一種增強目標語音的裝置及其方法與流程
2023-06-06 13:23:21 2
本發明涉及語音信號處理技術領域,具體地,涉及一種基於聲學矢量傳感器高階波束形成技術增強目標語音的裝置及其方法。
背景技術:
在實際環境中,麥克風在拾取語音信號時,不可避免地會受到來自周圍環境噪聲、傳輸媒介噪聲、通信設備內部電噪聲、房間混響以及其它說話人的話音幹擾,因此拾取語音的質量受到影響。語音增強技術是語音處理領域的核心技術之一,能夠實現從帶噪語音中提取乾淨的目標語音,以改善接收端語音質量,提高語音的清晰度、可懂度和舒適度,使人易於接受或提高語音處理系統的性能。
基於單個麥克風的語音增強技術的研究已經有四十多年的歷史。但是實際情況中,噪聲總是來自於四面八方,且其與語音信號在時間和頻譜上常常是相互交疊的,再加上回波和混響的影響,利用單麥克風增強感興趣的聲音並有效抑制背景噪聲和方向性強幹擾是相當困難的。引入麥克風陣列技術後,語音增強技術取得了很大突破。相比傳統的單一麥克風語音增強技術,麥克風陣列語音增強技術可以利用語音信號的空間信息來形成波束,實現對幹擾噪聲的消除,能夠保證在語音信息損失最小的條件下實現噪聲抑制(j.benesty,s.makino,andj.e.chen,speechenhancement.berlin,.germany:springer,2005.)。因此近十多年來,麥克風陣列語音增強技術已成為了語音增強技術的研究熱點和關鍵技術。然而,目前大多數的麥克風陣列語音增強技術的性能都是正比於陣列所用麥克風數目的,因此該種技術的研究往往採用較多麥克風的陣列,有的麥克風陣列甚至使用數百個麥克風,而較多的麥克風數目造成麥克風陣列的體積也較大,最典型的案例是mit搭建的用於噪聲消除和語音增強的麥克風陣列使用了1020個麥克風,其陣列孔徑有幾米長。因此麥克風陣列技術噪聲抑制性能雖好,但由於其設備體積大,算法運算複雜度高,故在實際應用時受到了許多限制。
聲學矢量傳感器(acousticvectorsensor,avs)作為音頻信號採集器。與常用的聲壓麥克風相比,avs在結構上具有其特殊性:一顆avs由2到3個正交放置的壓力梯度傳感器和1個全向壓力傳感器構成(a.nehoraiande.paldi,"vector-sensorarrayprocessingforelectromagneticsourcelocalization,"signalprocessing,ieeetransactionson,vol.42,pp.376-398,1994.),它的空間結構緊湊,傳感器近似同位放置,各個傳感器接收到的音頻信號無時延差別。對於理想的avs,各通道接收信號存在三角函數關係,因此,僅單顆avs就能夠實現單個或者多個的空間聲源到達方向的估計。隨著移動網際網路和智慧機器人等應用需求的不斷增長,具有更小體積的avs,必將使之在眾多場景中替代常規麥克風陣列技術,成為未來音頻傳感和噪聲抑制的最佳解決方案之一。
為便於描述,以二維場景為例進行說明,即只利用avs中2個正交同位放置的壓力梯度傳感器採集音頻信號的場景。實際應用中,可同理推廣至三維場景或利用更多傳感器的情形。在二維場景下,其梯度傳感器輸出的信號模型可表示為:
其中xavs(t)=[xu(t)xv(t)]t是avs的輸出信號,navs(t)=[nu(t)nv(t)]t是傳感器穩態背景噪聲,s(t)是目標聲源信號,ni(t)為幹擾源信號,i為幹擾源的數目。a(φs)=[usvs]t=[cosφssinφs]t是目標聲源的導向矢量,同理幹擾源的導向矢量為a(φi)=[uivi]t=[cosφisinφi]t。
基於avs的空間匹配波束形成器(spacialmatchedfilter,smf)的輸出可表示為:
smf波束形成器(k.t.wong,h.chi,"beampatternsofanunderwateracousticvectorhydrophonelocatedawayfromanyreflectingboundary,"ieeejournalofoceanicengineering,vol.27,no.33,pp.628-637,july2002)能夠在目標方向形成波束,其權值矢量與目標信號源的導向矢量的指向是一致的。當對目標信源到達角度φs方向進行波束形成時,smf的權值ws通常的解表示為:
ws=a(φs)/(||ah(φs)||||a(φs)||)(3)
該波束形成器對任意角度φ的聲源,波束響應可表示為:
由波束響應可知smf波束形成器能夠一定程度抑制非目標方向的幹擾聲源,但是由於smf的目標波束較寬,對幹擾方向的抑制效果十分有限,難以滿足實際應用。
技術實現要素:
本發明的目的在於克服單通道語音增強方法由於無法利用聲源的空間方位信息難以抑制空間幹擾噪聲以及傳統麥克風陣列的語音增強方法受限於陣列體積過大和計算複雜難以便攜設備的缺陷和不足,提供一種增強目標語音的裝置,該裝置能夠利用聲源方位信息有效抑制空間幹擾源和背景噪聲,對目標方向語音加以增強,增強後的目標語音失真度小,聽覺感知評價得分較高;同時該裝置具有較低的計算複雜度,極具在小型設備上的應用和推廣優勢。
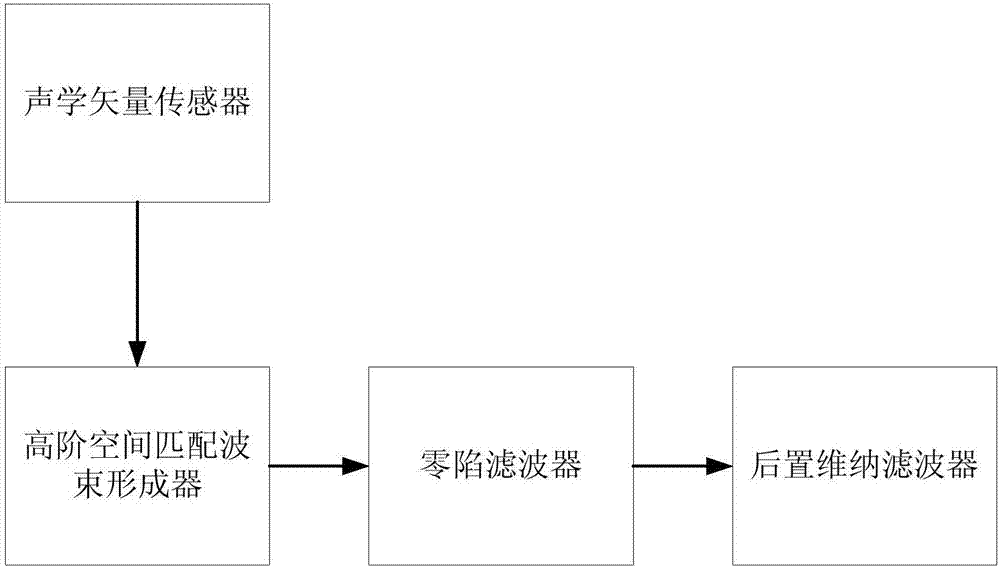
為了達到上述目的,本發明提供一種增強目標語音的裝置,所述裝置包括用於採集音頻信號的聲學矢量傳感器,所述裝置還包括:
高階空間匹配波束形成器,用於進一步收窄空間匹配波束形成器的目標波束;
零陷濾波器,用於對非目標方向的幹擾聲源進行自動跟蹤或者定位,並調整所述高階空間匹配波束形成器在主要幹擾方向形成零陷;
後置維納濾波器,用於濾除殘餘噪聲;
所述聲學矢量傳感器將採集到的音頻信號通過依次相連接的所述高階空間匹配波束形成器、零陷濾波器以及後置維納濾波器進行波束處理,即對於提取的目標方向語音信號首先通過所述高階空間匹配波束形成器對其進行波束進一步收窄處理,其次通過所述零陷濾波器對收窄後的波束在主要幹擾方向形成零陷,最後利用所述後置維納濾波器濾除殘餘噪聲,從而獲得增強的目標方向語音。
根據本發明的一個實施例,所述高階空間匹配波束形成器在任意時頻下的權值whos為:
其中,為所述高階空間匹配波束形成器的高階係數,φs為目標聲源的到達角度,a(φs)為目標聲源的導向矢量,φ為起主要作用的聲源到達角度。
根據本發明的一個實施例,當噪聲水平較小時,所述高階空間匹配波束形成器在任意時頻(k,l)下的權值whos(φs,φ,bwn,k,l)為:
其中,為所述高階空間匹配波束形成器的高階係數,φs為目標聲源的到達角度,a(φs)為目標聲源的導向矢量,φ為起主要作用的聲源到達角度,γuv(k,l)為所述聲學矢量傳感器接收信號的u通道和v通道分量數據比。
根據本發明的一個實施例,所述其中,a取值為4,b取值為16,tr為目標語音的功率
佔空間總信號功率的比率。
根據本發明的一個實施例,所述零陷濾波器在任意時頻(k,l)下的權值wni(φi,φ,bwni,k,l)為:
其中,φi為主要幹擾聲源的到達角度,φ為起主要作用的聲源到達角度,φd(k,l)=φ,bwni根據經驗取值為128。
根據本發明的一個實施例,所述後置維納濾波器在任意時頻(k,l)下的權值wpf(k,l)為:
其中,利用所述高階空間匹配波束形成器和零陷濾波器對接收信號的各通道信號做波束形成處理,並提取初步增強的目標語音時頻譜,其輸出為ys,利用空間匹配波束形成器對接收信號的各通道原始信號做固定波束形成處理,其輸出為ym,為ys和ym的互功率譜,為ym的自功率譜。
本發明的另外一個目的還在於提供一種增強目標語音的方法,所述方法包括以下步驟:
a1:對聲學矢量傳感器中的各梯度傳感器輸出數據加窗分幀,進行短時傅立葉變換,分別得到各通道傳感器的時頻譜數據;
a2:根據所述步驟a1中得到的各通道時頻譜數據獲得各通道傳感器間的相互數據比isdr,並根據所得的isdr值求得任意時頻點佔支配地位的聲源到達角度估計;
a3:對所述步驟a1中所得的各通道時頻譜數據計算聲源功率譜的空間分布,並利用目標方向的功率譜與空間總功率譜的比率配置高階空間匹配濾波階數;
a4:在短時傅立葉變換域,根據所述步驟a2獲得目標聲源到達角度和各時頻點處佔支配地位的聲源到達角度,以及根據所述步驟a3中獲得的所述濾波階數,計算空間匹配波束形成器的高階係數,完成高階空間匹配波束形成器的設計;
a5:根據所述步驟a3中的聲源功率譜的空間分布信息進一步獲得主要幹擾聲源的到達角度;
a6:根據所述步驟a5中獲得的主要幹擾聲源的到達角度以及根據所述步驟a2獲得各時頻點處佔支配地位的聲源到達角度,從而獲得零陷濾波係數,完成零陷濾波器的設計;
a7:利用所述步驟a4設計的高階空間匹配波束形成器以及所述步驟a6設計的零陷濾波器對所述步驟a1中各通道原始數據進行濾波,並提取初步增強的目標聲源的時頻譜;再根據目標聲源到達角度獲得固定波束形成器權向量,對所述步驟a1中的各通道原始數據進行固定波束形成;從而獲得後置維納濾波器的權值,完成後置維納濾波器的設計;
a8:通過所述步驟a7設計的所述後置維納濾波器對所述固定波束形成器的輸出進行濾波,並對濾波後的數據進行傅立葉反變換,用疊接相加法重建增強後的目標聲源時域信號。
根據本發明的一個實施例,所述步驟a7中,所述固定波束形成器的輸出為所述後置維納濾波器的輸入,並利用所述高階空間匹配波束形成器和零陷濾波器對接收信號的各通道信號做波束形成處理,並提取初步增強的目標語音時頻譜,獲得信號輸出為ys;利用所述空間匹配波束形成器對接收信號的各通道原始信號做固定波束形成處理,獲得信號輸出為ym;將ys和ym的互功率譜作為分子,將ym的自功率譜作為分母,兩者比值即為所述後置維納濾波器的權值。
根據本發明的一個實施例,所述步驟a2中,根據獲得各通道傳感器間的相互數據比isdr值,利用三角函數關係求得任意時頻點佔支配地位的聲源到達角度估計。
本發明相對於現有技術,具有以下有益效果:本發明增強目標語音的裝置及其方法能夠在多人說話的環境下有效地增強目標方向的語音,抑制幹擾語音,同時抑制背景噪聲;其次,本發明採用聲學矢量傳感器採集語音信號,體積小,易於在小型設備上集成,同時算法複雜度較低,易於實時運行在運算能力有限的嵌入式平臺上;最後本發明的目標語音增強方法不依賴任何先驗知識,實用性和可靠性強。
附圖說明
圖1是本發明增強目標語音的裝置的結構示意圖;
圖2為本發明實施例示意圖;
圖3為本發明實施例示意圖;
圖4為本發明實施例示意圖。
具體實施方式
下面結合實施例及附圖,對本發明作進一步地詳細說明,但本發明的實施方式不限於此。
如圖1所示為本發明一種增強目標語音的裝置的結構示意圖,該裝置包括用於採集音頻信號的聲學矢量傳感器、用於進一步收窄空間匹配波束形成器的目標波束的高階空間匹配波束形成器、用於對非目標方向的幹擾聲源進行自動跟蹤或者定位,並調整所述高階空間匹配波束形成器在主要幹擾方向形成零陷的零陷濾波器以及用於濾除殘餘噪聲的後置維納濾波器。該聲學矢量傳感器將採集到的音頻信號通過依次相連接的高階空間匹配波束形成器、零陷濾波器以及後置維納濾波器進行波束處理,即對於提取的目標方向語音信號首先通過高階空間匹配波束形成器對其進行波束進一步收窄處理,其次通過零陷濾波器對收窄後的波束在主要幹擾方向形成零陷,最後利用後置維納濾波器濾除殘餘噪聲,從而獲得增強的目標方向語音。
本發明還提供了一種增強目標語音的方法,該方法包括以下步驟:
a1:對聲學矢量傳感器中的各梯度傳感器輸出數據加窗分幀,進行短時傅立葉變換,分別得到各通道傳感器的時頻譜數據;
a2:根據步驟a1中得到的各通道時頻譜數據獲得各通道傳感器間的相互數據比isdr,並根據所得的isdr值利用三角函數可以求得任意時頻點佔支配地位的聲源到達角度估計;
a3:對步驟a1中所得的各通道時頻譜數據計算聲源功率譜的空間分布,並利用目標方向的功率譜與空間總功率譜的比率配置高階空間匹配濾波階數;
a4:在短時傅立葉變換域,根據步驟a2獲得目標聲源到達角度和各時頻點處佔支配地位的聲源到達角度,以及根據步驟a3中獲得的所述濾波階數,計算空間匹配波束形成器的高階係數,完成高階空間匹配波束形成器的設計;
a5:根據步驟a3中的聲源功率譜的空間分布信息進一步獲得主要幹擾聲源的到達角度;
a6:根據步驟a5中獲得的主要幹擾聲源的到達角度以及根據步驟a2獲得各時頻點處佔支配地位的聲源到達角度,從而獲得零陷濾波係數,完成零陷濾波器的設計;
a7:利用步驟a4設計的高階空間匹配波束形成器以及步驟a6設計的零陷濾波器對步驟a1中各通道原始數據進行濾波,並提取初步增強的目標聲源的時頻譜;再根據目標聲源到達角度獲得固定波束形成器權向量,對步驟a1中的各通道原始數據進行固定波束形成;從而獲得後置維納濾波器的權值,完成後置維納濾波器的設計;本發明實施例中,固定波束形成器的輸出為後置維納濾波器的輸入,並利用高階空間匹配波束形成器和零陷濾波器對接收信號的各通道信號做波束形成處理,並提取初步增強的目標語音時頻譜,獲得信號輸出為ys;利用空間匹配波束形成器對接收信號的各通道原始信號做固定波束形成處理,獲得信號輸出為ym;將ys和ym的互功率譜作為分子,將ym的自功率譜作為分母,兩者比值即為後置維納濾波器的權值。
a8:通過步驟a7設計的所述後置維納濾波器對所述固定波束形成器的輸出進行濾波,並對濾波後的數據進行傅立葉反變換,用疊接相加法重建增強後的目標聲源時域信號。
本發明的增強目標語音的裝置中的高階空間匹配波束形成器設計如下,其濾波器權值為(針對三維的聲學矢量傳感器為例):
其中,為高階空間匹配波束形成器的高階係數,φs為目標聲源的到達角度,a(φs)為目標聲源的導向矢量,φ為起主要作用的聲源到達角度。
則高階空間匹配波束形成器的波束響應為:
由此可見,其波束的寬度僅與bwn有關,並隨著bwn的增大而變窄,通過設置不同的bwn值能夠得到理想的波束寬度,進而抑制幹擾噪聲並增強目標語音。其具體實現方式如下:
如圖2所示為兩個純淨的語音信號,二者的空間夾角為45°,如圖3為聲學矢量傳感器的u通道和v通道拾取的混合語音信號。以16khz的採樣率對聲學矢量傳感器接收的信號進行採樣,並進行加窗分幀,分幀短時窗採用漢寧窗,窗長k=1024採樣點,傅立葉變換點數也為k,幀移50%,得到各通道的時頻譜數據:
其中,k為傅立葉變換的頻率指數,l是短時幀序號。
定義u通道傳感器與v通道傳感器之間的分量數據比(intersensordatarate,isdr)如下式:
同理,u通道傳感器與o通道傳感器間分量數據比如下式:
根據研究(李波,基於信號稀疏性的聲學矢量傳感器doa估計方法研究,碩士學位論文,北京大學,2012),語音信號在短時傅立葉域具有較好的稀疏性。當一段語音有多個說話人出現時,仍會有某些語音片段只有一個說話人處於活躍狀態而其他所有的說話人處於靜音狀態(短暫停頓或停歇)。即使在多個說話人同時處於活躍狀態的片段,不同說話人的語音信號能量在頻域仍有可能佔據不同的離散頻率。在某個具體的時頻點,可以近似的認為至多只有一個信源佔支配地位,其它信源的影響可以忽略。將此性質稱作語音的時頻域稀疏性。根據時頻稀疏性假設,在時頻數據點(k,l)處至多只有一個信源佔支配地位,不妨用sd(k,l)表示該信源,導向矢量ad(φd)=[udvd]t=[cosφdsinφd]t。考慮傳感器穩態噪聲遠小於各聲源的情況,有:
其中,ε表示分量數據比誤差分量,該誤差由假性噪聲引起,且均值為零。該時頻數據點(k,l)處信源doa角度與isdr有關。對γuv(k,l)求反餘切,有
其中,σ大小與穩態噪聲水平有關,當噪聲水平較小時,近似認為:
其中,由於反餘切函數的值域只能對應180°範圍,為求得360°範圍的φd角度,引入參數flag,其值由下式求得:
綜上,對於任意信源的到達角度φ(k,l)在時頻點(k,l)上的短時狀態,可以用φd(k,l)來估計,帶入公式(5),得:
對於bwn的取值,當環境幹擾聲源較強時,可採取較大bwn值,但不宜過大,過大的值會導致目標聲源的信息缺失。可利用φd(k,l)計算信源功率譜的空間分布,根據目標語音功率佔空間總信號功率的比率的情況,配置高階空間匹配濾波階數。本發明實施例中,採用如下方法配置高階空間匹配濾波階數。
首先計算空間總信號功率:
ew=sum(xu(k,l)x*u(k,l)+xv(k,l)x*v(k,l))(17)
下面計算目標語音功率,因目標語音未知,所以用估算為:
其中ns為一個常數,與目標語音估計的精度有關,設置為256。於是,目標語音功率佔空間總信號功率的比率為:
最後求得bwn為:
其中a和b的分別取值為4和16。
根據文獻(石偉,基於聲學矢量傳感器的魯棒doa估計方法研究與實現)的方法,對信源功率譜的空間分布信息進一步計算,得到主要幹擾信源的到達角度估計φi,如實時更新則表示為φi(k,l)。參照高階空間匹配波束形成器的設計思路,設計零陷濾波器如下:
其中,bwni的取值為128。
利用(16)所得高階空間匹配波束形成器和(21)所得零陷濾波器對(7)(8)(9)各通道信號做波束形成處理,提取初步增強的目標語音時頻譜,其輸出為:
利用公式(3)中的smf波束形成期對各通道信號做固定波束形成處理,固定波束形成器輸出為:
接下來描述後置維納濾波器權值的計算。該後置維納濾波器的輸入是固定波束形成器的輸出ym,計算ys和ym的互功率譜,作為後置濾波器權值計算公式的分子,即:
其中e[.]表示統計均值,可採用鄰近m幀結果的平均值,m的適當取值能夠有效降低音樂噪聲並減少語音失真,但取值不宜過長,會影響語音清晰度。本發明中參數m取值為2。又固定波束形成器的輸出的自功率譜為故後置維納濾波器的權值計算公式具體可表示為:
最終的增強目標語音時頻譜為:
y(k,l)=wpf(k,l)ym(k,l)(26)
最後對y(k,l)進傅立葉反變換,採用疊接相加法(overlapadd)重建時域語音信號,即獲得增強後的目標語音,如圖4所示,為分別對兩個目標信號方向增強的結果。
綜上所述,本發明的增強目標語音的裝置通過聲學矢量傳感器在空間匹配波束形成器的權值中引入高階係數,設計高階空間匹配波束形成器,進一步收窄空間波束形成器的目標波束,在提取目標方向語音的同時,較好地抑制波束外的各種幹擾噪聲。針對非目標方向的幹擾聲源,能夠自動跟蹤定位,並調整高階波束形成器在主要幹擾方向形成零陷,進一步抑制幹擾聲源。最後,利用後置維納濾波器濾除殘餘噪聲,獲得增強的目標方向語音。
上述實施例為本發明較佳的實施方式,但本發明的實施方式並不受上述實施例的限制,其他的任何未違背本發明的精神實質與原理下所作的改變、修飾、替代、組合、簡化,均應為等效的置換方式,都包含在本發明的保護範圍之內。