求反序列化成Call查詢作業。
步驟12,獲取所述Call查詢作業所歸屬用戶的用戶優先級。
步驟13,根據預先設置的用戶優先級和查詢優先級的對應關係,將所述Call查詢作業放到多個請求隊列CallQueue中的一個請求隊列CallQueue中, 其中每個請求隊列CallQueue具有一個查詢優先級,不同請求隊列CallQueue之間的查詢優先級不同。
這裡,用戶優先級和查詢優先級按照優先級別一一對應,如最高用戶優先級對應最高查詢優先級,最低用戶優先級對應最低用戶優先級。且每個請求隊列CallQueue根據查詢優先級的不同享有不同規格的查詢資源,如具有最高查詢優先級的請求隊列CallQueue享有最高規格的查詢資源,具有最低查詢優先級的請求隊列CallQueue享有最低規格的查詢資源。
步驟14,根據所述請求隊列CallQueue的查詢優先級,處理所述請求隊列CallQueue中的Call查詢作業,得到查詢結果;以及
步驟15,將所述查詢結果返回給用戶。
本發明實施例的Hadoop資料庫HBase的查詢方法,通過採用多請求隊列CallQueue調度,可靈活地根據用戶優先級,來分配合適的查詢資源,使不同優先級的用戶查詢請求享有不同規格的查詢資源,從而最終控制不同優先級用戶的查詢請求的響應時延有差異。在保證整體用戶體驗的同時,為高優先級用戶提供了更優質的服務體驗,實現了雲計算形態的大數據服務。
為了使多個請求隊列CallQueue都保持較高的運行效率,從而保證整體用戶的體驗,本發明的具體實施例中,所述查詢方法還可以包括:
步驟16,建立一個資源跟蹤線程,監聽每個請求隊列CallQueue的隊列信息,並根據所述隊列信息對所述請求隊列CallQueue進行動態資源調度。
當然可以理解的是,步驟16可以是針對上述步驟13中所提及的請求隊列CallQueue進行動態資源調度。
此時,通過對請求隊列CallQueue進行動態資源調度,實現了多個請求隊列CallQueue之間的動態資源平衡,使多個請求隊列CallQueue都能保持在較高的運行效率,保證了整體用戶的體驗。
這裡,可將監聽到的隊列信息存入日誌文件中,方便讀取和使用。
其中,所述隊列信息可包括負載數量和平均響應時延,所述動態資源可包括請求隊列CallQueue的隊列資源;
相應地,上述步驟16具體可以包括:
步驟161,建立一個資源跟蹤線程,監聽每個請求隊列CallQueue的負載 數量和平均響應時延;
步驟162,根據所述負載數量和所述平均響應時延,對所述請求隊列CallQueue的隊列資源進行調度。
此時,通過監聽請求隊列CallQueue的負載數量和平均響應時延,以對請求隊列CallQueue的隊列資源進行調度,可使負載較重的請求隊列CallQueue也具有充足的隊列資源。保證了負載較重的請求隊列CallQueue的運行效率,避免了負載過重的請求隊列CallQueue運行效率過慢,影響用戶體驗的問題,從而有效提高了整體用戶的體驗。
進一步的,上述步驟162具體可以包括:
步驟1621,根據所述負載數量和所述平均響應時延,從多個請求隊列CallQueue中,獲取負載數量小於隊列資源限定的最大門限值,且平均響應時延大於預設閾值的請求隊列CallQueue的空閒隊列資源。
這裡,由於享有不同規格查詢資源的請求隊列CallQueue要求的響應時延也不同,因此可預先根據查詢優先級設定每個請求隊列CallQueue要求的平均響應時延的閾值,以根據該閾值判斷請求隊列CallQueue的平均響應時延是否滿足對應查詢優先級的要求。從而保證不同優先級用戶的用戶體驗。
這裡,若某個請求隊列CallQueue的負載數量小於隊列資源限定的最大門限值,且平均響應時延大於預設閾值,則該請求隊列CallQueue具有多餘的隊列資源,且滿足自身查詢優先級的要求。
步驟1622,將所述空閒隊列資源分配給負載數量大於隊列資源限定的最大門限值或平均響應時延小於預設閾值的請求隊列CallQueue。
這裡,若某個請求隊列CallQueue的負載數量大於隊列資源限定的最大門限值,且平均響應時延小於預設閾值,則該請求隊列CallQueue的負載較重,隊列資源不夠用,且無法滿足自身查詢優先級的要求。
此時,通過將獲取的空閒隊列資源給負載較重的請求隊列CallQueue。保證了負載較重的請求隊列CallQueue的運行效率,避免了負載過重的請求隊列CallQueue運行效率過慢,影響用戶體驗的問題,從而有效提高了整體用戶的體驗。
其中,每個請求隊列CallQueue預先配置有不同的處理線程資源,所述隊 列信息可包括Call查詢作業數量和平均響應時延,所述動態資源可包括請求隊列CallQueue的處理線程資源;
相應地,上述步驟16具體可以包括:
步驟163,建立一個資源跟蹤線程,監聽每個請求隊列CallQueue的Call查詢作業數量和平均響應時延;
步驟164,根據所述Call查詢作業數量和所述平均響應時延,對所述請求隊列CallQueue的處理線程資源進行調度。
此時,通過監聽請求隊列CallQueue的Call查詢作業數量和平均響應時延,以對請求隊列CallQueue的處理線程資源進行調度,可使具有較多Call查詢作業數量的請求隊列CallQueue具有充足的處理線程資源,從而保證了每個請求隊列CallQueue查詢作業的順利進行,進而保證了用戶體驗。
進一步的,上述步驟164具體可以包括:
步驟1641,根據所述Call查詢作業數量和所述平均響應時延,從多個請求隊列CallQueue中,獲取Call查詢作業數量小於處理線程資源具有的線程數量,且平均響應時延大於預設閾值的請求隊列CallQueue的空閒處理線程資源。
步驟1642,將所述空閒處理線程資源分配給Call查詢作業數量大於處理線程資源具有的線程數量或平均響應時延小於預設閾值的請求隊列CallQueue。
此時,通過將獲取的空閒處理線程資源分配給Call查詢作業數量較多的請求隊列CallQueue,保證了Call查詢作業數量較多的請求隊列CallQueue查詢處理的順利進行,從而保證了處理效率和用戶體驗。
優選的,上述步驟1642之後,若所述空閒處理線程資源所在的請求隊列CallQueue的Call查詢作業數量增加到大於自身處理線程資源具有的線程數量,則收回所述空閒處理線程資源到該請求隊列CallQueue。
本發明的具體實施例中,上述步驟12具體可為:
步驟121,根據所述Call查詢作業的網絡互聯協議IP位址,獲取所述Call查詢作業所歸屬用戶的用戶優先級。
此時,通過Call查詢作業的IP位址可準確獲取到Call查詢作業所歸屬的用戶,進而獲取到Call查詢作業所歸屬用戶的用戶優先級,提高了操作的準確性和處理效率。
下面對本發明的一具體實現實施例舉例說明如下。
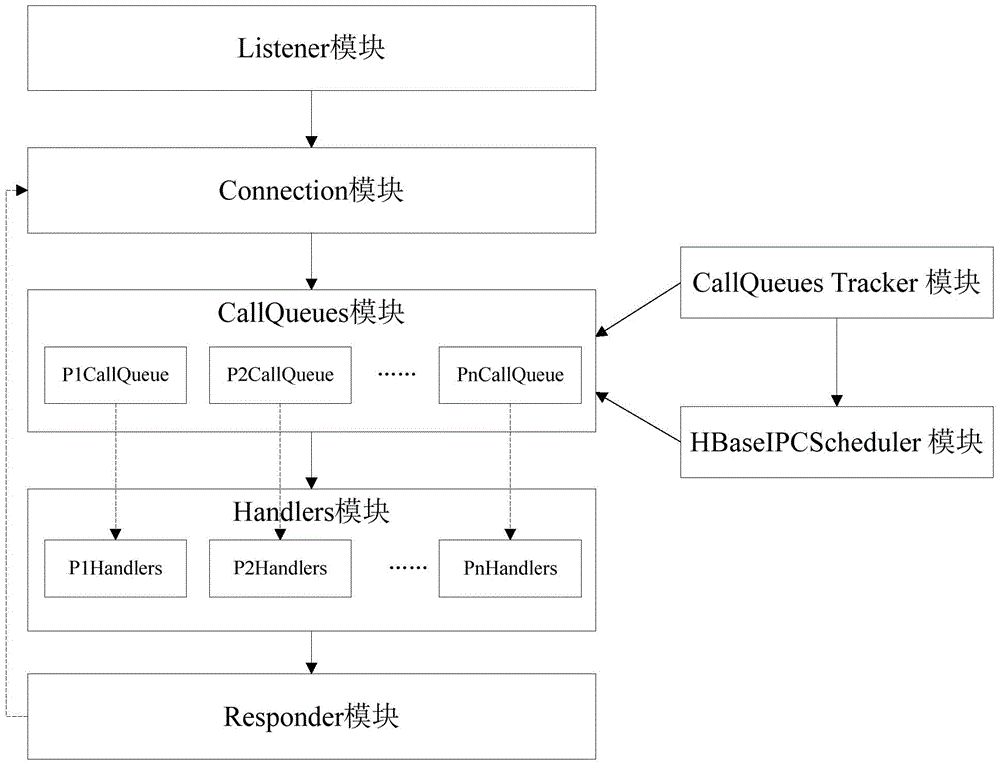
如圖2-3所示,本發明實施例的Hadoop資料庫HBase的查詢方法可通過接聽Listener模塊、連接Connection模塊、CallQueues模塊、處理Handlers模塊、請求隊列監聽CallQueues Tracker模塊、Hadoop進程間通信調度HBaseIPCScheduler模塊和應答Responder模塊實現。
其中,上述步驟11可通過接聽Listener模塊來實現。Listener模塊包括多個子線程讀取Reader模塊和一個主線程Listener模塊。主線程Listener模塊負責接收用戶的查詢請求。子線程Reader模塊負責連接具體的查詢操作,將查詢請求反序列化成Call查詢作業。
其中,上述步驟12和步驟13可通過連接Connection模塊實現。具體的,Connection模塊從Listener模塊中讀出Call查詢作業,並根據Call查詢作業的IP位址獲取所歸屬用戶的用戶優先級,最後根據預先設置的用戶優先級和查詢優先級的對應關係,將Call查詢作業放到多個請求隊列CallQueue中的一個請求隊列CallQueue中。
這裡,多個請求隊列CallQueue可通過CallQueues模塊進行管理,且請求隊列CallQueue的數量可由HBase資料庫的管理員進行設置。由於用戶優先級與請求隊列CallQueue的查詢優先級一一對應,所以管理員通過設置用戶優先級的數量n,便可決定請求隊列CallQueue的數量。如用戶優先級的數量為n個,則請求隊列CallQueue的數量也為n個:P1CallQueue、P2CallQueue、…、PnCallQueue,其中n為大於或等於1的整數。
進一步的,上述步驟14可通過處理Handlers模塊實現。其中處理Handlers模塊包括多個與請求隊列CallQueue相對應的Handlers單元,每個Handlers單元根據對應請求隊列CallQueue的查詢優先級,處理該請求隊列CallQueue中的Call查詢作業。
如請求隊列CallQueue包括:P1CallQueue、P2CallQueue、…、PnCallQueue,則Handlers模塊包括:P1Handlers、P2Handlers、…、PnHandlers。且P1Handlers處理P1CallQueue隊列中的查詢作業,P1Handlers處理P1CallQueue隊列中的查詢作業,PnHandlers處理PnCallQueue隊列中的查詢作業。如圖3所示,假定n為3,則請求隊列CallQueue的數量為3個:P1CallQueue、P2CallQueue、 P3CallQueue,且Handlers模塊包括:P1Handlers、P2Handlers、P3Handlers。
這裡,每個請求隊列CallQueue預先配置有不同的處理線程資源,該處理線程資源即Handlers單元根據請求隊列CallQueue的查詢優先級,預先分配的處理線程資源。其中,所有Handlers單元的處理線程資源總和不能超過Handlers模塊具有的總資源:P1Handlers+P2Handlers+…+PnHandlers≤hbase.regionserver.handler.count。
其中,上述步驟16可通過請求隊列監聽CallQueues Tracker模塊、Hadoop進程間通信調度HBaseIPCScheduler模塊實現。
CallQueues Tracker模塊新建一個資源跟蹤線程,實時對每個請求隊列CallQueue的負載數量、Call查詢作業數量和平均響應時延等進行統計,並將統計結果存入日誌文件,作為動態資源調度的依據。
HBaseIPCScheduler模塊根據負載數量、Call查詢作業數量和平均響應時延,對請求隊列CallQueue進行動態資源調度。這裡,HBaseIPCScheduler模塊的調度策略可參照容量調度器Yarn的模型實現,對不同優先級用戶採用不同的策略,保證高優先級用戶查詢作業先執行,對低優先級用戶查詢作業兼顧公平性。
具體的,HBaseIPCScheduler模塊在根據負載數量和平均響應時延,判斷某個請求隊列CallQueue具有空閒隊列資源時,可將空閒隊列資源動態分配給負載較重的請求隊列CallQueue,以保證負載較重的請求隊列CallQueue的處理效率。HBaseIPCScheduler模塊在根據Call查詢作業數量和平均響應時延,判斷某個請求隊列CallQueue的處理Handlers具有空閒處理線程資源時,可將處理線程資源動態分配給Call查詢作業數量較多的請求隊列CallQueue,以保證請求隊列CallQueue查詢處理的順利進行,提高了處理效率,保證了整體用戶的體驗。也可在空閒處理線程資源所在的請求隊列CallQueue的Call查詢作業數量增加時,收回該空閒處理線程資源。
如當請求隊列P1CallQueue中待處理的Call查詢作業數量小於P1Handlers具有的線程數量,且平均響應時延大於預設閾值時,則可將多餘的處理線程資源分配給負載較重的P2CallQueue或P3CallQueue使用。當P1CallQueue負載增加時,則收回分出的處理線程資源,用於處理P1CallQueue的作業。
進一步的,上述步驟15可通過應答Responder模塊實現,Responder模塊將查詢結果返回給用戶。
如圖4所示,應用如圖2所示的系統,本發明實施例的Hadoop資料庫HBase的查詢方法,包括:
步驟S01,配置參數:用戶優先級的數量n、Handlers模塊具有的總資源(hbase.regionserver.handler.count)、每個請求隊列CallQueue(P1CallQueue、P2CallQueue、…、PnCallQueue)對應的Handlers單元(P1Handlers、P2Handlers、…、PnHandlers)的處理線程資源等。例如:n=3、hbase.regionserver.handler.count=100,P1Handlers=50、P2Handlers=30、P3Handlers=20。然後根據配置參數,初始化CallQueues模塊和Handlers模塊。
步驟S02,Listener模塊接收用戶的查詢請求,將查詢請求反序列化成Call查詢作業。
步驟S03,Connection模塊從Listener模塊中讀出Call查詢作業,根據Call查詢作業的IP位址獲取所歸屬用戶的用戶優先級,並根據用戶優先級與查詢優先級的對應關係,將Call查詢作業放入對應的CallQueue隊列中。
步驟S04,CallQueueTrackers模塊新建資源跟蹤線程,定時對每個請求隊列CallQueue的負載數量、Call查詢作業數量、平均響應時間等進行統計,將結果存入日誌文件,並反饋給HBaseIPCScheduler模塊,作為動態調整資源的依據。
步驟S05,HBaseIPCScheduler模塊根據負載數量、Call查詢作業數量和平均響應時間對多個請求隊列CallQueue進行調度。
步驟S06,Handlers模塊執行相應請求隊列CallQueue的查詢作業,將查詢結果返回給Responder模塊。
步驟S07,Responder模塊將查詢結果返回給用戶。
本發明實施例的Hadoop資料庫HBase的查詢方法,通過採用多請求隊列CallQueue調度,可靈活地根據用戶優先級,來分配合適的查詢資源,使不同優先級的用戶查詢請求享有不同規格的查詢資源,從而最終控制不同優先級用戶的查詢請求的響應時延有差異。為高優先級用戶提供了更優質的服務體驗,實現了雲計算形態的大數據服務。且使多個請求隊列CallQueue都保持在較高 的運行效率,有效保證了整體用戶的體驗。
現有技術中,HRegionServer端的RPC通信被實現為一個反應器Reactor模式的請求/響應隊列模型。所有的查詢請求在HRegionServer端被解碼後放入請求隊列CallQueue,交給處理器Handler線程池處理,Handler線程池不斷地從請求隊列CallQueue裡取得查詢請求,交給HRegionServer執行查詢,並將執行結果以響應隊列ResponseQueue形式,依次返回給查詢客戶端。
現有HBase的查詢方法採用基於單請求隊列CallQueue的優先級調度策略,無法保證整體用戶的體驗,不能為高優先級用戶提供更優質服務,無法實現雲計算形體的大數據服務。
本發明實施例的Hadoop資料庫HBase的查詢方法,解決了現有技術的不足,在保證整體用戶體驗的同時,為高優先級用戶提供了更優質的服務體驗,實現了雲計算形態的大數據服務。
如圖5所示,本發明的實施例還提供了一種Hadoop資料庫HBase的查詢裝置,包括:
接收模塊,用於接收用戶的查詢請求,並將所述查詢請求反序列化成Call查詢作業;
獲取模塊,用於獲取所述Call查詢作業所歸屬用戶的用戶優先級;
存放模塊,用於根據預先設置的用戶優先級和查詢優先級的對應關係,將所述Call查詢作業放到多個請求隊列CallQueue中的一個請求隊列CallQueue中,其中每個請求隊列CallQueue具有一個查詢優先級,不同請求隊列CallQueue之間的查詢優先級不同;
處理模塊,用於根據所述請求隊列CallQueue的查詢優先級,處理所述請求隊列CallQueue中的Call查詢作業,得到查詢結果;以及
返回模塊,用於將所述查詢結果返回給用戶。
本發明實施例的Hadoop資料庫HBase的查詢裝置,通過採用多請求隊列CallQueue調度,可靈活地根據用戶優先級,來分配合適的查詢資源,使不同優先級的用戶查詢請求享有不同規格的查詢資源,從而最終控制不同優先級用戶的查詢請求的響應時延有差異。在保證整體用戶體驗的同時,為高優先級用戶提供了更優質的服務體驗,實現了雲計算形態的大數據服務。
本發明的具體實施例中,所述查詢裝置還包括:
調度模塊,用於建立一個資源跟蹤線程,監聽每個請求隊列CallQueue的隊列信息,並根據所述隊列信息對所述請求隊列CallQueue進行動態資源調度。
其中,所述隊列信息包括負載數量和平均響應時延,所述動態資源包括請求隊列CallQueue的隊列資源;
相應地,所述調度模塊具體包括:
第一監聽模塊,用於建立一個資源跟蹤線程,監聽每個請求隊列CallQueue的負載數量和平均響應時延;
第一調度子模塊,用於根據所述負載數量和所述平均響應時延,對所述請求隊列CallQueue的隊列資源進行調度。
進一步的,所述第一調度子模塊包括:
第二獲取模塊,用於根據所述負載數量和所述平均響應時延,從多個請求隊列CallQueue中,獲取負載數量小於隊列資源限定的最大門限值,且平均響應時延大於預設閾值的請求隊列CallQueue的空閒隊列資源;
第一分配模塊,用於將所述空閒隊列資源分配給負載數量大於隊列資源限定的最大門限值或平均響應時延小於預設閾值的請求隊列CallQueue。
其中,每個請求隊列CallQueue預先配置有不同的處理線程資源,所述隊列信息包括Call查詢作業數量和平均響應時延,所述動態資源包括請求隊列CallQueue的處理線程資源;
相應地,所述調度模塊具體包括:
第二監聽模塊,用於建立一個資源跟蹤線程,監聽每個請求隊列CallQueue的Call查詢作業數量和平均響應時延;
第二調度子模塊,用於根據所述Call查詢作業數量和所述平均響應時延,對所述請求隊列CallQueue的處理線程資源進行調度。
進一步的,所述第二調度子模塊包括:
第三獲取模塊,用於根據所述Call查詢作業數量和所述平均響應時延,從多個請求隊列CallQueue中,獲取Call查詢作業數量小於處理線程資源具有的線程數量,且平均響應時延大於預設閾值的請求隊列CallQueue的空閒處理線程資源;
第二分配模塊,用於將所述空閒處理線程資源分配給Call查詢作業數量大於處理線程資源具有的線程數量或平均響應時延小於預設閾值的請求隊列CallQueue。
其中,所述獲取模塊進一步用於根據所述Call查詢作業的網絡互聯協議IP位址,獲取所述Call查詢作業所歸屬用戶的用戶優先級。
下面對本發明的一具體實現實施例舉例說明如下。
如圖2-3所示,上述接收模塊可通過Listener模塊實現,上述獲取和存放可通過Connection模塊實現,上述處理模塊可通過Handlers模塊實現,上述調度模塊可通過請求隊列監聽CallQueues Tracker模塊和Hadoop進程間通信調度HBaseIPCScheduler模塊實現,上述返回模塊可通過Responder模塊實現。
本發明實施例的Hadoop資料庫HBase的查詢方法,通過採用多請求隊列CallQueue調度,可靈活地根據用戶優先級,來分配合適的查詢資源,使不同優先級的用戶查詢請求享有不同規格的查詢資源,從而最終控制不同優先級用戶的查詢請求的響應時延有差異。為高優先級用戶提供了更優質的服務體驗,實現了雲計算形態的大數據服務。且使多個請求隊列CallQueue都保持在較高的運行效率,有效保證了整體用戶的體驗。
本發明實施例的Hadoop資料庫HBase的查詢裝置,解決了現有技術的不足,在保證整體用戶體驗的同時,為高優先級用戶提供了更優質的服務體驗,實現了雲計算形態的大數據服務。
需要說明的是,該實現Hadoop資料庫HBase的查詢裝置是與上述Hadoop資料庫HBase的查詢方法相對應的裝置,其中上述方法實施例中所有實現方式均適用於該裝置的實施例中,也能達到同樣的技術效果。
以上所述是本發明的優選實施方式,應當指出,對於本技術領域的普通技術人員來說,在不脫離本發明所述原理的前提下,還可以作出若干改進和潤飾,這些改進和潤飾也應視為本發明的保護範圍。