一種基於專利引文的新興技術識別方法與流程
2023-06-11 10:22:41 3
本發明涉及計算機數據挖掘領域,具體涉及一種基於專利引文的新興技術識別方法。
背景技術:
當今世界,科技的發展已經進入到了一個前所未有的時代。新興技術發展勢頭強勁,進步速度迅猛,技術類型層出不窮。新興技術是新技術的一部分,反過來,新技術就不一定屬於新興技術,正因如此,在所有新技術中對新興技術進行有效識別就顯得至關重要,它將直接關乎到我們的經濟、科技的發展速度。隨著社會發展與科技進步,各領域裡大量的新興技術如雨後春筍般湧現出來。但是真正能夠進入市場並產生較大社會影響的卻是寥寥無幾,因而,誰能率先識別並應用這些技術指導生產實踐,誰就能在競爭中脫穎而出,從而引領群雄。隨著社會的發展,新興技術識別的手段和方法越來越多,複雜性也越來越高,識別難度也在逐步增大。
識別方法主要分為主觀識別方法和基於文獻的識別方法。最早的新興技術識別方法主要採用專家討論的形式來實現,此方法比較便捷,主觀方法取決於專家的個人經驗和能力,存在追隨權威和隨眾現象,以及缺乏客觀評價標準等弊端。隨著計算機技術的發展,人們收集處理數據能力越來越強。基於文獻的新興技術識別方法成為主要的研究趨勢。依據文獻來源分為基於非專利文獻與專利文獻測新興技術識別方法。主要採用文本聚類技術、主題提取、共詞分析、網絡演化等方法對新興技術的識別進行實證研究,利用這些方法來識別新興技術。通過從這些文獻中抽取特徵詞來構成實體,然後在構建識別模型,在一定程度上降低了主觀性的影響,但是特徵詞抽取的難度較大,而且會造成信息損失。
在新興技術識別中,目標技術和新興技術的依賴性起到了關鍵的作用,並且技術發展越快,新興技術的作用就越突出。正因如此,在所有新技術中對新興技術進行有效識別就顯得至關重要,它將直接關乎到中國的經濟、科技的發展速度。隨著社會的全面發展,各大領域裡的新興技術快速的湧現出來。但是真正能夠進入市場並產生較大社會影響的卻是寥寥無幾,因而,誰能率先識別並應用這些技術指導生產實踐,誰就能在競爭中脫穎而出,從而引領群雄。
技術實現要素:
本發明通過對特徵化處理的引文數據進行新興技術標註與識別。採用聚類方法對特徵化的引文信息進行聚類,將相似特徵信息的專利數據劃分到同一個聚族,再利用往年的新興技術與專利分類號得關係對聚族進行新興技術標註,利用標註的數據訓練分類器,將新興技術的識別問題轉化為一個分類問題。
基於專利引文的新興技術識別方法,所述方法包括以下步驟:
s1特徵化用於訓練的引文資料庫;
s2將在t+1年公布的每一項專利依據其主分類號進行分組,將分組記為gy;
s3如果該主分類號是t+1年新建立的,將gy標註為新技術分組,否則記為非新技術分組;
s4對於t年中所有專利根據專利引文特徵向量進行聚類,將聚簇記為cx;
s5對於t年的任一計算與t+1年所有分組cy的專利同引的耦合度;
s6找到與專利同引的耦合度最高的分組;
s7如果為新興技術分組,將聚簇標記為新興技術,否則標記為非新型技術;
s8循環步驟4,直至t年所有的聚簇cx被標記完畢;
s9循環步驟1,直至專利數據除了年份最大的其他專利都完成聚類與標註;
s10採用標註數據訓練分類器;
s11使用該分類器判定基於專利引文特徵向量的聚簇是否為新興技術。
所述步驟s1中,特徵化引文資料庫是指引文數據表達(或者特徵)的選擇,既抽取引文或專利文件的部分指標數據作為特徵數據,多個特徵數據構成特徵向量,例如選取權利要求項數、引文總數量、非專利文獻引文數量、專利分類號、技術生命周期、被引技術的相似性指數、被引技術所有者平均相似性指數等作為特徵向量。
所述步驟s5中,專利同引的耦合度是指聚簇cx和gy的文獻耦合相似度(bcs),計算公式為:
本發明的技術效果或優點:
相比現有的技術方案,本發明提出的基於專利引文分析的新興技術識別方法可以降低現有識別方法的主觀性,簡化了特徵提取的複雜度,可以客觀快速的對專利數據進行新興技術標註,這些標註數據可以用於訓練各種分類器,因此該方法具有良好的可擴展性,可以高效迅速準確的預測新興技術。
附圖說明
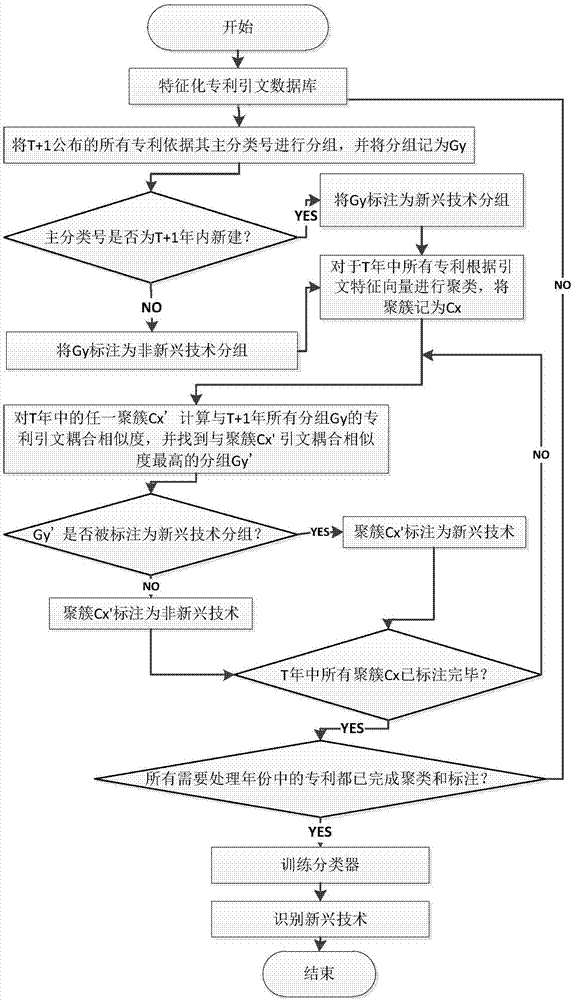
圖1是基於專利引文的新興技術識別方法流程圖。
圖2是深度神經網絡分類器的系統結構圖
具體實施方式
下面結合附圖和實施例,對本發明的具體實施方式做進一步描述。
基於專利引文的新興技術識別方法,如圖1所示,所述方法包括以下步驟:
s1特徵化用於訓練的引文資料庫;
s2將在t+1年公布的每一項專利依據其主分類號進行分組,將分組記為gy;
s3如果該主分類號是t+1年新建立的,將gy標註為新技術分組,否則記為非新技術分組;
s4對於t年中所有專利根據專利引文特徵向量進行聚類,將聚簇記為cx;
s5對於t年的任一計算與t+1年所有分組cy的專利同引的耦合度;
s6找到與專利同引的耦合度最高的分組;
s7如果為新興技術分組,將聚簇標記為新興技術,否則標記為非新型技術;
s8循環步驟4,直至t年所有的聚簇cx被標記完畢;
s9循環步驟1,直至專利數據除了年份最大的其他專利都完成聚類與標註;
s10採用標註數據訓練分類器;
s11使用該分類器判定基於專利引文特徵向量的聚簇是否為新興技術。
在步驟s1中,特徵化引文資料庫是指引文數據表達(或者特徵)的選擇,既抽取引文或專利文件的部分指標數據作為特徵數據,多個特徵數據構成特徵向量。在本實施例中採用如下特徵數據:
1)權利要求項數;2)引文總數量;3)非專利文獻引文數量;4)專利分類號;5)技術生命周期,本實施例中採用如下計算公式:
其中是第i篇專利申請日期,是第i篇專利引用的第j篇專利的申請日期;
6)被引技術的相似性指數(ctsi)專利分類系統對不同領域的技術進行了劃分。大類只是限定了大概的領域,而小類才會給出更具體的領域,在實際中往往是採用大類和小類相結合來共同構成專利的分類號。本實施例採用如下的計算公式:
下面給出用於兩個主分類號之間相似性計算的公式:
如果一項專利往往擁有幾項分類號,因此需要求出兩項專利分類號之間的平均相似度,以下是的表達式:
這裡表示專利p和專利q各自所擁有的分類號的數量。
最後,再來計算第x篇專利的被引技術相似性指數,指標的計算公式如下:
此處,是引用的專利總數,是被x引用的第n項專利;
7)被引技術所有者平均相似性指數(casi)。一項專利通常情況下有一個或多個專利權人,採取下面的公式計算兩項技術的專利權人相似性指標:
其中
這裡是專利p和專利q各自的專利權人的數量,
。
在步驟s4中,對專利引文數據進行特徵化後進行聚類操作,在本實施例中結合兩種聚類算法和美國專利分類體系的優勢來設計聚類步驟。首先,使用dbscan聚類算法按不同的年份對引文數據進行聚類,得到該數據集的聚簇類別數k1,然後考慮美國專利分類體系中的大類數目為450,這樣就可以得到兩個聚類的數目,為了減少誤差,最終取這兩個類別數的平均值,即k=(k1+450)/2,並向上取整。這樣得到的這個k就更加接近真實的類別數,然後將k值帶入k-means聚類算法,按不同年份對引文數據進行聚類。
在步驟s5中專利同引的耦合度是指聚簇cx和gy的文獻耦合相似度(bcs),在本實施例中採用以下計算公式:
在步驟s10採用標註數據訓練分類器,在本實施例中採用深度神經網絡作為分類器。如圖2所示,該分類器可分為四層,如圖所示第一層是輸入層,本層需要對輸入數據進行預處理,形成統一格式的數據矩陣;然後就是深度神經網絡層,該層由3層rbm堆疊而成,主要功能就是對數據進行重構,自動提取出合適的特徵;接下來是分類器所在的決策層,該層使用logisticregression算法來設計分類器,然後再對分類結果應用softmax算法進行概率轉換。將結果中概率較大的所對應的下標作為分類結果,因為原分類結果只有兩個維度,因此最終的分類結果只有0或者1,0代表非新興技術,1代表新興技術。
本實施例中選取rbm算法作為深度信念網絡各層之間的重構算法。信念網絡裡面各層之間rbm調節的主要通過多個隱含層的相互轉化,從而為rbm內部的參數調節提供訓練目標,通過降低重構矩陣與原矩陣的差異來達到調節rbm參數的最終目標。對於rbm的參數學習採用對數似然度極大化的思想來獲取rbm算法中參數,的表達式定義如下:
為了獲得最優參數,可以使用隨機梯度上升法,其中關鍵步驟是計算關於各個模型參數的偏導數。由式2.1可以求出求關於分布p的均值。
深度模型的反饋微調主要通過三個過程來實現:加載參數、構造數據矩陣、循環調節。其中前兩個過程主要是在完成整個深度模型前期的準備工作,而循環調節過程才是整個深度模型反饋調節機制的核心。隨層次增加,深度表示的維度也在逐漸變化,在反饋微調階段,先通過識別模型自底向上進行轉換,到了最上層之後,再進行自頂向下的生成模型的轉換,從而生成對各個層次的重構展現。最後通過對原始表示和重構表示的不斷優化調節,從而來實現兩者的誤差最小化。
本實施例中採用bp算法對自底向上的識別模型和自頂向下的生成模型相結合的方式來進行微調。經過網絡的識別模型,本文可以近似得到深度模型對輸入數據最初的各個層次上的表示形式,並得到一個深度模型對樣本最高層次的抽象表示形式,通過該生成模型,本文可以從模型的最高層次表示形式出發,重構展示深度模型對樣本數據的各個層次的表示,這樣就可以為原來的每個層級的訓練提供優化目標。經過各個層次的不斷調節,生成模型就可以重構出具有較低誤差的訓練樣本,通過以上步驟模型可以自動學習出原樣本的數據特徵,即最高層次的抽象表示形式。
上面是本發明提供的基於專利引文的新興技術識別方法優選實施方式,並不構成對本發明的保護權限,任何在本發明上的改進,只要原理相同,都包含在本發明的權利要求保護範圍之內。