數據處理的方法和裝置與流程
2023-08-07 13:02:51 3
本發明涉及數據處理技術領域,特別涉及一種數據處理的方法和裝置。
背景技術:
隨著網際網路的發展,信息成爆炸式增長,需要處理的數據量也隨之驟增。並且這些數據對應的特徵維數高,甚至達到上億級別,直接處理運算開銷極大,因此,如何有效地對高維數的數據進行處理是迫切需要解決的問題。MapReduce是一種分布式編程模型,用於大規模數據集的並行運算,如大於1TB的數據集的並行運算。首先,Map映射函數對雜亂無章的原始數據進行特徵提取得到key-value鍵值對,然後經過MapReduce框架的Shuffle階段得到歸納好的數據集合,最後由Reduce化簡函數對數據集合進行並行處理得到最終結果。其中,Reduce函數每次處理的所有鍵值對均共享同一個鍵。但是,上述處理過程中,MapReduce框架需要歸納處理的鍵值對數量相當大,運算開銷大,耗時長,極大地影響數據處理速度。
技術實現要素:
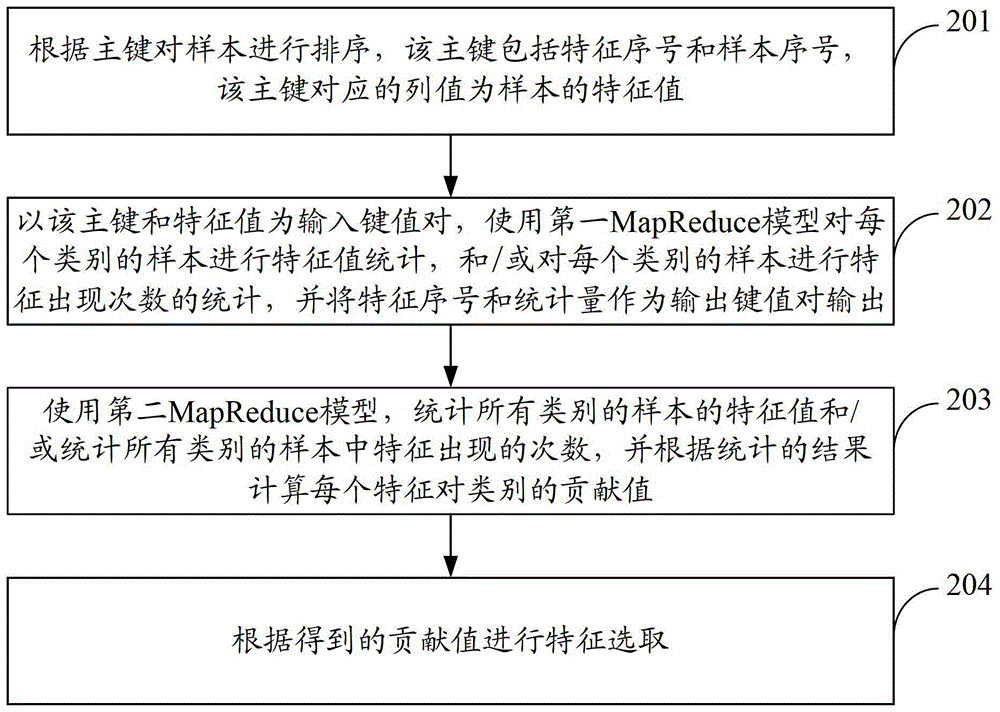
為了提高數據的處理速度,本發明實施例提供了一種數據處理的方法和裝置。所述技術方案如下:一方面,提供了一種數據處理的方法,包括:根據主鍵對樣本進行排序,所述主鍵包括特徵序號和樣本序號,所述主鍵對應的列值為樣本的特徵值;以所述主鍵和特徵值為輸入鍵值對,使用第一算法模型計算得到每個類別中的每個特徵的統計量,並將特徵序號和統計量作為輸出鍵值對輸出;使用第二算法模型對所述輸出鍵值對進行計算,得到每個特徵對類別的貢獻值,根據所述貢獻值進行特徵選取。另一方面,提供了一種數據處理的裝置,包括:排序模塊,用於根據主鍵對樣本進行排序,所述主鍵包括特徵序號和樣本序號,所述主鍵對應的列值為樣本的特徵值;第一處理模塊,用於以所述主鍵和特徵值為輸入鍵值對,使用第一算法模型計算得到每個類別中的每個特徵的統計量,並將特徵序號和統計量作為輸出鍵值對輸出;第二處理模塊,用於使用第二算法模型對所述輸出鍵值對進行計算,得到每個特徵對類別的貢獻值,根據所述貢獻值進行特徵選取。本發明提供的技術方案帶來的有益效果是:通過根據主鍵對樣本進行排序,以主鍵和對應的特徵值為輸入鍵值對,使用第一算法模型計算得到每個類別中的每個特徵的統計量,並將特徵序號和統計量作為輸出鍵值對輸出;使用第二算法模型對所述輸出鍵值對進行計算,得到每個特徵對類別的貢獻值,根據所述貢獻值進行特徵選取,極大地提高了數據的處理速度,縮短了數據的處理時間,降低了運算開銷,通過兩次算法模型計算,實現了快速特徵選擇。附圖說明為了更清楚地說明本發明實施例中的技術方案,下面將對實施例描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對於本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。圖1是本發明實施例1提供的數據處理的方法流程圖;圖2是本發明實施例2提供的數據處理的方法流程圖;圖3是本發明實施例2提供的MapReduce模型處理過程示意圖;圖4是本發明實施例3提供的數據處理的裝置結構圖之一;圖5是本發明實施例3提供的數據處理的裝置結構圖之二;圖6是本發明實施例3提供的數據處理的裝置結構圖之三。具體實施方式為使本發明的目的、技術方案和優點更加清楚,下面將結合附圖對本發明實施方式作進一步地詳細描述。實施例1參見圖1,本實施例提供了一種數據處理的方法,包括:101:根據主鍵對樣本進行排序,該主鍵包括特徵序號和樣本序號,該主鍵對應的列值為樣本的特徵值;102:以該主鍵和特徵值為輸入鍵值對,使用第一算法模型計算得到每個類別中的每個特徵的統計量,並將特徵序號和統計量作為輸出鍵值對輸出;103:使用第二算法模型對該輸出鍵值對進行計算,得到每個特徵對類別的貢獻值,根據該貢獻值進行特徵選取。本實施例中,所述主鍵是指存儲所述樣本的分布式資料庫中一個列或者列的組合,該列或列的組合的值能夠唯一地標識資料庫的表中的一行。主鍵與對應的列值也可以看成鍵值對。本實施例中的樣本可以預先存儲在資料庫中,存儲的樣本可以按照類別存儲,每種類別都有一個或者多個樣本。特徵是指與樣本有關的元素,可以在一定程度上反映樣本的特性,特徵可以根據需要設置。其中,每個特徵都具有一個特徵序號,用來標識該特徵,每個特徵還具有一個特徵值,特徵值的具體數值可以按照預設的規則統計或計算得到。本實施例中,所述第一算法模型或者所述第二算法模型具體地可以為MapReduce模型,當然,在其它實施方式下也可以採用其它算法模型,本實施例對此不做具體限定。本實施例中,所述貢獻值是指一個特徵對某個類別的代表性,貢獻值越高, 表明該特徵對該類別的代表性越強,貢獻值越低,表明該特徵對該類別的代表性越弱。因此,通過貢獻值可以反映相應的特徵是否能夠代表一個類別,從而可以依據貢獻值來進行特徵選取。結合上述方法,在第一種實施方式下,根據主鍵對樣本進行排序,包括:當該主鍵由特徵序號和樣本序號拼接而成時,先按照特徵序號對樣本進行排序,然後對於相同特徵序號的樣本按照樣本序號進行排序;或者,當該主鍵由樣本序號和特徵序號拼接而成時,先按照樣本序號對樣本進行排序,然後對於相同樣本序號的樣本按照特徵序號進行排序。結合上述方法,在第二種實施方式下,使用第一算法模型計算得到每個類別中的每個特徵的統計量,包括:使用第一算法模型,對每個類別的樣本進行特徵值統計,和/或,對每個類別的樣本進行特徵出現次數的統計。結合上述第二種實施方式,在第三種實施方式下,對每個類別的樣本進行特徵值統計,包括:對每個類別,計算屬於該類別的所有樣本的特徵值之和;和/或,對每個類別,計算屬於該類別的所有樣本的特徵值的平方之和。結合上述第二種實施方式,在第四種實施方式下,對每個類別的樣本進行特徵出現次數的統計,包括:在每個類別中,對每個特徵記錄該特徵在該類別的所有樣本中特徵值不為零的次數,作為該特徵在該類別的樣本中出現的次數。結合上述方法,在第五種實施方式下,使用第二算法模型對該輸出鍵值對進行計算,得到每個特徵對類別的貢獻值,包括:使用第二算法模型,統計所有類別的樣本的特徵值和/或統計所有類別的樣本中特徵出現的次數,並根據統計的結果計算每個特徵對類別的貢獻值。結合上述方法,在第六種實施方式下,根據該貢獻值進行特徵選取,包括:按照貢獻值從大到小確定指定個數個貢獻值,在所有特徵中選出該確定的 貢獻值對應的特徵。本實施例提供的上述方法,通過根據主鍵對樣本進行排序,以主鍵和對應的特徵值為輸入鍵值對,使用第一算法模型計算得到每個類別中的每個特徵的統計量,並將特徵序號和統計量作為輸出鍵值對輸出;使用第二算法模型對所述輸出鍵值對進行計算,得到每個特徵對類別的貢獻值,根據所述貢獻值進行特徵選取,極大地提高了數據的處理速度,縮短了數據的處理時間,降低了運算開銷,通過兩次算法模型計算,實現了快速特徵選擇。實施例2參見圖2,本實施例提供了一種數據處理的方法,包括:201:根據主鍵對樣本進行排序,該主鍵包括特徵序號和樣本序號,該主鍵對應的列值為樣本的特徵值;本實施例中,所述主鍵是指存儲所述樣本的分布式資料庫中一個列或者列的組合,該列或列的組合的值能夠唯一地標識資料庫的表中的一行。主鍵與對應的列值也可以看成鍵值對。本實施例中的主鍵為列的組合,包括特徵序號和樣本序號,該主鍵對應的列值為樣本的特徵值。在主鍵中,特徵序號與樣本序號的拼接順序有兩種,一種是特徵序號與樣本序號進行拼接,另一種是樣本序號與特徵序號進行拼接,本實施例對此不做具體限定。本實施例中的樣本可以預先存儲在資料庫中,存儲的樣本可以按照類別存儲,每種類別都有一個或者多個樣本。特徵是指與樣本有關的元素,可以在一定程度上反映樣本的特性,特徵可以根據需要設置。其中,每個特徵都具有一個特徵序號,用來標識該特徵,每個特徵還具有一個特徵值,特徵值的具體數值可以按照預設的規則統計或計算得到。例如,樣本為2本書,分別屬於數學、體育兩個類別,特徵包括:籃球和公式,其中,「籃球」的特徵值為該詞在樣本中出現的次數,對應2本書的特徵值分別為:8,0;「公式」的特徵值為該詞在樣本中出現的次數,對應2本書的特 徵值分別為:0,5。本步驟中,一種實施方式下,根據主鍵對樣本進行排序,可以包括:當該主鍵由特徵序號和樣本序號拼接而成時,先按照特徵序號對樣本進行排序,然後對於相同特徵序號的樣本按照樣本序號進行排序。例如,有3個樣本,樣本序號分別為1,2,3,有3個特徵,特徵序號分別為1,2,3,按照先特徵序號排序後樣本序號排序的方法可以得到如表1所示的排序結果。表1特徵序號1+樣本序號1特徵序號1+樣本序號2特徵序號1+樣本序號3特徵序號2+樣本序號1特徵序號2+樣本序號2特徵序號2+樣本序號3特徵序號3+樣本序號1特徵序號3+樣本序號2特徵序號3+樣本序號3本步驟中,另一種實施方式下,根據主鍵對樣本進行排序,可以包括:當該主鍵由樣本序號和特徵序號拼接而成時,先按照樣本序號對樣本進行排序,然後對於相同樣本序號的樣本按照特徵序號進行排序。例如,有3個樣本,樣本序號分別為1,2,3,有3個特徵,特徵序號分別為1,2,3,按照先樣本序號排序後特徵序號排序的方法可以得到如表2所示的排序結果。表2樣本序號1+特徵序號1樣本序號1+特徵序號2樣本序號1+特徵序號3樣本序號2+特徵序號1樣本序號2+特徵序號2樣本序號2+特徵序號3樣本序號3+特徵序號1樣本序號3+特徵序號2樣本序號3+特徵序號3202:以該主鍵和特徵值為輸入鍵值對,使用第一MapReduce模型,對每個類別的樣本進行特徵值統計,和/或,對每個類別的樣本進行特徵出現次數的統計,並將特徵序號和統計量作為輸出鍵值對輸出;本實施例是以MapReduce模型作為算法模型進行說明的,當然,採用其它算法模型也能夠實現,此處不做過多說明。本實施例中,第一MapReduce模型使用Map映射函數和Reduce化簡函數來進行數據處理。其中,Map映射函數對主鍵對應的特徵值進行計算得到中間值,該中間值包括但不限於:特徵值本身、特徵值的平方值、特徵值是否為零的計數值等等,如特徵值為零則計數值為零,特徵值不為零則計數值為1,本實施例對此不做具體限定。MapReduce框架將Map函數輸出的具有相同特徵序號的中間值,歸納為中間值集合輸出給Reduce函數。Reduce函數對中間值集合中的中間值進行統計,如特徵值的求和、特徵值平方值的求和、計數值的求和等等,統計後得到每個特徵的統計量,並將特徵序號與該統計量作為輸出鍵值對輸出。進一步地,Reduce函數還可以將該輸出鍵值對存儲到上述資料庫中。其中,該輸出鍵值對中特徵序號作為鍵key,統計量作為與該鍵對應的值value。所述第一MapReduce模型中的Map函數可以為多個,Reduce函數也可以為多個。每個Reduce函數處理的鍵值對均共享同一個鍵。例如,參見圖3,為第一MapReduce模型的處理過程示意圖。其中,3個樣本的9條記錄分別輸入到2個Map函數中,主鍵作為輸入的鍵,由特徵序號和樣本序號拼接組成,且在輸入至Map函數前已經對主鍵進行了排序如圖所示。經Map函數計算各個特徵值的平方以及特徵值是否為零的計數值後,得到的中間值由MapReduce框架按照特徵序號歸納為中間集合,對於Mapper1函數輸出的鍵值對歸納後得到「特徵序號1」及對應的「中間集合1」,以及「特徵序號2」及對應的「中間集合2_1」;對於Mapper2函數輸出的鍵值對歸納後得到「特徵序號2」及對應的「中間集合2_2」,以及「特徵序號3」及對應的「中間集合3」。 其中,「特徵序號1」及對應的「中間集合1」輸入到Reducer1函數中進行統計量的計算,如將該中間集合1中的所有樣本的特徵值累加,或者,將該中間集合1中的所有樣本的特徵值平方累加,或者,將該中間集合中的所有樣本的計數值累加等等,得到統計量1,並將特徵序號1與對應的統計量1作為輸出鍵值對輸出。類似的,Reducer2函數和Reducer3函數也進行統計量的計算,並將特徵序號與對應的統計量作為輸出鍵值對輸出。由上述例子可以明顯看出,MapReduce框架對Map函數的輸出進行歸納處理的過程中,由於作為Map函數的輸入的主鍵已經是排序後的主鍵,因此,降低了合併整理的中間數據量,減少了合併的次數,提高了數據處理的速度。步驟202中,對每個類別的樣本進行特徵值統計,可以包括:對每個類別j,計算屬於該類別j的所有樣本的特徵值之和和/或,對每個類別j,計算屬於該類別j的所有樣本的特徵值的平方之和以M個樣本,特徵維數為N為例進行說明,其中,M個樣本屬於W個類別,j=1,2,…,W;屬於第j個類別的樣本i的第f個特徵的特徵值為f=1,2,…,N。具體地,一個樣本只可能屬於一個類別,不會同時屬於多個類別,一個類別中可以包括多個樣本,所述可以用如下公式來計算:可以用如下公式來計算:步驟202中,對每個類別的樣本進行特徵出現次數的統計,可以包括:在每個類別j中,對每個特徵f記錄該特徵f在該類別j的所有樣本中特徵值不為零的次數,作為該特徵在該類別的樣本中出現的次數具體地,可以用如下公式來計算:<![CDATA[countfj=Σi=1M1(ifxifj0)---(3)]]>本實施例以計算上述三個統計量中的至少一個為例進行說明,在實際應用中,可以任意組合這三個統計量,當然,在其它實施方式中,也可以計算其它的統計量,或者,將其它統計量與上述三個統計量進行任意的組合,本實施例對此不做具體限定。203:使用第二MapReduce模型,統計所有類別的樣本的特徵值和/或統計所有類別的樣本中特徵出現的次數,並根據統計的結果計算每個特徵對類別的貢獻值;其中,所述第一MapReduce模型的輸出鍵值對作為第二MapReduce模型的輸入鍵值對,鍵為特徵序號,值為統計量。本實施例中,所述貢獻值是指一個特徵對某個類別的代表性,貢獻值越高,表明該特徵對該類別的代表性越強,貢獻值越低,表明該特徵對該類別的代表性越弱。因此,通過貢獻值可以反映相應的特徵是否能夠代表一個類別,從而可以依據貢獻值來進行特徵選取。所述第二MapReduce模型計算貢獻值rankf的公式可以有多種,包括但不限於:其中,所述參見上述公式(1)至公式(3),此處不贅述。204:根據得到的貢獻值進行特徵選取。具體地,本步驟可以包括:按照貢獻值從大到小確定指定個數個貢獻值,在所有特徵中選出該確定的 貢獻值對應的特徵。所述指定個數可以根據需要設置,具體數值本實施例對此不做限定。例如,所述指定個數為T,可以將得到的貢獻值按照從大到小的順序排序,然後選出前面T個貢獻值,將該T個貢獻值對應的特徵選出作為最終結果。本實施例中,第二MapReduce模型使用Map函數和Reduce函數進行數據處理。其中,Map函數的輸入為上述特徵序號和對應的統計量,Map函數根據所述統計量進行計算得到每個特徵對類別的貢獻值,並將特徵序號作為key,將貢獻值作為value輸出。Reduce函數對Map函數輸出的所有貢獻值進行排序,根據排序的結果在所有特徵中選取需要的特徵,得到最終結果。所述第二MapReduce模型的Map函數可以使用上述公式(4)來計算貢獻值,當然,也可以使用其它公式來計算貢獻值,本實施例對此不做具體限定。本實施例提供的上述方法,通過根據主鍵對樣本進行排序,以主鍵和對應的特徵值為輸入鍵值對,使用第一MapReduce模型計算得到每個類別中的每個特徵的統計量,並將特徵序號和統計量作為輸出鍵值對輸出;使用第二MapReduce模型對所述輸出鍵值對進行計算,得到每個特徵對類別的貢獻值,根據所述貢獻值進行特徵選取,極大地提高了數據的處理速度,縮短了數據的處理時間,降低了運算開銷,通過兩次MapReduce模型計算,實現了快速特徵選擇。實施例3參見圖4,本實施例提供了一種數據處理的裝置,包括:排序模塊401,用於根據主鍵對樣本進行排序,該主鍵包括特徵序號和樣本序號,該主鍵對應的列值為樣本的特徵值;第一處理模塊402,用於以該主鍵和特徵值為輸入鍵值對,使用第一算法模型計算得到每個類別中的每個特徵的統計量,並將特徵序號和統計量作為輸出鍵值對輸出;第二處理模塊403,用於使用第二算法模型對該輸出鍵值對進行計算,得到每個特徵對類別的貢獻值,根據該貢獻值進行特徵選取。本實施例中,所述主鍵是指存儲所述樣本的分布式資料庫中一個列或者列的組合,該列或列的組合的值能夠唯一地標識資料庫的表中的一行。主鍵與對應的列值也可以看成鍵值對。本實施例中的主鍵包括特徵序號和樣本序號,該主鍵對應的列值為樣本的特徵值。本實施例中,所述第一算法模型或者所述第二算法模型具體地可以為MapReduce模型,當然,在其它實施方式下也可以採用其它算法模型,本實施例對此不做具體限定。本實施例中的樣本可以預先存儲在資料庫中,存儲的樣本可以按照類別存儲,每種類別都有一個或者多個樣本。特徵是指與樣本有關的元素,可以在一定程度上反映樣本的特性,特徵可以根據需要設置。其中,每個特徵都具有一個特徵序號,用來標識該特徵,每個特徵還具有一個特徵值,特徵值的具體數值可以按照預設的規則統計或計算得到。本實施例中,所述貢獻值是指一個特徵對某個類別的代表性,貢獻值越高,表明該特徵對該類別的代表性越強,貢獻值越低,表明該特徵對該類別的代表性越弱。因此,通過貢獻值可以反映相應的特徵是否能夠代表一個類別,從而可以依據貢獻值來進行特徵選取。結合上述裝置,在第一種實施方式下,排序模塊401包括:第一排序單元,用於當該主鍵由特徵序號和樣本序號拼接而成時,先按照特徵序號對樣本進行排序,然後對於相同特徵序號的樣本按照樣本序號進行排序;或者,第二排序單元,用於當該主鍵由樣本序號和特徵序號拼接而成時,先按照樣本序號對樣本進行排序,然後對於相同樣本序號的樣本按照特徵序號進行排序。參見圖5,結合上述裝置,在第二種實施方式下,第一處理模塊402包括:統計單元402a,用於使用第一算法模型,對每個類別的樣本進行特徵值統計,和/或,對每個類別的樣本進行特徵出現次數的統計。結合上述第二種實施方式,在第三種實施方式下,統計單元402a用於:對每個類別,計算屬於該類別的所有樣本的特徵值之和;和/或,對每個類別,計算屬於該類別的所有樣本的特徵值的平方之和。結合上述第二種實施方式,在第四種實施方式下,統計單元402a用於:在每個類別中,對每個特徵記錄該特徵在該類別的所有樣本中特徵值不為零的次數,作為該特徵在該類別的樣本中出現的次數。參見圖6,結合上述裝置,在第五種實施方式下,第二處理模塊403包括:計算單元403a,用於使用第二算法模型,統計所有類別的樣本的特徵值和/或統計所有類別的樣本中特徵出現的次數,並根據統計的結果計算每個特徵對類別的貢獻值。結合上述裝置,在第六種實施方式下,第二處理模塊403包括:選取單元403b,用於按照貢獻值從大到小確定指定個數個貢獻值,在所有特徵中選出該確定的貢獻值對應的特徵。本實施例提供的上述裝置可以執行上述任一方法實施例中提供的方法,詳細過程見方法實施例中的描述,此處不贅述。本實施例提供的上述裝置,通過根據主鍵對樣本進行排序,以主鍵和對應的特徵值為輸入鍵值對,使用第一算法模型計算得到每個類別中的每個特徵的統計量,並將特徵序號和統計量作為輸出鍵值對輸出;使用第二算法模型對所述輸出鍵值對進行計算,得到每個特徵對類別的貢獻值,根據所述貢獻值進行特徵選取,極大地提高了數據的處理速度,縮短了數據的處理時間,降低了運算開銷,通過兩次算法模型計算,實現了快速特徵選擇。本領域普通技術人員可以理解實現上述實施例的全部或部分步驟可以通過硬體來完成,也可以通過程序來指令相關的硬體完成,所述的程序可以存儲於 一種計算機可讀存儲介質中,上述提到的存儲介質可以是只讀存儲器,磁碟或光碟等。以上所述僅為本發明的較佳實施例,並不用以限制本發明,凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護範圍之內。