一種面向數據分類的特徵權重確定方法及裝置與流程
2023-06-14 10:20:46 6
本發明涉及機器學習技術領域,特別是涉及一種面向數據分類的特徵權重確定方法及裝置。
背景技術:
數據分類問題就是根據數據的特徵對數據所屬的類別進行判定。例如,對一個國家的經濟水平,可以根據GDP、國民收入、國土面積等特徵,來判定該國家屬於發達國家或發展中國家。數據分類方法的基礎思想是,選取一些已知類別的訓練數據,確定每個訓練數據的特徵權重,並利用各特徵權重訓練多個分類器,之後利用各分類器,對未知類別的測試數據進行分類。具體地,可以計算測試數據屬於每種類別的置信度,最後將測試數據歸屬於置信度最大的類別。
現有技術中,數據分類方法主要是選取已知類別的訓練數據,然後對所有訓練數據確定一個統一的特徵權重,並利用確定的特徵權重,訓練分類器,之後利用分類器,對未知類別的測試數據進行分類。
但是,每個訓練數據對數據分類的重要程度是不同的,重要的訓練數據有助於數據分類,不重要訓練數據可能會干擾數據分類。如上述例子,訓練數據中的國土面積對經濟水平的判定不重要,而且還會干擾經濟水平的判定。這樣的話,由於每個訓練數據對數據分類的重要程度不同,如果將所有訓練數據的特徵權重設置為相同,將導致不重要的訓練數據對數據分類造成幹擾,進而致使數據分類不準確。
技術實現要素:
本發明實施例的目的在於提供一種面向數據分類的特徵權重確定方法及裝置,以準確的對數據進行分類。具體技術方案如下:
一種面向數據分類的特徵權重確定方法,包括:
獲取各類別的訓練數據,初始化每個訓練數據的當前特徵權重為相同值,並獲取預設的執行數量;
將各訓練數據的當前特徵權重確定為對應各訓練數據的第一特徵權重;
針對每個訓練數據,將該訓練數據作為第一訓練數據,並根據每個訓練數據的第一特徵權重,計算所述第一訓練數據與其他各訓練數據的歐式距離;
根據所述第一訓練數據與其他各訓練數據的歐式距離,確定其他各訓練數據的樣本權重;
根據其他各訓練數據的樣本權重、所述第一訓練數據的第一特徵權重、以及預先構建的多目標優化函數,確定所述第一訓練數據的當前特徵權重;
判斷已執行的循環次數是否為所述執行數量;如果否,返回執行所述將各訓練數據的當前特徵權重確定為對應各訓練數據的第一特徵權重的步驟。
可選地,所述根據其他各訓練數據的樣本權重、所述第一訓練數據的第一特徵權重、以及預先構建的多目標優化函數,確定所述第一訓練數據的當前特徵權重包括:
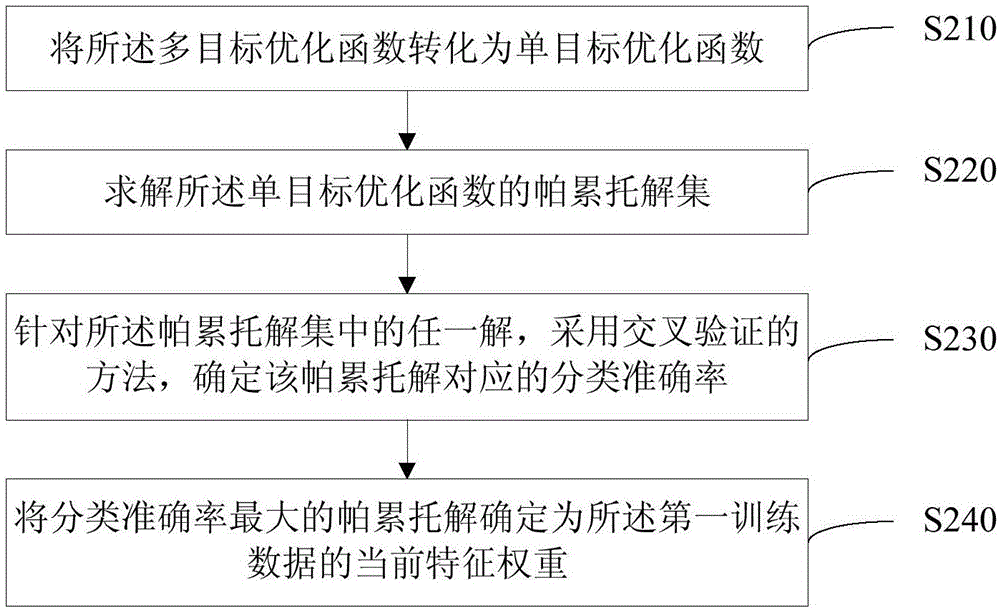
將所述多目標優化函數轉化為單目標優化函數;
求解所述單目標優化函數的帕累託解集;
針對所述帕累託解集中的任一解,採用交叉驗證的方法,確定該帕累託解對應的分類準確率;
將分類準確率最大的帕累託解確定為所述第一訓練數據的當前特徵權重。
可選地,所述針對所述帕累託解集中的任一解,採用交叉驗證的方法,確定該帕累託解對應的分類準確率包括:
針對所述帕累託解集中的任一解,利用該帕累託解確定所述第一訓練數據的分類器半徑;
針對任一其他訓練數據,根據所述第一訓練數據的分類器半徑以及所述第一訓練數據與該訓練數據的歐式距離,確定該訓練數據針對所述第一訓練數據的分類信息,其中,所述分類信息包括該訓練數據與所述第一訓練數據屬於同一類別或不屬於同一類別;
根據所確定的分類信息以及每個訓練數據的所屬類別,確定該帕累託解對應的分類準確率。
可選地,所述確定其他各訓練數據的樣本權重包括:
根據以下公式,確定當第一訓練數據為x(i)時,任一其他訓練數據x(j)(j=1,...,N,j≠i)的樣本權重:
其中,所述N為訓練數據的個數,所述為所述訓練數據x(j)(j=1,...,N,j≠i)的樣本權重,所述dij|k為所述第一訓練數據x(i)與所述訓練數據x(j)的歐式距離dij|k,所述所述為訓練數據x(k)(k=1,...,N)的第一特徵權重,所述表示向量按元素相乘,所述所述y(i)為所述第一訓練數據x(i)所屬的類別集合,所述y(j)為所述其他訓練數據x(j)所屬的類別集合。
可選地,所述多目標優化函數為:
其中,所述為與所述第一訓練數據屬於同一類別的訓練數據與所述第一訓練數據的加權距離和,所述所述f(i)為所述第一訓練數據x(i)的當前特徵權重,所述為與所述第一訓練數據不屬於同一類別的訓練數據與所述第一訓練數據的加權距離和,所述M為訓練數據的特徵維度。
可選地,所述單目標優化函數為:
其中,ε∈[0,tr(b(i))]。
為達到上述目的,本發明實施例還提供了一種面向數據分類的特徵權重確定裝置,包括:
獲取單元,用於獲取各類別的訓練數據,初始化每個訓練數據的當前特徵權重為相同值,並獲取預設的執行數量;
第一確定單元,用於將各訓練數據的當前特徵權重確定為對應各訓練數據的第一特徵權重;
計算單元,用於針對每個訓練數據,將該訓練數據作為第一訓練數據,並根據每個訓練數據的第一特徵權重,計算所述第一訓練數據與其他各訓練數據的歐式距離;
第二確定單元,用於根據所述第一訓練數據與其他各訓練數據的歐式距離,確定其他各訓練數據的樣本權重;
第三確定單元,用於根據其他各訓練數據的樣本權重、所述第一訓練數據的第一特徵權重、以及預先構建的多目標優化函數,確定所述第一訓練數據的當前特徵權重;
判斷單元,用於判斷執行的循環次數是否為所述執行數量,如果否,觸發所述第一確定單元。
可選地,所述第三確定單元包括:
轉化子單元,用於將所述多目標優化函數轉化為單目標優化函數;
求解子單元,用於求解所述單目標優化函數的帕累託解集;
第一確定子單元,用於針對所述帕累託解集中的任一解,採用交叉驗證的方法,確定該帕累託解對應的分類準確率;
第二確定子單元,用於將分類準確率最大的帕累託解確定為所述第一訓練數據的當前特徵權重。
可選地,所述第一確定子單元包括:
第一確定子模塊,用於針對所述帕累託解集中的任一解,利用該帕累託解確定所述第一訓練數據的分類器半徑;
第二確定子模塊,用於針對任一其他訓練數據,根據所述第一訓練數據的分類器半徑以及所述第一訓練數據與該訓練數據的歐式距離,確定該訓練數據針對所述第一訓練數據的分類信息,其中,所述分類信息包括該訓練數據與所述第一訓練數據屬於同一類別或不屬於同一類別;
第三確定子模塊,用於根據所確定的分類信息以及每個訓練數據的所屬類別,確定該帕累託解對應的分類準確率。
可選地,所述第二確定單元具體用於:
根據以下公式,確定當第一訓練數據為x(i)時,任一其他訓練數據x(j)(j=1,...,N,j≠i)的樣本權重:
其中,所述N為訓練數據的個數,所述為所述訓練數據x(j)(j=1,...,N,j≠i)的樣本權重,所述dij|k為所述第一訓練數據x(i)與所述訓練數據x(j)的歐式距離dij|k,所述所述為訓練數據x(k)(k=1,...,N)的第一特徵權重,所述表示向量按元素相乘,所述所述y(i)為所述第一訓練數據x(i)所屬的類別集合,所述y(j)為所述其他訓練數據x(j)所屬的類別集合。
本發明實施例提供了一種面向數據分類的特徵權重確定方法及裝置,首先獲取各類別的訓練數據,初始化每個訓練數據的當前特徵權重為相同值,並獲取預設的執行數量;然後依次執行循環次數為所述執行數量的下列步驟:將各訓練數據的當前特徵權重確定為對應各訓練數據的第一特徵權重;針對每個訓練數據,將該訓練數據作為第一訓練數據,並計算所述第一訓練數據與其他各訓練數據的歐式距離;根據所述第一訓練數據與其他各訓練數據的歐式距離,以及每個訓練數據的第一特徵權重,確定其他各訓練數據的樣本權重;根據其他各訓練數據的樣本權重、所述第一訓練數據的第一特徵權重、以及預先構建的多目標優化函數,確定所述第一訓練數據的當前特徵權重。與現有技術相比,應用本發明實施例,可以確定每個訓練數據的特徵權重,進而能夠準確的對數據進行分類。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對於本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
圖1為本發明實施例所提供的一種面向數據分類的特徵權重確定方法的流程示意圖;
圖2為本發明實施例所提供的一種面向數據分類的特徵權重確定方法中確定當前特徵權重方法的流程示意圖;
圖3為本發明實施例所提供的一種面向數據分類的特徵權重確定裝置的結構示意圖。
具體實施方式
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅僅是本發明一部分實施例,而不是全部的實施例。基於本發明中的實施例,本領域普通技術人員在沒有做出創造性勞動前提下所獲得的所有其他實施例,都屬於本發明保護的範圍。
為了能夠準確的對數據進行分類,本發明實施例提供了一種面向數據分類的特徵權重確定方法及裝置。需要說明的是,本發明實施例所提供的一種面向數據分類的特徵權重確定方法及裝置可以應用於伺服器。本實施例中的公式中所出現的參數均為各個訓練數據或測試數據在同一特徵空間中的特徵值。
如圖1所示,本實施例提供了一種面向數據分類的特徵權重確定方法,應用於伺服器,該方法包括以下步驟:
S110,獲取各類別的訓練數據,初始化每個訓練數據的當前特徵權重為相同值,並獲取預設的執行數量。
在本發明實施例中,伺服器可以針對待分析的各類別,獲取每個類別的訓練數據。例如,針對國家是否為「發達國家」和「不發達國家」兩個類別,獲取GDP數據、國民收入數據、國土面積數據,並將這些數據作為訓練數據。
然後,伺服器可以將每個訓練數據映射到同一個特徵空間,以保證每個訓練數據的特徵維度相同。之後將每個訓練數據的當前特徵權重初始化為相同值,例如可以將每個訓練數據的當前特徵權重初始化為零向量,零向量的維度為訓練數據的特徵維度。
在本發明實施例中,在伺服器獲取訓練數據之前,用戶可以根據訓練數據的收斂函數,預先設定執行數量,並將預設的執行數量保存在伺服器本地。伺服器可以在初始化每個訓練數據的當前特徵權重為相同值後,直接在本地獲取預設的執行數量。例如,用戶可以將執行數量預設為2到5之間的任一整數,並將預設的執行數量保存到伺服器本地。
S120,將各訓練數據的當前特徵權重確定為對應各訓練數據的第一特徵權重。
伺服器可以針對每個訓練數據,將該訓練數據的當前特徵權重確定為該訓練數據的第一特徵權重。
S130,針對每個訓練數據,將該訓練數據作為第一訓練數據,並根據每個訓練數據的第一特徵權重,計算所述第一訓練數據與其他各訓練數據的歐式距離。
可以理解,其他各訓練數據可以包括第一訓練數據所屬的類別中除第一訓練數據之外的其他各訓練數據,以及其他類別中的各訓練數據。
具體地,伺服器將每個訓練數據映射到同一個特徵空間後,可以首先選取一個訓練數據作為第一訓練數據x(i),然後,計算第一訓練數據x(i)與其他各訓練數據x(j)(j=1,...,N,j≠i)的歐式距離dij|k。其中,為訓練數據x(k)(k=1,...,N)的第一特徵權重,所述表示向量按元素相乘。
例如,假設第一訓練數據為x1,其他訓練數據有5個,為{x2,x3,x4,x5,x6},則伺服器在將每個訓練數據{x1,x2,x3,x4,x5,x6}映射到同一個特徵空間後,根據公式分別計算第一訓練數據x1與其他5個訓練數據{x2,x3,x4,x5,x6}的歐式距離dij|k。
需要說明的是,伺服器計算目標訓練數據與其他訓練數據的歐式距離的過程,還可以採用現有的任一種方法,本發明實施例對此不進行贅述。
S140,根據所述第一訓練數據與其他各訓練數據的歐式距離,確定其他各訓練數據的樣本權重。
具體地,可以根據以下公式,確定當第一訓練數據為x(i)時,任一其他訓練數據x(j)(j=1,...,N,j≠i)的樣本權重:
其中,所述N為訓練數據的個數,所述為所述訓練數據x(j)(j=1,...,N,j≠i)的樣本權重,所述dij|k為所述第一訓練數據x(i)與所述訓練數據x(j)的加權歐式距離dij|k,所述所述為訓練數據x(k)(k=1,...,N)的第一特徵權重,所述表示向量按元素相乘,所述所述y(i)為所述第一訓練數據x(i)所屬的類別集合,所述y(j)為所述其他訓練數據x(j)所屬的類別集合。
例如,假設第一訓練數據為x1,其他訓練數據有5個,為{x2,x3,x4,x5,x6},則確定的訓練數據x2的樣本權重為:
S150,根據其他各訓練數據的樣本權重、所述第一訓練數據的第一特徵權重、以及預先構建的多目標優化函數,確定所述第一訓練數據的當前特徵權重。
伺服器可以將確定的其他各訓練數據的樣本權重和第一訓練數據的第一特徵權重帶入到預先構建的多目標優化函數,對多目標函數進行求解,進而確定第一訓練數據的當前特徵權重。
詳細地,預先構建的多目標函數可以為:
其中,M為訓練數據的特徵維度,為與第一訓練數據屬於同一類別的訓練數據與第一訓練數據的加權距離和,f(i)為第一訓練數據x(i)的當前特徵權重,為與第一訓練數據不屬於同一類別的訓練數據與第一訓練數據的加權距離和,1T表示f(i)的各個元素相加,例如,f(1)=(a b c)T,則1Tf(1)=a+b+c。
為了方案布局清晰,後續對根據其他各訓練數據的樣本權重、第一訓練數據的第一特徵權重、以及預先構建的多目標優化函數,確定第一訓練數據的當前特徵權重的過程進行詳細介紹。
S160,判斷執行的循環次數是否為所述執行數量,如果是,結束,如果否,返回S120。
如果循環次數只有一次的話,最終確定的每個訓練數據的特徵權重的區別很小,可能無法避免不重要的訓練數據對數據分類的幹擾。因此,為了能夠準確的確定每個訓練數據的特徵權重,進而準確的對數據進行分類,可以迭代更新每個訓練數據的樣本權重以及當前特徵權重。也就是說,在確定出每個訓練數據的當前特徵權重後,伺服器可以判斷已執行的循環次數是否為預設的執行數量,如果是,結束,如果否,則返回到S120。可以理解,返回到S120時,此時,S120中,針對各訓練數據,該訓練數據的第一特徵權重為上一次循環確定該訓練數據的當前特徵權重。
應用本實施例,通過根據選定的第一訓練數據與其他各訓練數據的歐式距離以及各訓練數據的第一特徵權重,可以確定其他個訓練數據的樣本權重。並根據確定樣本權重以及第一訓練數據的第一特徵權重、以及預先構建的多目標優化函數,能夠確定第一訓練數據的當前特徵權重。可以確定每個訓練數據的特徵權重,進而能夠準確的對數據進行分類。
下面介紹根據其他各訓練數據的樣本權重、第一訓練數據的第一特徵權重、以及預先構建的多目標優化函數,確定第一訓練數據的當前特徵權重的過程,如圖2所示,該過程可以包括:
S210,將所述多目標優化函數轉化為單目標優化函數。
可以理解,為便於計算,可以對預先構建的多目標函數進行轉化,將其轉化為單目標函數。
例如,伺服器可以根據主要目標法將預先構建的多目標函數進行轉化,轉化後的單目標函數為:
其中,ε∈[0,tr(b(i))],tr(b(i))表示矩陣b(i)的對角線上元素的和。
S220,求解所述單目標優化函數的帕累託解集。
在將多目標函數轉化為單目標函數之後,伺服器可以對轉化後的單目標函數進行求解,得到單目標優化函數的帕累託解集。
例如,在求解S210中的單目標函數的過程中,可以令ε按一定間隔取值,每一個確定的ε對應一個f(i)的最優解,取遍所有ε即得到本次循環中該第一訓練數據的對應的帕累託解集。例如,ε按間隔0.05取值,則ε的取值有0,0.05,0.1,0.15,0.2……。
可以理解,伺服器求解單目標優化函數的帕累託解集的過程,可以採用現有的任一種方法,本發明實施例對此不進行贅述。
S230,針對所述帕累託解集中的任一解,採用交叉驗證的方法,確定該帕累託解對應的分類準確率。
具體地,確定該帕累託解對應的分類準確率的過程可以包括:
首先,針對所述帕累託解集中的任一解,利用該帕累託解確定第一訓練數據的分類器半徑。
具體地,假設第一訓練數據x(i)對應的帕累託解為其中β=1,2...P,P為帕累託解集中的帕累託解的個數。則第一訓練數據x(i)的分類器半徑的確定過程可以包括:獲取第一訓練數據的類別為Ci,將滿足預設條件的最大第一預設閾值確定為第一訓練數據的分類器半徑。其中,預設條件為:與第一訓練數據在下的加權距離小於第一預設閾值的所有訓練數據中,類別不屬於類別Ci的訓練數據數量與屬於類別是Ci的訓練數據數量之比小於第一預設閾值。將第一訓練數據的分類器半徑記為
需要說明的是,對於確定其他各訓練數據的分類器半徑的過程,還可以採用現有技術中的任一分類器半徑確定方法,被實施例不再贅述。
然後,針對任一其他訓練數據,確定該訓練數據針對第一訓練數據的分類信息,其中,分類信息包括該訓練數據與第一訓練數據屬於同一類別或不屬於同一類別。
具體地,可以根據以下公式,確定該訓練數據x(e),e=1,2,...,N,e≠i針對第一訓練數據x(i)的分類信息:
其中,dei為第一訓練數據x(i)與訓練數據x(e)的歐式距離,為第一訓練數據的分類器半徑,為第一訓練數據對應的帕累託解。
最後,根據所確定的分類信息以及每個訓練數據的所屬類別,確定該帕累託解對應的分類準確率。
具體地,針對任一訓練數據,如果所確定的分類信息與該訓練數據的所屬類別一致,則表示第一訓練數據對該訓練數據分類正確。例如,訓練數據x(e)與第一訓練數據x(i)屬於同一類別,且訓練數據x(e)針對第一訓練數據x(i)的分類信息為1,則該訓練數據所確定的分類信息與該訓練數據的所屬類別一致,即第一訓練數據對該訓練數據分類正確。
舉例而言,假設第一訓練數據為x1,其他訓練數據有5個,為{x2,x3,x4,x5,x6},第一訓練數據x(i)以及訓練數據x2,x3屬於類比C1,訓練數據x4,x5,x6屬於類比C2,{x2,x3,x4,x5,x6}針對第一訓練數據x(i)的分類信息分別為:{1,1,1,0,0},根據每個訓練數據的所屬類別,x4的分類信息中是錯誤的,{x2,x3,x5,x6}的分類信息中是正確的,則該帕累託解對應的分類準確率為4/5=80%。
S240,將分類準確率最大的帕累託解確定為所述第一訓練數據的當前特徵權重。
伺服器在確定出帕累託解集中的所有帕累託解對應的分類準確率後,可以將分類準確率最大的帕累託解確定為第一訓練數據的當前特徵權重。
作為本實施例的一種可選方案,在計算出每個訓練數據的特徵權重之後,該方法還可以包括:
首先,獲取測試數據x(q)。
然後,針對每個類別,計算該類別中各個訓練數據與測試數據x(q)的歐氏距離。
例如假設有三個類別,則伺服器計算測試數據x(q)與這三個類別中的每個訓練數據x(i)的歐式距離dqi。具體地,其中,f(i)為訓練數據x(i)的特徵權重。可以理解,公式中的x(q)以及x(i)為測試數據x(q)與訓練數據x(i)在同一特徵空間的特徵值。
之後,根據該類別中各個訓練數據對應的歐氏距離,以及該訓練數據的分類器半徑,確定該訓練數據針對測試數據的分類信息,其中,分類信息包括該訓練數據與測試數據屬於同一類別或不屬於同一類別。
具體地,針對該類別中每個訓練數據,根據以下公式,確定該訓練數據針對測試數據的分類信息:
其中,r(i)是該訓練數據x(i)的分類器半徑,dqi為該訓練數據x(i)與測試數據x(q)的歐氏距離,s(i)(x(q))為該訓練數據xi針對測試數據x(q)的分類信息。
例如,類別C1中有三個訓練數據{x(1),x(2),x(3)},訓練數據x(1)的分類器半徑為r(1)=0.5,測試數據x(q)與訓練數據x(1)的歐式距離為dq1=0.4,則有dq1≤r(1),則訓練數據x(1)針對測試數據x(q)的分類信息是1。
然後,根據該類別中各個訓練數據針對所述測試數據的分類信息,確定測試數據屬於該類別的置信度。
具體地,可以根據以下公式,確定測試數據屬於該類別的置信度:
其中,為測試數據x(q)屬於該類別Cl的置信度,|Cl|是該類別Cl中包括的訓練數據x(i)的數量。
例如,類別C1中有三個訓練數據{x(1),x(2),x(3)},訓練數據{x(1),x(2),x(3)}針對測試數據x(q)的分類信息分別是s(1)(x(q))=1,s(2)(x(q))=0,s(3)(x(q))=1,則測試數據x(q)屬於類別C1的置信度為
最後,確定測試數據屬於最大置信度對應的類別。
伺服器在計算出測試數據屬於每個類別的置信度後,確定測試數據屬於最大置信度對應的類別,即
例如,有三個類別C1,C2,C3,測試數據x(q)屬於每個類別的置信度為則伺服器確定測試數據x(q)屬於類別C2,即
如圖3所示,本實施例提供了一種面向數據分類的特徵權重確定裝置,應用於伺服器,該裝置包括:
獲取單元310,用於獲取各類別的訓練數據,初始化每個訓練數據的當前特徵權重為相同值,並獲取預設的執行數量;
第一確定單元320,用於將各訓練數據的當前特徵權重確定為對應各訓練數據的第一特徵權重;
計算單元330,用於針對每個訓練數據,將該訓練數據作為第一訓練數據,並計算第一訓練數據與其他各訓練數據的歐式距離;
第二確定單元340,用於根第一訓練數據與其他各訓練數據的歐式距離,以及每個訓練數據的第一特徵權重,確定其他各訓練數據的樣本權重;
第三確定單元350,用於根據其他各訓練數據的樣本權重、第一訓練數據的第一特徵權重、以及預先構建的多目標優化函數,確定第一訓練數據的當前特徵權重;
判斷單元360,用於判斷執行的循環次數是否為執行數量,如果否,觸發第一確定單元320,如果是,結束。
可選地,第三確定單元350包括:
轉化子單元(圖3中未示出),用於將多目標優化函數轉化為單目標優化函數;
求解子單元(圖3中未示出),用於求解單目標優化函數的帕累託解集;
第一確定子單元(圖3中未示出),用於針對帕累託解集中的任一解,採用交叉驗證的方法,確定該帕累託解對應的分類準確率;
第二確定子單元(圖3中未示出),用於將分類準確率最大的帕累託解確定為第一訓練數據的當前特徵權重。
可選地,第一確定子單元(圖3中未示出)包括:
第一確定子模塊(圖3中未示出),用於針對帕累託解集中的任一解,利用該帕累託解確定所述第一訓練數據的分類器半徑;
第二確定子模塊(圖3中未示出),用於針對任一其他訓練數據,根據所述第一訓練數據的分類器半徑以及所述第一訓練數據與該訓練數據的歐式距離,確定該訓練數據針對第一訓練數據的分類信息,其中,分類信息包括該訓練數據與第一訓練數據屬於同一類別或不屬於同一類別;
第三確定子模塊(圖3中未示出),用於根據所確定的分類信息以及每個訓練數據的所屬類別,確定該帕累託解對應的分類準確率。
可選地,第二確定單元340具體用於:
根據以下公式,確定當第一訓練數據為x(i)時,任一其他訓練數據x(j)(j=1,...,N,j≠i)的樣本權重:
其中,N為訓練數據的個數,為訓練數據x(j)(j=1,...,N,j≠i)的樣本權重,dij|k為第一訓練數據x(i)與訓練數據x(j)的歐式距離dij|k,為訓練數據x(k)(k=1,...,N)的第一特徵權重,表示向量按元素相乘,y(i)為第一訓練數據x(i)所屬的類別集合,y(j)為其他訓練數據x(j)所屬的類別集合。
具體地,預先構建的多目標優化函數可以為:
其中,為與第一訓練數據屬於同一類別的訓練數據與第一訓練數據的加權距離和,f(i)為第一訓練數據x(i)的當前特徵權重,為與第一訓練數據不屬於同一類別的訓練數據與第一訓練數據的加權距離和,M為訓練數據的特徵維度。
具體地,轉化後的單目標優化函數為:
其中,ε∈[0,tr(b(i))]。
需要說明的是,在本文中,諸如第一和第二等之類的關係術語僅僅用來將一個實體或者操作與另一個實體或操作區分開來,而不一定要求或者暗示這些實體或操作之間存在任何這種實際的關係或者順序。而且,術語「包括」、「包含」或者其任何其他變體意在涵蓋非排他性的包含,從而使得包括一系列要素的過程、方法、物品或者設備不僅包括那些要素,而且還包括沒有明確列出的其他要素,或者是還包括為這種過程、方法、物品或者設備所固有的要素。在沒有更多限制的情況下,由語句「包括一個……」限定的要素,並不排除在包括所述要素的過程、方法、物品或者設備中還存在另外的相同要素。
本說明書中的各個實施例均採用相關的方式描述,各個實施例之間相同相似的部分互相參見即可,每個實施例重點說明的都是與其他實施例的不同之處。尤其,對於系統實施例而言,由於其基本相似於方法實施例,所以描述的比較簡單,相關之處參見方法實施例的部分說明即可。
以上所述僅為本發明的較佳實施例而已,並非用於限定本發明的保護範圍。凡在本發明的精神和原則之內所作的任何修改、等同替換、改進等,均包含在本發明的保護範圍內。