基於人工智慧的跨語種語音轉錄方法、設備及可讀介質與流程
2023-09-23 23:36:55 4
【技術領域】
本發明涉及計算機應用技術領域,尤其涉及一種基於人工智慧的跨語種語音轉錄方法、設備及可讀介質。
背景技術:
人工智慧(artificialintelligence;ai),是研究、開發用於模擬、延伸和擴展人的智能的理論、方法、技術及應用系統的一門新的技術科學。人工智慧是計算機科學的一個分支,它企圖了解智能的實質,並生產出一種新的能以人類智能相似的方式做出反應的智能機器,該領域的研究包括機器人、語言識別、圖像識別、自然語言處理和專家系統等。
隨著語音技術的發展,從語音到對應文本的語音轉錄在日常生活中逐步的普及。然而,當前的語音轉錄技術只能識別轉錄當前語種的語音,例如一段普通話的語音,對應的轉錄結果會為其對應的漢字文本,而並不能滿足跨語種語音轉錄的需求,例如無法將輸入的一段普通話語音,直接輸出跨語種語音轉錄的對應的英文翻譯文本。為了實現跨語種的語音轉錄,現有技術中多採用兩步走的方案:首先,通過語音識別工具對輸入的語音進行轉錄生成文本;然後,通過機器翻譯的方法,對前面生成的文本進行翻譯,最後得到跨語種的語音轉錄文本結果。
但是現有的跨語種語音轉錄時,若第一步的語音識別工具識別錯誤,那麼機器翻譯得到的最終的語音轉錄文本便無可避免地發生錯誤,即現有技術的跨語種語音轉錄不可避免地會發生錯誤累積的問題,導致現有技術的跨語種語音轉錄準確性較差、轉錄效率較低。
技術實現要素:
本發明提供了一種基於人工智慧的跨語種語音轉錄方法、設備及可讀介質,用於提高跨語種語音轉錄準確性和轉錄效率。
本發明提供一種基於人工智慧的跨語種語音轉錄方法,所述方法包括:
將待轉錄的語音數據進行預處理,獲取多個聲學特徵;所述待轉錄的語音數據採用第一語種表示;
根據多個所述聲學特徵以及預先訓練的跨語種轉錄模型,預測所述語音數據對應的轉錄後的翻譯文本;其中,所述翻譯文本採用第二語種表示,所述第二語種不同於所述第一語種。
進一步可選地,如上所述的方法中,將待轉錄的語音數據進行預處理,獲取多個聲學特徵,具體包括:
對所述待轉錄的語音數據採用預設的採樣率進行採樣,得到多個語音數據採樣點;
對所述多個語音數據採樣點按照預設的量化位數進行量化處理,得到脈衝編碼調製文件;
從所述脈衝編碼調製文件中提取多個所述聲學特徵。
進一步可選地,如上所述的方法中,從所述脈衝編碼調製文件中提取多個所述聲學特徵,具體包括:
從所述脈衝編碼調製文件的開頭選取預設幀長的數據幀;並按照從前至後依次調整預設幀移後選取所述預設幀長的數據幀,共得到多個所述數據幀;
分別從多個所述數據幀中提取每個所述數據幀的聲學特徵,得到多個所述聲學特徵。
進一步可選地,如上所述的方法中,根據多個所述聲學特徵以及預先訓練的跨語種轉錄模型,預測所述語音數據對應的轉錄後的翻譯文本之前,所述方法還包括:
採集數條所述第一語種表示的訓練語音數據以及各條所述訓練語音數據轉錄為所述第二語種表示的真實翻譯文本;
採用各條所述訓練語音數據和對應的所述真實翻譯文本,訓練所述跨語種轉錄模型。
進一步可選地,如上所述的方法中,採用各條所述訓練語音數據和對應的所述真實翻譯文本,訓練所述跨語種轉錄模型,具體包括:
將當前的所述訓練語音數據代入所述跨語種轉錄模型,使得所述跨語種轉錄模型預測所述訓練語音數據對應的預測翻譯文本;
判斷所述訓練語音數據的所述預測翻譯文本與所述真實翻譯文本是否一致;
若不一致時,修改所述跨語種轉錄模型的模型參數,使得所述跨語種轉錄模型預測的所述訓練語音數據的所述預測翻譯文本與對應的所述真實翻譯文本趨於一致;並繼續選擇下一條所述訓練語音數據進行訓練;
利用各條所述訓練語音數據,按照執行上述步驟,重複對所述跨語種轉錄模型進行訓練,直至所述跨語種轉錄模型預測的所述訓練語音數據的所述預測翻譯文本與對應的所述真實翻譯文本一致,確定所述跨語種轉錄模型的模型參數,從而確定所述跨語種轉錄模型。
本發明提供一種基於人工智慧的跨語種語音轉錄裝置,所述裝置包括:
獲取模塊,用於將待轉錄的語音數據進行預處理,獲取多個聲學特徵;所述待轉錄的語音數據採用第一語種表示;
預測模塊,用於根據多個所述聲學特徵以及預先訓練的跨語種轉錄模型,預測所述語音數據對應的轉錄後的翻譯文本;其中,所述翻譯文本採用第二語種表示,所述第二語種不同於所述第一語種。
進一步可選地,如上所述的裝置中,所述獲取模塊,具體用於:
對所述待轉錄的語音數據採用預設的採樣率進行採樣,得到多個語音數據採樣點;
對所述多個語音數據採樣點按照預設的量化位數進行量化處理,得到脈衝編碼調製文件;
從所述脈衝編碼調製文件中提取多個所述聲學特徵。
進一步可選地,如上所述的裝置中,所述獲取模塊,具體用於:從所述脈衝編碼調製文件的開頭選取預設幀長的數據幀;並按照從前至後依次調整預設幀移後選取所述預設幀長的數據幀,共得到多個所述數據幀;
分別從多個所述數據幀中提取每個所述數據幀的聲學特徵,得到多個所述聲學特徵。
進一步可選地,如上所述的裝置中,所述裝置還包括:
採集模塊,用於採集數條所述第一語種表示的訓練語音數據以及各條所述訓練語音數據轉錄為所述第二語種表示的真實翻譯文本;
訓練模塊,用於採用各條所述訓練語音數據和對應的所述真實翻譯文本,訓練所述跨語種轉錄模型。
進一步可選地,如上所述的裝置中,所述訓練模塊,具體用於:
將當前的所述訓練語音數據代入所述跨語種轉錄模型,使得所述跨語種轉錄模型預測所述訓練語音數據對應的預測翻譯文本;
判斷所述訓練語音數據的所述預測翻譯文本與所述真實翻譯文本是否一致;
若不一致時,修改所述跨語種轉錄模型的模型參數,使得所述跨語種轉錄模型預測的所述訓練語音數據的所述預測翻譯文本與對應的所述真實翻譯文本趨於一致;並繼續選擇下一條所述訓練語音數據進行訓練;
利用各條所述訓練語音數據,按照執行上述步驟,重複對所述跨語種轉錄模型進行訓練,直至所述跨語種轉錄模型預測的所述訓練語音數據的所述預測翻譯文本與對應的所述真實翻譯文本一致,確定所述跨語種轉錄模型的模型參數,從而確定所述跨語種轉錄模型。
本發明還提供一種計算機設備,所述設備包括:
一個或多個處理器;
存儲器,用於存儲一個或多個程序,
當所述一個或多個程序被所述一個或多個處理器執行,使得所述一個或多個處理器實現如上所述的基於人工智慧的跨語種語音轉錄方法。
本發明還提供一種計算機可讀介質,其上存儲有電腦程式,該程序被處理器執行時實現如上所述的基於人工智慧的跨語種語音轉錄方法。
本發明的基於人工智慧的跨語種語音轉錄方法、設備及可讀介質,通過將待轉錄的語音數據進行預處理,獲取多個聲學特徵;待轉錄的語音數據採用第一語種表示;根據多個聲學特徵以及預先訓練的跨語種轉錄模型,預測語音數據對應的轉錄後的翻譯文本;其中,翻譯文本採用第二語種表示,第二語種不同於第一語種。採用本發明的技術方案,跨語種語音轉錄時不用先進行語音識別,再進行機器翻譯,而是直接根據預先訓練的跨語種轉錄模型便可以進行跨語種轉錄,能夠克服現有技術中的兩步走的跨語種轉錄方式中的錯誤累積的問題,與現有技術相比,能夠有效地提高跨語種語音轉錄的準確性和轉錄效率。
【附圖說明】
圖1為本發明的基於人工智慧的跨語種語音轉錄方法實施例一的流程圖。
圖2為本發明的基於人工智慧的跨語種語音轉錄方法實施例二的流程圖。
圖3為本發明的基於人工智慧的跨語種語音轉錄方法實施例三的流程圖。
圖4為本發明的基於人工智慧的跨語種語音轉錄裝置實施例一的結構圖。
圖5為本發明的基於人工智慧的跨語種語音轉錄裝置實施例二的結構圖。
圖6為本發明的計算機設備實施例的結構圖。
圖7為本發明提供的一種計算機設備的示例圖。
【具體實施方式】
為了使本發明的目的、技術方案和優點更加清楚,下面結合附圖和具體實施例對本發明進行詳細描述。
圖1為本發明的基於人工智慧的跨語種語音轉錄方法實施例一的流程圖。如圖1所示,本實施例的基於人工智慧的跨語種語音轉錄方法,具體可以包括如下步驟:
100、將待轉錄的語音數據進行預處理,獲取多個聲學特徵;待轉錄的語音數據採用第一語種表示;
101、根據多個聲學特徵以及預先訓練的跨語種轉錄模型,預測語音數據對應的轉錄後的翻譯文本;其中,翻譯文本採用第二語種表示,第二語種不同於第一語種。
本實施例的基於人工智慧的跨語種語音轉錄方法的執行主體為一基於人工智慧的跨語種語音轉錄裝置,該基於人工智慧的跨語種語音轉錄裝置能夠對待轉錄的語音數據直接進行跨語種的轉錄。本實施例的基於人工智慧的跨語種語音轉錄方法,主要用於實現將第一語種表示的待轉錄的語音數據,轉錄為第二語種表示的翻譯文本。其中的第一語種可以為中文、英文、日文、韓文、藏文、彝文等等。由於第一語種採用語音形式,因此,本實施例的第一語種可以為任一國家的語種,也可以為任一具有自己民族語言的少數民族的語種。第二語種採用文本形式展現,因此第二語種需要具有其文本形式的語種。而每一個國家對應的國家內的標準語種都具有其文本形式,因此第二語種也可以為任一國家的語種。另外,有些少數民族,如藏族、彝族、傣族、壯族等等少數民族不僅具有自己獨立的語種,還有自己語種對應的文字。因此,第二語種也可以為任一具有自己語種的文字的少數民族的語種。
本實施例的基於人工智慧的跨語種語音轉錄方法中,預先訓練的跨語種轉錄模型可以為預先經過深度學習訓練得到的網絡模型。如,本實施例的跨語種轉錄模型可以是基於attention的序列到序列的深度學習模型,例如可以為一種採用encoder-decoder方式的深度學習模型。本實施例的跨語種轉錄模型輸入的是待轉錄的語音數據的多個聲學特徵,因此,本實施例中,首先,將第一語種表示的待轉錄的語音數據進行預處理,獲取待轉錄的語音數據多個聲學特徵;然後將待轉錄的語音數據多個聲學特徵,輸入至預先訓練的跨語種轉錄模型中。由於該跨語種轉錄模型預先訓練中採用深度學習的方式進行訓練,此時該訓練好的跨語種轉錄模型可以根據輸入的待轉錄的語音數據的多個聲學特徵,預測該語音數據對應的轉錄後的第二語種表示的翻譯文本。本實施例中,雖然該跨語種轉錄模型預測的翻譯文本為預測的結果,但是由於該跨語種轉錄模型是經過深度學習訓練得到的,此時可以認為該跨語種轉錄模型預測的翻譯文本與真實的翻譯文本一致。
本實施例的基於人工智慧的跨語種語音轉錄方法,通過將待轉錄的語音數據進行預處理,獲取多個聲學特徵;待轉錄的語音數據採用第一語種表示;根據多個聲學特徵以及預先訓練的跨語種轉錄模型,預測語音數據對應的轉錄後的翻譯文本;其中,翻譯文本採用第二語種表示,第二語種不同於第一語種。採用本實施例的技術方案,跨語種語音轉錄時不用先進行語音識別,再進行機器翻譯,而是直接根據預先訓練的跨語種轉錄模型便可以進行跨語種轉錄,能夠克服現有技術中的兩步走的跨語種轉錄方式中的錯誤累積的問題,與現有技術相比,能夠有效地提高跨語種語音轉錄的準確性和轉錄效率。
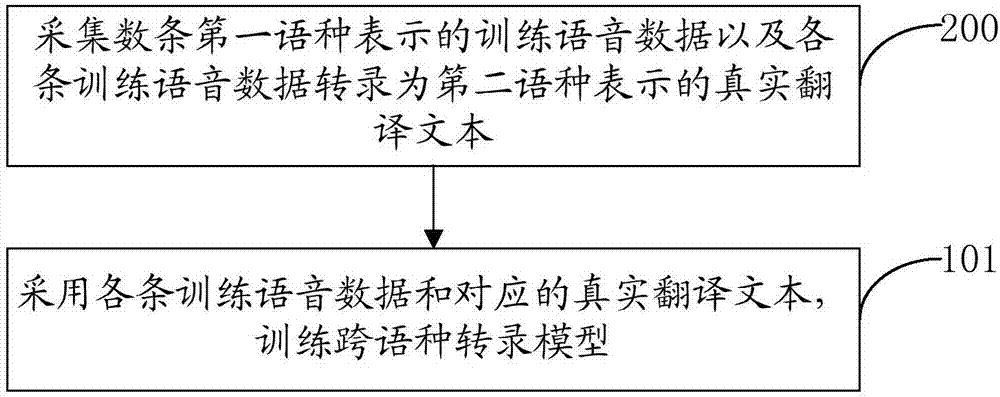
圖2為本發明的基於人工智慧的跨語種語音轉錄方法實施例二的流程圖。本實施例的基於人工智慧的跨語種語音轉錄方法,在上述圖1所示實施例的技術方案的基礎上,更加詳細地介紹本發明的技術方案。如圖2所示,本實施例的基於人工智慧的跨語種語音轉錄方法,在上述圖1所示實施例的步驟101之前,具體還可以包括如下步驟:
200、採集數條第一語種表示的訓練語音數據以及各條訓練語音數據轉錄為第二語種表示的真實翻譯文本;
本實施例中在對跨語種轉錄模型進行訓練時,需要採集數條第一語種表示的訓練語音數據以及各條訓練語音數據轉錄為第二語種表示的真實翻譯文本。例如,具體可以從網絡上,或者已經成功轉錄的資料庫中採集數條第一語種表示的訓練語音數據以及各條訓練語音數據轉錄為第二語種表示的真實翻譯文本。其中每一條訓練語音數據與對應的真實翻譯文本作為一條訓練數據,本實施例中,為了保證訓練的跨語種轉錄模型的準確性,採集的訓練數據的條數可以達到數以萬條,例如可以包括20萬條或者30萬條甚至更多條數。其中採集的訓練數據的條數越多,訓練得到的跨語種轉錄模型越準確,後續步驟101對第一語種表示的待轉錄的語音數據轉錄的第二語種表示的翻譯文本越準確。
201、採用各條訓練語音數據和對應的真實翻譯文本,訓練跨語種轉錄模型。
本實施例中,採集到數條第一語種表示的訓練語音數據以及各條訓練語音數據轉錄為第二語種表示的真實翻譯文本之後,可以將採集的數條第一語種表示的訓練語音數據以及各條訓練語音數據轉錄為第二語種表示的真實翻譯文本存儲在一個資料庫中,生成訓練資料庫。然後訓練時,採用訓練資料庫中的每一條訓練語音數據和對應的真實翻譯文本,對跨語種轉錄模型進行訓練。
例如,本實施例的步驟201「採用各條訓練語音數據和對應的真實翻譯文本,訓練跨語種轉錄模型」,具體可以包括如下步驟:
(a1)將當前的訓練語音數據代入跨語種轉錄模型,使得跨語種轉錄模型預測訓練語音數據對應的預測翻譯文本;
(a2)判斷訓練語音數據的預測翻譯文本與真實翻譯文本是否一致;若不一致時,執行步驟(a3);否則,執行步驟(a4);
(a3)修改跨語種轉錄模型的模型參數,使得跨語種轉錄模型預測的訓練語音數據的預測翻譯文本與對應的真實翻譯文本趨於一致;執行步驟(a4);
(a4)繼續選擇下一條訓練語音數據作為當前的訓練數據,以準備採用上述步驟(a1-(a3)進行訓練;
利用各條訓練語音數據,按照執行上述步驟(a1)-(a4),重複對跨語種轉錄模型進行訓練,直至跨語種轉錄模型預測的訓練語音數據的預測翻譯文本與對應的真實翻譯文本一致,確定跨語種轉錄模型的模型參數,從而確定跨語種轉錄模型。
例如,訓練時,為了便於採用每條訓練語音數據和對應的真實翻譯文本,對跨語種轉錄模型進行訓練,避免重複採用同一條訓練語音數據和對應的真實翻譯文本,重複對跨語種轉錄模型進行訓練,可以將各條訓練語音數據排序,每次訓練時選取一條訓練語音數據作為當前的訓練語音數據,該條訓練語音數據訓練完畢,可以繼續選擇下一條訓練語音數據作為當前的訓練語音數據,繼續對跨語種轉錄模型進行訓練。
需要說明的時,訓練之前,本實施例的跨語種轉錄模型的模型參數具有初始值。若採用第一條訓練語音數據對跨語種轉錄模型進行訓練時,將第一條訓練語音數據作為當前的訓練語音數據,輸入至跨語種轉錄模型中,此時,跨語種轉錄模型根據當前的模型參數的初始值,輸出一個該訓練語音數據對應的預測翻譯文本。然後判斷訓練語音數據的預測翻譯文本與真實翻譯文本是否一致;若不一致時,修改跨語種轉錄模型的模型參數,使得跨語種轉錄模型預測的訓練語音數據的預測翻譯文本與對應的真實翻譯文本趨於一致;否則若一致,繼續選擇下一條訓練語音數據作為當前的訓練數據,繼續進行訓練。
訓練時,至少要利用訓練資料庫中的各條訓練數據進行一輪訓練,若一輪訓練完畢後,可以確定跨語種轉錄模型預測的訓練語音數據的預測翻譯文本與對應的真實翻譯文本一致,此時確定跨語種轉錄模型的模型參數,從而確定跨語種轉錄模型。
若一輪訓練完畢,跨語種轉錄模型預測的訓練語音數據的預測翻譯文本與對應的真實翻譯文本仍然不一致,此時可以使用訓練資料庫中的各條訓練數據進行再一輪、兩輪或者多輪訓練,直至跨語種轉錄模型預測的訓練語音數據的預測翻譯文本與對應的真實翻譯文本一致,確定跨語種轉錄模型的模型參數,從而確定跨語種轉錄模型。
本實施例訓練得到的跨語種轉錄模型,可以對一種第一語種表示的待轉錄的語音數據,跨語種轉錄為一種第二語種表示的翻譯文本。如果一個跨語種轉錄模型若能夠支持英語到中文的跨語種轉錄,而不能實現義大利語到中文的跨語種轉錄,也就是說本實施例的跨語種轉錄模型為一對一的形式,不支持一對多或者多對一的形式。另外,需要說明的是,本實施例中,若第二語種表示的翻譯文本為中文時,為了便於與其它語種對應,優選地,選擇以文字的漢語拼音來表示翻譯文本。而且本實施例的漢語拼音的表示方式可以為每個漢字的拼音作為最小的建模單元來表示,如「zhongguoren」;也可以使用聲韻母為最小的建模單元,如將「zhongguoren」切分為「zhongguoren」。
本實施例的基於人工智慧的跨語種語音轉錄方法,通過採用上述技術方案訓練得到的跨語種轉錄模型,可以準確地對待轉錄的語音數據進行跨語種轉錄,與現有技術相比,跨語種語音轉錄時不用先進行語音識別,再進行機器翻譯,而是直接根據預先訓練的跨語種轉錄模型便可以進行跨語種轉錄,能夠克服現有技術中的兩步走的跨語種轉錄方式中的錯誤累積的問題,與現有技術相比,能夠有效地提高跨語種語音轉錄的準確性和轉錄效率。
圖3為本發明的基於人工智慧的跨語種語音轉錄方法實施例三的流程圖。本實施例的基於人工智慧的跨語種語音轉錄方法,在上述圖1或者圖2所示實施例的技術方案的基礎上,更加詳細地介紹本發明的技術方案。如圖3所示,本實施例的基於人工智慧的跨語種語音轉錄方法,具體可以包括如下步驟:
300、對第一語種表示的待轉錄的語音數據採用預設的採樣率進行採樣,得到多個語音數據採樣點;
例如,本實施例中的預設的採樣率可以為16k,即每1/16000秒選擇一個採樣點,這樣,1秒時長的語音有16000個採樣點。實際應用中預測的採樣率也可以為8k-20k的任意採樣率。
301、對多個語音數據採樣點按照預設的量化位數進行量化處理,得到脈衝編碼調製(pulsecodemodulation;pcm)文件;
本實施例的預設的量化位數優選地可以為16,位,實際應用中也可以選擇16位。其中量化位數越多,表示質量越高。量化處理後可以得到pcm文件。而且該pcm文件為單通道的pcm文件。
302、從pcm文件中提取多個聲學特徵;
最後從pcm文件中提取多個聲學特徵,例如可以提取fbank40格式的聲學特徵,其中fbank40格式的聲學特徵採用一個40維的向量表示。實際應用中也可以採用其他格式的其它維度的向量來表示各聲學特徵。
例如該步驟302,具體可以包括如下步驟:
(b1)從pcm文件的開頭選取預設幀長的數據幀;並按照從前至後依次調整預設幀移後選取預設幀長的數據幀,共得到多個數據幀;
(b2)分別從多個數據幀中提取每個數據幀的聲學特徵,得到多個聲學特徵。
本實施例在從pcm文件時,由於pcm文件也採用幀表示,可以先從pcm文件的開頭選取預設幀長的數據幀,例如預設幀長可以為25ms。然後按照從前至後依次調整預設幀移後選取預設幀長的數據幀,例如同一個pcm文件,開頭取了25ms的數據幀之後,幀移10ms,再取25ms的數據幀,然後再幀移10ms,再取25ms的數據幀,直到pcm文件取完,但是pcm文件的長度不一定是預設幀長的整數倍,此時最後剩下不足25ms長的數據幀可以丟棄,或者可以通過填零補位至25ms的幀長。這樣,得到的每個數據幀的長度時一樣,這樣,從待轉錄的語音數據對應的每個數據幀中提取的聲學特徵的方式,以及得到的聲學特徵的維度也是一樣的。而實際應用中,每段待轉錄的語音的長度可以不相同,但根據待轉錄的語音獲取的每個數據幀的長度是相同的。因此,在根據本實施例的跨語種轉錄模型跨語種轉錄時,可跨語種轉錄的待轉錄的語音數據的長短可以不做限制,理論上,可以對不超過可處理的最大時長的任意時長的待轉錄的語音數據進行跨語種轉錄,當然得到的跨語種轉錄後的翻譯文本的長度也不一。
上述步驟300-302為上述圖1所示實施例的步驟100的一種具體實現方式,實際應用中,也可以採用相關現有技術中的從語音數據中提取聲學特徵的方式來實現,在此不再一一舉例贅述。
303、將待轉錄的語音數據對應的多個聲學特徵輸入至預先訓練的跨語種轉錄模型中,該跨語種轉錄模型預測並輸出對應的轉錄後的第二語種表示的翻譯文本。
本實施例的預先訓練的跨語種轉錄模型採用上述圖2所示實施例的方式獲取到,詳細可以參考上述圖2所示實施例的記載,在此不再贅述。
本實施例的基於人工智慧的跨語種語音轉錄方法,通過採用上述技術方案,跨語種語音轉錄時不用先進行語音識別,再進行機器翻譯,而是直接根據預先訓練的跨語種轉錄模型便可以進行跨語種轉錄,能夠克服現有技術中的兩步走的跨語種轉錄方式中的錯誤累積的問題,與現有技術相比,能夠有效地提高跨語種語音轉錄的準確性和轉錄效率。
圖4為本發明的基於人工智慧的跨語種語音轉錄裝置實施例一的結構圖。如圖4所示,本實施例的發明的基於人工智慧的跨語種語音轉錄裝置,具體可以包括:獲取模塊10和預測模塊11。
其中,獲取模塊10用於將待轉錄的語音數據進行預處理,獲取多個聲學特徵;待轉錄的語音數據採用第一語種表示;
預測模塊11用於根據獲取模塊10獲取的多個聲學特徵以及預先訓練的跨語種轉錄模型,預測語音數據對應的轉錄後的翻譯文本;其中,翻譯文本採用第二語種表示,第二語種不同於第一語種。
本實施例的基於人工智慧的跨語種語音轉錄裝置,通過採用上述模塊實現基於人工智慧的跨語種語音轉錄的實現原理以及技術效果與上述相關方法實施例的實現相同,詳細可以參考上述相關方法實施例的記載,在此不再贅述。
圖5為本發明的基於人工智慧的跨語種語音轉錄裝置實施例二的結構圖。如圖5所示,本實施例的基於人工智慧的跨語種語音轉錄裝置,在上述圖4所示實施例的技術方案的基礎上,進一步更加詳細地介紹本發明的技術方案。
本實施例的基於人工智慧的跨語種語音轉錄裝置中,獲取模塊10具體用於:
對待轉錄的語音數據採用預設的採樣率進行採樣,得到多個語音數據採樣點;
對多個語音數據採樣點按照預設的量化位數進行量化處理,得到脈衝編碼調製文件;
從脈衝編碼調製文件中提取多個聲學特徵。
進一步可選地,本實施例的基於人工智慧的跨語種語音轉錄裝置中,獲取模塊10具體用於:從脈衝編碼調製文件的開頭選取預設幀長的數據幀;並按照從前至後依次調整預設幀移後選取預設幀長的數據幀,共得到多個數據幀;
分別從多個數據幀中提取每個數據幀的聲學特徵,得到多個聲學特徵。
進一步可選地,如圖5所示,本實施例的基於人工智慧的跨語種語音轉錄裝置,還包括:
採集模塊12用於採集數條第一語種表示的訓練語音數據以及各條訓練語音數據轉錄為第二語種表示的真實翻譯文本;
訓練模塊13用於採用採集模塊12採集的各條訓練語音數據和對應的真實翻譯文本,訓練跨語種轉錄模型。
此時對應地,預測模塊11用於根據獲取模塊10獲取的多個聲學特徵以及訓練模塊13預先訓練的跨語種轉錄模型,預測語音數據對應的轉錄後的翻譯文本;
進一步可選地,本實施例的基於人工智慧的跨語種語音轉錄裝置中,訓練模塊13具體用於:
將當前的訓練語音數據代入跨語種轉錄模型,使得跨語種轉錄模型預測訓練語音數據對應的預測翻譯文本;
判斷訓練語音數據的預測翻譯文本與真實翻譯文本是否一致;
若不一致時,修改跨語種轉錄模型的模型參數,使得跨語種轉錄模型預測的訓練語音數據的預測翻譯文本與對應的真實翻譯文本趨於一致;並繼續選擇下一條訓練語音數據進行訓練;
利用各條訓練語音數據,按照執行上述步驟,重複對跨語種轉錄模型進行訓練,直至跨語種轉錄模型預測的訓練語音數據的預測翻譯文本與對應的真實翻譯文本一致,確定跨語種轉錄模型的模型參數,從而確定跨語種轉錄模型。
本實施例的基於人工智慧的跨語種語音轉錄裝置,通過採用上述模塊實現基於人工智慧的跨語種語音轉錄的實現原理以及技術效果與上述相關方法實施例的實現相同,詳細可以參考上述相關方法實施例的記載,在此不再贅述。
圖6為本發明的計算機設備實施例的結構圖。如圖6所示,本實施例的計算機設備,包括:一個或多個處理器30,以及存儲器40,存儲器40用於存儲一個或多個程序,當存儲器40中存儲的一個或多個程序被一個或多個處理器30執行,使得一個或多個處理器30實現如上圖1-圖3所示實施例的基於人工智慧的跨語種語音轉錄方法。圖6所示實施例中以包括多個處理器30為例。
例如,圖7為本發明提供的一種計算機設備的示例圖。圖7示出了適於用來實現本發明實施方式的示例性計算機設備12a的框圖。圖7顯示的計算機設備12a僅僅是一個示例,不應對本發明實施例的功能和使用範圍帶來任何限制。
如圖7所示,計算機設備12a以通用計算設備的形式表現。計算機設備12a的組件可以包括但不限於:一個或者多個處理器16a,系統存儲器28a,連接不同系統組件(包括系統存儲器28a和處理器16a)的總線18a。
總線18a表示幾類總線結構中的一種或多種,包括存儲器總線或者存儲器控制器,外圍總線,圖形加速埠,處理器或者使用多種總線結構中的任意總線結構的局域總線。舉例來說,這些體系結構包括但不限於工業標準體系結構(isa)總線,微通道體系結構(mac)總線,增強型isa總線、視頻電子標準協會(vesa)局域總線以及外圍組件互連(pci)總線。
計算機設備12a典型地包括多種計算機系統可讀介質。這些介質可以是任何能夠被計算機設備12a訪問的可用介質,包括易失性和非易失性介質,可移動的和不可移動的介質。
系統存儲器28a可以包括易失性存儲器形式的計算機系統可讀介質,例如隨機存取存儲器(ram)30a和/或高速緩存存儲器32a。計算機設備12a可以進一步包括其它可移動/不可移動的、易失性/非易失性計算機系統存儲介質。僅作為舉例,存儲系統34a可以用於讀寫不可移動的、非易失性磁介質(圖7未顯示,通常稱為「硬碟驅動器」)。儘管圖7中未示出,可以提供用於對可移動非易失性磁碟(例如「軟盤」)讀寫的磁碟驅動器,以及對可移動非易失性光碟(例如cd-rom,dvd-rom或者其它光介質)讀寫的光碟驅動器。在這些情況下,每個驅動器可以通過一個或者多個數據介質接口與總線18a相連。系統存儲器28a可以包括至少一個程序產品,該程序產品具有一組(例如至少一個)程序模塊,這些程序模塊被配置以執行本發明上述圖1-圖5各實施例的功能。
具有一組(至少一個)程序模塊42a的程序/實用工具40a,可以存儲在例如系統存儲器28a中,這樣的程序模塊42a包括——但不限於——作業系統、一個或者多個應用程式、其它程序模塊以及程序數據,這些示例中的每一個或某種組合中可能包括網絡環境的實現。程序模塊42a通常執行本發明所描述的上述圖1-圖5各實施例中的功能和/或方法。
計算機設備12a也可以與一個或多個外部設備14a(例如鍵盤、指向設備、顯示器24a等)通信,還可與一個或者多個使得用戶能與該計算機設備12a交互的設備通信,和/或與使得該計算機設備12a能與一個或多個其它計算設備進行通信的任何設備(例如網卡,數據機等等)通信。這種通信可以通過輸入/輸出(i/o)接口22a進行。並且,計算機設備12a還可以通過網絡適配器20a與一個或者多個網絡(例如區域網(lan),廣域網(wan)和/或公共網絡,例如網際網路)通信。如圖所示,網絡適配器20a通過總線18a與計算機設備12a的其它模塊通信。應當明白,儘管圖中未示出,可以結合計算機設備12a使用其它硬體和/或軟體模塊,包括但不限於:微代碼、設備驅動器、冗餘處理器、外部磁碟驅動陣列、raid系統、磁帶驅動器以及數據備份存儲系統等。
處理器16a通過運行存儲在系統存儲器28a中的程序,從而執行各種功能應用以及數據處理,例如實現上述實施例所示的基於人工智慧的跨語種語音轉錄方法。
本發明還提供一種計算機可讀介質,其上存儲有電腦程式,該程序被處理器執行時實現如上述實施例所示的基於人工智慧的跨語種語音轉錄方法。
本實施例的計算機可讀介質可以包括上述圖7所示實施例中的系統存儲器28a中的ram30a、和/或高速緩存存儲器32a、和/或存儲系統34a。
隨著科技的發展,電腦程式的傳播途徑不再受限於有形介質,還可以直接從網絡下載,或者採用其他方式獲取。因此,本實施例中的計算機可讀介質不僅可以包括有形的介質,還可以包括無形的介質。
本實施例的計算機可讀介質可以採用一個或多個計算機可讀的介質的任意組合。計算機可讀介質可以是計算機可讀信號介質或者計算機可讀存儲介質。計算機可讀存儲介質例如可以是——但不限於——電、磁、光、電磁、紅外線、或半導體的系統、裝置或器件,或者任意以上的組合。計算機可讀存儲介質的更具體的例子(非窮舉的列表)包括:具有一個或多個導線的電連接、可攜式計算機磁碟、硬碟、隨機存取存儲器(ram)、只讀存儲器(rom)、可擦式可編程只讀存儲器(eprom或快閃記憶體)、光纖、可攜式緊湊磁碟只讀存儲器(cd-rom)、光存儲器件、磁存儲器件、或者上述的任意合適的組合。在本文件中,計算機可讀存儲介質可以是任何包含或存儲程序的有形介質,該程序可以被指令執行系統、裝置或者器件使用或者與其結合使用。
計算機可讀的信號介質可以包括在基帶中或者作為載波一部分傳播的數據信號,其中承載了計算機可讀的程序代碼。這種傳播的數據信號可以採用多種形式,包括——但不限於——電磁信號、光信號或上述的任意合適的組合。計算機可讀的信號介質還可以是計算機可讀存儲介質以外的任何計算機可讀介質,該計算機可讀介質可以發送、傳播或者傳輸用於由指令執行系統、裝置或者器件使用或者與其結合使用的程序。
計算機可讀介質上包含的程序代碼可以用任何適當的介質傳輸,包括——但不限於——無線、電線、光纜、rf等等,或者上述的任意合適的組合。
可以以一種或多種程序設計語言或其組合來編寫用於執行本發明操作的電腦程式代碼,所述程序設計語言包括面向對象的程序設計語言—諸如java、smalltalk、c++,還包括常規的過程式程序設計語言—諸如」c」語言或類似的程序設計語言。程序代碼可以完全地在用戶計算機上執行、部分地在用戶計算機上執行、作為一個獨立的軟體包執行、部分在用戶計算機上部分在遠程計算機上執行、或者完全在遠程計算機或伺服器上執行。在涉及遠程計算機的情形中,遠程計算機可以通過任意種類的網絡——包括區域網(lan)或廣域網(wan)—連接到用戶計算機,或者,可以連接到外部計算機(例如利用網際網路服務提供商來通過網際網路連接)。
在本發明所提供的幾個實施例中,應該理解到,所揭露的系統,裝置和方法,可以通過其它的方式實現。例如,以上所描述的裝置實施例僅僅是示意性的,例如,所述單元的劃分,僅僅為一種邏輯功能劃分,實際實現時可以有另外的劃分方式。
所述作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位於一個地方,或者也可以分布到多個網絡單元上。可以根據實際的需要選擇其中的部分或者全部單元來實現本實施例方案的目的。
另外,在本發明各個實施例中的各功能單元可以集成在一個處理單元中,也可以是各個單元單獨物理存在,也可以兩個或兩個以上單元集成在一個單元中。上述集成的單元既可以採用硬體的形式實現,也可以採用硬體加軟體功能單元的形式實現。
上述以軟體功能單元的形式實現的集成的單元,可以存儲在一個計算機可讀取存儲介質中。上述軟體功能單元存儲在一個存儲介質中,包括若干指令用以使得一臺計算機設備(可以是個人計算機,伺服器,或者網絡設備等)或處理器(processor)執行本發明各個實施例所述方法的部分步驟。而前述的存儲介質包括:u盤、移動硬碟、只讀存儲器(read-onlymemory,rom)、隨機存取存儲器(randomaccessmemory,ram)、磁碟或者光碟等各種可以存儲程序代碼的介質。
以上所述僅為本發明的較佳實施例而已,並不用以限制本發明,凡在本發明的精神和原則之內,所做的任何修改、等同替換、改進等,均應包含在本發明保護的範圍之內。