一種社交媒體中企業硬體設施敏感信息防護方法與流程
2023-06-08 11:17:56
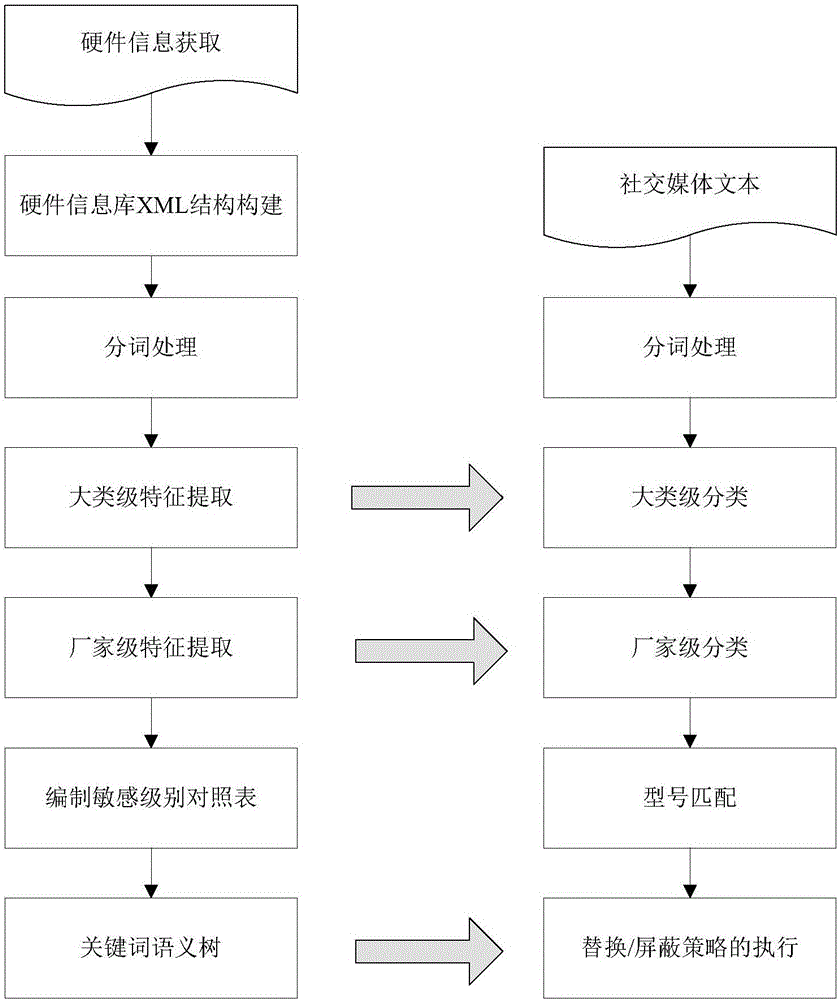
本發明涉及一種社交媒體中企業硬體設施敏感信息防護方法,屬於隱私保護
技術領域:
。
背景技術:
:伴隨著微博、網絡論壇等傳統的社交媒體以及微信、Facebook、Twitter等新興的社交媒體的出現,人們進入了社交媒體時代。社交媒體的快速興起加速了信息的流動,使得人與人之間的溝通變得越來越便捷。但不可忽視的是,社交媒體的廣泛使用也帶來了安全上的隱患,社交媒體用戶也在有意或無意地對企業或機構的機密敏感信息造成了威脅,這些信息如果被商業機構或一些不法分子非善意獲取、整合和利用,就會導致個人或機構隱私洩露[1]。行動裝置用戶可以很方便地依靠基於位置的服務獲得自己的位置和相關的服務信息。儘管基於位置的服務為用戶提供了極大的方便,但基於位置的服務需要先獲取移動用戶的位置信息才能對用戶提供相應的服務,而基於位置的服務系統並不能保證伺服器不洩露或非法使用用戶的位置信息。因此基於位置的服務給用戶的位置隱私保護帶來了極大的挑戰[2]。另外隨著近年來大數據技術的興起,基於大數據技術的隱私保護技術也越來越多,但總體上來說,當前國內外針對大數據安全與隱私保護的相關研究還不充分,只有通過技術手段與相關政策法規等相結合,才能更好地解決大數據安全與隱私保護問題[3]。隨著網際網路的廣泛應用,國內外關於隱私保護或商業機密保護的研究也越來越多。隱私保護的主要研究方向包括通用的隱私保護技術、面向數據挖掘的隱私保護技術、基於隱私保護的數據發布原則、隱私保護算法等。通用的隱私保護技術致力於在較低應用層次上保護數據的隱私,一般通過引入統計模型和概率模型來實現;面向數據挖掘的隱私保護技術主要解決在高層數據應用中,如何根據不同數據挖掘操作的特性,實現對隱私的保護;基於隱私保護的數據發布原則是為了提供一種在各類應用可以通用的隱私保護方法,進而使得在此基礎上設計的隱私保護算法也具有通用性。作為新興的研究熱點,隱私保護技術不論在理論研究還是實際應用方面,都具有非常重要的價值[4]。傳統的敏感信息防護方法主要是基於關鍵詞匹配的過濾方法,但這種方法忽視了上下文的語義環境,準確性較低,並且難以抵抗人工幹擾,需要維護大量的關鍵詞詞典,人工成本較高。新興的敏感信息防護方法包括基於自然語言處理和人工智慧的防護方法,但這些技術尚處於研究階段,並不能滿足實際情況下對於過濾準確性的要求。技術實現要素:本發明不從宏觀的角度對敏感信息的防護進行研究,而是選取隱私或商業機密保護的某一具體方面,即社交媒體中企業硬體信息保護進行研究,給出了相應的信息保護方法。如前所述,社交媒體用戶在發表言論的時候有可能導致隱私信息的洩露,同樣地,當企業內部人員在微博或論壇等社交媒體上發表言論時也有可能導致企業內部硬體型號、配置等敏感信息的洩露。為了解決上述技術問題,本發明提出了一個新的角度,即結合了文本分類和語義替換的策略進行信息防護。其基本思路是首先通過分類確定信息發布者所描述的硬體類別和型號,然後從已經建立的硬體信息庫中查找該型號硬體的所有屬性信息,並根據該屬性信息中的關鍵詞去屏蔽或替換發布者所發布的硬體描述信息中的關鍵詞。本發明的主要創新點在於構建了硬體信息庫、設計了硬體信息分類模型和硬體型號匹配算法、給出了關鍵敏感詞替換方法;本發明的技術方案具體介紹如下。本發明提供一種社交媒體中企業硬體設施敏感信息防護方法,具體步驟如下:步驟一、構建模型(1)硬體信息庫的構建獲取硬體信息,提取包括硬體大類、廠家和型號在內的多個層級、屬性和屬性值信息,組織成XML層次結構,構建硬體信息庫;(2)對硬體信息庫中的硬體描述信息進行中文分詞(3)構建硬體分類模型和硬體型號匹配算法對硬體信息庫中的硬體描述信息進行分詞後,首先提取大類的特徵信息,再在大類分類的基礎上,提取廠家的特徵信息,構建廠家分類模型;最後通過大類和廠家的類別信息,構建硬體型號匹配算法,確定硬體的型號;(4)構建關鍵詞屏蔽替換模型針對每一個硬體大類,對硬體描述信息中出現的屬性關鍵詞進行敏感級別劃分,並對不同敏感級別的關鍵詞採取不同的處理方式,構建關鍵詞屏蔽替換模型;其中,敏感級別劃分為0、1、2、3和4;對於敏感級別為0的關鍵詞不作處理,對於敏感級別為4的關鍵詞直接用星號屏蔽,對於敏感級別為1、2、3的關鍵詞通過關鍵詞語義樹進行處理;所述關鍵詞語義樹由硬體信息庫中不同層級上的關鍵詞按照XML結構關係構建;關鍵詞語義樹有四層,基於關鍵詞語義樹的替換策略如下:對於敏感級別為1的關鍵詞,採用其父節點進行替換;對於敏感級別為2的關鍵詞,採用其父節點的父節點進行替換;對於敏感級別為3的關鍵詞直接利用根節點進行替換;步驟二、檢測防護對輸入的社交媒體內容進行分詞處理後,根據步驟一中的硬體分類模型和硬體型號匹配算法確定歸屬大類、歸屬廠家和歸屬型號;確定型號後,再利用步驟一中構建的關鍵詞屏蔽替換模型,將分詞後的社交媒體內容中的屬性關鍵詞,利用對應的敏感級別和處理方式執行相應的動作,即屏蔽、替換和不作處理。本發明中,硬體分類模型中通過特徵選擇算法和分類算法對硬體大類和硬體廠家進行分類。本發明中,進行硬體大類的分類時,特徵選擇算法採用改進的信息增益的方法;具體計算公式如下:其中,t是特徵,c表示類別,k表示類別個數,dis(t)表示特徵t在類間的分布,它是特徵t出現的樣本數和所有樣本總數的比值,P(t)表示特徵出現的概率,P(c)表示類別出現的概率,P(c,t)表示特徵和類別共同出現的概率,表示特徵不出現的概率,表示特徵不出現樣本屬於類別c的概率。分類算法採用改進的KNN的方法,其中的距離計算公式如下:其中,x代表未分類樣本,y代表已分類樣本,它們都是n維向量,向量中的每一維代表一個特徵值,IG』(ti)代表第i個特徵ti的信息增益值,x=(x1,x2,…,xn),y=(y1,y2,…,yn),d(x,y)表示x和y之間的距離,xiyi表示樣本的第i個特徵值。本發明中,進行硬體廠家的分類時,特徵選擇算法採用採用特徵相似度的方法進行特徵選擇;採用類之間在特徵上的相似度來選擇特徵,定義p個類之間在特徵ti上的相似度,令這p個類分別是c1,c2,…,cp,定義這p個類在特徵ti上的相似度為任意兩個類在ti上的相似度和的平均值,即:如果則認為特徵ti在這p個類之間相似度過大,不適合作為分類的特徵,反之則可以作為分類的特徵;分類算法採用改進的KNN的方法,其選擇相似度的倒數作為特徵的權重參與到KNN算法的計算中,以下是具體的KNN的距離計算公式:其中,ci表示第i個類別,p是類別總數,ti表示第i個特徵,n為特徵總數,x=(x1,x2,…,xn),y=(y1,y2,…,yn)分別表示未分類樣本和已分類樣本,它們具有n個特徵值xiyi。本發明中,硬體型號匹配算法採用基於硬體型號集合的方法,即將相同屬性值的硬體型號放到一個集合中,通過確定待匹配硬體在某些屬性上的屬性值,從而確定該硬體所屬的型號集合,然後求這些集合的交集,得到該硬體所屬的型號。本發明中,關鍵詞語義樹的最底層的葉子結點是硬體信息庫中XML結構的最內層屬性關鍵詞的子特徵詞,語義樹的倒數第二層對應的是硬體信息庫中XML結構的最內層屬性關鍵詞,語義樹的倒數第三層是XML結構的第二層屬性關鍵詞,第四層為根結點,根節點為硬體大類的名稱。和現有技術相比,本發明具有實質性特點和顯著進步:(1)可以用於發現社交媒體內容發布時所存在的可能洩露企業硬體信息的敏感內容,提供了細粒度的內容控制方法,相比於現有方法只能對整個內容進行控制的粗粒度方式具有一定先進性,儘可能地保留了社交媒體內容共享的本質需要。(2)設計了基於大類、廠家和型號三個層次的分類和匹配方法,可以充分利用同類別的詞彙、屬性等信息,提高檢測的召回率,避免硬體敏感的洩露。同時在匹配時縮小搜索範圍,只需要在同一個廠家的信息庫中進行匹配,提高了匹配效率。(3)在硬體信息庫結構、特徵選擇、分類器構建以及防護方法上提出了新的思路和實現方法,設計了XML的結構形式,改進了信息增益計算方法,設計了基於廠家類別特徵相似度的特徵選擇方法,構建了關鍵詞語義樹,給出了具體的防護策略。附圖說明圖1是本發明的總體流程圖。圖2是硬體廠家的分類流程示意圖。圖3是硬體型號匹配方法的流程示意圖。圖4是關鍵詞屏蔽替換方法的流程圖。圖5是硬體信息庫(XML結構)圖。圖6是實施例中語義樹的每層關鍵詞和XML每層關鍵詞之間的對應關係圖。圖7是實施例中建立的語義樹的最終樣例圖。具體實施方式下面結合附圖和實施例對本發明的技術方案進行詳細說明。本發明的總體流程見圖1所示,具體包含了圖1中左邊的構建模型流程和右邊的檢測防護流程,其中模型構建流程在三個環節的處理結果為檢測防護流程提供必要的基礎數據。本發明的主要工作包括:(1)硬體信息庫的構建;(2)對硬體描述信息進行中文分詞;(3)構建硬體分類模型和硬體型號匹配算法;(4)構建關鍵詞屏蔽替換方法。下面依次對上述過程中所涉及的關鍵技術進行詳細解釋。1、硬體信息庫的構建實施例中,針對某大型電腦網,設計了網絡爬蟲程序,自動爬取了36個大類上萬種型號的硬體信息,包括手機、筆記本、交換機、路由器等。將這些硬體信息組織成XML文件的形式,其中XML的每一個標籤代表該硬體的屬性,標籤所對應的文本描述內容代表該硬體的屬性值。通過XML本身的結構描述能力,構造了樹形硬體信息庫。該硬體信息庫構成了後續處理流程所需要的基本信息源。構建的硬體信息庫(XML結構)如圖5所示。2、對硬體信息進行中文分詞雖然在第1步的工作中已經獲得了所有型號的硬體信息,但這些信息不能直接用於計算機處理,需要進行中文分詞,去掉輔助詞,提取出其中的關鍵詞,然後利用提取出的關鍵詞進行後續的分類處理等工作。目前常見的分詞方法都可以用於該步驟,例如中國科學院計算技術研究所研製的基於層次隱馬爾科夫模型的漢語詞法分析系統ICTCLAS等,支持用戶詞典和多種編碼格式,分詞正確率高達97.5%。3、構建硬體分類模型和硬體型號匹配算法在分詞的基礎上,本發明通過構建分類模型和硬體型號匹配算法來確定硬體描述信息所描述的硬體型號。而硬體分類模型包括兩個子分類過程,分別是硬體大類的分類和硬體廠家的分類,其中硬體廠家的分類是在硬體大類分類的基礎上進行的。經過這兩個步驟就可以確定硬體所屬的類別和廠家,最後通過硬體型號匹配方法就可以確定該硬體所屬的型號,下面就對這三個過程的基本思路進行描述。(1)硬體大類的分類硬體大類的分類借鑑了文本分類中的KNN分類方法,首先通過特徵選擇選出那些對分類貢獻較大的特徵詞,然後通過分類算法對硬體進行分類。本發明的特徵選擇算法和分類算法分別借鑑了信息增益的方法和KNN的方法,但針對硬體信息庫的特點進行了改進,有助於提高分類的準確性。傳統的信息增益方法只考慮了特徵詞是否出現對全局信息熵的影響,而沒有考慮特徵詞在類內和類間出現的頻率問題,本發明對傳統的信息增益方法進行了改進,考慮了特徵詞在類間的頻率,提高了特徵選擇的效果。改進的信息增益方法的計算公式如下:其中,dis(t)表示特徵t在類間的分布,它是特徵t出現的樣本數和所有樣本總數的比值。之所以選擇作為調整係數是基於以下兩個原因,首先,是dis(t)的減函數,即特徵t在類間的分布值很小的時候,比較大,這正好符合要求;其次,選擇為調整係數可以平衡傳統的信息增益值IG(t)和特徵t的類間分布值dis(t)之間的權重,使計算結果不致過多依賴某一方。同樣地,本發明對傳統的KNN算法進行了改進,改進之處在於考慮了不同的特徵對分類的影響不同,利用特徵選擇的信息增益值作為KNN算法的權重,一個特徵的信息增益值代表該特徵對信息熵的影響大小,如果信息增益值越大,則該特徵對分類的結果的影響越大,所以直接利用特徵的信息增益值作為該特徵在KNN算法中的權重,這樣就可以體現不同信息增益值的特徵對分類的貢獻度。下面給出了改進後的KNN算法中距離的計算公式。其中,x代表未分類樣本,y代表已分類樣本,它們都是n維向量,向量中的每一維代表一個特徵值。IG(ti)代表第i個特徵ti的信息增益值。x=(x1,x2,…,xn),y=(y1,y2,…,yn)。(2)硬體廠家的分類硬體大類的分類之後,硬體廠家的分類是確定硬體在該類別下的某個廠家。同樣地,在這一步的分類中需要進行特徵選擇和利用合適的分類算法進行分類。本發明所採用的特徵選擇算法是基於特徵相似度的計算方法,即針對每個特徵,考察它們在不同廠家類別之間的特徵相似度,如果該特徵相似度大於或等於某個閾值,則認為該特徵在不同廠家之間過於相似,不適合作為分類的特徵,反之則可以作為分類的特徵。同樣地,在這一部分的分類中繼續採用改進的KNN分類算法,只是將特徵的權重改為特徵相似度的倒數的對數,具體如下介紹。在硬體信息庫中,每一個硬體特徵可能會包含多個子特徵,如「外形尺寸」這一特徵的特徵值包含長、寬、高三個維度值。在這裡,長度、寬度、高度就是「外形尺寸」這一特徵的三個子特徵。假定特徵ti由n個子特徵組成,即ti=(ti1,ti2,…,tin)。某一個樣本在特徵ti上的特徵值為另外一個樣本在特徵ti上的特徵值為則定義和之間的相似度為:即利用向量之間夾角的餘弦來定義兩個特徵之間的相似度。由於所要考察的不同特徵可能包含不同的子特徵個數,即不同的維數,所以這樣做的目的是可以忽略向量的維數,著重從兩個向量夾角的角度考察兩個向量之間的相似度,當兩個向量,即兩個特徵相似時,夾角的餘弦值較大,反之則較小。定義完單個特徵的相似度之後,接下來給出兩個類之間在某個特徵上的相似度的計算方法。由於每個類可能包含多個樣本,所以假定兩個類c1和c2包含的樣本數分別是m1和m2,則定義這兩個類在特徵ti上的相似度計算如下:由上式可以看出,對兩個類在特徵ti上的相似度定義是直接取兩個類所有樣本對在特徵ti上相似度的均值,這樣做可以把兩個類之間所有樣本對在特徵ti上的相似度均考慮進去。在兩個類之間在特徵ti上的相似度計算基礎上,下面定義p個類之間在特徵ti上的相似度。令這p個類分別是c1,c2,…,cp,定義這p個類在特徵ti上的相似度為任意兩個類在ti上的相似度和的平均值,即:如果這p個類在特徵ti上的相似度大於或等於某一閾值δ,即則認為特徵ti在這p個類之間相似度過大,不適合作為分類的特徵,反之則可以作為分類的特徵。在個步驟的分類仍然採用改進的KNN算法進行分類,只是在這裡特徵的權重要發生改變,不再是信息增益值,而是特徵的相似度的倒數。之所以選擇選擇特徵相似度的倒數作為特徵的權重是基於這樣的原因,特徵相似度代表不同類別之間在該特徵上的相似程度,對於相似度較高的特徵,它們對分類的貢獻不大,應當賦予較小的權重,而對於相似度較低的特徵則對分類的貢獻較大,應當賦予較高的特徵,所以本發明選擇相似度的倒數作為特徵的權重參與到KNN算法的計算中是合理的,以下是具體的KNN的距離計算公式:硬體廠家的分類流程如下,圖2展示了相應的流程圖。1)從硬體信息庫中選擇某一類別下不同廠家的樣本;2)針對不同的特徵計算該特徵在不同廠家之間的特徵相似度;3)如果該特徵的特徵相似度小於某個閾值,則將該特徵作為分類特徵,否則返回2),選擇下一個特徵繼續計算特徵相似度;4)利用選出的特徵和改進的KNN算法進行分類,得到相應的廠家類別。(3)硬體型號的匹配在確定了硬體的類別和該類別下的廠家之後,本發明通過構建硬體型號匹配算法來確定該硬體在該廠家下的型號。本發明所採用的硬體型號匹配算法是基於硬體型號集合的方法,即將相同屬性值的硬體型號放到一個集合中,當需要確定某個硬體的型號時,只需要確定該硬體在某些屬性上的屬性值,這樣就可以確定該硬體所屬的型號集合,然後求這些集合的交集就可以得到該硬體所屬的型號。這種硬體型號匹配方法相對於逐次進行硬體型號比對來說在效率上具有很大的優勢,能夠大大減少比對的次數。在進行硬體型號匹配的時候並不是把所有的產品逐一比對一遍,而是建立了一個新的算法使比對有更高的效率。具體來說,假如該類別的產品具有n個屬性(t1,t2,…,tn),每一個屬性ti都包含ai個子特徵,即把該廠家生產的產品中在屬性ti上相同的產品劃歸到一個集合中去。並且由於某種型號的產品可能在不止一個屬性上和其他產品相同,所以該型號的產品可能在不同的集合中都會出現,也即各個集合之間可能互有交集。假如該硬體的描述信息中出現了p個屬性,分別是屬性的特徵值是則硬體型號匹配的算法描述如下:1)將屬性ti上具有相同屬性值的硬體型號放在同一個集合中;2)令i=1,C=Ω,其中Ω表示全集;3)尋找和屬性具有相同屬性值的集合4)5)如果C只包含一個元素或者i>p,則進行6),否則i=i+1,並返回3);6)返回集合C,集合C便是最終的硬體型號比對結果。圖3展示了硬體型號匹配方法的具體的流程圖,主要步驟說明如下。1)針對每一屬性構建具有相同屬性值的硬體型號集合;2)取出某一屬性,考察該硬體在該屬性上的屬性值,得到該屬性值對應的硬體型號集合;3)將該硬體型號集合和已經得到的硬體型號集合取交集,如果交集只包含一個元素或者屬性已經取完則停止,交集中的元素即為該硬體所屬的型號,否則返回2);4、構建關鍵詞屏蔽替換模型本發明通過設計關鍵詞屏蔽替換模型對硬體描述信息中所出現的有可能洩露硬體敏感信息的關鍵詞進行屏蔽替換。其針對不同的關鍵詞劃分不同的敏感級別,並對不同敏感級別的關鍵詞採取不同的處理方式。(1)關鍵詞敏感級別劃分針對每一個硬體大類,事先建立所有的屬性值關鍵詞的5個敏感級別,分別用數字0、1、2、3、4表示,它們的敏感程度依次上升,具體見表1所示。表1敏感級別對照表敏感級別01234意義不敏感稍微敏感一般敏感比較敏感十分敏感處理方式不作處理替換替換替換屏蔽對不同敏感級別的關鍵詞採取不同的處理方式。其中,對於敏感級別為0的關鍵詞不作處理,對於敏感級別為4的關鍵詞直接用星號屏蔽,對於敏感級別為1、2、3的關鍵詞通過構建語義樹的方式進行處理。(2)關鍵詞語義樹的構造通過構建語義樹的方式對敏感級別為1、2、3的關鍵詞進行替換。語義樹中葉節點是語義最具體的關鍵詞,隨著節點層次的上升,語義逐漸模糊,根結點是語義最模糊的節點。對於硬體描述信息而言,其語義樹總共有4層,基於語義樹的替換策略如下:對於敏感級別為1的關鍵詞,採用其父節點進行替換;對於敏感級別為2的關鍵詞,採用其父節點的父節點進行替換;對於敏感級別為3的關鍵詞直接利用根節點進行替換。在硬體信息庫中每一個型號硬體的XML文檔是一個層次結構,並且上層的屬性關鍵詞比下層的屬性關鍵詞的在語義上更加模糊,所以可以利用該XML文檔去建立的關鍵詞語義樹。本發明建立語義樹的方法是這樣的,最底層的葉子結點是最內層屬性關鍵詞的子特徵詞。語義樹的倒數第二層對應的是硬體信息庫中XML結構的最內層屬性關鍵詞,它們在語義上要比各自的子特徵詞更加模糊。語義樹的倒數第三層是XML結構的第二層屬性關鍵詞,由於XML文檔的第一層是該硬體的具體型號,這是十分敏感的信息,所以語義樹的倒數第四層並不對應XML文檔的第一層,而是採取了比倒數第三層語義上更加模糊的硬體大類的名稱作為該層的關鍵詞,由於倒數第四層已經上升到了硬體大類的名稱,所以該層也是整個語義樹的第一層,即根結點。圖6展示了語義樹的每層關鍵詞和XML每層關鍵詞之間的對應關係,圖7展示了建立的語義樹的最終樣例,樣例中的「第二層屬性關鍵詞」和「第三層屬性關鍵詞」均是指XML文檔中的第二層和第三層屬性關鍵詞。應用實例由於網際網路社交媒體上可得的與企業IT硬體設施相關的信息內容還不是很多,搜集起來比較困難。這裡的實例驗證中,首先從硬體信息庫中提取了5000條硬體描述的部分信息,並將這些描述信息整理成文本文檔,每一條描述信息對應一個文本文檔。所用的分詞後的關鍵詞樣本(經過隨機刪除一些關鍵詞)與從社交媒體獲取的內容處理之後是一致的,因此經過處理後的數據可以近似模擬社交媒體中的硬體描述信息樣本。從每一大類中任選60個樣本作為訓練樣本,總的訓練樣本有2160個,而每一類剩餘的40個樣本則作為待分類樣本進行測試,總共有1440個測試樣本,得到分類性能與k值的關係如表2所示。表2不同k值條件下硬體大類的正確分類比例和F1平均值參數k151015202530正確分類比例80.1%72.8%69.3%67.3%65.7%63.8%60%F1平均值0.8050.7340.7060.6890.6760.6630.639在硬體廠家分類中,以「手機」這一硬體大類為例對硬體的廠家進行分類,選取手機的八個廠家,分別是三星、蘋果、華為、OPPO、vivo、魅族、聯想、酷派。測試了不同k值條件下正確分類樣本的比例和F1平均值,得到的驗證結果如表3所示。表3不同k值條件下廠家的正確分類樣本的比例和F1平均值參數k15101520253035正確分類比例42.4%36.0%34.7%35.6%31.8%35.6%33.5%31.4%F1平均值0.4220.3500.3390.3280.2950.3190.2990.281隨機選出手機類別下的200個文本,將各個子特徵值根據其對應的子特徵詞的敏感級別進行相應的處理,最終的統計數據如表4所示。表4部分關鍵詞屏蔽替換的性能數據子特徵詞全網通移動4G聯通4G電信4G橫向子特徵詞個數20897641138正確處理的個數20897641138正確率100%100%100%100%100%參考文獻[1]郭晴.社交媒體使用中用戶信息隱私及保護[J].中國信息安全,2014,(7):90-93.[2]魏瓊,盧炎生.位置隱私保護技術研究進展[J].計算機科學,2008,35(9):21-25.[3]馮登國,張敏,李昊.大數據安全與隱私保護[J].計算機學報,2014,37(1):246-258.[4]周水庚,李豐,陶宇飛,肖小奎.面向資料庫應用的隱私保護研究綜述[J].計算機學報,2009,32(5):847-861。當前第1頁1 2 3