一種高維不完整數據特徵選擇方法與流程
2023-09-14 15:59:20 5
本發明涉及一種高維不完整數據特徵選擇方法,屬於機器學習,數據挖掘技術領域。
背景技術:
隨著數據獲取技術的發展,高維數據廣泛應用在於社交網絡,圖像處理,生物醫學等領域中.然而在實際的數據的採集中,由於探測儀器的限制、數據敏感、樣本破損等原因會導致採集數據的不完整,從而形成高維不完整數據.對於不完整數據的預處理通常採用刪除和填補的方法,對於包含了大量冗餘信息和噪聲的高維數據,通常先採用特徵提取和特徵選擇[6]對其進行降維.根據特徵子集評估策略的差異,可將特徵選擇分為三類:filter模型、wrapper模型和embedded模型.filter模型僅依賴數據的內在特性來選擇特徵,而不依賴任何具體的學習算法指導.wrapper模型則需要一個預先設定的學習算法,將特徵子集在其算法上的表現作為評估來確定最終的特徵子集.embedded模型則是在學習算法的目標分析過程中包含變量選擇,將此作為訓練過程的一部分.共同之處是這三種模型都是通過相關性度量來選擇特徵,但是對於高維數據,得到的相關矩陣中會存在大量噪聲.
隨機矩陣理論(randommatrixtheory,rmt)通過比較隨機的多維序列統計特性,可以體現出實際數據對隨機的偏離程度,並揭示實際數據中整體關聯的行為特徵.隨機矩陣理論是在原子物理中由wigner,dyson,mehta等人發展而來,在物理學,通訊理論,金融等方面應用非常廣泛.laloux(1999)[9]等人研究了如何去掉金融相關係數矩陣的噪聲,plerou(2002)等人詳細研究了相關矩陣的特徵值、特徵向量的分布.
本文以隨機矩陣理論為基礎,提出一種特徵選擇方法,通過比較原始數據的相關矩陣和隨機數據的相關矩陣在奇異值上的差異,去除原始相關矩陣的噪聲,同時充分利用奇異值分解後的子矩陣來消除特徵之間的冗餘性,更好的實現特徵選擇.又根據熵概率選擇,使這種方法能夠應用於不完整數據.在分類準確率和運行時間上表明了本方法的高效性.
技術實現要素:
本發明針對現有技術的不足,本發明提供一種高維不完整數據特徵選擇方法。
本發明的是通過下述技術方案實現的:一種高維不完整數據特徵選擇方法,包括如下步驟:
(1)判斷初始數據是否為完整數據;若為不完整數據,則轉到步驟(2);若為完整數據,則轉到步驟(3);
(2)採用不完整矩陣計算方法處理數據,具體為:
(2.1)假設現在有各個維度的數據,用1表示該數據項是完整的,用0表示該數據項是缺失的.計算每個維度的缺失率,接著通過下式計算缺失熵:
其中pi是每個維度的缺失率,h(x)表示缺失熵;
(2.2)h(x)越大說明不確定性越高,缺失率越接近0.5,h(x)的極值為0.5;依次算出每個維度的缺失熵;
(2.3)對結果進行加權平均;
(2.4)對每一個維度x的缺失值,p(忽略)=hmean(x),p(填補)=1-hmean(x);
(3)在高維數據中進行特徵選擇時,通過比較原始數據矩陣的相關矩陣和隨機矩陣在奇異值上的差異,對相關矩陣進行去噪,其實現步驟如下:
(3.1)設有原始n×l數據矩陣d,其中特徵集合f={f1,f2,…,,ft},類集合c={c1,c2,…,ck},通過(1)式構建互信息矩陣m,當k較小時,無法很好的滿足隨機矩陣的特徵,因此需要對m進行增廣,複製m次,即m=[m,m(m)],為了保持初始的行列比,這裡m=((l-1)2/n*k)-1.
其中p(x,y)是特徵和類別的聯合分布,p(x)和p(y)分別是特徵和類別的出現概率
(3.2)為了保證一般性,對矩陣m進行規範化,通過(2)式中心化,然後再通過(3)式進行標準化,得到矩陣md.接著根據(4)式計算得到t×t的特徵相關矩陣c.
iij是矩陣m中第i行第j列的元素,maxii是第i行中最大的元素,minii是第i行中最小的元素。
是(2)式中的求得的元素,表示求第i行中所有元素平方和的算術平方根
(3.3)對c按(5)式進行奇異值分解.其中λ=diag(σ1,σ2,…,σr)且σ1≥σ2≥…σt>0,σi(i=1,2,…,r)為矩陣c的奇異值,這時稱上式為矩陣c的奇異值分解式.
c=uλv(5)
(3.4)建立t×m隨機矩陣,其變量服從均值為0,方差為1的正態分布,根據下式可以得到相關矩陣的最大特徵值.
其中q是矩陣的行列比,即q=t/m,;
(3.5)根據隨機矩陣理論,認為的奇異值是噪聲,則令所有i≥j的σi=0,t-j剩下的j-1個奇異值包含了所有的真實信息,因此可以矩陣相乘得到新的相關矩陣cnew:
cnew=uλnewv(6)
(3.6)對cnew進行奇異值分解的到unew和vnew,,cnew中的每個元素kij表示任意2個特徵對初始類的相關程度,vnew中的每個元素eij是每個特徵對新類的相關程度.
(3.7)對通過去噪後的相關矩陣進行特徵選擇,特徵選擇的目標是去除與類不相關的特徵和相互冗餘的特徵.經過去噪的結果可知,共保留了j-1個奇異值,因此在這裡共選擇j-1個特徵,因此可以根據(7)式計算每一個特徵的重要度,其中f(i)表示第i個特徵的重要度,得到集合f={f1,f1,…,fi},接著對f進行降序排序,選擇前j-1個重要度最大的特徵,從而完成特徵選擇;
其中iij是矩陣m的第i行第j列的元素,eij是(6)式中cnew奇異值分解後得到的右奇異矩陣vnew的第i行第j列的元素,kij是相關矩陣cnew的第i行第j列的元素。
本發明的有益效果:與現有技術相比,本發明提出基於隨機矩陣理論的特徵選擇方法,其通過將相關矩陣中符合隨機矩陣預測的奇異值去除,從而得到去噪後的相關矩陣和選擇特徵的數量,接著對去噪後的相關矩陣再進行奇異值分解,通過分解矩陣獲得特徵與類的相關性,根據特徵與類的相關性和特徵之間冗餘性完成特徵選擇.。
附圖說明
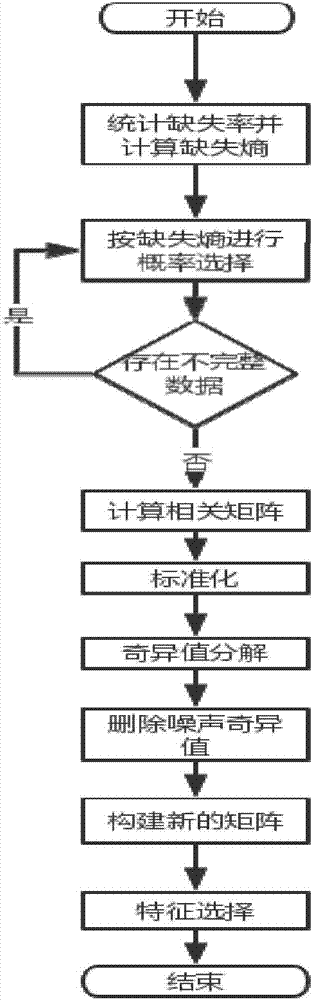
圖1為本發明方法流程圖。
具體實施方式
一種高維不完整數據特徵選擇方法,首先判斷初始數據是否為完整數據;如果原始數據是不完整的,無法按照完整數據的方式來計算。需要通過以下步驟針對不完整矩陣計算,具體包括如下:
第一步:假設現在有各個維度的數據,用1表示該數據項是完整的,用0表示該數據項是缺失的.計算每個維度的缺失率,接著通過下式計算缺失熵:
第二步:h(x)越大說明不確定性越高,缺失率越接近0.5,h(x)的極值為0.5;依次算出每個維度的缺失熵;
第三步:對結果進行加權平均;
第四步:對每一個維度x的缺失值,p(忽略)=hmean(x),p(填補)=1-hmean(x);本發明方法的具體應用過程如下:
如果原始數據是不完整的,無法按照完整數據的方式來計算.因此本文提出了一個不完整隨機矩陣計算方法.假設現在已經獲取到了一個n×l訓練數據矩陣,對於有數據缺失情況,需要更換計算方法.目前對於缺失值的處理通常有兩種方法:刪除和填補.考慮到缺失的數據可能是噪聲或者是真實值.因此在對缺失值進行計算時,採取一種基於概率選擇的計算方法.這裡通過一個例子來說明.
表1數據缺失情況
假設現在有各個維度的數據,用1表示該數據項是完整的,用0表示該數據項是缺失的.計算每個維度的缺失率,例如humidity,其缺失率p=2/7,接著通過下式計算缺失熵:
其中pi是每個維度的缺失率,h(x)表示缺失熵;
計算出維度humidity的熵,p(humidity=缺失)=p,p(humidity=完整)=1-p,則h(humidity)有:
h(p)=-plog2p-(1-p)log2(1-p)
h(p)=0.3,h(p)越大說明不確定性越高,缺失率越接近;依次算出每個維度的缺失熵得:
表2缺失熵
表3加權平均結果
接著進行加權平均,根據hmean(x)的值進行概率選澤.即對於每一個維度x的缺失值,p(忽略)=hmean(x),p(填補)=1-hmean(x).
對於完整數據則執行以下步驟:
在高維數據中進行特徵選擇時,通過比較原始數據矩陣的相關矩陣和隨機矩陣在奇異值上的差異,對相關矩陣進行去噪,其實現步驟如下:
第一步:設有原始n×l數據矩陣d,其中特徵集合f={f1,f2,…,,ft},類集合c={c1,c2,…,ck},通過(1)式構建互信息矩陣m,當k較小時,無法很好的滿足隨機矩陣的特徵,因此需要對m進行增廣,複製m次,即m=[m,m(m)],為了保持初始的行列比,這裡m=(l2/n)-1.
其中p(x,y)是特徵和類別的聯合分布,p(x)和p(y)分別是特徵和類別的出現概率
第二步:為了保證一般性,對矩陣m進行規範化,通過(2)式中心化,再通過(3)式標準化,得到矩陣md.接著根據(4)式計算得到t×t的特徵相關矩陣c.
iij是矩陣m中第i行第j列的元素,maxii是第i行中最大的元素,minii是第i行中最小的元素。
是(2)式中的求得的元素,表示求第i行中所有元素平方和的算術平方根;
第三步:對c按(5)式進行奇異值分解.其中λ=diag(σ1,σ2,…,σr)且σ1≥σ2≥…σt>0,σi(i=1,2,…,r)為矩陣c的奇異值,這時稱上式為矩陣c的奇異值分解式.
c=uλv(5)
第四步:建立t×m隨機矩陣,其變量服從均值為0,方差為1的正態分布,根據下式可以得到相關矩陣的最大特徵值.
其中q是矩陣的行列比,即q=t/m,;
第五步:根據隨機矩陣理論,認為的奇異值是噪聲,則令所有i≥j的σi=0,剩下的j-1個奇異值包含了所有的真實信息,因此可以矩陣相乘得到新的相關矩陣cnew:
cnew=uλnewv(6)
第六步:對cnew進行奇異值分解的到unew和vnew,cnew中的每個元素kij表示任意2個特徵對初始類的相關程度,vnew中的每個元素eij是每個特徵對新類的相關程度.
第七步:對通過去噪後的相關矩陣進行特徵選擇,特徵選擇的目標是去除與類不相關的特徵和相互冗餘的特徵.經過去噪的結果可知,共保留了j-1個奇異值,因此在這裡共選擇j-1個特徵,因此可以根據(6)式計算每一個特徵的重要度,其中f(i)表示第i個特徵的重要度,得到集合f={f1,f1,…,fi},接著對f進行降序排序,選擇前j-1個重要度最大的特徵,從而完成特徵選擇.
其中iij是矩陣m的第i行第j列的元素,eij是(6)式中cnew奇異值分解後得到的右奇異矩陣vnew的第i行第j列的元素,kij是相關矩陣cnew的第i行第j列的元素。
(3)實驗
(3.1)實驗數據集
為了說明本文提出的特徵選擇方法的有效性,通過分類實驗來驗證。選取uci機器學習知識庫上10個數據集進行實驗。表4是對數據集的描述,數據集中的實例數從13910到101,特徵從649到17,分布範圍很寬廣。
表4實驗中用到的數據集
(3.2)實驗結果與分析
實驗在win7_64系統,8gb內存,主頻2.93ghz的corei7-870的pc上運行,採用python3.6,scikit-learn工具包。使用經典的mdl[11]方法對數據進行離散化,採用1-n,cart,bayse三種分類器,選擇fcbf[12],mrmr[13],ig[14],cfs[15],relief-f[16]這5種經典特徵選擇方法與本文所提出的特徵選擇方法rmfs,rmfs-o進行對比。在給定的數據集上的10折交叉驗證,並給出了它們在10個數據集上的平均準確率。在表的最後一行wtl表示該特徵選擇方法與本文所提出的特徵選擇方法相比在10個數據集上的高於/持平/弱於的次數。同時在每一個數據集上的較高的準確率,以粗體表示。
表51-nn分類器準確率
表6cart分類器準確率
表7bayse分類器準確率
表8選擇特徵的個數
根據表5.6.7,可以看出本文所提的特徵選擇方法在三個分類器上整體勝率是63.3%,在平均準確率上的勝率是100%。當特徵數大於100時,整體勝率是90.4%,在高維特徵選擇表現優異。相對於表現較好的fcbf,本方法在平均準確率上領先其1.86%。同時所提出的優化方法rmfs-o相對於rmfs在特徵數大於300時,平均準確率領先1.38%。根據表8,本方法在平均特徵選擇數量上明顯優於對比方法,相對於最好的fcbf,平均縮小了44.4%的數據規模。當特徵數大於300時,類大於10時,相對於對比方法,平均縮小了59.7%的數據規模。