一種基於超圖的圖像檢索與標註方法與流程
2023-09-12 19:01:40 4
本發明涉及超圖上的top-k查詢技術,特別涉及一種基於超圖的圖像檢索與標註方法。
背景技術:
隨著社交媒體和移動網際網路的發展,社交圖像網站提供了大量由不同用戶進行文本標註的圖像。社交圖像往往附帶多種信息,譬如視覺特徵、標籤和用戶等,以及多種行為關係,譬如標註和評論等。對海量社交圖像進行檢索和標註應用非常廣泛,成為資料庫、數據挖掘和機器學習領域的研究熱點。
圖像檢索是根據給定的信息,查找最相近的圖像對象,根據給定的信息類型不同,又有相似圖像檢索和關鍵字圖像檢索等多種檢索類型。圖像標註是給指定圖像附加語義文本信息,也即根據圖像查找最相近的語義文本。超圖是普通圖模型的擴展,其中的超邊可包含多個結點,故能夠表示高維關係,更適合對複雜網絡進行建模。圖像檢索和標註在搜尋引擎和社交媒體等領域有重要的應用價值。
目前的圖像檢索和標註方法,一般僅對單一特徵進行管理,或使用普通圖對社交圖像進行建模。然而,單一特徵只能表示某方面的相關性,不能用來表示真實的語義關聯,普通圖不能夠表示高維關係(比如標註和評論關係),造成了信息缺失。一些機器學習領域的方法使用超圖模型,但使用了複雜的矩陣運算進行求解,時間和存儲開銷巨大且不具有擴展性。
技術實現要素:
針對上述不足,本發明提供一種基於超圖的圖像檢索與標註方法,該方法使用超圖對社交圖像進行建模來表示高維關係,使用批量、並行和緩衝技術來加速超圖模型構建,並使用個性化pagerank加速超圖上的top-k查詢,也使用並行和近似方法進一步加速了查詢,本發明既提高了查詢效率也保證了查詢質量。
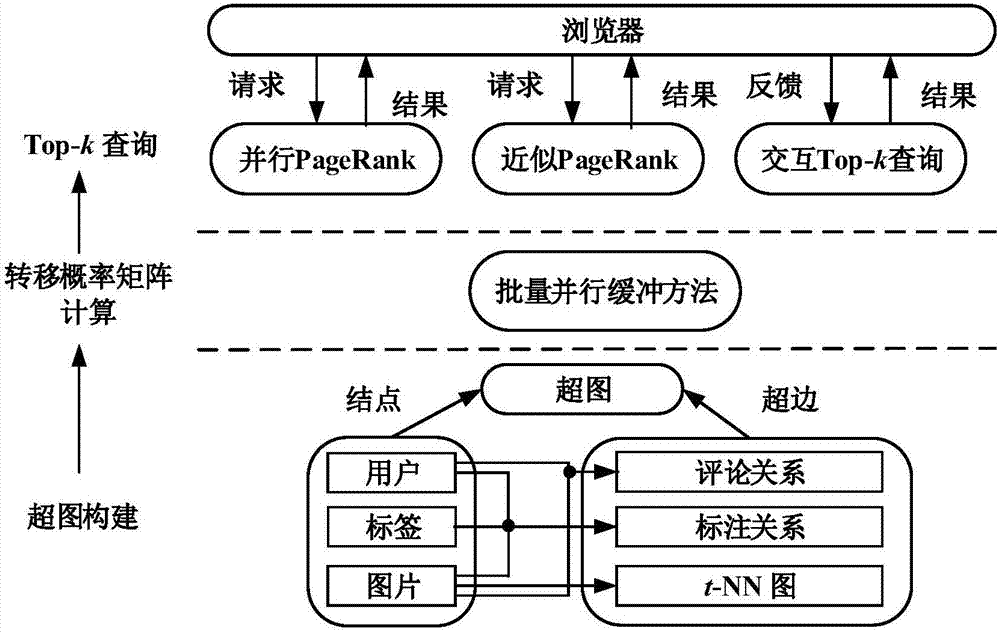
本發明解決其技術問題採用技術方案的步驟如下:一種基於超圖的圖像檢索與標註方法,該方法的步驟如下:
步驟(1):使用一個基於內容的圖像檢索引擎對圖像數據集建立t-nn圖,並將各圖像與其視覺特徵最相似的t張圖像建立聯繫;
步驟(2):根據圖像t-nn圖和圖像的社交關聯信息,建立超圖,計算其轉移概率矩陣並存儲到b+樹中;
步驟(3):用戶提交查詢對象集合和k值;
步驟(4):根據用戶提交的查詢對象集合生成查詢向量,而後在超圖上進行並行的個性化pagerank查詢,利用上、下界估計方法過濾超圖的結點,逐步縮小pagerank查詢過程中每輪迭代的候選點集合,直至得到k個結果;
步驟(5):用戶對步驟(4)得到的k個結果進行評價,生成反饋信息,再根據反饋信息調整步驟(4)中的查詢向量,形成新的查詢向量,再重複步驟(4),最終獲得新的查詢結果並返回給用戶。
進一步的,所述的步驟(1)中圖像檢索引擎基於度量空間spb樹索引結構,根據mpeg-7標準提取圖像的視覺特徵,建立spb樹,並對各圖像進行t-nn查詢,獲得與其最相近的t個查詢結果,進而建立t-nn圖。
進一步的,所述的步驟(2)中超圖的種類有三種:
1)以圖像t-nn圖中的各圖像和其t-nn圖像作為一種超邊;
2)以用戶對圖像進行標註的三元組合作為一種超邊;
3)以用戶對圖像進行評價的多元組合作為一種超邊。
進一步的,所述的步驟(2)中計算超圖轉移概率矩陣的具體步驟如下:
用g(v,e,w)表示一個超圖,其中v是結點集合,e是超邊集合,w是一個權重函數;一個超圖可以用一個|v|×|e|的矩陣h表示,其中矩陣元素h(v,e)為:
其中,v為結點,e為超邊;
結點v的度d(v)可以表示為:
d(v)=∑e∈e|v∈ew(e)=∑e∈ew(e)h(v,e)
其中,w(e)表示超邊e的權重;
超邊e的度δ(e)可以表示為:
δ(e)=|e|=∑v∈vh(v,e)
超圖的轉移概率矩陣,用p來表示,則p中的元素p[u,v]表示從結點u到結點v的轉移概率,其可以使用如下公式進行計算:
進一步的,所述的步驟(2)中轉移概率矩陣採用批量插入方法、並行技術和緩衝技術存儲到b+樹中;在將轉移概率矩陣存儲到b+樹中時,把超圖的出度結點和入度結點的組合作為鍵,轉移概率作為值。
進一步的,所述的步驟(3)中k是用戶指定的查詢返回結點個數。
進一步的,所述的步驟(4)中的個性化pagerank以查詢向量和k值作為輸入,在每輪迭代中,根據轉移概率矩陣,結點從該結點的入度結點獲得排名得分,該排名得分值為上一輪該入度結點的排名得分和轉移概率的乘積。
進一步的,所述的步驟(4)中上、下界估計具體如下:
1)對於下界估計,第i輪的下界估計si[u]使用如下公式計算:
其中,c為阻尼係數,i為當前迭代輪次,si-1[u]為第i-1輪的下界估計;λi[u]為第i輪迭代中從查詢節點到節點u的隨機遊走概率值,具體公式如下:
其中,q表示查詢向量,q[u]表示結點u的權重,且∑u∈vq[u]=1;另外用c[u]來表示結點u的入度結點集合,λi-1[v]為第i-1輪迭代中從查詢節點到節點v的隨機遊走概率值;
2)對於上界估計,第i輪上界估計使用如下公式計算:
其中,pmax[u]=max{p[v,u]|v∈v}為當前結點u的所有入度轉移概率的最大值;
進一步的,所述的步驟(4)中利用上、下界估計方法過濾超圖的結點,具體過濾步驟如下:
(4.1)當候選點集合大小大於k時,若候選點集合中的某結點的上界估計大於當前第k大的結點下界估計,則該結點為候選點,可能出現在最終的k個結果中,否則不可能成為結果點,則拋棄;若候選點集合大小為k時,則候選點集合中所有結點為最終返回結果,候選點集合中的結點排序通過步驟(4.2)或步驟(4.3)確定;
(4.2)當候選結點集合大小為k時,若候選結點集合中某結點的下界估計均大於集合內其他結點的上界估計,或者某結點的上界估計均小於集合內其他結點的下界估計時,則該結點的排序確定,將該結點加入結果結點集合;候選結點排序全部確定時停止迭代;
(4.3)當候選結點集合大小為k時,檢測當前所有候選結點的上下界估計差值,若所有結點的上下界估計差值小於設定閾值時,停止迭代,結點的排序根據下界估計降序確定。
進一步的,所述的步驟(5)中用戶對步驟(4)得到的k個結果進行評價,選出其中符合其查詢意願的結果圖像作為反饋節點,根據反饋節點調整步驟(4)中查詢向量,將反饋結點插入原查詢向量中,構成新的查詢向量,對新的查詢向量中的原查詢結點和新插入查詢結點重新進行權重分配,再次進行步驟(4)中個性化pagerank查詢,並使用上、下界估計方法進行過濾,最終獲得新的查詢結果並返回給用戶。
本發明具有的有益效果是:本發明採用超圖理論,使得社交圖像的評論關係、標註關係和視覺相似關係等多維關係可以得到有效的組織;採用空間資料庫中度量索引技術,充分利用了批量構建技術、並行技術和緩衝技術,使得超圖轉移概率矩陣的計算效率得到顯著的提高;採用上下界估計技術,帶來了查詢效率提高的技術效果,使得迭代次數極大減少,i/o開銷和cpu時間顯著降低;採用用戶反饋的優化方式,使得查詢效率得到顯著提高。
附圖說明
圖1是本發明的實施步驟流程圖;
圖2為基於超圖的圖像檢索和標註系統的工作原理示意圖。
具體實施方式
現結合附圖和具體實施對本發明的技術方案作進一步說明:
如圖1,圖2所示,本發明具體實施過程和工作原理如下:
步驟(1):使用一個基於內容的圖像檢索引擎對圖像數據集建立t-nn圖,並將各圖像與其視覺特徵最相似的t張圖像建立聯繫;
步驟(2):根據圖像t-nn圖和圖像的社交關聯信息,建立超圖,計算其轉移概率矩陣並存儲到b+樹中;
步驟(3):用戶提交查詢對象集合和k值;
步驟(4):根據用戶提交的查詢對象集合生成查詢向量,而後在超圖上進行並行的個性化pagerank查詢,利用上、下界估計方法過濾超圖的結點,逐步縮小pagerank查詢過程中每輪迭代的候選點集合,直至得到k個結果;
步驟(5):用戶對步驟(4)得到的k個結果進行評價,生成反饋信息,再根據反饋信息調整步驟(4)中的查詢向量,形成新的查詢向量,再重複步驟(4),最終獲得新的查詢結果並返回給用戶。
步驟(1)中圖像檢索引擎基於度量空間spb樹索引結構,根據mpeg-7標準提取圖像的視覺特徵,其中包含可度量色彩、色彩分布、色彩結構、邊緣直方圖和紋理五類特徵,建立spb樹,並對各圖像進行t-nn查詢,獲得與其最相近的t個查詢結果,進而建立t-nn圖。
步驟(2)中根據圖像t-nn圖和圖像的社交關聯信息建立超圖模型,其中超圖種類有三種:
1)以圖像t-nn圖中的各圖像和其t-nn圖像作為一種超邊;
2)以用戶對圖像進行標註的三元組合作為一種超邊;
3)以用戶對圖像進行評價的多元組合作為一種超邊。
步驟(2)中計算超圖轉移概率矩陣的具體步驟如下:
用g(v,e,w)表示一個超圖,其中v是結點集合,e是超邊集合,w是一個權重函數;一個超圖可以用一個|v|×|e|的矩陣h表示,其中矩陣元素h(v,e)為:
其中,v為結點,e為超邊;
結點v的度d(v)可以表示為:
d(v)=∑e∈e|v∈ew(e)=∑e∈ew(e)h(v,e)
其中,w(e)表示超邊e的權重;
超邊e的度δ(e)可以表示為:
δ(e)=|e|=∑v∈vh(v,e)
超圖的轉移概率矩陣,用p來表示,則p中的元素p[u,v]表示從結點u到結點v的轉移概率,其可以使用如下公式進行計算:
步驟(2)中轉移概率矩陣採用批量插入方法、並行技術和緩衝技術存儲到b+樹中;在將轉移概率矩陣並存儲到b+樹中時,把超圖的出度結點和入度結點的組合作為鍵,轉移概率作為值;其中:
1)使用批量插入方法將元素插入到b+樹中,減少了逐個插入在查找插入位置上的重複遍歷,按序插入又提升了局部性和b+樹結點空間利用率,提升b+樹結點插入的時間和空間效率;
2)由公式可知結點的入度邊權重僅和其自身以及入度結點有關,先使用一次遍歷統計結點和超邊的度,然後使用並行技術計算超圖轉移概率提升時間效率;
3)計算超圖轉移概率矩陣和b+樹元素插入可以並行,其間的數據流動使用一個雙緩衝,兩個緩衝區分別寫入超圖轉移概率矩陣元素和讀出待插入b+樹的元素,若寫緩衝滿或讀緩衝空時,交換兩個緩衝區;
b+樹存儲於磁碟上,具有可擴展性。
步驟(3)中k是用戶指定的查詢返回結點個數。查詢向量包含若干查詢結點,各查詢結點權重可由用戶指定,以對查詢結點有所側重,所有查詢結點的權重之和標準化為1。
步驟(4)中的個性化pagerank以查詢向量和k值作為輸入,在每輪迭代中,根據轉移概率矩陣,結點從該結點的入度結點獲得排名得分,該排名得分值為上一輪該入度結點的排名得分和轉移概率的乘積。
步驟(4)中上、下界估計具體如下:
1)對於下界估計,第i輪的下界估計si[u]使用如下公式計算:
其中,c為阻尼係數(一般取0.8);,i為當前迭代輪次,si-1[u]為第i-1輪的下界估計;λi[u]為第i輪迭代中從查詢節點到節點u的隨機遊走概率值,具體公式如下:
其中,q表示查詢向量,q[u]表示結點u的權重,且∑u∈vq[u]=1;另外用c[u]來表示結點u的入度結點集合,λi-1[v]為第i-1輪迭代中從查詢節點到節點v的隨機遊走概率值;
2)對於上界估計,第i輪上界估計使用如下公式計算:
其中,pmax[u]=max{p[v,u]|v∈v}為當前結點u的所有入度轉移概率的最大值;
步驟(4)中利用上、下界估計方法過濾超圖的結點,具體過濾步驟如下:
(4.1)當候選點集合大小大於k時,若候選點集合中的某結點的上界估計大於當前第k大的結點下界估計,則該結點為候選點,可能出現在最終的k個結果中,否則不可能成為結果點,則拋棄;若候選點集合大小為k時,則候選點集合中所有結點為最終返回結果,候選點集合中的結點排序通過步驟(4.2)或步驟(4.3)確定;
(4.2)當候選結點集合大小為k時,若候選結點集合中某結點的下界估計均大於集合內其他結點的上界估計,或者某結點的上界估計均小於集合內其他結點的下界估計時,則該結點的排序確定,將該結點加入結果結點集合;候選結點排序全部確定時停止迭代;
(4.3)當候選結點集合大小為k時,檢測當前所有候選結點的上下界估計差值,若所有結點的上下界估計差值小於設定閾值時,停止迭代,結點的排序根據下界估計降序確定。
步驟(5)中用戶對步驟(4)得到的k個結果進行評價,選出其中符合其查詢意願的結果圖像作為反饋節點,根據反饋節點調整步驟(4)中查詢向量,將反饋結點插入原查詢向量中,構成新的查詢向量,對新的查詢向量中的原查詢結點和新插入查詢結點重新進行權重分配,原查詢結點總權重為0.5,新插入查詢結點總權重為0.5,新插入結點平分此0.5的權重;再次進行步驟(4)中個性化pagerank查詢,並使用上、下界估計方法進行過濾,最終獲得新的查詢結果並返回給用戶。