一種基於行動網路數據的人員出行鏈識別方法與流程
2023-06-03 18:24:16 5
本發明屬於城市規劃管理技術領域,具體涉及一種基於行動網路數據的人員出行鏈識別方法。
背景技術:
近年來,隨著GPS導航儀和智慧型手機為代表的智能終端的普及與應用,人們已經可以以相對低廉的代價獲得大量用戶的位置數據,這些數據的背後,隱含豐富的用戶行為規律信息,本專利通過對這些信息的深入挖掘和利用,闡述一種基於行動網路數據的人員出行鏈識別方法,不僅有可能發現個體用戶的日常行為規律和群體用戶的共性行為特徵,還可以掌握社交關係信息,這對於智能交通、廣告投送、面向企業的商業合作應用服務具有重要意義,為交通規劃工作提供相關數據,並具有比傳統交通調查方法更低的成本和更短的數據更新周期。
技術實現要素:
本發明的目的是根據上述現有技術的不足之處,提供一種基於行動網路數據的人員出行鏈識別方法,該識別方法根據手機用戶的行動網路數據,採用DBSCAN空間聚類方法對行動網路數據進行空間聚類分簇;根據時間相鄰不同聚類點間的速度排除異常數據,得到篩選後的用戶位置數據,選取位置代表點記錄起始時刻,生成用戶位置序列數據;關聯土地利用性質,根據位置停留時間和土地利用性質來判定用戶的停留點或移動點,最終生成用戶的出行鏈數據。
本發明目的實現由以下技術方案完成:
一種基於行動網路數據的人員出行鏈識別方法,其特徵在於所述識別方法包括以下步驟:
(步驟1)選取待識別手機用戶的行動網路數據,包括用戶ID、時間戳、基站ID、基站經緯度;
(步驟2)基於DBSCAN空間聚類方法,對所述手機用戶的行動網路數據進行空間聚類分簇,得到空間聚類分簇後的用戶位置數據,包括用戶ID、時間戳、基站經緯度、聚類簇編號;
(步驟3)將用戶位置數據中的位置點按照時間戳進行升序排序,按順序計算時間相鄰的不同位置點間的距離和速度,判定速度是否處於速度閾值[a,b]範圍內,若是則表明位置點數據合理,若否則捨棄該位置點,其中,a、b分別表示速度閾值下限和速度閾值上限;繼續下一相鄰位置點的判定,直至完成所有位置點的判定;隨後對於聚類簇編號來回切換的位置點進行篩選,篩選之後的用戶位置數據沿用原聚類簇編號,包括用戶ID、時間戳、基站經緯度、聚類簇編號;
(步驟4)對於每一聚類簇位置點集合,以相同位置的出現次數為權重選取重心位置作為該聚類簇的位置代表點,並選取該聚類簇的時間上第一條記錄的時刻作為起始時刻、最後一條記錄的時刻作為終止時刻,生成所述手機用戶的位置序列數據,包括用戶ID、起始時刻、終止時刻、位置代表點的經緯度;
(步驟5)將所述手機用戶的位置序列數據中位置代表點的經緯度與土體利用數據進行空間關聯,生成所述手機用戶含有土地利用性質的位置序列數據,包括用戶ID、起始時刻、終止時刻、位置代表點的經緯度、土地利用類型;
(步驟6)根據位置序列數據中的終止時刻與起始時刻之差計算獲得位置停留時間,根據停留時間和土地利用類型,判斷該位置點的位置狀態,所述位置狀態是指停留或移動,生成所述手機用戶的出行軌跡數據,包括用戶ID、起始時刻、終止時刻、代表點的經緯度、土地利用類型、位置狀態。
所述步驟(2)包括以下步驟:
(2.1)DBSCAN空間聚類算法中MinPts的確定,其中,MinPts是指以所述行動網路數據中某一數據點為中心的鄰域內最少點的數量;
(2.2)DBSCAN空間聚類算法中半徑Eps的確定,其中,半徑Eps是指以給定數據點為中心的圓形鄰域範圍;計算所述手機用戶每個數據點位置與其它所有數據點位置之間的歐幾裡德距離,計算每個數據點的k-距離值,並對所有數據點的k-距離值集合進行升序排列,輸出排序後的k-距離值;
其中,k值對應於MinPts,指:給定數據集P={p(i);i=0,1…n},對於任一點p(i),計算點p(i)到集合D的子集S={p(1),p(2),…,p(i-1),p(i+1),…,p(n)}中所有點之間的距離,距離按照從小到大的順序排列,假設排序後的距離集合為D={d(1),d(2),…,d(k-1),d(k),d(k+1),…,d(n)},d(k)就被成為k-距離;
將所有數據點的k-距離值使用散點圖進行顯示,計算散點圖中所有相鄰數據點間連線所成的斜率的平均值,挑選所有大於4倍斜率平均值的斜率所對應的k-距離,這些k-距離的平均值即為半徑Eps的值;
(2.3)DBSCAN空間聚類算法中核心點的計算:以點P為中心、半徑為Eps的鄰域內的點的個數不少於MinPts,則稱點P為核心點;根據Eps和MinPts,計算所有核心點,並建立核心點與到核心點距離小於半徑Eps的點的映射,即為核心點集合;
(2.4)根據核心點集合以及半徑Eps的值,計算能夠連通的核心點,將能夠連通的每一組核心點以及到核心點距離小於半徑Eps的點,都放到一起形成一個聚類簇,並進行聚類簇編號ClusterID(1,2,3…n)。
DBSCAN空間聚類算法中MinPts取4。
所述步驟(3)為:
(3.1)將聚類分簇後的用戶位置數據中的位置點記錄按照時間戳進行升序排序,選取一條記錄,若此記錄為第一條記錄則進入步驟3.2,若否則進入步驟3.3;
(3.2)選取下一條記錄,進入步驟3.3;
(3.3)判斷本記錄與上一條記錄的聚類簇編號是否相同,若相同則保留上一條記錄,並返回步驟3.2;若否則計算兩條記錄的距離和速度,若速度處於速度閾值[a,b]範圍之內,則保存本記錄,若否則捨棄本條記錄,進入步驟3.4;
(3.4)判斷記錄是否遍歷完,若遍歷完則結束,若否則返回步驟3.2;直至遍歷完所有記錄,得到經速度篩選後的用戶位置數據;
(3.5)篩選聚類簇編號來回切換的位置點,對於步驟(3.4)中得到的每一條記錄,判斷其之後10分鐘時間段內是否有位置點的聚類簇編號來回切換大於或等於4次的,若有,則保留出現次數多的位置點數據,刪除出現次數少的位置點數據;若無,則判斷下一條記錄;直至遍歷完成所有記錄。
所述步驟(4)包括以下步驟:
(4.1)以相同位置的出現次數為權重選取重心位置為位置代表點,包括步驟:對於每一聚類簇位置集合,即當聚類簇編號ClusterID=i時,該聚類簇的位置點用(LONij,LATij)表示,其中,j=1,2,3,…,m,則該聚類簇位置集合的位置代表點的經緯度為(CoreLongitudei, CoreLatitudei),其中, QUOTE, QUOTE ,將該聚類簇上所有位置點的坐標都變更為位置代表點的經緯度(CoreLongitudei, CoreLatitudei);
(4.2)生成用戶位置序列數據,包括以下步驟:
(4.2.1)將聚類簇上的位置點記錄按照時間戳生序排列,選取任一條記錄;
(4.2.2)判斷當前記錄是否為第一條記錄,若為第一條記錄,則起始時刻為當前記錄的時間,終止時刻為當前記錄時刻,繼續選取下一條記錄;若非第一條記錄,則進入步驟(4.2.3);
(4.2.3)判斷當前記錄是否與前一條記錄的聚類簇編號相同,若相同,則更新終止時刻為當前記錄的時間;若不相同,則當前記錄為另一聚類簇位置數據,則起始時刻為當前記錄的時間,終止時刻為當前記錄時刻;
(4.2.4)判斷數據是否遍歷完全,若遍歷未完全,則返回步驟(4.2.2);若遍歷完全則結束,生成用戶位置序列數據,包括用戶ID、起始時刻、終止時刻、位置代表點的經緯度。
所述步驟(5)中所述土地利用類型分為9類,包括住宅用地、商業金融業用地、交通用地、公共建築用地、工業或倉儲用地、湖泊用地、市政用地、特殊用地、其它用地。
所述步驟(6)包括以下步驟:根據位置序列數據中的終止時刻與起始時刻之差計算獲得位置停留時間,若停留時間小於1h,則位置狀態為移動;若停留時間大於1h且土地利用類型為交通用地或市政用地,則狀態為停留;若停留時間大於3h且土體利用類型為住宅用地或商業金融業用地或公共建築用地,則狀態為停留;其它情況皆為移動;生成所述手機用戶的出行軌跡數據,包括用戶ID、起始時刻、終止時刻、代表點的經緯度、土地利用類型、位置狀態。
本發明的優點是,充分依託現有的無線通信網絡信息資源,結合用地性質快速方便的進行人員出行鏈識別,為交通規劃工作提供相關數據,並具有比傳統交通調查方法更低的成本和更短的數據更新周期。
附圖說明
圖1為本發明中基於行動網路數據的人員出行鏈識別方法流程示意圖;
圖2為本發明實施例中某手機用戶的部分行動網路數據統計表;
圖3為本發明實施例中某手機用戶每個位置點與其它所有位置點之間的歐幾裡德距離統計表;
圖4為本發明實施例中某手機用戶所有位置點的4-距離集合升序排列統計表;
圖5為本發明實施例中某手機用戶所有位置點的4-距離散點圖;
圖6為本發明圖5中排名570至624的位置點所對應的4-距離散點圖;
圖7為本發明實施例中形成4個聚類簇的數據統計表;
圖8為本發明步驟3中異常點排除方法流程示意圖;
圖9為本發明實施例中聚類後全天位置數據中上午9-10點時間段數據統計表;
圖10為本發明實施例中兩條記錄之間的速度判定數據統計表;
圖11為本發明實施例中遍歷判定完所有記錄後的數據結果統計表;
圖12為本發明實施例中9:04:01至9:14:49時間段內篩選來回切換位置點數據統計表;
圖13為本發明實施例中所有時間段內篩選來回切換位置點數據統計表;
圖14為本發明步驟4中用戶位置序列數據生成方法流程示意圖;
圖15為本發明實施例中將用戶記錄按照時間戳Time升序排列的數據統計表;
圖16為本發明實施例中生成用戶位置序列數據的數據統計表;
圖17為本發明中土地利用類型分類表;
圖18為本發明實施例中生成的含有土地利用性質的位置序列數據統計表;
圖19為本發明實施例中所生成的某手機用戶的出行軌跡數據表。
具體實施方式
以下結合附圖通過實施例對本發明的特徵及其它相關特徵作進一步詳細說明,以便於同行業技術人員的理解:
實施例:如圖1所示,本實施例具體涉及一種基於行動網路數據的人員出行鏈識別方法,該人員出行鏈識別方法具體以下步驟:
【步驟1】
選取某一手機用戶全天內的行動網路數據,該行動網路數據主要包括用戶ID(UserID)、時間戳(Time)、基站ID(CELLID)、基站經緯度(Longitude,Latitude);
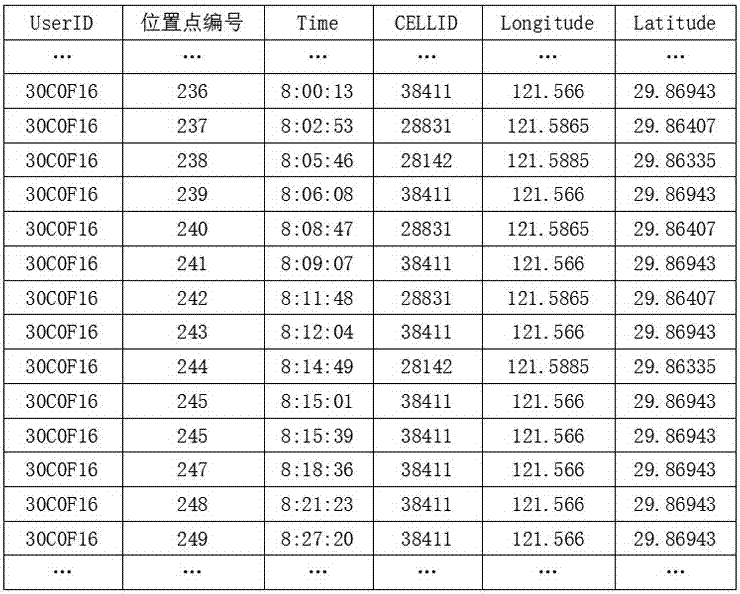
如圖2所示,本實施例中選取用戶ID為30C0F16的手機用戶在2016年4月26日的全天行動網路數據,總共672個位置點,由於位置點數量較多,因此圖2中僅列出其中部分數據。
【步驟2】
基於DBSCAN空間聚類方法,對該手機用戶的全天行動網路數據中的位置數據進行空間聚類,得到該手機用戶全天位置數據;
(步驟2.1)DBSCAN空間聚類算法中MinPts的確定:
DBSCAN空間聚類算法中的一個參數是MinPts,表示以某一位置點為中心的鄰域內最少位置點的數量;DBSCAN算法中取MinPts=4,下面確定Eps時,k-距離中設置k=4;
(步驟2.2)DBSCAN空間聚類算法中Eps的確定:
(2.2.1)DBSCAN空間聚類算法中另一個是參數半徑Eps,表示以給定位置點為中心的圓形鄰域的範圍;計算該手機用戶每個位置點與其它所有位置點之間的歐幾裡德距離,計算每個位置點的4-距離值,並對所有位置點的4-距離集合進行升序排列,輸出排序後的4-距離值;
在本實施例中,該手機用戶每個位置點與其它所有位置點之間的歐幾裡德距離如圖3所示;該手機用戶所有位置點的4-距離集合進行升序排列後如圖4所示;
(2.2.2)將如圖4中所示的4-距離值,在Excel軟體中使用散點圖顯示4-距離變化趨勢,將急劇發生變化的位置點所對應的4-距離值,確定為半徑Eps的值,如圖5所示(橫坐標是名次,縱坐標是4-距離值),排名570往後所對應的距離變化較為明顯,橫坐標排名625後變化太快可忽略;如圖6所示,進一步放大570至624所對應的4-距離;
所有相鄰位置點連線所成斜率的平均值為0.003685,則斜率均值的4倍為0.01474,大於此值所對應的4-距離值共有20個位置點,這20個平均4-距離值為540米,則半徑EPS=540米;
(步驟2.3)DBSCAN空間聚類算法中核心點計算:
以點P為中心、半徑為Eps的鄰域內的點的個數不少於MinPts,則稱點P為核心點;根據Eps=510米和MinPts=4,計算所有核心點,並建立核心點與到核心點距離小於半徑Eps的點的映射;
(步驟2.4)根據核心點集合,以及半徑Eps的值,計算能夠連通的核心點,將能夠聯通的每一組核心點,以及到核心點距離小於半徑Eps=540米的點,都放到一起,形成一個聚類簇,並進行聚類簇編號ClusterID(1,2,3…n),此實際案例中,形成4簇數據,如圖7所示。
【步驟3】
對於聚類後的全天位置數據,按照時間TIME進行升序排序,按速度(Speed)進行篩選,包括用戶ID(UserID)、時間戳(TIME)、基站經緯度(Longitude ,Latitude)、聚類簇編號(ClusterID);
如圖8、9所示,下文從聚類後的全天位置數據中選取上午9點至10點時間段,共26個記錄做具體分析:
(3.1)將聚類後的該用戶的全天位置數據按照Time進行升序排序,如下表,選取一條記錄,本案例選取時間為9:04:01的記錄,並假設為第一條記錄;
(3.2)選取下一條記錄,時間為9:07:00的記錄,作為本條記錄 ;
(3.3)本記錄9:07:00與上一條記錄09:04:01的聚類簇編號(ClusterID)均為2,保留上一條記錄;
(3.4)繼續選取下一條09:08:30記錄作為本條記錄,本記錄與上一條記錄09:07:00的聚類簇編號分別為1和2,計算兩條記錄的距離和速度;城市道路中車速一般不超過100km/h,即27m/s左右;行人速度一般1.5m/s,在此認為速度合理範圍為[1,27]m/s,速度合理範圍因地區不同而有所差異;
如圖10所示,上述兩條記錄之間速度為24.5m/s,在合理速度範圍內,保留本條09:08:30記錄;依此方法繼續遍歷數據直至遍歷完所有數據,數據結果如圖11所示;
(3.5)篩選來回切換位置點,對於如圖11表中的每一條記錄,時間向後推10分鐘,判斷這段時間內是否有位置點來回切換大於或等於4次的記錄,若有則保留出現次數多的位置點數據,刪除出現次數少的位置點數據;否則下一條記錄直至遍歷完所有記錄;此處所指的位置點來回切換具體是指位置點所屬的聚類簇編號來回變化;
以9:04:01向後10分鐘內的數據為例,即9:04:01至9:14:49這一時間段,該用戶在聚類簇編號CLUSTERID=2或1或0的位置聚類簇點之間來回切換,超過4次,聚類簇編號CLUSTERID=2或1或0的位置聚類簇點出現次數分別為:4次、1次2次;因此保留此時間段聚類簇編號CLUSTERID=2的數據,刪除此時間段聚類簇編號CLUSTERID=1或0的數據,得到如圖12所示的結果;
同樣的方法判斷9:07:00向後10分鐘內數據情況,以此類推直至全部數據,得到如圖13所示的最終位置序列數據。
【步驟4】
如圖14所示,對於每一聚類簇位置集合,以位置出現次數為權重選取重心位置作為位置代表點,並選取該聚類簇的時間上第一條記錄的時刻作為起始時刻(StartTime),選取該類的時間上最後一條記錄的時刻作為終止時刻(EndTime),生成該用戶的位置序列數據;
(4.1)對於每一聚類簇位置集合,即當聚類簇編號ClusterID=0時,這一聚類簇的位置點共有16個,獲得這一聚類簇位置集合的位置代表點的經緯度,將該聚類簇所有位置點的坐標都變更為位置代表點的經緯度;同樣的方法求出聚類簇編號ClusterID為1、2、3、4時的經緯度,分別為(121.61001,29.85892)、(121.58609,29.864989)、(121.543767,29.89086)、(121.565849,29.870109),用位置代表點的經緯度代替同一聚類簇所有位置點的經緯度;
(4.2)如圖14所示生成用戶位置序列數據
(4.2.1)將用戶記錄按照時間戳Time升序排列,選取一條記錄,時間為9:04:01,如圖15所示;
(4.2.2)假設此記錄為第一條記錄,則StartTime=9:04:01,EndTime=9:04:01;
(4.2.3)繼續選取下一條數據9:07:00,作為當前記錄,當前記錄是與上一條記錄的聚類簇編號ClusterID相同,均為2,則更新EndTime=9:07:00;
(4.2.4)繼續選取記錄,當選取9:29:21時,本記錄與上一條記錄分屬不同的聚類簇編號,則StartTime=9:29:21,EndTime=9:29:21,依次遍歷記錄,直至所有記錄;生成該用戶的位置序列數據,如圖16所示。
【步驟5】
將該手機用戶的位置序列數據的位置與土地利用數據進行空間關聯,生成該用戶的含有土地利用性質的位置序列數據,主要包括用戶ID(UserID)、起始時刻(StartTime)、終止時刻(EndTime)、代表位置經緯度(CoreLongitude , CoreLatitude)、土地利用類型(LanduseType);其中,由於土地利用類型眾多,本方法將之歸為9類,這9類包含所有土地利用類型,如圖17所示;
本實施例中所生成的含有土地利用性質的位置序列數據如圖18所示。
【步驟6】
如圖17、18所示,計算位置停留時間StayTime=EndTime-StartTime,根據停留時間和土地利用類型,判斷該位置點是停留點還是移動點,生成該用戶的出行軌跡數據。
若StayTime1h 且LanduseType為3或7,則狀態為Stay;
若StayTime>3h 且LanduseType為1或2或4,則狀態為Stay;
其他情況,狀態皆為Move;
從而得到生成該用戶的出行軌跡數據,如圖19所示。