基於CPU和GPU的資料庫防火牆系統和其的控制方法與流程
2023-06-09 02:12:11 2
本發明涉及網際網路技術領域,尤其涉及一種基於cpu和gpu的資料庫防火牆系統和基於cpu和gpu的資料庫防火牆系統的控制方法。
背景技術:
隨著網際網路技術和信息技術的迅速發展,以資料庫為基礎的信息系統在經濟、金融、軍工、醫療等領域的信息基礎設施建設中得到了廣泛的應用,越來越多的數據信息被不同組織和機構搜集、存儲以及發布,其中大量信息被用於行業合作和數據共享,因此資料庫防火牆的應用越來越廣泛,越來越重要,同時,隨著千兆、萬兆的網絡在國內的大規模應用,那麼用戶對資料庫防火牆的吞吐量的要求越來越高。
技術實現要素:
本發明的目的旨在至少解決上述技術缺陷之一,提供一種基於cpu和gpu的資料庫防火牆系統和基於cpu和gpu的資料庫防火牆系統的控制方法。
本發明提供一種基於cpu和gpu的資料庫防火牆系統,所述系統包括:至少一個多核cpu包括cpu調度核組,cpu計算核組和cpu常規任務核組;
至少一個gpu包括gpu會話組、gpu運算組和gpu集群通信接口;
網卡與所述gpu連接,包括網卡緩存區;
系統內存分別與所述多核cpu和gpu連接,包括gpu專享內存池、cpu內存池、網卡內存池、gpu與cpu的共享內存池以及通過所述網卡內存池和gpu專享內存池進行虛擬映射形成的nic與gpu的共享內存池,其中,所述網卡內存池和網卡緩存區具有相同的物理地址;
其中,所述cpu調度核組用於根據cpu調度核組中的核數量進行網卡緩存區的對應劃分。
從上述資料庫防火牆系統的方案可以看出,通過gpu去並行處理資料庫防火牆中所有的運算任務,從而滿足大數據環境以及雲計算環境中對高吞吐量安全的需求。而且採用嵌入式gpu防火牆硬體設計架構,實現大數據環境以及雲計算環境中高性能、低能耗、低成本。
本發明還提供一種基於cpu和gpu的資料庫防火牆系統的控制方法,所述控制方法包括以下步驟:
系統初始化;
根據cpu數量以及核數量將至少一個多核cpu劃分為cpu調度核組、cpu計算核組和cpu常規任務核組;
根據gpu數量將至少一個gpu劃分為gpu會話組和gpu運算組;
將系統內存劃分為gpu專享內存池、cpu內存池、網卡內存池和gpu與cpu的共享內存池,其中,所述網卡內存池和網卡緩存區具有相同的物理地址;
將所述網卡內存池和gpu專享內存池進行虛擬映射,形成nic與gpu的共享內存池;
根據cpu調度核組中的核數量進行網卡緩存區的對應劃分;以及
對gpu集群通信接口進行初始化。
從上述控制方法的方案可以看出,通過gpu去並行處理資料庫防火牆中所有的運算任務,從而滿足大數據環境以及雲計算環境中對高吞吐量安全的需求。而且採用嵌入式gpu防火牆硬體設計架構,實現大數據環境以及雲計算環境中高性能、低能耗、低成本。
附圖說明
圖1為本發明的基於cpu和gpu的資料庫防火牆系統一種實施例的結構示意圖;
圖2為本發明的基於cpu和gpu的資料庫防火牆系統的控制方法中初始方法的一種實施例的流程圖;
圖3為本發明的基於cpu和gpu的資料庫防火牆系統的控制方法中對網絡數據包的處理方法的一種實施例的流程圖;
圖4為本發明的基於cpu和gpu的資料庫防火牆系統的控制方法中對網絡數據包的處理方法的另一種實施例的流程圖;
圖5為本發明的基於cpu和gpu的資料庫防火牆系統的控制方法中的動態任務調度算法一種實施例的流程圖。
具體實施方式
為了使本發明所解決的技術問題、技術方案及有益效果更加清楚明白,以下結合附圖及實施例,對本發明進行進一步詳細說明。應當理解,此處所描述的具體實施例僅僅用以解釋本發明,並不用於限定本發明。
本發明提供一種實施例的基於cpu和gpu的資料庫防火牆系統,如圖1所示,所述系統包括:
至少一個多核cpu1包括cpu調度核組,cpu計算核組和cpu常規任務核組;
至少一個gpu2包括gpu會話組、gpu運算組和gpu集群通信接口;
網卡3即nic與所述gpu2連接,包括網卡緩存區;
系統內存4分別與所述多核cpu1和gpu2連接,包括gpu專享內存池、cpu內存池、網卡內存池、gpu與cpu的共享內存池以及通過所述網卡內存池和gpu專享內存池進行虛擬映射形成的nic與gpu的共享內存池,其中,所述網卡內存池和網卡緩存區即nic緩衝區具有相同的物理地址;
其中,所述cpu調度核組用於根據cpu調度核組中的核數量進行網卡緩存區的對應劃分。也就是說,多核多cpu、多gpu、高速網卡、以及系統內存構成一種高吞吐量的基於cpu和gpu的資料庫防火牆系統,另外將傳統cpu集群上的大型防火牆並行應用移植到gpu集群上,顯著減少空間、能耗等硬體資源需求,而且通過過cpu、gpu的混合調度充分利用cpu和gpu,在gpu計算複雜任務的同時讓cpu做一些較為簡單的調度和計算,充分發揮多cpu的調度優勢與多gpu的計算優勢減少網絡延遲。
在具體實施中,所述cpu常規任務核組可以包括如下功能:設備配置,集中管理,審計管理以及安全策略配置等。
在具體實施中,如圖1所示,網卡3與gpu2之間實現高速內存交換機制,即實現gpu與nic之間的內存(專屬內存)交換以及gpu與系統內存(專屬內存)的交換,把處於等待狀態(或在cpu調度原則下被剝奪運行權利)的gpu的映射內存空間騰出來,同時賦予忙碌狀態的gpu或nic採用內存管理,優化算法所消耗的內存空間,內存大小是有限的,而數據流是不斷產生,充分利用有限的內存一次性處理更多的數據,以達到數據流的實時處理。
在具體實施中,當網絡數據包進入網卡緩存區時,所述cpu調度核組還用於:調度gpu會話組,以及根據動態任務調度算法將所述gpu會話組分別與網卡緩存區中的網絡數據包和任務處理進行匹配;
所述gpu會話組,用於進行全局初始化,並對與其對應匹配的網絡數據包進行對應的任務處理,以及得到會話流和將會話流標誌位存入所述系統內存中。
也就是說,cpu調度核組採用動態任務調度算法,將調度的gpu會話組與nic緩衝區進行一一對應匹配計算,可以減小系統負載不均,提高硬體資源並行計算能力,使得所有計算資源儘可能在同一時間完成執行。
在具體實施中,gpu會話組進行的任務處理包括:
對網絡數據包進行會話管理;
對網絡數據包進行l2層解析;
對網絡數據包進行tcp/ip協議的解析;
對網絡數據包進行時域會話的hash計算對時域會話的數據包進行tcp流重組;以及對時域會話的數據包進行資料庫類型識別。
也就是說,gpu會話組採用基於gpu的數據流通用處理模型,該通用模型適合於各個應用領域的多條高維時間序列數據流,它涵蓋了數據流的預處理、減負、概要抽取和挖掘處理等多項功能,能完成數據流處理時的多項任務,如查詢處理、聚類、分類、頻繁項集挖掘等。任務包括但不限於:gpu會話組針對單一數據包進行checksumandcrc;gpu會話組針對單一數據包進行l2解析;gpu會話組針對單一數據包進行tcp協議的解析;gpu會話組針對單一數據包進行session會話的hash計算;gpu會話組針對session會話的數據包進行tcp流的重組;gpu會話組針對session會話進行資料庫類型的識別。即將gpu會話組劃分為多個會話小組,比如,第一會話小組的任務處理為:對網絡數據包進行會話管理,第二會話小組的任務處理為:對網絡數據包進行l2層解析,那麼第一會話小組從匹配的網卡緩存區中得到對應的網絡數據,並對所述對應的網絡數據進行會話管理,而第二會話小組從匹配的網卡緩存區中得到對應的網絡數據,並對所述對應的網絡數據進行l2層解析。
在具體實施中,當網絡數據包進入網卡緩存區時,所述cpu調度核組還用於:調度gpu計算組,以及根據動態任務調度算法將所述gpu運算組分別與網卡緩存區中的網絡數據包和任務處理進行匹配;
所述gpu運算組,用於進行全局初始化,對所述網絡數據包進行優化處理,並對匹配且優化後的網絡數據包進行任務處理。
在具體實施中,cpu調度核組採用聯合專用線程調度策略,調度gpu運算組進行不同會話的相關運算。
在具體實施中,gpu會話組進行的任務處理包括:
對會話管理組進行數據迭代運算;
對會話管理組進行資料庫協議解析
對會話管理組進行sql語法分析;
對會話管理組進行安全策略分析;
對網絡數據包進行安全策略自學習;
對網絡數據包進行安全策略關聯分析;以及對網絡數據包進行阻斷與放行。
也就是說,gpu運算組基於多層歸約的mapreduce實現方案,主要從線程的執行方式,共享內存緩存策略和輸入數據讀取3個方面進行優化,採用多層歸約機制在map計算結束後直接進行歸約計算,以減少中間數據的存儲開銷。多層歸約機制使塊內部的並發線程可以同時分別在共享內存和全局內存上高效的執行歸約計算,避免了由於頻繁的共享內存數據換出帶來的線程同步開銷,提高了線程並發執行的效率,包括但不限於以下的運算:gpu運算組針對會話管理組的數據進行數據迭代運算;gpu運算組針對會話管理組進行資料庫協議解析;gpu運算組針對會話管理組進行sql語法分析;gpu運算組針對會話管理組進行安全策略分析;gpu運算組進行安全策略自學習;gpu運算組進行安全策略關聯分析;gpu運算組進行數據包的阻斷與放行。即將gpu運算組劃分為多個運算小組,比如,第一運算小組的任務處理為:對會話管理組進行數據迭代運算,第二運算小組的任務處理為:對會話管理組進行資料庫協議解析,那麼第一會話小組從匹配的網卡緩存區中得到對應的網絡數據,並對會話管理組進行數據迭代運算,而第二會話小組從匹配的網卡緩存區中得到對應的網絡數據,並對會話管理組進行資料庫協議解析。
從上述資料庫防火牆系統的方案可以看出,通過gpu去並行處理資料庫防火牆中所有的運算任務,從而滿足大數據環境以及雲計算環境中對高吞吐量安全的需求。而且採用嵌入式gpu防火牆硬體設計架構,實現大數據環境以及雲計算環境中高性能、低能耗、低成本。進一步通過提供板間數據傳輸重疊化機制、片上內存虛擬地址管理、以及軟硬體任務並執行調度算法等優化策略,能夠對大數據應用取得可觀的性能功耗優勢。基於gpu的異構計算系統及並行計算模式使得大量傳統串行算法轉移到並行計算平臺上的並行化實現成為可能,無論是從高性能計算的成本控制、精度要求還是並行計算在硬體設備和應用服務之間的關鍵作用來說,基於gpu的高性能並行優化算法具有應用價值。另外,雲安全是大數據時代信息安全的體現,它融合了並行處理、網格計算、未知病毒行為判斷等新興技術和概念,高吞吐量的資料庫防火牆能夠有效地提高資料庫系統環境的安全,為雲機算環境的推廣與普及提供安全保障和技術支撐。
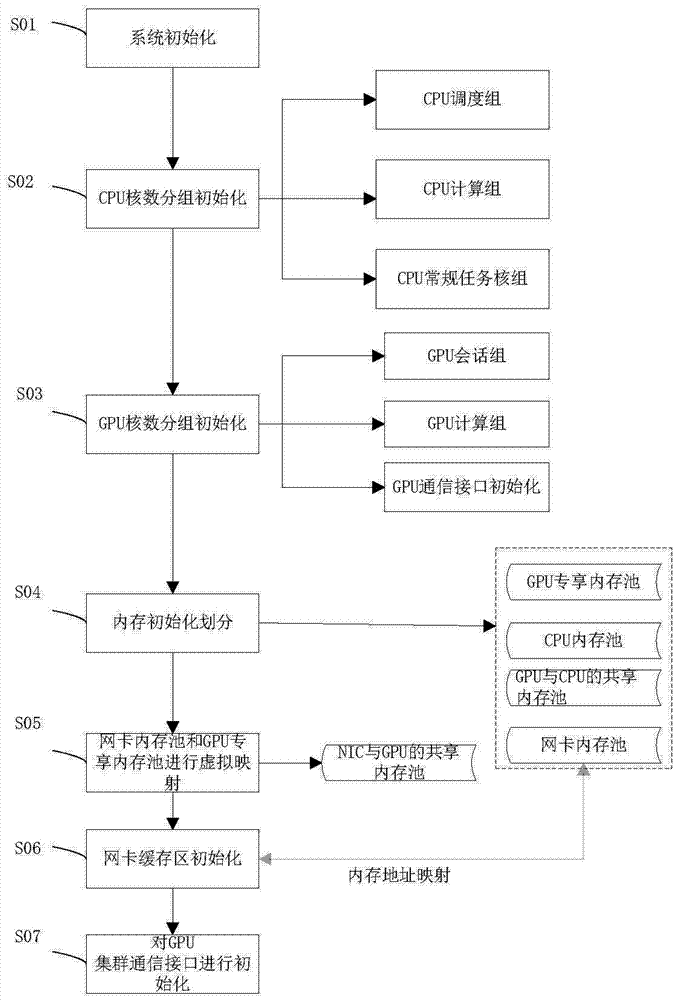
在具體實施中,本發明還提供一種實施例的基於cpu和gpu的資料庫防火牆系統的控制方法,如圖2所示,所述控制方法包括以下步驟:
步驟s01,系統初始化;
步驟s02,根據cpu數量以及核數量將至少一個多核cpu劃分為cpu調度核組、cpu計算核組和cpu常規任務核組;
步驟s03,根據gpu數量將至少一個gpu劃分為gpu會話組和gpu運算組;
步驟s04,將系統內存劃分為gpu專享內存池、cpu內存池、網卡內存池和gpu與cpu的共享內存池,其中,所述網卡內存池和網卡緩存區具有相同的物理地址;
步驟s05,將所述網卡內存池和gpu專享內存池進行虛擬映射,形成nic與gpu的共享內存池;
步驟s06,根據cpu調度核組中的核數量進行網卡緩存區的對應劃分,以及網卡緩存區與網卡內存池進行虛擬映射使得所述網卡內存池和網卡緩存區具有相同的物理地址即進行網卡緩存區初始化;
步驟s07,對gpu集群通信接口進行初始化。
也就是說,將傳統cpu集群上的大型防火牆並行應用移植到gpu集群上,顯著減少空間、能耗等硬體資源需求,而且通過過cpu、gpu的混合調度充分利用cpu和gpu,在gpu計算複雜任務的同時讓cpu做一些較為簡單的調度和計算,充分發揮多cpu的調度優勢與多gpu的計算優勢減少網絡延遲。
在具體實施中,如圖3所示,對網絡數據包的處理方法,在步驟s07之後還包括以下步驟:
步驟s31,當網絡數據包進入網卡緩存區時,cpu調度核組調度gpu會話組;
步驟s32,gpu會話組從系統內存映射中獲取數據包的物理地址;
步驟s33,gpu會話組進行全局初始化;
步驟s34,cpu調度核組根據動態任務調度算法將所述gpu會話組分別與網卡緩存區中的網絡數據包和任務處理進行匹配;
步驟s35,gpu會話組與其對應匹配的網絡數據包進行對應的任務處理,得到會話流並將會話流標誌位存入所述系統內存中。
也就是說,cpu調度核組採用動態任務調度算法,將調度的gpu會話組與nic緩衝區進行一一對應匹配計算,可以減小系統負載不均,提高硬體資源並行計算能力,使得所有計算資源儘可能在同一時間完成執行。
在具體實施中,gpu會話組進行的任務處理包括:
對網絡數據包進行會話管理;
對網絡數據包進行l2層解析;
對網絡數據包進行tcp/ip協議的解析;
對網絡數據包進行時域會話的hash計算
對時域會話的數據包進行tcp流重組;以及對時域會話的數據包進行資料庫類型識別。
也就是說,gpu會話組採用基於gpu的數據流通用處理模型,該通用模型適合於各個應用領域的多條高維時間序列數據流,它涵蓋了數據流的預處理、減負、概要抽取和挖掘處理等多項功能,能完成數據流處理時的多項任務,如查詢處理、聚類、分類、頻繁項集挖掘等。任務包括但不限於:gpu會話組針對單一數據包進行checksumandcrc;gpu會話組針對單一數據包進行l2解析;gpu會話組針對單一數據包進行tcp協議的解析;gpu會話組針對單一數據包進行session會話的hash計算;gpu會話組針對session會話的數據包進行tcp流的重組;gpu會話組針對session會話進行資料庫類型的識別。即將gpu會話組劃分為多個會話小組,比如,第一會話小組的任務處理為:對網絡數據包進行會話管理,第二會話小組的任務處理為:對網絡數據包進行l2層解析,那麼第一會話小組從匹配的網卡緩存區中得到對應的網絡數據,並對所述對應的網絡數據進行會話管理,而第二會話小組從匹配的網卡緩存區中得到對應的網絡數據,並對所述對應的網絡數據進行l2層解析。
在具體實施中,如圖4所示,對網絡數據包的處理方法,在步驟s07或步驟s35之後還包括以下步驟:
s41,當網絡數據包進入網卡緩存區時,cpu調度核組調度gpu運算組;
s42,gpu運算組從系統內存映射中獲取數據包的物理地址;
s43,gpu運算組進行全局初始化;
s44,gpu運算組對所述網絡數據包進行優化處理;
s45,cpu調度核組根據動態任務調度算法將所述gpu運算組分別與網卡緩存區中的網絡數據包和任務處理進行匹配;
s46,gpu運算組與其對應匹配的網絡數據包進行對應的任務處理。
在具體實施中,cpu調度核組採用聯合專用線程調度策略,調度gpu運算組進行不同會話的相關運算。
在具體實施中,gpu會話組進行的任務處理包括:
對會話管理組進行數據迭代運算;
對會話管理組進行資料庫協議解析
對會話管理組進行sql語法分析;
對會話管理組進行安全策略分析;
對網絡數據包進行安全策略自學習;
對網絡數據包進行安全策略關聯分析;以及對網絡數據包進行阻斷與放行。
在具體實施中,所述gpu運算組對所述網絡數據包進行優化處理的步驟,具體包括:
數據加載;
數據分割;以及統計中間鍵值對應的歸約頻率也就是說,gpu運算組基於多層歸約的mapreduce實現方案,主要從線程的執行方式,共享內存緩存策略和輸入數據讀取3個方面進行優化,採用多層歸約機制在map計算結束後直接進行歸約計算,以減少中間數據的存儲開銷。多層歸約機制使塊內部的並發線程可以同時分別在共享內存和全局內存上高效的執行歸約計算,避免了由於頻繁的共享內存數據換出帶來的線程同步開銷,提高了線程並發執行的效率,包括但不限於以下的運算:gpu運算組針對會話管理組的數據進行數據迭代運算;gpu運算組針對會話管理組進行資料庫協議解析;gpu運算組針對會話管理組進行sql語法分析;gpu運算組針對會話管理組進行安全策略分析;gpu運算組進行安全策略自學習;gpu運算組進行安全策略關聯分析;gpu運算組進行數據包的阻斷與放行。即將gpu運算組劃分為多個運算小組,比如,第一運算小組的任務處理為:對會話管理組進行數據迭代運算,第二運算小組的任務處理為:對會話管理組進行資料庫協議解析,那麼第一會話小組從匹配的網卡緩存區中得到對應的網絡數據,並對會話管理組進行數據迭代運算,而第二會話小組從匹配的網卡緩存區中得到對應的網絡數據,並對會話管理組進行資料庫協議解析。
在具體實施中,如圖5所示,所述動態任務調度算法具體包括以下步驟:
步驟s51,判斷是否第一次運行,如果是,進入步驟s52,如果否,進入步驟s55;
步驟s52,任務隨機分配;
步驟s53,計算每個gpu的負載量;
步驟s54,計算每個gpu的計算速率,返回步驟s51;
步驟s55,預處理;
步驟s56,更新每個gpu的負載量;
步驟s57,更新每個gpu的計算速率;
步驟s58,減負;
步驟s59,概要抽取;
步驟s510,對兩次負載和兩次計算速率的差值進行加權;
步驟s511,判斷加權的差值是否達到穩定速率或負載量的20%,如果是,進入步驟s512,如果否,返回步驟s55;
步驟s512,任務執行。
在步驟s512中,對於gpu會話組則執行與gpu會話組對應的任務,對於gpu運算組則執行與gpu運算組對應的任務。
在具體實施中,實現單次掃描算法,不允許任何可以暫時阻塞數據流的操作,所有的數據只能掃描一次。
從上述控制方法的方案可以看出,通過gpu去並行處理資料庫防火牆中所有的運算任務,從而滿足大數據環境以及雲計算環境中對高吞吐量安全的需求。而且採用嵌入式gpu防火牆硬體設計架構,實現大數據環境以及雲計算環境中高性能、低能耗、低成本。進一步通過提供板間數據傳輸重疊化機制、片上內存虛擬地址管理、以及軟硬體任務並執行調度算法等優化策略,能夠對大數據應用取得可觀的性能功耗優勢。基於gpu的異構計算系統及並行計算模式使得大量傳統串行算法轉移到並行計算平臺上的並行化實現成為可能,無論是從高性能計算的成本控制、精度要求還是並行計算在硬體設備和應用服務之間的關鍵作用來說,基於gpu的高性能並行優化算法具有應用價值。另外,雲安全是大數據時代信息安全的體現,它融合了並行處理、網格計算、未知病毒行為判斷等新興技術和概念,高吞吐量的資料庫防火牆能夠有效地提高資料庫系統環境的安全,為雲機算環境的推廣與普及提供安全保障和技術支撐。
以上所述僅為本發明的較佳實施例而已,並不用以限制本發明,凡在本發明的精神和原則之內所作的任何修改、等同替換和改進等,均應包含在本發明的保護範圍之內。