基於人工智慧的匹配度評估方法、裝置、設備及存儲介質與流程
2023-05-27 06:14:46 8
【技術領域】
本發明涉及計算機應用技術,特別涉及基於人工智慧的匹配度評估方法、裝置、設備及存儲介質。
背景技術:
人工智慧(artificialintelligence),英文縮寫為ai。它是研究、開發用於模擬、延伸和擴展人的智能的理論、方法、技術及應用系統的一門新的技術科學。人工智慧是計算機科學的一個分支,它企圖了解智能的實質,並生產出一種新的能以人類智能相似的方式做出反應的智能機器,該領域的研究包括機器人、語言識別、圖像識別、自然語言處理和專家系統等。
信息檢索的一個核心任務就是計算用戶輸入的查詢(query)與作為檢索對象的各文檔(doc)之間的語義相關程度。
具體地,可對query與各doc的標題(title)的匹配度進行評估,如計算query與title之間的匹配度評分(score),並可按照評分由高到低的順序對各doc進行排序,進而將排序後處於前n位的doc作為檢索結果返回給用戶,n為正整數。
現有技術中,在計算query與title之間的匹配度評分時,通常採用以下方式:先用卷積神經網絡(cnn,convolutionalneuralnetwork)或循環神經網絡(rnn,recurrentneuralnetwork)等分別得到query和title的表達,然後基於這兩個表達來計算諸如cosine相似度,從而得到query與title之間的匹配度評分。
但是,上述方式中,將一段複雜的文本作為一個整體映射到一個低維空間中的向量(表達),在壓縮過程中容易丟失一些關鍵的信息,從而只能從整體上對兩個文本的匹配程度進行大致評估,評估結果的準確性較低。
技術實現要素:
有鑑於此,本發明提供了基於人工智慧的匹配度評估方法、裝置、設備及存儲介質,能夠提高評估結果的準確性。
具體技術方案如下:
一種基於人工智慧的匹配度評估方法,包括:
分別獲取查詢query中的各單詞的單詞表達以及標題title中的各單詞的單詞表達;
根據所述單詞表達,分別獲取所述query中的各單詞的基於上下文的單詞表達以及所述title中的各單詞的基於上下文的單詞表達;
根據獲取到的信息生成匹配特徵;
根據所述匹配特徵確定出所述query與所述title之間的匹配度評分。
根據本發明一優選實施例,所述分別獲取query中的各單詞的單詞表達以及title中的各單詞的單詞表達包括:
將所述query中的各單詞分別embedding成一個低維向量,得到序列qe=[q1,…,qi,…,qm];
其中,m表示所述query中包括的單詞數,qi表示所述query中的第i個單詞的低維向量,i為正整數,且1≤i≤m;
將所述title中的各單詞分別embedding成一個低維向量,得到序列te=[t1,…,tj,…,tn];
其中,n表示所述title中包括的單詞數,tj表示所述title中的第j個單詞的低維向量,j為正整數,且1≤j≤n。
根據本發明一優選實施例,所述分別獲取所述query中的各單詞的基於上下文的單詞表達以及所述title中的各單詞的基於上下文的單詞表達包括:
將所述qe輸入給雙向循環神經網絡rnn,分別得到從左向右方向處理後的輸出q1以及從右向左方向處理後的輸出q2;
將所述te輸入給雙向rnn,分別得到從左向右方向處理後的輸出t1以及從右向左方向處理後的輸出t2;
將所述qe、q1和q2進行拼接,得到q(m,3d),所述d表示表達維度,embedding和雙向rnn使用同樣的表達維度;
將所述te、t1和t2進行拼接,得到t(n,3d);
將所述query以及所述title中的每個單詞對應的長為3d的向量作為所述單詞的基於上下文的單詞表達。
根據本發明一優選實施例,所述根據獲取到的信息生成匹配特徵包括:
根據獲取到的信息生成局部匹配特徵;
根據所述局部匹配特徵生成高級匹配特徵。
根據本發明一優選實施例,所述根據獲取到的信息生成局部匹配特徵包括:
根據各單詞的所述基於上下文的單詞表達,分別按照不同的匹配度計算方式,計算出所述query中的單詞與所述title中的單詞兩兩之間的匹配度,得到三維的張量tensor(m,n,t);
其中,t表示t維的向量,針對每組單詞q[i]和t[j],分別計算出t個匹配度,t個匹配度構成所述t維的向量,q[i]表示所述query中的單詞,t[j]表示所述title中的單詞;
所述tensor中的每一個值(i,j,k)表示q[i]和t[j]對應的第k個匹配度,1≤k≤t。
根據本發明一優選實施例,所述根據所述局部匹配特徵生成高級匹配特徵包括:
將所述(m,n,t)輸入給卷積神經網絡cnn,將得到的輸出(m,n,t1)、…、(m,n,tw)作為所述高級匹配特徵,w為正整數,表示cnn中包括的卷積層數。
根據本發明一優選實施例,所述根據所述匹配特徵確定出所述query與所述title之間的匹配度評分包括:
將所述(m,n,t)以及所述高級匹配特徵進行拼接,得到(m,n,t+t1+…+tw);
針對每個(m,n)矩陣,分別採用按行pooling的方式確定出一個(m,k』)的序列表達,k』為正整數,得到(m,(t+t1+…+tw)*k』);
將所述(m,(t+t1+…+tw)*k』)輸入給雙向rnn,得到雙向rnn最後一個位置上的表達;
根據所述最後一個位置上的表達確定出所述匹配度評分。
根據本發明一優選實施例,所述針對每個(m,n)矩陣,分別採用按行pooling的方式確定出一個(m,k』)的序列表達包括:
針對所述(m,n)每一行中的n個值,分別選取其中的最大的k』個值,並按從大到小的順序進行排序,k』≤n。
根據本發明一優選實施例,所述最後一個位置上的表達為一個長為2f的向量,f表示表達維度;
所述根據所述最後一個位置上的表達確定出所述匹配度評分包括:
將所述長為2f的向量輸入給包含單隱層的全連接網絡,得到輸出的所述匹配度評分。
一種基於人工智慧的匹配度評估裝置,包括:表達處理單元、特徵處理單元以及評分單元;
所述表達處理單元,用於分別獲取查詢query中的各單詞的單詞表達以及標題title中的各單詞的單詞表達;根據所述單詞表達,分別獲取所述query中的各單詞的基於上下文的單詞表達以及所述title中的各單詞的基於上下文的單詞表達;
所述特徵處理單元,用於根據所述表達處理單元獲取到的信息生成匹配特徵;
所述評分單元,用於根據所述匹配特徵確定出所述query與所述title之間的匹配度評分。
根據本發明一優選實施例,所述表達處理單元中包括:第一處理子單元以及第二處理子單元;
所述第一處理子單元,用於將所述query中的各單詞分別embedding成一個低維向量,得到序列qe=[q1,…,qi,…,qm];
其中,m表示所述query中包括的單詞數,qi表示所述query中的第i個單詞的低維向量,i為正整數,且1≤i≤m;
將所述title中的各單詞分別embedding成一個低維向量,得到序列te=[t1,…,tj,…,tn];
其中,n表示所述title中包括的單詞數,tj表示所述title中的第j個單詞的低維向量,j為正整數,且1≤j≤n;
所述第二處理子單元,用於根據所述qe和te,分別獲取所述query中的各單詞的基於上下文的單詞表達以及所述title中的各單詞的基於上下文的單詞表達。
根據本發明一優選實施例,
所述第二處理子單元將所述qe輸入給雙向循環神經網絡rnn,分別得到從左向右方向處理後的輸出q1以及從右向左方向處理後的輸出q2;
將所述te輸入給雙向rnn,分別得到從左向右方向處理後的輸出t1以及從右向左方向處理後的輸出t2;
將所述qe、q1和q2進行拼接,得到q(m,3d),所述d表示表達維度,embedding和雙向rnn使用同樣的表達維度;
將所述te、t1和t2進行拼接,得到t(n,3d);
將所述query以及所述title中的每個單詞對應的長為3d的向量作為所述單詞的基於上下文的單詞表達。
根據本發明一優選實施例,所述特徵處理單元中包括:第三處理子單元以及第四處理子單元;
所述第三處理子單元,用於根據所述表達處理單元獲取到的信息生成局部匹配特徵;
所述第四處理子單元,用於根據所述局部匹配特徵生成高級匹配特徵。
根據本發明一優選實施例,
所述第三處理子單元根據各單詞的所述基於上下文的單詞表達,分別按照不同的匹配度計算方式,計算出所述query中的單詞與所述title中的單詞兩兩之間的匹配度,得到三維的張量tensor(m,n,t);
其中,t表示t維的向量,針對每組單詞q[i]和t[j],分別計算出t個匹配度,t個匹配度構成所述t維的向量,q[i]表示所述query中的單詞,t[j]表示所述title中的單詞;
所述tensor中的每一個值(i,j,k)表示q[i]和t[j]對應的第k個匹配度,1≤k≤t。
根據本發明一優選實施例,所述第四處理子單元將所述(m,n,t)輸入給卷積神經網絡cnn,將得到的輸出(m,n,t1)、…、(m,n,tw)作為所述高級匹配特徵,w為正整數,表示cnn中包括的卷積層數。
根據本發明一優選實施例,
所述評分單元將所述(m,n,t)以及所述高級匹配特徵進行拼接,得到(m,n,t+t1+…+tw);
針對每個(m,n)矩陣,分別採用按行pooling的方式確定出一個(m,k』)的序列表達,k』為正整數,得到(m,(t+t1+…+tw)*k』);
將所述(m,(t+t1+…+tw)*k』)輸入給雙向rnn,得到雙向rnn最後一個位置上的表達;
根據所述最後一個位置上的表達確定出所述匹配度評分。
根據本發明一優選實施例,所述評分單元針對所述(m,n)每一行中的n個值,分別選取其中的最大的k』個值,並按從大到小的順序進行排序,得到所述(m,k』),k』≤n。
根據本發明一優選實施例,所述最後一個位置上的表達為一個長為2f的向量,f表示表達維度;
所述評分單元將所述長為2f的向量輸入給包含單隱層的全連接網絡,得到輸出的所述匹配度評分。
一種計算機設備,包括存儲器、處理器及存儲在所述存儲器上並可在所述處理器上運行的電腦程式,所述處理器執行所述程序時實現如以上所述的方法。
一種計算機可讀存儲介質,其上存儲有電腦程式,所述程序被處理器執行時實現如以上所述的方法。
基於上述介紹可以看出,採用本發明所述方案,構建了底層的單詞表達以及基於上下文的單詞表達,這些表達既能夠強調局部的信息,同時也融合了全局的信息,從而能夠更好地反映query與title之間的匹配程度,進而提高了評估結果的準確性。
【附圖說明】
圖1為本發明所述基於人工智慧的匹配度評估方法實施例的流程圖。
圖2為本發明所述獲取query與title之間的匹配度評分的過程示意圖。
圖3為本發明所述基於人工智慧的匹配度評估裝置實施例的組成結構示意圖。
圖4示出了適於用來實現本發明實施方式的示例性計算機系統/伺服器12的框圖。
【具體實施方式】
為了使本發明的技術方案更加清楚、明白,以下參照附圖並舉實施例,對本發明所述方案進行進一步說明。
顯然,所描述的實施例是本發明一部分實施例,而不是全部的實施例。基於本發明中的實施例,本領域技術人員在沒有作出創造性勞動前提下所獲得的所有其它實施例,都屬於本發明保護的範圍。
圖1為本發明所述基於人工智慧的匹配度評估方法實施例的流程圖,如圖1所示,包括以下具體實現方式。
在101中,分別獲取query中的各單詞(關鍵詞)的單詞表達以及title中的各單詞的單詞表達。
具體地,可將query中的各單詞分別embedding成一個低維向量,從而得到序列qe=[q1,…,qi,…,qm]。
其中,m表示query中包括的單詞數,qi表示query中的第i個單詞的低維向量,i為正整數,且1≤i≤m。
另外,將title中的各單詞分別embedding成一個低維向量,從而得到序列te=[t1,…,tj,…,tn]。
其中,n表示title中包括的單詞數,tj表示title中的第j個單詞的低維向量,j為正整數,且1≤j≤n。
在實際應用中,需要預先對query和title分別進行切詞等預處理,從而得到query和title中的各單詞。
以query為例,假設其中共包括4個單詞,分別為單詞1、單詞2、單詞3和單詞4,那麼可分別將單詞1、單詞2、單詞3和單詞4embedding成一個低維向量,從而得到qe=[q1,q2,q3,q4],如何得到所述低維向量為現有技術。
在102中,根據單詞表達,分別獲取query中的各單詞的基於上下文的單詞表達以及title中的各單詞的基於上下文的單詞表達。
在分別獲取到query中的各單詞的單詞表達以及title中的各單詞的單詞表達之後,可進一步獲取query中的各單詞的基於上下文的單詞表達以及title中的各單詞的基於上下文的單詞表達。
比如,可將qe輸入給雙向rnn,分別得到從左向右方向處理後的輸出q1以及從右向左方向處理後的輸出q2,將te輸入給雙向rnn,分別得到從左向右方向處理後的輸出t1以及從右向左方向處理後的輸出t2。
即將qe和te分別輸入到不同的雙向rnn中,從而分別得到q1和q2以及t1和t2。
embedding和雙向rnn可以使用同樣的表達維度d,d的具體取值可根據實際需要而定,因此,qe、q1和q2的大小為(m,d),相應地,te、t1和t2的大小為(n,d)。
可將qe、q1和q2進行拼接,從而得到q(m,3d),將te、t1和t2進行拼接,從而得到t(n,3d),這樣,query以及title中的每個單詞將分別對應一個長為3d的向量,該向量即為基於上下文的單詞表達。
可以看出,所述拼接是指按列拼接。
對於每個單詞對應的長為3d的向量來說,前d維表示該單詞的embedding結果,中間d維表示該單詞的左context,後d維表示該單詞的右context,因此,長為3d的向量即為包含了該單詞的上下文信息的基於上下文的單詞表達。
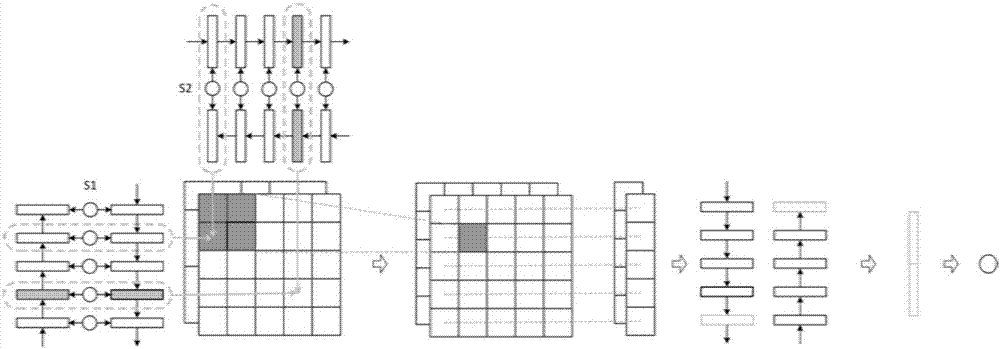
在103中,根據獲取到的信息生成匹配特徵。
首先,可根據獲取到的信息生成局部匹配特徵,之後,可根據局部匹配特徵進一步生成高級匹配特徵,以下分別對局部匹配特徵以及高級匹配特徵的獲取方式進行詳細說明。
1)局部匹配特徵
即基於之前獲取到的表達進行匹配得到所有局部的匹配特徵。
具體地,可根據各單詞的基於上下文的單詞表達,分別按照不同的匹配度計算方式,計算出query中的單詞與title中的單詞兩兩之間的匹配度,從而得到三維的張量(tensor)(m,n,t)。
其中,t表示t維的向量,針對每組單詞q[i]和t[j],分別計算出t個匹配度,t個匹配度構成一個t維的向量,q[i]表示query中的單詞,t[j]表示title中的單詞。
tensor中的每一個值(i,j,k)表示q[i]和t[j]對應的第k個匹配度,1≤k≤t。
舉例說明:
假設query中共包括兩個單詞,分別為單詞1和單詞2,title中也包括兩個單詞,分別為單詞3和單詞4;
針對單詞1和單詞3,可分別按照不同的匹配度計算方式,計算出t個匹配度;
針對單詞1和單詞4,可分別按照不同的匹配度計算方式,計算出t個匹配度;
針對單詞2和單詞3,可分別按照不同的匹配度計算方式,計算出t個匹配度;
針對單詞2和單詞4,可分別按照不同的匹配度計算方式,計算出t個匹配度。
其中,可根據兩個單詞的基於上下文的單詞表達,計算出兩個單詞之間的匹配度。
具體採用哪些匹配度計算方式可根據實際需要而定,比如可包括張量神經網絡以及cosine等多種匹配度計算方式。
另外,還可以採用傳統的基於關鍵詞的匹配的方式來構造不同的匹配矩陣(matchingmatrix),方便融入人工知識,即人工可以根據知識來構建額外的匹配矩陣作為匹配特徵,從而為信息檢索等場景中引入人工知識提供了良好的途徑。
2)高級匹配特徵
上述獲取到的(m,n,t)的tensor中包含的是單詞級和基於上下文的單詞級匹配特徵,在此基礎上,還可進一步利用cnn來提取高維度特徵。
類似於在圖像中,m和n是圖片的大小,t是featuremap的數量。
可將(m,n,t)輸入給cnn,得到輸出的(m,n,t1)、…、(m,n,tw),作為高級匹配特徵,w為正整數,表示cnn中包括的卷積層數。
假設卷積層數為1,那麼將(m,n,t)輸入給cnn後,可得到(m,n,t1),t1為cnn的kernel數量,在實際應用中,可採用一種動態padding的方式使得卷積的輸入和輸出的大小是一樣的。
進一步地,還可堆疊多個卷積層來提取更高層的匹配特徵。
在104中,根據匹配特徵確定出query與title之間的匹配度評分。
首先,可將(m,n,t)以及得到的高級匹配特徵進行拼接,從而得到(m,n,t+t1+…+tw),假設卷積層數為2,那麼則指將(m,n,t)、(m,n,t1)和(m,n,t2)拼接為(m,n,t+t1+t2),也就是t+t1+t2個大小為(m,n)的匹配矩陣。
針對每個(m,n)匹配矩陣,可分別採用按行pooling的方式確定出一個(m,k』)的序列表達,k』為正整數,從而得到(m,(t+t1+…+tw)*k』)。
比如,可針對(m,n)每一行中的n個值,分別選取其中的最大的k』個值,並按從大到小的順序進行排序,從而得到(m,k』),k』≤n,假設一共有t+t1+t2個匹配矩陣,那麼得到的輸出則為(m,(t+t1+t2)*k』)。
上述過程的直觀含義是為query中的每個單詞從該單詞對應的匹配特徵中找出最大的(t+t1+t2)*k』特徵,query中的每個單詞都非常重要,用來清晰的描述用戶的信息需求,這些特徵表明了title對query中的各信息需求的滿足情況。
通過上述方式,可以知道最終的匹配最強的地方發生在(m,n)匹配矩陣中的哪個具體的位置(i,j),因此,可以看到query中的各單詞具體和title中的哪個單詞相匹配,具有很強的可解釋性。
上述得到的(m,(t+t1+…+tw)*k』)是一個變長的序列,可採用雙向rnn的方式來對該序列的信息進行融合,並可將雙向rnn最後一個位置上的表達作為融合後的表達。
即將(m,(t+t1+…+tw)*k』)輸入給雙向rnn,從而得到雙向rnn最後一個位置上的表達,進而可根據最後一個位置上的表達確定出query與title之間的匹配度評分。
最後一個位置上的表達可為一個長為2f的向量,f表示表達維度,具體取值可根據實際需要而定,由於是雙向rnn,因此針對每個方向,可分別得到一個長為f的向量,組合起來即為一個長為2f的向量。
最後,可將長為2f的向量輸入給包含單隱層的全連接網絡,從而得到輸出的匹配度評分。
在信息檢索場景中,在分別計算出用戶輸入的query與各doc的title的匹配度評分之後,可按照評分由高到低的順序對各doc進行排序,進而將排序後處於前n位的doc作為檢索結果返回給用戶,n為正整數。
綜合上述介紹,圖2為本發明所述獲取query與title之間的匹配度評分的過程示意圖,具體實現可參照前述相關說明,不再贅述。
可以看出,採用上述實施例所述方案,構建了底層的單詞表達以及基於上下文的單詞表達,這些表達既能夠強調局部的信息,同時也融合了全局的信息,從而能夠更好地反映query與title之間的匹配程度,進而提高了評估結果的準確性。
而且,採用本實施例所述方案,所有的局部關鍵匹配特徵都能夠得到很好的保留,基於這些局部匹配特徵,又可進一步提取出高級匹配特徵,從而能夠有效地捕獲對於信息檢索來說至關重要的語義匹配以及匹配鄰近度信息等。
另外,在獲取到匹配特徵之後,可按照query中的每個單詞進行pooling,以此來建模title對query的所有關鍵信息需求的覆蓋情況,由於中間得到的所有匹配矩陣都參與本次pooling,因此最終得到的結果是各單詞在多個層次上的信息需求被覆蓋情況,而且具有良好的可解釋性,query中的每個單詞具體是被title中的哪個單詞所滿足,都能基於pooling的結果進行回溯。
以上是關於方法實施例的介紹,以下通過裝置實施例,對本發明所述方案進行進一步說明。
圖3為本發明所述基於人工智慧的匹配度評估裝置實施例的組成結構示意圖,如圖3所示,包括:表達處理單元301、特徵處理單元302以及評分單元303。
表達處理單元301,用於分別獲取query中的各單詞的單詞表達以及title中的各單詞的單詞表達;根據單詞表達,分別獲取query中的各單詞的基於上下文的單詞表達以及title中的各單詞的基於上下文的單詞表達。
特徵處理單元302,用於根據表達處理單元301獲取到的信息生成匹配特徵。
評分單元303,用於根據匹配特徵確定出query與title之間的匹配度評分。
如圖3所示,表達處理單元301中可具體包括:第一處理子單元3011以及第二處理子單元3012。
第一處理子單元3011,用於將query中的各單詞分別embedding成一個低維向量,得到序列qe=[q1,…,qi,…,qm];
其中,m表示query中包括的單詞數,qi表示query中的第i個單詞的低維向量,i為正整數,且1≤i≤m;
將title中的各單詞分別embedding成一個低維向量,得到序列te=[t1,…,tj,…,tn];
其中,n表示title中包括的單詞數,tj表示title中的第j個單詞的低維向量,j為正整數,且1≤j≤n;
第二處理子單元3012,用於根據qe和te,分別獲取query中的各單詞的基於上下文的單詞表達以及title中的各單詞的基於上下文的單詞表達。
具體地,第二處理子單元3012可將qe輸入給雙向rnn,分別得到從左向右方向處理後的輸出q1以及從右向左方向處理後的輸出q2;
將te輸入給雙向rnn,分別得到從左向右方向處理後的輸出t1以及從右向左方向處理後的輸出t2;
將qe、q1和q2進行拼接,得到q(m,3d),d表示表達維度,embedding和雙向rnn使用同樣的表達維度;
將te、t1和t2進行拼接,得到t(n,3d);
將query以及title中的每個單詞對應的長為3d的向量作為單詞的基於上下文的單詞表達。
如圖3所示,特徵處理單元302中可具體包括:第三處理子單元3021以及第四處理子單元3022。
第三處理子單元3021,用於根據表達處理單元獲取到的信息生成局部匹配特徵。
第四處理子單元3022,用於根據局部匹配特徵生成高級匹配特徵。
其中,第三處理子單元3021可根據各單詞的基於上下文的單詞表達,分別按照不同的匹配度計算方式,計算出query中的單詞與title中的單詞兩兩之間的匹配度,得到三維的張量tensor(m,n,t);
其中,t表示t維的向量,針對每組單詞q[i]和t[j],分別計算出t個匹配度,t個匹配度構成t維的向量,q[i]表示query中的單詞,t[j]表示title中的單詞;
tensor中的每一個值(i,j,k)表示q[i]和t[j]對應的第k個匹配度,1≤k≤t。
具體採用哪些匹配度計算方式可根據實際需要而定,比如可包括張量神經網絡以及cosine等多種匹配度計算方式。
上述獲取到的(m,n,t)的tensor中包含的是單詞級和基於上下文的單詞級匹配特徵,在此基礎上,還可進一步利用cnn來提取高維度特徵。
相應地,第四處理子單元3022可將(m,n,t)輸入給cnn,將得到的輸出(m,n,t1)、…、(m,n,tw)作為高級匹配特徵,w為正整數,表示cnn中包括的卷積層數。
假設卷積層數為1,那麼將(m,n,t)輸入給cnn後,可得到(m,n,t1),t1為cnn的kernel數量,在實際應用中,可採用一種動態padding的方式使得卷積的輸入和輸出的大小是一樣的。
進一步地,還可堆疊多個卷積層來提取更高層的匹配特徵。
之後,評分單元303可將(m,n,t)以及高級匹配特徵進行拼接,得到(m,n,t+t1+…+tw),假設卷積層數為2,那麼則指將(m,n,t)、(m,n,t1)和(m,n,t2)拼接為(m,n,t+t1+t2),也就是t+t1+t2個大小為(m,n)的匹配矩陣。
針對每個(m,n)匹配矩陣,評分單元303可分別採用按行pooling的方式確定出一個(m,k』)的序列表達,k』為正整數,得到(m,(t+t1+…+tw)*k』)。
比如,可針對(m,n)每一行中的n個值,分別選取其中的最大的k』個值,並按從大到小的順序進行排序,從而得到(m,k』),k』≤n,假設一共有t+t1+t2個匹配矩陣,那麼得到的輸出則為(m,(t+t1+t2)*k』)。
上述得到的(m,(t+t1+…+tw)*k』)是一個變長的序列,可採用雙向rnn的方式來對該序列的信息進行融合,並可將雙向rnn最後一個位置上的表達作為融合後的表達。
即評分單元303可將(m,(t+t1+…+tw)*k』)輸入給雙向rnn,從而得到雙向rnn最後一個位置上的表達,進而可根據最後一個位置上的表達確定出query與title之間的匹配度評分。
最後一個位置上的表達可為一個長為2f的向量,f表示表達維度,具體取值可根據實際需要而定,由於是雙向rnn,因此針對每個方向,可分別得到一個長為f的向量,組合起來即為一個長為2f的向量。
最後,可將長為2f的向量輸入給包含單隱層的全連接網絡,從而得到輸出的匹配度評分。
圖3所示裝置實施例的具體工作流程可參照前述方法實施例中的相應說明,不再贅述。
可以看出,採用上述實施例所述方案,構建了底層的單詞表達以及基於上下文的單詞表達,這些表達既能夠強調局部的信息,同時也融合了全局的信息,從而能夠更好地反映query與title之間的匹配程度,進而提高了評估結果的準確性。
而且,採用本實施例所述方案,所有的局部關鍵匹配特徵都能夠得到很好的保留,基於這些局部匹配特徵,又可進一步提取出高級匹配特徵,從而能夠有效地捕獲對於信息檢索來說至關重要的語義匹配以及匹配鄰近度信息等。
另外,在獲取到匹配特徵之後,可按照query中的每個單詞進行pooling,以此來建模title對query的所有關鍵信息需求的覆蓋情況,由於中間得到的所有匹配矩陣都參與本次pooling,因此最終得到的結果是各單詞在多個層次上的信息需求被覆蓋情況,而且具有良好的可解釋性,query中的每個單詞具體是被title中的哪個單詞所滿足,都能基於pooling的結果進行回溯。
圖4示出了適於用來實現本發明實施方式的示例性計算機系統/伺服器12的框圖。圖4顯示的計算機系統/伺服器12僅僅是一個示例,不應對本發明實施例的功能和使用範圍帶來任何限制。
如圖4所示,計算機系統/伺服器12以通用計算設備的形式表現。計算機系統/伺服器12的組件可以包括但不限於:一個或者多個處理器(處理單元)16,存儲器28,連接不同系統組件(包括存儲器28和處理器16)的總線18。
總線18表示幾類總線結構中的一種或多種,包括存儲器總線或者存儲器控制器,外圍總線,圖形加速埠,處理器或者使用多種總線結構中的任意總線結構的局域總線。舉例來說,這些體系結構包括但不限於工業標準體系結構(isa)總線,微通道體系結構(mac)總線,增強型isa總線、視頻電子標準協會(vesa)局域總線以及外圍組件互連(pci)總線。
計算機系統/伺服器12典型地包括多種計算機系統可讀介質。這些介質可以是任何能夠被計算機系統/伺服器12訪問的可用介質,包括易失性和非易失性介質,可移動的和不可移動的介質。
存儲器28可以包括易失性存儲器形式的計算機系統可讀介質,例如隨機存取存儲器(ram)30和/或高速緩存存儲器32。計算機系統/伺服器12可以進一步包括其它可移動/不可移動的、易失性/非易失性計算機系統存儲介質。僅作為舉例,存儲系統34可以用於讀寫不可移動的、非易失性磁介質(圖4未顯示,通常稱為「硬碟驅動器」)。儘管圖4中未示出,可以提供用於對可移動非易失性磁碟(例如「軟盤」)讀寫的磁碟驅動器,以及對可移動非易失性光碟(例如cd-rom,dvd-rom或者其它光介質)讀寫的光碟驅動器。在這些情況下,每個驅動器可以通過一個或者多個數據介質接口與總線18相連。存儲器28可以包括至少一個程序產品,該程序產品具有一組(例如至少一個)程序模塊,這些程序模塊被配置以執行本發明各實施例的功能。
具有一組(至少一個)程序模塊42的程序/實用工具40,可以存儲在例如存儲器28中,這樣的程序模塊42包括——但不限於——作業系統、一個或者多個應用程式、其它程序模塊以及程序數據,這些示例中的每一個或某種組合中可能包括網絡環境的實現。程序模塊42通常執行本發明所描述的實施例中的功能和/或方法。
計算機系統/伺服器12也可以與一個或多個外部設備14(例如鍵盤、指向設備、顯示器24等)通信,還可與一個或者多個使得用戶能與該計算機系統/伺服器12交互的設備通信,和/或與使得該計算機系統/伺服器12能與一個或多個其它計算設備進行通信的任何設備(例如網卡,數據機等等)通信。這種通信可以通過輸入/輸出(i/o)接口22進行。並且,計算機系統/伺服器12還可以通過網絡適配器20與一個或者多個網絡(例如區域網(lan),廣域網(wan)和/或公共網絡,例如網際網路)通信。如圖4所示,網絡適配器20通過總線18與計算機系統/伺服器12的其它模塊通信。應當明白,儘管圖中未示出,可以結合計算機系統/伺服器12使用其它硬體和/或軟體模塊,包括但不限於:微代碼、設備驅動器、冗餘處理單元、外部磁碟驅動陣列、raid系統、磁帶驅動器以及數據備份存儲系統等。
處理器16通過運行存儲在存儲器28中的程序,從而執行各種功能應用以及數據處理,例如實現圖1所示實施例中的方法,即分別獲取query中的各單詞的單詞表達以及title中的各單詞的單詞表達,根據所述單詞表達,分別獲取query中的各單詞的基於上下文的單詞表達以及title中的各單詞的基於上下文的單詞表達,根據獲取到的信息生成匹配特徵,根據匹配特徵確定出query與title之間的匹配度評分。
具體實現請參照前述各實施例中的相關說明,不再贅述。
本發明同時公開了一種計算機可讀存儲介質,其上存儲有電腦程式,該程序被處理器執行時將實現如圖1所示實施例中的方法。
可以採用一個或多個計算機可讀的介質的任意組合。計算機可讀介質可以是計算機可讀信號介質或者計算機可讀存儲介質。計算機可讀存儲介質例如可以是——但不限於——電、磁、光、電磁、紅外線、或半導體的系統、裝置或器件,或者任意以上的組合。計算機可讀存儲介質的更具體的例子(非窮舉的列表)包括:具有一個或多個導線的電連接、可攜式計算機磁碟、硬碟、隨機存取存儲器(ram)、只讀存儲器(rom)、可擦式可編程只讀存儲器(eprom或快閃記憶體)、光纖、可攜式緊湊磁碟只讀存儲器(cd-rom)、光存儲器件、磁存儲器件、或者上述的任意合適的組合。在本文件中,計算機可讀存儲介質可以是任何包含或存儲程序的有形介質,該程序可以被指令執行系統、裝置或者器件使用或者與其結合使用。
計算機可讀的信號介質可以包括在基帶中或者作為載波一部分傳播的數據信號,其中承載了計算機可讀的程序代碼。這種傳播的數據信號可以採用多種形式,包括——但不限於——電磁信號、光信號或上述的任意合適的組合。計算機可讀的信號介質還可以是計算機可讀存儲介質以外的任何計算機可讀介質,該計算機可讀介質可以發送、傳播或者傳輸用於由指令執行系統、裝置或者器件使用或者與其結合使用的程序。
計算機可讀介質上包含的程序代碼可以用任何適當的介質傳輸,包括——但不限於——無線、電線、光纜、rf等等,或者上述的任意合適的組合。
可以以一種或多種程序設計語言或其組合來編寫用於執行本發明操作的電腦程式代碼,所述程序設計語言包括面向對象的程序設計語言—諸如java、smalltalk、c++,還包括常規的過程式程序設計語言—諸如」c」語言或類似的程序設計語言。程序代碼可以完全地在用戶計算機上執行、部分地在用戶計算機上執行、作為一個獨立的軟體包執行、部分在用戶計算機上部分在遠程計算機上執行、或者完全在遠程計算機或伺服器上執行。在涉及遠程計算機的情形中,遠程計算機可以通過任意種類的網絡——包括區域網(lan)或廣域網(wan)—連接到用戶計算機,或者,可以連接到外部計算機(例如利用網際網路服務提供商來通過網際網路連接)。
在本發明所提供的幾個實施例中,應該理解到,所揭露的裝置和方法等,可以通過其它的方式實現。例如,以上所描述的裝置實施例僅僅是示意性的,例如,所述單元的劃分,僅僅為一種邏輯功能劃分,實際實現時可以有另外的劃分方式。
所述作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位於一個地方,或者也可以分布到多個網絡單元上。可以根據實際的需要選擇其中的部分或者全部單元來實現本實施例方案的目的。
另外,在本發明各個實施例中的各功能單元可以集成在一個處理單元中,也可以是各個單元單獨物理存在,也可以兩個或兩個以上單元集成在一個單元中。上述集成的單元既可以採用硬體的形式實現,也可以採用硬體加軟體功能單元的形式實現。
上述以軟體功能單元的形式實現的集成的單元,可以存儲在一個計算機可讀取存儲介質中。上述軟體功能單元存儲在一個存儲介質中,包括若干指令用以使得一臺計算機設備(可以是個人計算機,伺服器,或者網絡設備等)或處理器(processor)執行本發明各個實施例所述方法的部分步驟。而前述的存儲介質包括:u盤、移動硬碟、只讀存儲器(rom,read-onlymemory)、隨機存取存儲器(ram,randomaccessmemory)、磁碟或者光碟等各種可以存儲程序代碼的介質。
以上所述僅為本發明的較佳實施例而已,並不用以限制本發明,凡在本發明的精神和原則之內,所做的任何修改、等同替換、改進等,均應包含在本發明保護的範圍之內。