一種基於通信時空特徵的演變網絡特殊群體挖掘方法及系統與流程
2023-06-14 19:48:51 2
本發明涉及通訊單社區發現技術領域,特別涉及一種基於通信時空特徵的演變網絡特殊群體挖掘方法及系統。
背景技術:
當今社會正處於數據爆發式增長的大數據時代。人們在社交媒體上以一種前所未有的速度交流、分享、聯絡、互動,同時產生極具規模的數據。電話、簡訊這種傳統社交媒體在當今時代依舊起著溝通聯絡的主導地位。
社交媒體的發展產生了大量的數據,對於社會科學、商業發展、人類進步帶來了巨大潛力,社交媒體挖掘就是一種伴隨著社交媒體高速發展的新型研究領域,它是一種社會學與計算科學的交叉研究型學科,經常使用或綜合研究多個領域如統計學、數據挖掘、機器學習、社會心理學等。
社區也稱為群組(group)、集群(cluster)等,直觀上,是指網絡中的一些密集群體,每個社區內部的結點間的聯繫相對緊密,它在社會學領域中已經被廣泛、深入的研究。社區發現主要針對與顯示社區相對的隱式社區挖掘。本發明主要針對於,傳統通信媒體網絡的社區發現,傳統社區發現聚類算法主要有如下幾類:
現有方法一:層次聚類,假設社區是存在層次結構,計算網絡中每對節點的相似程度,根據相似程度進行進一步劃分,主要有如下兩種劃分方法:凝聚法,根據節點對的相似度從強到弱進行連接,形成樹狀圖,然後根據需求對樹狀圖進行橫切,最終獲得社區結構;分裂法,依照得出的相似度,找出節點對中相互關聯最弱的節點,刪除他們之間的邊,反覆操作將社交網絡劃分為越來越小的組件,最終連通的網絡構成社區。
現有方法二:劃分聚類,劃分聚類就是典型的機器學習中無監督學習的聚類方法,該種聚類方法很多,k-means算法是最為經典的基於劃分的聚類方法,該方法是將數據依照不同特徵標準化後計算相應的距離,往往使用歐式距離進行計算,初始以空間中隨機k個點為中心進行聚類,對最靠近他們的對象歸類,通過迭代的方法,逐次更新各聚類中心,直至得到最好的聚類結果;
現有方法三:譜聚類,建立在譜圖理論基礎上,根據給定的樣本數據集定義一個描述成對數據點相似度的拉普拉斯矩陣,並且計算矩陣的特徵值和特徵向量,然後選擇合適的特徵向量聚類不同的點。其本質是將聚類問題轉化為圖的最優劃分問題,是一種點對聚類算法。
隨著即時通信的不斷發展,演變社交網絡的研究也越來越引起社交媒體挖掘的研究者的關注,主要針對演變網絡的聚類方法有:
現有方法四:演變聚類算法,chakrabarti在2006年最先提出的演變社交網絡,並提出了一種時間平滑性框架。時間平滑性框架的是使任意時刻聚類表現的儘可能的好,並且使聚類在時間上具有平滑性。演變聚類算法就是將當前時間的聚類,跟歷史的聚類做比較得出偏差,利用時間平滑框架中的時間懲罰因子做計算,最終得出當前時刻的聚類結果。
現有方法缺陷:現有方法一,假設社區存在層級結構的基礎上進行的,傳統通信媒體網絡往往不具備層次結構,從傳統通信媒體網絡結構考慮,使用現有方法一進行社區發現不滿足條件。現有方法二,傳統劃分聚類,應用於很多領域,經實踐證明具有較好的實用效果,但針對傳統通信媒體網絡的某些具有在不定時間、不定地點集會特徵的特殊群體的挖掘方面上,不具備很強的優勢,傳統通信媒體網絡在針對案發時間和地點方面屬於演變的社交網絡,且通訊單中數據特徵不適合用於表示網絡中節點距離,固現有技術二不滿足本發明的使用場景。現有方法三,與其他兩種方法比較具有能在任意形狀的樣本空間上聚類且收斂於全局最優解的優點,而且通過計算得出的拉普拉斯矩陣的特徵向量雖然方便用於現有方法二的聚類,但在演變的社交網絡,特別是針對特殊群體集會的時間、地點等因素的演變社交網絡不滿足條件。現有方法四,雖考慮了時間的因素,但卻忽視了集會地點這個至關重要的因素,而且特殊群體集會時個體往往交替出現,演變聚類算法在使用時間代價的同時可能將不長出現的個體排除在聚類外,固現有方法四也不適用於某些會在不定時間、地點集會的特殊群體的挖掘任務。
技術實現要素:
發明人在進行針對具有不定時間不定地點集會特徵的特殊群體挖掘研究時,發現現有方法三的缺陷是由於沒有考慮到針對特殊群體的集會時間和地點等因素的考慮導致的,發明人經過調查、研究並參考現有方法四演變網絡社區發現的研究發現,在考慮特殊群體集會的案發時間和地點等因素的基礎上,將演變的傳統通信媒體網絡變成多個靜態網絡,利用現有方法三的拉普拉斯矩陣特徵向量和現有方法二的k-means聚類方法將每一個靜態網絡進行聚類,然後針對總體的演變的傳統通信媒體網絡採用投票機制挖掘出最終的特殊群體,因此本發明提出一種基於通信時空特徵的演變網絡特殊群體挖掘方法及系統。
本發明提出一種基於通信時空特徵的演變網絡特殊群體挖掘方法,包括:
步驟1,根據通信數據,獲取時間特徵數據與空間特徵數據,其中所述空間特徵數據為產生所述通信數據的地點;
步驟2,按照所述時間特徵數據與所述空間特徵數據及通信關係,構建靜態通信網絡,並構建與所述靜態通信網絡相對應的拉普拉斯矩陣,計算矩陣特徵向量,並對矩陣特徵向量進行聚類,將聚類分為特殊群體和非特殊群體兩種類簇,並獲取聚類結果;
步驟3,根據所述聚類結果,採取投票機制,獲取最終特殊群體聚類結果。
通過逆地址解析將將所述通信數據中的基站數據轉化為經緯度地點數據。
所述靜態通信網絡為無向加權通信圖。
所述步驟3中所述投票機制為設投票閾值為n,採用迭代方法找到滿足閾值的結果。
還包括對所述最終特殊群體聚類結果進行評價,評價公式為:
準確率pred的計算公式:
其中accuate是準確判斷出所述群體電話號碼的數量,n是電話號碼總個數;
召回率recall的計算公式:
其中realsum是經驗證的所述群體使用的電話號碼;
根據準確率pred與召回率recall計算評價標準f1值,計算所述評價標準f1值的計算公式如下:
本發明還提出一種基於通信時空特徵的演變網絡特殊群體挖掘系統,包括:
獲取數據模塊,用於根據通信數據,獲取時間特徵數據與空間特徵數據,其中所述空間特徵數據為產生所述通信數據的地點;
聚類模塊,用於按照所述時間特徵數據與所述空間特徵數據及通信關係,構建靜態通信網絡,並構建與所述靜態通信網絡相對應的拉普拉斯矩陣,計算矩陣特徵向量,並對矩陣特徵向量進行聚類,將聚類分為特殊群體和非特殊群體兩種類簇,並獲取聚類結果;
獲取結果模塊,用於根據所述聚類結果,採取投票機制,獲取最終特殊群體聚類結果。
通過逆地址解析將將所述通信數據中的基站數據轉化為經緯度地點數據。
所述靜態通信網絡為無向加權通信圖。
所述獲取結果模塊中所述投票機制為設投票閾值為n,採用迭代方法找到滿足閾值的結果。
還包括對所述最終特殊群體聚類結果進行評價,評價公式為:
準確率pred的計算公式:
其中accuate是準確判斷出所述群體電話號碼的數量,n是電話號碼總個數;
召回率recall的計算公式:
其中realsum是經驗證的所述群體使用的電話號碼;
根據準確率pred與召回率recall計算評價標準f1值,計算所述評價標準f1值的計算公式如下:
由以上方案可知,本發明的優點在於:
本發明可幫助用戶對具有不定時間不定地點集會特徵的特殊群體進行挖掘和發現。
附圖說明
圖1為本發明流程圖;
圖2為無向加權圖。
具體實施方式
本發明中「特殊群體」為一種具有不定時間不定地點集會特徵的隱藏群體。
以下為本發明的總體流程,如下所示:
步驟1,針對通信數據將其中的基站數據轉化為經緯度從而確定通信數據產生的地點,提取符合案件時空特徵的數據;
步驟2,將整體通信數據構建的傳統通信媒體網絡,按照每個集會的不同的時空特徵及通信關係構建靜態的通信網絡;
步驟3,按照不同時空特徵的靜態通信網絡,構建與之對應的拉普拉斯矩陣,利用譜聚類中計算矩陣特徵向量,選用合適的特徵向量,使用k-means聚類方法進行聚類,得出聚類結果;
步驟4,根據每個靜態網絡聚類結果,採用投票機制,得出最終的聚類結果,該聚類結果就是總的演變的傳統通信媒體網絡的特殊群體挖掘結果。
以下為本發明的一實施例:
如圖1所示,本發明的實驗數據來源於真實的團夥犯罪案件。根據實驗數據的通信時空特徵構建演變網絡,並從中挖掘出特殊群體即案件中的犯罪團夥,具體實施方式如下所示:
s01、根據集會時間選取符合時間特徵數據。
警察依照作案手段、手法、時間、地點的綜合考慮,實驗數據中多起案件均來自於同一個犯罪團夥。每起案件有詳細的案發時間和案發地點,即特殊群體中的集會時間和集會地點。
根據生活經驗,特殊群體在進行集會前會進行大量的聯繫,同樣按照警察刑偵經驗,團夥犯罪案件中,犯罪團夥在實施犯罪前,需要選擇犯罪地點和目標,並對目標進行觀察從而制定高效的犯罪行為,犯罪團夥在進行觀察、制定方案過程中需要通過電話、簡訊、微信等社交媒體進行大量的聯絡。
依照上述特徵,選取特殊群體集會時間,即該實驗中每起案件案發時間,該時間前幾日內的電話、簡訊數據進行保留,與集會無關的時間採取忽略策略。
s02、將lac(位置區碼)、ci(小區識別)轉換為經緯度。
從電信運營商中取得的通信數據中,有用於確定移動臺的位置標示位置區的lac(位置區碼)和具有唯一標示的運營商定義的小區編碼ci(小區識別)等兩類欄位值,通過這兩類值可以獲取到某條通信數據產生於哪個基站,將用於基站的lac(位置區碼)和ci(小區識別)轉化為地理信息系統中常使用的經緯度坐標,用以判定通信數據產生的位置。
s03、根據集會地點的經緯度選取符合空間特徵數據。
實驗數據中的每起案件的案發地點,即集會地點,通過逆地址解析的方法,將案件的案發地點轉換為地理信息系統中常使用的經緯度坐標,然後,以每起案件中案發地點經緯度為中心取一個大致範圍,根據步驟s02中轉換後的經緯度坐標,將在該區域內產生的電話、簡訊數據進行保留,不在該範圍內產生的數據則不做考慮。
s04、依照集會時空特徵獲取通信數據
傳統社交媒體中的電話和簡訊屬於即時通信範圍,即時通信的網絡會隨著時間的推演不斷產生變化。任何時間點內產生的交互數據是有限的,按照任何時間點進行社區發現是不合理的,固這裡將整體的演變網絡,取不同時間段的產生的靜態網絡進行挖掘,根據每個靜態網絡的挖掘結果,構建整個演變網絡的挖掘結果。
考慮到特殊群體的通信特點和集會流程,加入集會地點因素,即取集會地點經緯度坐標為中心的一定範圍的圓區內。按照步驟s01和s03得出的數據,取不同集會的不同的時空特徵,即集會前一段時間和集會地點一定範圍內,選取滿足條件的通信數據。
本發明實驗中則採用不同案件的時空特徵,即案發前一段時間和案發地點一定範圍內,選取滿足條件的通信數據。
s05、構建每次集會的無向加權通信圖。
無向圖g=,其中:v是非空集合,稱為頂點集;e是v中元素構成的無序二元組的集合,稱為邊集。由頂點的集合和邊的集合共同構建的沒有方向的圖,稱為無向圖。
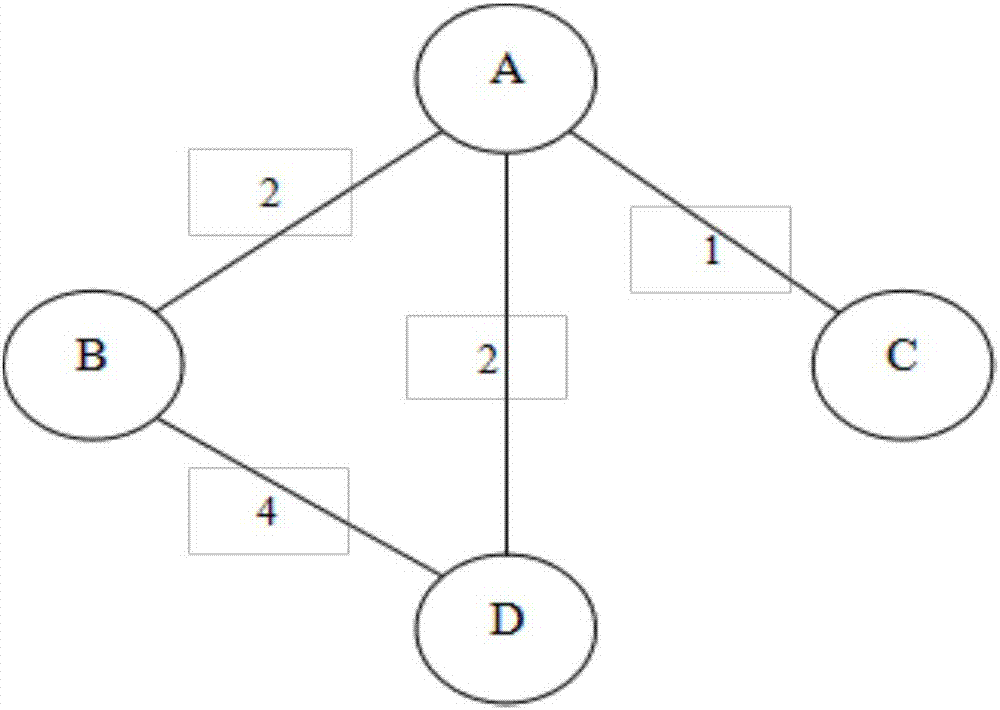
對圖的每一條邊e來說,都對應於一個實數w(e),我們把w(e)稱為邊e的權重。把這樣的無向圖g稱為無向加權圖。無向加權圖,如下圖2所示。
按照步驟s04取出滿足每次集會的時空特徵的通信數據,根據取出的通信數據,按照通信關係,即不同號碼間有過電話、簡訊等聯繫,例如號碼a與號碼b在集會時間、集會地點範圍內打過電話或者發過簡訊一次,則在網絡中將頂點a與頂點b連接並將該權重加1,通過這種方式構建每次集會,即實驗中每起案件的無向加權通信網絡,如下圖2所示,頂點a與頂點b鄰接邊權重為2,表示為號碼a與號碼b在集會時間和集會地點範圍內有過兩次聯絡。
每次集會的無向加權通信圖,就是整個演變網絡中根據不同集會時空特徵提取的靜態網絡。
s06、構建與無向加權通信圖相關的拉普拉斯矩陣。
拉普拉斯矩陣(laplacianmatrix)也叫做導納矩陣、基爾霍夫矩陣或離散拉普拉斯算子,主要應用在圖論中,作為一個圖的矩陣表示。拉普拉斯特徵向量可以將處於流形上的數據,在儘量保留原數據間相似度的情況下,映射到低維度下表示。
本發明考慮通信話單不同維度的數據特徵不具備可比較性,即使標準化後採用歐氏距離進行聚類仍存在嚴重不合理性,所以使用拉普拉斯矩陣的特徵向量降維處理,然後聚類。
拉普拉斯矩陣公式如下所示:
l=d-a
其中d是度矩陣,a是鄰接矩陣,l是拉普拉斯矩陣。
構建鄰接矩陣a,鄰接矩陣是表示頂點之間相鄰關係的矩陣,根據圖2構建的鄰接矩陣a如下所示:
構建度矩陣d,d根據圖中的入度、出度僅考慮其中一個構建的對角矩陣,在本發明中無向加權通信圖中使用度的值構建,根據圖2構建的度矩陣d如下所示:
根據拉普拉斯矩陣公式,得出圖2的拉普拉斯矩陣l如下:
根據依照s05方法構建的每次集會的無向加權通信圖,依照上述取得拉普拉斯矩陣的方法,構建與無向加權通信圖圖相關的拉普拉斯矩陣。
s07、計算每個靜態網絡的拉普拉斯矩陣求特徵向量α。
設a是n階矩陣,如果存在數λ和非零n維列向量α,使得公式成立,公式如下:
a*α=λ*α
λ是a的一個特徵值。則非零n維列向量α稱為矩陣a的對應於特徵值λ的特徵向量,簡稱a的特徵向量。
根據上述特徵值計算公式,根據s06構建的每起案件的拉普拉斯矩陣,可以得出每起案件拉普拉斯矩陣的特徵向量。
s08、對每個靜態網絡的特徵向量使用k-means進行聚類。
k-means算法的基本思想是:以空間中k個點為中心進行聚類,對最靠近他們的對象歸類。通過迭代的方法,逐次更新各聚類中心的值,直至得到最好的聚類結果。
假設要把樣本集分為c個類別,算法描述如下:
(1)隨機選擇c個類的初始中心;
(2)在第k次迭代中,對任意一個樣本,求其到c個中心的距離,將該樣本歸到距離最短的中心所在的類;
(3)利用均值等方法更新該類的中心值;
(4)對於所有的c個聚類中心,如果利用(2)(3)的迭代法更新後,中心值保持不變,則迭代結束,否則繼續迭代。
利用s07得出的每個靜態網絡的拉普拉斯矩陣的特徵向量,選擇其中合適的特徵向量使用上述算法對其劃分成兩個類,屬於特殊群體的聚類和不屬於特殊群體的聚類。從而,得出實驗數據中每起案件的犯罪團夥社區。
s09、根據每個靜態網絡挖掘出的特殊群體社區得出最終的特殊群體社區。
由根據s08的k-means算法挖掘出每個靜態網絡挖掘出的特殊群體社區,採用投票機制設票數閾值為n,在每個靜態網絡挖掘出的特殊群體社區中出現的號碼記票數為1,對每個靜態網絡挖掘出的特殊群體社區進行遍歷,計算每個號碼的票數,當號碼的票數達到閾值時,則將它記入整個演變網絡的特殊群體社區中,得出最終的特殊群體社區。
s10、對得出的結果進行評價。
用於本發明的通信數據中,有效電話號碼共1316個。團夥犯罪案件共14起,僅採用其中7起案件。最終,依照上述方法得出聚類結果共11個犯罪團夥嫌疑人電話號碼,經警方驗證,整個犯罪團夥共使用8個號碼,其中4個出現在犯罪團夥的挖掘結果中。
準確率pred的計算公式:
其中accuate是準確判斷出犯罪嫌疑人電話號碼的數量,n是挖掘結果中共多少個電話號碼。依照上述公式得出最終演變網絡的犯罪團夥社區的準確率pred約為0.364。
召回率recall的計算公式:
其中accuate是準確判斷出犯罪嫌疑人電話號碼的數量,realsum是經警方驗證的犯罪團夥使用的電話號碼。依照上述公式得出召回率recall為0.5。
利用準確率pred和召回率recall得出的結果,可以計算出更合理的評價標準f1值。f1值的計算公式如下:
依照上述公式得出整個演變網絡犯罪團夥挖掘的f1值約為0.421。
本發明還提出一種基於通信時空特徵的演變網絡特殊群體挖掘系統,包括:
獲取數據模塊,用於根據通信數據,獲取時間特徵數據與空間特徵數據,其中所述空間特徵數據為產生所述通信數據的地點;
聚類模塊,用於按照所述時間特徵數據與所述空間特徵數據及通信關係,構建靜態通信網絡,並構建與所述靜態通信網絡相對應的拉普拉斯矩陣,計算矩陣特徵向量,並對矩陣特徵向量進行聚類,將聚類分為特殊群體和非特殊群體兩種類簇,並獲取聚類結果;
獲取結果模塊,用於根據所述聚類結果,採取投票機制,獲取最終特殊群體聚類結果。
通過逆地址解析將將所述通信數據中的基站數據轉化為經緯度地點數據。
所述靜態通信網絡為無向加權通信圖。
所述獲取結果模塊中所述投票機制為設投票閾值為n,採用迭代方法找到滿足閾值的結果。
還包括對所述最終特殊群體聚類結果進行評價,評價公式為:
準確率pred的計算公式:
其中accuate是準確判斷出所述群體電話號碼的數量,n是電話號碼總個數;
召回率recall的計算公式:
其中realsum是經驗證的所述群體使用的電話號碼;
根據準確率pred與召回率recall計算評價標準f1值,計算所述評價標準f1值的計算公式如下: