一種音頻內容校核方法及裝置與流程
2023-06-09 10:39:41 4
本發明屬於計算機技術領域,尤其涉及一種音頻內容校核方法及裝置。
背景技術:
隨著網際網路技術的發展和移動終端(例如,MP3、MP4、智慧型手機等)的普及,音頻小說、音頻課件等音頻文件被各行各業廣泛採用,以方便用戶使用可隨身攜帶的這些移動終端或可攜式設備播放音頻文件,以收聽小說或課件等,從而進一步解放用戶的眼睛,成為用戶日常生活中閱讀小說或學習的方式之一。
目前,在製作音頻小說、音頻課件時,主要通過計算機或人工錄製,從而實現從文字到音頻的轉化,然而,由於受到時間和成本控制,音頻內容的校核大多採用人工方式,準確率不高,需要耗費較多的時間,因此,音頻製作者很少對製作的音頻內容進行後期校核,降低了音頻小說或音頻課件的質量,進而降低了用戶體驗。
技術實現要素:
本發明的目的在於提供一種音頻內容校核方法及裝置,旨在解決由於現有技術無法提供一種有效的音頻內容校核方法,導致音頻校核效率低下的問題。
一方面,本發明提供了一種音頻內容校核方法,所述方法包括下述步驟:
接收待校核的音頻文件,對所述音頻文件進行語音識別,得到識別後的文本文件;
將所述識別後的文本文件與所述音頻文件關聯的原始文本文件進行匹配,獲取不匹配文字部分所在的文本位置;
在所述音頻文件中標記出所述文本位置對應的音頻位置,輸出所述標記後的所述音頻文件。
另一方面,本發明提供了一種音頻內容校核裝置,所述裝置包括:
語音識別單元,用於接收待校核的音頻文件,對所述音頻文件進行語音識別,得到識別後的文本文件;
文本匹配單元,用於將所述識別後的文本文件與所述音頻文件關聯的原始文本文件進行匹配,獲取不匹配文字部分所在的文本位置;以及
錯誤標記單元,用於在所述音頻文件中標記出所述文本位置對應的音頻位置,輸出所述標記後的所述音頻文件。
本發明在接收待校核的音頻文件後,對音頻文件進行語音識別,得到識別後的文本文件,將識別後的文本文件與音頻文件關聯的原始文本文件進行匹配,獲取不匹配文字部分所在的文本位置,在音頻文件中標記出文本位置對應的音頻位置,輸出標記後的音頻文件,從而實現對音頻文件全自動校核並標記,提高了音頻文件的校核效率。
附圖說明
圖1是本發明實施例一提供的音頻內容校核方法的實現流程圖;
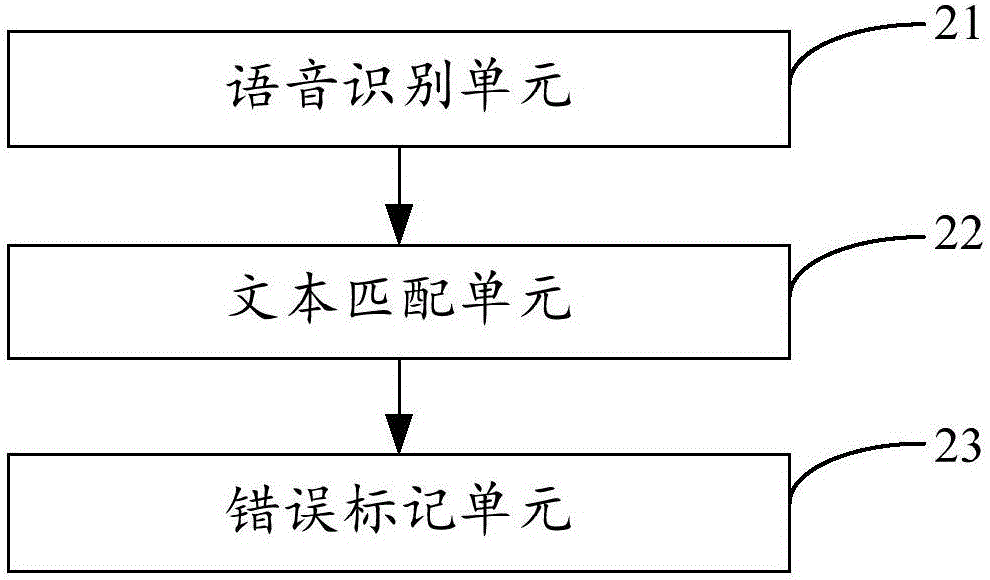
圖2是本發明實施例二提供的音頻內容校核裝置的結構示意圖;以及
圖3是本發明實施例三提供的音頻內容校核裝置的結構示意圖。
具體實施方式
為了使本發明的目的、技術方案及優點更加清楚明白,以下結合附圖及實施例,對本發明進行進一步詳細說明。應當理解,此處所描述的具體實施例僅僅用以解釋本發明,並不用於限定本發明。
以下結合具體實施例對本發明的具體實現進行詳細描述:
實施例一:
圖1示出了本發明實施例一提供的音頻內容校核方法的實現流程,為了便於說明,僅示出了與本發明實施例相關的部分,詳述如下:
在步驟S101中,接收待校核的音頻文件,對音頻文件進行語音識別,得到識別後的文本文件。
本發明實施例適用於處理音視頻文件的計算機設備或系統,以對音頻文件內容進行校核。當計算機設備或系統接收到的是視頻文件時,首先對視頻文件進行預處理,提取其中的音頻,並對音頻進行降噪等處理,以得到較為乾淨的音頻文件。
優選地,在對音頻文件進行語音識別時,根據音頻文件中的停頓標誌將音頻文件劃分為多個音頻段,記錄每個音頻段對應開始時間和停止時間,進而對多個音頻段進行語音識別,得到多個音頻段對應的文本文字,從而將音頻段和文本文字對應起來。
在本發明實施例中,音頻文件中的詞語停頓標誌是指單個詞語對應的語音之間的分隔標誌,音頻文件中的語句停頓標誌是指語句對應語音之間的分隔標誌,這樣音頻文件可被劃分或分割為單個詞語語音段或語句語音段。具體地,詞語停頓標誌和語句停頓標誌可以為靜音音頻段,進一步可根據靜音音頻段的時間長度來定義是詞語停頓標誌還是語句停頓標誌,若時間較短,則為詞語停頓標誌,若時間較長則為語句停頓標誌。當然,也可以採用其他標誌進行標記。
因此,在將音頻劃分或分割為多個音頻段時,優選地,可根據用戶設置的校核精確度設置識別時檢測的停頓標誌,根據設置的停頓標誌將音頻文件劃分為多個音頻段。作為示例地,若用戶需要得到較高精確度的校核結果時,則根據音頻文件中的詞語停頓標誌將音頻文件劃分為多個音頻段,該多個音頻段與對應的詞語對應。若用戶只需得到語句粒度的精確度的校核結果時,則根據音頻文件中的語句停頓標誌將音頻文件劃分為多個音頻段,該多個音頻段與對應的語句對應。之後對對得到的多個音頻段進行語音識別,得到多個音頻段對應的文本文字。
進一步優選地,在將音頻劃分或分割為多個音頻段時通過記錄的每個音頻段對應開始時間和停止時間,為對應的文本文字構建時間軸,以與音頻文件進行關聯,從而與音頻文件的時間軸建立一一對應關係。
在步驟S102中,將識別後的文本文件與音頻文件關聯的原始文本文件進行匹配,獲取不匹配文字部分所在的文本位置。
在本發明實施例中,待校核的音頻文件是根據原始文本文件製作得到,因此,為了對製作的音頻文件進行校核,將識別後的文本文件與音頻文件的原始文本文件進行匹配,以獲取不匹配文字部分所在的文本位置。
在步驟S103中,在音頻文件中標記出文本位置對應的音頻位置,輸出標記後的音頻文件。
在本發明實施例中,根據文本文字與音頻段的對應關係,在音頻文件中標記出文本位置對應的音頻位置,從而實現對音頻文件的自動校核,提高了校核效率。另外,可根據校核的精確度要求,通過在語音識別時設置檢測的停頓標誌將音頻劃分或分割為多個音頻段,從而提高校核的靈活度和智能化程度。
本領域普通技術人員可以理解實現上述實施例方法中的全部或部分步驟是可以通過程序來指令相關的硬體來完成,所述的程序可以存儲於一計算機可讀取存儲介質中,所述的存儲介質,如ROM/RAM、磁碟、光碟等。
實施例二:
圖2示出了本發明實施例二提供的音頻內容校核裝置的結構,為了便於說明,僅示出了與本發明實施例相關的部分,其中包括:
語音識別單元21,用於接收待校核的音頻文件,對音頻文件進行語音識別,得到識別後的文本文件;
文本匹配單元22,用於將識別後的文本文件與音頻文件關聯的原始文本文件進行匹配,獲取不匹配文字部分所在的文本位置;以及
錯誤標記單元23,用於在音頻文件中標記出文本位置對應的音頻位置,輸出所述標記後的所述音頻文件。
優選地,如圖3所示,語音識別單元21可包括:
音頻劃分單元211,用於根據音頻文件中的停頓標誌將音頻文件劃分為多個音頻段,記錄每個音頻段對應的開始時間和停止時間;以及
語音識別子單元212,用於對多個音頻段進行語音識別,得到多個音頻段對應的文本文字。
進一步地,音頻內容校核裝置還可以包括:
文件關聯單元30,用於通過記錄的每個音頻段對應的開始時間和停止時間,為對應的文本文字構建時間軸,以與音頻文件進行關聯。
在本發明實施例中,音頻內容校核裝置的各單元可由相應的硬體或軟體單元實現,各單元可以為獨立的軟、硬體單元,也可以集成為計算機設備或系統的一個軟、硬體單元,在此不用以限制本發明。音頻內容校核裝置的各單元的具體實施方式可參考實施例一對應步驟的描述,在此不再贅述。
以上所述僅為本發明的較佳實施例而已,並不用以限制本發明,凡在本發明的精神和原則之內所作的任何修改、等同替換和改進等,均應包含在本發明的保護範圍之內。